contact: jurkovich.nikola@gmail.com
Nikola Jurkovic
Karma: 1,930
The base models seem to have topped out their task length around 2023 at a few minutes (see on the plot that GPT-4o is little better than GPT-4). Reasoning models use search to do better.
Note that Claude 3.5 Sonnet (Old) and Claude 3.5 Sonnet (New) have a longer time horizon than 4o: 18 minutes and 28 minutes compared to 9 minutes (Figure 5 in Measuring AI Ability to Complete Long Tasks). GPT-4.5 also has a longer time horizon.
Thanks for writing this.
Aside from maybe Nikola Jurkovic, nobody associated with AI 2027, as far as I can tell, is actually expecting things to go as fast as depicted.
I don’t expect things to go this fast either—my median for AGI is in the second half of 2028, but the capabilities progression in AI 2027 is close to my modal timeline.
Note that the goal of “work on long-term research bets now so that a workforce of AI agents can automate it in a couple of years” implies somewhat different priorities than “work on long-term research bets to eventually have them pay off through human labor”, notably:
The research direction needs to be actually pursued by the agents, either through the decision of the human leadership, or through the decision of AI agents that the human leadership defers to. This means that if some long-term research bet isn’t respected by lab leadership, it’s unlikely to be pursued by their workforce of AI agents.
This implies that a major focus of current researchers should be on credibility and having a widely agreed-on theory of change. If this is lacking, then the research will likely never be pursued by the AI agent workforce and all the work will likely have been for nothing.
Maybe there is some hope that despite a research direction being unpopular among lab leadership, the AI agents will realize its usefulness on their own, and possibly persuade the lab leadership to let them expend compute on the research direction in question. Or maybe the agents will have so much free reign over research that they don’t even need to ask for permission to pursue new research directions.
Setting oneself up for providing oversight to AI agents. There might be a period during which agents are very capable at research engineering / execution but not research management, and leading AGI companies are eager to hire human experts to supervise large numbers of AI agents. If one doesn’t have legible credentials or good relations with AGI companies, they are less likely to be hired during this period.
Delaying engineering-heavy projects until engineering is cheap relative to other types of work.
(some of these push in opposite directions, e.g., engineering-heavy research outputs might be especially good for legibility)
I expect the trend to speed up before 2029 for a few reasons:
AI accelerating AI progress once we reach 10s of hours of time horizon.
The trend might be “inherently” superexponential. It might be that unlocking some planning capability generalizes very well from 1-week to 1-year tasks and we just go through those doublings very quickly.
This has been one of the most important results for my personal timelines to date. It was a big part of the reason why I recently updated from ~3 year median to ~4 year median to AI that can automate >95% of remote jobs from 2022, and why my distribution overall has become more narrow (less probability on really long timelines).
All of the above but it seems pretty hard to have an impact as a high schooler, and many impact avenues aren’t technically “positions” (e.g. influencer)
I think that everyone expect “Extremely resilient individuals who expect to get an impactful position (including independent research) very quickly” is probably better off following the strategy.
I think that for people (such as myself) who think/realize timelines are likely short, I find it more truth-tracking to use terminology that actually represents my epistemic state (that timelines are likely short) rather than hedging all the time and making it seem like I’m really uncertain.
Under my own lights, I’d be giving bad advice if I were hedging about timelines when giving advice (because the advice wouldn’t be tracking the world as it is, it would be tracking a probability distribution I disagree with and thus a probability distribution that leads to bad decisions), and my aim is to give good advice.
Like, if a house was 70% likely to be set on fire, I’d say something like “The people who realize that the house is dangerous should leave the house” instead of using think.
But yeah, point taken. “Realize” could imply consensus, which I don’t mean to do.
I’ve changed the wording to be more precise now (“have <6 year median AGI timelines”)
The waiting room strategy for people in undergrad/grad school who have <6 year median AGI timelines: treat school as “a place to be until you get into an actually impactful position”. Try as hard as possible to get into an impactful position as soon as possible. As soon as you get in, you leave school.
Upsides compared to dropping out include:
Lower social cost (appeasing family much more, which is a common constraint, and not having a gap in one’s resume)
Avoiding costs from large context switches (moving, changing social environment).
Extremely resilient individuals who expect to get an impactful position (including independent research) very quickly are probably better off directly dropping out.
Dario Amodei and Demis Hassabis statements on international coordination (source):
Interviewer: The personal decisions you make are going to shape this technology. Do you ever worry about ending up like Robert Oppenheimer?
Demis: Look, I worry about those kinds of scenarios all the time. That’s why I don’t sleep very much. There’s a huge amount of responsibility on the people, probably too much, on the people leading this technology. That’s why us and others are advocating for, we’d probably need institutions to be built to help govern some of this. I talked about CERN, I think we need an equivalent of an IAEA atomic agency to monitor sensible projects and those that are more risk-taking. I think we need to think about, society needs to think about, what kind of governing bodies are needed. Ideally it would be something like the UN, but given the geopolitical complexities, that doesn’t seem very possible. I worry about that all the time and we just try to do, at least on our side, everything we can in the vicinity and influence that we have.
