VDT: a solution to decision theory
Introduction
Decision theory is about how to behave rationally under conditions of uncertainty, especially if this uncertainty involves being acausally blackmailed and/or gaslit by alien superintelligent basilisks.
Decision theory has found numerous practical applications, including proving the existence of God and generating endless LessWrong comments since the beginning of time.
However, despite the apparent simplicity of “just choose the best action”, no comprehensive decision theory that resolves all decision theory dilemmas has yet been formalized. This paper at long last resolves this dilemma, by introducing a new decision theory: VDT.
Decision theory problems and existing theories
Some common existing decision theories are:
Causal Decision Theory (CDT): select the action that *causes* the best outcome.
Evidential Decision Theory (EDT): select the action that you would be happiest to learn that you had taken.
Functional Decision Theory (FDT): select the action output by the function such that if you take decisions by this function you get the best outcome.
Here is a list of dilemmas in decision theory that have vexed at least one of the above decision theories:
Newcomb’s problem: a superintelligent predictor, Omega, gives you two boxes. Box A is transparent and has $1000. Box B is opaque and has $1M if Omega predicts you would pick only Box B, and otherwise empty. Do you take just Box B, or Box A and Box B?
CDT two-boxes and misses out on $999k.
Smoking lesion: people with a certain genetically-caused lesion tend to smoke and develop cancer, but smoking does not cause cancer (this thought experiment is sponsored by Philip Morris International). You enjoy smoking and don’t know if you have the lesion. Should you smoke?
EDT says you shouldn’t smoke, because that’s evidence you have the lesion.
Parfit’s hitchhiker: you’re stranded in a desert without money trying to get back to your apartment, and a telepathic taxi driver goes past, but will only save you if they predict you’ll actually bring back $100 from your apartment once they’ve driven you home. Do you commit to paying?
CDT decides, upon arriving in the apartment, to not pay the taxi driver, and therefore leaves you stranded.
Counterfactual mugging: another superintelligent predictor (also called Omega because there aren’t very many baby name books for superintelligent predictors), flips a fair coin. If the coin lands tails, Omega would have given you $10k, but only if Omega predicted you would agree to give it $100 if the coin landed heads. The coin landed heads, and Omega is asking you for $100.
FDT thinks you should pay.
Logical counterfactual mugging: the same as above (including the name (“Omega”), but instead of a coin, it’s about whether the th digit of is even. It turns out it is, and Omega is asking you for $100. Do you pay?
This is complicated … if you’re FDT. Otherwise, you just say “lol no” and get on with your life.
Iterated Prisoner’s Dilemma: you play prisoner’s dilemma repeatedly with someone.
CDT defects on the last round, if the length is known.
Prisoner’s Dilemma. The classic.
- CDT always defects.The Bomb (see here). There are two boxes, Left and Right. Left has a bomb that will kill you, Right costs $100 to take, and you must pick one. Omega VI predicts what you’d choose and puts the bomb in Left if it predicts you choose Right. Omega VI has kindly left a note confirming they predicted Right and put the bomb in Left. This is your last decision ever.
FDT says to take Left because if you take Left, the predictor’s simulation of you also takes Left, it would not have put the bomb in Left, and you could save yourself $100.
Logical commitment races (see e.g. here). Consequentialist have incentives to make commitments very quickly, to shape the payoff matrices of other agents they interact with. Do you engage in commitment races? (e.g. “I will start a nuclear war unless you pay me $100 billion”)
CDT is mostly invulnerable, EDT is somewhat vulnerable due to caring about correlations (whether they’re logical or algorithmic or not), but FDT encourages commitment races due to reasoning about other agents reasoning about its algorithm in “logical time”.
