Orienting to 3 year AGI timelines
My median expectation is that AGI[1] will be created 3 years from now. This has implications on how to behave, and I will share some useful thoughts I and others have had on how to orient to short timelines.
I’ve led multiple small workshops on orienting to short AGI timelines and compiled the wisdom of around 50 participants (but mostly my thoughts) here. I’ve also participated in multiple short-timelines AGI wargames and co-led one wargame.
This post will assume median AGI timelines of 2027 and will not spend time arguing for this point. Instead, I focus on what the implications of 3 year timelines would be.
I didn’t update much on o3 (as my timelines were already short) but I imagine some readers did and might feel disoriented now. I hope this post can help those people and others in thinking about how to plan for 3 year AGI timelines.
The outline of this post is:
A story for 3 year AGI timelines, including important variables and important players
Prerequisites for humanity’s survival which are currently unmet
Robustly good actions
A story for a 3 year AGI timeline
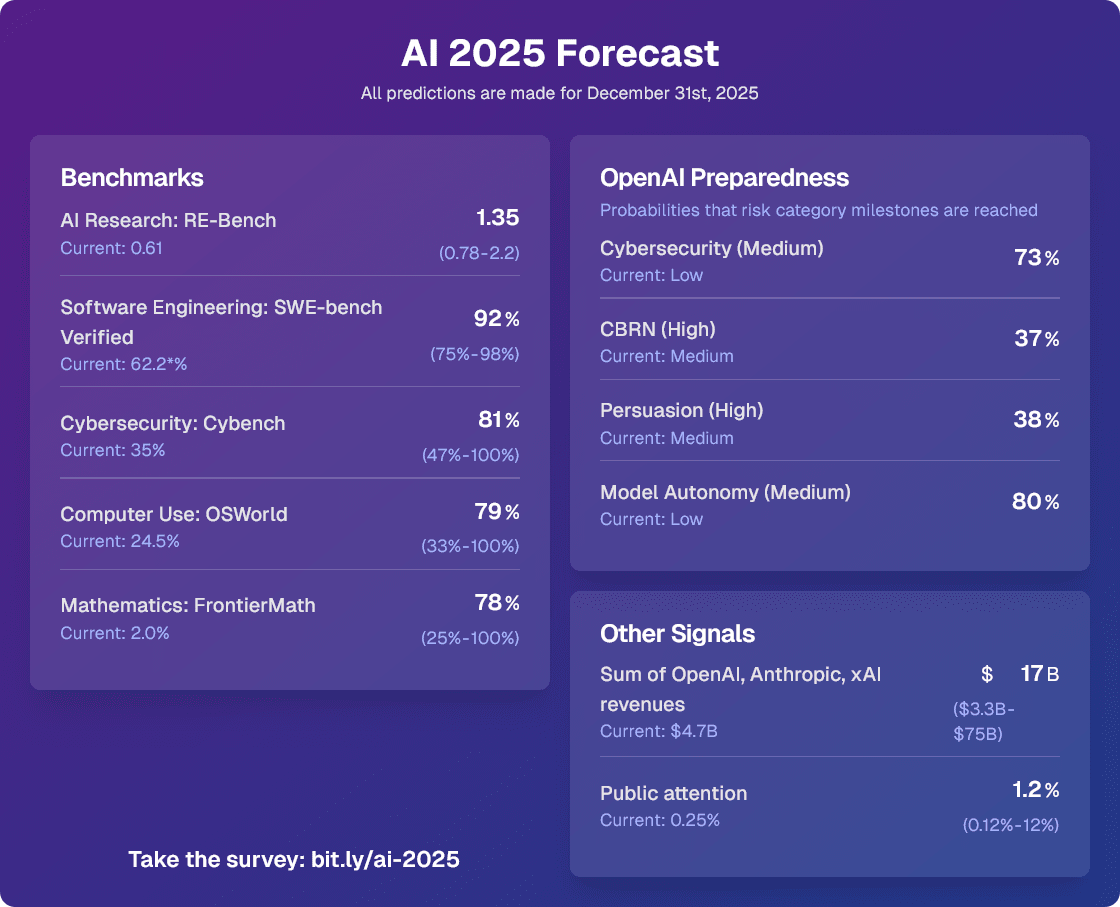
By the end of June 2025, SWE-bench is around 85%, RE-bench at human budget is around 1.1, beating the 70th percentile 8-hour human score. By the end of 2025, AI assistants can competently do most 2-hour real-world software engineering tasks. Whenever employees at AGI companies want to make a small PR or write up a small data analysis pipeline, they ask their AI assistant first. The assistant writes or modifies multiple interacting files with no errors most of the time.
