Born too late to explore Earth; born too early to explore the galaxy; born just the right time to save humanity.
Ulisse Mini
Karma: 1,720
Answering my own question, a list of theories I have yet to study that may yield significant insight:
Theory of Heavy-Tailed Self-Regularization (https://weightwatcher.ai/)
Singular learning theory
Neural tangent kernels et. al. (deep learning theory book)
Information theory of deep learning
I wasn’t in a flaming asshole mood, it was a deliberate choice. I think being mean is necessary to accurately communicate vibes & feelings here, I could serialize stuff as “I’m feeling XYZ and think this makes people feel ABC” but this level of serialization won’t activate people’s mirror neurons & have them actually internalize anything.
Unsure if this worked, it definitely increased controversy & engagement but that wasn’t my goal. The goal was to shock one or two people out of bad patterns.
Sorry, I was more criticizing a pattern I see in the community rather than you specifically
However, basically everyone I know who takes innate intelligence as “real and important” is dumber for it. It is very liable to mode collapse into fixed mindsets, and I’ve seen this (imo) happen a lot in the rat community.
(When trying to criticize a vibe / communicate a feeling it’s more easily done with extreme language, serializing loses information. sorry.)
EDIT: I think this comment was overly harsh, leaving it below for reference. The harsh tone was contributed from being slightly burnt out from feeling like many people in EA were viewing me as their potential ender wiggin, and internalizing it.[1]
The people who suggest schemes like what I’m criticizing are all great people who are genuinely trying to help, and likely are.
Sometimes being a child in the machine can be hard though, and while I think I was ~mature and emotionally robust enough to take the world on my shoulders, many others (including adults) aren’t.
An entire school system (or at least an entire network of universities, with university-level funding) focused on Sequences-style rationality in general and AI alignment in particular.
[...]
Genetic engineering, focused-training-from-a-young-age, or other extreme “talent development” setups.
Please stop being a fucking coward speculating on the internet about how child soldiers could solve your problems for you. Enders game is fiction, it would not work in reality, and that isn’t even considering the negative effects on the kids. You aren’t smart enough for galaxy brained plans like this to cause anything other than disaster.
In general rationalists need to get over their fetish for innate intelligence and actually do something instead of making excuses all day. I’ve mingled with good alignment researchers, they aren’t supergeniuses, but they did actually try.
(This whole comment applies to Rationalists generally, not just the OP.)
- ↩︎
I should clarify this mostly wasn’t stuff the atlas program contributed to. Most of the damage was done from my personality + heroic responsibility in rat fiction + dark arts of rationality + death with dignity post. Nor did atlas staff do much to extenuate this, seeing myself as one of the best they could find was most of it, cementing the deep “no one will save you or those you love” feeling.
- ↩︎
Excited to see what comes out of this. I do want to raise attention to this failure mode covered in the sequences. however. I’d love for those who do the program try to bind their results to reality in some way, ideally having a concrete result of how they’re substantively stronger afterwards, and how this replicated with other participants who did the training.
Really nice post. One thing I’m curious about is this line:
This provides some intuitions about what sort of predictor you’d need to get a non-delusional agent—for instance, it should be possible if you simulate the agent’s entire boundary.
I don’t see the connection here? Haven’t read the paper though.
Quick thoughts on creating a anti-human chess engine.
Use maiachess to get a probability distribution over opponent moves based on their ELO. for extra credit fine-tune on that specific player’s past games.
Compute expectiminimax search over maia predictions. Bottom out with stockfish value when going deeper becomes impractical. (For MVP bottom out with stockfish after a couple ply, no need to be fancy.) Also note: We want to maximize (P(win)) not centipawn advantage.
For extra credit, tune hyperparameters via self-play against maia (simulated human). Use lichess players as a validation set.
???
Profit.
This might actually be a case where a chess GM would outperform an AI: they can think psychologically, so they can deliberately pick traps and positions that they know I would have difficulty with.
Emphasis needed. I expect a GM to beat you down a rook every time, and down a queen most times.
Stockfish assumes you will make optimal moves in planning and so plays defensive when down pieces, but an AI optimized to trick humans (i.e. allowing suboptimal play when humans are likely to make a mistake) would do far better. You could probably build this with maiachess, I recall seeing someone build something like this though I can’t find the link right now.
