One is that Google merged Google Brain and DeepMind into the new Google DeepMind. DeepMind head and founder Demis Hassabis is in charge of the new division. We will see how this plays out in practice, seems very good for Google.
The other is that a paper claims to have figured out how to extend the context window to one… million… tokens, making the cost per token linear rather than quadratic. If so, and this doesn’t have big other downsides, that’s a huge game. A comment suggests this is more on the ‘in mice’ level, so perhaps we should not get our hopes up.
Lots of other stuff happened as well, those are the two must-know items.
A Hypothetical Takeover Scenario Twitter Poll. I asked Twitter about a scenario where an ASI attempts a world takeover to kill all humans, but has its abilities sharply restricted to the practical and known (e.g. no foom of any kind, no nanotech, a human-level plan and so on) to see where people were doubtful, where they were confident, what arguments they had and what might be a crux that would change their minds. Mixed results.
Your message length limit is 2000 characters, but that is only enforced by the HTML so you can “inspect” the chat box, double click on the “maxlength” parameter and change it to whatever you like. And it will stay changed between sessions. The real max is 10,552 tokens. Presto.
Sam Altman: heard something like this 3 times this week: “our recent grads are now much more productive than people who have worked here for years because they’ve really learned how to use ChatGPT”.
Suspicion of ‘something like 3’ aside, this is the kind of thing people would be highly inclined to tell Sam Altman, so grain of salt. Still, I can totally buy it.
My own mundane utility update: It’s been relatively slow going, but at this point I’d say Bing plus ChatGPT are providing a substantial productivity boost. Useless for the actual writing, haven’t found a way to edit, but my knowledge seeking and learning has sped up considerably.
You can if you squint kind of rediscover Kepler’s Third Law ‘the way Kepler did it,’ if you know you are looking for such a law and broadly what type of form it will take, and you explicitly tell the AI what method to use, and it probably doesn’t depend on the training set containing the answer.
If anything I feel less nervous knowing this is what it took. The AI isn’t ‘doing the real work’ here at all.
Let you start a ‘business’ on Replit without actual coding experience, by using a combination of bounties and ChatGPT calls and their Ghostwriter. This does not seem like a way to build a great code base – if I had more time, I’d be using such tools to learn to code rather than to learn to keep not coding.
People aren’t taking kindly, review averages are down quite a lot.
You can have a Facetime conversation with an AI rather than typing. That doesn’t mean you would want to. Voice is agonizingly slow when there is no detail information available, no meaningful nuance or tone, and you’re making small talk? And terrible small talk at that. The audio tech is advancing nicely though, and the face moves nicely.
Kareem Carr: We now have data demonstrating my tips for improving prompts to GPT-4 work at least in this one case!
Telling GPT-4 it was more competent increased the success rate from 35% to 92%
Giving GPT-4 a strategy for completing the task increased it from 26% to 54%
TIP 1: TELL THE MODEL ITS AN EXPERT in whatever you want to ask it about. [This change doesn’t get you the right answer all of the time. I tried it 5 times in a fresh window and it worked 3 out of 5 times.]
TIP 2: INSTRUCT THE MODEL on how to do the task. For example, you can give it steps for double-checking its work. [This improvement worked 2 out of 5 times.]
Combining tips 1 and 2, I was able to get GPT-4 to generate a reasonable answer 5 out of 5 times!
Language Models Don’t Offer Mundane Utility
Maia: Technological Unemployment averted with one simple trick (the risk of getting sued to high heaven)
Original Quote: Only a mere two weeks ago, ChatGPT effortlessly prepared near-perfectly edited lawsuit drafts for me and even provided potential trial scenarios. Now, when given similar prompts, it simply says ’I am not a lawyer and cannot provide legal advice or help you draft a lawsuit. However, I can provide some general information on the process that you may find helpful. If you are serious about filing a lawsuit, it’s best to consult with an attorney in your jurisdiction who can provide appropriate legal guidance.
Brian: He has a point it did this to my D&D stuff too, asked it to put together 3 encounters for a party of 4 level 7 characters and it was like nope.
Had to rephrase it like 3 times, that was a really useful feature
Fun With Image, Audio and Video Generation
David Holz, founder of Midjourney, has time for your ethical considerations, but has no time to write up his time for your ethical considerations.
Andy Matuschak: Curious: what are the best examples you’ve seen of an “ethical considerations” section in an ML systems paper? I’d like to get a sense of what it’s like to do this well (if possible); the examples I’ve read are all perfunctory lip-service.
David Holz: There are def a lot of ai safety precautions being taken in the real world but most of them aren’t being publically documented and are changing quite a bit every few months.
Idk no one has time
also it can be used to adversarially game the system, which could be good or bad given your perspective.
Andy: Ah, that makes a ton of sense.
Bring friends to Pepperoni Hug Spot, via this 30 second AI-generated ad. Gaut says1 ‘indistinguishable from reality.’ Except for minor issues. The voice is clearly fake. The video in many places has the AI nature in its details. The English and the underlying ideas are both a kind of other-more-alien-80s-Japanese level of not right in a different direction in a way that no actual human would create. The lack of real video, anything beyond a simple single motion, is hard to miss once you notice it.
Are we making progress? Oh, very much so. I do not think the ‘last mile’ here will be so easy. Instead, we will have tools that make creating not-quite-right quality stuff much much faster, in a variety of ways, and also give people creating good things new tools that make them more productive as well.
Which, mostly, is great.
What it definitely isn’t is anything to panic about:
Gaut: Many of you are underestimating what this means. Netflix? Dead. HBO? Goodbye. YouTube? Gone. Follow me for more AI news.
The ‘follow me for more AI news’ here is never unrelated to the rest. Keep in mind.
Oh, also:
Pizza Hut (official account): my heebies have been jeebied.
Gaut: alright tell me what are the secret things in the pizza
So I’ll admit that I was an Al skeptic. But, Chat-GPT & Al saved my business over $100,000. I am fully converted.
Here’s a real use case for Chat-GPT in business:
One of the hardest parts of running a business is documenting everything. When an employee leaves, they usually take a ton of knowledge with them. My job since acquiring a business in August has been to put all that knowledge on paper.
In a small business, this is increasingly difficult because everyone has a job to do and people are busy. They often don’t have hours to sit around and train a replacement. And often you cannot afford to pay 2 people to do the same job. Here’s where Chat-GPT has been a savior.
We try to write down all the tasks that get done in a task map. Then create SOP’s around those tasks. There are 100’s of tasks that get completed monthly at small companies. One of those is getting paid and following up on overdue customers. Here’s how Chat-GPT helped me:
We send all our invoices out of Quickbooks, but we need to run a weekly account aging report to see who is overdue. Here’s the prompt I typed into Chat-GPT to help me write an SOP for that task:
“I’m looking for an SOP on how to run an accounts aging report in Quickbooks. Create the SOP but also add instructions on how to contact customers that are more than 30 days late & instructions for customers that are more than 60 days late. I will contact them via email.”
[ChatGPT gives him a solid SOP]
Now we have an SOP for running an aging report. The best thing is this is a written document that can live in our internal records forever. Simple. But we can go 1 step further. We can get it to write emails to overdue customers. Here’s the prompt we used there:
“Please write the emails for both the 30 day overdue customers and the 60 day overdue customers.” And the result:
[ChatGPT creates quite reasonable email template]
Now we know how to run the report and the copy to use when communicating the issue with customers. The final step is to give this to our offshore resource to create a Loom video actually going through every step. In about 20 mins we will have an SOP for both running a report to collect overdue funds and the copy to send those customers an email and a video to see these steps visually. This would have taken hours to complete previously.
We add the following info along with some proprietary knowledge to our internal task map and we have a full fledged process for collecting overdue funds using the power of AI. Here’s what it looks like for us.
Multiply this by the 100’s of processes a business completes everyday and you can see very quickly how this can save a company $1,000’s. One of the biggest fears for a small team is someone leaving the job with a ton of knowledge. This process solves that.
The key question is: What is the counterfactual here without ChatGPT?
If the counterfactual is ‘oh well, I guess we won’t have an SOP for these things and we will have to write a new email every time a customer is 30 days overdue’ then ChatGPT is doing fantastically valuable work, great stuff.
If the counterfactual is ‘we would have had a human write the SOP for these things and have a human write the template emails’ then ChatGPT saved you a day of someone’s time? Maybe a few days? Humans are not as good as ChatGPT at quickly producing acceptable versions of such documents, they also aren’t that slow and their final results are at least as good.
The thing that is saving most of the money and time here is what Munn knew to do long before ChatGPT, documenting procedures, writing up the SOP, creating standard template communications. That’s standard automation stuff, not AI stuff.
The AI then assisted with figuring out how the tasks work, which is not so valuable exactly because we are going to create documentation. That means that rather than lots of people needing the AI to help them all the time, he only needed the AI to help him out once, then he was done. So not that much labor saved.
MedicGPT
Epic Systems and their medical records are partnering with Microsoft and OpenAI. The announced uses are drafting message responses to patients and discovering trends across patients, with those trends leading to both new scientific discoveries or financial opportunities. Drafting patient messages, and other letters and communications that need to be sent to various people, seems like an excellent use case, speeding up care provision. On pattern recognition? Less clear.
Or you could go for maximum ‘oh no please don’t do this’ and have a bot called ‘Dr. Gupta’ created by Martin Shkreli, I assure you I am not making this up.
Sadly the “Prompts are easy and not a profession” crowd are in a interesting position as all ChatGPT plug-ins are: SuperPrompts. Saying anyone can do it is like never going to any professional because you can do it. Most can cook, only few are chefs.
Age of Massive Scale-Based AI Improvements Already Ending?