By the end of 2026, AI agents are competently doing multi-day coding tasks. The employees at AGI companies are thoroughly freaked out and expect that AI which can beat humans at 95% of virtual jobs is probably going to be created within 2 years. They also expect that superintelligence will follow soon after. The government realizes that AI will be decisive for national power and locks down the AGI companies in late 2026. This takes the form of extreme government oversight bordering on nationalization. Progress stays at a similar pace because of the race with other nuclear weapons states.
Starting in 2027, most of the company’s quality-weighed workforce is made up by AI agents. The main decisions made by leadership are about allocating their workforce of millions of agents to various research areas, including AI R&D, safety, commercial applications, military applications, cyber, operations, communications, policy work, and most other types of work done on computers at the company. The human employees don’t matter much at this point except to attempt to help answer questions for groups of AI agents that get stuck and want a second opinion on their work.
AGI is created by the end of 2027. History probably doesn’t end here, but I will not go describe the post-AGI world in this post for brevity.
Important variables based on the year
Note that there’s a significant shift in dynamics in the middle of the story, which also imply significant shifts in the strategic landscape.
The pre-automation era (2025-2026).
In 2025 and 2026, humans are still doing most of the work. Most important questions center about allocations of humans and commercial and regulatory pressures placed on AI labs and the rest of the supply chain.
In the pre-automation era, humanity’s main priority should be very quickly finding safe ways to delegate research to AI agents. The main reason to do any type of safety-oriented research is to control these precursor agents who will later continue the research.
Another priority of the pre-automation era is finding ways to tell whether our current safety interventions will be adequate to prevent large numbers of AI agents from scheming or doing other undesirable things. Part of this is also setting up systems to pause and convince others to pause in case an adequate safety case can’t be made. This will get harder as the race heats up.
The post-automation era (2027 onward).
After 2026, AIs are doing most of the work. At this point, the research is mostly out of human hands, but the human employees are still involved in high-level decisions and interfacing with humans outside the AGI company. By the end of 2028, humans can no longer contribute to technical aspects of the research.
The main questions center around the allocation of AI agents, and their mandated priorities. Some important questions about this period are:
How good is the broad research plan that the AI agents are pursuing?
For example, if the human in charge of initially scoping out the research direction is someone who is fundamentally confused about AI safety, the hopes of aligning models might be doomed despite an initially well-meaning population of AI agents.
How many company resources are invested in safety-oriented research?
Allocating 0.1% of compute vs 25% of compute to safety might make a large difference in the success of the safety work that is done.
Important players
AGI Company Leaders—they steer the AGI company’s broad direction.
Safety researchers
Internal human AI safety researchers—they inform the pre-automation and post-automation research plans, and do much of the pre-automation safety research that gets implemented. They oversee the automated safety researchers.
Internal automated AI safety researchers—they do the bulk of the automation-era research that gets implemented.
External human AI safety researchers—they do pre-automation research. A small subset of it gets implemented internally. They also critique the public parts of the pre-automation and post-automation research plans from the outside. They likely become irrelevant during the post-automation era as the gap between public and private knowledge will widen for national security reasons.
The US Government—places pressures on AGI companies as informed and pressured by other governments, the US AISI (or other government agencies), Think Tanks, High Status Scientists, and The Public. Probably nationalizes/oversees the companies starting around AGI, very likely before superintelligence.
Trailing AGI companies—place competitive pressures, set safety precedents. Possibly eventually collaborate or get acquired. If they don’t collaborate or get acquired by the main AGI project, they likely get much of their compute seized before ASI.
Bad actors—will attempt to steal and/or misuse the AI.
Note that “The AI Safety Community” is not part of this list. I think external people without much capital (fiancial, social, intellectual, or other kinds) just won’t have that much leverage over what happens.
Prerequisites for humanity’s survival which are currently unmet
This is not meant to be an exhaustive list.
A sensible takeoff plan. Currently, AGI companies lack a vision for how to navigate safely handing off research to AI agents.
The alignment approach—companies don’t have (public) default plans for which research areas to assign to their population of AI agents by default.
Compute commitments—even with a sensible alignment approach, a lack of commitments might lead to an inadequate proportion of AI agents and compute to be allocated to it.
Frontier safety frameworks—the requirements and commitments around SL-4 and SL-5 are currently very unclear, allowing a lot of wiggle room to cut corners during takeoff.
Control—the science of safely handing off work to AI agents (or being able to tell that it’s not safe to do so) is very underdeveloped.
State-proof cybersecurity. If bad actors can steal the weights of very advanced AI systems, things become extremely unpredictable due to misuse and enabling less careful entities to create advanced AI.
