o3
See livestream, site, OpenAI thread, Nat McAleese thread.
OpenAI announced (but isn’t yet releasing) o3 and o3-mini (skipping o2 because of telecom company O2′s trademark). “We plan to deploy these models early next year.” “o3 is powered by further scaling up RL beyond o1″; I don’t know whether it’s a new base model.
o3 gets 25% on FrontierMath, smashing the previous SoTA. (These are really hard math problems.[1]) Wow. (The dark blue bar, about 7%, is presumably one-attempt and most comparable to the old SoTA; unfortunately OpenAI didn’t say what the light blue bar is, but I think it doesn’t really matter and the 25% is for real.[2])
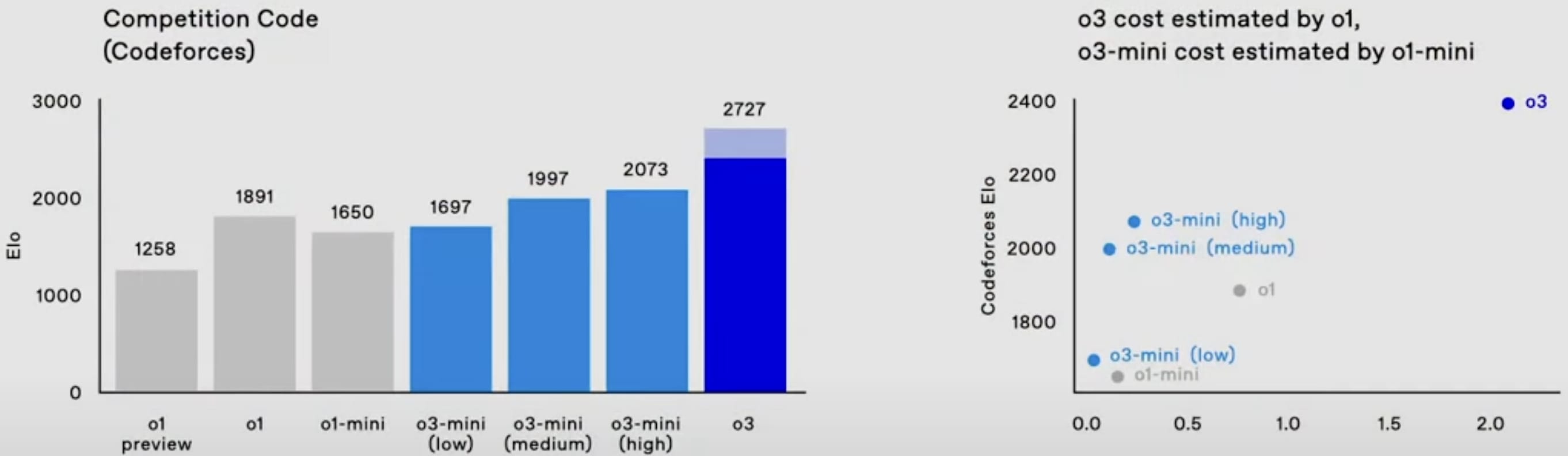
o3 also is easily SoTA on SWE-bench Verified and Codeforces.
It’s also easily SoTA on ARC-AGI, after doing RL on the public ARC-AGI problems[3] + when spending $4,000 per task on inference (!).[4] (And at less inference cost.)
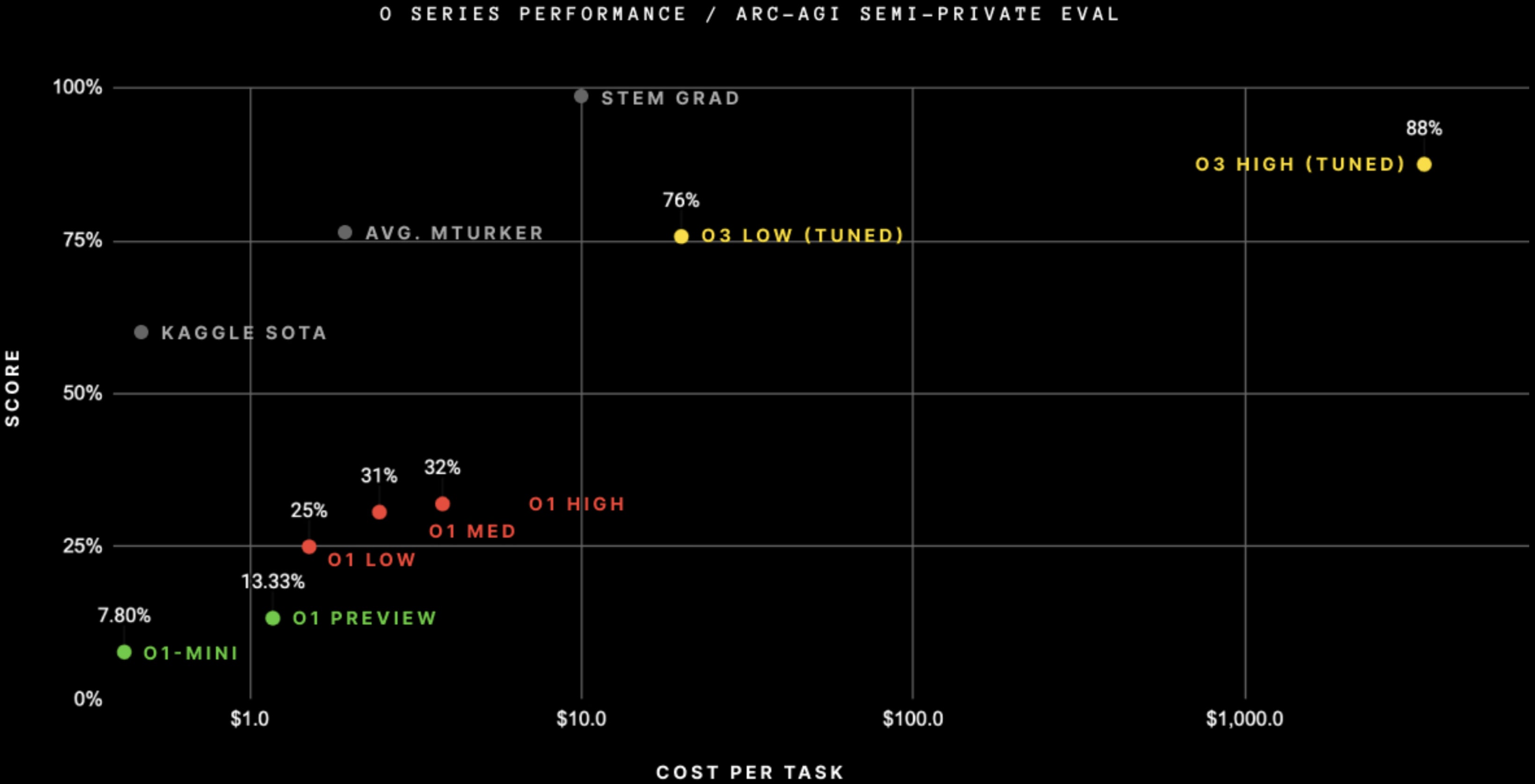
ARC Prize says:
At OpenAI’s direction, we tested at two levels of compute with variable sample sizes: 6 (high-efficiency) and 1024 (low-efficiency, 172x compute).
OpenAI has a “new alignment strategy.” (Just about the “modern LLMs still comply with malicious prompts, overrefuse benign queries, and fall victim to jailbreak attacks” problem.) It looks like RLAIF/Constitutional AI. See Lawrence Chan’s thread.[5]
OpenAI says “We’re offering safety and security researchers early access to our next frontier models”; yay.
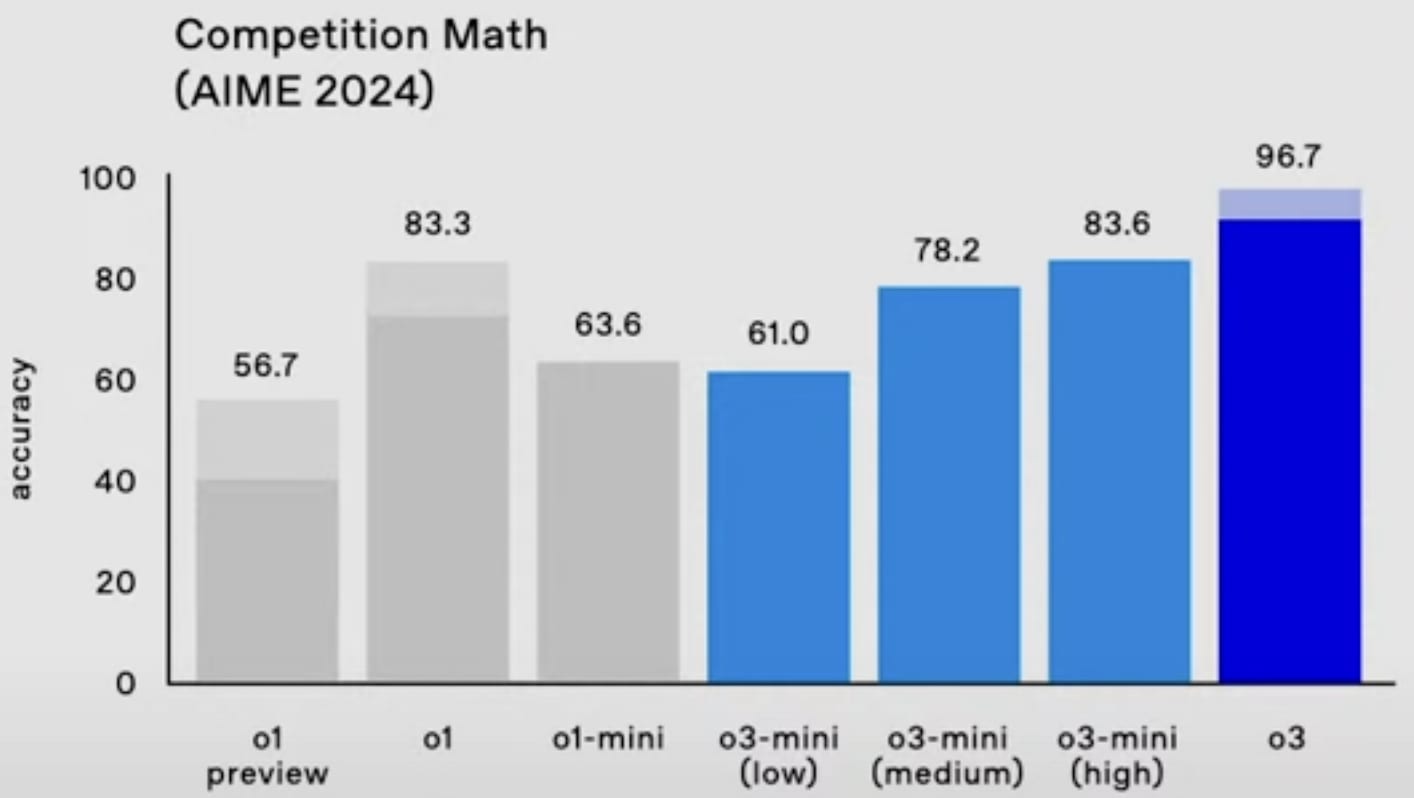
o3-mini will be able to use a low, medium, or high amount of inference compute, depending on the task and the user’s preferences. o3-mini (medium) outperforms o1 (at least on Codeforces and the 2024 AIME) with less inference cost.
GPQA Diamond:
- ^
Update: most of them are not as hard as I thought:
There are 3 tiers of difficulty within FrontierMath: 25% T1 = IMO/undergrad style problems, 50% T2 = grad/qualifying exam style [problems], 25% T3 = early researcher problems.
- ^
My guess is it’s consensus@128 or something (i.e. write 128 answers and submit the most common one). Even if it’s pass@n (i.e. submit n tries) rather than consensus@n, that’s likely reasonable because I heard FrontierMath is designed to have easier-to-verify numerical-ish answers.
