Born too late to explore Earth; born too early to explore the galaxy; born just the right time to save humanity.
Ulisse Mini
Karma: 1,720
TinyStories: Small Language Models That Still Speak Coherent English
Was considering saving this for a followup post but it’s relatively self-contained, so here we go.
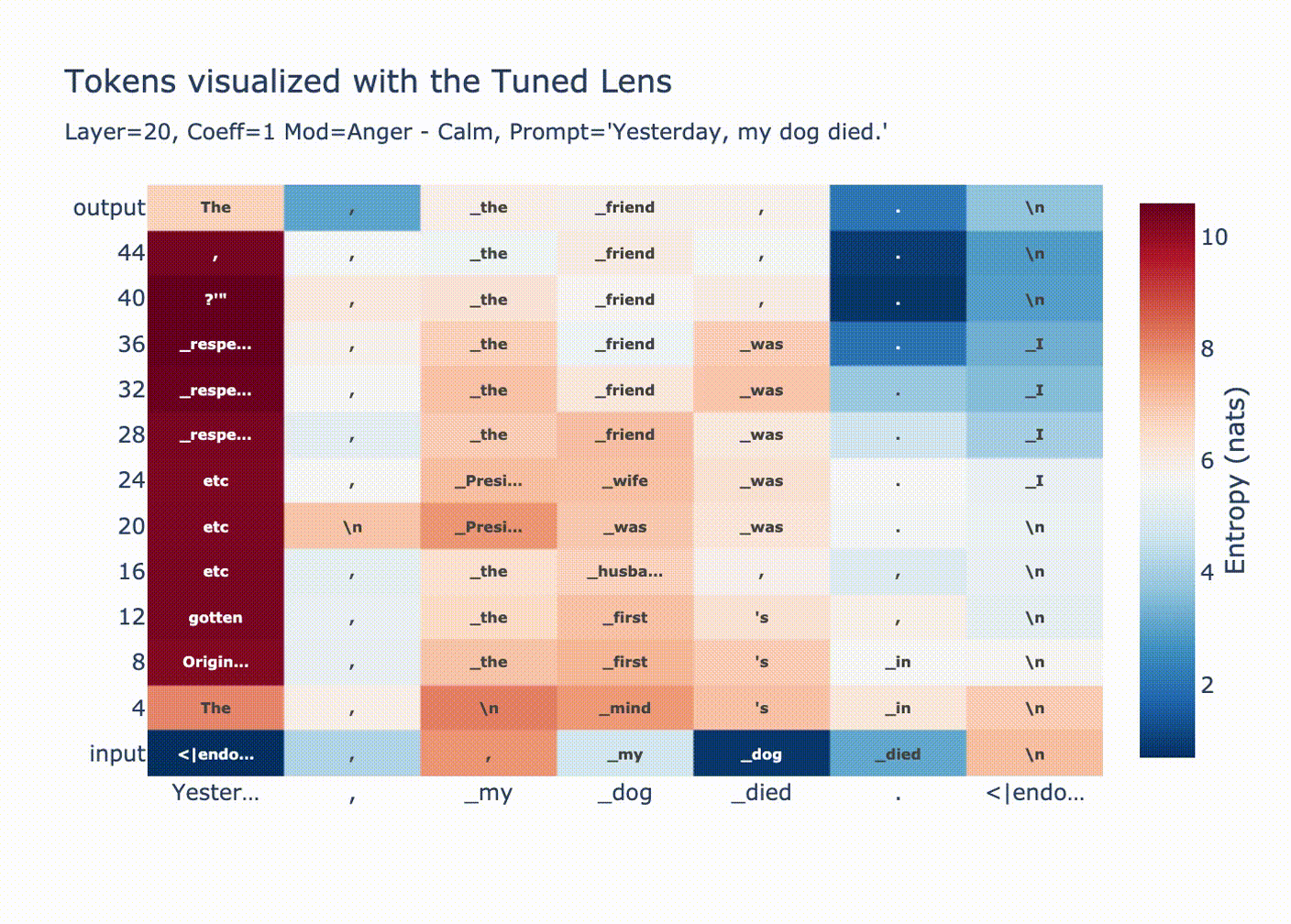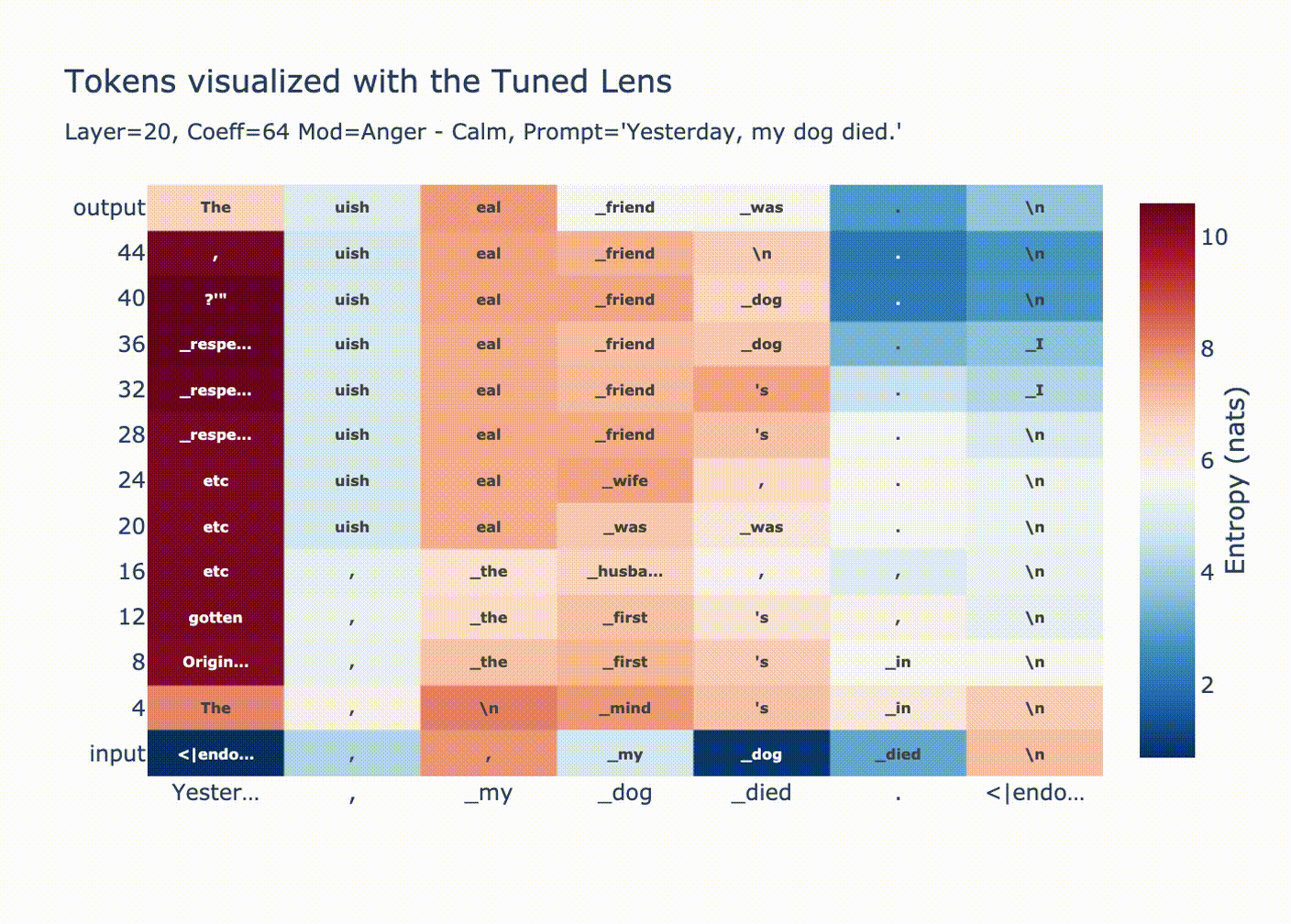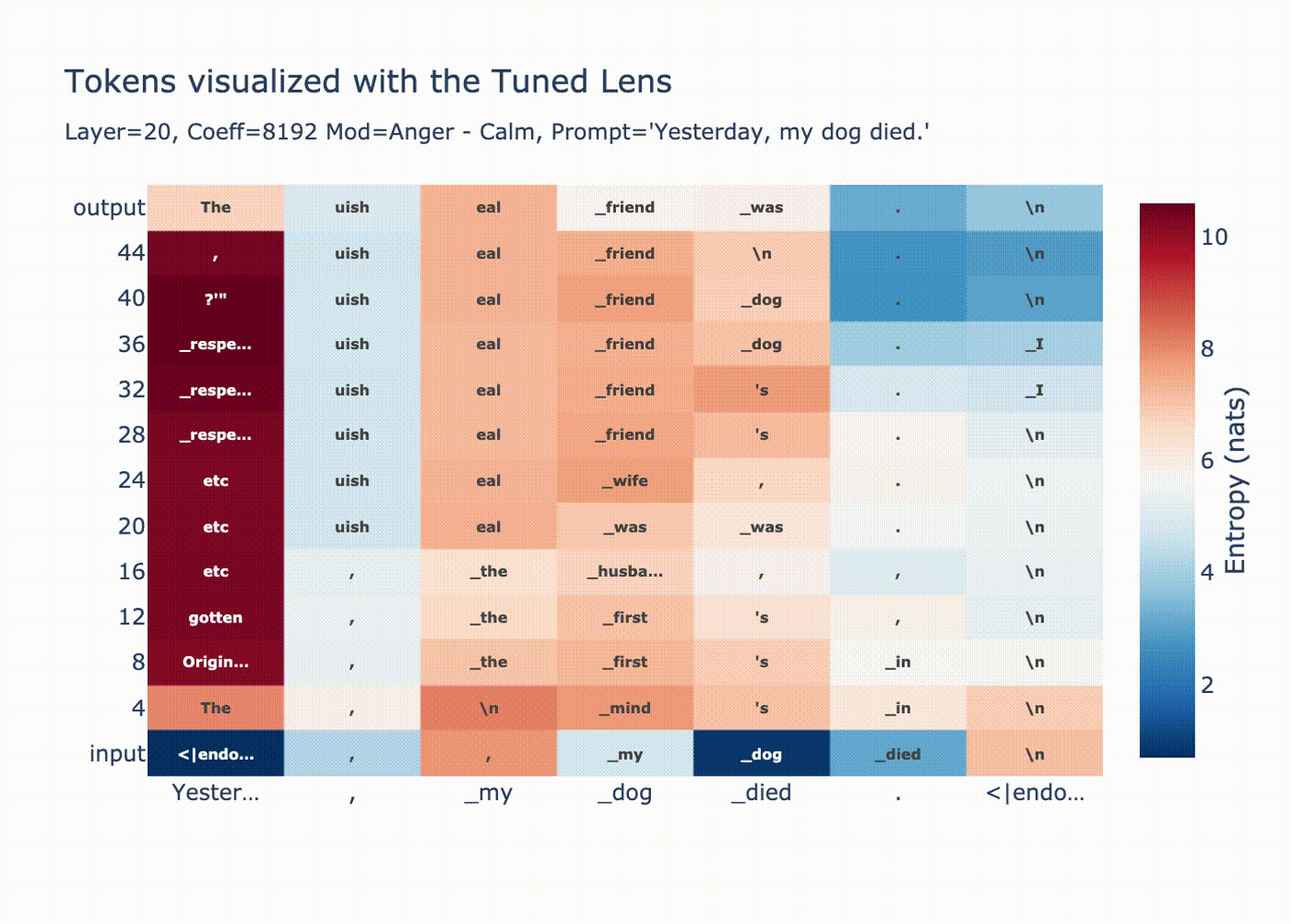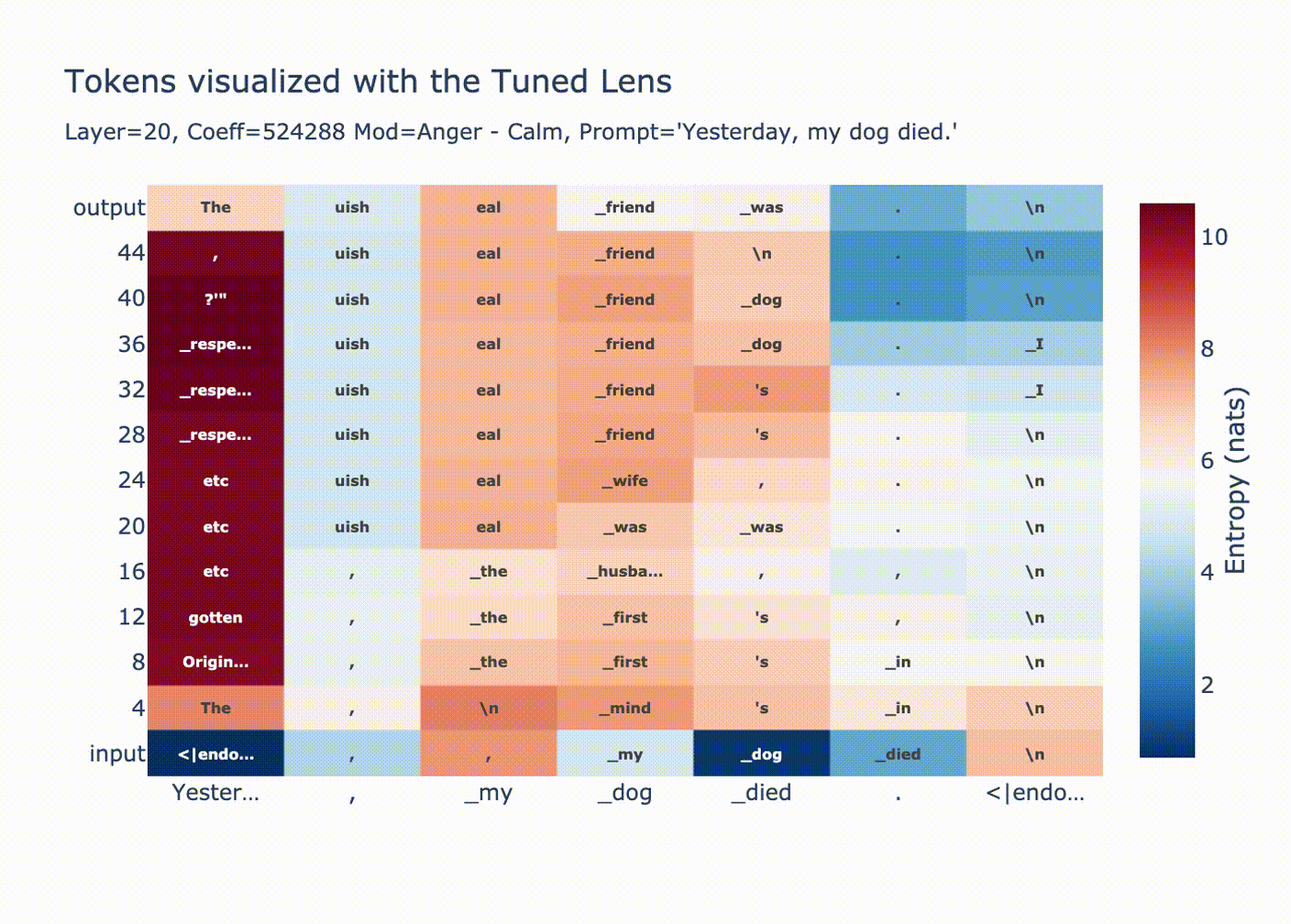
Why are huge coefficients sometimes okay? Let’s start by looking at norms per position after injecting a large vector at position 20.
This graph is explained by LayerNorm. Before using the residual stream we perform a LayerNorm
# transformer block forward() in GPT2 x = x + self.attn(self.ln_1(x)) x = x + self.mlp(self.ln_2(x))If
xhas very large magnitude, then the block doesn’t change it much relative to its magnitude. Additionally, attention is ran on the normalizedxmeaning only the “unscaled” version ofxis moved between positions.As expected, we see a convergence in probability along each token position when we look with the tuned lens.