Dario: My thoughts exactly echo Demis. My feeling is that almost every decision that I make feels like it’s kind of balanced on the edge of a knife. If we don’t build fast enough, then the authoritarian countries could win. If we build too fast, then the kinds of risks that Demis is talking about and that we’ve written about a lot could prevail. Either way, I’ll feel that it was my fault that we didn’t make exactly the right decision. I also agree with Demis that this idea of governance structures outside ourselves. I think these kinds of decisions are too big for any one person. We’re still struggling with this, as you alluded to, not everyone in the world has the same perspective, and some countries in a way are adversarial on this technology, but even within all those constraints we somehow have to find a way to build a more robust governance structure that doesn’t put this in the hands of just a few people.
Interviewer: [...] Is it actually possible [...]?
Demis: [...] Some sort of international dialogue is going to be needed. These fears are sometimes written off by others as luddite thinking or deceleration, but I’ve never heard a situation in the past where the people leading the field are also expressing caution. We’re dealing with something unbelievably transformative, incredibly powerful, that we’ve not seen before. It’s not just another technology. You can hear from a lot of the speeches at this summit, still people are regarding this as a very important technology, but still another technology. It’s different in category. I don’t think everyone’s fully understood that.Interviewer: [...] Do you think we can avoid there having to be some kind of a disaster? [...] What should give us all hope that we will actually get together and create this until something happens that demands it?
Dario: If everyone wakes up one day and they learn that some terrible disaster has happened that’s killed a bunch of people or caused an enormous security incident, that would be one way to do it. Obviously, that’s not what we want to happen. [...] every time we have a new model, we test it, we show it to the national security people [...]
My best guess is around 2⁄3.
Oh, I didn’t get the impression that GPT-5 will be based on o3. Through the GPT-N convention I’d assume GPT-5 would be a model pretrained with 8-10x more compute than GPT-4.5 (which is the biggest internal model according to Sam Altman’s statement at UTokyo).
Sam Altman said in an interview:
We want to bring GPT and o together, so we have one integrated model, the AGI. It does everything all together.
This statement, combined with today’s announcement that GPT-5 will integrate the GPT and o series, seems to imply that GPT-5 will be “the AGI”.
(however, it’s compatible that some future GPT series will be “the AGI,” as it’s not specified that the first unified model will be AGI, just that some unified model will be AGI. It’s also possible that the term AGI is being used in a nonstandard way)
At a talk at UTokyo, Sam Altman said (clipped here and here):
“We’re doing this new project called Stargate which has about 100 times the computing power of our current computer”
“We used to be in a paradigm where we only did pretraining, and each GPT number was exactly 100x, or not exactly but very close to 100x and at each of those there was a major new emergent thing. Internally we’ve gone all the way to about a maybe like a 4.5”
“We can get performance on a lot of benchmarks [using reasoning models] that in the old world we would have predicted wouldn’t have come until GPT-6, something like that, from models that are much smaller by doing this reinforcement learning.”
“The trick is when we do it this new way [using RL for reasoning], it doesn’t get better at everything. We can get it better in certain dimensions. But we can now more intelligently than before say that if we were able to pretrain a much bigger model and do [RL for reasoning], where would it be. And the thing that I would expect based off of what we’re seeing with a jump like that is the first bits or sort of signs of life on genuine new scientific knowledge.”
“Our very first reasoning model was a top 1 millionth competitive programmer in the world [...] We then had a model that got to top 10,000 [...] O3, which we talked about publicly in December, is the 175th best competitive programmer in the world. I think our internal benchmark is now around 50 and maybe we’ll hit number one by the end of this year.”
“There’s a lot of research still to get to [a coding agent]”
“I don’t think I’m going to be smarter than GPT-5”—Sam Altman
Context: he polled a room of students asking who thinks they’re smarter than GPT-4 and most raised their hands. Then he asked the same question for GPT-5 and apparently only two students raised their hands. He also said “and those two people that said smarter than GPT-5, I’d like to hear back from you in a little bit of time.”
The full talk can be found here. (the clip is at 13:45)
The redesigned OpenAI Safety page seems to imply that “the issues that matter most” are:
Child Safety
Private Information
Deep Fakes
Bias
Elections
Some things I’ve found useful for thinking about what the post-AGI future might look like:
More philosophical:
Letter from Utopia by Nick Bostrom
Actually possible: thoughts on Utopia by Joe Carlsmith
Entertainment:
Do people have recommendations for things to add to the list?
Note that for HLE, most of the difference in performance might be explained by Deep Research having access to tools while other models are forced to reply instantly with no tool use.
