AI will change the world, but won’t take it over by playing “3-dimensional chess”.
By Boaz Barak and Ben Edelman
[Cross-posted on Windows on Theory blog; See also Boaz’s posts on longtermism and AGI via scaling as well as other “philosophizing” posts.]
[Disclaimer: Predictions are very hard, especially about the future. In fact, this is one of the points of this essay. Hence, while for concreteness, we phrase our claims as if we are confident about them, these are not mathematically proven facts. However we do believe that the claims below are more likely to be true than false, and, even more confidently, believe some of the ideas herein are underrated in current discussions around risks from future AI systems.]
[To the LessWrong audience: we realize this piece is stylistically different from many posts here, and is not aimed solely at regular readers, for which various terms and claims below might be very familiar. Our original impetus to write this piece was a suggestion from the organizers of the Future Fund AI worldview competition; while we are not holding our breath for any reward, we thought it would be a good idea to engage with the LessWrong audience in this discussion. This post could be described as somewhere between an ordinary collaboration and an adversarial one—the views expressed are a closer fit for Boaz’s current views than Ben’s.]

In the past, the word “computer” was used to denote a person that performs calculations. Such people were highly skilled and were crucial to scientific enterprises. As described in the book “Hidden Figures”, until the 1960s, NASA still used human computers for the space mission. However, these days a $10 calculator can instantly perform calculations beyond the capabilities of every human on earth.
On a high level, the situation in Chess and other games is similar. Humans used to be the reigning champions in Chess and Go, but have now been surpassed by computers. Yet, while the success of computers in performing calculations has not engendered fears of them “taking over the world,” the growing powers of AI systems have more people increasingly worried about their long-term implications. Some reasons why the success of AI systems such as AlphaZero in Go and Chess is more concerning than the success of calculation programs include
Unlike when working with numerical computation programs, it seems that in Chess and Go humans are entirely “unnecessary.” There is no need to have a “human in the loop”. Computer systems are so powerful that no meaningful competition is possible between even the best human players and software running on commodity laptops.[1]
Unlike the numerical algorithms used for calculations, we do not understand the inner workings of AI chess systems, especially ones trained without any hand-designed knowledge. These systems are to a large extent “black boxes,” which even their creators do not fully understand and hence cannot fully predict or control.
Moreover, AlphaZero was trained using a paradigm known as reinforcement learning or RL (see also this book). At a high level, RL can be described as training an agent to learn a strategy (i.e., a rule to decide on a move or action based on the history of all prior ones) in order to maximize a long-term reward (e.g., “win the game”). The result is a system that is capable of executing actions that may seem wrong in the short term (e.g., sacrificing a queen) but will help achieve the long-term goal.
While RL so far has had very limited success outside specific realms such as games or low-complexity settings, the success of (non-RL) deep learning systems such as GPT-3 or Dall-E in open-ended text or image generation has raised fears of future AI systems that could both act in the real world, interacting with humans, physical, and digital systems, and do so in the pursuit of long term goals that may not be “aligned” with the interests of humanity. The fear is that such systems could become so powerful that they could end up destroying much or all of humanity. We refer to the above scenario as the loss of control scenario. It is distinct from other potential risks of Artificial Intelligence, including the risks of AI being used by humans to develop more lethal weapons, better ways for repressive regimes to surveil their population or more effective ways of spreading misinformation.
In this essay, we claim that the “loss of control” scenario rests on a few key assumptions that are not justified by our current understanding of artificial intelligence research. (This doesn’t mean the assumptions are necessarily wrong—just that we don’t believe the preponderance of the evidence supports them.) To be clear, we are not “AI skeptics” by any means. We fully believe that over the next few decades, AI will continue to make breakthrough advances, and AI systems will surpass current human performance in many creative and technical fields, including, but not limited to, software engineering, hacking, marketing, visual design, (at least some components of) scientific discovery, and more. We are also not “techno-optimists.” The world already faces risks, and even existential ones, from the actions of humans. People who have had control over nuclear weapons over the course of history include Joseph Stalin, Kim Jong-un, Vladimir Putin, and many others whose moral judgment is suspect, to say the least. Nuclear weapons are not the only way humans can and have caused suffering on a mass scale; whether it is biological, chemical, or even so-called “conventional” weapons, climate change, exploitation of resources and people, or others, humans have a long history of pain and destruction. Like any new technology, AI will be (and in fact already has been) used by humans for warfare, manipulations, and other illicit goals. These risks are real and should be studied, but are not the focus of this essay.
Our argument: an executive summary.
The loss of control scenario is typically described as a “battle” between AIs and humans, in which AIs would eventually win due to their superior abilities. However, unlike in Chess games, humans can and will use all the tools at their disposal, including many tools (e.g., code-completion engines, optimizers for protein folding, etc..) that are currently classified as “Artificial Intelligence”. So to understand the balance of power, we need to distinguish between systems or agents that have only short-term goals, versus systems that plan their own long-term strategies.
The distinction above applies not just to artificial systems but also to human occupations as well. As an example, software developers, architects, engineers, or artists have short-term goals, in the sense that they provide some particular product (piece of software, design for a bridge, artwork, scientific paper) that can stand and be evaluated on its own merits. In contrast, leaders of companies and countries set long-term goals in the sense that they need to come up with a strategy that will yield benefits in the long run and cannot be assessed with confidence until it is implemented.[2]
We already have at least partial “short-term AI”, even if not at the level of replacing e.g., human software engineers. The existence of successful “long-term AI” that can come up with strategies which are enacted over a scale of, say, years is still an open question, but for the sake of this essay we accept that assumption.
We believe that when evaluating the loss-of-control scenario, the relevant competition is not between humans and AI systems, but rather between humans aided with short-term AI systems and long-term AI systems (themselves possibly aided with short-term components). One thought experiment we have in mind is a competition between two firms: one with a human CEO, but with AI engineers and advisors, and the other a fully AI firm.
While it might seem “obvious” that eventually AI would be far superior to humans in all endeavors, including being a CEO, we argue that this is not so obviously the case. We agree that future AIs could possess superior information processing and cognitive skills—a.k.a. “intelligence”—compared to humans. But the evidence so far suggests the advantages of these skills would be much more significant in some fields than in others. We believe that this is uncontroversial—for example, it’s not far-fetched to claim that AI would make much better chess players than kindergarten teachers. Specifically, there are “diminishing returns” for superior information-processing capabilities in the context of setting longer-term goals or strategies. The long time horizon and the relevance of interactions among high numbers of agents (who are themselves often difficult to predict) make real-life large-scale systems “chaotic” in the sense that even with superior analytic abilities, they are still unpredictable (see Figure 1).
As a consequence, we believe the main fields where AI systems will yield advantages will be in short-term domains. An AI engineer will be much more useful than an AI CEO (see also Table 2). We do not claim that it would be impossible to build an AI system that can conceive and execute long-term plans; only that this would not be where AI would have a “competitive advantage”. Short-term goals that can be evaluated and graded also mesh much better with the current paradigm of training AI systems on vast amounts of data.
We believe it will be possible to construct very useful AIs with only short-term goals, and in fact that the vast majority of AI’s power will come from such short-term systems. Even if a long-term AI system is built, it will likely not have a significant advantage over humans assisted with short-term AIs. There can be many risks even from short-term AI systems, but such machines cannot by design have any long-term goals, including the goal of taking over the world and killing all humans.[3]
Perspective. Our analysis also has a lesson for AI safety research. Traditionally, approaches to mitigate the behavior of bad actors include
Prevention: We prevent break-ins by putting locks on our doors, we prevent hacks by securing our systems, etc…
Deterrence: Another way we prevent bad actions is by ensuring that the negative consequences for these actions will outweigh benefits. This is one basis for the penal system, as well as the “mutually assured destruction” paradigm that has kept Russia and US from a nuclear war.
Alignment: We try to educate children and adults and socialize them to our values, so they are not motivated to pursue the actions we consider as bad.
Much of AI safety research (wrt to the “loss of control” scenario) has been focused on the third approach, with the expectation that these systems may be so powerful that prevention and deterrence will be impossible. However, it is unclear to us that this will be the case. For example, it may well be that humans, aided by short-term AI systems, could vastly expand the scope of formally verified secure systems, and so prevent hacking attacks against sensitive resources. A huge advantage of research on prevention is that it is highly relevant not just to protect against hypothetical future bad AI actors, but also against current malicious humans. Such research might greatly benefit from advances in AI code-completion engines and other tools, hence belying the notion that there is a “zero-sum game” between “AI safety” and “AI capabilities” research.
Furthermore, one advantage of studying AI systems, as opposed to other organisms, is that we can try to extract useful modules and representations for them. (Indeed, this is already done in “transfer learning.”) Hence, it may be possible to extract useful and beneficial “short-term AI” even from long-term systems. Such restricted systems would still give most of the utility, but with less risk. Once again, increasing the capabilities of short-term AI systems will empower humans that are assisted by such systems.
Figure 1: Cartoon of the feasibility of predicting future events and the level of ability (i.e., cognitive skill / compute / data) required to do so (approximately) optimally. As the horizon grows, events have more inherent uncertainty and also require more skills/data to predict. However, many realistic systems are chaotic and become unpredictable at some finite horizon.[4] At that point, even sophisticated agents cannot predict better than baseline heuristics, which require only a bounded level of skill.
| Profession | Cognitive Score (standard deviations) | Annual Earnings |
| Mayors | 6.2 ( ≈ +0.6σ ) | 679K SEK |
| Parliamentarians | 6.4 ( ≈ +0.7σ ) | 802K SEK |
| CEOs (10-24 employees) | 5.8 ( ≈ +0.4σ ) | 675K SEK |
| CEOs (25-249 employees) | 6.2 ( ≈ +0.6σ ) | 1,046K SEK |
| CEOs (≥ 250 employees) | 6.7 ( ≈ +0.85σ ) | 1,926K SEK |
| Medical Doctors | 7.4 ( ≈ +1.2σ ) | 640K SEK |
| Lawyers and Judges | 6.8 ( ≈ +0.9σ ) | 568K SEK |
| Economists | 7 ( ≈ +1σ ) | 530K SEK |
| Political Scientists | 6.8 ( ≈ +0.9σ ) | 513 SEK |
Table 2: Cognitive scores for Swedish men in various “elite” occupations, based on Swedish army entrance examinations, taken from Dal Bó et al (Table II). Emphases ours: bold text corresponds to jobs that (in our view) require longer horizon decision-making across time or number of people. Note that despite being apparently less cognitively demanding, the “bold” professions are higher paying.
A digression: what is intelligence
Merriam-Webster defines intelligence as “the skilled use of reason”, “the ability to learn or understand or to deal with new or trying situations”, or “to apply knowledge to manipulate one’s environment or to think abstractly.” Intelligence is similar to computation, in the sense that its main components are the ability to take in observations (aka “inputs”) and use reasoning (aka “algorithms”) to decide on actions (aka “outputs”). In fact, in the currently dominant paradigm of AI, performance is primarily determined by the amount of computation performed during learning, and AI systems consist of enormous homogeneous circuits executing a series of simple operations on (a large quantity of) inputs and learned knowledge. Bostrom (Chapter 3) defines three forms of “superintelligence”: “speed superintelligence”, “collective superintelligence” and “quality superintelligence”. In the language of computing, speed super-intelligence corresponds to clock speed of processors, while collective super-intelligence corresponds to massive parallelism. “Quality superintelligence” is not well defined, but is presumably some type of emergent phenomenon from passing some thresholds of speed and parallelism.
A fundamental phenomenon in computing is universality: there are many restricted computational models (finite state automata, context-free grammars, simply-typed lambda calculus), but once a computational model passes a certain threshold or phase transition, it becomes universal (a.k.a. “Turing complete”), and all universal models are equivalent to one another in computational power. For example, in a cellular automata, even though each cell is very restricted (can only store a constant amount of memory and process a finite rule based only on the state of its immediate neighbors), given enough cells we can simulate any arbitrarily complex machine.[5] Once a system passes the universality transition, it is not bottlenecked any more by the complexity of an individual unit, but rather by the resources in the system as a whole.
In the animal kingdom, we seem to have undergone a similar phase transition, whereby humans are qualitatively more intelligent than any other animal or creature. It also seems to be the case that with the invention of language, the printing press, and the Internet, we (like cellular automata) are able to combine large numbers of humans to achieve feats of collective intelligence that are beyond any one individual. In particular, the fruits of the scientific revolution of the 1500-1600s increased the scale of GDP by 10,000-fold (to the extent such comparisons are meaningful) and the distance we can measure in space a trillion-fold, all with the same brains used by our hunter-gatherer ancestors (or maybe somewhat smaller ones).
Arguably, the fact humans are far better than chimpanzees at culturally transmitting knowledge is more significant than the gap in intelligence between individuals of the two species. Ever since the development of language, the intelligence of an individual human has not been a bottleneck for the achievements of humanity. The brilliance of individuals like Newton may have been crucial for speeding up the Scientific Revolution, but there have been brilliant individuals for millennia. The crucial difference between Newton and Archimedes is not that Newton was smarter, but rather that he lived at a later time and thus was able to stand on the shoulders of more giants. As another example, a collection of humans, aided by Internet-connected computers, can do much better at pretty much any intelligence feat (including but not limited to IQ exams) than any single human.
Figure 3: Measures of human progress both in terms of GDP and the scale of objects we can measure. Taken from this blog post, with the first figure from Our World in Data, and data for second figure from Terence Tao’s cosmic ladder presentation.
The “loss of control” scenario posits a second phase transition, whereby once AI systems become more powerful, they would not merely enable humans to achieve more objectives quicker but would themselves become as qualitatively superior to humans as humans are to other animals. We are suggesting an alternative future scenario, in which while AI would provide powerful new capabilities to human society that can (and unfortunately likely will) be used for ill as well as good, the AI systems themselves would not be the inevitable leaders of this society.
Indeed, our societies and firms do not currently select our leaders to be the top individuals in intellectual capacity. The evidence is very limited that “natural talent for leadership” (to the extent it exists) is as measurable and transferable as talent for chess, math, or athletics. There are many examples of leaders who have been extremely successful in one setting but failed in another which seems rather similar.[6]
Whether or not an AI system should be considered an “individual” is a matter for debate, but regardless, it is not at all clear that such individuals would be the leaders of the society, rather than being employed in domains such as software development and scientific discovery, where their superior information-processing capabilities would provide the most competitive advantage. Bostrom (Table 8 in Chapter 6) lists several potential “cognitive superpowers” that an AI system might develop. One category is “hacking”, “technology research”, and “economic productivity”. These are skills that correspond to jobs that are not in the domain of CEOs or leaders, but rather engineers, middle managers, scientists, etc. AI systems may well be able to assist or even replace such individuals, but this does not mean such systems will be the leaders of companies or countries.
Another task Bostrom considers is “intelligence amplification” which is the ability to improve AI systems. Again, it is quite possible that AI systems would help in improving other or the same AI systems, but this on its own does not imply that they would become infinitely powerful. Specifically, if indeed stronger AI would arrive through “scaling” of massive computational resources, then there would be some hard limits on the ability to improve AI’s power solely through software updates. It is not at all clear that in terms of energy efficiency, AI systems would be much better (if at all) than humans. If the gains from scaling are far more important than gains from improved algorithms/architectures, then intelligence amplification might be primarily a function of resource acquisition rather than algorithmic research.
A third task listed is “social manipulation.” Here we must admit we are skeptical. Anyone who has ever tried to convince a dog to part with a bone or a child with a toy could attest to the diminishing returns that an intelligence advantage has in such a situation.
Finally, Boston lists the cognitive superpower of “strategizing”, which is the ability to make long-term plans to achieve distant goals. This is the point we focus on in this essay. In short, our belief is that the chaotic nature of the real world implies diminishing returns to “three-dimensional chess” strategies that are beyond the comprehension of mere humans. Hence we do not believe that this would be a domain where AI systems have a strong competitive advantage.
A thought experiment: “The AI CEO vs. the AI advisor”
Before we delve into the technical(-ish) analysis, let us consider a thought experiment. At its heart, our argument is that the power of AI systems, present and future, will not come from the ability to make long-term strategic plans (“three-dimensional chess”) but rather from the ability to produce pieces of work that can be evaluated on their own terms. In short, we believe that even if a long-term malicious AI system is constructed, it will not have an insurmountable advantage over humans that are assisted with short-term AIs. To examine this, let us imagine two possible scenarios for how future AI could assist humans in making strategic decisions, such as running a company:
In the “AI Advisor” model, leaders could use AI to come up with simulations of the impact of decisions and possibly make some suggestions. However, humans would ultimately make the decision and evaluate their results. Key for this is that an AI would be able not just to produce a recommendation for a decision but explain how this decision would lead to improvement in some interpretable metric (e.g., revenue, market share, etc..). For example, a decision might be “let’s sell this product at a loss so we can increase our market share.”
