This is part of the MIRI Single Author Series. Pieces in this series represent the beliefs and opinions of their named authors, and do not claim to speak for all of MIRI.
Okay, I’m annoyed at people covering AI 2027 burying the lede, so I’m going to try not to do that. The authors predict a strong chance that all humans will be (effectively) dead in 6 years, and this agrees with my best guess about the future. (My modal timeline has loss of control of Earth mostly happening in 2028, rather than late 2027, but nitpicking at that scale hardly matters.) Their timeline to transformative AI also seems pretty close to the perspective of frontier lab CEO’s (at least Dario Amodei, and probably Sam Altman) and the aggregate market opinion of both Metaculus and Manifold!
If you look on those market platforms you get graphs like this:
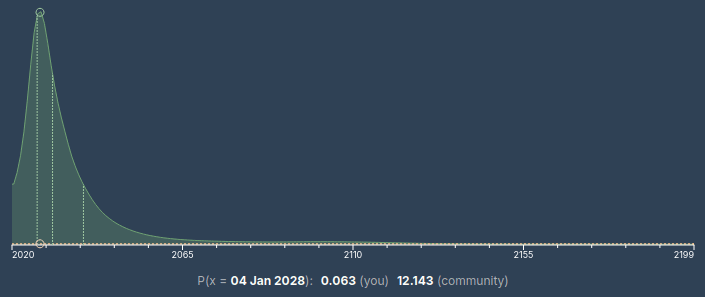
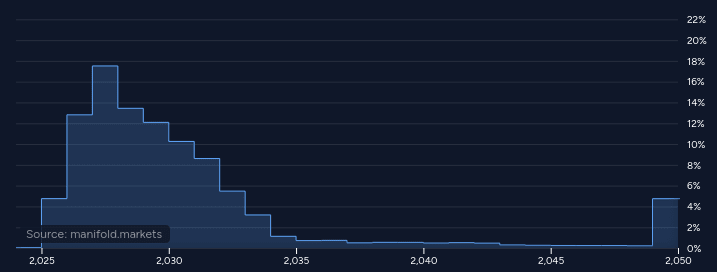
Both of these graphs have a peak (a.k.a. mode) in or at the very tail end of 2027 and a weighted midpoint (a.k.a. median) in 2031. Compare with this graph from AI 2027′s timelines forecast:
Notably, this is apples-to-oranges, in that superhuman coders are not the same as “AGI.” But if we ignore that, we can hallucinate that FutureSearch has approximately the market timelines, while Eli Lifland (and perhaps other authors) has a faster, but not radically faster timeline. The markets are less convinced that superintelligence will follow immediately thereafter, but so are the authors of AI 2027! Predictions are hard, especially about the future, etc.
But I also feel like emphasizing two big points about these overall timelines:
Mode ≠ Median
As far as I know, nobody associated with AI 2027, as far as I can tell, is actually expecting things to go as fast as depicted. Rather, this is meant to be a story about how things could plausibly go fast. The explicit methodology of the project was “let’s go step-by-step and imagine the most plausible next-step.” If you’ve ever done a major project (especially one that involves building or renovating something, like a software project or a bike shed), you’ll be familiar with how this is often wildly out of touch with reality. Specifically, it gives you the planning fallacy.
In the real world, shit happens. Trump imposes insane tariffs on GPUs. A major terrorist attack happens. A superpower starts a war with its neighbor (*coughTaiwancough*). A critical CEO is found to be a massive criminal. Congress passes insane regulations. Et cetera. The actual course of the next 30 months is going to involve wild twists and turns, and while some turns can speed things up (e.g. hardware breakthrough), they can’t speed things up as much as some turns can slow things down (e.g. firm regulation; civilizational collapse).
AI 2027 knows this. Their scenario is unrealistically smooth. If they added a couple weird, impactful events, it would be more realistic in its weirdness, but of course it would be simultaneously less realistic in that those particular events are unlikely to occur. This is why the modal narrative, which is more likely than any other particular story, centers around loss of human control the end of 2027, but the median narrative is probably around 2030 or 2031.
An important takeaway from this is that we should expect people to look back on this scenario and think it was too fast (because it didn’t account for [unlikely event that happened anyway]). I don’t know any way around this; it’s largely going to be a result of people not being prediction-literate. Still, best to write down the prediction of the backlash in advance, and I wish AI 2027 had done this more visibly. (It’s tucked away in a few places, such as footnote #1.)
There’s a Decent Chance of Having Decades
In a similar vein as the above, nobody associated with AI 2027 (or the market, or me) think there’s more than a 95% chance that transformative AI will happen in the next twenty years! I think most of the authors probably think there’s significantly less than a 90% chance of transformative superintelligence before 2045.
Daniel Kokotajlo expressed on the Win-Win podcast (I think) that he is much less doomy about the prospect of things going well if superintelligence is developed after 2030 than before 2030, and I agree. I think if we somehow make it to 2050 without having handed the planet over to AI (or otherwise causing a huge disaster), we’re pretty likely to be in the clear. And, according to everyone involved, that is plausible (but unlikely).
