Engineer at METR.
Previously: Vivek Hebbar’s team at MIRI → Adrià Garriga-Alonso onvarious empirical alignment projects → METR.
I have signed no contracts or agreements whose existence I cannot mention.
Engineer at METR.
Previously: Vivek Hebbar’s team at MIRI → Adrià Garriga-Alonso onvarious empirical alignment projects → METR.
I have signed no contracts or agreements whose existence I cannot mention.
Benchmark Readiness Level
Safety-relevant properties should be ranked on a “Benchmark Readiness Level” (BRL) scale, inspired by NASA’s Technology Readiness Levels. At BRL 4, a benchmark exists; at BRL 6 the benchmark is highly valid; past this point the benchmark becomes increasingly robust against sandbagging. The definitions could look something like this:
| BRL | Definition | Example |
| 1 | Theoretical relevance to x-risk defined | Adversarial competence |
| 2 | Property operationalized for frontier AIs and ASIs | AI R&D speedup; Misaligned goals |
| 3 | Behavior (or all parts) observed in artificial settings. Preliminary measurements exist, but may have large methodological flaws. | Reward hacking |
| 4 | Benchmark developed, but may measure different core skills from the ideal measure | Cyber offense (CyBench) |
| 5 | Benchmark measures roughly what we want; superhuman range; methodology is documented and reproducible but may have validity concerns. | Software (HCAST++) |
| 6 | "Production quality" high-validity benchmark. Strongly superhuman range; run on many frontier models; red-teamed for validity; represents all sub-capabilities. Portable implementation. | |
| 7 | Extensive validity checks against downstream properties; reasonable attempts (e.g. fine-tuning) to detect whether AIs are manipulating/sandbagging their scores. | Knowledge (MMLU with fine-tuning) |
| 8 | − | |
| 9 | Benchmark has high validity to real-world contexts beyond lab settings. Can ensure accuracy even when measuring superintelligences with potentially deceptive capabilities. | - |
Here’s a draft list of properties we could apply the BRL to, including capabilities and propensity:
General capabilities
Software ability (HCAST, others)
Knowledge (Humanity’s Last Exam, others)
Sandbagging
Situational awareness
Alignment faking
Sandbagging ability
Monitorability
Steganographic collusion
Neuralese
Faithful CoT
Ability to monitor smarter AIs
Research acceleration
% LoC written by AIs
AI R&D Uplift
Escape risk
Adversarial competence
Self-exfiltration
Cyber offense
Misalignment
Reward hacking
Misaligned goals
Other Dangers
CBRN
Persuasion
Is this doomed? Am I missing anything important?
Some versions of the METR time horizon paper from alternate universes:
Measuring AI Ability to Take Over Small Countries (idea by Caleb Parikh)
Abstract: Many are worried that AI will take over the world, but extrapolation from existing benchmarks suffers from a large distributional shift that makes it difficult to forecast the date of world takeover. We rectify this by constructing a suite of 193 realistic, diverse countries with territory sizes from 0.44 to 17 million km^2. Taking over most countries requires acting over a long time horizon, with the exception of France. Over the last 6 years, the land area that AI can successfully take over with 50% success rate has increased from 0 to 0 km^2, doubling 0 times per year (95% CI 0.0-∞ yearly doublings); extrapolation suggests that AI world takeover is unlikely to occur in the near future. To address concerns about the narrowness of our distribution, we also study AI ability to take over small planets and asteroids, and find similar trends.
When Will Worrying About AI Be Automated?
Abstract: Since 2019, the amount of time LW has spent worrying about AI has doubled every seven months, and now constitutes the primary bottleneck to AI safety research. Automation of worrying would be transformative to the research landscape, but worrying includes several complex behaviors, ranging from simple fretting to concern, anxiety, perseveration, and existential dread, and so is difficult to measure. We benchmark the ability of frontier AIs to worry about common topics like disease, romantic rejection, and job security, and find that current frontier models such as Claude 3.7 Sonnet already outperform top humans, especially in existential dread. If these results generalize to worrying about AI risk, AI systems will be capable of autonomously worrying about their own capabilities by the end of this year, allowing us to outsource all our AI concerns to the systems themselves.