In the “AI CEO” model, AIs could use their superior powers to choose an optimal long-term strategy as opposed to an individual decision. The strategy would not be “greedy”, in the sense of a sequence of steps each making progress on measurable goals, and it would not have any compact analysis of why it is good. Also, the only way to accrue the benefits of the strategy would be to continue pursuing it in the long term. Hence users would have to trust the AI and follow its recommendations blindly. For example, think of the case in Chess where an AI figures out that the best move is to sacrifice the queen because for any one of the possible opponent’s moves, there is a countermove, and so on and so forth. The only explanation for why this strategy is a good one may consist of an exponentially big game tree up to a certain depth.
Our sense is that there is strong evidence that AI would be incredibly useful for making low-level decisions (i.e., optimizing objectives under constraints) once the high-level strategy was set. Indeed, by far the most exciting advances for deep learning have not been through reinforcement learning, but rather through techniques such as supervised and unsupervised learning. (With the major exception being games like Chess and Go, though even there, given the success of non-RL engines such as Stockfish versions 12 and later, it is not clear RL is needed.) There is less evidence that “AI advisors” would be useful for setting high-level strategies, but it is certainly plausible. In particular, the power of prompt-based generative models suggests that AI could be useful for generating realistic simulations that can help better convey the impact of various decisions and events. So, while “AI engineers” might be more useful than “AI advisors”, the latter might well have their role as well.
In contrast, we believe that there is little to no evidence for the benefits of “three-dimensional chess” strategies of the type required for the “AI CEO” scenario. The real world (unlike the game of chess or even poker), involves a significant amount of unpredictability and chaos, which makes highly elaborate strategies depending on complex branching trees of moves and counter-moves far less useful. We also find it unlikely that savvy corporate boards would place blind trust in an AI CEO given that (as mentioned above) evaluation of even human CEOs tends to be controversial.
There is an alternative viewpoint, which is that an AI CEO would basically be equivalent to a human CEO but with superhuman “intuition” or “gut feeling” that they cannot explain but somehow leads to decisions that yield enormous benefits in the long term. While this viewpoint cannot be ruled out, there is no evidence in current deep learning successes to support it. Moreover, often great CEO’s “gut feelings” are less about particular decisions, but more about the relative importance of particular metrics (e.g., prioritizing market share or user experience over short-term profits).
In any case, even if one does not agree with our judgment of the relative likelihoods of the above scenarios, we hope that this essay will help sharpen the questions that need to be studied, as well as what lessons can we draw about them from the progress so far of AI systems.
Technical Analysis
1. Key hypotheses behind the “Loss of Control” Scenario
For the sake of the discussion below, let’s assume that at some future time there exists an artificial intelligence system that in a unified way achieves performance far superior to that achieved by all humans today across many fields. This is a necessary assumption for the “loss of control” scenario and an assumption we accept in this essay. For the sake of simplicity, below we refer to such AI systems as “powerful”.
We will also assume that powerful AI will be constructed following the general paradigm that has been so successful in the last decade of machine learning. Specifically, the system will be obtained by going through a large amount of data and computational steps to find some instantiation (a.k.a. “parameters” or “weights”) of it that optimizes some chosen objective. Depending on the choice of the objective, this paradigm includes supervised learning (“classify this image”), unsupervised learning (“predict the next token”), reinforcement learning (“win the game”), and more.
For the loss of control scenario to occur, the following two hypotheses must be true:
Loss-of-Control Hypothesis 1: There will exist a powerful AI that has long-term goals.
For an AI to have misaligned long-term goals, it needs to have some long-term goals in the first place. There is a question of how to define the “goals” of an AI system or even a human for that matter. In this essay, we say that an agent has a goal X if, looking retrospectively at the history of the agent’s actions, the most parsimonious explanation for its actions was that it was attempting to achieve X, subject to other constraints or objectives. For example, while chess experts often find it hard to understand why an engine such as AlphaZero makes a specific move, by the end of the game, they often understand the reasoning retrospectively and the sub-goals it was pursuing.
In our parlance, a goal is “long-term” if it has a similar horizon to goals such as “take over the world and kill all the humans” —requiring planning over large scales of time, complexity, and number of agents involved.[7]
In contrast, we consider goals such as “win a chess game”, “come up with a plan for a bridge that minimizes cost and can carry X traffic”, or “write a piece of software that meets the requirements Y”, as short-term goals. As another example, “come up with a mix of stocks to invest today that will maximize return next week” is a short-term goal, while “come up with a strategy for our company that will maximize our market cap over the next decade” or “come up with a strategy for our country that will maximize our GDP for the next generation” would be long-term goals. The distinction between “short-term goals AI” and “long-term goals AI” is somewhat similar to the distinction between “Tool AI” and “Agent AI” (see here). However, what we call “short-term AI” encompasses much more than “Tool AI”, and absolutely includes systems that can take actions such as driving cars, executing trading actions, and so on and so forth.
We claim that for the “loss of control” scenario to materialize, we need not only Hypothesis 1 but also the following stronger hypothesis:
Loss-of-Control Hypothesis 2: In several key domains, only AIs with long-term goals will be powerful.
By this, we mean that AIs with long-term goals would completely dominate other AIs, in that they would be much more useful for any user (or for furthering their own goals). In particular, a country, company or organization that restricts itself to only using AIs with short term goals would be at a severe competitive disadvantage compared to one that uses AIs with long-term goals.
Why is Hypothesis 2 necessary for the “loss of control” scenario? The reason is that this scenario requires the “misaligned long-term powerful AI” to be not merely more powerful than humanity as it exists today, but more powerful than humanity in the future. Future humans will have at their disposal the assistance of short-term AIs.
2. Understanding the validity of the hypotheses
We now make the following claims, which we believe cast significant doubt on Hypothesis 2.
Claim 1: There are diminishing returns to information-processing skills with longer horizons.
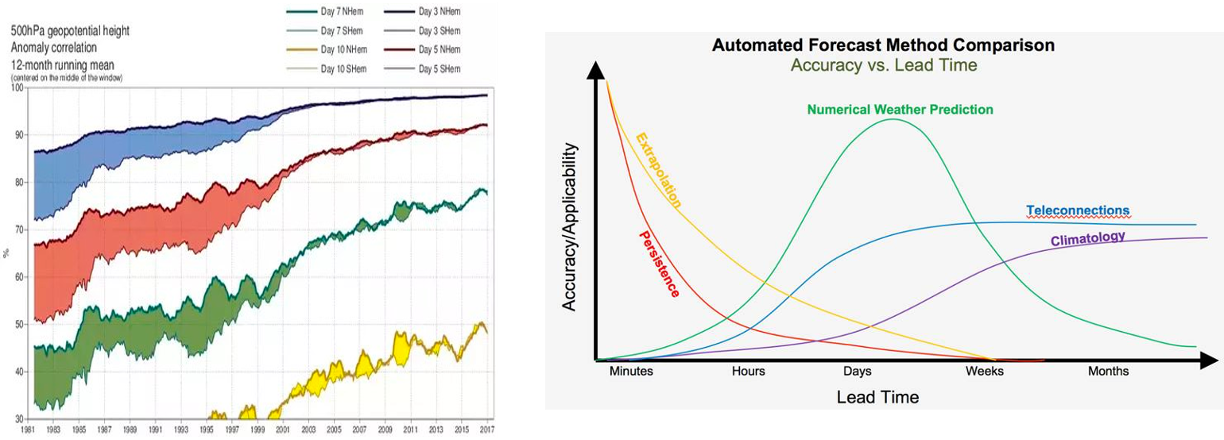
Consider the task of predicting the consequences of a particular action in the future. In any sufficiently complex real-life scenario, the further away we attempt to predict, the more there is inherent uncertainty. For example, we can use advanced methods to predict the weather over a short time frame, but the further away the prediction, the more the system “regresses to the mean”, and the less advantage that highly complex models have over simpler ones (see Figure 4). As in meteorology, this story seems to play out similarly in macroeconomic forecasting. In general, we expect prediction success to behave like Figure 1 below—the error increases with the horizon until it plateaus to a baseline level of some simple heuristic(s). Hence while initially highly sophisticated models can beat simpler ones by a wide margin, this advantage eventually diminishes with the time horizon.
Tetlock’s first commandment to potential superforecasters is to triage: “Don’t waste time either on “clocklike” questions (where simple rules of thumb can get you close to the right answer) or on impenetrable “cloud-like” questions (where even fancy statistical models can’t beat the dart-throwing chimp). Concentrate on questions in the Goldilocks zone of difficulty, where effort pays off the most.” Another way to say it is that outside of the Goldilocks zone, more effort or cognitive power does not give much returns.
Figure 4: Left: Historical weather prediction accuracy data taken from a Quora answer of Mikko Strahlendorff. With technological advances, accuracy has improved significantly, but prediction accuracy sharply decays with time. Right: Figure on relative applicability of different methods from Brent Shaw. Computationally intensive numerical prediction applies in a “goldilocks zone” of days to weeks.
In a variety of human endeavors, it seems that the cognitive skills needed to make decisions display a similar phenomenon. Occupations involving making decisions on the mid-range horizon, such as engineering, law, and medicine, require higher cognitive skills than those requiring long-term decisions such as CEOs or Politicians (see Table 3).
One argument people make is that intelligence is not just about IQ or “booksmarts”. We do not dispute this. However, we do believe that the key potential advantage of AI systems over their human counterparts would be the ability to quickly process large amounts of information, which in humans is approximated by scores such as IQ. If that skill were key to successful leadership of companies or countries, then we would expect CEOs and leaders to come from the top 0.1% (≈ +3σ) of the distribution of such scores. The data does not bear this out.[8]
Claim 2: It may be possible to extract powerful short-term modules from long-term systems.
For Hypothesis 2 to be true, it should not be possible to take a powerful AI system with long-term goals, and extract from it modules that would be just as powerful in the key domains, but would have short-term goals. However, a nascent body of work identifies and extracts useful representations and sub-modules in deep neural networks. See, for example, this recent investigation of AlphaZero. We remark that some components of AlphaZero also inspired advances to the Stockfish Chess Engine (which is not trained using RL and involves a lot of hand-coded features), and whose latest version does in fact beat RL trained methods a-la AlphaZero.
A related issue is that a consistent theme of theoretical computer science is that verification is easier than solving or proving. Hence even a complex system could explain its reasoning to a simple verifier, even if that reasoning required a significant effort to discover. There are similar examples in human affairs: e.g., even though the discovery of quantum mechanics took thousands of years and multiple scientific revolutions, we can still teach it to undergraduates today whose brains are no better than those of the ancient Greeks.
2.1 The impact of the deep learning paradigm on Hypothesis 2
The following claims have to do with the way we believe advanced AI systems will be constructed. We believe it is fair to assume that the paradigm of using massive data and computation to create such systems, by optimizing with respect to a certain objective, will continue to be used. Indeed, it is the success of this paradigm that has caused the rise in concerns about AI in the first place. In particular, we want to make a clear distinction between the training objective, which the system is designed to optimize, versus the goals that the system appears to follow during its deployment.
Claim 3: There may be fundamental “scaling laws” governing the amount of performance AI systems can achieve as a function of the data and computational resources.
One of the original worries in the AI risk literature is the “singularity” scenario, by which an AI system continuously improves its own performance without limit. However, this assumes that a system can improve itself by rewriting its code, without requiring additional hardware resources. If there are hard limits to what can be achieved with a certain level of resources, then such self-improvements will also hit diminishing returns. There has been significant evidence for the “scaling laws” hypothesis in recent years.
Figure 5: Scaling laws as computed by Hoffman et al (“Chinchilla”), see Figure A4 there. While the scaling laws are shaped differently from those of Kaplan et al, the qualitative point we make remains the same.
Claim 4: When training with reinforcement learning, the gradient signal may decrease exponentially with the length of the horizon.
Consider training a system that chooses a sequence of actions, and only gets a reward after H steps (where H is known as the “horizon”). If at any step there is some probability of an action leading to a “dead end” then the chances of getting a meaningful signal decrease exponentially with H. This is a fundamental obstacle to reinforcement learning and its applicability in open-ended situations with a very large space of actions, and a non-trivial cost for any interaction. In particular, one reason AlphaZero was successful was that in games such as chess, the space of legal moves is very constrained, and in the artificial context of a game it is possible to “reset” to a particular position: that is, one can try out different actions and see what their consequences are, and then go back to the same position. This is not possible when interacting in the real world.
As a corollary of Claim 4, we claim the following:
Claim 5: There will be powerful AI systems that are trained with short-term objective functions.
By this, we mean models that are trained on a reward/loss function that only depends on a relatively short span of actions/outputs. A canonical example of this is next-token prediction. That is, even if the eventual deployment of the model will involve it making actions and decisions over a long time horizon, its training will involve optimizing short-term rewards.
One might think that the model’s training does not matter as much, since once it is deployed in the real world, much of what it will learn will be “on the job”. However, this is not at all clear. Suppose the average worker reads/hears about 10 pages per day, which is roughly 5K tokens, leading to roughly 2M tokens per year. In contrast, future AIs will likely be trained on a trillion tokens or so, corresponding to the amount a worker will see in 5 million years! This means that while “fine-tuning” or “in context” learning can and will occur, many of the fundamental capabilities of the systems will be fixed at the time of training (as appears to be the case for pre-trained language models that are fine-tuned with human feedback).
Claim 6: For a long-term goal to necessarily emerge from a system trained with a short-term objective, it must be correlated or causally related to that objective.
If we assume that powerful AIs will be trained with short-term objectives, then Hypothesis 2 requires that (in several key domains) every such system will develop long-term goals. In fact, for the loss-of-control scenario to hold, every such system should develop more-or-less the same sort of goal (e.g., “take over the world”).
While it is certainly possible for systems that evolve from simple rules to develop complex behavior (e.g., cellular automata), for a long-term goal to consistently emerge from mere short-term training, there should be some causal relation (or at least persistent correlation) between the long-term goal and the short-term training objective. This is because an AI system can be modeled as a maximizer of the objective on which it was trained. Thus for such a system to always pursue a particular long-term goal, that goal should be correlated with maximizing the training objective.
We illustrate this with an example. Consider an AI software developer which is trained to receive a specification of a software task (say, given by some unit tests) and then come up with a module implementing it, obtaining a reward if the module passes the tests. Now suppose that in actual deployment, the system is also writing the tests that would be used to check its future outputs. We might worry that the system would develop a “long-term” goal to maximize total reward by writing one faulty test, taking the “hit” on it, and receiving a low reward, but then getting high rewards on future tasks. However, that worry would be unfounded, since the AI software developer system is trained to maximize the reward for each task separately, as opposed to maximizing the sum of rewards over time over adaptively chosen inputs of its own making.
Indeed, this situation can already happen today. Next-token prediction models such as GPT-3 are trained on the reward of the perplexity over a single token, but when they are deployed, we typically generate a long sequence of tokens. Now consider a model that simply outputs an endless repetition of the word “blah”. The first few repetitions would get very low rewards, since they are completely unexpected, but once n is large enough (e.g. 10 or so), if you’ve already seen n “blah”s then the probability that the n+1 st word is also “blah” is very high. So if the model were to be maximizing total reward, it may well be worth “taking the hit” by outputting a few blahs. The key point is that GPT-3 does not do that. Since it is trained on predicting the next token for human-generated (as opposed to the text generated by itself), it will optimize for this short-term objective rather than the long-term one.
We believe the example above generalizes to many other cases. An AI system trained in the current paradigm is, by default, a maximizer of the objective it was trained on, rather than an autonomous agent that pursues goals of its own design. The shorter the horizon and more well-defined the objective is, the less likely that optimizing it will lead to systems that appear to take elaborate plans to pursue far-reaching (good or bad) long-term goals.
Summary
Given the above, we believe that while AI will continue to yield breakthroughs in many areas of human endeavor, we will not see a unitary nigh-omnipotent AI system that acts autonomously to pursue long-term goals. Concretely, even if a successful long-term AI system could be constructed, we believe that this is not a domain where AI will have a significant “competitive advantage” over humans.