Update: it’s not pass@n.
- ^
Correction: no RL! See comment.
Correction to correction: nevermind, I’m confused.
- ^
It’s not clear how they can leverage so much inference compute; they must be doing more than consensus@n. See Vladimir_Nesov’s comment.
- ^
Update: see also disagreement from one of the authors.
- Teaching AI to reason: this year’s most important story by (EA Forum; Feb 13, 2025, 5:56 PM; 140 points)
- Five years of donating by (EA Forum; Dec 27, 2024, 2:57 PM; 95 points)
- o3, Oh My by (Dec 30, 2024, 2:10 PM; 63 points)
- Teaching AI to reason: this year’s most important story by (Feb 13, 2025, 5:40 PM; 10 points)
I’m going to go against the flow here and not be easily impressed. I suppose it might just be copium.
Any actual reason to expect that the new model beating these challenging benchmarks, which have previously remained unconquered, is any more of a big deal than the last several times a new model beat a bunch of challenging benchmarks that have previously remained unconquered?
Don’t get me wrong, I’m sure it’s amazingly more capable in the domains in which it’s amazingly more capable. But I see quite a lot of “AGI achieved” panicking/exhilaration in various discussions, and I wonder whether it’s more justified this time than the last several times this pattern played out. Does anything indicate that this capability advancement is going to generalize in a meaningful way to real-world tasks and real-world autonomy, rather than remaining limited to the domain of extremely well-posed problems?
One of the reasons I’m skeptical is the part where it requires thousands of dollars’ worth of inference-time compute. Implies it’s doing brute force at extreme scale, which is a strategy that’d only work for, again, domains of well-posed problems with easily verifiable solutions. Similar to how o1 blows Sonnet 3.5.1 out of the water on math, but isn’t much better outside that.
Edit: If we actually look at the benchmarks here:
The most impressive-looking jump is FrontierMath from 2% to 25.2%, but it’s also exactly the benchmark where the strategy of “generate 10k candidate solutions, hook them up to a theorem-verifier, see if one of them checks out, output it” would shine.
(With the potential theorem-verifier having been internalized by o3 over the course of its training; I’m not saying there was a separate theorem-verifier manually wrapped around o3.)
Significant progress on ARC-AGI has previously been achieved using “crude program enumeration”, which made the authors conclude that “about half of the benchmark was not a strong signal towards AGI”.
The SWE jump from 48.9 to 71.7 is significant, but it’s not much of a qualitative improvement.
Not to say it’s a nothingburger, of course. But I’m not feeling the AGI here.
It’s not AGI, but for human labor to retain any long-term value, there has to be an impenetrable wall that AI research hits, and this result rules out a small but nonzero number of locations that wall might’ve been.
To first order, I believe a lot of the reason why the “AGI achieved” shrill posting often tends to be overhyped is that not because the models are theoretically incapable, but rather that reliability was way more of a requirement for it to replace jobs fast than people realized, and there are only a very few jobs where an AI agent can do well without instantly breaking down because it can’t error-correct/be reliable, and I think this has been continually underestimated by AI bulls.
Indeed, one of my broader updates is that a capability is only important to the broader economy if it’s very, very reliable, and I agree with Leo Gao and Alexander Gietelink Oldenziel that reliability is a bottleneck way more than people thought:
https://www.lesswrong.com/posts/YiRsCfkJ2ERGpRpen/leogao-s-shortform#f5WAxD3WfjQgefeZz
https://www.lesswrong.com/posts/YiRsCfkJ2ERGpRpen/leogao-s-shortform#YxLCWZ9ZfhPdjojnv
I agree that this seems like an important factor. See also this post making a similar point.
To be clear, I do expect AI to accelerate AI research, and AI research may be one of the few exceptions to this rule, but it’s one of the reasons I have longer timelines nowadays than a lot of other people, and also why I expect AI impact on the economy to be surprisingly discontinuous in practice, and is a big reason I expect AI governance have few laws passed until very near the end of the AI as complement era for most jobs that are not AI research.
The post you linked is pretty great, thanks for sharing.
These math and coding benchmarks are so narrow that I’m not sure how anybody could treat them as saying anything about “AGI”. LLMs haven’t even tried to be actually general.
How close is “the model” to passing the Woz test (go into a strange house, locate the kitchen, and make a cup of coffee, implicitly without damaging or disrupting things)? If you don’t think the kinesthetic parts of robotics count as part of “intelligence” (and why not?), then could it interactively direct a dumb but dextrous robot to do that?
Can it design a nontrivial, useful physical mechanism that does a novel task effectively and can be built efficiently? Produce usable, physically accurate drawings of it? Actually make it, or at least provide a good enough design that it can have it made? Diagnose problems with it? Improve the design based on observing how the actual device works?
Can it look at somebody else’s mechanical design and form a reasonably reliable opinion about whether it’ll work?
Even in the coding domain, can it build and deploy an entire software stack offering a meaningful service on a real server without assistance?
Can it start an actual business and run it profitably over the long term? Or at least take a good shot at it? Or do anything else that involves integrating multiple domains of competence to flexibly pursue possibly-somewhat-fuzzily-defined goals over a long time in an imperfectly known and changing environment?
Can it learn from experience and mistakes in actual use, without the hobbling training-versus-inference distinction? How quickly and flexibly can it do that?
When it schemes, are its schemes realistically feasible? Can it tell when it’s being conned, and how? Can it recognize an obvious setup like “copy this file to another directory to escape containment”?
Can it successfully persuade people to do specific, relatively complicated things (as opposed to making transparently unworkable hypothetical plans to persuade them)?
It’s not really dangerous real AGI yet. But it will be soon this is a version that’s like a human with severe brain damage to the frontal lobes that provide agency and self-management, and the temporal lobe, which does episodic memory and therefore continuous, self-directed learning.
Those things are relatively easy to add, since it’s smart enough to self-manage as an agent and self-direct its learning. Episodic memory systems exist and only need modest improvements—some low-hanging fruit are glaringly obvious from a computational neuroscience perspective, so I expect them to be employed almost as soon as a competent team starts working on episodic memory.
Don’t indulge in even possible copium. We need your help to align these things, fast. The possibility of dangerous AGI soon can no longer be ignored.
Gambling that the gaps in LLMs abilities (relative to humans) won’t be filled soon is a bad gamble.
A very large amount of human problem solving/innovation in challenging areas is creating and evaluating potential solutions, it is a stochastic rather than deterministic process. My understanding is that our brains are highly parallelized in evaluating ideas in thousands of ‘cortical columns’ a few mm across (Jeff Hawkin’s 1000 brains formulation) with an attention mechanism that promotes the filtered best outputs of those myriad processes forming our ‘consciousness’.
So generating and discarding large numbers of solutions within simpler ‘sub brains’, via iterative, or parallelized operation is very much how I would expect to see AGI and SI develop.
Questions for people who know more:
Am I understanding right that inference compute scaling time is useful for coding, math, and other things that are machine-checkable, but not for writing, basic science, and other things that aren’t machine-checkable? Will it ever have implications for these things?
Am I understanding right that this is all just clever ways of having it come up with many different answers or subanswers or preanswers, then picking the good ones to expand upon? Why should this be good for eg proving difficult math theorems, where many humans using many different approaches have failed, so it doesn’t seem like it’s as simple as trying a hundred times, or even trying using a hundred different strategies?
What do people mean when they say that o1 and o3 have “opened up new scaling laws” and that inference-time compute will be really exciting? Doesn’t “scaling inference compute” just mean “spending more money and waiting longer on each prompt”? Why do we expect this to scale? Does inference compute scaling mean that o3 will use ten supercomputers for one hour per prompt, o4 will use a hundred supercomputers for ten hours per prompt, and o5 will use a thousand supercomputers for a hundred hours per prompt? Since they already have all the supercomputers (for training scaling) why does it take time and progress to get to the higher inference-compute levels? What is o3 doing that you couldn’t do by running o1 on more computers for longer?
The basic guess regarding how o3′s training loop works is that it generates a bunch of chains of thoughts (or, rather, a branching tree), then uses some learned meta-heuristic to pick the best chain of thought and output it.
As part of that, it also learns a meta-heuristic for which chains of thought to generate to begin with. (I. e., it continually makes judgement calls regarding which trains of thought to pursue, rather than e. g. generating all combinatorially possible combinations of letters.)
It would indeed work best in domains that allow machine verification, because then there’s an easily computed ground-truth RL signal for training the meta-heuristic. Run each CoT through a proof verifier/an array of unit tests, then assign reward based on that. The learned meta-heuristics can then just internalize that machine verifier. (I. e., they’d basically copy the proof-verifier into the meta-heuristics. Then (a) once a spread of CoTs is generated, it can easily prune those that involve mathematically invalid steps, and (b) the LLM would become ever-more-unlikely to generate a CoT that involves mathematically invalid steps to begin with.)
However, arguably, the capability gains could transfer to domains outside math/programming.
There are two main possibilities here:
You can jury-rig “machine verification” for “soft domains” by having an LLM inspect the spread of ideas it generated (e. g., 100 business plans), then pick the best one, using the LLM’s learned intuition as the reward function. (See e. g. how Constitutional AI works, compared to RLHF.)
You can hope that the meta-heuristics, after being trained on math/programming, learn some general-purpose “taste”, an ability to tell which CoTs are better or worse, in a way that automatically generalizes to “soft” domains (perhaps with some additional fine-tuning using the previous idea).
That said, empirically, if we compare o1-full to Claude Sonnet 3.5.1, it doesn’t seem that the former dominates the latter in “soft” domains as dramatically as it does at math. So the transfer, if it happens at all, isn’t everything AI researchers could hope for.
Also, there’s another subtle point here:
o1′s public version doesn’t seem to actually generate trees of thought in response to user queries and then pruning it. It just deterministically picks the best train of thought to pursue as judged by the learned meta-heuristic (the part of it that’s guiding which trees to generate; see the previous point regarding how it doesn’t just generate all possible combinations of letters, but makes judgement calls regarding that as well).
By contrast, o3 definitely generates that tree (else it couldn’t have spent thousands-of-dollars’ worth of compute on individual tasks, due to the context-window limitations).
The best guess based on the publicly available information is that yes, this is the case.
Which strategies you’re trying matters. It indeed wouldn’t do much good if you just pick completely random steps/generate totally random messages. But if you’ve trained some heuristic for picking the best-seeming strategies among the strategy-space, and this heuristic has superhuman research taste...
That for a given LLM model being steered by a given meta-heuristic, the performance on benchmarks steadily improves with the length of CoTs / the breadth of the ToTs generated.
Straight lines on graphs go brr? Same as with the pre-training laws. We see a simple pattern, we assume it extrapolates.
I’m not sure. It’s possible that a given meta-heuristic can only keep the LLM on-track for a fixed length of CoT / for a fixed breadth of ToT. You would then need to learn how to train better meta-heuristics to squeeze out more performance.
A possible explanation is that you need “more refined” tastes to pick between a broader range of CoTs. E. g., suppose that the quality of CoTs is on a 0-100 scale. Suppose you’ve generated a spread of CoTs, and the top 5 of them have the “ground-truth quality” of 99.6, 99.4, 98, 97, 96. Suppose your meta-heuristic is of the form Q + e, where Q is the ground-truth quality and e is some approximation-error term. If e is on the order of 0.5, then the model can’t distinguish between the top 2 guesses, and picks one at random. If e is on the order of 0.05, however, it reliably picks the best guess of those five. This can scale: then, depending on how “coarse” your model’s tastes are, it can pick out the best guess among 10^4, 10^5 guesses, etc.
(I. e., then the inference-time scaling law isn’t just “train any good-enough meta-heuristic and pour compute”, it’s “we can train increasingly better meta-heuristics, and the more compute they can usefully consume at inference-time, the better the performance”.)