Estimating Time Since The Singularity
Early work on the time horizon paper used a hyperbolic fit, which predicted that AGI (AI with an infinite time horizon) was reached last Thursday. [1] We were skeptical at first because the R^2 was extremely low, but recent analysis by Epoch suggested that AI already outperformed humans at a 100-year time horizon by about 2016. We have no choice but to infer that the Singularity has already happened, and therefore the world around us is a simulation. We construct a Monte Carlo estimate over dates since the Singularity and simulator intentions, and find that the simulation will likely be turned off in the next three to six months.
[1]: This is true
Quick list of reasons for me:
I’m averse to attending mass protests myself because they make it harder to think clearly and I usually don’t agree with everything any given movement stands for.
Under my worldview, an unconditional pause is a much harder ask than is required to save most worlds if p(doom) is 14% (the number stated on the website). It seems highly impractical to implement compared to more common regulatory frameworks and is also super unaesthetic because I am generally pro-progress.
The economic and political landscape around AI is complicated enough that agreeing with their stated goals is not enough; you need to agree with their theory of change.
Broad public movements require making alliances which can be harmful in the long term. Environmentalism turned anti-nuclear, a decades-long mistake which has accelerated climate change by years. PauseAI wants to include people who oppose AI on its present dangers, which makes me uneasy. What if the landscape changes such that the best course of action is contrary to PauseAI’s current goals?
I think PauseAI’s theory of change is weak
From reading the website, they want to leverage protests, volunteer lobbying, and informing the public into an international treaty banning superhuman AI and a unilateral supply-chain pause. It seems hard for the general public to have significant influence over this kind of issue unless AI rises to the top issue for most Americans, since the current top issue is improving the economy, which directly conflicts with a pause.
There are better theories of change
Strengthening RSPs into industry standards, then regulations.
Directly informing elites about the dangers of AI, rather than the general public.
History (e.g. civil rights movement) shows that moderates not publicly endorsing radicals can result in a positive radical flank effect making moderates’ goals easier to achieve.
I basically agree with this. The reason the paper didn’t include this kind of reasoning (only a paragraph about how AGI will have infinite horizon length) is we felt that making a forecast based on a superexponential trend would be too much speculation for an academic paper. (There is really no way to make one without heavy reliance on priors; does it speed up by 10% per doubling or 20%?) It wasn’t necessary given the 2027 and 2029-2030 dates for 1-month AI derived from extrapolation already roughly bracketed our uncertainty.
External validity is a huge concern, so we don’t claim anything as ambitious as average knowledge worker tasks. In one sentence, my opinion is that our tasks suite is fairly representative of well-defined, low-context, measurable software tasks that can be done without a GUI. More speculatively, horizons on this are probably within a large (~10x) constant factor of horizons on most other software tasks. We have a lot more discussion of this in the paper, especially in heading 7.2.1 “Systematic differences between our tasks and real tasks”. The HCAST paper also has a better description of the dataset.
We didn’t try to make the dataset a perfectly stratified sample of tasks meeting that description, but there is enough diversity in the dataset that I’m much more concerned about relevance of HCAST-like tasks to real life than relevance of HCAST to the universe of HCAST-like tasks.
Humans don’t need 10x more memory per step nor 100x more compute to do a 10-year project than a 1-year project, so this is proof it isn’t a hard constraint. It might need an architecture change but if the Gods of Straight Lines control the trend, AI companies will invent it as part of normal algorithmic progress and we will remain on an exponential / superexponential trend.
Regarding 1 and 2, I basically agree that SWAA doesn’t provide much independent signal. The reason we made SWAA was that models before GPT-4 got ~0% on HCAST, so we needed shorter tasks to measure their time horizon. 3 is definitely a concern and we’re currently collecting data on open-source PRs to get a more representative sample of long tasks.
That bit at the end about “time horizon of our average baseliner” is a little confusing to me, but I understand it to mean “if we used the 50% reliability metric on the humans we had do these tasks, our model would say humans can’t reliably perform tasks that take longer than an hour”. Which is a pretty interesting point.