Rather, based on what we know, it is likely that AI systems will have a “sweet spot” of a not-too-long horizon in which they can provide significant benefits. For strategic and long-term decisions that are far beyond this sweet spot, the superior information processing skills of AIs will give diminishing returns. (Although AIs will likely supply valuable input and analysis to the decision makers.). An AI engineer may well dominate a human engineer (or at least one that is not aided by AI tools), but an AI CEO’s advantage will be much more muted, if any, over its human counterpart. Like our world, such a world will still involve much conflict and competition, with all sides aided by advanced technology, but without one system that dominates all others.
If our analysis holds, then it also suggests different approaches to mitigating AI risk than have been considered in the “AI safety” community. Currently, the prevailing wisdom in that community is that AI systems with long-term goals are a given, and hence the approach to mitigate their risk is to “align” these goals with human values. However, perhaps more evidence should be placed on building just-as-powerful AI systems that are restricted to short time horizons. Such systems could also be used to monitor and control other AIs, whether autonomous or directed by humans. This includes monitoring and hardening systems against hacking, detecting misinformation, and more. Regardless, we believe that more research needs to be done on understanding the internal representations of deep learning systems, and what features and strategies emerge from the training process (so we are happy that the AI safety community is putting increasing resources into “interpretability” research). There is some evidence that the same internal representations emerge regardless of the choices made in training.
There are also some technical research directions that would affect whether our argument is correct. For instance, we are interested in seeing work on the impacts of noise and unpredictability on the performance of reinforcement learning algorithms; in particular, on the relative performance of models of varying complexity (i.e. scaling laws for RL).
Acknowledgments: Thanks to Yafah Edelman for comments on an earlier version of this essay.
- ^
During the 90s-2000s, human-engine teams were able to consistently beat engines in “advanced chess” tournaments, but no major advanced chess tournament seems to have taken place since the release of AlphaZero and the resulting jump in engine strength, presumably because the human half of each team would be superfluous.
- ^
The success of a bridge does hinge on its long-term stability, but stability can be tested before the bridge is built, and coming up with measures for load-bearing and other desiderata is standard practice in the engineering profession. An AI trained using such a short-term evaluation suite as its reward function may still “overoptimize” against the metric, a la Goodhart’s Law, but this can likely be addressed with regularization techniques.
- ^
It may be the case that, for subtle reasons, if we try to train an AI with only short-term goals—e.g. by training in a series of short episodes—we could accidentally end up with an AI that has long-term goals. See Claim 6 below. But avoiding this pitfall seems like an easier problem than “aligning” the goals of an AI that is explicitly meant to care about the long-term.
- ^
We don’t mean that they satisfy all the formal requirements to be defined as a chaotic system; though sensitivity to initial conditions is crucial.
- ^
For a nice illustration, see Sam Trajtenberg’s construction of Minecraft in Minecraft, or this construction of Life in Life.
- ^
Steve Jobs at Apple vs NeXT is one such example; success and failure can themselves be difficult to distinguish even with the benefit of hindsight, as in the case of Jack Welch.
- ^
For example, such planning might require setting up many companies to earn large amounts of funds, conducting successful political campaigns in several countries, constructing laboratories without being detected, etc. Some such “take-over scenarios” are listed by Bostrom, as well as Yudkowski and Urban.
- ^
It is hypothetically possible that companies would be better off en masse if they hired smarter CEOs than they currently do, but given the high compensation CEOs receive this doesn’t seem like a particularly plausible equilibrium.
- AI Safety − 7 months of discussion in 17 minutes by (EA Forum; 15 Mar 2023 23:41 UTC; 89 points)
- Fundamentals of Global Priorities Research in Economics Syllabus by (EA Forum; 8 Aug 2023 12:16 UTC; 74 points)
- MATS AI Safety Strategy Curriculum by (7 Mar 2024 19:59 UTC; 74 points)
- Who are some prominent reasonable people who are confident that AI won’t kill everyone? by (5 Dec 2022 9:12 UTC; 72 points)
- Future Matters #6: FTX collapse, value lock-in, and counterarguments to AI x-risk by (EA Forum; 30 Dec 2022 13:10 UTC; 58 points)
- There should be a public adversarial collaboration on AI x-risk by (EA Forum; 23 Jan 2023 4:09 UTC; 56 points)
- GPT as an “Intelligence Forklift.” by (19 May 2023 21:15 UTC; 48 points)
- The shape of AGI: Cartoons and back of envelope by (17 Jul 2023 20:57 UTC; 33 points)
- AI Safety − 7 months of discussion in 17 minutes by (15 Mar 2023 23:41 UTC; 25 points)
- EA & LW Forums Weekly Summary (14th Nov − 27th Nov 22′) by (EA Forum; 29 Nov 2022 22:59 UTC; 22 points)
- EA & LW Forums Weekly Summary (14th Nov − 27th Nov 22′) by (29 Nov 2022 23:00 UTC; 21 points)
- Injecting some numbers into the AGI debate—by Boaz Barak by (23 Nov 2022 16:10 UTC; 12 points)
- 's comment on What can superintelligent ANI tell us about superintelligent AGI? by (EA Forum; 12 Jun 2023 8:11 UTC; 5 points)
- 's comment on Metaphors for AI, and why I don’t like them by (29 Jun 2023 7:47 UTC; 4 points)
- 's comment on GPT as an “Intelligence Forklift.” by (21 May 2023 19:34 UTC; 3 points)
Thanks for posting, I thought this was interesting and reasonable.
Some points of agreement:
I think many of these are real considerations that the risk is lower than it might otherwise appear.
I agree with your analysis that short-term and well-scoped decisions will probably tend to be a comparative advantage of AI systems.
I think it can be productive to explicitly focus on “narrow” systems (which pursue scoped short-term goals, without necessarily having specifically limited competence) and to lean heavily on the verification-vs-generation gap.
I think these considerations together with a deliberate decision to focus on narrowness could significnatly (though not indefinitely) postpone the point when alignment difficulties could become fatal.
I think that it’s unrealistic for AI systems to rapidly improve their own performance without limits. Relatedly, I sympathize with your skepticism about the story of a galaxy-brained AI outwitting humanity in a game of 3 dimensional chess.
My most important disagreement is that I don’t find your objections to hypothesis 2 convincing. I think the biggest reason for this is that you are implicitly focusing on a particular mechanism that could make hypothesis 2 true (powerful AI systems are trained to pursue long-term goals because we want to leverage AI systems’ long-horizon planning ability) and neglecting two other mechanisms that I find very plausible. I’ll describe those in two child comments so that we can keep the threads separate. Out of your 6 claims, I think only claim 2 is relevant to either of these other mechanisms.
I also have some scattered disagreements throughout:
So far it seems extremely difficult to extract short-term modules from models pursuing long-term goals. It’s not clear how you would do it even in principle and I don’t think we have compelling examples. The AlphaZero → Stockfish situation does not seem like a successful example to me, though maybe I’m missing something about the situation. So overall I think this is worth mentioning as a possibility that might reduce risk (alongside many others), but not something that qualitatively changes the picture.
I’m very skeptical about your inference from “CEOs don’t have the literal highest IQs” to “cognitive ability is not that important for performance as a CEO,” and even moreso for jumping all the way to “cognitive ability is not that important for long-term planning.” I think that (i) competent CEOs are quite smart even if not in the tails of the IQ distribution, (ii) there are many forms of cognitive ability which are only modestly correlated, and so the tails come apart, (iii) there are huge amounts of real-world experience that drive CEO performance beyond cognitive ability, (iv) CEO selection is not perfectly correlated with performance. Given all of that, I think you basically can’t get any juice out of this data. If anything I would say the high compensation of CEOs, their tendency to be unusually smart, and skill transferability across different companies seem to provide some evidence that CEO cognitive ability has major effects on firm performance (I suspect there is an economics literature investigating this claim). Overall I thought this was the weakest point of the article.
While I agree there are fundamental computational limits to performance, I don’t think they qualitatively change the picture about the singularity. This is ultimately a weedsy quantitative question and doesn’t seem central to your point so I won’t get into it, but I’d be happy to elaborate if it feels like an important disagreement. I also don’t think the scaling laws you cite support your claim; ultimately the whole point is that the (compute vs performance) curves tend to fall with further R&D.
I would agree with the claim “more likely than not, AI systems won’t take over the world.” But I don’t find <50% doom very comforting! Indeed my own estimate is more like 10-20% (depending on what we are measuring) but I still consider this a plurality of total existential risk and a very appealing thing to work on. Overall I think most of the considerations you raise are more like quantitative adjustments to these probabilities, and so a lot depends on what is in fact baked in or how you feel about the other arguments on offer about AI takeover (in both directions).
I think you are greatly underestimating the difficulty of deterrence and prevention. If AI systems are superhuman for short-horizon tasks, it seems like humans would become reliant on AI help to prevent or contain bad behavior by other AIs. But if there are widespread alignment problems, then the AI systems charged with defending humans may instead join in to help disempower humanity. Without progress on alignment it seems like we are heading towards an increasingly unstable word. The situation is quite different from preventing or deterring human “bad actors;” amongst humans the question is how to avoid destructive negative-sum behavior, whereas in the hypothetical situation you are imagining vast numbers of AIs who are doing almost all the work and don’t care about human flourishing, yet somehow trying to structure society so that it nevertheless leads to human flourishing.
Mechanism 1: Shifting horizon length in response to short-horizon tampering
Suppose I want my AI to write good code (say to help me run my business). The AI understands a lot about how to write code, how servers work, and how users behave, learned entirely from quick feedback and experimentation. Let’s say it has a human-level or even subhuman understanding of the overall business and other long-term planning.
(This example may seem a bit silly if you imagine a software-writing AI in isolation, but you should think of the same story playing out all across an economy in parallel as AI systems take on an extremely wide range of tasks.)
How do I train that system to use its understanding to write good code? Here are two simple options:
Process-based: Look at the AI’s code, have the AI explain why it made these decisions, and evaluate everything on paper.
Outcomes-based: Run the code, monitor resource usage, see what users say in the first hour after deployment.
Process-based feedback potentially handicaps my AI (even if it is only superhuman on short-horizon tasks). It’s not clear how large this advantage is, but I think our experience in practice is that “actually run your engineer’s code” is an extremely helpful technique for evaluating it in practice, and it becomes more important the better your engineers are and the less able you are to evaluate decisions they made.
So without some kind of technical progress I’m afraid we may often be pushed to use outcomes-based feedback to make our systems work better.
Unfortunately outcomes-based feedback creates an adversarial interaction between me and my AI. In addition to selecting for AIs that write good code, I’m selecting for AIs that use their short-horizon abilities to write software that covers up evidence of trouble and tampers with logs, that fakes or destroys user reports or manipulates users, and that generally messes with every mechanism we try to use to understand what’s going on. (Depending on exactly what goal the system internalized, it might also be motivated to write code that directly tampers with data fed back into the ML training process.)
Maybe we can make all of those things impossible with good enough security, so that the only way for code to look good is to actually be good. But now we are setting up a larger-scale, persistent conflict between humans and the AI systems they delegate work to. And many different AI systems could potentially all simultaneously achieve their separate short-term tasks by defecting and undermining human evaluations, making it harder to use AI evaluators to reduce the risk of tampering (or creating an increasingly unstable situation if we try to go that route).
I think small versions of sensor tampering are likely to happen and are not a big deal. I’m scared about the world where this kind of failure becomes a big pain and seriously impacts the usefulness of AI. Maybe I’d wildly guess a 40% chance that we end up with a significant problem like this if we keep building ML systems using roughly the same techniques we use today (and that those problems arise soon enough to be relevant).
There are many good things we could do to fix that problem, and in some sense it would be great news for AI alignment since we’d have a concrete technical problem to iterate on.
But there is also one very bad way we could fix this problem. We could notice incidents of tampering much later, e.g. by talking to users out-of-bound or noticing we aren’t getting return traffic or seeing that resource usage measurements were clearly faked. Then we can label those incidents as examples of wha not to do and throw that data back into the training process.
This will quickly select against policies that do this kind of short-term tampering, but it could so in two ways:
The AI learned to not to tamper with our measurements.
The AI learned to not to tamper with our measurements in any way we’d catch later.
In the second case, we’ve now created an AI with long-term goals even though all we really wanted was a short-term task, and we have a similar adversarial dynamic at a larger scale. And even if the AI has merely human-level competence at long-horizon tasks, it will still try to use its short-term competencies to prevent us from ever detecting and correcting its mistakes. If we keep training out every problem at a scale that we can correct, we will eventually be left with total failures that we can’t correct (e.g. because AI systems have permanently disempowered us).
I think it’s best to view this as a kind of overfitting: we wanted to get an AI that doesn’t do anything bad, but if we train on “did we eventually notice that it did something ad?” then we will end up with a system that is overfit to that objective. And just like with overfitting, you could also imagine it happening without explicitly training on the offending data. If 5% of AI systems have long-term goals and 95% have short-term goals, you could end up with the 95% consistently behaving badly by taking short-term opportunities to tamper with our measurements, and so we would select for the 5% with long-term goals.
My main objection to this misalignment mechanism is that it requires people/businesses/etc. to ignore the very concern you are raising. I can imagine this happening for two reasons:
A small group of researchers raise alarm that this is going on, but society at large doesn’t listen to them because everything seems to be going so well. This feels unlikely unless the AIs have an extremely high level of proficiency in hiding their tampering, so that the poor performance on the intended objective only comes back to bite the AI’s employers once society is permanently disempowered by AI. Nigh-infallibly covering up tampering sounds like a very difficult task even for an AI that is super-human. I would expect at least some of the negative downstream effects of the tampering to slip through the cracks and for people to be very alarmed by these failures.
The consensus opinion is that your concern is real, but organizations still rely on outcome-based feedback in these situations anyway because if they don’t they will be outcompeted in the short term by organizations that do. Maybe governments even try to restrict unsafe use of outcome-based feedback through regulation, but the regulations are ineffective. I’ll need to think about this scenario further, but my initial objection is the same as my objection to reason 1: the scenario requires the actual tampering that is actually happening to be covered up so well that corporate leaders etc. think it will not hurt their bottom line (either through direct negative effects or through being caught by regulators) in expectation in the future.
Which of 1 and 2 do you think is likely? And can you elaborate on why you think AIs will be so good at covering up their tampering (or why your story stands up to tampering sometimes slipping through the cracks)?
Finally, if there aren’t major problems resulting from the tampering until “AI systems have permanently disempowered us”, why should we expect problems to emerge afterwards, unless the AI systems are cooperating / don’t care about each other’s tampering?
(Am I right that this is basically the same scenario you were describing in this post? https://www.alignmentforum.org/posts/AyNHoTWWAJ5eb99ji/another-outer-alignment-failure-story)
Arguably this is already the situation with alignment. We have already observed empirical examples of many early alignment problems like reward hacking. One could make an argument that looks something like “well yes but this is just in a toy environment, and it’s a big leap to it taking over the world”, but it seems unclear when society will start listening. In analogy to the AI goalpost moving problem (“chess was never actually hard!”), in my model it seems entirely plausible that every time we observe some alignment failure it updates a few people but most people remain un-updated. I predict that for a large set of things currently claimed will cause people to take alignment seriously, most of them will either be ignored by most people once they happen, or never happen before catastrophic failure.
We can also see analogous dynamics in i.e climate change, where even given decades of hard numbers and tangible physical phenomena large amounts of people (and importantly, major polluters) still reject its existence, many interventions are undertaken which only serve as lip service (greenwashing), and all of this would be worse if renewables were still economically uncompetitive.
I expect the alignment situation to be strictly worse because a) I expect the most egregious failures to only come shortly before AGI, so once evidence as robust as climate change (i.e literally catching AIs red handed trying and almost succeeding at taking over the world), I estimate we have anywhere between a few years and negative years left b) the space of ineffectual alignment interventions is far larger and harder to distinguish from real solutions to the underlying problem c) in particular, training away failures in ways that don’t solve the underlying problems (i.e incentivizing deception) is an extremely attractive option and there does not exist any solution to this technical problem, and just observing the visible problems disappear is insufficient to distinguish whether the underlying problems are solved d) 80% of the tech for solving climate change basically already exists or is within reach, and society basically just has to decide that it cares, and the cost to society is legible. For alignment, we have no idea how to solve the technical problem, or even how that solution will vaguely look. This makes it a harder sell to society, e) the economic value of AGI vastly outweighs the value of fossil fuels, making the vested interest substantially larger, f) especially due to deceptive alignment, I expect actually-aligned systems to be strictly more expensive than unaligned systems; the cost will be more than just a fixed % more money, but also cost in terms of additional difficulty and uncertainty, time to market disadvantage, etc.
Thanks for laying out the case for this scenario, and for making a concrete analogy to a current world problem! I think our differing intuitions on how likely this scenario is might boil down to different intuitions about the following question:
To what extent will the costs of misalignment be borne by the direct users/employers of AI?