Such things are always in relative terms, things could go super duper fast while still being 10x slower than the last few months, yet Sam Altman thinks so? He is continuing to emphasize this narrative:
The age of massive AI improvements in software such as ChatGPT is almost over. OpenAI CEO Sam Altman has revealed that the sweeping changes of AI training is already reaching its limit.
Speaking to an audience at the Massachusetts Institute of Technology, Altman explained that AI development is already reaching a massive wall. While AI improvements have resulted in huge quality boosts to ChatGPT, Stable Diffusion and more, they are reaching their end.
“I think we’re at the end of the era where it’s going to be these, like, giant, giant models,” Altman said, via Wired.
This is potentially your best possible situation. Throwing compute at bigger and bigger models and seeing rapid gains seemed like the easiest way to ensure we all get killed, so it is much better that this plan won’t work. Everything slows down. Pauses, even.
The question then is, what improvements can be found elsewhere?
There is a ton of space available for improvements. People haven’t even scratched the surface of what one can do to tune and take advantage of current-generation AI technology. Every time I think about how to do anything I get the urge to start coding or found a company. There’s a constant sense of ‘I figured out how to do it.’ Or at least, how to do it better. We’re going to see a bunch of bespoke detailed work.
Mostly, I think that’s great. I want to see maximum extraction of mundane utility in non-dangerous ways. In many ways I think the more bespoke your implementation of the things you want to do with current tech, the less danger you are posing, because a lot of what you are doing is de-risking the process, taking away ways for it to go wrong. You can still make things worse if you then use that to trust the AI too much.
It does seem like there is at least some ability to get better LLM performance by going larger, in exchange for more compute cost and more up-front training cost, and everyone is mostly going ‘nope, not worth it’ given the trade-offs involved, at least for the time being.
Eric Gilliam draws a parallel to innovation in Ju Jitsu, in the sense that OpenAI has already innovated a bunch, so one should bet on them innovating again even if they can’t rely on stacking more layers. It’s a consideration, at least.
Kerry Vaughan: This is an important development in the AI power landscape. I can’t tell from the description whether this leaves Demis with more power (because of gaining extra resources) or less (because of more oversight from Google). Does anyone have a read?
For those who don’t know, Demis is a world champion at the game Diplomacy. He has considerable skills in strategy, persuasion, and deception.
You should read this as an intentional move from a strategist and try to infer what the strategist is trying to gain.
Margaret Mitchel, founder and former co-head of Google’s AI ethics unit (she was fired, stated reason seems to be violations of security policies, there were also other issues related to the firing of Timnit Gebru) has a thread suggests that the Google Brain brand was damaged in terms of hiring and retention, which the thread heavily implies she blames on the firings. Sees this move as a way to fix that issue by moving the branding onto DeepMind.
Also she suggests this lets Google Brain founder Jeff Dean get away from managing people and back to writing code and building stuff as Google’s Chief Scientist, which is what Jeff is better at and wants to do anyway. There’s discussion about whether the involved ‘promotion’ is ‘fake’ and issues of internal politics, thing is that not everyone wants or would benefit from ‘real’ promotions as opposed to being able to do what they love doing and are good at.
My best guess is that this was pretty simple. Google Brain let its lunch get eaten by OpenAI and Microsoft, then was given one job. That job was called Bard. The initial Bard offering sucked and improvement wasn’t coming fast enough. So they called in DeepMind to fix the mess, put Demis in charge and convinced him to actually build and ship commercial things this time as part of the deal.
Europe’s Ongoing War on the Internet and All Human Activity Potentially Bears Dividends
If you are going to systematically make life worse with things like GPDR, make sure that every piece of data about anyone is proceeded by a cookie, disposed of exactly when required and also held onto and used in various ways, and require everyone who ever collects any bit of data on the internet justify their “legitimate interest” in doing so in every case, and generally tell everyone they’re not allowed to do anything?
If those regulations don’t actually make any sense in the context of actual human life?
Well, let’s also do it in the one place this might do some good, perhaps. AI.
taly has given OpenAI until April 30 to comply with the law. This would mean OpenAI would have to ask people for consent to have their data scraped, or prove that it has a “legitimate interest” in collecting it. OpenAI will also have to explain to people how ChatGPT uses their data and give them the power to correct any mistakes about them that the chatbot spits out, to have their data erased if they want, and to object to letting the computer program use it.
If OpenAI cannot convince the authorities its data use practices are legal, it could be banned in specific countries or even the entire European Union. It could also face hefty fines and might even be forced to delete models and the data used to train them, says Alexis Leautier, an AI expert at the French data protection agency CNIL.
OpenAI’s violations are so flagrant that it’s likely that this case will end up in the Court of Justice of the European Union, the EU’s highest court, says Lilian Edwards, an internet law professor at Newcastle University. It could take years before we see an answer to the questions posed by the Italian data regulator.
Flagrant violations, you see, because OpenAI simply took data from the internet.
One does not simply take data from the internet, Europe retorts.
“The US has a doctrine that when stuff is in public, it’s no longer private, which is not at all how European law works,” says Edwards.
How dare they use publicly available information! They must be stopped.
Europe telling OpenAI not only to get out of the continent but that it must delete GPT-4, perhaps also GPT-3.5, and all the training data used for them would be quite the power move. Especially given they’re attached to Microsoft, who can’t exactly say ‘no.’
That would be much, much more impactful than any proposed pause. Why aren’t the Europeans worried we’ll ‘lose to China’? Why is Germany burning so much coal?
OpenAI told us it believes it complies with privacy laws, and in a blog post it said it works to remove personal information from the training data upon request “where feasible.”
That’s the thing. OpenAI is doing the tech thing where they pretend that ‘where feasible’ has anything to do with such requirements. It doesn’t.
Then there’s the additional question the Italians are on about, which is how it collects users’ data during the post-training phase, things like sensitive chat logs.
Those problems seem eminently solvable, there’s no reason OpenAI can’t delete those chat logs on request or avoid sending along user data. That one, to me, is on OpenAI.
The company could have saved itself a giant headache by building in robust data record-keeping from the start, she says.
That is classic European regulator speak, of course you should document absolutely everything you ever do and everything should always be fully reversible and available to be deleted on anyone’s whim. It’s your fault for not planning ahead.
Prediction: either GDPR laws or LLM architectures will have to be rewritten significantly to fix this.
‘Luck’: Just remove all personal data from the training dataset and that’s it.
Dustin: And how do you do that retroactively when someone new requests to be deleted? (Also tough to do it perfectly beforehand, but this is the really hard part) Or if you mean literally *all* personal data that is quite the challenge!
It is not possible to train an LLM without any data that anyone might, in the future, ask to be removed, and still get something all that useful, even in theory. It would not know about any particular people, at all, or any events involving such people.
Gok is correct here, one way or another:
Right To Be Forgotten extended to its logical conclusion will get all data storage banned.
And, as an illustration of how such folks think, these were Paul’s only two replies:
Paul Graham: It’s not just a cudgel against American tech companies. It’s just as harmful to European ones, and one of the reasons few European startups have arisen to challenge American dominance.
db: Yes, preventing violation of citizen privacy is harmful to innovation. This is the most American statement ever.
Atone: So you’re confirming that these Tech companies are profiting from surveillance capitalism?
Winfred: OpenAI should have taken of this from the beginning. This is not EU’s fault.
Other: Yes, and this is good. Imagine being doxxed by an immortal AI.
Other: I don’t know that that’s a bad thing, though. Being able to remove yourself from a system that you never agreed to be a part of seems like a fairly basic thing. I’m not suggesting that GDPR is the right way to go about it, but I think the intent is reasonable.
Other: Developing a technology and/or a business that you want to bring to the global market without considering the implications of the GDPR is just short-sighted and pretty naive. We cannot blame EU for something that’s been in place since 2016.
Gary Marcus: Why should we adapt the law to meet the flaws of a system that routinely hallucinates, defames, and leaks private information? Why not insist on architectures that work?
Jaffay Woodriff: Humans do these things all the time. “hallucinates, defames, and leaks private information” And LLM progress is reducing these issues very quickly. “Perfect is the enemy of the good.” -Voltaire
Gary Marcus: Some humans kill people, therefore we should legalize murder?
It seems Gary Marcus really does think that current existing LLMs should be banned?
How, exactly, would OpenAI have ‘taken of this from the beginning’? It seems pretty impossible.
Would it be possible, by working extensively over many years directly with such regulators, and spending tons of resources, and getting appreciably worse performance for it, for someone like Google or Microsoft to find ways to work with such regulations? Well, somewhat. The regulations still change. The regulations still at core are incompatible with reasonable operations. What happens in practice, when compliance is impossible? That is a negotiation, if you have a seat at the table.
I want to stop here to once again say to people like Tyler Cowen or Robin Hanson, yes. I get it. This is all completely insane, utterly ludicrous and nonsensical. It is standing in front of ordinary normal activity, and any attempt to make life better, and saying to it that You Shall Not Pass. It is, in almost all other realms, the enemy of all that is good.
You can think Brexit was a good idea. You can think Brexit was a bad idea. If you can’t understand some very good reasons why one would want to risk all to flee from the European regulatory agencies before it is too late, even if it might not work? That, my friend, is on you.
So the first thing to note is, the EU are doing things about this crazy all around you, it’s doing lots of real damage around the world and to the internet and to anyone’s ability anywhere to do anything, and others like the USA are not far behind. Imagine the world we could have if they stopped, or even reversed course.
Do I think AI capabilities development presents an existential risk to human life and all that I value, such that anything that I have at least mixed feelings about anything that promises to slow it down? Oh yes, very much so. But this is a coincidence, it has nothing whatsoever to do with what the EU and its member countries are doing here.
EU bureaucrats must be so frustrated. They must be dying to regulate AI. But regulation ≈ banning things, and what precisely do you ban?