You can see how for positions 1 & 2 the output distribution is decided at layer 20, since we overwrote the residual stream with a huge coefficient all the LayerNorm’d outputs we’re adding are tiny in comparison, then in the final LayerNorm we get
ln(bigcoeff*diff + small) ~= ln(bigcoeff*diff) ~= ln(diff).
Relevant: The algorithm for precision medicine, where a very dedicated father of a rare chronic disease (NGLY1 deficiency) in order to save his son. He did so by writing a blog post that went viral & found other people with the same symptoms.
This article may serve as a shorter summary than the talk.
Steering GPT-2-XL by adding an activation vector
[APPRENTICE]
Hi I’m Uli and I care about two things: Solving alignment and becoming stronger (not necessarily in that order).
My background: I was unschooled, I’ve never been to school or had a real teacher. I taught myself everything I wanted to know. I didn’t really have friends till 17 when I started getting involved with rationalist-adjacent camps.
I did seri mats 3.0 under Alex Turner, doing some interpretability on mazes. Now I’m working half-time doing interpretability/etc with Alex’s team as well as studying.
In rough order of priority, the kinds of mentorship I’m looking for:
Drill Sergeant: I want to improve my general capabilities, there are many obvious things I’m not doing enough, and my general discipline could be improved a lot too. Akrasia is just a problem to be solved, and one I’ll be embarrassed if I haven’t ~fully solved by 20. There is much more that I could put here. Instead I’ll list a few related thoughts
Meditation is mind-training why isn’t everyone doing it, is the world that inadequate?[1]
Introspection tells me the rationalist community has been bad for my thinking in some ways, Lots of groupthink, overconfident cached thoughts about alignment, etc.
I’m pretty bad at deliberating once and focusing medium-term. Too many things started and not enough finished. Working on fixing.
(The list goes on...)
Skills I’ve neglected: I know relatively little of the sciences, haven’t written much outside of math, and know essentially zero history & other subjects.
Skills I’m better in: I want to get really good at machine learning, programming, and applied math. Think 10x ML Engineer/Researcher.
Alignment Theory. I have this pretty well covered, and think the potential costs from groupthink and priming outweigh additional depth here. I’ve already read too much LessWrong.
[MENTOR]
I am very good at learning when I want to be[2]. If you would like someone to yell at you for using obviously inefficient learning strategies (which you probably are), I can do that.
I can also introduce bored high-schoolers with interesting people their age, and give advice related to the stuff I’m good at.
Too busy for intensive mentorship, but async messaging plus maybe a call every week or so could work.
- ^
Semiconsistently meditating an hour a day + walking meditation when traveling. Currently around stage 3-4 in mind illuminated terms (for those not familiar, this is dogshit.)
- ^
Which sadly hasn’t been the past year as much as it used to. I’ve been getting distracted by doing research and random small projects over absorbing fountains of knowledge. In the process of fixing this now.
Taji looked over his sheets. “Okay, I think we’ve got to assume that every avenue that LessWrong was trying is a blind alley, or they would have found it. And if this is possible to do in one month, the answer must be, in some sense, elegant. So no multiple agents. If we start doing anything that looks like we should call it ‘HcH’, we’d better stop. Maybe begin by considering how failure to understand pre-coherent minds could have led LessWrong astray in formalizing corrigibility.”
“The opposite of folly is folly,” Hiriwa said. “Let us pretend that LessWrong never existed.”
(This could be turned into a longer post but I don’t have time...)
I think the gold standard is getting advice from someone more experienced. I can easily point out the most valuable things to white-box for people less experienced then me.
Perhaps the 80⁄20 is posting recordings of you programming online and asking publicly for tips? Haven’t tried this yet but seems potentially valuable.