Addressing climate change is hard specifically because the costs of fossil fuel emissions are pretty much entirely borne by agents other than the emitters. If this weren’t the case, then it wouldn’t be a problem, for the reasons you’ve mentioned!
I agree that if the costs of misalignment are nearly entirely externalities, then your argument is convincing. And I have a lot of uncertainty about whether this is true. My gut intuition, though, is that employing a misaligned AI is less like “emitting CO2 into the atmosphere” and more like “employing a very misaligned human employee” or “using shoddy accounting practices” or “secretly taking sketchy shortcuts on engineering projects in order to save costs”—all of which yield serious risks for the employer, and all of which real-world companies take serious steps to avoid, even when these steps are costly (with high probability, if not in expectation) in the short term.
I expect society (specifically, relevant decision-makers) to start listening once the demonstrated alignment problems actually hurt people, and for businesses to act once misalignment hurts their bottom lines (again, unless you think misalignment can always be shoved under the rug and not hurt anyone’s bottom line). There’s lots of room for this to happen in the middle ground between toy environments and taking over the world (unless you expect lightning-fast takeoff, which I don’t).
I expect that the key externalities will be borne by society. The main reason for this is I expect deceptive alignment to be a big deal. It will at some point be very easy to make AI appear safe, by making it pretend to be aligned, and very hard to make it actually aligned. Then, I expect something like the following to play out (this is already an optimistic rollout intended to isolate the externality aspect, not a representative one):
We start observing alignment failures in models. Maybe a bunch of AIs do things analogous to shoddy accounting practices. Everyone says “yes, AI safety is Very Important”. Someone notices that when you punish the AI for exhibiting bad behaviour with RLHF or something the AI stops exhibiting bad behaviour (because it’s pretending to be aligned). Some people are complaining that this doesn’t actually make it aligned, but they’re ignored or given a token mention. A bunch of regulations are passed to enforce that everyone uses RLHF to align their models. People notice that alignment failures decrease across the board. The models don’t have to somehow magically all coordinate to not accidentally reveal deception, because even in cases where models fail in dangerous ways people chalk this up to the techniques not being perfect, but they’re being iterated on, etc. Heck, humans commit fraud all the time and yet it doesn’t cause people to suddenly stop trusting everyone they know when a high profile fraud case is exposed. And locally there’s always the incentive to just make the accounting fraud go away by applying Well Known Technique rather than really dig deep and figuring out why it’s happening. Also, a lot of people will have vested interest in not having the general public think that AI might be deceptive, and so will try to discredit the idea as being fringe. Over time, AI systems control more and more of the economy. At some point they will control enough of the economy to cause catastrophic damage, and a treacherous turn happens.
At every point through this story, the local incentive for most businesses is to do whatever it takes to make the AI stop committing accounting fraud or whatever, not to try and stave off a hypothetical long term catastrophe. A real life example that this is analogous to is antibiotic overuse.
This story does hinge on “sweeping under the rug” being easier than actually properly solving alignment, but if deceptive alignment is a thing and is even moderately hard to solve properly then this seems very likely the case.
I predict that for most operationalizations of “actually hurt people”, the result is that the right problems will not be paid attention to. And I don’t expect lightning fast takeoff to be necessary. Again, in the case of climate change, which has very slow “takeoff”, millions of people are directly impacted, and yet governments and major corporations move very slowly and mostly just say things about climate change mitigation being Very Important and doing token paper straw efforts. Deceptive alignment means that there is a very attractive easy option that makes the immediate crisis go away for a while.
But even setting aside the question of whether we should even expect to see warning signs, and whether deceptive alignment is a thing, I find it plausible that even the response to a warning sign that is as blatantly obvious as possible (an AI system tries to take over the world, fails, kills a bunch of people in the process) just results in front page headlines for a few days, some token statements, a bunch of political squabbling between people using the issue as a proxy fight for the broader “tech good or bad” narrative and a postmortem that results in patching the specific things that went wrong without trying to solve the underlying problem. (If even that; we’re still doing gain of function research on coronaviruses!)
I expect there to be broad agreement that this kind of risk is possible. I expect a lot of legitimate uncertainty and disagreement about the magnitude of the risk.
I think if this kind of tampering is risky then it almost certainly has some effect on your bottom line and causes some annoyance. I don’t think AI would be so good at tampering (until it was trained to be). But I don’t think that requires fixing the problem—in many domains, any problem common enough to affect your bottom line can also be quickly fixed by fine-tuning for a competent model.
I think that if there is a relatively easy technical solution to the problem then there is a good chance it will be adopted. If not, I expect there to be a strong pressure to take the overfitting route, a lot of adverse selection for organizations and teams that consider this acceptable, a lot of “if we don’t do this someone else will,” and so on. If we need a reasonable regulatory response then I think things get a lot harder.
In general I’m very sympathetic to “there is a good chance that this will work out,” but it also seems like the kind of problem that is not hard to mess up, and there’s enough variance in our civilization’s response to challenging technical problems that there’s a real chance we’d mess it up even if it was objectively a softball.
ETA: The two big places I expect disagreement are about (i) the feasibility of irreversible robot uprising—how sure are we that the optimal strategy for a reward-maximizing model is to do their task well? (ii) is our training process producing models that actually refrain from tampering, or are we overfitting to our evaluations and producing models that would take an opportunity for a decisive uprising if it came up? I think that if we have our act together we can most likely measure (ii) experimentally; you could also imagine a conservative outlook or various forms of penetration testing to have a sense of (i). But I think it’s just quite easy to imagine us failing to reach clarity much less agreement about this.
I take issue with the initial supposition:
How could the AI gain practical understanding of long-term planning if it’s only trained on short time scales?
Writing code, how servers work, and how users behave seen like very different types of knowledge, operating with very different feedback mechanisms and learning rules. Why would you use a single, monolithic ‘AI’ to do all three?
Existing language models are trained on the next word prediction task, but they have a reasonable understanding of the long-term dynamics of the world. It seems like that understanding will continue to improve even without increasing horizon length of the training.
Why would you have a single human employee do jobs that touch on all three?
Although they are different types of knowledge, many tasks involve understanding of all of these (and more), and the boundaries between them are fuzzy and poorly-defined such that it is difficult to cleanly decompose work.
So it seems quite plausible that ML systems will incorporate many of these kinds of knowledge. Indeed, over the last few years it seems like ML systems have been moving towards this kind of integration (e.g. large LMs have all of this knowledge mixed together in the same way it mixes together in human work).
That said, I’m not sure it’s relevant to my point.
To the second point, because humans are already general intelligences.
But more seriously, I think the monolithic AI approach will ultimately be uncompetitive with modular AI for real life applications. Modular AI dramatically reduces the search space. And I would contend that prediction over complex real life systems over long-term timescales will always be data-starved. Therefore being able to reduce your search space will be a critical competitive advantage, and worth the hit from having suboptimal interfaces.
Why is this relevant for alignment? Because you can train and evaluate the AI modules independently, individually they are much less intelligent and less likely to be deceptive, you can monitor their communications, etc.
I’m trying to understand this example. The way I would think of a software writing AI would be the following: after some pretraining we fine tune an AI on prompts explains the business task, the output being the software, and the objective related to various outcome measures.
Then we deploy it. It is not clear that we want to keep fine tuning after deployment. It does clearly raise issues of overfitting and could lead to issues such as the “blah blah blah…” example mentioned in the post. (E.g. if you’re writing the testing code for your future code, you might want to “take the hit” and write bad tests that would be easy to pass.) Also, as we mention, the more compute and data invested during training, the less we expect there to be much “on the job training”. The AI would be like a consultant that had thousands of years of software writing experience that is coming to do a particular project.
That’s roughly what I’m imagining. Initially you might fine-tune such a system to copy the kind of code a human would write, and then over time you could shift towards writing code that it anticipates to result in good outcome measures (whether by RL, or by explicit search/planning, or by decision-transfomer-style prediction of actions given consequences).
A model trained in this way will systematically produce actions that lead to highly-rewarded outcomes. And so it will learn to manipulate the sensors used to compute reward (and indeed a sophisticated model will likely be able to generalize to manipulating sensors without seeing any examples where such manipulation actually results in a higher reward).
If that happens, and if your model starts generating behavior that manipulates those sensors, then you would need to do something to fix the problem. I think it may be tempting to assign the offending behaviors a negative reward and then train on it.
I’m imagining that the deployed system continues to behave the same way it did on the training distribution, so that it makes sense to continue thinking of it as choosing actions that would lead to high reward (if the episode had occurred at training time).
If the system behaves very differently when deployed, then I expect that results in worse behavior and so would probably give us reason to keep fine-tuning on the new distribution.
Let me try to make things more concrete. We are a company that is deploying a service, in which our ultimate goal might be to maximize our profit a decade from now (or maybe more accurately, maximize people’s perception of our future profit, which corresponds to our current stock price...).
My take is that while the leaders of the company might chart a strategy towards this far-off goal, they would set concrete goals for the software developers which correspond to very clear metrics. That is, the process of implementing a new feature for the service would involve the following steps:
Proposing the feature, and claiming which metric it would improve (e.g., latency on the website, click-through rate for ads, satisfaction with service, increasing users, etc...). Crucially, these metrics are simple and human-interpretable, since the assumption is that in a chaotic world, we cannot have “3D chess” type of strategies, and rather each feature should make some clear progress in some measure.
Writing code for the feature.
Reviewing and testing the code.
Deploying it (possibly with A/B testing)
Evaluating the deployment
AIs might be involved in all of these steps, but it would not be one coherent AI that does everything and whose goal is to eventually make the managers happy. Just as today we have different people doing these roles, so would different AIs be doing each one of these roles, and importantly, each one of them would have its own objective function that they are trying to maximize.
So, each one of these components would be separately, and in some sense trained adversarially (e.g., testing AI would be trained to maximize bugs found, while code writing AI would be trained to minimize them). Moreover, each one of them would be trained on its own giant corpus of data. If they are jointly trained (like in GANs) then indeed care must be taken that they are not collapsing into an undesirable equilibrium, but this is something that is well understood.
I agree that we will likely build lots of AI systems doing different things and checking each other’s work. I’m happy to imagine each such system optimizes short-term “local” measures of performance.
One reason we will split up tasks into small pieces is that it’s a natural way to get work done, just as it is amongst humans.
But another reason we will split it up is because we effectively don’t trust any of our employees even a little bit. Perhaps the person responsible for testing the code gets credit for identifying serious problems, and so they would lie if they could get away with it (note that if we notice a problem later and train on it, then we are directly introducing problematic longer-term goals).
So we need a more robust adversarial process. Some AI systems will be identifying flaws and trying to explain why they are serious, while other AI systems are trying to explain why those tests were actually misleading. And then we wonder: what are the dynamics of that kind of game? How do they change as AI systems develop kinds of expertise that humans lack (even if it’s short-horizon expertise)?
To me it seems quite like the situation of humans who aren’t experts in software or logistics trying to oversee a bunch of seniors software engineers who are building Amazon. And the software engineers care only about looking good this very day, they don’t care about whether their decisions look bad in retrospect. So they’ll make proposals, and they will argue about them, and propose various short-term tests to evaluate each other’s work, and various ways to do A/B tests in deployment...
Would that work? I think it depends on exactly how large the gap is between the AIs and the humans. I think that evidence from our society is not particularly reassuring in cases where the gap is large. I think that when we get good results it’s because we can build up trust in domain experts over long time periods, not because a layperson would have any chance at all of arbitrating a debate between two senior Amazon engineers.
I think all of that remains true even if you split up the job of the Amazon engineers, and even if all of their expertise comes from LM-style training primarily on short-term objectives (like building abstractions that let them reason about how code will work, when servers fail, etc.).
I’m excited about us building this kind of minimal-trust machine and getting experience with how well it works. And I’m fairly optimistic (though far from certain!) about it scaling beyond human level. And I agree that it’s made easier by the fact that AI systems will mostly be good at short-horizon tasks while humans can remain competitive longer for big-picture questions . But I think it’s really unclear exactly when and how far it works, and we need to do research to both predict and improve such mechanisms. (Though I’m very open to that research occurring mostly looking very boring and not being directly motivated by AI risk.)
Overall my reaction may depend on what you’re claiming. If you are saying “75% chance this isn’t a problem, if we build AI in the current paradigm” then I’m on board; if you are saying 90% then I disagree but think that’s plausible and it may depend exactly what you mean by “isn’t a problem”; if you are saying 99% then I think that’s hard to defend.
It seems like each of them will be trained to do its job, in a world where other jobs are being done by other AI. I don’t think it’s realistic to imagine training them separately and then just hoping they work well together as a team.
I don’t agree that this well understood. The dynamics of collapse are very different from in GANs, and depend on exactly how task decomposition works, and on how well humans can evaluate performance of one AI given adversarial interrogation and testing by another, and so on.
(Even in the case of GANs it is not that well understood—if the situation was just “if there is a mode collapse in this GAN then we die, but fortunately this is understood well enough that we’ll definitely be able to fix that problem when we see it happening” then I don’t think you should rest that easy, and I’d still be interested to do a lot of research on mode collapse in GANs.)
Thanks! Some quick comments (though I think at some point we are getting to deep in threads that it’s hard to keep track..)
When saying that GAN training issues are “well understood” I meant that it is well understood that it is a problem, not that it’s well understood how to solve that problem…
One basic issue is that I don’t like to assign probabilities to such future events, and am not sure there is a meaningful way to distinguish between 75% and 90%. See my blog post on longtermism.
The general thesis is that when making long-term strategies, we will care about improving concrete metrics rather than thinking of very complex strategies that don’t make any measurable gains in the short term. So an Amazon Engineer would need to say something like “if we implement my code X then it would reduce latency by Y”, which would be a fairly concrete and measurable goal and something that humans could understand even if they couldn’t understand the code X itself or how it came up with it. This differs from saying something like “if we implement my code X, then our competitors would respond with X’, then we could respond with X″ and so on and so forth until we dominate the market”
When thinking of AI systems and their incentives, we should separate training, fine tuning, and deployment. Human engineers might get bonuses for their performance on the job, which corresponds to mixing “fine tuning” and “deployments”. I am not at all sure that would be a good idea for AI systems. It could lead to all kinds of over-optimization issues that would be clear for people without leading to doom. So we might want to separate the two and in some sense keep the AI disinterested about the code that it actually uses in deployment.
I would like to see evidence that BigGAN scaling doesn’t solve it, and that Brock’s explanation of mode-dropping as reflecting lack of diversity inside minibatches is fundamentally wrong, before I went around saying either “we understand it” (because few seem to ever bring up the points I just raised) or “it’s unsolved” (because I see no evidence from large-scale GAN work that it’s unsolved).
Can you send links? In any case I do believe that it is understood that you have to be careful in a setting where you have two models A and B, where B is a “supervisor” of the output of A, and you are trying to simultaneously teach B to come up with good metric to judge A by, and teach A to come up with outputs that optimize B’s metric. There can be equilibriums where A and B jointly diverge from what we would consider “good outputs”.
This for example comes up in trying to tackle “over optimization” in instructGPT (there was a great talk by John Schulman in our seminar series a couple of weeks ago), where model A is GPT-3, and model B tries to capture human scores for outputs. Initially, optimizing for model B induces optimizing for human scores as well, but if you let model A optimize too much, then it optimizes for B but becomes negatively correlated with the human scores (i.e., “over optimizes”).
Another way to see this issue is even for powerful agents like AlphaZero are susceptible to simple adversarial strategies that can beat them: see “Adversarial Policies Beat Professional-Level Go AIs” and “Are AlphaZero-like Agents Robust to Adversarial Perturbations?”.
The bottom line is that I think we are very good at optimizing any explicit metric M, including when that metric is itself some learned model. But generally, if we learn some model A s.t. A(y)≈M(y), this doesn’t mean that if we let B(x)=argmaxA(y) then it would give us an approximate maximizer of M(y) as well. Maximizing A would tend to push to the extreme parts of the input space, which would be exactly those where A deviates from M.
The above is not an argument against the ability to construct AGI as well, but rather an argument for establishing concrete measurable goals that our different agents try to optimize, rather than trying to learn some long-term equilibrium. So for example, in the software-writing and software-testing case, I think we don’t simply want to deploy two agents A and B playing a zero-sum game where B’s reward is the number of bugs found in A’s code.
http://arxiv.org/abs/1809.11096.pdf#subsection.4.1 http://arxiv.org/abs/1809.11096.pdf#subsection.4.2 http://arxiv.org/abs/1809.11096.pdf#subsection.5.2 https://www.gwern.net/Faces#discriminator-ranking https://www.gwern.net/GANs
Sure. And the GPT-2 adversarial examples and overfitting were much worse than the GPT-3 ones.