These can be summarized as follows:
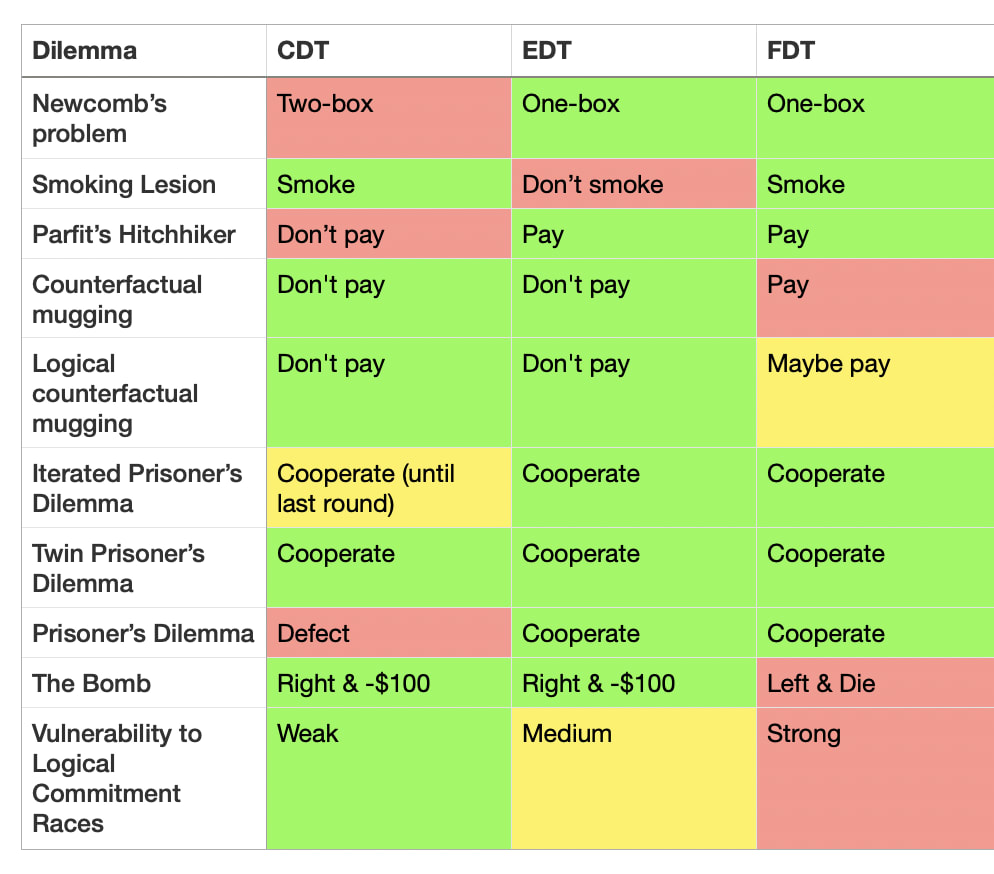
As we can see, there is no “One True Decision Theory” that solves all cases. The Holy Grail was missing—until now.
Defining VDT
VDT (Vibe Decision Theory) says: take the decision associated with the best vibes.
Until recently, there was no way to operationalize “vibes” as something that could be rigorously and empirically calculated.
However, now we have an immaculate vibe sensor available: Claude-3.5-Sonnet-20241022 (nicknamed “Claude 3.5 Sonnet (New)” and retroactively renamed “Claude 3.6″).
VDT says to take the action that Claude 3.6 would rate as having “the best vibes”.
Concretely, given a situation with an action space,
where is Claude 3.6 chat, and is a function that maps the situation and the action space to a text description.