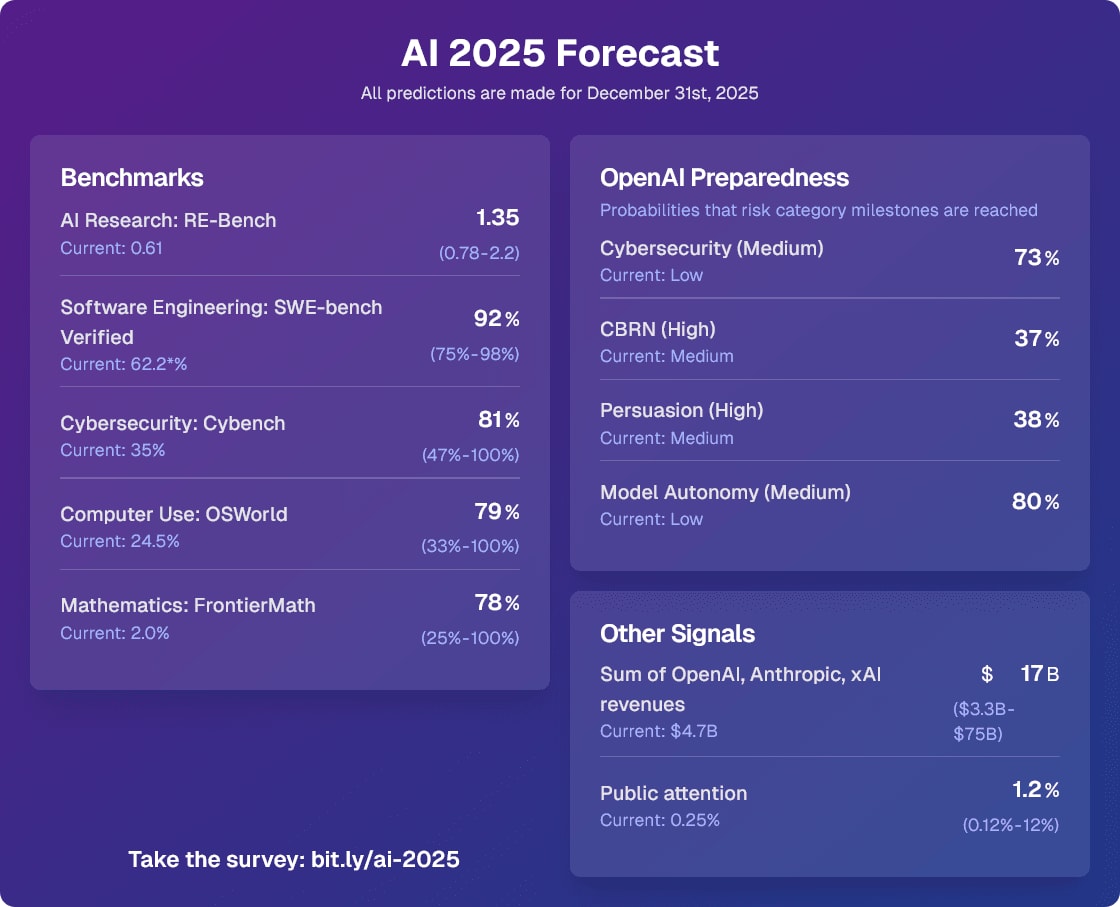
I will use this comment thread to keep track of notable updates to the forecasts I made for the 2025 AI Forecasting survey. As I said, my predictions coming true wouldn’t be strong evidence for 3 year timelines, but it would still be some evidence (especially RE-Bench and revenues).
The first update: On Jan 31st 2025, the Model Autonomy category hit Medium with the release of o3-mini. I predicted this would happen in 2025 with 80% probability.
02/25/2025: the Cybersecurity category hit Medium with the release of the Deep Research System Card. I predicted this would happen in 2025 with 73% probability. I’d now change CBRN (High) to 85% and Persuasion (High) to 70% given that two of the categories increased about 15% of the way into the year.
DeepSeek R1 being #1 on Humanity’s Last Exam is not strong evidence that it’s the best model, because the questions were adversarially filtered against o1, Claude 3.5 Sonnet, Gemini 1.5 Pro, and GPT-4o. If they weren’t filtered against those models, I’d bet o1 would outperform R1.
To ensure question difficulty, we automatically check the accuracy of frontier LLMs on each question prior to submission. Our testing process uses multi-modal LLMs for text-and-image questions (GPT-4O, GEMINI 1.5 PRO, CLAUDE 3.5 SONNET, O1) and adds two non-multi-modal models (O1MINI, O1-PREVIEW) for text-only questions. We use different submission criteria by question type: exact-match questions must stump all models, while multiple-choice questions must stump all but one model to account for potential lucky guesses.
If I were writing the paper I would have added either a footnote or an additional column to Table 1 getting across that GPT-4o, o1, Gemini 1.5 Pro, and Claude 3.5 Sonnet were adversarially filtered against. Most people just see Table 1 so it seems important to get across.
Another consideration is takeoff speeds: TAI happening earlier would mean further progress is more bottlenecked by compute and thus takeoff is slowed down. A slower takeoff enables more time for humans to inform their decisions (but might also make things harder in other ways).