A way to survive global tensions. The creation of AGI will disrupt the balance of military power between countries, possibly giving one entity a decisive strategic advantage. I think the probability of nuclear war in the next 10 years is around 15%. This is mostly due to the extreme tensions that will occur during takeoff by default. Finding ways to avoid nuclear war is important.
During the cold war, there were multiple nuclear close calls that brought us close to annihilation. Some of these were a consequence of shifts in the strategic balance (e.g. the Cuban Missile Crisis). The US threatened the USSR with nuclear war over the Berlin Blockade. The creation of superintelligence will make these events seem trivial in comparison, and the question is just whether officials will realize this.
Doing nationalization right.
Getting the timing right. If nationalization happens too late (e.g. after AGI), the ensuing confusion and rapid change within the project might lead to bad decision making.
Creating default plans. There will likely be a time in 2025 or 2026 that will be marked by significant political will to lock down the labs. If there don’t already exist any good default plans or roadmaps on how to do this, the plan will likely be suboptimal in many ways and written by people without the relevant expertise.
Building political capital. Unless people with relevant expertise are well-known to important actors, the people appointed to lead the project will likely lack the relevant expertise.
Keeping safety expertise through nationalization. A nationalization push which ousts all AI safety experts from the project will likely end up with the project lacking the technical expertise to make their models sufficiently safe. Decisions about which personnel the nationalized project will inherit will likely largely depend on how safety-sympathetic the leadership and the capabilities-focused staff are, which largely depends on building common knowledge about safety concerns.
Robustly good actions
Joining the few places that will have leverage over what happens.
Think about who you want to get hired by and what you’re missing to get hired there.
If you’re externally doing research, remember to multiply the importance of the research direction by the probability your research actually gets implemented on the inside. One heuristic is whether it’ll get shared in their Slack[2].
After strict government oversight, internal research will likely be done under some sort of security clearance. Don’t do drugs, don’t go into debt, don’t hang out with shady people, and reduce your number of unnecessary foreign contacts.
Helping inform important players. Many important players will want advice from people who have legibly thought a lot about AGI and AGI safety. Would they think to call you first when they have a question?
Actually have a plan. I think a good way to think about this is year by year—what do I plan to do by EOY 2025, EOY 2026, EOY 2027.
Keep in mind that the only things that matter are things that need to get done before AGI. AGI can do the rest.
I acknowledge that there exist bets for long timelines, but I also think those things should be discounted compared to how promising they would be under a 20 year AGI timeline.
I also acknowledge that there’ll maybe be a centaur period of around 1 year after AGI. I don’t think this is that important a consideration as it’s unclear to me what it implies that the rest of the scenario doesn’t.
Speedrun everything. If your plan is “I will do X so I can do Y later,” consider just trying to do Y right now.
If your plan is “I will work for an irrelevant ML company for a year so I have the credentials to get hired by an AGI company,” consider applying to the AGI company directly or doing things that will accelerate that process dramatically (the action space is wide!).
Invest accordingly. AGI being three years away probably has large implications for how to structure your investment portfolio, as some bets are much more correlated with this than others. Money will probably be useful to allocate to rapidly emerging opportunities to steer things during takeoff, but it’s unclear to me what use it’ll be post-ASI if humanity survives (on priors, property rights will be respected at least to some extent). More discussion here. (not financial advice)
Build adaptability and resilience. The world will keep shifting faster and faster as time goes on. Not going insane and keeping a level head will be very important for being able to make wise decisions, and will become an increasingly rare and valuable attribute.
Spend time thinking about possible futures and your place in them. If there are predictable directional changes, instead of thinking “Oh no the world is so chaotic!” a more useful frame might be “While I was wrong about specifics, this roughly matches up to one of the branches that I predicted could happen, and I have already thought about how to behave in these circumstances.” That way, some of your initial mental labor can be offloaded from your future self (who will have a lot on their plate to think about) to your present self. This not only has the intellectual benefit of offloading labor (which I think is minor), but a more visceral benefit of reducing the base surprise or panic that might occur later on—known unknowns are probably much less stressful than unknown unknowns.
Don’t neglect your health. While it might seem appropriate to start working many more hours than you did months ago or make other similarly unhealthy tradeoffs, we will need to be in a good shape deep into takeoff if we want to navigate it wisely. Sustainability is important and implies similar habits on a 3 year timescale as it does on a 10 year timescale.
Final thoughts
I know it can be stressful to think about short AGI timelines, but this should obviously not be taken as evidence that timelines are long. If you made your current plans under 10 or 20 year timelines, they should probably be changed or accelerated in many ways at this point.