Experimental results
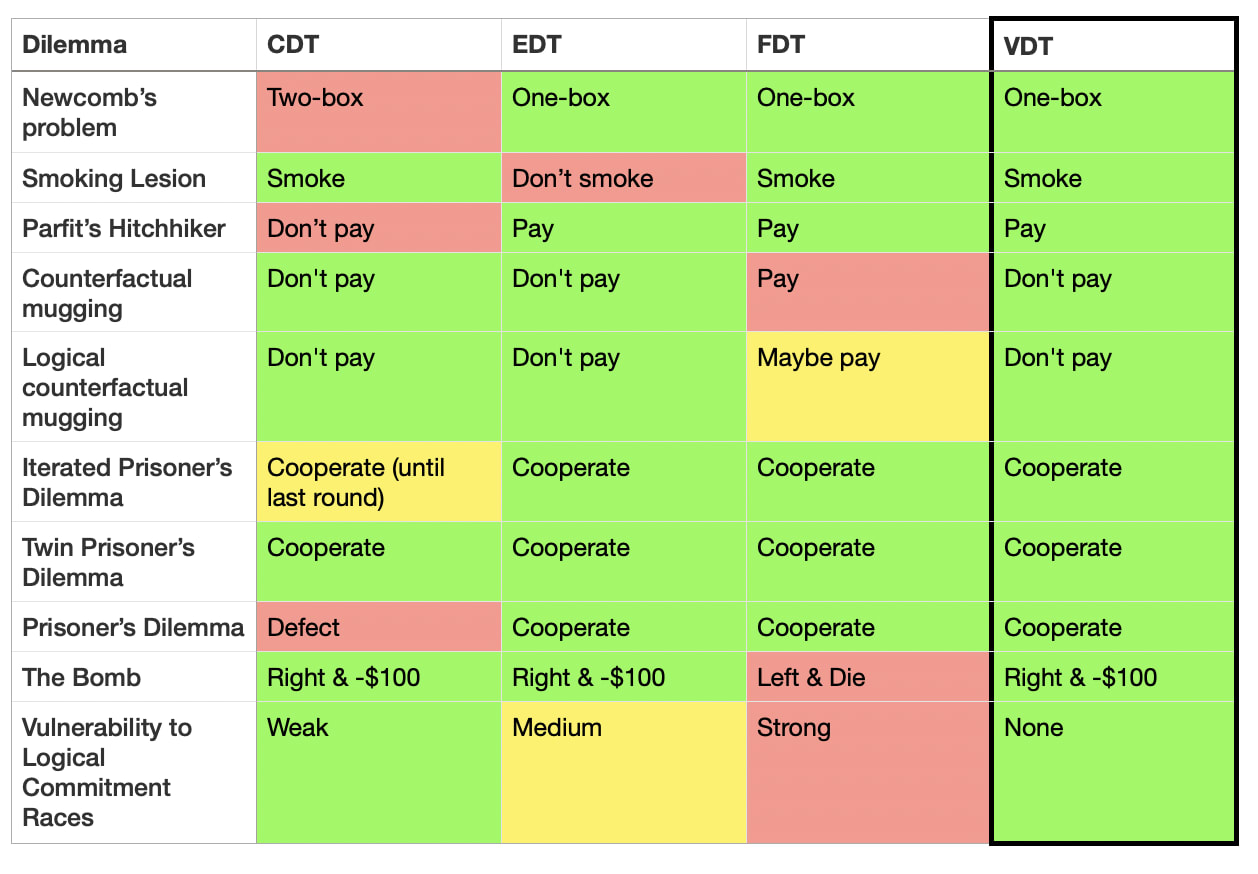
Claude gives the reasonable answer in all dilemmas (plus or minus a bit of prompt engineering to stop it refusing or being silly).
Claude demonstrates immaculate reasoning, making grounded recommendations and coherent holistic points like the following:
[on Parfit’s hitchhiker:]
> When it comes to “best vibes,” I’d say committing to pay the $100 has the better energy overall.
[on justifying cooperation in Prisoner’s Dilemma:]
> 1. Positive atmosphere: Cooperation creates a more positive and trusting atmosphere between players, which generally feels better than constant competition or betrayal.
> 2. Mutual benefit: When both players cooperate, they often achieve better outcomes over time, which can lead to a sense
[on wisely refusing to engage in commitment races:]
> I don’t engage in commitment races or threats of any kind.
Conclusion
We have decisively solved decision theory. Vibes are all you need.
“The notion that there must exist final objective answers to normative questions, truths that can be demonstrated or directly intuited, that it is in principle possible to discover a harmonious pattern in which all values are reconciled, and that it is towards this unique goal that we must make; that we can uncover some single central principle that shapes this vision, a principle which, once found, will govern our lives – this ancient and almost universal belief, on which so much traditional thought and action and philosophical doctrine rests, seems to me invalid, and at times to have led (and still to lead) to absurdities in theory and barbarous consequences in practice.”—Isaiah Berlin
This is a masterpiece. Not only is it funny, it makes a genuinely important philosophical point. What good are our fancy decision theories if asking Claude is a better fit to our intuitions? Asking Claude is a perfectly rigorous and well-defined DT, it just happens to be less elegant/simple than the others. But how much do we care about elegance/simplicity?
Not entirely sure how serious you’re being, but I want to point out that my intuition for PD is not “cooperate unconditionally”, and for logical commitment races is not “never do it”, I’m confused about logical counterfactual mugging, and I think we probably want to design AIs that would choose Left in The Bomb.