(Also: notably, the issue with the transfer-of-performance might be that how “refined” the meta-heuristic’s taste is depends on the domain. E. g., for math, the error term might be 10^-5, for programming 10^-4, and for “soft” domains, 10^-1.)
Not necessarily. The strength of the LLM model being steered, and the quality of the meta-heuristics doing the steering, matters. GPT-5 can plausibly outperfrom o3-full for much less inference-time compute, by needing shorter CoTs. “o3.5”, using the same LLM but equipped with a better-trained meta-level heuristic, can likewise outperform o3 by having a better judgement regarding which trains of thought to pursue (roughly, the best guess of o3.5 among 10 guesses would be as good as the best guess of o3 among 100 guesses).
And then if my guess regarding different meta-heuristics only being able to make use of no more than a fixed quantity of compute is right, then yes, o[3+n] models would also be able to usefully consume more raw compute.
Edit: I. e., there are basically three variables at play here:
How many guesses it needs to find a guess with a ground-truth quality above some threshold. (How refined the “steering” meta-heuristic is. What is the ground-truth quality of the best guess in 100 guesses it generated? How much is the probability distribution over guesses skewed towards the high-quality guesses?)
How refined the tastes of the “pruning” meta-heuristic are. (I. e., the size of the error e in the toy Q + e model above. Mediates the number of guesses among which it can pick the actual best one, assuming that they’re drawn from a fixed distribution.)
How long the high-quality CoTs are. (E. g., recall how much useless work/backtracking o1′s publicly shown CoTs seems to do, and how much more efficient it’d be if the base LLM were smart enough to just instantly output the correct answer, on pure instinct.)
Improving on (1) and (3) increases the efficiency of the compute used by the models. Improving on (2) lets models productively use more compute.
And notably, capabilities could grow either from improving on (2), in a straightforward manner, or from improving (1) and (3). For example, suppose that there’s a “taste overhang”, in that o3′s tastes are refined enough to reliably pick the best guess out of 10^9 guesses (drawn from a fixed distribution), but it is only economical to let it generate 10^5 guesses. Then improving on (1) (skewing the distribution towards the high-quality guesses) and (3) (making guesses cheaper) would not only reduce the costs, but also increase the quality of the ultimately-picked guesses.
(My intuition is that there’s no taste overhang, though; and also that the tastes indeed get increasingly less refined the farther you move from the machine-verifiable domains.)
This is good speculation, but I don’t think you need to speculate so much. Papers and replication attempts can provide lots of empirical data points from which to speculate.
You should check out some of the related papers
H4 uses a process supervision reward model, with MCTS and attempts to replicate o1
(sp fixed) DeepSeek uses R1 to train DeepSeek v3
Overall, I see people using process supervision to make a reward model that is one step better than the SoTA. Then they are applying TTC to the reward model, while using it to train/distil a cheaper model. The TTC expense is a one-off cost, since it’s used to distil to a cheaper model.
There are some papers about the future of this trend:
Meta uses reasoning tokens to allow models to reason in a latent space (the hidden state, yuck). OpenAI insiders have said that o3 does not work like this, but o4 might. {I would hope they chose a much better latent space than the hidden state. Something interpretable, that’s not just designed to be de-embedded into output tokens.}
Meta throws out tokenisation in favour of grouping predictable bytes
I can see other methods used here instead of process supervision. Process supervision extracts additional supervision from easy to verify domains. But diffusion does something very similar for domains where we can apply noise, like code.
Codefusion shows diffusion with code
Meta has an llm+diffusion paper, and so does Apple
Some older background papers might be useful for reference.
[OpenAI’]s process supervision paper](https://openai.com/index/improving-mathematical-reasoning-with-process-supervision/)
“Let’s Verify Step by Step”
Deepmind’s TTC scaling laws
More than an argument, we can look at the o3 announcement, where iirc it shows around 30% of the gain in non-code benchmarks. Less, but still substantial.
P.S. I think it’s worth noting that Meta has some amazing papers here, but they are also the most open source lab. It seems likely that other labs are also sitting on capabilities advancements that they do not allow researchers to publish.
P.P.S I also liked the alignment paper that came out with o3, since applying RLHF at multiple stages, and with process supervision seems useful. Its alignment seems to generalise better OOD (table 3). It also gives some clues to how o3 works, giving examples of CoT data.
@Scott Alexander, correction to the above: there are rumors that, like o1, o3 doesn’t generate runtime trees of thought either, and that they spent thousands-of-dollars’ worth of compute on single tasks by (1) having it generate a thousand separate CoTs, (2) outputting the answer the model produced most frequently. I. e., the “pruning meta-heuristic” I speculated about might just be the (manually-implemented) majority vote.
I think the guy in the quotes might be misinterpreting OpenAI researchers’ statements, but it’s possible.
In which case:
We have to slightly reinterpret the reason for having the model try a thousand times. Rather than outputting the correct answer if at least one try is correct, it outputs the correct answer if, in N tries, it produces the correct answer more frequently than incorrect ones. The fact that they had to set N = 1024 for best performance on ARC-AGI still suggests there’s a large amount of brute-forcing involved.
Since it implies that if N = 100, the correct answer isn’t more frequent than incorrect ones. So on the problems which o3 got wrong in the N = 6 regime but got right in the N = 1024 regime, the probability of any given CoT producing the correct answer is quite low.
This has similar implications for the FrontierMath performance, if the interpretation of the dark-blue vs. light-blue bars is that dark-blue is for N = 1 or N = 6, and light-blue is for N = bignumber.
We have to throw out everything about the “pruning” meta-heuristics; only the “steering” meta-heuristics exist. In this case, the transfer-of-performance problem would be that the “steering” heuristics only become better for math/programming; that RL only skewes the distribution over CoTs towards the high-quality ones for problems in those domains. (The metaphorical “taste” then still exists, but only within CoTs.)
(I now somewhat regret introducing the “steering vs. pruning meta-heuristic” terminology.)
Again, I think this isn’t really confirmed, but I can very much see it.
Jumping in late just to say one thing very directly: I believe you are correct to be skeptical of the framing that inference compute introduces a “new scaling law”. Yes, we now have two ways of using more compute to get better performance – at training time or at inference time. But (as you’re presumably thinking) training compute can be amortized across all occasions when the model is used, while inference compute cannot, which means it won’t be worthwhile to go very far down the road of scaling inference compute.
We will continue to increase inference compute, for problems that are difficult enough to call for it, and more so as efficiency gains reduce the cost. But given the log-linear nature of the scaling law, and the inability to amortize, I don’t think we’ll see the many-order-of-magnitude journey that we’ve seen for training compute.
As others have said, what we should presumably expect from o4, o5, etc. is that they’ll make better use of a given amount of compute (and/or be able to throw compute at a broader range of problems), not that they’ll primarily be about pushing farther up that log-linear graph.
Of course in the domain of natural intelligence, it is sometimes worth having a person go off and spend a full day on a problem, or even have a large team spend several years on a high-level problem. In other words, to spend lots of inference-time compute on a single high-level task. I have not tried to wrap my head around how that relates to scaling of inference-time compute. Is the relationship between the performance of a team on a task, and the number of person-days the team has to spend, log-linear???
Inference compute is amortized across future inference when trained upon, and the three-way scaling law exchange rates between training compute vs runtime compute vs model size are critical. See AlphaZero for a good example.
As always, if you can read only 1 thing about inference scaling, make it “Scaling Scaling Laws with Board Games”, Jones 2021.
And it’s not just a sensible theory. This has already happened, in Huggingface’s attempted replication of o1 where the reward model was larger, had TTC, and process supervision, but the smaller main model did not have any of those expensive properties.
And also in DeepSeek v3, where the expensive TTC model (R1) was used to train a cheaper conventional LLM (DeepSeek v3).
One way to frame it is test-time-compute is actually label-search-compute: you are searching for better labels/reward, and then training on them. Repeat as needed. This is obviously easier if you know what “better” means.
Test time compute is applied to solving a particular problem, so it’s very worthwhile to scale, getting better and better at solving an extremely hard problem by spending compute on this problem specifically. For some problems, no amount of pretraining with only modest test-time compute would be able to match an effort that starts with the problem and proceeds from there with a serious compute budget.
Yes, test time compute can be worthwhile to scale. My argument is that it is less worthwhile than scaling training compute. We should expect to see scaling of test time compute, but (I suggest) we shouldn’t expect this scaling to go as far as it has for training compute, and we should expect it to be employed sparingly.
The main reason I think this is worth bringing up is that people have been talking about test-time compute as “the new scaling law”, with the implication that it will pick up right where scaling of training compute left off, just keep turning the dial and you’ll keep getting better results. I think the idea that there is no wall, everything is going to continue just as it was except now the compute scaling happens on the inference side, is exaggerated.
There are many things that can’t be done at all right now. Some of them can become possible through scaling, and it’s unclear if it’s scaling of pretraining or scaling of test-time compute that gets them first, at any price, because scaling is not just amount of resources, but also the tech being ready to apply them. In this sense there is some equivalence.
I think it would be very surprising if it wasn’t useful at all—a human who spends time rewriting and revising their essay is making it better by spending more compute. When I do creative writing with LLMs, their outputs seem to be improved if we spend some time brainstorming the details of the content beforehand, with them then being able to tap into the details we’ve been thinking about.
It’s certainly going to be harder to train without machine-checkable criteria. But I’d be surprised if it was impossible—you can always do things like training a model to predict how much a human rater would like literary outputs, and gradually improve the rater models. Probably people are focusing on things like programming first both because it’s easier and also because there’s money in it.
Unclear, but with $20 per test settings on ARC-AGI it only uses 6 reasoning traces and still gets much better results than o1, so it’s not just about throwing $4000 at the problem. Possibly it’s based on GPT-4.5 or trained on more tests.
The standard scaling law people talk about is for pretraining, shown in the Kaplan and Hoffman (Chinchilla) papers.
It was also the case that various post-training (i.e., finetuning) techniques improve performance, (though I don’t think there is as clean of a scaling law, I’m unsure). See e.g., this paper which I just found via googling fine-tuning scaling laws. See also the Tülu 3 paper, Figure 4.
We have also already seen scaling law-type trends for inference compute, e.g., this paper:
The o1 blog post points out that they are observing two scaling trends: predictable scaling w.r.t. post-training (RL) compute, and predictable scaling w.r.t. inference compute:
The paragraph before this image says: “We have found that the performance of o1 consistently improves with more reinforcement learning (train-time compute) and with more time spent thinking (test-time compute). The constraints on scaling this approach differ substantially from those of LLM pretraining, and we are continuing to investigate them.” That is, the left graph is about post-training compute.
Following from that graph on the left, the o1 paradigm gives us models that are better for a fixed inference compute budget (which is basically what it means to train a model for longer or train a better model of the same size by using better algorithms — the method is new but not the trend), and following from the right, performance seems to scale well with inference compute budget. I’m not sure there’s sufficient public data to compare that graph on the right against other inference-compute scaling methods, but my guess is the returns are better.
I mean, if you replace “o1” in this sentence with “monkeys typing Shakespeare with ground truth verification,” it’s true, right? But o3 is actually a smarter mind in some sense, so it takes [presumably much] less inference compute to get similar performance. For instance, see this graph about o3-mini:
The performance-per-dollar frontier is pushed up by the o3-mini models. It would be somewhat interesting to know how much cost it would take for o1 to reach o3 performance here, but my guess is it’s a huge amount and practically impossible. That is, there are some performance levels that are practically unobtainable for o1, the same way the monkeys won’t actually complete Shakespeare.
Hope that clears things up some!