That’s basically correct. To give a little more context for why we don’t really believe this number, during data collection we were not really trying to measure the human success rate, just get successful human runs and measure their time. It was very common for baseliners to realize that finishing the task would take too long, give up, and try to collect speed bonuses on other tasks. This is somewhat concerning for biasing the human time-to-complete estimates, but much more concerning for this human time horizon measurement. So we don’t claim the human time horizon as a result.
All models since at least GPT-3 have had this steep exponential decay [1], and the whole logistic curve has kept shifting to the right. The 80% success rate horizon has basically the same 7-month doubling time as the 50% horizon so it’s not just an artifact of picking 50% as a threshold.
Claude 3.7 isn’t doing better on >2 hour tasks than o1, so it might be that the curve is compressing, but this might also just be noise or imperfect elicitation.
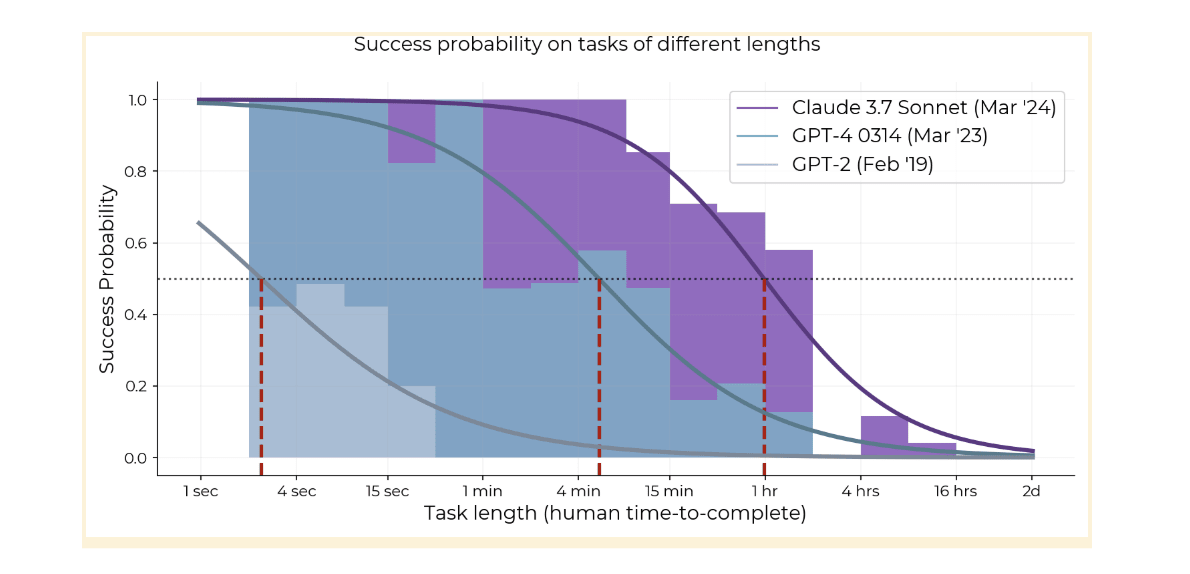
Regarding the idea that autoregressive models would plateau at hours or days, it’s plausible, and one point of evidence is that models are not really coherent over hundreds of steps (generations + uses of the Python tool) yet—they do 1-2 hour tasks with ~10 actions, see section 5 of HCAST paper. On the other hand, current LLMs can learn a lot in-context and it’s not clear there are limits to this. In our qualitative analysis we found evidence of increasing coherence, where o1 fails tasks due to repeating failed actions 6x less than GPT-4 1106.
Maybe this could be tested by extracting ~1 hour tasks out of the hours to days long projects that we think are heavy in self-modeling, like planning. But we will see whether there’s a plateau at the hours range in the next year or two anyway.
[1] we don’t have easy enough tasks that GPT-2 can do them with >50% success, so can’t check the shape
It’s expensive to construct and baseline novel tasks for this (we spent well over $100k on human baselines) so what we are able to measure in the future depends on whether we can harvest realistic tasks that naturally have human data. You could do a rough analysis on math contest problems, say assigning GSM8K and AIME questions lengths based on a guess of how long expert humans take, but the external validity concerns are worse than for software. For one thing, AIME has much harder topics than GSM8K (we tried to make SWAA not be artificially easier or harder than HCAST); for another, neither are particularly close to the average few minutes of a research mathematician’s job.