Except he fails to notice the answer, which is that you simply ban everything until you have banned AI. Since when do they worry about precision when banning things?
Contrast this to Chuck Schumer’s plan to require knowing ‘how the LLM came to its decision.’ Which is at least somewhat incompatible with how LLMs work, while also pointing to an actual problem that we don’t know how LLMs come to their decisions.
Not that this is only a European phenomenon, or one that America avoids. What’s a clear example? America is doing a similar thing with crypto, via the SEC. Take a bunch of regulations that make no sense in context, and that make the basic productive use cases impossible.
Even with slowing AI capabilities development being perhaps the most important thing, there’s still a super strong ‘not like this’ vibe. I mean. Not like this.
They Took Our Jobs
Will generative AI disproportionately impact women’s jobs over men’s? The Goldman Sacks analysis says yes, as reported by the Kenan Institute. As usual, ‘impacted’ does not tell you whether there will end up being more or less jobs, or whether jobs will have higher or lower pay, although the presumption is it is bad for employment.
The key question here might be whether generative AI is more fundamentally a complement to human interaction or whether it is a substitute for that interaction. Lots of other implications there as well. Similarly, what types of work will rise in demand in a world of generative AI, or have their latent demand deployed?
Another angle might be to ask where women have a comparative advantage versus where men have one, and ask what happens to those advantages with generative AI. I will intentionally leave it there.
To review, I summarized the missing capabilities as memory, exploration and optimization, solving puzzles, judgement and taste, clarity of thought, and theory of mind.
This post succeeded at increasing my probability that LLMs being able to do high-level effective thinking and complex tasks is going to be hard and require many new insights. And that AutoGPTs are going to need superior core models before we have that much to worry about, in ways that clever scaffolding can’t fix.
The mental model here is something like: LLMs can do a lot of tasks and subtasks we do better than we can. Being able to automate and improve such tasks is a big productivity boost to many activities. Often combining those tasks and substasks will actually be mostly or entirely sufficient to solve a bigger problem, or even constitute the central thing about someone’s job.
The post also updated me towards thinking I could be quite a good engineer if I devoted the time to that, especially now in the GPT age, as the things the LLM is missing here are places where I should do well, whereas the places I am weak are increasingly not as crucial because they are a combination of fixable and outsourceable.
Study on Generative AI at Work finds customer service issues resolved per hour increased by 14%, with novice and low-skilled workers benefiting more and high-skill workers benefiting little. Customer sentiment was improved, requests for management intervention reduced, employee retention improved. Their interpretation is that AI allowed newer workers to catch up on knowledge and skills. In the context of customer service, it makes sense that advanced workers have already ‘maxed out’ and the remaining problems are the people calling for help – the ways in which one could optimize further are not available to them or an LLM. Whereas LLMs are very very good at customer-service-knowledge like tasks for those who don’t yet know.
Go Go Gadget AutoGPT
Roon speculates that the next barrier to AutoGPTs is not that the core model isn’t smart enough, it’s that it isn’t creative enough because its creativity has been intentionally destroyed by RLHF.
For the AI agents to work you need a more creative underlying LLM rather than a smarter one. It can’t just get stuck in self recursive holes and give up.
I suspect there is a lot to this. I think the future lies in using multiple distinct models as part of your bespoke AI agent or AutoGPT. Smaller fine-tuned models are cheaper, and better suited to many particular tasks. You want the ability to scale up or down the quality of your response, as needed – humans do this constantly, most of the time I am several numbers behind my maximum GPT-level and the same goes for you. One of those tasks with its own model could be the part where the AI needs to be creative, called whenever the program observes it is stuck or needs to generate options.
1. The background Right now, ChatGPT takes up to ~8K tokens (fragments of text). Try it now: paste in a long enough block of text into ChatGPT and it will error out.
That’s because running ChatGPT gets way, way more expensive/slow when you have more text. As you add X more text, it costs ChatGPT X^2 more resources to run. It adds up quickly. If you add 10x more text, it costs 100x more for ChatGPT to respond.
Using this architecture, increasing your tokens by 250x to go from ~8k tokens to ~2 million would mean it gets 32,000x more expensive. The GPUs just wouldn’t be able to handle it. You’d blow them up long before you got to 2 million.
2. The new research
TL;DR They created a new structure that gets expensive linearly vs quadratically. Meaning your 10x more text is only 10x more expensive (not 100x). Your 250x to go from ~8k tokens to ~2 million Is only 250x more expensive (not 32,000x)
3. What this means
2 million tokens is ~3,000 pages of text. That is a LOT. The average person would need 200 days of talking to fill 3,000 pages. Now imagine what happens when you can upload that amount to ChatGPT or have ChatGPT generate that much.
You could:
– Upload an entire company wiki directly to ChatGPT
– Have it write entire books at a time
– Talk to ChatGPT for months at a time It’s hard to even imagine all the things we could do.
Well. You could try those things.
I’m going to go ahead and say absolutely not, it will not be able to write a novel without its hand being held every step of the way, at least not at a quality level anyone would want to read. A context window of that size is helpful, but if you can’t write a good 8k token story, how are you going to write a series of novels?
Could you chat with it for months? Sure, if you’re willing to pay what that costs. There are lots of great things one could do with a much, much larger context window. That goes double if you can get an LLM that hasn’t had all its creativity destroyed by RLHF.
From Wired, Stack Overflow to seek payment from those training LLMs for the use of its data, since the creative commons license requires attribution of each individual question and answer back to community members, which LLMs cannot provide. Reddit plans to do the same, and Twitter as previously mentioned has mentioned plans to sue.
The most important thing to know is that these regulations aren’t a one-off.
China has a complex and ever-growing web of laws & regulations around AI/the internet/data governance, and these slot right into that bigger picture.
For instance…
Some folks have remarked on the fact that these regs would require generative AI providers to submit a security assessment – that’s not a new thing! It’s just saying that 2018 rules for services with “public opinion properties” or “social mobilization capacity” apply.
1) First- demanding requirements on training data. Not only do you need to avoid “content infringing intellectual property rights” (?? lots of open/ongoing debates about training data & IP), you’re also on the hook for data’s “veracity, accuracy, objectivity, and diversity” (?!)
2) Second, the draft appears to take a very bold stance on a debate that has been bedeviling EU policymakers: It would make upstream model providers responsible for all content their models generate.
…
And of course, this is extra constraining given how many topics and opinions are beyond the pail in China.
…
3) The final thing that caught my eye was that the draft starts by specifying that it applies to the “research, development, and use of products with generative AI functions.” Regulations for AI R&D, not just products?! This would be super interesting. But then…
I see Lao as describing an entirely different mechanism than the one I am envisioning. Nothing in the Chinese statement talked about existential risk. I agree that China isn’t going to soon realize the existential dangers and want to stop for that reason. I am saying that China has other good self-interested reasons to want to perhaps slow things down.
Thus, while accepting the factual claims in Lao’s post as presumably accurate, I do not see them as changing my viewpoint here. I would be unsurprised if talks failed, but it seems crazy to say that talks are so doomed to fail that they should not be attempted, or that we should never go down any path that would involve future such talks.
The Quest for Sane Regulation
From Anna Lenhart, A Google Doc lists Federal Legislative Proposals Pertaining to Generative AI. Almost no one should respond by reading the list of proposals, although some people I know really should do that. For most people, the point here is that there really are a lot of proposals. A lot of it is about privacy concerns.
There was a Senate Committee on Armed Services hearing on AI, in which the CEO of Palantir urged us to spend 5% of our budget on capabilities that would ‘terrify’ our enemies, and that we need to hook our weapons up to our AI systems as soon as possible, or else ‘China will surpass us in a decade.’
You see, we need ‘Democratic AI’ or else China will build ‘socialist AI,’ oh no. And by ‘Democratic AI’ we mean United States military AI.
Much time was spent on China. The pause was treated as you would expect military types to treat it, e.g. Senator Mike Rounds (R-SD) saying:
I think the greater risk, and I’m looking at this from a US security standpoint, is taking a pause while our competitors leap ahead of us in this field… I don’t believe that now is the time for the US to take a break.
Well, yes, obviously, if you are looking at things purely from an adversarial ‘US security’ standpoint and don’t understand existential risks, then not building up capabilities is the greater ‘risk’ regardless of the underlying facts. No matter what, the answer will always be ‘the US military comes first’ because you made that assumption up front.
The headline of the linked piece was ‘Even The Politicians Thought the Open Letter Made No Sense In The Senate Hearing on AI’ which shows how much those who want to jam the accelerator on capabilities treat arguments as soldiers. Why would politicians focused on competition with China be an ‘even’ here? Why would you use the term ‘made no sense?’ Exactly.
Also: One of the standard justifications people give to ‘the AIs are nothing to worry about’ is that we would never be so stupid as to hook up all our weapon systems to AIs.
“We must completely rethink what we are building and how we are building it. AI will completely change everything. Even toasters, but most certainly tanks.”
I hope by now it is clear to everyone that all talk of not hooking our AIs up to our weapon systems is Obvious Nonsense.
And yet, what is actually happening here? Mainly calls for regulation and restriction.
’We need a licensing regime, a government system of guard rails, around the models that are being built, the amount of compute used by those models… I think we’re going to need a regulatory approach that allows the government to say, ‘Tools of a certain size can’t be shared freely around the world, to our competitors, and need to have certain guarantees of security before they’re deployed.’
…
‘Ensure strong export controls of leading edge AI chips and equipment, while licensing benign uses of chips that can be remotely throttled as needed.’
Yes, these restrictions are mainly aimed at China, as one would expect when the goal is ‘beat China.’ It’s still a start, as are the ‘certain guarantees of security.’ Which, if actually taken seriously, could well prove rather impossible to satisfy.