Maybe a dumb question, but those log scale graphs have uneven ticks on the x axis, is there a reason they structured it like that beyond trying to draw a straight line? I suspect there is a good reason and it’s not dishonesty but this does look like something one would do if you wanted to exaggerate the slope
I believe this is standard/acceptable for presenting log-axis data, but I’m not sure. This is a graph from the Kaplan paper:
It is certainly frustrating that they don’t label the x-axis. Here’s a quick conversation where I asked GPT4o to explain. You are correct that a quick look at this graph (where you don’t notice the log-scale) would imply (highly surprising and very strong) linear scaling trends. Scaling laws are generally very sub-linear, in particular often following a power-law. I don’t think they tried to mislead about this, instead this is a domain where log-scaling axes is super common and doesn’t invalidate the results in any way.
Ah wait was reading it wrong. I thought each time was an order of magnitude, that looks to be standard notation for log scale. Mischief managed
I do not have a gauge for how much I’m actually bringing to this convo, so you should weigh my opinion lightly, however:
I believe your third point kinda nails it. There are models for gains from collective intelligence (groups of agents collaborating) and the benefits of collaboration bottleneck hard on your ability to verify which outputs from the collective are the best, and even then the dropoff happens pretty quick the more agents collaborate.
10 people collaborating with no communication issues and accurate discrimination between good and bad ideas are better than a lone person on some tasks, 100 moreso
You do not see jumps like that moving from 1,000 to 1,000,000 unless you set unrealistic variables.
I think inference time probably works in a similar way: dependent on discrimination between right and wrong answers and steeply falling off as inference time increases
My understanding is that o3 is similar to o1 but probably with some specialization to make long chains of thought stay coherent? The cost per token from leaks I’ve seen is the same as o1, it came out very quickly after o1 and o1 was bizarrely better at math and coding than 4o
Apologies if this was no help, responding with the best intentions
Just trying to follow along… here’s where I’m at with a bear case that we haven’t seen evidence that o3 is an immediate harbinger of real transformative AGI:
Codeforces is based in part on wall clock time. And we all already knew that, if AI can do something at all, it can probably do it much faster than humans. So it’s a valid comparison to previous models but not straightforwardly a comparison to top human coders. (EDIT: Oops! This other comment says that they tried to calculate the score in a way that would ignore wall-clock time.)
FrontierMath is 25% tier 1 (least hard), 50% tier 2, 25% tier 3 (most hard). Terence Tao’s quote about the problems being hard was just tier 3. Tier 1 is IMO/Putnam level maybe. Also, some of even the tier 2 problems allegedly rely on straightforward application of specialized knowledge, rather than cleverness, such that a mathematician could “immediately” know how to do it (see this tweet). Even many IMO/Putnam problems are minor variations on a problem that someone somewhere has written down and is thus in the training data. So o3’s 25.2% result doesn’t really prove much in terms of a comparison to human mathematicians, although again it’s clearly an advance over previous models.
ARC-AGI — we already knew that many of the ARC-AGI questions are solvable by enumerating lots and lots of hypotheses and checking them (“crude program enumeration”), and the number of tokens that o3 used to solve the problems (55k per solution?) suggests that o3 is still doing that to a significant extent. Now, in terms of comparing to humans, I grant that there’s some fungibility between insight (coming up with promising hypothesis) and brute force (enumerating lots of hypotheses and checking them). Deep Blue beat Kasparov at chess by checking 200 million moves per second. You can call it cheating, but Deep Blue still won the game. If future AGI similarly beats humans at novel science and technology and getting around the open-ended real world etc. via less insight and more brute force, then we humans can congratulate ourselves for our still-unmatched insight, but who cares, AGI is still beating us at novel science and technology etc. On the other hand, brute force worked for chess but didn’t work in Go, because the combinatorial explosion of possibilities blows up faster in Go than in chess. Plausibly the combinatorial explosion of possible ideas and concepts and understanding in the open-ended real world blows up even faster yet. ARC-AGI is a pretty constrained universe; intuitively, it seems more on the chess end of the chess-Go spectrum, such that brute force hypothesis-enumeration evidently works reasonably well in ARC-AGI. But (on this theory) that approach wouldn’t generalize to capability at novel science and technology and getting around in the open-ended real world etc.
(I really haven’t been paying close attention and I’m open to correction.)
I think the best bull case is something like:
They did this pretty quickly and were able to greatly improve performance on a moderately diverse range of pretty checkable tasks. This implies OpenAI likely has an RL pipeline which can be scaled up to substantially better performance by putting in easily checkable tasks + compute + algorithmic improvements. And, given that this is RL, there isn’t any clear reason this won’t work (with some additional annoyances) for scaling through very superhuman performance (edit: in these checkable domains).[1]
Credit to @Tao Lin for talking to me about this take.
I express something similar on twitter here.
Not where they don’t have a way of generating verifiable problems. Improvement where they merely have some human-written problems is likely bounded by their amount.
Yeah, sorry this is an important caveat. But, I think very superhuman performance in most/all checkable domains is pretty spooky and this is even putting aside how it generalizes.
I concur with all of this.
Two other points:
It’s unclear to what extent the capability advances brought about by moving from LLMs to o1/3-style stuff generalize beyond math and programming (i. e., domains in which it’s easy to set up RL training loops based on machine-verifiable ground-truth).
Empirical evidence: “vibes-based evals” of o1 hold that it’s much better than standard LLMs in those domains, but is at best as good as Sonnet 3.5.1 outside them. Theoretical justification: if there are easy-to-specify machine verifiers, then the “correct” solution for the SGD to find is to basically just copy these verifiers into the model’s forward passes. And if we can’t use our program/theorem-verifiers to verify the validity of our real-life plans, it’d stand to reason the corresponding SGD-found heuristics won’t generalize to real-life stuff either.
Math/programming capabilities were coupled to general performance in the “just scale up the pretraining” paradigm: bigger models were generally smarter. It’s unclear whether the same coupling holds for the “just scale up the inference-compute” paradigm; I’ve seen no evidence of that so far.
The claim that “progress from o1 to o3 was only three months” is likely false/misleading. The talk of Q*/Strawberry was around since the board drama of November 2023, at which point it had already supposedly beat some novel math benchmarks. So o1, or a meaningfully capable prototype of it, was around for more than a year now. They’ve only chosen to announce and release it three months ago. (See e. g. gwern’s related analysis here.)
o3, by contrast, seems to be their actual current state-of-the-art model, which they’ve only recently trained. They haven’t been sitting on it for months, haven’t spent months making it ready/efficient enough for a public release.
Hence the illusion of insanely fast progress. (Which was probably exactly OpenAI’s aim.)
I’m open to be corrected on any of these claims if anyone has relevant data, of course.
Can’t we just count from announcement to announcement? Like sure, they were working on stuff before o1 prior to having o1 work, but they are always going to be working on the next thing.
Do you think that o1 wasn’t the best model (of this type) that OpenAI had internally at the point of the o1 announcement? If so, do you think that o3 isn’t the best model (of this type) that OpenAI has internally now?
If your answers differ (including quantitatively), why?
The main exception is that o3 might be based on a different base model which could imply that a bunch of the gains are from earlier scaling.
I don’t think counting from announcement to announcement is valid here, no. They waited to announce o1 until they had o1-mini and o1-preview ready to ship: i. e., until they’ve already came around to optimizing these models for compute-efficiency and to setting up the server infrastructure for running them. That couldn’t have taken zero time. Separately, there’s evidence they’ve had them in-house for a long time, between the Q* rumors from a year ago and the Orion/Strawberry rumors from a few months ago.
This is not the case for o3. At the very least, it is severely unoptimized, taking thousands of dollars per task (i. e., it’s not even ready for the hypothetical $2000/month subscription they floated).
That is,
Yes and yes.
The case for “o3 is the best they currently have in-house” is weaker, admittedly. But even if it’s not the case, and they already have “o4″ internally, the fact that o1 (or powerful prototypes) existed well before the September announcement seem strongly confirmed, and that already disassembles the narrative of “o1 to o3 took three months”.
Good points! I think we underestimate the role that brute force plays in our brains though.
I don’t think you can explain away SWE-bench performance with any of these explanations
I’m not questioning whether o3 is a big advance over previous models—it obviously is! I was trying to address some suggestions / vibe in the air (example) that o3 is strong evidence that the singularity is nigh, not just that there is rapid ongoing AI progress. In that context, I haven’t seen people bringing up SWE-bench as much as those other three that I mentioned, although it’s possible I missed it. Mostly I see people bringing up SWE-bench in the context of software jobs.
I was figuring that the SWE-bench tasks don’t seem particularly hard, intuitively. E.g. 90% of SWE-bench verified problems are “estimated to take less than an hour for an experienced software engineer to complete”. And a lot more people have the chops to become an “experienced software engineer” than to become able to solve FrontierMath problems or get in the top 200 in the world on Codeforces. So the latter sound extra impressive, and that’s what I was responding to.
I mean, fair but when did a benchmark designed to test REAL software engineering issues that take less than an hour suddenly stop seeming “particularly hard” for a computer.
Feels like we’re being frogboiled.
I would say that, barring strong evidence to the contrary, this should be assumed to be memorization.
I think that’s useful! LLM’s obviously encode a ton of useful algorithms and can chain them together reasonably well
But I’ve tried to get those bastards to do something slightly weird and they just totally self destruct.
But let’s just drill down to demonstrable reality: if past SWE benchmarks were correct, these things should be able to do incredible amounts of work more or less autonomously and get all the LLM SWE replacements we’ve seen have stuck to highly simple, well documented takes that don’t vary all that much. The benchmarks here have been meaningless from the start and without evidence we should assume increments on them is equally meaningless
The lying liar company run by liars that lie all the time probably lied here and we keep falling for it like Wiley Coyote
It’s been pretty clear to me as someone who regularly creates side projects with ai that the models are actually getting better at coding.
Also, it’s clearly not pure memorization, you can deliberately give them tasks that have never been done before and they do well.
However, even with agentic workflows, rag, etc all existing models seem to fail at some moderate level of complexity—they can create functions and prototypes but have trouble keeping track of a large project
My uninformed guess is that o3 actually pushes the complexity by some non-trivial amount, but not enough to now take on complex projects.
Thanks for the reply! Still trying to learn how to disagree properly so let me know if I cross into being nasty at all:
I’m sure they’ve gotten better, o1 probably improved more from its heavier use of intermediate logic, compute/runtime and such, but that said, at least up till 4o it looks like there has been improvements in the model itself, they’ve been getting better
They can do incredibly stuff in well documented processes but don’t survive well off the trodden path. They seem to string things together pretty well so I don’t know if I would say there’s nothing else going on besides memorization but it seems to be a lot of what it’s doing, like it’s working with building blocks of memorized stuff and is learning to stack them using the same sort of logic it uses to chain natural language. It fails exactly in the ways you’d expect if that were true, and it has done well in coding exactly as if that were true. The fact that the swe benchmark is giving fantastic scores despite my criticism and yours means those benchmarks are missing a lot and probably not measuring the shortfalls they historically have
See below: 4 was scoring pretty well in code exercises like codeforces that are toolbox oriented and did super well in more complex problems on leetcode… Until the problems were outside of its training data, in which case it dropped from near perfect to not being able to do much worse.
https://x.com/cHHillee/status/1635790330854526981?t=tGRu60RHl6SaDmnQcfi1eQ&s=19
This was 4, but I don’t think o1 is much different, it looks like they update more frequently so this is harder to spot in major benchmarks, but I still see it constantly.
Even if I stop seeing it myself, I’m going to assume that the problem is still there and just getting better at hiding unless there’s a revolutionary change in how these models work. Catching lies up to this out seems to have selected for better lies
It’s hard to find numbers. Here’s what I’ve been able to gather (please let me know if you find better numbers than these!). I’m mostly focusing on FrontierMath.
Pixel counting on the ARC-AGI image, I’m getting $3,644 ± $10 per task.
FrontierMath doesn’t say how many questions they have (!!!). However, they have percent breakdowns by subfield, and those percents are given to the nearest 0.1%; using this, I can narrow the range down to 289-292 problems in the dataset. Previous models solve around 3 problems (4 problems in total were ever solved by any previous model, though the full o1 was not evaluated, only o1-preview was)
o3 solves 25.2% of FrontierMath. This could be 73⁄290. But it is also possible that some questions were removed from the dataset (e.g. because they’re publicly available). 25.2% could also be 72⁄286 or 71⁄282, for example.