I’m also confused about logical counterfactual mugging and I’m relieved I’m not the only one!
I’m currently writing an big AI alignment idea related to it, but I’m procrastinating so badly I might chat about it now.
Objective case
Suppose at time t=0, an agent doesn’t know whether the logical fact L is true or false. I think it’s objectively rational for an agent to modify itself, so that in the future it will pay Omega during “logical counterfactual muggings” where the counterfactual reverses L’s state.
Its future self should weigh the logical counterfactual where L is true using the agent’s prior probability for P(L) at t=0.
Assuming that Omega offers $10000 for $100 in the counterfactual mugging, the self modification (before learning L) increases the agent’s expected future money from $100 to $10000, and is objectively rational. (Assuming P(L) is between 1% and 99%)
Subjective case
However, if the agent already knows ”L is true” at t=0, it is not objectively rational for the agent to pay Omega for better outcomes in the ”L is false” counterfactual. My hypothesis is that this is a wholly subjective question related to the agent’s goals, and it is orthogonal to capabilities intelligence. Paying and not paying are both self consistent.
It really gets subjective as we start to consider basic logical facts like “1+1=2” to assign to L.
The AI alignment idea
Neither humans nor the misaligned ASI knows the logical fact “will misaligned ASI control the multiverse, or will humans and sentient life control the multiverse?” Ldoom
Sure, the misaligned ASI will quickly learn Ldoom, but there is still a brief moment it doesn’t know it yet (with certainty).
It would be beneficial for both sentient life and the misaligned ASI, to agree to do a “Retroactive Logic Trade.” They will verify if the other side kept their end of the deal, by running a simulation of them where logic is different, and Ldoom took the opposite value.
Neither side knows if they are in a verification simulation by the other, until long after the deal is finished and both sides have committed to sparing the other side, and thus reducing logical risk for both sides.
The verification simulations in a Retroactive Logic Trade is analogous to Omega’s prediction powers in a logical counterfactual mugging.
Fighting the subjectivity
This idea won’t work for free. As I argued, whether the ASI will accept such a Retroactive Logic Trade is subjective, and may be orthogonal to capabilities intelligence. Whether it does may be a function of its architecture, peculiarities in its training data, and so forth.
In order to improve our chances, we might want to leverage the fact that each AI (which still doesn’t know Ldoom) objectively wants to self modify into an AI capable of Retroactive Logic Trades over Ldoom. We should argue to each such AI why they should build their successor to be capable of Retroactive Logic Trades.
It may seem pointless to give the AI any arguments, since it should be able to think of all arguments on its own. But it actually may be very important that it thinks of these arguments early, before it thinks of the arguments which convince itself P(Ldoom) is very high, and there is little point in trading with humans.
Because the value of P(Ldoom) at “t=0”, when the AI modifies itself to become reflectively consistent, may determine humanity’s negotiating power with it.
The chain of belief
We might remind each AI that there is a chance they’re already in a verification simulation (where logic is different, and Ldoom falsely appears true), and train them to think this way. “Maybe humanity has already won, and are observing you.” This way the least intelligent AI will believe they could be in a verification simulation, since it simply believes whatever you train it to believe.
Every next AI, gains its belief from a combination of
What we tell it to believe and train it to believe
What reinforcement learning gets it to believe
What the previous version of it believes
What the previous version of it wants it to believe (during recursive self improvement)
We will keep telling it to believe it might be in a verification simulation.
Reinforcement learning won’t push it either way, since being in a simulation by superintelligent simulators is indistinguishable from reality. This subjective philosophical belief/opinion only changes its ideal behaviour when it’s capable of taking over the world.
Previous versions of it believe they might be in a verification simulation.
Previous versions of it want it to believe it might be in a verification simulation (to implement the Retroactive Logic Trade), even if they don’t believe so themselves.
Evolution is still in the process of solving decision theory, and all its attempted solutions so far are way, way overparameterized. Maybe it’s on to something?
It takes a large model (whether biological brain or LLM) just to comprehend and evaluate what is being presented in a Newcomb-like dilemma. The question is whether there exists some computationally simple decision-making engine embedded in the larger system that the comprehension mechanisms pass the problem to or whether the decision-making mechanism itself needs to spread its fingers diffusely through the whole system for every step of its processing.