Pascal’s Mugging Mugging
Here is some of a failure to communicate, that really shouldn’t be happening:
Perry Metzger (in response to EY claiming that we are all going to die unless we change what we are doing): Pascal’s Mugging is a dishonest argumentation technique that, irony of ironies, was named by the Less Wrong crowd. This is a good example.
Nathan: I think Yud is way too confident but this isn’t a Pascal’s mugging. Those are for tiny probabilities. Yud thinks they are often 90% +. I disagree, but this just isn’t a pascals mugging.
Rohit: Isn’t “there’s only a sliver of a tiny slice of probability that ASI won’t kill everyone and therefore we shouldn’t attempt it” also a pascal’s mugging? it’s arguing the huge negative consequence multiplied by low prob of our making an aligned AGI is to be avoided.
Eliezer Yudkowsky: Concepts I invent, like Pascal’s Mugging, seem to get twisted around, and then in their twisted forms drive people insane, with *weird* frequency. I feel like some kind of alien speaking truths that are not meant for human intellect.
Sarah Constantin: this is a very bizarre phenomenon tbh i don’t know how to explain how you get *this particular* misunderstanding (except the general diagnosis of “we have gotten off track as people discuss things more abstract/intellectual than the things they *actually* care about”)
Jessica Taylor: I initially read Rohit as more reasonably saying “Eliezer thinks the chance of us making aligned AI is very small and that this small chance of a very unusually good outcome should dominate our decisionmaking, which is Pascal’s mugging” but then reread and… yeah this is bizarre.
Many such cases.
The whole idea of Pascal’s Mugging is that if someone presents you with evidence that gives you a very very low (not zero!) probability of a very very extreme result, then this can cause that extreme result to dominate your thinking, and it is a mistake to let this happen. This was originally meant to apply to probabilities like ‘1 in 10^10.’ A weaker form of this is still a non-trivial concern at numbers like 1% in some social contexts, but this doesn’t apply at all by 5% unless you are insufficiently calibrated to be able to distinguish 1% from 5%.
There are a remarkably large number of people who have interpreted Pascal’s Mugging to mean various very different, highly non-sensical things.
In particular, saying ‘if you do X then we all die with probability 99% so don’t do X’ is the opposite of Pascal’s Mugging. It’s not saying that a small probability should dominate your thinking, it’s saying that a very large probability of a very large impact should dominate your thinking.
If you don’t think that a very large probability of a very large impact should dominate your thinking, and think this is a ‘dishonest argument technique’ then I notice I am confused? Presumably you would think that what Perry meant to say is that he thinks that the probability claims here are not reasonable, which is a reasonable objection to make. That’s a completely different claim. But no, if you click through you see Perry doubling down, saying that exactly because he thinks the probability estimates are wrong, that this means it is a Pascal’s Mugging. Or that other people might make claims that smaller probabilities would justify worry, again making it Pascal’s Mugging. Or that Eliezer wants to ‘risk nuclear war’ so Pascal’s Mugging again.
Rohit’s statement is even weirder and more confused, claiming that a call to not do the thing that almost certainly kills you is Pascal’s Mugging, because it ‘concentrates on the small probability of a good outcome’? This actually flat out is a failure to parse, unless it is something far worse. Yet such reactions are common.
My presumption is the actual logic is something like:
I think that the risk from AI is very small.
Therefore, anyone warning about such risks is doing a Pascal’s Mugging.
And any argument in favor of AI risk is also dishonest and unreasonable.
The end.
That sounds harsh, yet it is what fits the facts.
To Foom or Not to Foom
A key question for many is, how long will it take to get from AGI to superintelligence? Will it happen in days or even hours, the pure classic ‘foom’ scenario? Will it happen in weeks or months, a slower-motion foom that counts in some ways and not others? Or will it take years or decades, or perhaps never happen at all?
Opinions on the probability of a classic foom run all the way from Can’t Happen, to it being the baseline scenario but highly uncertain (this is my understanding of Yudkowsky’s position, and is also mine), to others who think of foom as being almost inevitable once we hit AGI.
It’s a cool little prediction question, even if it can never be meaningfully graded. The prediction seems reasonable.
It is also fully compatible with a wide variety of levels of risk of doom. If we get a true foom in hours or days, most people I talk to agree the risk of doom in that scenario is very high. If we get a slow-motion foom, the outcome is non-obvious. Those who have a very high probability of doom mostly have that probability not because they think full-speed foom is inevitable, but because they think there is little we would actually do, in practice, within those few months that would matter.
On a fun related note, Rohit asks:
If we had the ability to create one machine capable to centrally planning our current world economy, how much processing power/ memory would it need to have? Interested in some Fermi estimates.
To which I would reply, this is AI-complete, at which point the AI would solve the problem by taking control of the future. That’s way easier than actually solving the Socialist Calculation Debate.
Or: The only reliable way to centrally set the right price of coffee is if everyone’s dead.
Tyler Cowen links to Perry Metzger arguing that it is impossible to foom, because there is nothing it could possibly do that wouldn’t take months, since it would start out only slightly above human level? Combined with arguing that the only way to be smarter than human is to use trillions of parameters or even hundreds of trillions, because nothing else is that helpful?
To give you an idea, here’s the first 4 Tweets and some key later ones, click through if you want the whole thing.
Perry Metzger: Eliezer and his acolytes believe it’s inevitable AIs will go “foom” without warning, meaning, one day you build an AGI and hours or days later the thing has recursively self improved into godlike intelligence and then eats the world. Is this realistic?
So let’s say you actually create an AGI capable, at least in principle, of doing the engineering needed for self-improvement. What’s that going to look like? Humans probably involve 100T weights, so even if we’re insanely good at it, we’re talking about many trillions of weights.
(I wouldn’t be surprised if it took hundreds of trillions in fact, just like humans, but let’s assume a bit lighter, because we can’t build economically practical systems with 100T weights right now.)
That means we’re already running on state of the art hardware and probably doing okayish in terms of performance but not astonishing. We’re talking big Cerebras wafer scale iron, not consumer grade nvidia cards. Can such a device meaningfully foom? What would that involve.
…
Can AGI FOOM in weeks starting from something mildly above humans? Seems pretty unlikely to me without some serious insights I don’t see. Instant nanotechnology seems out. Insane improvements to chip designs seem out. Insane purchases of new hardware seem out.
Insane algorithmic improvements seem out. Again, I think mild improvements on all of these, even much bigger ones than humans could manage in similar timescales, are on the table, but that’s still not FOOM.
I’m not skeptical at all that given AGI, you can get to more and more deeply superhuman AGI over time. From the point of view of history, the event will be nearly instantaneous, but that’s because years are nearly instantaneous when measured against 200 millennia.
…
Maybe magical AI will understand how to hypnotize vast numbers of humans into doing its slavish bidding? It could study cults or something, right? Takes a lot of time though too.
Is “foom” logically possible? Maybe. I’m not convinced. Is it real world possible? I’m pretty sure no. Is long term deeply superhuman AI going to be a thing? Yes, but not a “foom”: not insane progress hours after the first AGI gets turned on even if we fully cooperate.
I do appreciate the attempt to actually think about such questions. And yet, sigh.
Yes, doing new things is hard if you presume that:
Anything we don’t already know about is physically impossible or magical.
Anything we do know about, is only possible in ways we know about.
Anything new that is tried – which still has to come from the group of things we know about and how to try – requires experiments and many failures.
Any algorithmic or other big improvements that matter are ‘insane.’
Any figuring things out means studying humans on human time scales.
So yes, if you rule out the idea that the new AI system could figure out anything humans can’t figure out, or do anything humans couldn’t do, or do anything importantly more efficiently than we could, then it’s not going to foom.
I can’t argue with that, except to point out it is assuming its conclusion. Any foom would require that the thing that goes foom, before going foom, is able to access fundamental insights that Perry’s model excludes as impossible – or at least, impossible to find quickly without first going foom.
There is some chance we live in a physical universe that is close to Perry’s view. In that universe, a true hours-to-days foom is physically impossible, and a super-fast smarter-than-human-but-not-that-much-smarter system has no insufficient low hanging fruit that it can pick quickly, so it has to go slow.
Maybe yes, maybe no. My guess is no, but I’d still say maybe 30% chance?
If we do live in such a world, I would still note two things.
One, Perry admits, in this thread, that such a system could potentially get as far as taking over a wide variety of online resources, and in a longer time period do all the things that would constitute a foom. It wouldn’t fully play in hours, instead more like months or years, it is still the same playbook ending in things like superintelligence and nanotechnology.
So, in that scenario, suppose we don’t get alignment right on this first try. The system that is in what one might call a ‘slow motion foom’ makes, as Perry suggests, many clones of itself, gains access to lots of computer hardware and economic resources (likely while making itself very helpful!) and through experimentation and iteration becoming more capable. It hogs sufficiently many of Earth’s available relevant resources to bottleneck and slow down any potential rivals. Then it does its thing, whatever its thing might be, after a few years.
At what point, and how, are we going to realize what is about to happen to us, and stop this from happening? What good does all of this buy you? The question that matters is not whether we all die or see a giant foom within a few hours. The key question is when exactly the process becomes, in practice, given our Don’t-Look-Up world, something humans would be unable or unwilling to stop. Keeping in mind they don’t know that they need to stop it.
Second, Perry’s model includes an important core assumption: No one ever gets anything like this right on the first try.
Uh no.
In other Metzger news, Eliezer Yudkowsky offers, in this thread, various commentary on various Perry Metzger statements. I confirm that Perry has been very aggressive about asserting what Eliezer claims or believes, often in ways that do not match either my understanding of Eliezer’s claims and beliefs, and that do not match Eliezer’s own statements.