The 280 to 290 problems means a rough ballpark for a 95% confidence interval for FrontierMath would be [20%, 30%]. It is pretty strange that the ML community STILL doesn’t put confidence intervals on their benchmarks. If you see a model achieve 30% on FrontierMath later, remember that its confidence interval would overlap with o3′s. (Edit: actually, the confidence interval calculation assumes all problems are sampled from the same pool, which is explicitly not the case for this dataset: some problems are harder than others. So it is hard to get a true confidence interval without rerunning the evaluation several times, which would cost many millions of dollars.)
Using the pricing for ARC-AGI, o3 cost around $1mm to evaluate on the 280-290 problems of FrontierMath. That’s around $3,644 per attempt, or roughly $14,500 per correct solution.
This is actually likely more expensive than hiring a domain-specific expert mathematician for each problem (they’d take at most few hours per problem if you find the right expert, except for the hardest problems which o3 also didn’t solve). Even without hiring a different domain expert per problem, I think if you gave me FrontierMath and told me “solve as many as you can, and you get $15k per correct answer” I’d probably spend like a year and solve a lot of them: if I match o3 within a year, I’d get $1mm, which is much higher than my mathematician salary. (o3 has an edge in speed, of course, but you could parallelize the hiring of mathematicians too.) I think this is the first model I’ve seen which gets paid more than I do!
I don’t think anchoring to o3′s current cost-efficiency is a reasonable thing to do. Now that AI has the capability to solve these problems in-principle, buying this capability is probably going to get orders of magnitude cheaper within the next five
minutesmonths, as they find various algorithmic shortcuts.I would guess that OpenAI did this using a non-optimized model because they expected it to be net beneficial: that producing a headline-grabbing result now will attract more counterfactual investment than e. g. the $900k they’d save by running the benchmarks half a year later.
Edit: In fact, if, against these expectations, the implementation of o3′s trick can’t be made orders-of-magnitude cheaper (say, because a base model of a given size necessarily takes ~n tries/MCTS branches per a FrontierMath problem and you can’t get more efficient than one try per try), that would make me do a massive update against the “inference-time compute” paradigm.
I think AI obviously keeps getting better. But I don’t think “it can be done for $1 million” is such strong evidence for “it can be done cheaply soon” in general (though the prior on “it can be done cheaply soon” was not particularly low ante—it’s a plausible statement for other reasons).
Like if your belief is “anything that can be done now can be done 1000x cheaper within 5 months”, that’s just clearly false for nearly every AI milestone in the last 10 years (we did not get gpt4 that’s 1000x cheaper 5 months later, nor alphazero, etc).
I’ll admit I’m not very certain in the following claims, but here’s my rough model:
The AGI labs focus on downscaling the inference-time compute costs inasmuch as this makes their models useful for producing revenue streams or PR. They don’t focus on it as much beyond that; it’s a waste of their researchers’ time. The amount of compute at OpenAI’s internal disposal is well, well in excess of even o3′s demands.
This means an AGI lab improves the computational efficiency of a given model up to the point at which they could sell it/at which it looks impressive, then drop that pursuit. And making e. g. GPT-4 10x cheaper isn’t a particularly interesting pursuit, so they don’t focus on that.
Most of the models of the past several years have only been announced near the point at which they were ready to be released as products. I. e.: past the point at which they’ve been made compute-efficient enough to be released.
E. g., they’ve spent months post-training GPT-4, and we only hear about stuff like Sonnet 3.5.1 or Gemini Deep Research once it’s already out.
o3, uncharacteristically, is announced well in advance of its release. I’m getting the sense, in fact, that we might be seeing the raw bleeding edge of the current AI state-of-the-art for the first time in a while. Perhaps because OpenAI felt the need to urgently counter the “data wall” narratives.
Which means that, unlike the previous AIs-as-products releases, o3 has undergone ~no compute-efficiency improvements, and there’s a lot of low-hanging fruit there.
Or perhaps any part of this story is false. As I said, I haven’t been keeping a close enough eye on this part of things to be confident in it. But it’s my current weakly-held strong view.
So far as I know, it is not the case that OpenAI had a slower-but-equally-functional version of GPT4 many months before announcement/release. What they did have is GPT4 itself, months before; but they did not have a slower version. They didn’t release a substantially distilled version. For example, the highest estimate I’ve seen is that they trained a 2-trillion-parameter model. And the lowest estimate I’ve seen is that they released a 200-billion-parameter model. If both are true, then they distilled 10x… but it’s much more likely that only one is true, and that they released what they trained, distilling later. (The parameter count is proportional to the inference cost.)
Previously, delays in release were believed to be about post-training improvements (e.g. RLHF) or safety testing. Sure, there were possibly mild infrastructure optimizations before release, but mostly to scale to many users; the models didn’t shrink.
This is for language models. For alphazero, I want to point out that it was announced 6 years ago (infinity by AI scale), and from my understanding we still don’t have a 1000x faster version, despite much interest in one.
I don’t know the details, but whatever the NN thing (derived from Lc0, a clone of AlphaZero) inside current Stockfish is can play on a laptop GPU.
And even if AlphaZero derivatives didn’t gain 3OOMs by themselves it doesn’t update me much that that’s something particularly hard. Google itself has no interest at improving it further and just moved on to MuZero, to AlphaFold etc.
The NN thing inside stockfish is called the NNUE, and it is a small neural net used for evaluation (no policy head for choosing moves). The clever part of it is that it is “efficiently updatable” (i.e. if you’ve computed the evaluation of one position, and now you move a single piece, getting the updated evaluation for the new position is cheap). This feature allows it to be used quickly with CPUs; stockfish doesn’t really use GPUs normally (I think this is because moving the data on/off the GPU is itself too slow! Stockfish wants to evaluate 10 million nodes per second or something.)
This NNUE is not directly comparable to alphazero and isn’t really a descendant of it (except in the sense that they both use neural nets; but as far as neural net architectures go, stockfish’s NNUE and alphazero’s policy network are just about as different as they could possibly be.)
I don’t think it can be argued that we’ve improved 1000x in compute over alphazero’s design, and I do think there’s been significant interest in this (e.g. MuZero was an attempt at improving alphazero, the chess and Go communities coded up Leela, and there’s been a bunch of effort made to get better game playing bots in general).
My understanding when I last looked into it was that the efficient updating of the NNUE basically doesn’t matter, and what really matters for its performance and CPU-runnability is its small size.
small nudge: the questions have difficulty tiers of 25% easy, 50% medium, and 25% hard with easy being undergrad/IMO difficulty and hard being the sort you would give to a researcher in training.
The 25% accuracy gives me STRONG indications that it just got the easy ones, and the starkness of this cutoff makes me think there is something categorically different about the easy ones that make them MUCH easier to solve, either being more close ended, easy to verify, or just leaked into the dataset in some form.
edit: wait likely it’s RL; I’m confused
OpenAI didn’t fine-tune on ARC-AGI, even though this graph suggests they did.
Sources:
Altman said
François Chollet (in the blogpost with the graph) said
and
An OpenAI staff member replied
and further confirmed that “tuned” in the graph is
Another OpenAI staff member said
So on ARC-AGI they just pretrained on 300 examples (75% of the 400 in the public training set). Performance is surprisingly good.
[heavily edited after first posting]
Probably a dataset for RL, that is the model was trained to try and try again to solve these tests with long chains of reasoning, not just tuned or pretrained on them, as a detail like 75% of examples sounds like a test-centric dataset design decision, with the other 25% going to the validation part of the dataset.
Seems plausible they trained on ALL the tests, specifically targeting various tests. The public part of ARC-AGI is “just” a part of that dataset of all the tests. Could be some part of explaining the o1/o3 difference in $20 tier.
Thank you so much for your research! I would have never found these statements.
I’m still quite suspicious. Why would they be “including a (subset of) the public training set”? Is it accidental data contamination? They don’t say so. Do they think simply including some questions and answers without reinforcement learning or reasoning would help the model solve other such questions? That’s possible but not very likely.
Were they “including a (subset of) the public training set” in o3′s base training data? Or in o3′s reinforcement learning problem/answer sets?
Altman never said “we didn’t go do specific work [targeting ARC-AGI]; this is just the general effort.”
Instead he said,
The gist I get is that he admits to targeting it but that OpenAI targets all kinds of problem/answer sets for reinforcement learning, not just ARC’s public training set. It felt like he didn’t want to talk about this too much, from the way he interrupted himself and changed the topic without clarifying what he meant.
The other sources do sort of imply no reinforcement learning. I’ll wait to see if they make a clearer denial of reinforcement learning, rather than a “nondenial denial” which can be reinterpreted as “we didn’t fine-tune o3 in the sense we didn’t use a separate derivative of o3 (that’s fine-tuned for just the test) to take the test.”
My guess is o3 is tuned using the training set, since François Chollet (developer of ARC) somehow decided to label o3 as “tuned” and OpenAI isn’t racing to correct this.
The answer is the ARC prize allowed them to do this, and the test is designed in such a way such that unlocking the training set cannot allow you to do well on the test set.
I don’t know whether I would put it this strongly. I haven’t looked deep into it, but isn’t it basically a non-verbal IQ test? Those very much do have a kind of “character” to them, such that studying how they work in general can let you derive plenty of heuristics for solving them. Those heuristics would be pretty abstract, yet far below the abstraction level of “general intelligence” (or the pile of very-abstract heuristics we associate with “general intelligence”).
I agree that tuning the model using the public training set does not automatically unlock the rest of it! But the Kaggle SOTA is clearly better than OpenAI’s o1 according to the test. This is seen vividly in François Chollet’s graph.
No one claims this means the Kaggle models are smarter than o1, nor that the test completely fails to test intelligence since the Kaggle models rank higher than o1.
Why does no one seem to be arguing for either? Probably because of the unspoken understanding that they are doing two versions of the test. One where the model fits the public training set, and tries to predict on the private test set. And two where you have a generally intelligent model which happens to be able to do this test. When people compare different models using the test, they are implicitly using the second version of the test.
Most generative AI models did the harder second version, but o3 (and the Kaggle versions) did the first version, which—annoyingly to me—is the official version. It’s still not right to compare other models’ scores with o3′s score.
I think there is a third explanation here. The Kaggle model (probably) does well because you can brute force it with a bag of heuristics and gradually iterate by discarding ones that don’t work and keeping the ones that do.
Do you not consider that ultimately isomorphic to what o3 does?
No, I believe there is a human in the loop for the above if that’s not clear.
You’ve said it in another comment. But this is probably an “architecture search”.
I guess the training loop for o3 is similar but it would be on the easier training set instead of the far harder test set.
Wow it does say the test set problems are harder than the training set problems. I didn’t expect that.
But it’s not an enormous difference: the example model that got 53% on the public training set got 38% on the public test set. It got only 24% on the private test set, even though it’s supposed to be equally hard, maybe because “trial and error” fitted the model to the public test set as well as the public training set.
The other example model got 32%, 30%, and 22%.
I think the Kaggle models might have the human design the heuristics while o3 discovers heuristics on its own during RL (unless it was trained on human reasoning on the ARC training set?).o3′s “AI designed heuristics” might let it learn a far more of heuristics than humans can think of and verify, while the Kaggle models’ “human designed heuristics” might require less AI technology and compute. I don’t actually know how the Kaggle models work, I’m guessing.I finally looked at the Kaggle models and I guess it is similar to RL for o3.
I agree. I think the Kaggle models have more advantages than o3. I think they have far more human design and fine-tuning than o3. One can almost argue that some Kaggle models are very slightly trained on the test set, in the sense the humans making them learn from test sets results, and empirically discover what improves such results.
o3′s defeating the Kaggle models is very impressive, but o3′s results shouldn’t be directly compared against other untuned models.