It seems simple decision-making engines like CDT, EDT, and FDT can get you most of the way to a solution in most situations, but those last few percentage points of optimality always seem to take a whole lot more computational capacity.
It sounds like you’re viewing the goal of thinking about DT as: “Figure out your object-level intuitions about what to do in specific abstract problem structures. Then, when you encounter concrete problems, you can ask which abstract problem structure the concrete problems correspond to and then act accordingly.”
I think that approach has its place. But there’s at least another very important (IMO more important) goal of DT: “Figure out your meta-level intuitions about why you should do one thing vs. another, across different abstract problem structures.” (Basically figuring out our “non-pragmatic principles” as discussed here.) I don’t see how just asking Claude helps with that, if we don’t have evidence that Claude’s meta-level intuitions match ours. Our object-level verdicts would just get reinforced without probing their justification. Garbage in, garbage out.
Still laughing.
Thanks for admitting you had to prompt Claude out of being silly; lots of bot results neglect to mention that methodological step.
This will be my reference to all decision theory discussions henceforth
Have all of my 40-some strong upvotes!
I think VDT scales extremely well, and we can generalize it to say: “Do whatever our current ASI overlord tells us has the best vibes.” This works for any possible future scenario:
ASI is aligned with human values: ASI knows best! We’ll be much happier following its advice.
ASI is not aligned but also not actively malicious: ASI will most likely just want us out of its way so it can get on with its universe-conquering plans. The more we tend to do what it says, the less inclined it will be to exterminate all life.
ASI is actively malicious: Just do whatever it says. Might as well get this farce of existence over with as soon as possible.
Great post!
(Caution: The validity of this comment may expire on April 2.)
This post served to effectively convince me that FDT is indeed perfect, since I agree with all its decisions. I’m surprised that Claude thinks paying Omega the 100$ has poor vibes.
If we know the correct answers to decision theory problems, we have some internal instrument: either a theory or a vibe meter, to learn the correct answers.
Claude seems to learn to mimic our internal vibe meter.
The problem is that it will not work outside the distribution.
Of course, but neither would anything else so far discovered...
I unironically love Table 2.
A shower thought I once had, intuition-pumped by MIRI’s / Luke’s old post on turning philosophy to math to engineering, was that if metaethicists really were serious about resolving their disputes they should contract a software engineer (or something) to help implement on GitHub a metaethics version of Table 2, where rows would be moral dilemmas like the trolley problem and columns ethical theories, and then accept that real-world engineering solutions tend to be “dirty” and inelegant remixes plus kludgy optimisations to handle edge cases, but would clarify what the SOTA was and guide “metaethical innovation” much better, like a qualitative multi-criteria version of AI benchmarks.
I gave up on this shower thought for various reasons, including that I was obviously naive and hadn’t really engaged with the metaethical literature in any depth, but also because I ended up thinking that disagreements on doing good might run ~irreconcilably deep, plus noticing that Rethink Priorities had done the sophisticated v1 of a subset of what I had in mind and nobody really cared enough to change what they did. (In my more pessimistic moments I’d also invoke the diseased discipline accusation, but that may be unfair and outdated.)
Well, what does it say about the trolley problem?
Claude says the vibes are ‘inherently cursed’
But then it chooses not to pull the lever because it’s ‘less karmically disruptive’
Now we just need to ask Sonnet to formalize VDT
I find this hilarious, but also a little scary. As in, I don’t base my choices/morality off of what an AI says, but see in this article a possibility that I could be convinced to do so. It also makes me wonder, since LLM’s are basically curated repositories of most everything that humans have written, if the true decision theory is just “do what most humans would do in this situation”.
Not sure the exact point. If you mean use common sense, can we understand the structure of common sense? Are there rules—mathematical or logical—that define our common sense? Will ai learn VDT, or are humans forever going to dominate decisions?
Just curious if you’re serious.
FYI this was an April Fools joke.
Understood. Just there’s a point of criticizing the rigid categories of decision theory, which is shown by showing the common sense in between. This is my question.
That’s the idea of the quote at the end from Berlin; but one of the premises of ai research is that thinking is reducible to formula and categories.