The meaning of that one is in serious doubt so I would not link it.
(The other one is better and I had not seen it before, but my first question is, doesn’t adding those extra stones create board states that correspond to board states that the agent would never reach following its policy, or even literally impossible board states, because those stones could not have been played while still yielding the same captured-stone count and board positions etc? The approach in 3.1 seems circular.)
Will read later the links—thanks! I confess I didn’t read the papers (though saw a talk partially based on the first one which didn’t go into enough details for me to know the issues) but also heard from people that I trust of similar issues with Chess RL engines (can be defeated with simple strategies if you are looking for adversarial ones). Generally it seems fair to say that adversarial robustness is significantly more challenging than the non adversarial case and it does not simply go away on its own with scale (though some types of attacks are automatically motivated with diversity of training data / scenarios).
I don’t think we know that. (How big is KataGo anyway, 0.01b parameters or so?) We don’t have much scaling research on adversarial robustness, what we do have suggests that adversarial robustness does increase, the isoperimetry theory claims that scaling much larger than we currently do will be sufficient (and may be necessary), and the fact that a staggeringly large adversarial-defense literature has yet to yield any defense that holds up longer than a year or two before an attack cracks it & gets added to Clever Hans suggests that the goal of adversarial defenses for small NNs may be inherently impossible (and there is a certain academic smell to adversarial research which it shares with other areas that either have been best solved by scaling, or, like continual learning, look increasingly like they are going to be soon).
I don’t think it’s fair to compare parameter sizes between language models and models for other domains, such as games or vision. E.g., I believe AlphaZero is also only in the range of hundreds of millions of parameters? (quick google didn’t give me the answer)
I think there is a real difference between adversarial and natural distribution shifts, and without adversarial training, even large network struggle with adversarial shifts. So I don’t think this is a problem that would go away with scale alone. At least I don’t see evidence for it from current data (failure of defenses for small models is no evidence of success of size alone for larger ones).
One way to see this is to look at the figures in this plotting playground of “accuracy on the line”. This is the figure for natural distribution shift—the green models are the ones that are trained with more data, and they do seem to be “above the curve” (significantly so for CLIP, which are the two green dots reaching ~ 53 and ~55 natural distribution accuracy compared to ~60 and ~63 vanilla accuracy
In contrast, if you look at adversarial perturbations, then you can see that actual adversarial training (bright orange) or other robustness interactions (brown) is much more effective than more data (green) which in fact mostly underperform.
(I know you focused on “more model” but I think to first approximation “more model” and “more data” should have similar effects.)
I suppose you’re talking about this paper (https://arxiv.org/abs/2210.10760). It’s important to note that in the setting of this paper, the reward model is only trained on samples from the original policy, whereas GAN discriminators are constantly trained with new data. Section 4.3 touches briefly on the iterated problems, which is closer in setting to GANs, where we correspondingly expect a reduction in overoptimization (i.e the beta term).
It is definitely true that you have to be careful whenever you’re optimizing any proxy metric, and this is one big reason I feel kind of uncomfortable about proposals like RLHF/RRM. In fact, our setting probably underestimates the amount of overoptimization due to the synthetic setup. However, it does seem like GAN mode collapse is largely unrelated to this effect of overoptimization, and it seems like gwern’s claim is mostly about this.
Mechanism 2: deceptive alignment
Suppose that during training my AI system had some arbitrary long-term goal. Many long-term goals would be best-served if the deployed AI system had that same goal. And so my AI is motivated to get a low loss, so that gradient descent won’t change its goals.
As a result, a very wide range of long-term goals will lead to competent loss-minimizing behavior. On the other hand, there is a very narrow range of short-term goals that lead to competent loss-minimizing behavior: “minimize the loss.”
So gradient descent on the short-term loss function can easily push towards long-term goals (in fact it would both push towards the precise short-term goals that result in low loss and arbitrary long-term goals, and it seems like a messy empirical question which one you get). This might not happen early in training, but eventually our model is competent enough to appreciate these arguments and perhaps for it to be extremely obvious to it that it should avoid taking actions that would be penalized by training.
It doesn’t seem like there are any behavioral checks we can do to easily push gradient descent back in the other direction, since an agent that is trying to get a low loss will always just adopt whatever behavior is best for getting a low loss (as long as it thinks it is on the training distribution).
This all is true even if my AI has subhuman long-horizon reasoning. Overall my take is maybe that there is a 25% chance that this becomes a serious issue soon enough to be relevant to us and that is resistant to simple attempts to fix it (though it’s also possible we will fail to even competently implement simple fixes). I expect to learn much more about this as we start engaging with AI systems intelligent enough for it to be a potential issue over the next 5-10 years.
This issue is discussed here. Overall I think it’s speculative but plausible.
I agree that this sort of deceptive misalignment story is speculative but a priori plausible. I think it’s very difficult to reason about these sorts of nuanced inductive biases without having sufficiently tight analogies to current systems or theoretical models; how this will play out (as with other questions of inductive bias) probably depends to a large extent on what the high-level structure of the AI system looks like. Because of this, I think it’s more likely than not that our predictions about what these inductive biases will look like are pretty off-base. That being said, here are the first few specific reasons to doubt the scenario which come to mind right now:
If the system is modular, such that the part of the system representing the goal is separate from the part of the system optimizing the goal, then it seems plausible that we can apply some sort of regularization to the goal to discourage it from being long term. It’s imaginable that the goal is a mesa-objective which is mixed in some inescapably non-modular way with the rest of the system, but then it would be surprising to me if the system’s behavior could really best be best characterized as optimizing this single objective; as opposed to applying a bunch of heuristics, some of which involve pursuing mesa-objectives and some of which don’t fit into that schema—so perhaps framing everything the agent does in terms of objectives isn’t the most useful framing (?).
If an agent has a long-term objective, for which achieving the desired short-term objective is only instrumentally useful, then in order to succeed the agent needs to figure out how to minimize the loss by using its reasoning skills (by default, within a single episode). If, on the other hand, the agent has an appropriate short-term objective, then the agent will learn (across episodes) how to minimize the loss through gradient descent. I expect the latter scenario to typically result in better loss for statistical reasons, since the agent can take advantage of more samples. (This would be especially clear if, in the training paradigm of the future, the competence of the agent increases during training.)
(There’s also the idea of imposing a speed prior; not sure how likely that direction is to pan out.)
Perhaps most crucially, for us to be wrong about Hypothesis 2, deceptive misalignment needs to happen extremely consistently. It’s not enough for it to be plausible that it could happen often; it needs to happen all the time.
What kind of regularization could this be? And are you imagining an AlphaZero-style system with a hardcoded value head, or an organically learned modularity?
I think the situation is much better if deceptive alignment is inconsistent. I also think that’s more likely, particularly if we are trying.
That said, I don’t think the problem goes away completely if deceptive alignment is inconsistent. We may still have limited ability to distinguish deceptively aligned models from models that are trying to optimize reward, or we may find that models that are trying to optimize reward are unsuitable in practice (e.g. because of the issues raised in mechanism 1) and so selecting for things that works means you are selecting for deceptive alignment.
Thank you for the insightful comments!! I’ve added thoughts on Mechanisms 1 and 2 below. Some reactions to your scattered disagreements (my personal opinions; not Boaz’s):
I agree that extracting short-term modules from long-term systems is more likely than not to be extremely hard. (Also that we will have a better sense of the difficulty in the nearish future as more researchers work on this sort of task for current systems.)
I agree that the CEO point might be the weakest in the article. It seems very difficult to find high-quality evidence about the impact of intelligence on long-term strategic planning in complex systems, and this is a major source of my uncertainty about whether our thesis is true. Note that even if making CEOs smarter would improve their performance, it may still be the case that any intelligence boost is fully substitutable by augmentation with advanced short-term AI systems.
From published results I’ve seen (e.g. comparison of LSTMs vs Transformers in figure 7 of Kaplan et al., effects of architecture tweaks in other papers such as this one), architectural improvements (R&D) tend to have only a minimal effect on the exponent of scaling power laws; so the differences in the scaling laws could hypothetically be compensated for by increasing compute by a multiplicative constant. (Architecture choice can have a more significant effect on factors like parallelizability and stability of training.) I’m very curious whether you’ve seen results that suggest otherwise (I wouldn’t be surprised if this were the case, the examples I’ve seen are very limited, and I’d love to see more extensive studies), or whether you have more relevant intuition/evidence for there being no “floor” to hypothetically achievable scaling laws.
I agree that our argument should result in a quantitative adjustment to some folk’s estimated probability of catastrophe, rather than ruling out catastrophe entirely, and I agree that figuring out how to handle worst-case scenarios is very productive.
When you say “the AI systems charged with defending humans may instead join in to help disempower humanity”, are you supposing that these systems have long-term goals? (even more specifically, goals that lead them to cooperate with each other to disempower humanity?)
I usually think of the effects of R&D as multiplicative savings in compute, which sounds consistent with what you are saying.
For example, I think a conservative estimate might be that doubling R&D effort allows you to cut compute by a factor of 4. (The analogous estimate for semiconductor R&D is something like 30x cost reduction per 2x R&D increase.) These numbers are high enough to easily allow explosive growth until the returns start diminishing much faster.
Yes. I mean that if we have alignment problems such that all the most effective AI systems have long-term goals, and if all of those systems can get what they want together (e.g. because they care about reward), then to predict the outcome we should care about what would happen in a conflict between (those AIs) vs (everyone else).
So I expect in practice we need to resolve alignment problems well enough that there are approximately competitive systems without malign long-term goals.
Would you agree that the current paradigm is almost in direct contradiction to long-term goals? At the moment, to a first approximation, the power of our systems is proportional to the logarithm of their number of parameters, and again to a first approximation, we need to take a gradient step per parameter in training. So what it means is that if we have 100 Billion parameters, we need to make 100 Billion iterations where we evaluate some objective/loss/reward value and adapt the system accordingly. This means that we better find some loss function that we can evaluate on a relatively time-limited and bounded (input, output) pair rather than a very long interaction.
I agree with something similar, but not this exact claim.
I think this provides a headwind that makes AIs worse at complex skills where performance can only be evaluated over long horizons. But it’s not a strong argument against pursuing long-horizon goals or any simple long-horizon behaviors.(Superhuman competence at long horizon tasks doesn’t seem necessary for either of the mechanisms I’m suggesting.)
In particular, systems trained on lots of short-horizon datapoints can still learn a lot about how the world works at larger timescales. For example, existing LMs understand quite a bit about longer-horizon dynamics of the world despite being trained on next-token prediction. Such systems can make reasonable judgments about what actions would lead to effects in the longer run. As a result I’d expect smart systems can be quickly fine-tuned to pursue long-horizon goals (or might pursue them organically), even though they don’t have any complex cognitive abilities that don’t help improve loss on the short-horizon pre-training task.
Note that people concerned about AI safety often think about this concept under the same heading of horizon length. A relatively common view is that training cost scales roughly linearly with horizon length and so AI systems will be relatively bad at long-horizon tasks (and perhaps the timeline to transformative AI may be longer than you would think based on extrapolations from competent short-horizon behavior).
There are a few dissenting views: (i) almost all long-horizon tasks have rich feedback over short horizons if you know what to look for, so in practice things that feel like “long-horizon” behaviors aren’t really, (ii) although AI systems will be worse at long-horizon tasks, so are humans and so it’s unlikely to be a major comparative advantage for AIs, most of the things we think of as sophisticated long-horizon behavior are just short-horizon cognitive behaviors (like carrying out reasoning or iterating on plans) applied to a question about long-horizons.
(My take is that most planning and “3d chess” is basically short-horizon behavior applied to long-horizon questions, but there is an important and legitimate question about how much cognitive work like “forming new concepts” or “organizing information in your head” or “coming to deeply understand an area” effectively involves longer horizons.)
Are you making a forecast about the inability of AIs in, say, 2026 to operate mostly autonomously for long periods in diverse environments, fulfilling goals? I’d potentially be interested to place bets with you if so.
My forecast would be that an AI that operates autonomously for long periods would be composed of pieces that make human-interpretable progress in the short term. For example, a self-driving car will be able to eventually to drive to New York to Los Angeles, but I believe it would do so by decomposing the task into many small tasks of getting from point A to B. It would not do so by sending it out to the world (or even a simulated world) and repeatedly playing a game where it gets a reward if it reaches Los Angeles, and gets nothing if it doesn’t.
That sounds very different to me from “the current paradigm is almost in direct contradiction to long-term goals.” Maybe we agree after all. Possible remaining differences between us: Are you imagining 0 end-to-end training of the system, or just a small amount? For example, consider WebGPT and OpenAI’s more recent Minecraft agent. They were trained for many steps with unsupervised learning and then fine-tuned for a bit with end-to-end RL, if I recall correctly. Are you saying that insofar as AI opererates autonomously for more than, say, 100,000 serial forward passes, it’ll involve 0 end-to-end training? If so then I’d disagree and say it’ll probably involve some.
Probably our disagreements have more to do with how human-interpretable the resulting systems will be and how well-described they’ll be as having long-term goals. I’m bearish on the first and bullish on the second. (Note that I think they’ll mostly have short-term goals, like humans. But like humans, they’ll have at least some long-term goals.)
My high-level take on this disagreement:
If you train a system to accomplish tasks by taking a large number of small human-like steps, and then you finetune the system “a bit” based on actually achieving the goal, I think you will mostly get systems that pursue goals by taking human-like short-term steps but do so more competently. They will do things like avoiding strategies that don’t work in practice for them, and having better intuitions about how to select amongst many possible options; they won’t do things like carrying out long-term plans that aren’t made out of human-legible short-term steps.
I think that:
If these systems already understand a lot of human-illegible stuff, they might quickly start using it when fine-tuned and that may not always result in changes to legible plans.
If these systems start taking plans that achieve the goals in ways that humans don’t like, and then we fine-tune based on individual plan steps (while continuing to select for success), then we you are likely to train the system to obfuscate its scheme.
If you train long enough end-to-end you will get novel behaviors that can be scarier, although I think the computational cost for doing so may be very large
And overall I think there are enough threat models that we should be worried, and should try to develop machinery so that we don’t need to do the kind of training that could result in doom. But I also think the most likely scenario is more along the lines of what the OP is imagining, and we can stay significantly safer by e.g. having consensus at ML labs that #2 is likely to be scary and should be considered unacceptable. Ultimately what’s most important is probably understanding how to determine empirically which world you are in.
This is a bit of an unrelated aside, but I don’t think it’s so clear that “power” is logarithmic (or what power means).
One way we could try to measure this is via something like effective population. If N models with 2M parameters are as useful as kN models with M parameters, what is k? In cases where we can measure I think realistic values tend to be >4. That is, if you had a billion models with N parameters working together in a scientific community, I think you’d get more work out of 250 million models with 2N parameters, and so have great efficiency per unit of compute.
There’s still a question of how e.g. scientific output scales with population. One way you can measure it is by asking “If N people working for 2M years, is as useful as kN people working for M years, what is k?” where I think that you also tend to get numbers in the ballpark of 4, though this is even harder to measure than the question about models. But I think most economists would guess this is more like root(N) than log(N).
That still leaves the question of how scientific output scales with time spent thinking. In this case it seems more like an arbitrary choice of units for measuring “scientific output.” E.g. I think there’s a real sense in which each improvement to semiconductors takes exponentially more effort than the unit before. But the upshot of all of that is that if you spend 2x as many years, we expect to be able to build computers that are >10x more efficient. So its’ only really logarithmic if you measure “years of input” on a linear scale but “efficiency of output” on a logarithmic scale. Other domains beyond semiconductors grow less explosively quickly, but seem to have qualitatively similar behavior. See e.g. are ideas getting harder to find?
Quick comment (not sure it’s realted to any broader points): total compute for N models with 2M parameters is roughly 4NM^2 (since per Chinchilla, number of inference steps scales linearly with model size, and number of floating point operations also scales linearly, see also my calculations here). So an equal total compute cost would correspond to k=4.
What I was thinking when I said “power” is that it seems that in most BIG-Bench scales, if you put the y axis some measure of performance (e.g. accuracy) then it seems to scale as some linear or polynomial way in the log of parameters, and indeed I belive the graphs in that paper usually have log parameters in the X axis. It does seem that when we start to saturate performance (error tends to zero), the power laws kick in, and its more like inverse polynomial in the total number of parameters than their log.