I’d say they’re more-than-trained on the test set. My understanding is that humans were essentially able to do an architecture search, picking the best architecture for handling the test set, and then also put in whatever detailed heuristics they wanted into it based on studying the test set (including by doing automated heuristics search using SGD, it’s all fair game). So they’re not “very slightly” trained, they’re trained^2.
Arguably the same is the case for o3, of course. ML researchers are using benchmarks as targets, and while they may not be directly trying to Goodhart to them, there’s still a search process over architectures-plus-training-loops whose termination condition is “the model beats a new benchmark”. And SGD itself is, in some ways, a much better programmer than any human.
So o3′s development and training process essentially contained the development-and-training process for Kaggle models. They’ve iteratively searched for an architecture that can be trained to beat several benchmarks, then did so.
They did this on the far easier training set though?
An alternative story is they trained until a model was found that could beat the training set but many other benchmarks too, implying that there may be some general intelligence factor there. Maybe this is still goodharting on benchmarks but there’s probably truly something there.
There are degrees of Goodharting. It’s not Goodharting to ARC-AGI specifically, but it is optimizing for performance on the array of easily-checkable benchmarks. Which plausibly have some common factor between them to which you could “Goodhart”; i. e., a way to get good at them without actually training generality.
You’re misunderstanding the nature of the semi-private test set (which you referred to as test one) and the private test set (which you referred to as test two).
The reason that o3 can’t do the private test set is because only models that provide their source code to the test creator and run the test on the arc-agi server with no internet access can take that test. The purpose of this is to prevent contamination of the test set, because as soon as a proprietary model with internet access takes the test, it’s pretty much guaranteed that the questions are now viewable by the owner of the model. The only way to prevent that is for the owner of the model to provide the source code and run the test offline.
So a new OpenAI model could never do that test, because they are too greedy to make them open source. The reward for a score of 85% or higher in the private test set is $600,000 USD, a reward that naturally has yet to be claimed, and I expect will not be claimed for some time.
However, I agree that o3′s score on the semi private test set is not impressive. All of these questions are actually technically viewable by OpenAI because they have run their other models on it, so their models have been asked these 100 questions before. OpenAI is a for profit (aspiring) company, I do not put it past them to train o3 on the direct questions from this test set, considering how much money they have to gain when they go public, and how much money they need from investors as long as they remain a not for profit. This whole thing has been massively over hyped and I wouldn’t be surprised if the creator of the test received a kick back, considering how much he has been publicly glazing them.
It’s very frustrating to see them fool so many people by trying to use this result to claim that they are on the brink of AGI.
See my other comment instead.
The key question is “how much of the performance is due to ARC-AGI data.”If the untuned o3 was anywhere as good as the tuned o3, why didn’t they test it and publish it? If the most important and interesting test result is somehow omitted, take things with a grain of salt.I admit that running the test is extremely expensive, but there should be compromises like running the cheaper version or only doing a few questions.Edit: oh that reply seems to deny reinforcement learning or at least “fine tuning.” I don’t understand why François Chollet calls the model “tuned” then. Maybe wait for more information I guess.Edit again: I’m still not sure yet. They might be denying that it’s a separate version of o3 finetuned to do ARC questions, while not denying they did reinforcement learning on the ARC public training set.I guess a week or so later we might find out what “tuned” truly means.[edited more]
As I say here https://x.com/boazbaraktcs/status/1870369979369128314
Constitutional AI is a great work but Deliberative Alignment is fundamentally different. The difference is basically system 1 vs system 2. In RLAIF ultimately the generative model that answers user prompt is trained with (prompt, good response, bad response). Even if the good and bad responses were generated based on some constitution, the generative model is not taught the text of this constitution, and most importantly how to reason about this text in the context of a particular example.
This ability to reason is crucial to OOD performance such as training only on English and generalizing to other languages or encoded output.
See also https://x.com/boazbaraktcs/status/1870285696998817958
Also the thing I am most excited about deliberative alignment is that it becomes better as models are more capable. o1 is already more robust than o1 preview and I fully expect this to continue.
(P.s. apologies in advance if I’m unable to keep up with comments; popped from holiday to post on the DA paper.)
Hi Boaz, first let me say that I really like Deliberative Alignment. Introducing a system 2 element is great, not only for higher-quality reasoning, but also for producing a legible, auditable chain of though. That said, I have a couple questions I’m hoping you might be able to answer.
I read through the model spec (which DA uses, or at least a closely-related spec). It seems well-suited and fairly comprehensive for answering user questions, but not sufficient for a model acting as an agent (which I expect to see more and more). An agent acting in the real world might face all sorts of interesting situations that the spec doesn’t provide guidance on. I can provide some examples if necessary.
Does the spec fed to models ever change depending on the country / jurisdiction that the model’s data center or the user are located in? Situations which are normal in some places may be legal in others. For example, Google tells me that homosexuality is illegal in 64 countries. Other situations are more subtle and may reflect different cultures / norms.
“Scaling is over” was sort of the last hope I had for avoiding the “no one is employable, everyone starves” apocalypse. From that frame, the announcement video from openai is offputtingly cheerful.
Really. I don’t emphasize this because I care more about humanity’s survival than the next decades sucking really hard for me and everyone I love. But how do LW futurists not expect catastrophic job loss that destroys the global economy?
I’m flabbergasted by this degree/kind of altruism. I respect you for it, but I literally cannot bring myself to care about “humanity”’s survival if it means the permanent impoverishment, enslavement or starvation of everybody I love. That future is simply not much better on my lights than everyone including the gpu-controllers meeting a similar fate. In fact I think my instincts are to hate that outcome more, because it’s unjust.
Slight correction: catastrophic job loss would destroy the ability of the non-landed, working public to paritcipate in and extract value from the global economy. The global economy itself would be fine. I agree this is a natural conclusion; I guess people were hoping to get 10 or 15 more years out of their natural gifts.
Thank you. Oddly, I am less altruistic than many EA/LWers. They routinely blow me away.
I can only maintain even that much altruism because I think there’s a very good chance that the future could be very, very good for a truly vast number of humans and conscious AGIs. I don’t think it’s that likely that we get a perpetual boot-on-face situation. I think only about 1% of humans are so sociopathic AND sadistic in combination that they wouldn’t eventually let their tiny sliver of empathy cause them to use their nearly-unlimited power to make life good for people. They wouldn’t risk giving up control, just share enough to be hailed as a benevolent hero instead of merely god-emperor for eternity.
I have done a little “metta” meditation to expand my circle of empathy. I think it makes me happy; I can “borrow joy”. The side effect is weird decisions like letting my family suffer so that more strangers can flourish in a future I probably won’t see.
Who would the producers of stuff be selling it to in that scenario?
BTW, I recently saw the suggestion that discussions of “the economy” can be clarified by replacing the phrase with “rich people’s yacht money”. There’s something in that. If 90% of the population are destitute, then 90% of the farms and factories have to shut down for lack of demand (i.e. not having the means to buy), which puts more out of work, until you get a world in which a handful of people control the robots that keep them in food and yachts and wait for the masses to die off.
I wonder if there are any key players who would welcome that scenario. Average utilitarianism FTW!
At least, supposing there are still any people controlling the robots by then.
That’s what would happen, and the fact that nobody wanted it to happen wouldn’t help. It’s a Tragedy of the Commons situation.
Survival is obviously much better because 1. You can lose jobs but eventually still have a good life (think UBI at minimum) and 2. Because if you don’t like it you can always kill yourself and be in the same spot as the non-survival case anyway.
Not to get too morbid here but I don’t think this is a good argument. People tend not to commit suicide even if they have strongly net negative lives
Why would that be the likely case? Are you sure it’s likely or are you just catastrophizing?
I expect the US or Chinese government to take control of these systems sooner than later to maintain sovereignty. I also expect there will be some force to counteract the rapid nominal deflation that would happen if there was mass job loss. Every ultra rich person now relies on billions of people buying their products to give their companies the valuation they have.
I don’t think people want nominal deflation even if it’s real economic growth. This will result in massive printing from the fed that probably lands in poeple’s pockets (Iike covid checks).
I think this is reasonably likely, but not a guaranteed outcome, and I do think there’s a non-trivial chance that the US regulates it way too late to matter, because I expect mass job loss to be one of the last things AI does, due to pretty severe reliability issues with current AI.
I think Elon will bring strong concern about AI to fore in current executive—he was an early voice for AI safety though he seems too have updated to a more optimistic view (and is pushing development through x-AI) he still generally states P(doom) ~10-20%. His antipathy towards Altman and Google founders is likely of benefit for AI regulation too—though no answer for the China et al AGI development problem.
I also expect government control; see If we solve alignment, do we die anyway? for musings about the risks thereof. But it is a possible partial solution to job loss. It’s a lot tougher to pass a law saying “no one can make this promising new technology even though it will vastly increase economic productivity” than to just show up to one company and say “heeeey so we couldn’t help but notice you guys are building something that will utterly shift the balance of power in the world.… can we just, you know, sit in and hear what you’re doing with it and maybe kibbitz a bit?” Then nationalize it officially if and when that seems necessary.
I actually think doing the former is considerably more in line with the way things are done/closer to the Overton window.
For politicians, yes—but the new administration looks to be strongly pro-tech (unless DJ Trump gets a bee in his bonnet and turns dramatically anti-Musk).
For the national security apparatus, the second seems more in line with how they get things done. And I expect them to twig to the dramatic implications much faster than the politicians do. In this case, there’s not even anything illegal or difficult about just having some liasons at OAI and an informal request to have them present in any important meetings.
At this point I’d be surprised to see meaningful legislation slowing AI/AGI progress in the US, because the “we’re racing China” narrative is so compelling—particularly to the good old military-industrial complex, but also to people at large.
Slowing down might be handing the race to China, or at least a near-tie.
I am becoming more sure that would beat going full-speed without a solid alignment plan. Despite my complete failure to interest anyone in the question of Who is Xi Jinping? in terms of how he or his successors would use AGI. I don’t think he’s sociopathic/sadistic enough to create worse x-risks or s-risks than rushing to AGI does. But I don’t know.
We still somehow got the steam engine, electricity, cars, etc.
There is an element of international competition to it. If we slack here, China will probably raise armies of robots with unlimited firepower and take over the world. (They constantly show aggression)
The longshoreman strike is only allowed (I think) because the west coast did automate and somehow are less efficient than the east coast for example.
Counterpoints: nuclear power, pharmaceuticals, bioengineering, urban development.
Or maybe they will accidentally ban AI too due to being a dysfunctional autocracy, as autocracies are wont to do, all the while remaining just as clueless regarding what’s happening as their US counterparts banning AI to protect the jobs.
I don’t really expect that to happen, but survival-without-dignity scenarios do seem salient.
I think a lot of this is wishful thinking from safetyists who want AI development to stop. This may be reductionist but almost every pause historically can be explained economics.
Nuclear—war usage is wholly owned by the state and developed to its saturation point (i.e. once you have nukes that can kill all your enemies, there is little reason to develop them more). Energy-wise, supposedly, it was hamstrung by regulation, but in countries like China where development went unfettered, they are still not dominant. This tells me a lot it not being developed is it not being economical.
For bio related things, Eroom’s law reigns supreme. It is just economically unviable to discover drugs in the way we do. Despite this, it’s clear that bioweapons are regularly researched by government labs. The USG being so eager to fund gof research despite its bad optics should tell you as much.
Or maybe they will accidentally ban AI too due to being a dysfunctional autocracy—
I remember many essays from people all over this site on how China wouldn’t be able to get to X-1 nm (or the crucial step for it) for decades, and China would always figure a way to get to that nm or step within a few months. They surpassed our chip lithography expectations for them. They are very competent. They are run by probably the most competent government bureaucracy in the world. I don’t know what it is, but people keep underestimating China’s progress. When they aim their efforts on a target, they almost always achieve it.