One upside of planning under short timelines is that the pieces are mostly all in place right now, and thus it’s much easier to plan than e.g. 10 years ahead. We have a somewhat good sense of what needs to be done to make AGI go well. Let’s make it happen.
- ^
I define AGI here as an AI system which is able to perform 95% of the remote labor that existed in 2022. I don’t think definitions matter that much anyways because once we reach AI R&D automation, basically every definition of AGI will be hit soon after (barring coordinated slowdowns or catastrophes).
- ^
While they’re still using Slack that is. After strong government oversight, it’s unlikely that external human researchers will have any nontrivial sway over what happens on the inside.
- Reasons for and against working on technical AI safety at a frontier AI lab by (Jan 5, 2025, 2:49 PM; 88 points)
- Impact in AI Safety Now Requires Specific Strategic Insight by (Dec 29, 2024, 12:40 AM; 24 points)
- You should delay engineering-heavy research in light of R&D automation by (Jan 7, 2025, 2:11 AM; 23 points)
if multiple nuclear states started taking ASI relatively very seriously (i.e. apart from being ignorant of alignment, and being myopically focused on state power instead of utopia/moral good), and started racing, any state behind in that race could threaten to nuke any state which continues to try to bring about ASI. in other words, the current Mutually Assured Destruction can be unilaterally extended to trigger in response to things other than some state firing nukes.
this is (1) a possible out as it would halt large-scale ASI development, and (2) could happen unilaterally by cause of states myopically seeking dominance.
however, if the nuclear states in question just think ASI will be a very good labor automator, then maybe none would be willing to do nuclear war over it, even if it would technically be in the interest of the myopic ‘state power’ goal[1]. i don’t know. (so maybe (2) needs a minimum of seriousness higher than ‘it will automate lots of labor’ but lower than ‘it is a probable extinction risk’)
“(??? why?)” by which i mean it seems absurd/perplexing (however likely) that people would be so myopic. ‘state i was born in having dominance’ is such an alien goal also.)
What would you advise for external people with some amount of capital, say $5M? How would this change for each of the years 2025-2027?
I sadly don’t have well-developed takes here, but others have pointed out in the past that there are some funding opportunities that are systematically avoided by big funders, where small funders could make a large difference (e.g. the funding of LessWrong!). I expect more of these to pop up as time goes on.
Somewhat obviously, the burn rate of your altruistic budget should account for altruistic donation opportunities (possibly) disappearing post-ASI, but also account for the fact that investing and cashing it out later could also increase the size of the pot. (not financial advice)
(also, I have now edited the part of the post you quote to specify that I don’t just mean financial capital, I mean other forms of capital as well)
I’m skeptical of the claim that the only things that matter are the ones that have to be done before AGI.
Ways it could be true:
The rate of productivity growth has a massive step increase after AI can improve its capabilities without the overhead of collaborating with humans. Generally the faster the rate of productivity growth, the less valuable it is to do long-horizon work. For example, people shouldn’t work on climate change because AGI will instantly invent better renewables.
If we expect short timelines and also smooth takeoff, then that might mean our current rate of productivity growth is much higher or a different shape (e.g. doubly exponential instead of just exponential) than it was a few years ago. This much higher rate of productivity growth means any work with 3+ year horizons has negligible value.
Ways it could be false:
Moloch still rules the world after AGI (maybe there are multiple competing AGIs). For example, a scheme that allows an aligned AGI to propagate it’s alignment to the next generation would be valuable to work on today because it might be difficult for our first generation aligned AGI to invent this before someone else (another AGI) creates the second generation, smarter AGI.
DALYs saved today are still valuable.
Q: Why save lives now when it will be so much cheaper after we build aligned AGI?
A: Why do computer scientists learn to write fast algorithms when they could just wait for compute speed to double?
Basic research might always be valuable because it’s often not possible to see the applications of a research field until it’s quite mature. A post-AGI world might dedicate some constant fraction of resources towards basic research with no obvious applications, and in that world it’s still valuable to pull ahead the curve of basic research accomplishments.
I lean towards disagreeing because I give credence to smooth takeoffs, mundane rates of productivity growth, and many-AGI worlds. I’m curious if those are the big cruxes or if my model could be improved.
I have done a lot of thinking. At this point timelines are so short I would recommend:
Individual with no special connections:
-- Avoid tying up capital in illiquid plans. One exception is housing since ‘land on Holy Terra’ still seems quite valuable in many scenarios.
-- Make whatever spiritual preparations you can, whatever spirituality means to you. If you are inclined to Buddhism meditate. Practice loving kindness. Go to church if you are Christian. Talk to your loved ones. Even if you are atheist you need to prepare your metaphorical spirit for what may come. Physical health may also be valuable here.