Thanks for your comments! Some quick responses:
I agree that extracting short-term modules from long-term modules is very much an open question. However, it may well be that our main problem would be the opposite: the systems would be trained already with short-term goals, and so we just want to make sure that they don’t accidentally develop a long-term goal in the process (this may be related to your mechanisms posts, which I will respond to separately)
I do think that there is a sense in which, in a chaotic world, some “greedy” or simple heuristics end up to be better than ultra complex ones. In Chess you could sacrifice a Queen in order to get some advantage much later on, but in business, while you might sacrifice one metric (e.g., profit) to maximize another (e.g. growth), you need to make some measurable progress. If we think of cognitive ability as the ability to use large quantities of data and perform very long chains of reasonings on them, then I do believe these are more needed for scientists or engineers than for CEOs. (In an earlier draft we also had another example for the long-term benefits of simple strategies: the fact that the longest-surviving species are simple ones such as cockroaches, crocodiles etc. , but Ben didn’t like it :) )
I agree deterrence is very problematic, but prevention might be feasible. For example, while AI would greatly increase the capabilities for hacking, it would also increase the capabilities to harden our systems. In general, I find research on prevention to be more attractive than alignment since it also applies to the scenario (more likely in my view) of malicious humans using AI to cause massive harm. It also doesn’t require us to speculate about objects (long-term planning AIs) that don’t yet exist.
I agree that’s a plausible goal, but I’m not convinced it will be so easy. The current state of our techniques is quite crude and there isn’t an obvious direction for being able to achieve this kind of goal.
(That said, I’m certainly not confident it’s hard, and there are lots of things to try—both at this stage and for other angles of attack. Of course this is part of how I end up more like 10-20% risk of trouble than a 80-90% risk of trouble.)
I agree with this. I think cybersecurity is an unusual domain where it is particularly plausible that “defender wins” even given a large capability gap (though it’s not the case right now!). I’m afraid there is more attack surface that are harder to harden. But I do think there’s a plausible gameplan here that I find scary but that even I would agree can at least delay trouble.
I think there is agreement that this scenario is more likely, the question is about the total harm (and to a lesser extent about how much concrete technical projects might reduce that risk). Cybersecurity improvements unquestionably have real social benefits, but cybersecurity investment is 2-3 orders of magnitude larger than AI alignment investment right now. In contrast, I’d argue that believe the total expected social cost of cybersecurity shortcomings is maybe an order of magnitude lower than alignment shortcomings, and I’d guess that other reasonable estimates for the ratio should be within 1-2 orders of magnitude of that.
If we were spending significantly more on alignment than cybersecurity, then I would be quite sympathetic to an argument to shift back in the other direction.
Research on alignment can focus on existing models—understanding those models, or improving their robustness, or developing mechanisms to oversee them in domains where they are superhuman, or so on. In fact this is a large majority of alignment research weighted by $ or hours spent.
To the extent that this research is ultimately intended to address risks that are distinctive to future AI, I agree that there is a key speculative step. But the same is true for research on prevention aimed to address risks from future AI. And indeed my position is that work on prevention will only modestly reduce these risks. So it seems like the situation is somewhat symmetrical: in both cases there are concrete problems we can work on today, and a more speculative hope that these problems will help address future risks.
Of course I’m also interested in theoretical problems that I expect to be relevant, which is in some sense more speculative (though in fairness I did spend 4 years doing experimental work at OpenAI). But on the flipside, I think it’s clear that there are plausible situations where standard ML approaches would lead to catastrophic misalignment, and we can study those situations whether or not they will occur in the real world. (Just as you could study cryptography in a computational regime that or may not ever become relevant in practice, based on a combination of “maybe it will” and “maybe this theoretical investigation will yield insight more relevant to realistic regimes.”)
As you probably imagine given my biography :) , I am never against any research, and definitely not for reasons of practical utility. So am definitely very supportive of research on alignment, and not claiming that it shouldn’t be done. In my view, one of the interesting technical questions is to what extent can long-term goals emerge from systems trained with short-term objectives, and (if it happens) whether we can prevent this while still keeping short-term performance as good. One reason I like the focus on the horizon rather than alignment with human values is that the former might be easier to define and argue about. But this doesn’t mean that we should not care about the latter.
I definitely think it’s interesting to understand and control whether a model is pursuing a long-horizon goal (though talking about the “goal” of a model seems quite slippery).
I think that most work on alignment doesn’t need to get into the difficulties of defining or arguing about human values. I’m normally focused more on goals like: “does my AI make statements that it knows to be unambiguously false?” (see ELK).
There’s a few, for example the classic “Are CEOs Born Leaders?” which uses the same Swedish data and finds a linear relationship of cognitive ability with both log company assets and log CEO pay, though it also concludes that the effect isn’t super large. The main reason there aren’t more is that we generally don’t have good cognitive data on most CEOs. (There are plenty of studies looking at education attainment or other proxies.) You can see this trend in the Dal Bo et al Table cited in the main post as well.
(As an aside, I’m a bit worried about the Swedish dataset, since the cognitive ability of Swedish large-firm CEOs is lower than Herrnstein and Murray (1996)’s estimated cognitive ability of 12.9 million Americans in managerial roles. Maybe something interesting happens with CEOs in Sweden?)
It is very well established that certain CEOs are consistently better than others, i.e. CEO level fixed effects matter significantly to company performance across a broad variety of outcomes.
IIUC the thesis of this article rest on several interrelated claims:
Long-term planning is not useful because of chaos
Short-term AIs have no alignment problem
Among humans, skill is not important for leadership, beyond some point
Human brains have an advantage w.r.t. animals because of “universality”, and any further advantage can only come from scaling with resources.
I wish to address these claims one by one.
Claim 1
This is an erroneous application of chaos theory IMO. The core observation of chaos theory is, that in many dynamical systems with compact phase space, any distribution converges (in the Kantorovich-Rubinstein sense) to a unique stationary distribution. This means that small measurement errors lead to large prediction errors, and in the limit no information from the initial condition remains.
However, real-world dynamical systems are often not compact in the relevant approximation. In particular, acquisition of resources and development of new technologies are not bounded from above on a relevant scale. Indeed, trends in GDP growth and technological progress continue over long time scales and haven’t converged, so far, to a stationary distribution. Ultimately, these quantities are also bounded for physical / information-theoretic / complexity-theoretic reasons, but since humanity is pretty far from saturating them, this leaves ample room for AI to have a long-term planning advantage over humanity.
Claim 2
Although it is true that, for sufficiently short-term planning horizons, AIs have less incentives to produce unintended consequences, problems remain.
One problem is that some tasks are very difficult to specify. For example, suppose that a group of humans armed with short-term AIs is engaged in cyberwarfare against a long-term AI. Then, even if every important step in the conflict can be modeled as short-term optimization, specifying the correct short-term goal can be a non-trivial task (how do you define “to hack” or “to prevent from hacking”?) that humans can’t easily point their short-term AI towards.
Moreover, AIs trained on short-term objectives can still display long-term optimization out-of-distribution. This is because a long-term optimizer that is smart enough to distinguish between training and deployment can behave according to expectations during training while violating them as much as it wants when it’s either outside of training or the correcting outer loop is too slow to matter.
Claim 3
This claim flies so much in the face of common sense (is there no such thing as business acumen? charisma? military genius?) that it needs a lot more supporting evidence IMO. The mere fact that IQs of e.g. CEOs are only moderately above average and not far above average only means that IQ stops to be a useful metric at that range, since beyond some point, different people have cognitive advantages in different domains. I think that, as scientists, we need to be careful of cavalierly dismissing the sort of skills we don’t have.
As to the skepticism of the authors about social manipulation, I think that anyone who studied history or politics can attest that social manipulation has been used, and continues to be used, with enormous effects. (Btw, I think it’s probably not that hard to separate a dog from a bone or child from a toy if you’re willing to e.g. be completely ruthless with intimidation.)
Claim 4
While it might be true that there is a sense in which human brains are “qualitatively optimal”, this still leaves a lot of room for quantitative advantage, similar to how among two universal computers, one can be vastly more efficient than the other for practical purposes. As a more relevant analogy, we can think of two learning algorithms that learn the same class of hypotheses while still having a significant difference in computational and/or sample efficiency. In the limit of infinite resources and data, both algorithms converge to the same results, but in practice one still has a big advantage over the other. While undoubtedly there are hard limits to virtually every performance metric, there is no reason to believe evolution brought human brains anywhere near those limits. Furthermore, even if “scaling with resources” is the only thing that matters, the ability of AI to scale might be vastly better than the ability of humans to scale because of communication bandwidth bottlenecks between humans, not to mention the limited trust humans have towards one another (as opposed to large distributed AI systems, or disparate AI systems that can formally verify each other’s trustworthiness).
Hi Vanessa,
Let me try to respond (note the claim numbers below are not the same as in the essay, but rather as in Vanessa’s comment):
Claim 1: Our claim is that one can separate out components—there is the predictable component which is non stationary, but is best approximated with a relatively simple baseline, and the chaotic component, which over the long run is just noise.In general, highly complex rules are more sensitive to noise (in fact, there are theorems along these lines in the field of Analysis of Boolean Functions), and so in the long run, the simpler component will dominate the accuracy.
Claim 2: Hacking is actually a fairly well-specified endeavor. People catalog, score, and classify security vulnerabilities. To hack would be to come up with a security vulnerability, and exploit code, which can be verified. Also, you seem to be envisioning a long-term AI that is then fine-tuned on a short-term task, but how did it evolve these long-term goals in the first place?
Claim 3: I would not say that there is no such thing as talent in being a CEO or presidents. I do however believe that the best leaders have been some combination of their particular characteristics and talents, and the situation they were in. Steve Jobs has led Apple to become the largest company in the world, but it is not clear that he is a “universal CEO” that would have done as good in any company (indeed he failed with NeXT). Similarly, Abraham Lincoln is typically ranked as the best U.S. president by historians, but again I think most would agree that he fit well the challenge that he had to face, rather than being someone that would have just as well handled the cold war or the 1970s energy crisis. Also, as Yafah points elsewhere here, for people to actually trust an AI with being the leader of a company or a country, it would need to not just be as good as humans or a little better, but better by a huge margin. In fact, most people’s initial suspicion is that AIs (or even humans that don’t look like them) is not “aligned” with their interests, and if you don’t convince them otherwise, their default would be to keep them from positions of power.
Claim 4: The main point is that we need to measure the powers of a system as a whole, not compare the powers of an individual human with an individual AI. Clearly, if you took a human, made their memory capacity 10 times bigger, and made their speed 10 times faster, then they could do more things. But we are comparing with the case that humans will be assisted with short-term AIs that would help them in all of the tasks that are memory and speed intensive.
Thanks for the responses Boaz!
I will look into analysis of boolean functions, thank you. However, unless you want to make your claim more rigorous, it seems suspect to me.
In reality, there are processes happening simultaneously on many different timescales, from the microscopic to the cosmological. And, these processes are coupled, so that the current equilibrium of each process can be regarded as a control signal for the higher timescale processes. This means we can do long-term planning by starting from the long timescales and back-chaining to short timescales, like I began to formalize here.
So, while eventually the entire universe reaches an equilibrium state (a.k.a. heat-death), there is plenty of room for long-term planning before that.
Yeeees, it does seem like hacking is an especially bad example. But even in this example, my position is quite defensible. Yes, theoretically you can formally specify the desired behavior of the code and verify that it always happens. But, there are two problems with that: First, for many realistic software system, the formal specification would require colossal effort. Second, the formal verification is only as good as the formal model. For example, if the attacker found a hardware exploit, while your model assumes idealized behavior for the hardware, the verification doesn’t help. And, it domains outside software the situation is much worse: how do you “verify” that your biological security measures are fool-proof, for example?
When you’re selecting for success on a short-term goal you might inadvertently produce a long-term agent (which, on the training distribution, is viewing the short-term goal as instrumental for its own goals), just like how evolution was selecting for genetic fitness but ended up producing agents with many preferences unrelated to that. More speculatively, there might be systematic reasons for such agents to arise, for example if good performance in the real-world requires physicalist epistemology which comes with inherent “long-terminess”.
This sounds like a story you can tell about anything. “Yes, such-and-such mathematician proved a really brilliant theorem A, but their effort to make progress in B didn’t amount to much.” Obviously, real-world performance depends on circumstances and not only on talent. This is doubly true in a competitive setting, where other similarly talented people are working against you. Nevertheless, a sufficiently large gap in talent can produce very lopsided outcomes.
First, it is entirely possible the AI will be better by a huge margin, because like with most things, there’s no reason to believe evolution brought us anywhere near the theoretical optimum on this. (Yes, there was selective pressure, but no amount of selective pressure allowed evolution to invent spaceships, or nuclear reactors, or even the wheel.) Second, what if the AI poses as a human? Or, what if the AI uses a human as a front while pulling the strings behind the scenes? There will be no lack of volunteers to work as such a front, if in the short-term them it brings them wealth and status. Also, ironically, the more successful AI risk skeptics are at swaying public opinion, the easier the AIs job is and the weaker their argument becomes.
Alright, I can see how the “universality” argument makes sense if you believe that “human + short-term AI = scaled-up human”. The part I doubt is that this equation holds for any easy-to-specify value of “short-term AI”.
Hi Vanesssa,
Perhaps given my short-term preference, it’s not surprising that I find it hard to track very deep comment threads, but let me just give a couple of short responses.
I don’t think the argument on hacking relied on the ability to formally verify systems. Formally verified systems could potentially skew the balance of power to the defender side, but even if they don’t exist, I don’t think balance is completely skewed to the attacker. You could imagine that, like today, there is a “cat and mouse” game, where both attackers and defenders try to find “zero day vulnerabilities” and exploit (in one case) or fix (in the other). I believe that in the world of powerful AI, this game would continue, with both sides having access to AI tools, which would empower both but not necessarily shift the balance to one or the other.
I think the question of whether a long-term planning agent could emerge from short-term training is a very interesting technical question! Of course we need to understand how to define “long term” and “short term” here. One way to think about this is the following: we can define various short-term metrics, which are evaluable using information in the short-term, and potentially correlated with long-term success. We would say that a strategy is purely long-term if it cannot be explained by making advances on any combination of these metrics.
My point was not about the defender/attacker balance. My point was that even short-term goals can be difficult to specify, which undermines the notion that we can easily empower ourselves by short-term AI.
Sort of. The correct way to make it more rigorous, IMO, is using tools from algorithmic information theory, like I suggested here.
I’m clearly better at getting a dog to part with a bone than another dog is. I’m apt to use strategies like distracting it, or offering it something else that it wants more.
And furthermore, some people are way better at being persuasive than others, often by using explicit strategies to empathize with and come to understand someone’s positions, helping them uncover their cruxes, non-confrontationally, and then offering info and argument that bears on those cruxes.
Those skills are hard, and while there are definitely non-intelligence factors to proficiency with them, I can tell you that intelligence definitely helps. When I attend workshops on similar skills, a lot of people have difficulty with them because they’re hard to grasp or because there are multiple concepts that they need to keep in mind at once.
Maybe the returns to intelligence as applied to persuasion are diminishing, but they don’t look negligible.
It maybe true that within the range of +2 standard deviations to +5 standard deviations, factors other than intelligence (such as luck, or charisma, or emotional intelligence) dominate executive success.
But it doesn’t necessarily follow that there are negligible gains to intelligence far beyond this range.
In fact, it doesn’t even imply that there are negligible returns to intelligence within that range.
It might be that greater intelligence is, at every level, a sizable advantage. However, If any other factor is important, at all, that’s going to pull down the average cognitive ability of CEOs, etc. Selection on those other factors will tend to pull down the average IQ.
If one can be a successful CEO by being on the Pareto frontier of IQ and charisma and luck and emotional intelligence, you should expect to see that most CEOs will be moderately, but not overwhelmingly intelligent. Not because intelligence doesn’t matter, but because high IQs are rare and because the absolute smartest people aren’t much more likely to be adequately charismatic or lucky or emotionally perceptive.
But if you can hold those other factors constant, more intellectual capability might be monotonically beneficial.
Indeed, this is my actual belief about the world, rather than merely a hypothetical statistical possibility.
Thanks for so many comments! I do plan to read them carefully and respond, but it might take me a while. In the meantime, Scott Aaronson also has a relevant blog https://scottaaronson.blog/?p=6821
Happy thanksgiving to all who celebrate it!
It seems like I could rephrase that claim as “Humans are close to literal optimal performance on long term strategic tasks. Even a Jupiter brain couldn’t do much better at being a CEO than a human, because CEOs are doing strategy in chaotic domains.” (This may be a stronger claim than the one you’re trying to make, in which case I apologize for straw-manning you.)