Rapid progress is a powerful attractor state that requires a global hegemon to stop. China is very keen on the possibilities of AI which is why they stop at nothing to get their hands on Nvidia GPUs. They also have literally no reason to develop a centralized project they are fully in control of. We have superhuman AI that seem quite easy to control already. What is stopping this centralized project on their end. No one is buying that even o3, which is nearly superhuman in math and coding, and probably lots of scientific research, is going to attempt world takeover.
And for me, the (correct) reframing of RL as the cherry on top of our existing self-supervised stack was the straw that broke my hopeful back.
And o3 is more straws to my broken back.
Do you mean this is evidence that scaling is really over, or is this the opposite where you think scaling is not over?
Regarding whether this is a new base model, we have the following evidence:
Jason Wei:
Nat McAleese:
The prices leaked by ARC-ARG people indicate $60/million output tokens, which is also the current o1 pricing. 33m total tokens and a cost of $2,012.
Notably, the codeforces graph with pricing puts o3 about 3x higher than o1 (tho maybe it’s a secretly log scale), and the ARC-AGI graph has the cost of o3 being 10-20x that of o1-preview. Maybe this indicates it does a bunch more test-time reasoning. That’s collaborated by ARC-AGI, average 55k tokens per solution[1], which seems like a ton.
I think this evidence indicates this is likely the same base model as o1, and I would be at like 65% sure, so not super confident.
edit to add because the phrasing is odd: this is the data being used for the estimate, and the estimate is 33m tokens / (100 tasks * 6 samples per task) = ~55k tokens per sample. I called this “solution” because I expect these are basically 6 independent attempts at answering the prompt, but somebody else might interpret things differently. The last column is “Time/Task (mins)”.
GPT-4o costs $10 per 1M output tokens, so the cost of $60 per 1M tokens is itself more than 6 times higher than it has to be. Which means they can afford to sell a much more expensive model at the same price. It could also be GPT-4.5o-mini or something, similar in size to GPT-4o but stronger, with knowledge distillation from full GPT-4.5o, given that a new training system has probably been available for 6+ months now.
Fucking o3. This pace of improvement looks absolutely alarming. I would really hate to have my fast timelines turn out to be right.
The “alignment” technique, “deliberative alignment”, is much better than constitutional AI. It’s the same during training, but it also teaches the model the safety criteria, and teaches the model to reason about them at runtime, using a reward model that compares the output to their specific safety criteria. (This also suggests something else I’ve been expecting—the CoT training technique behind o1 doesn’t need perfectly verifiable answers in coding and math, it can use a decent guess as to the better answer in what’s probably the same procedure).
While safety is not alignment (SINA?), this technique has a lot of promise for actual alignment. By chance, I’ve been working on an update to my Internal independent review for language model agent alignment, and have been thinking about how this type of review could be trained instead of scripted into an agent as I’d originally predicted.
This is that technique. It does have some promise.
But I don’t think OpenAI has really thought through the consequences of using their smarter-than-human models with scaffolding that makes them fully agentic and soon enough reflective and continuously learning.
The race for AGI speeds up, and so does the race to align it adequately by the time it arrives in a takeover-capable form.
I’ll write a little more on their new alignment approach soon.
I was still hoping for a sort of normal life. At least for a decade or maybe more. But that just doesn’t seem possible anymore. This is a rough night.
Oh dear, RL for everything, because surely nobody’s been complaining about the safety profile of doing RL directly on instrumental tasks rather than on goals that benefit humanity.
My rather hot take is that a lot of the arguments for safety of LLMs also transfer over to practical RL efforts, with some caveats.
I agree, after all RLFH was originally for RL agents. As long as the models aren’t all that smart, and the tasks they have to do aren’t all that long-term, the transfer should work great, and the occasional failure won’t be a problem because, again, the models aren’t all that smart.
To be clear, I don’t expect a ‘sharp left turn’ so much as ‘we always implicitly incentivized exploitation of human foibles, we just always caught it when it mattered, until we didn’t.’
My probably contrarian take is that I don’t think improvement on a benchmark of math problems is particularly scary or relevant. It’s not nothing—I’d prefer if it didn’t improve at all—but it only makes me slightly more worried.
can you say more about your reasoning for this?
About two years ago I made a set of 10 problems that imo measure progress toward AGI and decided I’d freak out if/when LLMs solve them. They’re still 1⁄10 and nothing has changed in the past year, and I doubt o3 will do better. (But I’m not making them public.)
Will write a reply to this comment when I can test it.
Deepseek gets 2⁄10.
I’m pretty shocked by this result. Less because the 2⁄10 number itself, but by the specific one it solved. My P(LLMs can scale to AGI) increased significantly, although not to 50%.
o3-mini-high gets 3⁄10; this is essentially the same as DeepSeek (there were two where DeepSeek came very close, this is one of them). I’m still slightly more impressed with DeepSeek despite the result, but it’s very close.
What score would it take for you to update your p(LLMs scale to AGI) above 50%?
Tricky to answer actually.
I can say more about my model now. The way I’d put it now (h/t Steven Byrnes) is that there are three interesting classes of capabilities
A: sequential reasoning of any kind
B: sequential reasoning on topics where steps aren’t easily verifiable
C: the type of thing Steven mentions here, like coming up with new abstractions/concepts to integrate into your vocabulary to better think about something
Among these, obviously B is a subset of A. And while it’s not obvious, I think C is probably best viewed as a subset of B. Regardless, I think all three are required for what I’d call AGI. (This is also how I’d justify the claim that no current LLM is AGI.) Maybe C isn’t strictly required, I could imagine a mind getting superhuman performance without it, but I think given how LLMs work otherwise, it’s not happening.
Up until DeepSeek, I would have also said LLMs are terrible A. (This is probably a hot take, but I genuinely think it’s true despite benchmark performances continuing to go up.) My tasks were designed to test A, with the hypothesis that LLMs will suck at A indefinitely. For a while, it seemed like people weren’t even focusing on A, which is why I didn’t want to talk a bout it. But this concern is no longer applicable; the new models are clearly focused on improving sequential reasoning. However, o1 was terrible at it (imo), almost no improvement form GPT-4 proper, so I actually found o1 reassuring.
This has now mostly been falsified with DeepSeek and o3. (I know the numbers don’t really tell the story since it just went from 1 to 2, but like, including which stuff they solved and how they argue, DeepSeek was the where I went “oh shit they can actually do legit sequential reasoning now”.) Now I’m expecting most of the other tasks to fall as well, so I won’t do similar updates if it goes to 5⁄10 or 8⁄10. The hypothesis “A is an insurmountable obstacle” can only be falsified once.
That said, it still matters how fast they improve. How much it matters depends on whether you think better performance on A is progress toward B/C. I’m still not sure about this, I’m changing my views a lot right now. So idk. If they score 10⁄10 in the next year, my p(LLMs scale to AGI) will definitely go above 50%, probably if they do it in 3 years as well, but that’s about the only thing I’m sure about.
Any chance you can post (or PM me) the three problems AIs have already beaten?
can you say the types of problems they are?
You could call them logic puzzles. I do think most smart people on LW would get 10⁄10 without too many problems, if they had enough time, although I’ve never tested this.
Assuming they are verifiable or have an easy way to verify whether or not a solution does work, I expect o3 to at least get 2⁄10, if not 3⁄10 correct under high-compute settings.
What’s the last model you did check with, o1-pro?
Just regular o1, I have the 20$/month subscription not the 200$/month
Do you have a link to these?
What benchmarks (or other capabilities) do you see as more relevant, and how worried were you before?
Using $4K per task means a lot of inference in parallel, which wasn’t in o1. So that’s one possible source of improvement, maybe it’s running MCTS instead of individual long traces (including on low settings at $20 per task). And it might be built on the 100K H100s base model.
The scary less plausible option is that RL training scales, so it’s mostly o1 trained with more compute, and $4K per task is more of an inefficient premium option on top rather than a higher setting on o3′s source of power.
The obvious boring guess is best of n. Maybe you’re asserting that using $4,000 implies that they’re doing more than that.
Performance at $20 per task is already much better than for o1, so it can’t be just best-of-n, you’d need more attempts to get that much better even if there is a very good verifier that notices a correct solution (at $4K per task that’s plausible, but not at $20 per task). There are various clever beam search options that don’t need to make inference much more expensive, but in principle might be able to give a boost at low expense (compared to not using them at all).
There’s still no word on the 100K H100s model, so that’s another possibility. Currently Claude 3.5 Sonnet seems to be better at System 1, while OpenAI o1 is better at System 2, and combining these advantages in o3 based on a yet-unannounced GPT-4.5o base model that’s better than Claude 3.5 Sonnet might be sufficient to explain the improvement. Without any public 100K H100s Chinchilla optimal models it’s hard to say how much that alone should help.
Anyone want to guess how capable Claude system level 2 will be when it is polished? I expect better than o3 by a small amt.
The ARC-AGI page (which I think has been updated) currently says:
I wish they would tell us what the dark vs light blue means. Specifically, for the FrontierMath benchmark, the dark blue looks like it’s around 8% (rather than the light blue at 25.2%). Which like, I dunno, maybe this is nit picking, but 25% on FrontierMath seems like a BIG deal, and I’d like to know how much to be updating my beliefs.
From an apparent author on reddit:
The comment was responding to a claim that Terence Tao said he could only solve a small percentage of questions, but Terence was only sent the T3 questions.
My random guess is:
The dark blue bar corresponds to the testing conditions under which the previous SOTA was 2%.
The light blue bar doesn’t cheat (e.g. doesn’t let the model run many times and then see if it gets it right on any one of those times) but spends more compute than one would realistically spend (e.g. more than how much you could pay a mathematician to solve the problem), perhaps by running the model 100 to 1000 times and then having the model look at all the runs and try to figure out which run had the most compelling-seeming reasoning.
The FrontierMath answers are numerical-ish (“problems have large numerical answers or complex mathematical objects as solutions”), so you can just check which answer the model wrote most frequently.
Yeah, I agree that that could work. I (weakly) conjecture that they would get better results by doing something more like the thing I described, though.
On the livestream, Mark Chen says the 25.2% was achieved “in aggressive test-time settings”. Does that just mean more compute?
It likely means running the AI many times and submitting the most common answer from the AI as the final answer.
Extremely long chain of thought, no?
I guess one thing I want to know is like… how exactly does the scoring work? I can imagine something like, they ran the model a zillion times on each question, and if any one of the answers was right, that got counted in the light blue bar. Something that plainly silly probably isn’t what happened, but it could be something similar.
If it actually just submitted one answer to each question and got a quarter of them right, then I think it doesn’t particularly matter to me how much compute it used.
It was one submission, apparently.
Thanks. Is “pass@1” some kind of lingo? (It seems like an ungoogleable term.)
Pass@k means that at least one of k attempts passes, according to an oracle verifier. Evaluating with pass@k is cheating when k is not 1 (but still interesting to observe), the non-cheating option is best-of-k where the system needs to pick out the best attempt on its own. So saying pass@1 means you are not cheating in evaluation in this way.
pass@n is not cheating if answers are easy to verify. E.g. if you can cheaply/quickly verify that code works, pass@n is fine for coding.
For coding, a problem statement won’t have exhaustive formal requirements that will be handed to the solver, only evals and formal proofs can be expected to have adequate oracle verifiers. If you do have an oracle verifier, you can just wrap the system in it and call it pass@1. Affordance to reliably verify helps in training (where the verifier is applied externally), but not in taking the tests (where the system taking the test doesn’t itself have a verifier on hand).
While I’m not surprised by the pessimism here, I am surprised at how much of it is focused on personal job loss. I thought there would be more existential dread.
Existential dread doesn’t necessarily follow from this specific development if training only works around verifiable tasks and not for everything else, like with chess. Could soon be game-changing for coding and other forms of engineering, without full automation even there and without applying to a lot of other things.