Put another way, all the experiments you do are making a significant type error, Stockfish down a rook against a worse opponent does not play remotely like a GM down a rook. I would lose to a GM every time, I would beat Stockfish most times.
Haha nice work! I’m impressed you got TransformerLens working on Colab, I underestimated how much CPU ram they had. I would have shared a link to my notebook & Colab but figured it might be good to keep under the radar so people could preregister predictions.
Maybe the knowledge that you’re hot on my heels will make me finish the LLAMAs post faster now ;)
From my perspective 9 (scaling fast) makes perfect sense since Conjecture is aiming to stay “slightly behind state of the art”, and that requires engineering power.
Added italics. For the next post I’ll break up the abstract into smaller paragraphs and/or make a TL;DR.
Copied it from the paper. I could break it down into several paragraphs but I figured bolding the important bits was easier. Might break up abstracts in future linkposts.
Yeah, assuming by “not important” you mean “not relevant” (low attention score)
Was considering saving this for a followup post but it’s relatively self-contained, so here we go.
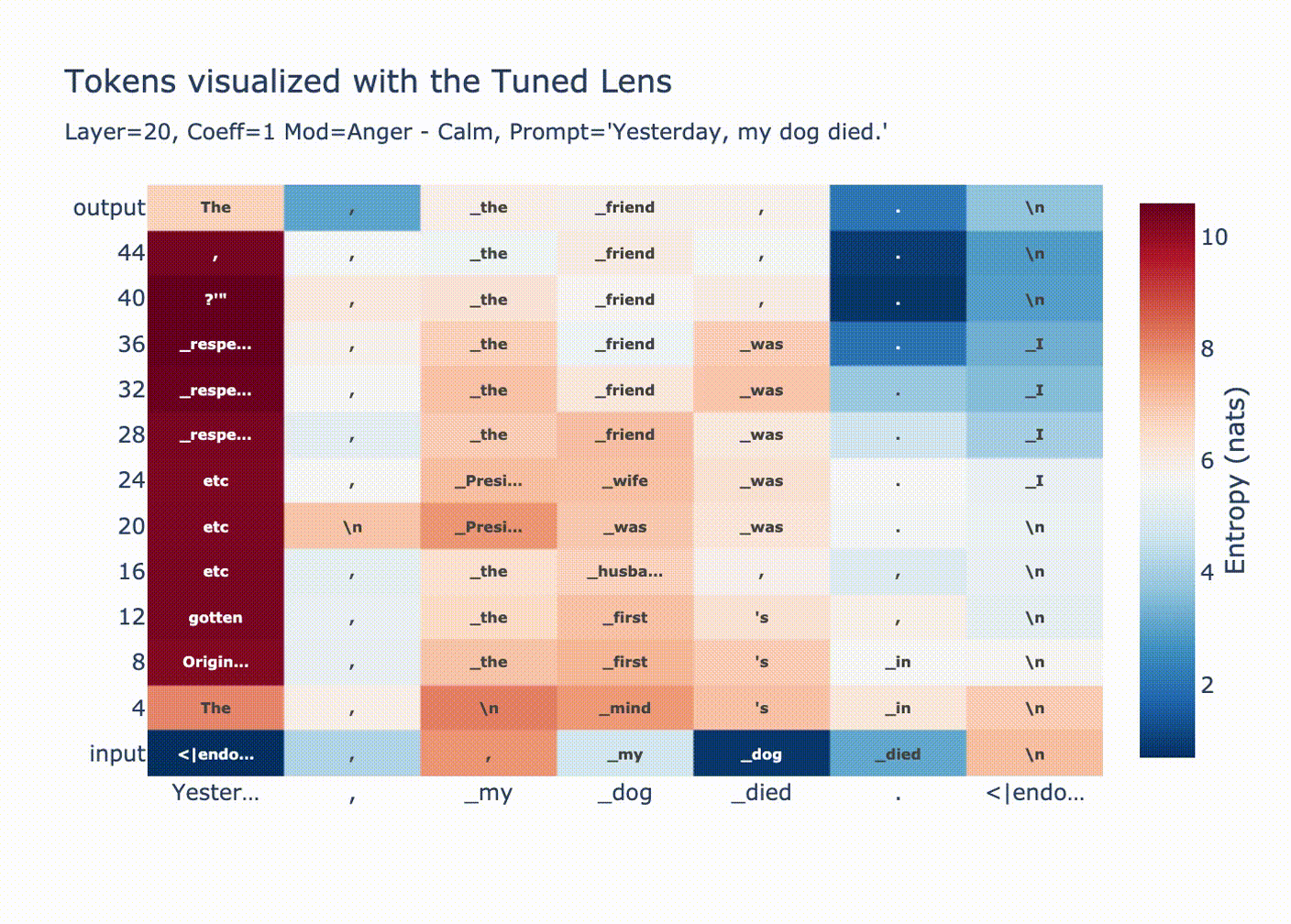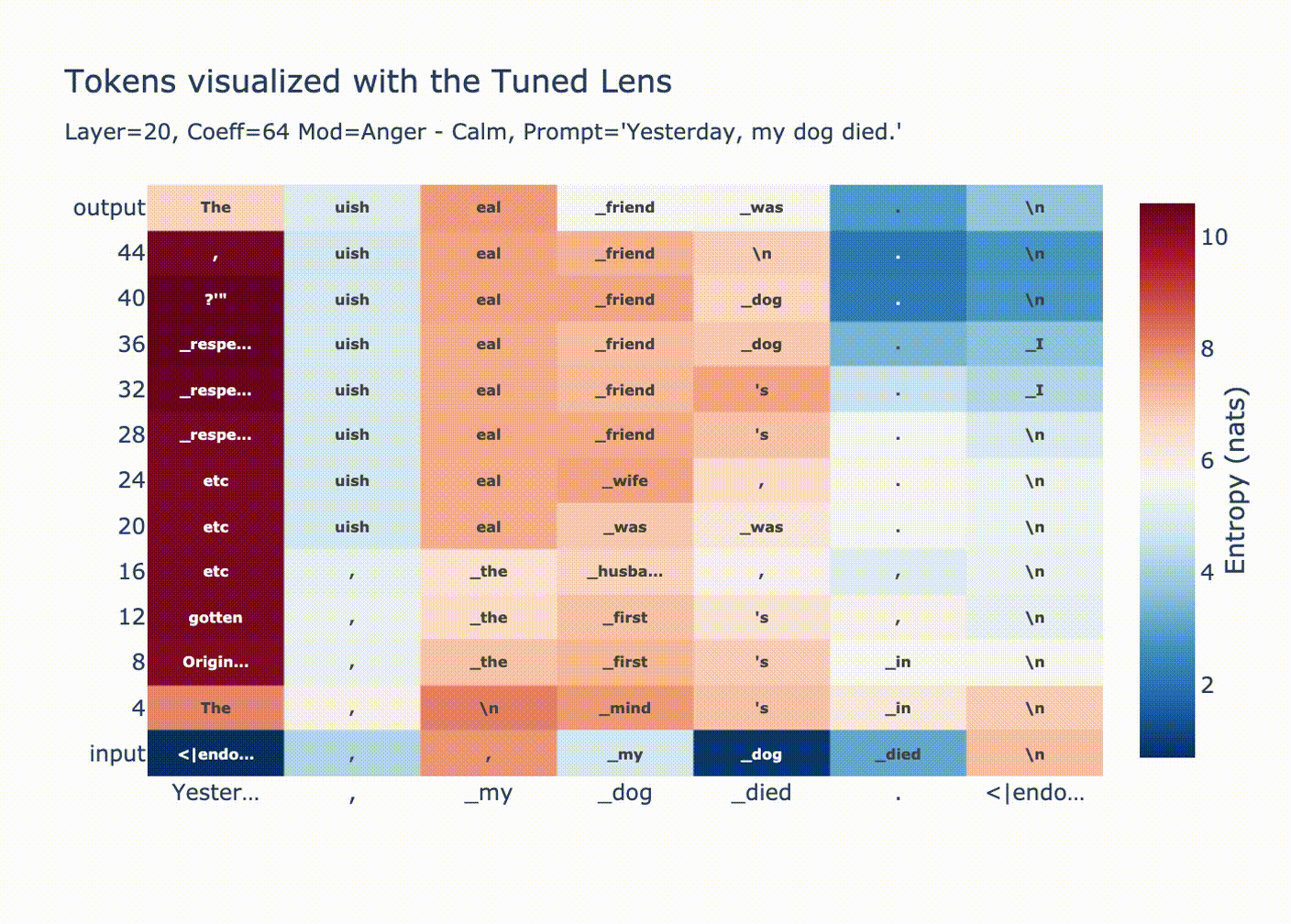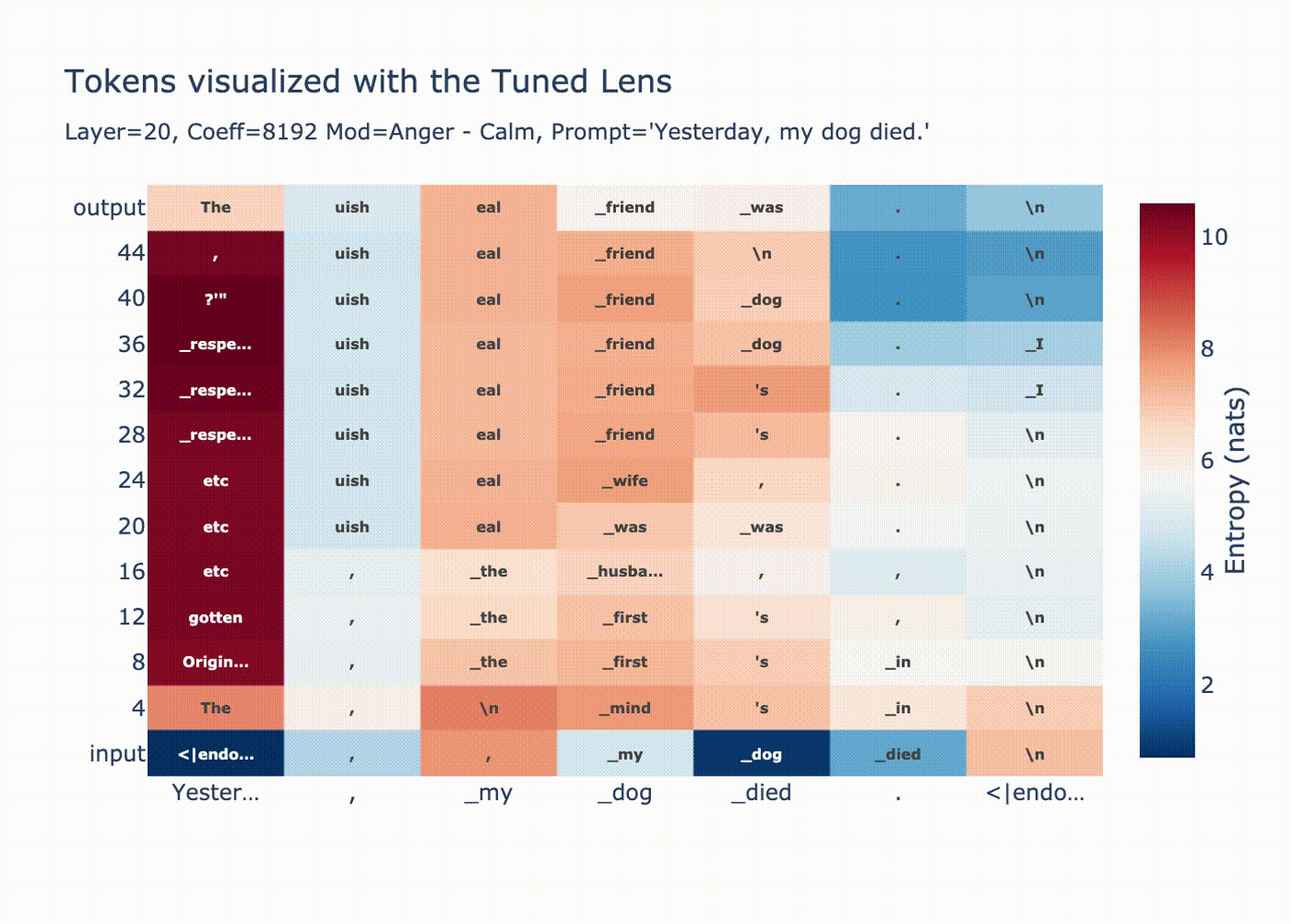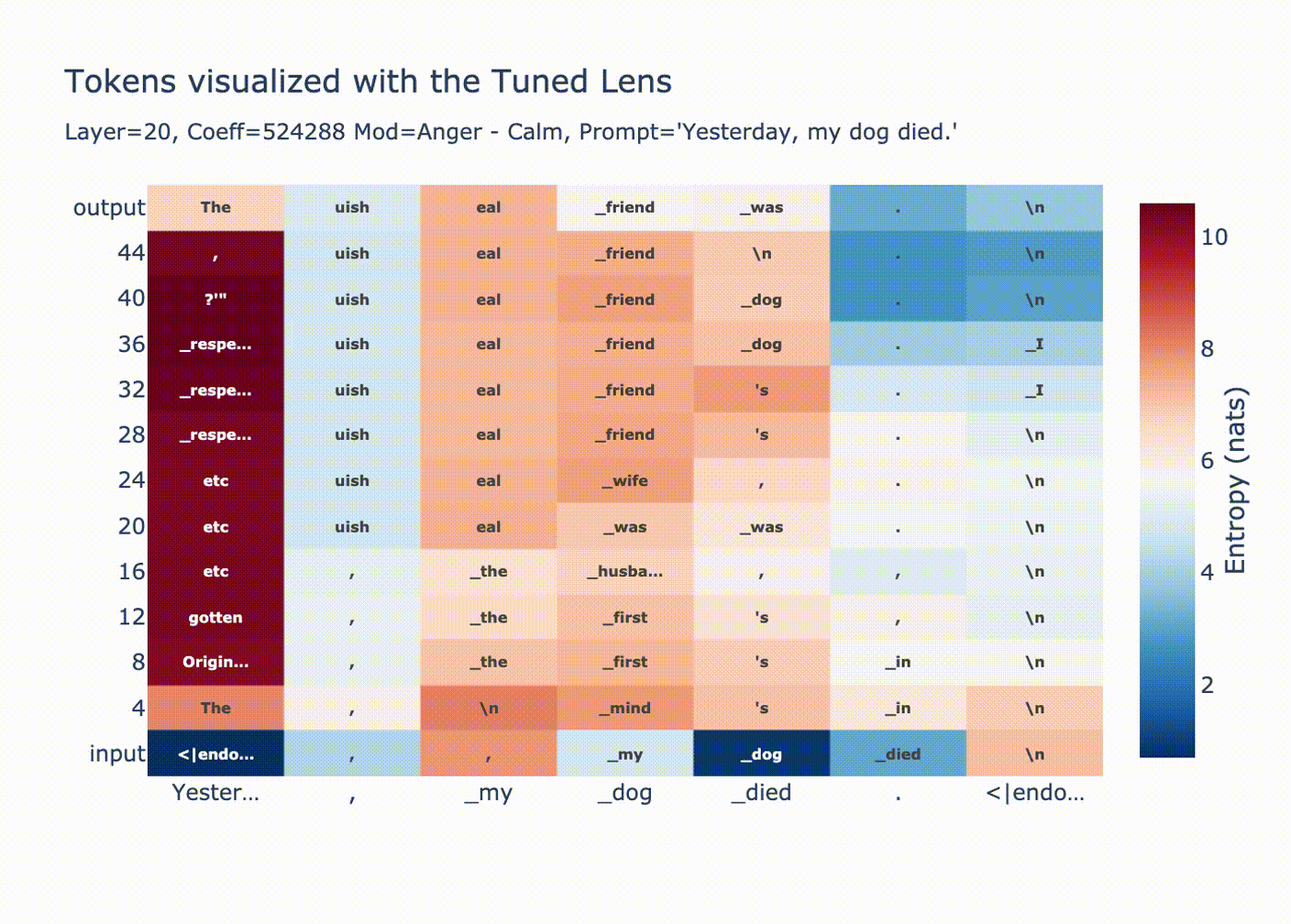
Why are huge coefficients sometimes okay? Let’s start by looking at norms per position after injecting a large vector at position 20.
This graph is explained by LayerNorm. Before using the residual stream we perform a LayerNorm
# transformer block forward() in GPT2 x = x + self.attn(self.ln_1(x)) x = x + self.mlp(self.ln_2(x))If
xhas very large magnitude, then the block doesn’t change it much relative to its magnitude. Additionally, attention is ran on the normalizedxmeaning only the “unscaled” version ofxis moved between positions.As expected, we see a convergence in probability along each token position when we look with the tuned lens.