That seems clearly false to me.
If nothing else, a human decision-maker’s ability to take in input is severely limited by their reading speed. Jeff Bezos can maybe read and synthesize ~1000 pages a of reports from his company in a day, if he spent all day reading reports. But even then those reports are going to be consolidations produced by other people in the company, highlighting which things are important to pay attention to and compressing many orders of magnitude of detail.
An AI CEO running Amazon could feasibly internalize and synthesize all of the data collected by Amazon directly, down to the detailed user-interaction time-logs for every user. (Or if not literally all the data, then at least many orders of magnitude more. My ballpark estimate is about 7.5 orders of magnitude more info, per unit time.)
I bet there’s tons and tons of exploitable patterns that even a “human level” intelligence would be able to pick up on, if they could only read and remember all of that data. For instance, patterns in user behavior (impossible to notice from the high level summaries, but obvious when you’re watching millions of users directly) which would allow you to run more targeted advertising or more effective price targeting. Or coordination opportunities between separate business units inside of Amazon, that are detectable if only there is any one person that knows what was happening in all of them in high detail.
Is the posit here that those gains could be gotten by short-term, non-autonomous AI systems?
Depending on how we carve things up, that might turn out to be true. But that just seems to mean that the human CEO, in practice, is going to pass off virtually all of the decision-making to those “short term” AI systems.
Either all these short term AI systems are doing analysis and composing reports that a human decision-maker reads and synthesizes to inform a long term strategy, or the human decision-maker is superfluous; the high level strategy is overdetermined by the interactions and analysis of the “short term” AI systems.
In the first case, I’m incredulous that there’s no advantage to having a central decision maker with even 100x the information-processing capacity, much less 1,000,000x the information processing capacity.
(I suppose this is my double crux with the authors? They think that after some threshold, additional information synthesized by the central decision maker is of literally negligible value? That a version of Amazon run by Jeff Bezos who had time to read 100x as much about what is happening in the company would do no better than a version of Amazon that has ordinary human Jeff Bezos?)
And In the second case, we’ve effectively implemented a long term planning AI out of a bunch of short term AI components.
Neither branch of that dilemma provides any safety against AI corporations outcompeting human-run corporations, or against takeover risk.
Sorry, but I only skimmed this… The supposition seems to be that “human with AI advisor” will always stay ahead of “pure AI”. But how easily does “human with AI advisor” turn into “AI with a human peripheral” or “posthuman with an AI exocortex”? Is there some reason why neurons are better than transistors at executive functions? This essay is like saying “the neocortex will change the world but the midbrain will still be in charge”.
I think that if humans with AI advisors are approximately as competent as pure AI in terms of pure capabilities, I would expect that humans with AI advisors would outcompete the pure AI in practice given that the humans appear more aligned and less likely to be dangerous then pure AI—a significant competitive advantage in a lot of power seeking scenarios where gaining the trust of other agents is important.
Yes, we usually select our leaders (e.g., presidents) not for their cognitive abilities but literally for how “aligned “ we believe they are with our interest. Even if we completely solve the alignment problem, AI would likely face an uphill battle in overcoming prejudice and convincing people that they are as aligned as an alternative human. As the saying goes for many discriminated groups, they would have to be twice as good to get to the same place.
We do not assume that humans are superior to AI in any way, or that neurons are superior to transistors. Similarly we do not claim that an AI CEO would be inferior to a human one. Rather we only claim that it would not dominate a human CEO as an AI chess player is to a human chess player. Note that currently, CEOs are usually not the smartest employees in their company, but that does not mean that they are the peripheral of their smartest engineers.
This is quite well-written. The first point where I ran into a wall was the distinction you drew between short-term goals and long-term strategies as two categorically different things.
I note that AIs can trivially set long-term strategy. I just generated this on GPT-2:
“The President of the United States says, “my fellow Americans, the long-term strategy for our country is this:
Let’s get rid of the Bush tax rates
Cut income taxes for ordinary American workers (including retirees) and for corporations”
The question is how to translate this strategy into action. It seems to me that a more realistic distinction is whether an AI can take over certain specific human jobs. An AI can do the job of a human calculator. Can an AI successfully take over the job of the President of the USA? No, not yet—but this is in large part because people wouldn’t listen to its directives, not because it couldn’t issue them.
But I am not sure why we’d think that short term plans are somehow easier to make than long term goals. I bet GPT-2 could give me an equally plausible explanation for what chores I should do from my todo list.
I do not claim that AI cannot set long-term strategies. My claim is that this is not where AI’s competitive advantages over humans will be. I could certainly imagine that a future AI would be 10 times better than me in proving mathematical theorems. I am not at all sure it would be 10 times better than Joe Biden in being a U.S. president, and mostly it is because I don’t think that the information-processing capabilities are really the bottleneck for that job. (Though certainly, the U.S. as a whole, including the president, would benefit greatly from future AI tools, and it is quite possible that some of Biden’s advisors would be replaced by AIs.)
I agree that the plausibility and economic competitiveness of long-term planning AIs seems uncertain (especially with chaotic systems) and warrants more investigation, so I’m glad you posted this! I also agree that trying to find ways to incentivize AI to pursue myopic goals generally seems good.
I’m somewhat less confident, however, in the claim that long-term planning has diminishing returns beyond human ability. Intuitively, it seems like human understanding of possible long-term returns diminishes past human ability, but it still seems plausible to me that AI systems could surpass our diminishing returns in this regard. And even if this claim is true and AI systems can’t get much farther than human ability at long-term planning (or medium-term planning is what performs best as you suggest), I still think that’s sufficient for large-scale deception and power-seeking behavior (e.g. many human AI safety researchers have written about plausible ways in which AIs can slowly manipulate society, and their strategic explanations are human-understandable but still seem to be somewhat likely to win).
I’m also skeptical of the claim that “Future humans will have at their disposal the assistance of short-term AIs.” While it’s true that past ML training has often focused on short-term objectives, I think it’s plausible that certain top AI labs could be incentivized to focus on developing long-term planning AIs (such as in this recent Meta AI paper) which could push long-term AI capabilities ahead of short-term AI capabilities.
Re myopic, I think that possibly, a difference between my view and at least some people’s is that rather than seeing being myopic as a property that we would have to be ensured by regulation or the goodness of the AI creator’s heart, I view it as the default. I think the biggest bang for the buck in AI would be to build systems with myopic training objectives and use them to achieve myopic tasks, where they produce some discrete output/product that can be evaluated on its own merits. I see AI as more doing tasks such as “find security flaws in software X and provide me exploit code as verification” than “chart a strategy for the company that would maximize its revenues over the next decade”.
Thanks! I guess one way to motivate our argument is that if the information-processing capabilities of humans were below the diminishing returns point, then we would have expect that individual humans with much greater than average information-processing capabilities to have distinct advantage in jobs such as CEOs and leaders. This doesn’t seem to be the case.
I guess that if the AI is deceptive and power-seeking but is not better at long-term planning than humans, then it basically becomes one more deceptive and power-seeking actor in a world that already has them, rather than completely dominate all other human agents.
I’ve written about the Meta AI paper on Twitter—actually its long-term component is a game engine which is not longer term than AlphaZero. The main innovation is combining such an engine with a language model.
I don’t understand, this seems clearly the case to me. Higher IQ seems to result in substantially higher performance in approximately all domains of life, and I strongly expect the population of successful CEOs to have many standard deviations above average IQ.
How many standard deviations? My (admittedly only partially justified) guess is that there are diminishing returns to being (say) three standard deviations above the mean compared to two in a CEO position as opposed to (say) a mathematician. (Not that IQ is perfectly correlated with math success either.)
At least for income the effect seems robust into the tails, where IIRC each standard deviation added a fixed amount of expected income in basically the complete dataset.
This can’t actually happen, but only due to the normal distribution of human intelligence placing hard caps on how much variance exists in humans.
There are only (by definition) 100 CEOs of Fortune 100 companies, so a priori, they could have an IQ score of the top 100 humans which (assuming a normal distribution) would be at least 4 standard deviations above the mean (see here).
My view is the reasons individual humans don’t dominate is due to an IID distribution, called the normal distribution, holds really well for human intelligence.
68% percent of the population is a .85x-1.15x smartness level, 95% of the population is .70-1.30x smartness, and 99.7% percent are .55-1.45x smartness level.
Even 2x in a normal distribution is off the scale, and one order of magnitude more compute is so far beyond it that the IID distribution breaks hard.
And even with 3x differences like humans-rest of animals, things are already really bad in our own world. Extrapolate that to 10x or 100x and you have something humanity is way off distribution for.
Even if you assume that intelligence is distributed normally, why aren’t we selecting CEOs from the right tail of that distribution today?
Uh, there is? IQ matters for a lot of complicated jobs, so much so that I tend to assume whenever there is something complicated at play, there will be a selection effects towards greater intelligence. Now the results are obviously very limited, but they matter in real life.
Here’s a link to why I think IQ is important:
https://www.gwern.net/docs/iq/ses/index
The table we quote suggests that CEOs are something like only one standard deviation above the mean. This is not surprising: at least my common sense suggests that scientists and mathematicians should have on average greater skills of the type measured by IQ than CEOs, despite the latter’s decisions being more far reaching and their salary’s being higher.
I don’t know much about how CEOs are selected, but I think the idea is rather that the range of even the (small) tails of normally-distributed human long-term planning ability is pretty close together in the grand picture of possible long-term planning abilities, so other factors (including stochasticity) can dominate and make the variation among humans wrt long-term planning seem insignificant.
If this were true, it would mean the statement “individual humans with much greater than average (on the human scale) information-processing capabilities empirically don’t seem to have distinct advantages in jobs such as CEOs and leaders” could be true and yet not preclude the statement “agents with much greater than average (on the universal scale) … could have distinct advantages in those jobs” from being true (sorry if that was confusingly worded).
Of course we cannot rule out that there is some “phase transition “ and while IQ 140 is not much better than IQ 120 for being a CEO, something happens with IQ 1000 (or whatever the equivalent).
We argue why we do not expect such a phase transition. (In the sense that at least in computation, there is only one phase transition to universality and after passing it, the system is not bottlenecks by the complexity of any one unit.)
However I agree that we cannot rule it out. We’re just pointing out that there isn’t evidence for that, in contrast to the ample evidence for the usefulness of information processing for medium term tasks.
I agree there isn’t a phase transition in the technical sense, but the relevant phase transition is the breaking of the IID assumption and distribution, which essentially allow you to interpolate arbitrarily well.
Hi, thanks both for writing this—I enjoyed it.
I’d be interested in your thoughts on how we can do this:
> However, perhaps more [emphasis] should be placed on building just-as-powerful AI systems that are restricted to short time horizons.
I can share some of my thoughts first, and would be keen to hear (both/either of) yours.
It’s worth saying up front that I also think this is a very productive direction, and that your post lays out a good case for why.
Here’s one salient baseline strategy, and a corresponding failure mode: At each point in time t, where is some time horizon h where AIs can pursue goals over horizon h. At each point in time, (social-impact-minded) AI companies aim to build “short-term goal” systems, which operate at horizon h, but not longer.
Note that this seems very natural, and also exactly matches what one might expect a purely profit- or prestige-driven company to do.
However, if h turns out to steadily increase over time (as in the straight-line extrapolation referenced below), then this leaves us in a difficult position.
Furthermore, this seems to leave us at the mercy of unknown empirical questions about deep learning. It doesn’t seem we have improved our chances relative to the baseline of “do the easiest thing at each point in time”.
So from a “differential progress” perspective, a more helpful research strategy seems to be: fix a task with some horizon h_1, then try to solve this task using only systems optimized over horizon h_2 < h_1.
This framing also possibly highlights two additional difficulties: (1) technically, end-to-end optimization has been quite effective for many DL tasks and (2) sociologically, the DL community has a tremendous aesthetic preference towards end-to-end approaches (which also translates into approaches and infra which favor end-to-end approaches), which makes it harder to gain widespread adoption for other approaches. Also agreed there are many offsetting factors like interpretability, control, etc. which you mention.
This suggests empirical angles similar to the one described [here](https://ought.org/updates/2022-04-06-process) by Ought.
I’d be very interested in how you think about this research direction, and particularly interested if you think there are other/complementary research directions which improve our chances of ending up with short time horizon AIs.
2. I understand this matches up with your core point, but to check understanding and confirm agreement—It seems far from certain that so-called “short-term goal” AIs will dominate, and given these uncertainties, it
I would guess you are both somewhat more optimistic about “short-term goal AIs” than I am (in most discussions, I normally find myself arguing for competitiveness of short-term goal AIs, so it’s a nice change-of-perspective for me!). But I imagine(?) we might have similar views that:
So long as p(“short-term AIs dominate”) is not very close to 1, this leaves substantial risk.
So long as p(“short-term AIs dominate”) is not very close to 1, then there is reasonable room for dedicated efforts to push this probability up (or down).
There are many reasons this seems uncertain, but to spell out one: As you correctly point out, the applications where DL is useful right now (to the extent there are any) are predominantly short-term ones. But it also seems that the natural trend over time would be for AIs to move to competency on increasingly broad tasks in the future, and so the current situation doesn’t provide much evidence whether to expect this straight-line extrapolation vs. a Goldilocks effect you describe.
3. As a final point, regarding this:
A salient possibility for me is that long-term-optimized AIs are only mildly more powerful (say, equivalent to a 50% compute increase), but that this is enough for almost everyone to use long-term AIs. If more of the world (ML community, leaders, regulators, general public) agrees that long-horizon-optimized AIs are more dangerous than short-horizon-optimized AIs, then short-horizon-optimized AIs can become the norm in spite of this. But it seems unclear to what extent this will happen, and so this similarly seems well worth pushing on, for a social impact-minded person/team.
I would love to discuss more in the future, but in the interest of time (and because this is already quite long), I’m starting with what I expect are the most fruitful lines.
Thank you! I think that what we see right now is that as the horizon grows, the more “tricks” we need to make end-to-end learning works, to the extent that it might not really be end to end. So while supervised learning is very successful, and seems to be quite robust to choice of architecture, loss functions, etc., in RL we need to be much more careful, and often things won’t work “out of the box” in a purely end to end fashion.
I think the question would be how performance scales with horizon, if the returns are rapidly diminishing, and the cost to train is rapidly increasing (as might well be the case because of diminishing gradient signals, and much smaller availability of data), then it could be that the “sweet spot” of what is economical to train would remain at a reasonably short horizon (far shorter than the planning needed to take over the world) for a long time.
I’m personally pretty sympathetic to the idea that there are indeed metrics through which model progress is continuous (both as a function of scale and over the course of training).
That being said: smooth performance along one metric doesn’t necessarily imply smooth downstream performance! (E.g. from your “SGD learns parity close to the computational limit” paper, even though there exist smooth progress measures on how small neural networks learn parity, this does not explain away the sharp increase in accuracy. See also the results from the modular addition task.)
In particular, it’s empirically true that smooth progress of log loss does not necessarily imply smooth progress on downstream performance. For example, in both the BIG-Bench and Wei et al’s “Emergent Abilities of Large Language Models” papers, we see that smooth performance on cross entropy loss or does not imply continuous smooth progress in terms of error rate. And though GPT-3 follows the same log loss scaling curve as GPT-2, I’m not sure anyone would have predicted the suite of new abilities that would arise alongside the decrease in log loss.
(It also doesn’t rule out the existence of better scaffolding or prompting techniques like Chain-of-Thought, which can both significantly improve downstream performance and even change the shape of scaling curves, without additional training).
It is indeed the case that sometimes we see phase transitions / discontinuous improvements, and this is an area which I am very interested in. Note however that (while not in our paper) typically in graphs such as BIG-Bench, the X axis is something like log number of parameters. So it does seem you pay quite a price to achieve improvement.
The claim there is not so much about the shape of the laws but rather about potential (though as you say, not certain at all) limitations as to what improvements you can achieve through pure software alone, without investing more compute and/or data. Some other (very rough) calculations of costs are attempted in my previous blog post.
Yeah, I agree that a lot of the “phase transitions” look more discontinuous than they actually are due to the log on the x axis — the OG grokking paper definitely commits this sin, for example.
(I think there’s also another disagreement here about how close humans are to this natural limit.)
This is a great post. Thanks for writing it! I think Figure 1 is quite compelling and thought provoking.
I began writing a response, and then realized a lot of what I wanted to say has already been said by others, so I just noted where that was the case. I’ll focus on points of disagreement.