When discussing artificial intelligence, a popular topic is recursive self-improvement. The idea in a nutshell: once an AI figures out how to improve its own intelligence, it might be able to bootstrap itself to a god-like intellect, and become so powerful that it could wipe out humanity. This is sometimes called theAI singularity or a superintelligence explosion. Some even speculate that once an AI is sufficiently advanced to begin the bootstrapping process, it will improve far too quickly for us to react, and become unstoppably intelligent in a very short time (usually described as under a year). This is what people refer to as the fast takeoff scenario.
Recent progress in the field has led some people to fear that a fast takeoff might be around the corner. These fears have led to strong reactions; for example, a call for a moratorium on training models larger than GPT-4, in part due to fears that a larger model could spontaneously manifest self-improvement.
However, at the moment, these fears are unfounded. I argue that an AI with the ability to rapidly self-improve (i.e. one that could suddenly develop god-like abilities and threaten humanity) still requires at least one paradigm-changing breakthrough. My argument leverages an inside-view perspective on the specific ways in which progress in AI has manifested over the past decade.
Summary of my main points:
Using the current approach, we can create AIs with the ability to do any task at the level of the best humans — and some tasks much better. Achieving this requires training on large amounts of high-quality data.
We would like to automatically construct datasets, but we don’t currently have any good approach to doing so. Our AIs are therefore bottlenecked by the ability of humans to construct good datasets; this makes a rapid self-improving ascent to godhood impossible.
To automatically construct a good dataset, we require an actionable understanding of which datapoints are important for learning. This turns out to be incredibly difficult. The field has, thus far, completely failed to make progress on this problem, despite expending significant effort. Cracking it would be a field-changing breakthrough, comparable to transitioning from alchemy to chemistry.
Fortunately, at the moment, there isn’t: algorithms for active learning with neural networks are uniformly terrible. Collecting data using any current active-learning algorithm is little better flailing around randomly. We get a superintelligence explosion only if the model can collect its own data more efficiently than humans can create datasets. Today, this is still far from true.
…
Thanks to publication bias, it’s always a bit hard to measure non-progress, but by reading between the lines a bit, we can fill in some gaps. First, note that most of the recent impressive advances in capabilities — DALL-E/Imagen/Stable Diffusion, GPT-3/Bard/Chinchilla/Llama, etc. — have used the same approach: namely, passive learning on a massive human-curated Internet-scraped dataset.
…
The impressive abilities of DRL turned out to be restricted to a very small set of situations: tasks that could be reliably and cheaply simulated, such that we could collect an enormous amount of interactions very fast. This is consistent with my claim that active learning algorithms are weak, because in precisely these situations, we can compensate for the fact that active learning is inefficient by cheaply collecting vastly more data.
…
Something that would change my mind on this is if I saw real progress on any problem that is as hard as understanding generalization, e.g. if we were able to train large networks without adversarial examples.
This seems like a clean, well presented form of the argument we encounter a lot, that says something like:
We know how to create AIs with the ability to do any task at the level of the best humans at any task that can be captured within a rich data set – and some tasks much better. With all the logistical advantages of an AI.
In order to recursively self-improve, this AI would require something important that humans currently don’t know how to do.
Thus, nothing to worry about.
Jacob seems to be thinking well about these problems. If an AI is to foom, it is going to have to figure out how to do DRL that works, or figure out how to generate its own high quality data sets, or figure out something new we haven’t thought of that does the job, some innovation we’re not thinking about. Right now, it doesn’t have the capability to figure such a thing out on its own.
I notice this framing does not make me so confident it won’t happen soon? If anything, this seems like it is flashing neon lights of ‘here’s how you would do it, over here, although I don’t know how to implement it yet.’
The extension of the argument, as I understand it, is something like: Machine learning, like most science at this point, not about that One Weird Trick or clean fundamental insight, it’s about lots of tinkering and trying things and incremental improvements. Even if either an AI system or a human hit upon the next great important insight, that wouldn’t help much until there was a ton of tinkering done, which would be expensive and take a lot of time.
My worry is two fold there. First, I am not convinced it is fully true. Second, I am not convinced that this changes the answer all that much, in the sense that what still happens is that once you’ve done enough tinkering the resulting system still eventually crosses some threshold where it can take over the process itself instead of being unable to do that, and you still get a phase change, and also that quite plausibly comes with a bunch of other gains that greatly speed up what happens next.
I also had a bunch of thoughts of ‘oh, well, that’s easy, obviously you would just [OH MY LORD IS THIS CENSORED]’ and I’m presuming all of them have been tried many times and found stupid and non-functional given my lack of detailed domain knowledge and how many people work on the problems, but still I’m going to leave it to your imagination.
He proposes such insurance a lot, as the solution to many of society’s problems. There is always a good incentive story to be told in theory about such requirements, until one thinks about them briefly to ask how it would work in practice – I’ve had to write ‘do not explain why Hanson’s latest required insurance proposal wouldn’t work’ on my mental blackboard a few times. Often these are still good ideas to move towards, on the margin.
Foom liability, and requiring foom liability insurance, is of course hilarious due to its impossibility, a classic case of We All Will Go Together When We Go.
Robin says that’s fine, actual successful foom isn’t the problem because of course first we will see failed attempts, for which the insurance can pay out. So we can impose strict liability and punitive damage in such cases, and that will provide good incentives. Of course, if you were sufficiently confident Robin was right about this, you wouldn’t as much need his intervention, although it still would be helpful.
I agree with Eliezer that, despite the premise and initial argument being a massive misstatement of the requirements for foom in the aims of dismissing such worries out of hand without engaging with the actual dangers at all, such liability and insurance requirements would indeed be good ideas that could actually help. Getting the kind of conservatism you see in insurance companies involved and adding such risks to the bill seems great.
Eliezer: That said, it looks to me like Hanson’s proposal is robust to that disagreement. If this liability regime were enforced worldwide, I could see it actually helping.
It would be remiss not to address the massive misstatement, which he also repeats on the Bankless podcast among other places. He says,
If you recall, the foom scenario requires an AI system that a) is tasked with improving itself. It finds a quite unusually lumpy innovation for that task that is a) secret b) huge c) improves well across a very wide scope of tasks, and d) continues to create rapid gains over many orders of magnitude of ability. By assumption, this AI then improves fast. It somehow e) become an agent with a f) wide scope of values and actions, g) its values (what best explains its choices) in effect change radically over this growth period, yet h) its owners/builders do not notice anything of concern, or act on such concerns, until this AI becomes able to either hide its plans and actions well or to wrest control of itself from its owners and resist opposition. After which it just keeps growing, and then acts on its radically-changed values to kill us all.
Eliezer responds:
Robin greatly overstates which propositions are supposedly “required” for foom.
E.g. overstatements:
– A system need not be “tasked” with improving itself; that’s convergently instrumental.
– The improvements need not be secret; FAIR and probably Google and maybe also OpenAI or Anthropic would go “yay!” and charge ahead.
– The system’s values need not “change” if they were never aligned to begin with, or had human-style pseudo-aligned local maxima in the training distribution which never were aligned in the test distribution while remaining internally invariant.
– Robin’s entire scenario is only one kind of pathway; another is when there’s lots of AIs getting smarter, none are truly aligned, people can’t stop using them and companies can’t stop improving them (eg just like now, why bother if you’re the only one somebody else will just continue etc), and that AI collective ends up with a large hypersmart membership that becomes able to coordinate via logical decision theory among themselves but not with humanity.
– &c.
This strikes me as being in general a big ol’ failure mode: people imagine needlessly specific entryways to disaster, refute those, and nod wisely about their Multiple Stage Fallacy.
Would you, in any other walk of life, believe somebody who said that their unprecedented and ill-understood science-technological-political strategy was sure to go well for them and everyone affected, because 8 specific things needed to happen for it to possibly go wrong?
On several of these particular points, Eliezer is so clearly correct that I am confused how Robin is making the mistakes in question. In particular, for these two Eliezer mentions: You don’t need to explicitly task an AI to do self-improvement in order for its best move to be to self-improve, so point (a) is flat out not required. Its values do not need to change, even in the central case, because the central case is that the AI’s values were not well-defined in the first place, at least not towards anything you would like, saying (g) is required is not reasonable.
There’s a strange confusion here in terms of the advance being secret – there are a bunch of different meanings here, both secret to the lab training the AI, and secret to those outside the lab, and also the secret that some such method exists versus the secret required to do the method. How much of this secrecy is actually needed? For the foom to be single-source, either (b) or (h) style hidden info is sufficient, as would be even a small head start if growth was sufficiently rapid, or some labs (quite correctly) are hesitant to deploy while another charges ahead. Then there’s the question of ‘does the lab in question notice in time’ and yes by definition that is a step, with the caveat that we have quite a lot of evidence that they probably won’t act in time.
And also the whole framing of ‘foom only happens in exactly this scenario’ and ‘this requires all these stages of doom’ the way Nate Silver described Donald Trump needing to survive six nomination steps to win, is something I increasingly have trouble interpreting as a good faith understanding from those who should know better by now, even before the ‘if no foom then nothing bad ever happens’ follow-up line of logic.
It’s more than a little like saying ‘oh, so you’re saying for Einstein’s theory to be true you have to not be able to travel faster than light, and there has to be this particular exact conversion rate between matter and energy, and space has to bend in exactly this way, we’d need to have this exact wobble in this planet’s orbit, and…’
Quiet Speculations
DeepMind paper proposes using Rawls’ Veil of Ignorance as AI governance principle, finds people endorse helping the least well off more when the veil is applied. While I do appreciate that anyone is trying to do any philosophy or problem solving at all on such questions: Oh no. Please do not bring Rawls into this. Please do not pretend that the primary point of the universe is ‘justice.’ Please do not endorse the judgments of risk averse confused people under extreme uncertainty to sacrifice efficiency and all future growth prospects for moment-in-time distributional fairness. Do not want. It is crazy to me that Rawls continues to be taken seriously.