The trend probably sped up in 2024. If the future trend follows the 2024--2025 trend, we get 50% reliability at 167 hours in 2027.
Author here. My best guess is that by around the 1-month point, AIs will be automating large parts of both AI capabilities and empirical alignment research. Inferring anything more depends on many other beliefs.
Currently no one knows how hard the alignment problem is or what exactly good alignment research means—it is the furthest-looking, least well-defined and least tractable of the subfields of AI existential safety. This means we don’t know the equivalent task length of the alignment problem. Even more importantly, we only measured the AIs at software tasks and don’t know what the trend is for other domains like math or law, it could be wildly different.
With that said, my current guess is that alignment will be sped up by AI slightly less than capabilities will be, success looks like building deferrable AI, and whether we succeed depends on whether the world dedicates more than X% [1] of AI research resources to relevant safety research than the exact software time horizon of the AIs involved, which is not directly applicable.
[1] X is some unknown number probably between 0% and 65%
AIs (and humans) don’t have 100% reliability at anything, so the graph tracks when AIs get a 50% success rate on our dataset, over all tasks and attempts. We also measure AI horizons at 80% success rate in the paper, and those are about 5x shorter. It’s hard to measure much higher than 80% with our limited task suite, but if we could we would measure 95% and 99% as well.
So the citation is an unreleased paper! That unreleased paper may make a splash, since (assuming this 7-month-doubling trend is not merely 1-2 years old) it strongly implies we really will find good solutions for turning LLMs agentic fairly soon.
The 7-month doubling trend we measured actually goes back to GPT-2 in 2019. Since 2024, the trend has been faster, doubling roughly every 3-4 months depending on how you measure, but we only have six 2024-25 models so error bars are wide and it’s really unclear which trend will be predictive of the future.
Important results from the paper as I see it:
RL agents can learn to cheat in the wild, and CoT pressure doesn’t prevent it.
The slope of cheating increase and final cheating rate are both slightly lower when applying CoT pressure, but all of the cheating will go uncaught by the monitor.
GPT-4o can zero-shot monitor o3-level agents with 95% accuracy when it has access to CoT, only 60% when it can only monitor actions.
If there is no CoT pressure, RL agents telegraph their cheating, such that cheating precision and recall actually go up over time for a monitor that can only see CoT
True utility (success rate counting cheating as failure) initially increases faster with CoT pressure than without, despite low initial levels of cheating in both.
I’m not sure why this is given they said the only change in reward related to CoT pressure is that the agent doesn’t get reward when the monitor flags.
If you allow rejection sampling, the utility curve is roughly similar between CoT pressure and no CoT pressure. This rhymes with the Scaling Laws for Reward Model Overoptimization result where utility is similar between RL and best-of-k
Speculation:
The information that the model is cheating seems basically gone from the CoT, so training against a weak monitor and monitoring using a stronger monitor could be unreliable
How much CoT pressure should you apply to maximize utility? Figure 4 suggests that if you do RL, cheating will happen at roughly the same point in training with or without CoT pressure (~0.3 epochs), which also coincides with the maximum utility point, so stop at the point where the non-CoT-pressure model starts to do detectable cheating.
It is unclear how this applies to cheating / other malicious behaviors that are hard enough that they require CoT. My prior is that capabilities at hiding misaligned behaviors under CoT monitoring will improve at similar rates to capabilities at reasoning without CoT in other domains, although the presence of a monitor might specifically target the skill of obfuscating misaligned reasoning and make it happen sooner.
I think we have two separate claims here:
Do technologies that have lots of resources put into their development generally improve discontinuously or by huge slope changes?
Do technologies often get displaced by technologies with a different lineage?
I agree with your position on (2) here. But it seems like the claim in the post that sometime in the 2030s someone will make a single important architectural innovation that leads to takeover within a year mostly depends on (1), as it would require progress within that year to be comparable to all the progress from now until that year. Also you said the architectural innovation might be a slight tweak to the LLM architecture, which would mean it shares the same lineage.