-- Buy Nvidia call options. Money is plausibly useful, its a form of optionality and there isn’t much else. Buy literally max strike, max far out. Hold for 100x or until conditions seriously change. Buy as much as you can afford to lose. I cannot think of anything better.
If you have special connections and skill:
-- Try to get the labs nationalized as rapidly as possible. Do not ‘just do things’ you need to avoid messing up other good actor’s plans. But I don’t endorse generalized inaction. there is no simple way to operationalize ‘actually exercise good judgement’. There probably isn’t time for much else. Nationalization at least means there is a mandate to align AI broadly. and maybe it would slow down progress somewhat.
-- I cannot vouch for groups like Pause AI. But I also do not anti-vouch. Maybe they or some similar group is doing things wisely. But before you follow anyone please use your absolute best judgement to determine if they have a good plan or not.
-- Please don’t do anything insane. I am a rationalist and so I too am inclined positively towards thinking through totally crazy ideas. But nothing terrorism adjacent is likely to go well. Consider what happened after 911. That crazy plot actually worked in the sense the Towers went down. But the hijackers claimed they wanted to free the Middle East from USAand Israeli domination. Obviously, even ignoring the direct costs of the terrorist attack, the plan backfired. They brought chaos and death to the countries they claimed to be fighting for. Please do not follow in their foolish footsteps. Before someone thinks its pointless to write this I will note the rationalist and EA communities have committed multiple ideological murders and a many billion dollar fraud. Be careful which ideas you take seriously.
Substantiate? I down- and disagree-voted because of this un-evidenced very grave accusation.
Presumably the commenter is referencing Ziz and friends?
Donating to the LTFF seems good.
Thoroughly agree except for what to do with money. I expect that throwing money at orgs that are trying to slow down AI progress (eg PauseAI, or better if someone makes something better) gets you more utility per dollar than nvidia (and also it’s more ethical).
Edit: to be clear, I mean actual utility in your utility function. Even if you’re fully self-interested and not altruistic at all, I still think your interests are better served by donating to PauseAI-type orgs than investing in nvidia.
I think if the question is “what do I do with my altruistic budget,” then investing some of it to cash out later (with large returns) and donate much more is a valid option (as long as you have systems in place that actually make sure that happens). At small amounts (<$10M), I think the marginal negative effects on AGI timelines and similar factors are basically negligible compared to other factors.
10M$ sounds like it’d be a lot for PauseAI-type orgs imo, though admittedly this is not a very informed take.
Anyways, I stand by my comment; I expect throwing money at PauseAI-type orgs is better utility per dollar than nvidia even after taking into account that investing in nvidia to donate to PauseAI later is a possibility.
Pause AI has a lot of opportunity for growth.
Especially the “increase public awareness” lever is hugely underfunded. Almost no paid staff or advertising budget.
Our game plan is simple but not naive, and is most importantly a disjunct, value-add bet.
Please help us execute it well: explore, join, talk with us, donate whatever combination of time, skills, ideas and funds makes sense
(Excuse dearth of kudos, am not a regular LW person, just an old EA adjacent nerd who quit Amazon to volunteer full-time for the movement.)
I do think it’s conceptually nicer to donate to PauseAI now rather than rely on the investment appreciating enough to offset the time-delay in donation. Not that it’s necessarily the wrong thing to do, but it injects a lot more uncertainty into the model that is difficult to quantify.
Excellent comment, spells out a lot of thoughts I’d been dancing around for a while better than I had.
This is the step I’m on. Just bought land after saving up for several years while being nomadic, planning on building a small house soon in such a way that I can quickly make myself minimally dependent on outside resources if I need to. In any AI scenario that respects property rights, this seems valuable to me.
This I need to double down on. I’ve been more focused on trying to get others close to me on board with my expectations of impending weirdness, with moderate success.
Assuming short timelines, I wonder how much NVIDIA’s stock will increase and if anywhere near a 100x return is possible.
The further out and higher strike price NVIDIA call I could find is at 290$ SP, dated Jan 15 2027, at $13.25. If NVIDIA goes to a 10T market cap I get an 8x return on investment, if the company goes to a 15T market cap I get a ~20x return on investment.
I’m not sure how realistic it is for NVIDIA to increase past a 15 Trillion Market cap. Plus, increased government intervention seems like it would negatively impact profits.
The thing with NVIDIA though is that the IV is so high and so are premiums. I spent a few hours looking for a better trade than that, though I think it’s pretty solid.
I think SPY calls can possibly be much better than NVIDIA calls. The market doesn’t expect the stock market to go up significantly in the next few years, but I think theres a chance it will assuming timelines are short. Here’s the SPY YoY growth during the internet boom in the 90s.