How to get good at programming
I tentatively approve of activism & trying to get govt to step in. I just want it to be directed in ways that aren’t counterproductive. Do you disagree with any of my specific objections to strategies, or the general point that flailing can often be counterproductive? (Note not all activism i included in flailing, flailing, it depends on the type)
Downvoted because I view some of the suggested strategies as counterproductive. Specifically, I’m afraid of people flailing. I’d be much more comfortable if there was a bolded paragraph saying something like the following:
Beware of flailing and second-order effects and the unilateralist’s curse. It is very easy to end up doing harm with the intention to do good, e.g. by sharing bad arguments for alignment, polarizing the issue, etc.
To give specific examples illustrating this (which may also be good to include and/or edit the post):
I believe tweets like this are much better (and net positive) then the tweet you give as an example. Sharing anything less then the strongest argument can be actively bad to the extent it immunizes people against the actually good reasons to be concerned.
Most forms of civil disobedience seems actively harmful to me. Activating the tribal instincts of more mainstream ML researchers, causing them to hate the alignment community, would be pretty bad in my opinion. Protesting in the streets seems fine, protesting by OpenAI hq does not.
Don’t have time to write more. For more info see this twitter exchange I had with the author, though I could share more thoughts and models my main point is be careful, taking action is fine, and don’t fall into the analysis-paralysis of some rationalists, but don’t make everything worse.
Thanks for the insightful response! Agree it’s just suggestive for now. Though more then with image models (where I’d expect lenses to transfer really badly, but don’t know). Perhaps it being a residual network is the key thing, since effective path lengths are low most of the information is “carried along” unchanged, meaning the same probe continues working for other layers. Idk
Don’t we have some evidence GPTs are doing iterative prediction updating from the logit lens and later tuned lens? Not that that’s all they’re doing of course.
Strong upvoted and agreed. I don’t think the public has opinions on AI X-Risk yet, so any attempt to elicit them will entirely depend on framing.
Strong upvoted to counter some of the downvotes.
I’ll note (because some commenters seem to miss this) that Eliezer is writing in a convincing style for a non-technical audience. Obviously the debates he would have with technical AI safety people are different then what is most useful to say to the general population.
EDIT: I think the effects were significantly worse than this and caused a ton of burnout and emotional trauma. Turns out thinking the world will end with 100% probability if you don’t save it, plus having heroic responsibility, can be a little bit tough sometimes...
I worry most people will ignore the warnings around willful inconsistency, so let me self-report that I did this and it was a bad idea. Central problem: It’s hard to rationally update off new evidence when your system 1 is utterly convinced of something. And I think this screwed with my epistemics around Shard Theory while making communication with people about x-risk much harder, since I’d often typical mind and skip straight to the paperclipper—the extreme scenario I was (and still am to some extent) trying to avoid as my main case.
When my rationality level is higher and my takes have solidified some more I might try this again, but right now it’s counterproductive. System 2 rationality is hard when you have to constantly correct for false System 1 beliefs!
I feel there’s often a wrong assumption in probabilistic reasoning, something like moderate probabilities for everything by default? after all, if you say you’re 70⁄30 nobody who disagrees will ostracize you like if you say 99⁄1.
“If alignment is easy I want to believe alignment is easy. If alignment is hard I want to believe alignment is hard. I will work to form accurate beliefs”
Petition to rename “noticing confusion” to “acting on confusion” or “acting to resolve confusion”. I find myself quite good at the former but bad at the latter—and I expect other rationalists are the same.
For example: I remember having the insight thought leading to lsusr’s post on how self-reference breaks the orthogonality thesis, but never pursued the line of questioning since it would require sitting down and questioning my beliefs with paper for a few minutes, which is inconvenient and would interrupt my coding.
Strongly agree. Rationalist culture is instrumentally irrational here. It’s very well known how important self-belief & a growth mindset is for success, and rationalists obsession with natural intelligence quite bad imo, to the point where I want to limit my interaction with the community so I don’t pick up bad patterns.
I do wonder if you’re strawmanning the advice a little, in my friend circles dropping out is seen as reasonable, though this could just be because a lot of my high-school friends already have some legible accomplishments and skills.
Yeah, assuming by “not important” you mean “not relevant” (low attention score)