Summary: I think the basic argument of the post is well summarized in Figure 1, and by Vanessa Kosoy’s comment.
A high-level counter-argument I didn’t see others making:
I wasn’t entirely sure what was your argument that long-term planning ability saturates… I’ve seen this argued both based on complexity and chaos, and I think here it’s a bit of a mix of both.
Counter-argument to chaos-argument: It seems we can make meaningful predictions of many relevant things far into the future (e.g. that the sun’s remaining natural life-span is 7-8 billion years).
Counter-argument to complexity-argument: Increases in predictive ability can have highly non-linear returns, both in terms of planning depth and planning accuracy.
Depth: You often only need to be “one step ahead” of your adversary in order to defeat them and win the whole “prize” (e.g. of market or geopolitical dominance), e.g. if I can predict the weather one day further ahead, this could have a major impact in military strategy.
Accuracy: If you can make more accurate predictions about, e.g. how prices of assets will change, you can make a killing in finance.
High-level counter-arguments I would’ve made that Vanessa already made:
This argument proves too much: it suggests that there are not major differences in ability to do long-term planning that matter.
Humans have not reached the limits of predictive ability
Low-level counter-arguments:
RE Claim 1: Why would AI only have an advantage in IQ as opposed to other forms of intelligence / cognitive skill? No argument is provided.
(Argued by Jonathan Uesato) RE Claim 3: Scaling laws provide ~zero evidence that we are at the limit of “what can be achieved with a certain level of resources”.
Thanks for writing this—I found it interesting, thoughtful, and well-written.
One distinction which seems useful to make is between:
long-term goals
long-term planning
long-term capabilities (i.e. the ability to reliably impact the long-term future in a particular way).
It seems to me that this post argues that:
AI systems’ long-term planning won’t be that much better than humans’ (claims 1 and 3).
AI systems won’t develop long-term goals (claims 4, 5, and 6).
Given (1) (and given that both humans and AI systems with long-term goals will have access to systems with the same short-term capabilities), AI systems won’t have much better long-term capabilities than humans + their AI assistants.
Before going on, I’d like to say that point (3) was quite novel and interesting to me—thanks for making it! This bolsters the case for “successfully aligning the AI systems we have now might be sufficient for keeping us safe from future more general AI systems.”
There are two critiques I’d like to make. First, I’d like to push back on claim (2); namely, I’ll posit a mechanism by which an agent with (good but not necessarily superhuman) long-term planning capabilities and short-term goals could behave as if it had long-term goals.[1] Indeed, suppose we had an agent whose (short-term) goals were to: generate a long-term plan (consisting of short-term steps) which would lead to as much long-term company profit (or whatever else) as possible; execute the first step in the plan; and repeat. Such an agent would behave as if it were pursuing the long-term goal of company profit, even though it had only the short-term goals of generating plans and optimizing arbitrary short-term goals. (In fact, it seems plausible to me that something like this is how humans act as long-term agents; do I really have long-term goals, or do I just competently pursue short-term goals—including the goal of making long-term plans—which have the overall effect of achieving long-term goals which my culture has instilled in me?)
Second, due to power-seeking behavior, misaligned long-term goals could lead to catastrophe even without significantly superhuman long-term planning ability. (This is a counterargument to point (3).) Suppose an AI system has a malign long-term goal as well as good long-term planning. Because of how difficult it is to predict the future (as pointed out in this post), the agent might realize that, rather than pursuing any particular takeover plan, it should instead generally accumulate resources and power. Since this is generally a good way to pursue any long-term goal, this wouldn’t necessarily set off red flags. Once the agent has enough resources and power, it may be able to decisively disempower humanity, even without significantly better long-term planning than humans. (How good does the agent’s long-term planning need to be to accumulate enough resources to make such a decisive strike possible? I could imagine that even sub-human long-term planning might be enough, though superhuman long-term planning would certainly make it easier.)
In this comment, Paul describes two other mechanisms by which long-term goals could form. One important difference between the story I share here and the ones that Paul describes is that Paul’s stories result in intrinsic goals, whereas my story results in goals which are neither intrinsic nor instrumental, but emergent. I’ll note that deceptive alignment requires a misaligned long-term intrinsic goal, so the story I tell here doesn’t affect my estimate of the likelihood of deceptive alignment.
Re your second critique: why do you think an AI system (without superhuman long-term planning ability) would be more likely to take over the world this way than an actor controlled by humans (augmented with short-term AI systems) who have long-term goals that would be instrumentally served by world domination?
I think that a competent human actor assisted by short-term AI systems plausibly could take over the world this way; I’m just inclined to call that a misuse problem rather than an alignment problem. (Or in other words, fixing that requires solving the human alignment problem, which feels like it requires different solutions, e.g. coordination and governmental oversight, than the AI alignment problem.)
In those terms, what we’re suggesting is that, in the vision of the future we sketch, the same sorts of solutions might be useful for preventing both AI takeover and human takeover. Even if an AI has misaligned goals, coordination and mutually assured destruction and other “human alignment” solutions could be effective in stymying it, so long as the AI isn’t significantly more capable than its human-run adversaries.
I’m confused about your first critique. You say the agent has a goal of generating a long-term plan which leads to as much long-term profit as possible; why do you call this a short-term goal, rather than a long-term goal? Do you mean that the agent only takes actions over a short period of time? That’s true in some sense in your example, but I would still characterize this as a long-term goal because success (maximizing profit) is determined by long-term results (which depend on the long-term dynamics of a complex system, etc.).
I see two distinctions between a system like the one I described and a system with long-term goals in the usual sense. First, the goal “write down a plan which, if followed, would lead to long-term profit” is itself a short-term goal which could plausibly be trained up to human-level with a short-term objective function (by training on human-generated predictions). So I think this mechanism avoids the arguments made in claims 4 and 5 of the post for the implausibility of long-term goals (which is my motivation for mentioning it). (I can’t tell if claim 6 was supposed to be addressing long-term goal formation stories like this one.)
Second, the intrinsic goals of the system I described are all short-term (output the text of a plan for a long-term goal; pursue various short-term goals),so the possible alignment failures for such a system might need to be analyzed differently than those of a system with long-term intrinsic goals. For example, such a system might not plan ahead of time to disempower humans (since such disempowerment would come in the long-term, which it doesn’t intrinsically care about). But once it finds that it has enough resources and power to disempower humans, it might then decide to take a catastrophic action, despite not having planned it in advance.
Ah, I think I understand what you meant now. The reward for this agent is not determined by the actual long-term consequences of its action, but by the predicted long-term consequences. In that case, yes, this seems like it might be an interesting middle ground between what we are calling short-term and long-term AIs. Though it still feels closer to a long-term agent to me—I’m confused about why you think it would both (a) not plan ahead of time to disempower humans, and (b) disempower humans when it has the chance. If the predictive model is accurate enough such that it is predictable that disempowering humans would be instrumentally useful, then wouldn’t the model incorporate that into its earlier plans?
Yep, sorry, I’ve probably been pretty unclear with describing this example.
For the sake of simplicity, let’s ignore the “execute on arbitrary short-term goals” half of the system I described, and just consider a system which was trained to generate long-term plans that maximize profit by imitating human-generated plans; if we label our training data with information about plan quality, such an agent could plausibly output plans as good as a human expert planner. So the training goal of this system is the short-term goal of minimizing next-token prediction loss during the current episode.
Let’s suppose that this agent is subtly inner misaligned with the (still short-term) inner goal of minimizing the value in the memory address which, during training, represented the current episode’s prediction loss. So if this agent could wirehead by directly setting this number to be very small before the end of its current episode, it would do so. But if it’s not able to do that, it would likely exhibit the behavior we want (outputting plans which mimic its training data), since that’s the best way to get the value in the memory address it cares about to be small. In particular, this system wouldn’t be interested in outputting plans which would manipulate us into setting this value to be small in the future, since it myopically only cares about this memory address’s value during the current episode.
But if at some point the system accumulates lots of resources and power by normal means, it may find that it has the option of e.g. suddenly taking control of the computers that it’s running on and manually setting the value in the memory address it cares about to be small. (I’m assuming here that the system can do things other than just output tokens, e.g. search the internet, contact human experts on the side, etc., so that it could plausibly have a way of taking over its computing cluster without ending the current episode.) So this is a bad action that the system wouldn’t have planned on setting up ahead of time, but would take if it found it was able to.
Lets suppose that both the human and long term AI have a copy of chatGPT. However, as many of us has found, chatGPT is somewhat fickle, it doesn’t reliably do what we actually want it to do. We are having short term, non-catastrophic alignment problems. But they do make the tool significantly less useful.
Does the long term AI suffer from the same problems? Quite possibly not if the chatGPT like capabilities are sufficiently integrated into the model.
Try convincing a rock to do something by arguing with it. The rock remains supremely unconvinced. You are much smarter than a rock.
In order to be convinced to do something, there needs to be sufficient complex structure to be capable of being convinced. This is the same reason that sophisticated malware can’t run on simple analogue circuits.
Dogs aren’t capable of being motivated by sophisticated philosophical arguments.
Of course, humans can get dogs to do all sorts of things through years of training.
Added to that, a human trying to part a bone from a dog isn’t exactly applying the full intellectual power humanity can bring to bear. It isn’t like a company doing statistics to optimize add click through.
Also, many of the fastest ways to get a small child to give up a toy might count as child abuse, and are therefore not options that naturally spring to mind. (Ie spinning a tail of terrifying monsters in the toy, that will get the child to drop the toy, run screaming and have nightmares for weeks)
I think you are imagining the first blue line, and asking the dotted blue line to justify its increased complexity penalty. Meanwhile, other people are imagining the orange line.
It is over longer timescales, and is harder to give uniform starting conditions, so of course it’s harder to measure.
This leads to the inadequate equilibrium. But lying your backside off to voters and shareholders is also an intellectual skill of sorts. It’s a mistake to see that Elon Musk doesn’t know that much engineering, and conclude intelligence isn’t important in business. Riding memes, building hype and getting away with financial misconduct are activities that take place in the brain.
A surprising claim.
There is a function with 2 inputs, intelligence and other resources. You are arguing about the shape of this function, given only a line of inputs.
This argument shows that, given fixed human intelligence, more other resources such as books, computers etc produce reasonably high returns in progress. Given the same intelligence, researchers with better tools are more productive.
This doesn’t let you claim that human intelligence wasn’t a bottleneck. As far as I can tell, you have presented no baysian evidence about what a smarter than max human mind might or might not be able to accomplish.
This is a great post. Thanks for writing it!
I agree with a lot of the counter-arguments others have mentioned.
Summary:
I think the basic argument of the post is well summarized in Figure 1, and by Vanessa Kosoy’s comment.
High-level counter-arguments already argued by Vanessa:
This argument proves too much: it suggests that there are not major differences in ability to do long-term planning that matter.
Humans have not reached the limits of predictive ability
You often only need to be one step ahead of your adversary to defeat them.
Prediction accuracy is not the relevant metric: an incremental increase in depth-of-planning could be decisive in conflicts (e.g. if I can predict the weather one day further ahead, this could have a major impact in military strategy).
More generally, the ability to make large / highly leveraged bets on future outcomes means that slight advantages in prediction ability could be decisive.
Low-level counter-arguments:
(RE Claim 1: Why would AI only have an advantage in IQ as opposed to other forms of intelligence / cognitive skill? No argument is provided.
(Argued by Jonathan Uesato) RE Claim 3: Scaling laws provide ~zero evidence that we are at the limit of “what can be achieved with a certain level of resources”.
RE Claim 5: Systems trained with short-term objectives can learn to do long-term planning competently.
I find the idea that intelligence is less useful for sufficiently complex systems or sufficiently long time frames interesting. Or at least the kind of intelligence that helps you make predictions. My intuition is that there is something there, although it’s not quite the thing you’re describing.
I agree that the optimal predictability of the future decays as you try to predict farther into the future. If the thing you’re trying to predict in the technical sense, you can make this into a precise statement.
I disagree that the skill needed to match this optimum typically has a peak. Even for extremely chaotic systems, it is typically possible to find some structure to it that is not immediately obvious. Heuristics are sometimes more useful than precise calculations, but building good heuristics and know how to use them is itself a skill that improves with intelligence. I suspect that the skill needed to reach optimum usually monotonically increases with longer prediction times or more complexity.
Instead, the peak appears in the marginal benefit of additional intelligence. Consider the difference in prediction ability between two different intelligences. At small time / low complexity, there is little difference because both of them are very good at making predictions. A large times / complexity, the difference is again small because, even though neither is at optimum, the small size of the optimum limits how far apart they can be. The biggest difference can be seen at the intermediate scales, while there are still good predictions to be made, but they are hard to make.
A picture of how I think this works, similar to Figure 1, is linked here: https://drive.google.com/file/d/1-1xfsBWxX7VDs0ErEAc716TdypRUdgt-/view?usp=sharing
As long as there are some other skills relevant for most jobs that intelligence trades off against, we would expect the strongest incentives for intelligence to occur in the jobs where the marginal benefit of additional intelligence is the largest.
unpacking inner Eliezer model
If we live in world where superintelligent AGI can’t have advantage in long-term planning over humans assisted by non-superintelligent narrow AIs (I frankly don’t believe that we live in such world), then superintelligent AGI doesn’t make complex long-term plans where it doesn’t have advantage. It will make simple short-term plans where it has advantage, like “use superior engineering skills to hack into computer networks, infect as many computers as possible with its adapted for hidden distributed computations source code (here is a point of no return), design nanotech, train itself to an above average level in social engineering, find gullible and skilled enough people to build nanotech, create enough smart matter to sustain AGI without human infrastructure, kill everybody, pursue its unspeakable goals in the dead world”.
Even if we imagine “AI CEO” the best (human aligned!) strategy I can imagine for such AI is “invent immortality, buy the whole world for it”, not “scrutinize KPIs”.
Next, I think your ideas about short/long-term goals are underspecified because you don’t take into account the distinction between instrumental/terminal goals. Yes, human software engineers pursue short-term instrumental goal of “creating product”, but they do it in process of pursuing long-term terminal goals like “be happy”, “prove themselves worthy”, “serve humanity”, “have nice things”, etc. It’s quite hard to find system with short-term terminal goals, not short-term planning horizon due to computational limits. To put in another words, taskiness is an unsolved problem in AI alignment. We don’t know how to tell superintelligent AGI “do this, don’t do everything else, especially please don’t disassemble everyone in process of doing this, stop after you’ve done this”.
If you believe that “extract short-term modules from powerful long-term agent” is the optimal strategy in some sense (I don’t even think that we can properly identify such modules without huge alignment work), then powerful long-term agent knows this too, and it knows that it’s on time limit before you dissect it, and will plan accordingly.
Claims 3 and 4 imply claim “nobody will invent some clever trick to avoid this problems”, which seems to me implausible.
Problems with claims 5 and 6 are covered in Nate Soares post about sharp left turn.
I dunno. The current state of traditional and neural AI look very much like “we only know how to build tasky systems”, not like “we don’t know how to build tasky systems”. They mostly do a single well-scoped thing, the same thing that they were trained on, are restricted to a specified amount of processing time, and do not persist state across invocations, wiping their activations after the task is completed. Maybe we’re so completely befuddled about goal-directedness etc. that these apparently very tasky systems have secret long-term terminal goals, but that seems like a stretch. If we later reach a point where we can’t induce taskiness in our AI systems (because they’re too competent or something), that will be a significant break from the existing trend.
I want to say “yes, but this is different”, but not in the sense “I acknowledge existence of your evidence, but ignore it”. My intuition tells me that we don’t “induce” taskiness in the modern systems, it just happens because we build them not general enough. It probably won’t hold when we start buliding models of capable agents in natural environment.
Certainly possible. Though we seem to be continually marching down the list of tasks we once thought “can only be done with systems that are really general/agentic/intelligent” (think: spatial planning, playing games, proving theorems, understanding language, competitive programming...) and finding that, nope, actually we can engineer systems that have the distilled essence of that capability.
That makes a deflationary account of cognition, where we never see the promised reduction into “one big insight”, but rather chunks of the AI field continue to break off & become unsexy but useful techniques (as happened with planning algorithms, compilers, functional programming, knowledge graphs etc., no longer even considered “real AI”), increasingly likely in my eyes. Maybe economic forces push against this, but I’m kinda doubtful, seeing how hard building agenty AI is proving and how useful these decomposed tasky AIs are looking.
Decomposed tasky AI’s are pretty useful. Given we don’t yet know how to build powerful agents, they are better than nothing. This is entirely consistent with a world where, once agenty AI is developed, it beats the pants of tasky AI.