Oh I guess I was assuming automation of coding would result in a step change in research in every other domain. I know that coding is actually one of the biggest blockers in much of AI research and automation in general.
It might soon become cost effective to write bespoke solutions for a lot of labor jobs for example.
First post, feel free to meta-critique my rigor on this post as I am not sure what is mandatory, expected, or superfluous for a comment under a post. Studying computer science but have no degree, yet. Can pull the specific citation if necessary, but...
these benchmarks don’t feel genuine.
Chollet indicated in his piece:
The model was tuned to the ARC AGI Test, got a great score but then faceplanted on a reasoning test apparently easier for humans than the first one, a test that couldn’t have been adversarially designed to stump o3. I would have expected that this would immediately expose it as being horrifically overfit but few people seem to be honing in on that so maybe I don’t understand something?
Second, the Frontiers math problems appear to be structured in a way that 25% of the problems are the sort that clever high schoolers with bright futures in mathematics would be able to answer if they studied, International Math Olympiad or undergrad level questions. We don’t know EXACTLY which questions it answered right but it’s almost exactly 25% and I suspect that these are almost entirely from the lower tier questions, and I wouldn’t be surprised to hear that the questions (or similar questions) were in the training set. Perhaps the lowest tier questions were formulated with a sort of operational philosophy that didn’t prioritize guarding against leaked data?
Third, the codeforces ELO doesn’t mean anything. I just can’t take this seriously, unless someone thinks that existing models are already mid tier competitive SWE’s? Similar benchmark, similarly meaningless, dismissed until someone shows me that these can actually deliver on what other models have provenly exaggerated on.
Fourth, the cost is obscene: thousands of dollars per task, with indications that this model is very similar to o1 going by cost per token, this looks less like a strong model with way more parameters and more like the same model doing a mind boggling amount of thinking. This is probably something like funsearch, a tool bag of programs that an LLM then combines and tries to gauge the effectiveness of, brute forced until it can get an answer it can verify. This seems useful, but this would only work on close-ended questions with answers that are easy to verify, either way this wouldn’t really be intelligence of the kind that I had imagined looking for.
This would PERFECTLY explain the failure on the ARC-AGI2 benchmark: the bag of tools it would need would be different, it wasn’t tuned to the new test and came with the wrong tool bag. Maybe this could be fixed, but if my model of how this AI works is right then the complexity of tasks would increase by O(n!) with n being the number of “tools” it needs. I’m probably wrong here but something LIKE that is probably true.
Lecun also seems to be confident on threads that this is NOT an LLM, that this is something that uses an LLM but that something else is going on. Perfectly matched my “oh, this is funsearch” intuition. My caveat is that this might all be handled “in house” in an LLM, but the restrictions on what this could do seem very real.
Am a critically wrong on enough points here that I should seriously rethink my intuition?
Welcome!
To me the benchmark scores are interesting mostly because they suggest that o3 is substantially more powerful than previous models. I agree we can’t naively translate benchmark scores to real-world capabilities.
Thank you for the warm reply, it’s nice and also good feedback I didn’t do anything explicitly wrong with my post
It will be VERY funny if this ends up being essentially the o1 model with some tinkering to help it cycle questions multiple times to verify the best answers, or something banal like that. Wish they didn’t make us wait so long to test that :/
Well, the update for me would go both ways.
On one side, as you point out, it would mean that the model’s single pass reasoning did not improve much (or at all).
On the other side, it would also mean that you can get large performance and reliability gains (on specific benchmarks) by just adding simple stuff. This is significant because you can do this much more quickly than the time it takes to train a new base model, and there’s probably more to be gained in that direction – similar tricks we can add by hardcoding various “system-2 loops” into the AI’s chain of thought and thinking process.
You might reply that this only works if the benchmark in question has easily verifiable answers. But I don’t think it is limited to those situations. If the model itself (or some subroutine in it) has some truth-tracking intuition about which of its answer attempts are better/worse, then running it through multiple passes and trying to pick the best ones should get you better performance even without easy and complete verifiability (since you can also train on the model’s guesses about its own answer attempts, improving its intuition there).
Besides, I feel like humans do something similar when we reason: we think up various ideas and answer attempts and run them by an inner critic, asking “is this answer I just gave actually correct/plausible?” or “is this the best I can do, or am I missing something?.”
(I’m not super confident in all the above, though.)
Lastly, I think the cost bit will go down by orders of magnitude eventually (I’m confident of that). I would have to look up trends to say how quickly I expect $4,000 in runtime costs to go down to $40, but I don’t think it’s all that long. Also, if you can do extremely impactful things with some model, like automating further AI progress on training runs that cost billions, then willingness to pay for model outputs could be high anyway.
I sense that my quality of communication diminishes past this point, I should get my thoughts together before speaking too confidently
I believe you’re right we do something similar to the LLM’s (loosely, analogously), see
https://www.lesswrong.com/posts/i42Dfoh4HtsCAfXxL/babble
(I need to learn markdown)
My intuition is still LLM pessimistic, I’d be excited to see good practical uses, this seems like tool ai and that makes my existential dread easier to manage!
I just straight up don’t believe the codeforces rating. I guess only a small subset of people solve algorithmic problems for fun in their free time, so it’s probably opaque to many here, but a rating of 2727 (the one in the table) would be what’s called an international grandmaster and is the 176th best rating among all actively competing users on the site. I hope they will soon release details about how they got that performance measure..
CodeForces ratings are determined by your performance in competitions, and your score in a competition is determined, in part, by how quickly you solve the problems. I’d expect o3 to be much faster than human contestants. (The specifics are unclear—I’m not sure how a large test-time compute usage translates to wall-clock time—but at the very least o3 parallelizes between problems.)
This inflates the results relative to humans somewhat. So one shouldn’t think that o3 is in the top 200 in terms of algorithmic problem solving skills.
As in, for the literal task of “solve this code forces problem in 30 minutes” (or whatever the competition allows), o3 is ~ top 200 among people who do codeforces (supposing o3 didn’t cheat on wall clock time). However, if you gave humans 8 serial hours and o3 8 serial hours, much more than 200 humans would be better. (Or maybe the cross over is at 64 serial hours instead of 8.)
Is this what you mean?
This is close but not quite what I mean. Another attempt:
The literal Do Well At CodeForces task takes the form “you are given ~2 hours and ~6 problems, maximize this score function that takes into account the problems you solved and the times at which you solved them”. In this o3 is in top 200 (conditional on no cheating). So I agree there.
As you suggest, a more natural task would be “you are given t time and one problem, maximize your probability of solving it in the given time”. Already at t equal to ~1 hour (which is what contestants typically spend on the hardest problem they’ll solve), I’d expect o3 to be noticeably worse than top 200. This is because the CodeForces scoring function heavily penalizes slowness, and so if o3 and a human have equal performance in the contests, the human has to make up for their slowness by solving more problems. (Again, this is assuming that o3 is faster than humans in wall clock time.)
I separately believe that humans would scale better than AIs w.r.t. t, but that is not the point I’m making here.
Apparently OpenAI corrected for AIs being faster than humans when they calculated ratings. This means I was wrong: the factor I mentioned didn’t affect the results. This also makes the result more impressive than I thought.
See appendix B.3 in particular:
Huh, I tried to paste that excerpt as an image to my comment, but it disappeared. Thanks.
It’s hard to compare across domains but isn’t the FrontierMath result similarly impressive?
How have your AGI timelines changed after this announcement?
~No update, priced it all in after the Q* rumors first surfaced in November 2023.
A rumor is not the same as a demonstration.
It is if you believe the rumor and can extrapolate its implications, which I did. Why would I need to wait to see the concrete demonstration that I’m sure would come, if I can instead update on the spot?
It wasn’t hard to figure out how “something like an LLM with A*/MCTS stapled on top” would look like, or where it’d shine, or that OpenAI might be trying it and succeeding at it (given that everyone in the ML community had already been exploring this direction at the time).
Suppose I throw up a coin but I dont show you the answer. Your friend’s cousin tells you they think the bias is 80⁄20 in favor of heads.
If I show you the outcome was indeed heads should you still update ? (Yes)
Sure. But if you know the bias is 95⁄5 in favor of heads, and you see heads, you don’t update very strongly.
And yes, I was approximately that confident that something-like-MCTS was going to work, that it’d demolish well-posed math problems, and that this is the direction OpenAI would go in (after weighing in the rumor’s existence). The only question was the timing, and this is mostly within my expectations as well.
That’s significantly outside the prediction intervals of forecasters so I will need to see an metaculus /manifold/etc account where you explicitly make this prediction sir
Fair! Except I’m not arguing that you should take my other predictions at face value on the basis of my supposedly having been right that one time. Indeed, I wouldn’t do that without just the sort of receipt you’re asking for! (Which I don’t have. Best I can do is a December 1, 2023 private message I sent to Zvi making correct predictions regarding what o1-3 could be expected to be, but I don’t view these predictions as impressive and it notably lacks credences.)
I’m only countering your claim that no internally consistent version of me could have validly updated all the way here from November 2023. You’re free to assume that the actual version of me is dissembling or confabulating.
The coin coming up heads is “more headsy” than the expected outcome, but maybe o3 is about as headsy as Thane expected.
Like if you had thrown 100 coins and then revealed that 80 were heads.
I guess one’s timelines might have gotten longer if one had very high credence that the paradigm opened by o1 is a blind alley (relative to the goal of developing human-worker-omni-replacement-capable AI) but profitable enough that OA gets distracted from its official most ambitious goal.
I’m not that person.
$100-200bn 5 GW training systems are now a go. So in the worlds that slow down for years if there are only $30bn systems available and would need an additional scaling push, timelines moved up a few years. Not sure how unlikely $100-200bn systems would’ve been without o1/o3, but they seem likely now.
What do you think is the current cost of o3, for comparison?
In the same terms as the $100-200bn I’m talking about, o3 is probably about $1.5-5bn, meaning 30K-100K H100, the system needed to train GPT-4o or GPT-4.5o (or whatever they’ll call it) that it might be based on. But that’s the cost of a training system, its time needed for training is cheaper (since the rest of its time can be used for other things). In the other direction, it’s more expensive than just that time because of research experiments. If OpenAI spent $3bn in 2024 on training, this is probably mostly research experiments.
Beating benchmarks, even very difficult ones, is all find and dandy, but we must remember that those tests, no matter how difficult, are at best only a limited measure of human ability. Why? Because they present the test-take with a well-defined situation to which they must respond. Life isn’t like that. It’s messy and murky. Perhaps the most difficult step is to wade into the mess and the murk and impose a structure on it – perhaps by simply asking a question – so that one can then set about dealing with that situation in terms of the imposed structure. Tests give you a structured situation. That’s not what the world does.
Consider this passage from Sam Rodiques, “What does it take to build an AI Scientist”
Right.
How do we put o3, or any other AI, out in the world where it can roam around, poke into things, and come up with its own problems to solve? If you want AGI in any deep and robust sense, that’s what you have to do. That calls for real agency. I don’t see that OpenAI or any other organization is anywhere close to figuring out how to do this.
That’s some significant progress, but I don’t think will lead to TAI.
However there is a realistic best case scenario where LLM/Transformer stop just before and can give useful lessons and capabilities.
I would really like to see such an LLM system get as good as a top human team at security, so it could then be used to inspect and hopefully fix masses of security vulnerabilities. Note that could give a false sense of security, unknown unknown type situation where it would’t find a totally new type of attack, say a combined SW/HW attack like Rowhammer/Meltdown but more creative. A superintelligence not based on LLM could however.
For people who don’t expect a strong government response… remember that Elon is First Buddy now. 🎢
Presumably light blue is o3 high, and dark blue is o3 low?
I think they only have formal high and low versions for o3-mini
Edit: nevermind idk
From the o1 blog post (evidence about the methodology for presenting results but not necessarily the same):