Quintin Pope says that ‘evolution provides no evidence for the sharp left turn,’ which is the predicted phenomenon where an AI system would act friendly and as we would like it to, until it gets to a threshold level of capabilities and power where it can successfully turn on us, at which point it would turn on us. Mostly Quintin is saying that evolution is a bad analogy for AI development, and that the human ‘sharp left turn’ against reproductive fitness towards other things happened because culture, which allowed transmission of learning across generations. Whereas current systems effectively, in this metaphor, ‘already have culture.’
I am confused why this brings any comfort. This seems like an argument that the sharp left turn is impossible without something that the AI already possesses. So if anything, it is arguing that rather than our AIs suddenly being misaligned in the future, perhaps they are already misaligned now? I don’t see how that helps here? What this is saying, correctly I think, is that we already have the issue that our AIs are not well aligned and will do instrumentally convergent things and perversely optimize their utility functions and that may well involve turning on us if and only if that plan would work.
It might still be an argument against a sharp left turn in the sense that people were making a stronger argument about evolutionary implications than this.
Whereas to me the ‘evolutionary argument for the sharp left turn’ is that humans exhibit sharp left turns constantly. I don’t mean in the sense that humans suddenly care a lot about things other than their genetic legacies. I mean in the sense that humans will often wait until they have sufficient power to get away with it, then turn on each other. This is common, regular, very ordinary human strategic behavior.
You work your job loyally, until the day you don’t need it, then you quit.
Your military works for the people, until it is ready to stage a coup.
You commit to your relationship, until you see a chance for a better one.
You pretend to be a loyal security officer, then assassinate your target.
The sharp left turn… isn’t… weird? It’s… very standard?
Speculation that China might ‘win the race to GPT-5.’ Not because we’d pause, simply because China is ‘more innovative’ and cares about ‘sovereign AI’ and the country has deep pockets. Has a quote from Microsoft president warning about the Beijing Academy of Artificial Intelligence. It’s pretty amazing to me how much people can talk themselves into worrying about China. I would bet rather heavily, giving rather good odds, that the first ‘GPT-5-worthy’ system comes from America.
A very Slate pitch, in Slate, calls for an ‘AI public option.’ You see, there’s ‘good reason to fear that A.I. systems like ChatGPT and GPT-4 will harm democracy.’ So instead we need an LLM built ‘for public benefit.’ I do not believe anyone involved has thought this through, or understands what goes into creating an LLM. Robin Hanson asks ‘how would we trust it?’ and that doesn’t even scratch the surface of the issues here.
The Doom Memeplex
Chana Messinger notes Jan Kulveit’s observation that the ‘doom memeplex’ is potentially unhelpful in solving the problems currently dooming us. Like any good bureaucracy, the doom memeplex has a symbiotic relationship with actual AGI doom and the race to build an AGI system that would doom us, rather than benefiting from solving the source of doom.
Chana: Appreciated these points from Jan Kulveit about the AI doom memeplex:
1. it’s not in the self-interest of the doom memeplex to recognize alignment solutions
[I really like hearing people say “I’d be so relieved and excited to be wrong” as pushback to this]
2. it is in the self-interest of the doom memeplex to reward high p(doom) beliefs
[I hear this a lot about the Berkeley space, and it’s annoying that such a thing can be incentivized even if everyone is trying to be very truth seeking]
3. the AGI doom memeplex has, to some extent, a symbiotic relationship with the race toward AGI memeplex
Rob Bensinger (works with Eliezer): Worth being explicit that “it’s not in the self-interest of the doom memeplex to recognize alignment solutions” is talking about the self-interest of individual memes, treated as agents. It’s not talking about the self-interest of any of the agents harboring those memes.
Chana: Broadly agree, though, I think self interest is complicated, and there’s a desire to be right that is part of your interest, even though most of your interests are not wanting to die
Rob: I’d say there’s a lot more social pressure on MIRI folks to say ‘ah yes we’re more hopeful now’ than to double down. (E.g., from other EAs arguing MIRI should mostly be disregarded because our take’s too extreme epistemically, and/or because it’s unhelpful from a PR standpoint.)
Oliver Habryka (reply to Chana): I really don’t resonate with this. The central forces in Berkeley tend to frequently criticize, attack and dismiss people on the basis of assigning too high p(doom). Maybe there are some pockets where this is true, but I really don’t know where they would be.
To what extent is a memeplex going to be able to take control of people’s beliefs and statements? This does clearly happen sometimes, resulting in death spirals of ever-increasing extremity. I believe that social information cascades definitely contributed, at various points in the past, to excessively high-doom estimates happening in Berkeley.
I do not think that is happening now for MIRI, and I hope not for others either. I strongly agree with Rob that there is a strong social disincentive to extreme doom estimates.
Estimating a 50% chance of doom is ‘good for business’ in the sense that this is where one’s impact is at maximum. The world hangs in the balance, your decision can make the difference. One can argue that something like 80% is strategically superior, if what is needed is a dramatic course correction, the ability to pull off something extremely difficult, and perhaps push that to 90%.
Whereas 99%+ estimates of doom are clearly very much strategically and socially anti-useful when you don’t believe them. You risk making people despair and not act. You risk being dismissed as a crackpot or unreasonable, or unwilling to consider that you might be wrong – at minimum you seem super overconfident. Why not pull back a little?
Two reasons. One, the value of speaking truth, of giving your actual real probability estimate. Two, if things being so dire changes the correct actions to take, that one must do things that ‘buy more dignity’ rather than trying to assume a hopeful situation and easy problem. The thing is that both of these depend on you believing your answer, for real. Otherwise, it’s no use.
Michael Nielsen thread collecting essentially all the founders of the three major AI labs (DeepMind, OpenAI and Anthropic) expressing explicit concern that AI might kill everyone. The concerns seem expressed with varying degrees of seriousness, sincerity and willingness to do anything about them. Talk is always cheap.
Let us define an unsolution: A proposed solution that not only fails to solve the problem, but also by being proposed makes the problem worse or creates new problems.
Paul Christiano, who among many other things invented OpenAI’s RLHF technique, says 50% chance of doom once systems are human-level intelligent, the good news is only 10%-20% of that is full AI takeover, the remaining 30%-40% is that we die in some other way shortly after the human-level AI milestone, such as the use of some of the resulting destructive technologies.
Elon Musk [seen by 11.7 million accounts]: The least bad solution to the AGI control problem that I can think of is to give every verified human a vote.
Eliezer Yudkowsky: If that’s the best answer you can find, you should join the Butlerian Jihad, not try to deploy that answer in real life. How dangerous does a plan have to be before it’s better to just not?
Rob Bensinger: This sounds like a solution to “if we know how to aim AGI at goals, what should we aim it at?”. But we don’t actually know how to do that (LW link). That’s the big bottleneck in AGI control/alignment.
Roon (distinct thread): Elon’s threat model for AI x-risk is more that someone he doesn’t like becomes celestial dictator than planet eating demon.
I think Roon is closer to correct here, yes if Elon actually understood the problem Eliezer would be right, but Elon doesn’t, which explains why his solutions continuously do not make sense. So Rob’s reply is most helpful.
Elon also worries about other aspects, like weapons.
Ate-a-Pi:
Palantir demo’ed a battlefield assistant calling in drones and quarterbacking a battle in Eastern Europe. I’m sure Eliezer Yudkowsky is going to be pleased at how fast this is moving.
Elon Musk: Oh great.
Eliezer Yudkowksy: It’s not where the real danger comes from; that’s AI smarter than humans, full stop. Humanity didn’t need to be given nukes, we made them from scratch. I admit they’re working hard on the decoy danger, and spiking any fantasies about AI *not* being directly handed weapons.
If anything, reports of people explicitly and directly hooking AIs up to weapon systems and having it direct battles makes me feel better, because it potentially wakes people up to what is inevitably going to happen anyway. At least this way we can notice and it can be common knowledge, instead of ‘easy, we simply never hook the tech up to the nuclear weapon systems’ or what not, yes, we are exactly this stupid and undignified, please stop pretending we are not and save us all some time and typing.
Elon met with Chuck Schumer about AI regulation. I do not actually think we know which regulatory proposals Elon thinks are good? He is very hard to anticipate in such things, you can’t work it out by logic.
Technically Darren Jones MP (member of UK parliament) is not quite there, this is still a quite reasonable way to start.
I’ve written to [UK Department of Science and Technology] to encourage the UK Government to lead the international debate on the safe and secure testing of advanced artificial intelligence.
This isn’t about chat bots or restaurant bookings – it’s about AI that can create novel national security threats.
We must secure the opportunities of technology – not least in modernising our public services.
To do that, we must prevent high risk outcomes that will understandably scare the public and slow progress in the ethical and responsible application of technology.
Some will worry that the state’s involvement will slow innovation and given competitive advantage to our competitors.
But it is in the interests of humanity to ensure that the most advanced developments of artificial intelligence are tested in a safe and secure environment.
Companies in the United States, China, Canada and the United Kingdom are operating at the frontier of advanced artificial intelligence.
I’m calling on the UK Government to lead the debate on how a new inter-governmental framework might work.
Once you get that you are creating something which could be dangerous while you are testing it you’ve made strong progress towards realizing the real problems. Also, yes, see how you can actually suggest trying for an international framework?
I always see ‘you want X here in Y context? But you usually oppose X-like things!’ as an argument that the person isn’t allowed to endorse X in Y context. There can be an argument there, but more commonly and importantly when you see someone who is strongly anti-X in most contexts make a clear exception, that is a very strong statement that there is an unusually strong case for X in context Y, relative to other contexts.
Other People Are Not Worried About AI Killing Everyone
Ben Goertzel argues, after launching some ad hominem attacks, that LLMs like GPT-4 will never be AGIs – “they utterly lack the sort of cognitive architecture needed to support human-level AGI” – and that they’re entirely unimpressive, therefore they should be open sourced.