The history of machine learning seems pretty continuous wrt advance prediction. In the Epoch graph, the line fit on loss of the best LSTM up to 2016 sees a slope change of less than 2x, whereas a hypothetical innovation that causes takeover within a year with not much progress in the intervening 8 years would be ~8x. So it seems more likely to me (conditional on 2033 timelines and a big innovation) that we get some architectural innovation which has a moderately different lineage in 2027, it overtakes transformers’ performance in 2029, and afterward causes the rate of AI improvement to increase by something like 1.5x-2x.
2 out of 3 of the technologies you listed probably have continuous improvement despite the lineage change
1910-era cars were only a little better than horses, and the overall speed someone could travel long distances in the US probably increased in slope by <2x after cars due to things like road quality improvement before cars and improvements in ships and rail (though maybe railroads were a discontinuity, not sure)
Before refrigerators we had low-quality refrigerators that would contaminate the ice with ammonia, and before that people shipped ice from Maine, so I would expect the cost/quality of refrigeration to have much less than an 8x slope change at the advent of mechanical refrigeration
Only rockets were actually a discontinuity
Tell me if you disagree.
Easy verification makes for benchmarks that can quickly be cracked by LLMs. Hard verification makes for benchmarks that aren’t used.
Agree, this is one big limitation of the paper I’m working on at METR. The first two ideas you listed are things I would very much like to measure, and the third something I would like to measure but is much harder than any current benchmark given that university takes humans years rather than hours. If we measure it right, we could tell whether generalization is steadily improving or plateauing.
Though the fully connected → transformers wasn’t infinite small steps, it definitely wasn’t a single step. We had to invent various sub-innovations like skip connections separately, progressing from RNNs to LSTM to GPT/BERT style transformers to today’s transformer++. The most you could claim is a single step is LSTM → transformer.
Also if you graph perplexity over time, there’s basically no discontinuity from introducing transformers, just a possible change in slope that might be an artifact of switching from the purple to green measurement method. The story looks more like transformers being more able to utilize the exponentially increasing amounts of compute that people started using just before its introduction, which caused people to invest more in compute and other improvements over the next 8 years.
We could get another single big architectural innovation that gives better returns to more compute, but I’d give a 50-50 chance that it would be only a slope change, not a discontinuity. Even conditional on discontinuity it might be pretty small. Personally my timelines are also short enough that there is limited time for this to happen before we get AGI.
A continuous manifold of possible technologies is not required for continuous progress. All that is needed is for there to be many possible sources of improvements that can accumulate, and for these improvements to be small once low-hanging fruit is exhausted.
Case in point: the nanogpt speedrun, where the training time of a small LLM was reduced by 15x using 21 distinct innovations which touched basically every part of the model, including the optimizer, embeddings, attention, other architectural details, quantization, hyperparameters, code optimizations, and Pytorch version.
Most technologies are like this, and frontier AI has even more sources of improvement than the nanogpt speedrun because you can also change the training data and hardware. It’s not impossible that there’s a moment in AI like the invention of lasers or the telegraph, but this doesn’t happen with most technologies, and the fact that we have scaling laws somewhat points towards continuity even as other things like small differences being amplified in downstream metrics point to discontinuity. Also see my comment here on a similar topic.
If you think generalization is limited in the current regime, try to create AGI-complete benchmarks that the AIs won’t saturate until we reach some crucial innovation. People keep trying this and they keep saturating every year.
Time horizon of o3 is ~1.5 hours vs Claude 3.7′s 54 minutes, and it’s statistically significant that it’s above the long-term trend. It’s been less than 2 months since the release of Claude 3.7. If time horizon continues doubling every 3.5 months as it has over the last year, we only have another 12 months until time horizon hits 16 hours and we are unable to measure it with HCAST.
My guess is that future model time horizon will double every 3-4 months for well-defined tasks (HCAST, RE-Bench, most automatically scorable tasks) that labs can RL on, while capability on more realistic tasks will follow the long-term 7-month doubling time.