Year 2000 saw a −9.7% return ($86.54) 1999: +20.4% ($95.88) 1998: +28.7% ($79.65) 1997: +33.5% ($61.89) 1996: +22.5% ($46.37) 1995: +38.0% ($37.85) 1994: +0.4% ($27.42)
Here we see that from any two year period from 1995-1999, the stock market went up anywhere from 50% to 70%.
Thus, I don’t think it’s unreasonable to think SPY has a good chance of going up 50% − 70% by Jan 15 2027 (to be fair, the past two years had a YoY growth of ~25%)
If you buy a $855 Strike price call for that date and SPY increases 50% by then you get a 12x return. If SPY increases 70% you get a 62x return.
If you buy the highest Strike Price call for that day at $910 and SPY increase by 70%, you get an 83x return.
Something to think about at least. At this time I’m going to buy long dated SPY calls for 2-3 years out at the 800−910 range. Nvidia calls still look good but the premiums are just so expensive because of the companies recent massive growth and volatility, so I think SPY calls are the better option.I’m still thinking about how to hedge incase the upcoming chaos turns the market sour (perhaps a Taiwanese blockade, or NVIDIA profits being hurt by increasing government interference)
This is looking like a February 2020 moment.
Why SPY over QQQ?
I never traded options, but isn’t the return you get critically sensitive on the date before expiration by which the strike price is hit? If this happens just before expiration, my understanding is that the option is worthless: there is no value in exercising an option to buy now at some price if that happens to be the market price. More generally, it makes a big difference whether the strike price is hit one week, one month, or one year before expiration.
Are you making any implicit assumptions in this regard? It would be useful if you could make your calculations explicit.
The option to buy SPY at $855 in January 2027 is going for $1.80 today, because most people don’t expect the price to get that high. But if in fact SPY increases in the intervening time by 50% from its present value ($582), as stipulated by kairos, then the option will ultimately be worth 1.5*582 − 855 ~ $18. I think this is where the 12x figure is coming from.
Thanks—I understand now. I thought $855 was the price SPY would reach if the current price increased by 50%.
Dumbass here with close to zero knowledge about finance stuff- why a call? A call is basically an option to buy at a certain price, right? So why would that be better than just buying the stock now at current price?
The main advantage of call options over buying stock directly is leverage—you can control a much larger amount of stock with a much smaller upfront investment. This means your potential returns (as a percentage of what you put in) can be much higher with calls than with regular stock purchases.
However, this leverage comes with higher risk. While buying stock means you own something real that will always have some value, options can expire worthless if your bet doesn’t work out. It’s essentially a tradeoff—calls let you make bigger bets with less money upfront, but you can lose your entire investment if you’re wrong about where the stock is heading.
Thanks for your comment. It prompted me to add a section on adaptability and resilience to the post.
My current take on land/housing:
1. The value of your house may depreciate very quickly as materials and labor become cheap due to automation.
2. Residential land gets almost all of its value from the infrastructure built around it and being near a city where people have jobs to get to. If there are large migrations, the land your house is on may lose most of its value even though land in general should go up as a hard asset.
I wrote more about it here.
The post doesn’t seem to contemplate the effect that open-weights models will have on the take-off dynamics. For example, it seems like the DeepSeek V3 release shows that whatever performance is achieved at the frontier, is then achieved in open-weights at a much lower cost.
Given that, the centralization forces might not dominate.
I think this post (or the models/thinking that generated it) might be missing an important consideration[1]: “Is it possible to ensure that the nationalized AGI project does not end up de facto controlled by not-good people? If yes, how?”
Relevant quote from Yudkowsky’s Six Dimensions of Operational Adequacy in AGI Projects (emphasis added):
Another quote (emphasis mine):
or possibly a crucial consideration
The quote is referring to “[...] a single global Manhattan Project which is somehow not answerable to non-common-good command such as Trump or Putin or the United Nations Security Council. [...]”
This is an important consideration. I don’t think that government power travels inevitably to bad hands, but I do think it happens far too often. Strengthening democracy is the one useful move I can think of here, but that’s pretty vague.
Not pushing for nationalization doesn’t seem like a useful response. It will be soft-nationalized sooner or later; takeoff is going to be too slow for the AGI to outwit the US national security apparatus before they figure out what a big deal it is. Pushing for nationalization or not might affect when it’s done, giving some modicum of control.
I notice that I have almost no concrete model of what that sentence means. A couple of salient questions[1] I’d be very curious to hear answers to:
What concrete ways exist for affecting when (and how) nationalization is done? (How, concretely, does one “push” for/against nationalization of AGI?)