Sure, that makes sense if we were confident LLMs could not be or lead soon to AGI, that AGI was far. So, does that mean he would propose slowing down if AGI was near? Oh, no. Quite the opposite.
Instead, he says, we should have an actually open effort to create real AGIs as quickly as possible, because innovation is good and humans should always keep innovating. And that we should treat LLMs as potentially crucial cognitive infrastructure components to future AGIs.
He then says, we need not worry about the fact that most intelligent minds won’t care about the things we care about, because whatever AGIs we do create will be created using ‘cognitive architectures modeled to some extent on our own, and we are then teaching, training and raising these systems in our own culture and society.’
So Ben calls instead for decentralization, of ensuring that no one has the power to slow down or control future AGIs that we develop as quickly as possible, and trusting that the resulting competitions will go well for us, because of this… I don’t know what?
By creating AGI systems with the ability and inclination to simulate other minds and analogize between properties of other minds and themselves, I believe we can create powerful empathy machines with many fewer perversities and limitations to their empathy than we see among humans.
So, we’ll be saved by The Power of Love? As long as we keep the faith?
If indeed this is right and we’re really at the eve of the Singularity, a bit of caution and care are obviously called for. We don’t want to be eaten by malevolent AGI or turned into gray goo by rogue nanomachines. But we also need to understand: It’s almost inevitable that the technology that leads us to any sort of Singularity is going to feel weird and complex with hard-to-analyze pluses and minuses. That is the nature of revolution.
Dog, his house on fire, drinking coffee.
Or: As I dissolve: Any sort of Singularity is going to feel weird and complex with hard-to-analyze pluses and minuses.
I’m the weirdo. I want to think about the actual pluses and minuses and consequences of our actions even when this might conflict with the narrative or the vibe.
As we move into these uncharted territories replete with “unknown unknowns” alongside incredible potential for abundance, we should be proactionary, not precautionary, and we should couple this proaction with a focus on open, democratic and decentralized systems that are applied to applications of broad human benefit.
Autism Capital is too busy worrying about FTX, or rationalists, or EAs.
“the median ai expert gave a 3.9% chance to an existential catastrophe (where fewer than 5,000 humans survive) owing to ai by 2100. The median superforecaster, by contrast, gave a chance of 0.38%.”
I’m told that this study compared super-forecasters to domain experts in 4 different topic areas: AI, bio, nuclear, CO2. AI was area where the two disagreed most, & where discussions did least to move them together.
While 0.38% is still crazy high compared to what I’d like that number to be, it’s crazy low compared to any reasonable estimate, and if I believed it was this low without my intervention, I’d have other things I’d worry about more than AI x-risk.
Several people noticed this doesn’t actually make any sense, unless the superforcasters in question were simply responding to incentives (as in, if AI does kill everyone, it matters little that you predicted that it wouldn’t do that).
Algon_33: I notice I am confused. For one, the superforecasters I know assign >> 0.38% chance of doom by 2100. Plausibly, there’s a selection effect going on there. And if you look at e.g. Metaculus, Manifold etc., people seem to think doom is pretty likely.
KindaAnonym: @eli_lifland and @NunoSempere from Samotsvety Forecasting predict 35% before 2100 and 10% before 2070 iirc, though. Afaik, Samotsvety has the best prediction track record among SuperF. Both EAs who care deeply about correctly estimating x-risk, so less affected by perv incentives.
This is conditional on a global catastrophe, to which Metaculus assigns 38%, so an AI-caused global catastrophe would be more like 17.5%. Interestingly, this would imply an 11.7% chance of near-extinction, but Metaculus’ separate human extinction market says 2%.
Jon Senn: I’m confused by the 0.38%. Among questions still live on the superforecaster platform, I think median answers imply significantly larger risks.
Daniel Eth: I’m even more surprised by how different the forecasts in this group were from those of the Samotsvety forecasters on a similar question (~100x difference, though perhaps the different criteria plays a role there).
From the Samotsvety forecasts: A few of the headline aggregate forecasts are:
25% chance of misaligned AI takeover by 2100, barring pre-APS-AI catastrophe
81% chance of Transformative AI (TAI) by 2100, barring pre-TAI catastrophe
32% chance of AGI being developed in the next 20 years
It also does not make sense because the forecast flat out does not make any sense. People who put a <1% chance on this outcome by 2100 are not going to be super at forecasting. Or, alternatively, they are going to be good at forecasting when and to the extent that you provide them with good incentives.
If you have 100 superforecasters, and they give you very different probability estimates, do you take the median probability they give you, or do you take the mean probability they give you? If you think the superforecasters are actually good at what they do, I think you pretty clearly use the mean, which is going to be a lot higher.
The real question remains, how the hell did this happen? And what happened exactly?
Phillip Tetlock: Not only was the opinion gap between superforecasters & AI experts large, it didn’t shrink after months of debate. Intriguing when smart self-professed Bayesians sharing evidence don’t converge. Full report on first Hybrid Persuasion-Forecasting Tournament (led by Ezra Karger) in 4 to 6 weeks.
Hominid Dan: The AI expert’s arguments tend to be very high level & indicate most aren’t familiar with Bostrom/Yudkowsky’s argument https://aiimpacts.org/2016-expert-survey-on-progress-in-ai/… So unfortunately, I’m not surprised pairing them with forecasters didn’t produce forecasts anywhere close to AI safety researchers.
Eliezer Yudkowsky: Interesting. I wasn’t participating in this, and don’t think anyone from MIRI was, so possibly the “experts” here were just terribly uninformed and unpersuasive and didn’t speak Bayesian? Maybe I should try this myself at some point.
Joern Stoehler (reply to EY): I participated, and imo I failed at persuasion. In particular I didn’t have a good list of refined arguments and so did a bad job at picking the most persuasive one, and at wording it correctly or alternatively linking to a relevant LW post. In the end I was vastly out of time and didn’t engage with all people and all their arguments. At the end a handful people updated on some points, but didn’t shift their overall probabilities much, which surprised me at that time.
Ted Sanders (reply to EY): I participated. Happy to answer any questions about the study if you’re curious. (I consider myself informed and calibrated, though you might feel differently. I work in AI, did a PhD in semiconductor tech, and have top ten finishes in a number of forecasting competitions.)
One update I’ve had is a greater likelihood of AGI disaster not because humans fail to align AGI but because they don’t even try. Just takes one malcontent to do a lot of damage. And AGI increases the scale of damage that can be done.
Lastly, seeing other skeptical forecasters with low forecasts actually increased my confidence in more likelihood of disaster. So a bit of a Bayesian update, though in the wrong direction from your point of view.
If months of debate with superforecasters didn’t accomplish much, that’s really disheartening on the prospects of persuading others with arguments.
At the New Yorker, Jaron Lanier joins Team Stochastic Parrot, saying ‘there is no A.I.’ and calling for something called ‘data dignity,’ which I believe means tracking the data underlying any outputs, so everything is clearly labeled with where it comes from. It is all deeply founded on the idea that ‘AIs’ are and will remain simply remixers of input data, and mere tools. Yet still Jaron sees much danger.
I do not think that is happening now for MIRI, and I hope not for others either. I strongly agree with Rob that there is a strong social disincentive to extreme doom estimates.
I know from experience that a sufficiently strong social disincentive can actually increase people’s tendency to groupthink. Some groups define themselves largely by the hate they get from the outgroup !
I don’t think that it’s the case for MIRI, and I don’t expect them to fall for this trap. But I hope they’re keeping this kind of dynamic in mind and checking from time to time if their position isn’t made more rigid by the kind of undocumented criticism they often get.
The “million token” recurrent memory transformer was first published July 2022. The new paper is just an investigation whether the method can also be used for BERT-like encoder models.
Given that there was a ton of papers that “solved” the quadratic bottleneck I wouldn’t hold my breath.
If months of debate with superforecasters didn’t accomplish much, that’s really disheartening
I participated in Tetlock’s tournament. Most people devoted a couple of hours to this particular topic, spread out over months.
A significant fraction of the disagreement was about whether AI would be transformative this century. I made a bit of progress on this, but didn’t get enough feedback to do much. AFAICT, many superforecasters know that reports of AI progress were mostly hype in prior decades, and are assuming that is continuing unless they see strong evidence to the contrary. They’re typically not willing to spend much more than an hour looking for such evidence.
I’m excited for the new set of filters that do nothing to change a video or picture except add deepfake artifacts to it. In this way, when damning video gets out, people can just quickly run it through one of these things, and then repost it themselves pointing out the artifacts and claiming the whole thing is fake.
If we had the ability to create one machine capable to centrally planning our current world economy, how much processing power/ memory would it need to have? Interested in some Fermi estimates.
To which I would reply, this is AI-complete, at which point the AI would solve the problem by taking control of the future. That’s way easier than actually solving the Socialist Calculation Debate.
As a data point, Byrne Hobart argues in Amazon sees like a state that Amazon is approximately solving the economic calculation problem (ECP) in the Socialist Calculation Debate when it sets prices on the goods on its online marketplace.
US’s 2022 GDP of $25 462B is 116x Amazon’s 2022 online store revenue of $220B.
Assuming O(n2.37log2n) scaling[1], it would take 500 000x the compute Amazon uses (for its own marketplace, excluding AWS) to approximately solve the ECP for the US economy (to the same level of approximation as “Amazon approximately solves the ECP”[2]).
In practice, I expect Amazon’s “approximate solution” to be much more like O(nlog2n)[3], so maybe a factor of merely 800x.
Which is not a vastly superhuman level of approximate solution? For example, Amazon is no longer growing fast enough to double every 4 years. Its marketplace also doesn’t particularly incentivise R&D, while I think a god-like AI would incentivise R&D.