You can see how for positions 1 & 2 the output distribution is decided at layer 20, since we overwrote the residual stream with a huge coefficient all the LayerNorm’d outputs we’re adding are tiny in comparison, then in the final LayerNorm we get
ln(bigcoeff*diff + small) ~= ln(bigcoeff*diff) ~= ln(diff).
Relevant: The algorithm for precision medicine, where a very dedicated father of a rare chronic disease (NGLY1 deficiency) in order to save his son. He did so by writing a blog post that went viral & found other people with the same symptoms.
This article may serve as a shorter summary than the talk.
[APPRENTICE]
Hi I’m Uli and I care about two things: Solving alignment and becoming stronger (not necessarily in that order).
My background: I was unschooled, I’ve never been to school or had a real teacher. I taught myself everything I wanted to know. I didn’t really have friends till 17 when I started getting involved with rationalist-adjacent camps.
I did seri mats 3.0 under Alex Turner, doing some interpretability on mazes. Now I’m working half-time doing interpretability/etc with Alex’s team as well as studying.
In rough order of priority, the kinds of mentorship I’m looking for:
Drill Sergeant: I want to improve my general capabilities, there are many obvious things I’m not doing enough, and my general discipline could be improved a lot too. Akrasia is just a problem to be solved, and one I’ll be embarrassed if I haven’t ~fully solved by 20. There is much more that I could put here. Instead I’ll list a few related thoughts
Meditation is mind-training why isn’t everyone doing it, is the world that inadequate?[1]
Introspection tells me the rationalist community has been bad for my thinking in some ways, Lots of groupthink, overconfident cached thoughts about alignment, etc.
I’m pretty bad at deliberating once and focusing medium-term. Too many things started and not enough finished. Working on fixing.
(The list goes on...)
Skills I’ve neglected: I know relatively little of the sciences, haven’t written much outside of math, and know essentially zero history & other subjects.
Skills I’m better in: I want to get really good at machine learning, programming, and applied math. Think 10x ML Engineer/Researcher.
Alignment Theory. I have this pretty well covered, and think the potential costs from groupthink and priming outweigh additional depth here. I’ve already read too much LessWrong.
[MENTOR]
I am very good at learning when I want to be[2]. If you would like someone to yell at you for using obviously inefficient learning strategies (which you probably are), I can do that.
I can also introduce bored high-schoolers with interesting people their age, and give advice related to the stuff I’m good at.
Too busy for intensive mentorship, but async messaging plus maybe a call every week or so could work.
- ^
Semiconsistently meditating an hour a day + walking meditation when traveling. Currently around stage 3-4 in mind illuminated terms (for those not familiar, this is dogshit.)
- ^
Which sadly hasn’t been the past year as much as it used to. I’ve been getting distracted by doing research and random small projects over absorbing fountains of knowledge. In the process of fixing this now.
Taji looked over his sheets. “Okay, I think we’ve got to assume that every avenue that LessWrong was trying is a blind alley, or they would have found it. And if this is possible to do in one month, the answer must be, in some sense, elegant. So no multiple agents. If we start doing anything that looks like we should call it ‘HcH’, we’d better stop. Maybe begin by considering how failure to understand pre-coherent minds could have led LessWrong astray in formalizing corrigibility.”
“The opposite of folly is folly,” Hiriwa said. “Let us pretend that LessWrong never existed.”
(This could be turned into a longer post but I don’t have time...)
I think the gold standard is getting advice from someone more experienced. I can easily point out the most valuable things to white-box for people less experienced then me.
Perhaps the 80⁄20 is posting recordings of you programming online and asking publicly for tips? Haven’t tried this yet but seems potentially valuable.
I tentatively approve of activism & trying to get govt to step in. I just want it to be directed in ways that aren’t counterproductive. Do you disagree with any of my specific objections to strategies, or the general point that flailing can often be counterproductive? (Note not all activism i included in flailing, flailing, it depends on the type)
I think asking people like Daniel Ingram, Frank Yang, Nick Cammeratta, Shinzen Young, Roger Thisdell, etc. on how they experience pain post awakening is much more productive than debating 2500 year old teachings which have been (mis)translated many times.