In METR: Measuring AI Ability to Complete Long Tasks found a Moore’s law like trend relating (model release date) to (time needed for a human to do a task the model can do).
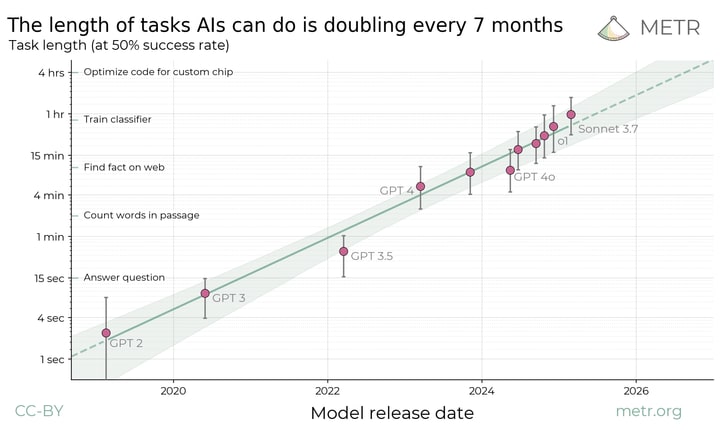
Here is their rationale for plotting this.
Current frontier AIs are vastly better than humans at text prediction and knowledge tasks. They outperform experts on most exam-style problems for a fraction of the cost. With some task-specific adaptation, they can also serve as useful tools in many applications. And yet the best AI agents are not currently able to carry out substantive projects by themselves or directly substitute for human labor. They are unable to reliably handle even relatively low-skill, computer-based work like remote executive assistance. It is clear that capabilities are increasing very rapidly in some sense, but it is unclear how this corresponds to real-world impact.
It seems that AI alignment research falls into this. The LLMs clearly have enough “expertise” at this point, but doing any kind of good research takes an expert a lot of time, even when it is purely on paper.
It seems therefore that we could use Metr’s law to predict when AI will be capable of alignment research. Or at least when it could substantially help.
My question is what time t does “automatically do tasks that humans can do in t” let us do enough research to solve the alignment problem?
(Even if you’re not a fan of automating alignment, if we do make it to that point we might as well give it a shot!)

To apply METR’s law we should distinguish conceptual alignment work from well-defined alignment work (including empirics and theory on existing conjectures). The METR plot doesn’t tell us anything quantitative about the former.
As for the latter, let’s take interpretability as an example: We can model uncertainty as a distribution over the time-horizon needed for interpretability research e.g. ranging over 40-1000 hours. Then, I get 66% CI of 2027-2030 for open-ended interp research automation—colab here. I’ve written up more details on this in a post here.
Author here. My best guess is that by around the 1-month point, AIs will be automating large parts of both AI capabilities and empirical alignment research. Inferring anything more depends on many other beliefs.
Currently no one knows how hard the alignment problem is or what exactly good alignment research means—it is the furthest-looking, least well-defined and least tractable of the subfields of AI existential safety. This means we don’t know the equivalent task length of the alignment problem. Even more importantly, we only measured the AIs at software tasks and don’t know what the trend is for other domains like math or law, it could be wildly different.
With that said, my current guess is that alignment will be sped up by AI slightly less than capabilities will be, success looks like building deferrable AI, and whether we succeed depends on whether the world dedicates more than X% [1] of AI research resources to relevant safety research than the exact software time horizon of the AIs involved, which is not directly applicable.
[1] X is some unknown number probably between 0% and 65%
You probably mention this somewhere, but I’ll ask here, are you currently researching whether these results hold for those other domains? I’m personally more interested about math than law.
It’s expensive to construct and baseline novel tasks for this (we spent well over $100k on human baselines) so what we are able to measure in the future depends on whether we can harvest realistic tasks that naturally have human data. You could do a rough analysis on math contest problems, say assigning GSM8K and AIME questions lengths based on a guess of how long expert humans take, but the external validity concerns are worse than for software. For one thing, AIME has much harder topics than GSM8K (we tried to make SWAA not be artificially easier or harder than HCAST); for another, neither are particularly close to the average few minutes of a research mathematician’s job.
Not answerable because METR is a flawed measure, imho.
This seems very related to what the Benchmarks and Gaps investigation is trying to answer, and it goes into quite a bit more detail and nuance than I’m able to get into here. I don’t think there’s a publicly accessible full version yet (but I think there will be at some later point).
It much more targets the question “when will we have AIs that can automate work at AGI companies?” which I realize is not really your pointed question. I don’t have a good answer to your specific question because I don’t know how hard alignment is or if humans realistically solve it on any time horizon without intelligence enhancement.
However, I tentatively expect safety research speedups to look mostly similar to capabilities research speedups, barring AIs being strategically deceptive and harming safety research.
I median-expect time horizons somewhere on the scale of a month (e.g. seeing an involved research project through from start to finish) to lead to very substantial research automation at AGI companies (maybe 90% research automation?), and we could see nonetheless startling macro-scale speedup effects at the scale of 1-day researchers. At 1-year researchers, things are very likely moving quite fast. I think this translates somewhat faithfully to safety orgs doing any kind of work that can be accelerated by AI agents.
8 hours of clock time for an expert seems likely to be enough to do anything humans can do; people rarely productively work in longer chunks than that, and as long as we assume models are capable of task breakdown and planning, (which seems like a non trivial issue, but an easier one than the scaling itself,) that should allow it to parallelize and serialize chucks to do larger human-type tasks.
But it’s unclear alignment can be solved by humans at all, and even if it can, of course, there is no reason to think these capabilities would scale as well or better for alignment than for capabilities and self-improvement, so this is not at all reassuring to me.
Life on earth started 3.5 billion years ago. Log_2(3.5 billion years/1 hour) = 45 doublings. With one doubling every 7 months, that makes 26 years, or in 2051.
(Obviously this model underestimates the difficulty of getting superalignment to work. But also extrapolating the METR trend is questionable for 45 doublings is dubious in an unknown direction. So whatever.)
You’re saying that if you assigned 1 human contractor the task of solving superalignment, they would succeed after ~3.5 billion years of work? 🤔 I think you misunderstood what the y-axis on the graph is measuring.
I mean I don’t really believe the premises of the question. But I took “Even if you’re not a fan of automating alignment, if we do make it to that point we might as well give it a shot!” to imply that even in such a circumstance, you still want me to come up with some sort of answer.