There was a Senate Committee on Armed Services hearing on AI, in which the CEO of Palantir urged us to spend 5% of our budget on capabilities that would ‘terrify’ our enemies, and that we need to hook our weapons up to our AI systems as soon as possible, or else ‘China will surpass us in a decade.’
I… honestly have no words. I am in general AI optimist. I am not this-kind-of-humanity optimist. With pro-AI people like that we don’t need actual ASI or AGI to blow ourselves. This is insanity.
if I had more time, I’d be using such tools to learn to code rather than to learn to keep not coding.
As someone heavily involved in development for 16 years and ML for 8+ - I heavily endorse this. This is where the actual value lies.
It doesn’t actually help with a lot of really difficult an complex tasks, but it raises the “ground level” of tasks you need to worry about without manual involvement. More or less the same what High-level programming languages did before that, and low level, and assembler and …
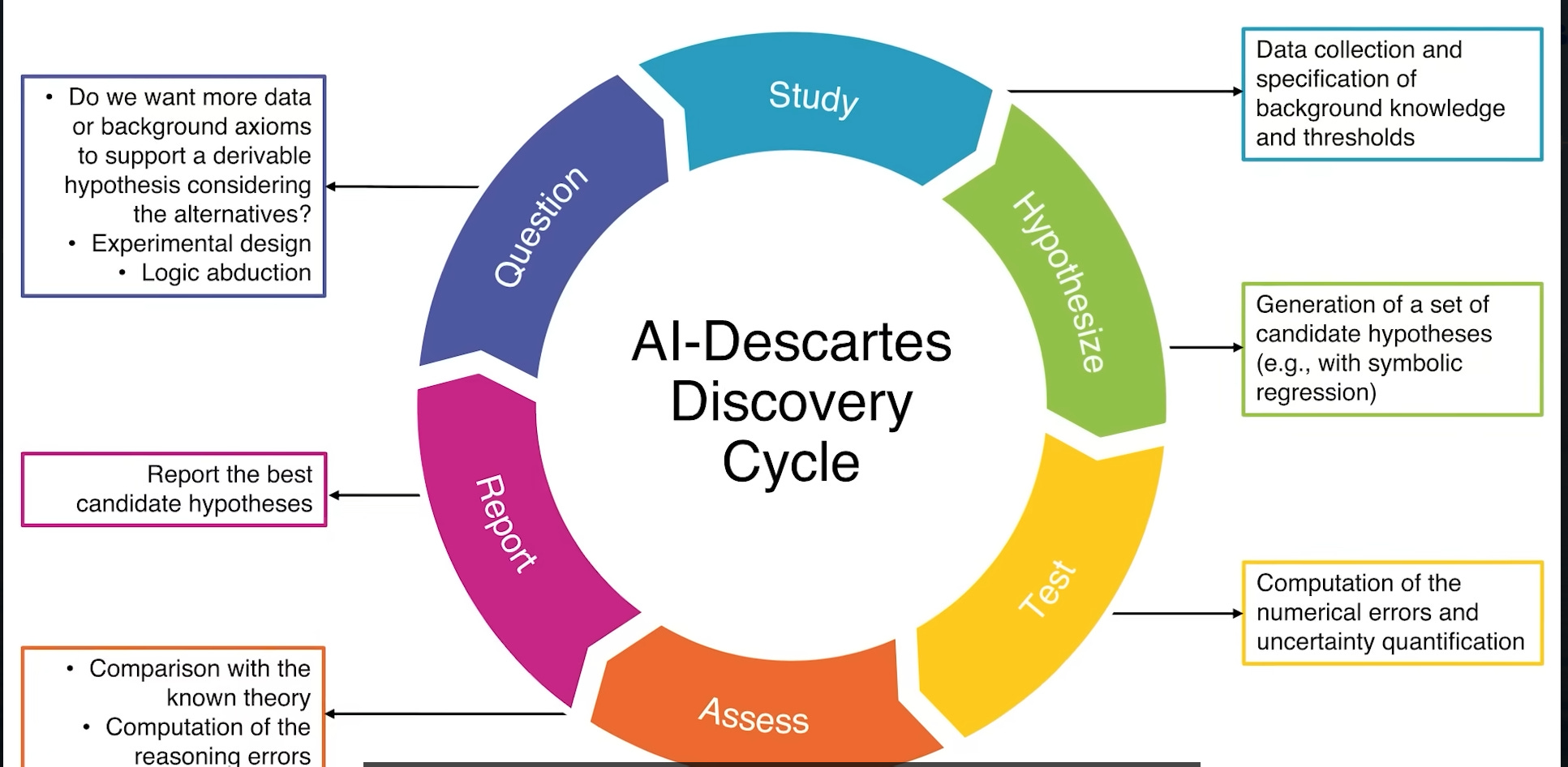




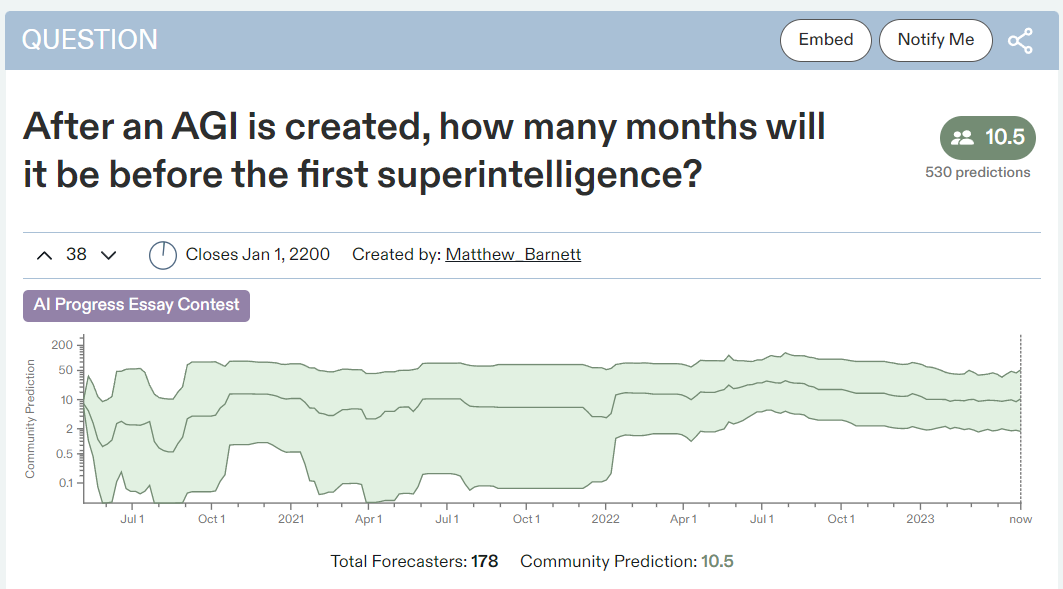



I know from experience that a sufficiently strong social disincentive can actually increase people’s tendency to groupthink. Some groups define themselves largely by the hate they get from the outgroup !
I don’t think that it’s the case for MIRI, and I don’t expect them to fall for this trap. But I hope they’re keeping this kind of dynamic in mind and checking from time to time if their position isn’t made more rigid by the kind of undocumented criticism they often get.
I applaud your Virtue of Silence, and I’m also uncomfortable with the simplicity of some of the ones I’m sitting on.
The “million token” recurrent memory transformer was first published July 2022. The new paper is just an investigation whether the method can also be used for BERT-like encoder models.
Given that there was a ton of papers that “solved” the quadratic bottleneck I wouldn’t hold my breath.
I participated in Tetlock’s tournament. Most people devoted a couple of hours to this particular topic, spread out over months.
A significant fraction of the disagreement was about whether AI would be transformative this century. I made a bit of progress on this, but didn’t get enough feedback to do much. AFAICT, many superforecasters know that reports of AI progress were mostly hype in prior decades, and are assuming that is continuing unless they see strong evidence to the contrary. They’re typically not willing to spend much more than an hour looking for such evidence.
I’m excited for the new set of filters that do nothing to change a video or picture except add deepfake artifacts to it. In this way, when damning video gets out, people can just quickly run it through one of these things, and then repost it themselves pointing out the artifacts and claiming the whole thing is fake.
As a data point, Byrne Hobart argues in Amazon sees like a state that Amazon is approximately solving the economic calculation problem (ECP) in the Socialist Calculation Debate when it sets prices on the goods on its online marketplace.
US’s 2022 GDP of $25 462B is 116x Amazon’s 2022 online store revenue of $220B.
Assuming O(n2.37log2n) scaling[1], it would take 500 000x the compute Amazon uses (for its own marketplace, excluding AWS) to approximately solve the ECP for the US economy (to the same level of approximation as “Amazon approximately solves the ECP”[2]).
In practice, I expect Amazon’s “approximate solution” to be much more like O(nlog2n)[3], so maybe a factor of merely 800x.
The economic calculation problem (ECP) is a convex optimisation problem (convexity of utility functions) which can be solved by linear programming in O(n2.37log2n).
Which is not a vastly superhuman level of approximate solution? For example, Amazon is no longer growing fast enough to double every 4 years. Its marketplace also doesn’t particularly incentivise R&D, while I think a god-like AI would incentivise R&D.
I just made it up.
I… honestly have no words. I am in general AI optimist. I am not this-kind-of-humanity optimist. With pro-AI people like that we don’t need actual ASI or AGI to blow ourselves. This is insanity.
As someone heavily involved in development for 16 years and ML for 8+ - I heavily endorse this. This is where the actual value lies.
It doesn’t actually help with a lot of really difficult an complex tasks, but it raises the “ground level” of tasks you need to worry about without manual involvement. More or less the same what High-level programming languages did before that, and low level, and assembler and …