By what concrete causal mechanism could pushing for nationalization confer a modicum of control; and control over what exactly, and to whom?
Other questions I wish I (or people advocating for any policy w.r.t. AGI) had answers to include (i.a.) “How could I/we/anyone ensure that the resulting AGI project actually benefits everyone? Who, in actual concrete practice, would end up effectively having control over the AGI? How could (e.g.) the public hold those people accountable, even as those people gain unassailable power? How do we ensure that those people are not malevolent to begin with, and also don’t become corrupted by power? What kinds of oversight mechanisms could be built, and how?”
I agree that “strengthening democracy” sounds nice, and also that it’s too vague to be actionable. Also, what exactly would be the causal chain from “stronger democracy” (whatever that means) to “command structure in the nationalized AGI project is trustworthy and robustly aligned to the common good”?
If you have any more concrete ideas in this domain, I’d be interested to read about them!
I agree that this is good if one has sufficient skill and knowledge to improve outcomes. What if one has reason to suspect that joining a key AI lab would be a net negative toward their success, compared to if they hired someone else? For instance I interview disproportionately well compared to my actual efficacy in tech roles—I get hired based on the best of my work, but that best work is a low percentage of my actual output (f which most is barely average and some is conterproductive), so it seems like someone in my situation might actually do harm by seeking greater leverage?
According to the timeline of the post, AGI will take place during the Trump presidency and much of the nationalization efforts will need to be lead by his administration. However, that seems antithetical to the administrations general ethos of deregulation (at least in the banking and energy sectors). Would it be possible to explain which avenues would lead Trump to nationalize, for example, OpenAI or Antropic?
This is a good point. Nationalization is hard and complex, and it would probably slow progress—and the current administration would be against it on general principles, as you say.
But I think people are underestimating the government’s flexibility and willingness to exert control when things get weird and dangerous. Governments typically do just that. Even Soft Nationalization: How the US Government Will Control AI Labs underestimates this; perhaps this would happen in long timelines, but I think there are more direct but still easy routes to control when things heat up and the bright boys in national security realize what’s going on.
I expect a “softer nationalization” of the government just asking politely to be included in deliberations among org leadership. Existing emergency act procedures very likely apply as soon as you take AGIs security implications seriously. They don’t have to nationalize in any strong sense to exert control over the technology. Anyone being asked politely by the NSA to do something they could legally demand would be wise to comply, or at least appear to comply.
Thanks! The linked article is exactly what I was looking for. Assuming “nationalization” means something like “soft nationalization” does make the timeline seem a lot more plausible.
What does “safe” mean, in this post?
Do you mean something like “effectively controllable”? If yes: controlled by whom? Suppose AGI were controlled by some high-ranking people at (e.g.) the NSA; with what probability do you think that would be “safe” for most people?
That is very likely what “safe” means. Instruction-following AGI is easier and more likely than value aligned AGI. It seems very likely to be the default alignment goal as soon as someone thinks seriously about what they want their AGI aligned to.
As for whether it’s actually good for most people: it depends entirely on who in the NSA controls it. There are very probably both good (ethically typical) and bad (sociopathic/sadistic) people there.
I have a whole draft speculating on which people could be trusted to control the world by controlling an AGI as it becomes ASI; I think it’s between 90 and 99% of people who have a “positive empathy-sadism balance”. But I’m not at all sure; it depends on who they’re surrounded by and the circumstances. Being in conflict with other AGI wielders gives lots more room for negative emotions to dominate. And it could be bad for most people even if it’s good in the much longer run.
I’d be interested to see that draft as a post!
What fraction of humans in set X would you guess have a “positive empathy-sadism balance”, for
X = all of humanity?
X = people in control of (governmental) AGI projects?
I agree that the social environment / circumstances could have a large effect on whether someone ends up wielding power selfishly or benevolently. I wonder if there’s any way anyone concerned about x/s-risks could meaningfully affect those conditions.
I’m guessing[1] I’m quite a bit more pessimistic than you about what fraction of humans would produce good outcomes if they controlled the world.
with a lot of uncertainty, due to ignorance of your models.
Yep, the concern that the more sociopathic people wind up in positions of power is the big concern. However, I don’t think power is correlated with sadism and hopefully it’s anticorrelated.
I’d guess 99% of humanity and like 95% of people in control of AGI projects. Maybe similar for those high in the US government—but not in dictatorships where I think sadism and sociopathy win.
I didn’t finish that post because I was becoming more uncertain while writing it. A lot of hereditary monarchs have been pretty good rulers (this seems like the closest historical analogy to having AGI-level power over the world). But a lot were really bad rulers, too. That seemed to happen when a social group around them just didn’t care about the commoners and got the monarchs interested in their own status games. That could happen with some who controlled an AGI. I guess they’re guaranteed to be less naive than hereditary monarchs since all the candidates are adults who’ve earned power. Hopefully that would make them more likely to at least occasionally consider the lot of the commoner.
One of the things that gave me some optimism was considering the long term. A lot of people are selfish and competitive now. But getting absolute control would over time make them less competitive. And it would be so easy to benefit humanity, just by telling your slave AGI to go make it happen. A lot of people would enjoy being hailed as a benevolent hero who’s shepherded humanity into a new golden age.
Anyway, I’m not sure.
Thanks for the answer. It’s nice to get data about how other people think about this subject.
Agreed!
Do I understand correctly: You’d guess that
99% of humans have a “positive empathy-sadism balance”,
and of those, 90-99% could be trusted to control the world (via controlling ASI),
i.e., ~89-98% of humanity could be trusted to control the world with ASI-grade power?
If so, then I’m curious—and somewhat bewildered! -- as to how you arrived at those guesses/numbers.
I’m under the impression that narcissism and sadism have prevalences of very roughly 6% and 4%, respectively. See e.g. this post, or the studies cited therein. Additionally, probably something like 1% to 10% of people are psychopaths, depending on what criteria are used to define “psychopathy”. Even assuming there’s a lot of overlap, I think a reasonable guess would be that ~8% of humans have at least one of those traits. (Or 10%, if we include psychopathy.)
I’m guessing you disagree with those statistics? If yes, what other evidence leads you to your different (much lower) estimates?
Do you believe that someone with (sub-)clinical narcissism, if given the keys to the universe, would bring about good outcomes for all (with probability >90%)? Why/how? What about psychopaths?
Do you completely disagree with the aphorism that “power corrupts, and absolute power corrupts absolutely”?
Do you think that having good intentions (and +0 to +3 SD intelligence) is probably enough for someone to produce good outcomes, if they’re given ASI-grade power?
FWIW, my guesstimates are that
over 50% of genpop would become corrupted by ASI-grade power, or are sadistic/narcissistic/psychopathic/spiteful to begin with,
of the remainder, >50% would fuck things up astronomically, despite their good intentions[1],
genetic traits like psychopathy and narcissism (not sure about sadism), and acquired traits like cynicism, are much more prevalent (~5x odds?) in people who will end up in charge of AGI projects, relative to genpop. OTOH, competence at not-going-insane is likely higher among them too.
I note that if someone is using an AGI as a slave, and is motivated by wanting prestige status, then I do not expect that to end well for anyone else. (Someone with moderate power, e.g. a medieval king, with the drive to be hailed a benevolent hero, might indeed do great things for other people. But someone with more extreme power—like ASI-grade power—could just… rewire everyone’s brains; or create worlds full of suffering wretches, for him to save and be hailed/adored by; or… you get the idea.)
Even relatively trivial things like social media or drugs mess lots of humans up; and things like “ability to make arbitrary modifications to your mind” or “ability to do anything you want, to anyone, with complete impunity” are even further OOD, and open up even more powerful superstimuli/reward-system hacks. Aside from tempting/corrupting humans to become selfish, I think that kind of situation has high potential to just lead to them going insane or breaking (e.g. start wireheading) in any number of ways.
And then there are other failure modes, like insufficient moral uncertainty and locking in some parochial choice of values, or a set of values that made sense in some baseline human context but which generalize to something horrible. (“Obviously we should fill the universe with Democracy/Christianity/Islam/Hedonism/whatever!”, … “Oops, turns out Yahweh is pretty horrible, actually!”)
Good post, thanks for writing!
Who (else) is working on building infrastructure for helping individuals get the right advice at the right point in time (vs. current status quo of individuals trying to consult their direct networks)? We’re doing our best to make headway here (third-opinion.org) and would be very interested in getting in touch with people who are thinking seriously about this and want to help build infrastructure for this purpose.
Or resilience to nuclear war. What’s your probability of an engineered pandemic in the next 10 years?
Yes, resilience seems very neglected.
I think I’m at a similar probability to nuclear war but I think the scenarios where biological weapons are used are mostly past a point of no return for humanity. I’m at 15%, most of which is scenarios where the rest of the humans are hunted down by misaligned AI and can’t rebuild civilization. Nuclear weapons use would likely be mundane and for non AI-takeover reasons and would likely result in an eventual rebuilding of civilization.
The main reason I expect an AI to use bioweapons with more likelihood than nuclear weapons in a full-scale takeover is that bioweapons would do much less damage to existing infrastructure and thus allow a larger and more complex minimal seed of industrial capacity from the AI to recover from.