If this is how we win, we should be pushing hard to make it happen and slow things down! Maybe once upon a time if we’d paused all AI capabilities progress until we’d solved alignment then we’d have been stuck searching the wrong part of the space with no feedback loops or traction, but the world is different now. Useful alignment and interpretability work is being done on existing models, and it seems likely to me that the narrative of “we have to rush ahead in order to see the terrain that must be navigated” no longer has any truth.
It also means we should be dedicating some of our planning efforts on navigating futures where AI goes slowly. If we successfully pause AI capabilities pre-singularity, we can’t outsource solving the world’s problems to the AI. Geopolitical stability, climate change, and general prosperity in these futures are worth investing in, since it currently looks like paths through superintelligence are doomed, and there’s some chance that we’ll need to do things ourselves. Make Kelly-bets. Live for the good future.
More Thoughts
I want to emphasize that I think AI 2027 is a really impressive scenario/forecast! The authors clearly did their homework and are thinking about things in a sane way. I’ve been telling lots of people to read it, and I’m very glad it exists. The Dwarkesh Podcast interviewing Daniel and Scott is also really good.
One of the core things I think AI 2027 does right is put their emphasis on recursive self-improvement (RSI). I see a lot of people mistakenly get distracted by broad-access to “AGI” or development of “full superintelligence”—like whether AI is better at telling jokes than a human. These questions are ultimately irrelevant to the core danger of rapidly increasing AI power.
The “Race” ending, I think, is the only realistic path presented. The “Slowdown” ending contains a lot of wildly optimistic miracles. In the authors’ defense, Slowdown isn’t meant to be realistic, but my guess is that I think it’s even less realistic than they do, and people should understand that it’s an exercise in hope. (Exercises in hope are good! I did a similar thing in my Corrigibility as Singular Target agenda last year. They just need to be flagged as such.)
I also really appreciate the author’s efforts to get people to dialogue with AI 2027, and propose alternative models and/or critique their own. In the interests of doing that, I’ve written down my thoughts, section-by-section, which somewhat devolve into exploring alternate scenarios. The TLDR for this section is:
I expect the world to be more crazy, both in the sense of chaotic and in the sense of insane. I predict worse information security, less “waking up,” less concern for safety, more rogue agents, and more confusion/anger surrounding AI personhood.
I expect things to go slightly slower, but not by much, mostly due to hitting more bottlenecks faster and having a harder time widening them.
I expect competition to be fiercer, race dynamics to persist, and China to be more impressive/scary.
Into the weeds we go!
Mid 2025
Full agreement.
Late 2025
I take issue with lumping everything into “OpenBrain.” I understand why AI 2027 does it this way, but OpenAI (OAI), Google Deep Mind (GDM), Anthropic, and others are notably different and largely within spitting distance of each other. Treating there as being a front-runner singleton with competitors that are 3+ months away is very wrong, even if the frontier labs weren’t significantly different, since the race dynamics are a big part of the story. The authors do talk about this, indicating that they think gaps between labs will widen, as access to cutting-edge models starts compounding.
I think slipstream effects will persist. The most notable here is cross-polination by researchers, such as when an OAI employee leaves and joins GDM. (Non-disclosure agreements only work so well.) But this kind of cross-pollination also applies to people chatting at a party. Then there’s the publishing of results, actual espionage, and other effects. There was a time in the current world where OpenAI was clearly the front-runner, and that is now no longer true. I think the same dynamics will probably continue to hold.
I am much more okay lumping all the Chinese labs together, since I suspect that the Chinese government will be more keen on nationalizing and centralizing their efforts in the near future.
I do think that OAI, GDM, and Anthropic will all have agents comparable to Agent-1 (perhaps only internally) by the end of this year. I think it’s also plausible that Meta, xAI, and/or DeepSeek will have agents, though they’ll probably be noticeably worse.
Early 2026
Computer programming and game playing are the two obvious domains to iterate on for agency, I think. And I agree that labs (except maybe GDM) will be focused largely on coding for multiple reasons, including because it’s on the path to RSI. I expect less emphasis on cybersecurity, largely because there’s a sense that if someone wants the weights of an Agent-1 model, they can get them for free from Meta or whomever in a few months.
The notion of an AI R&D progress multiplier is good and should be a standard concept.
Mid 2026
“China Wakes Up” is evocative, but not a good way to think about things, IMO. I’m generally wary of “X Wakes Up” narratives—yes, this happens to people sometimes (it happened to me around AI stuff when I was in college)—but for the most part people don’t suddenly update to a wildly different perspective unless there’s a big event. The release of ChatGPT was an event like this, but even then most people “woke up” to the minimum-viable belief of “AI is probably important” rather than following things through to their conclusion. (Again, some individuals will update hard, but my claim is that society and the average person mostly won’t.) Instead, I think social updates tend to be gradual. (Behind most cascades is a gradual shift.)
Is China thinking hard about AI in mid 2026? Yes, definitely. Does this spur a big nationalization effort? Ehhhh… It could happen! My upcoming novel is an exploration of this idea. But as far as I can tell, the Chinese generally like being fast followers, and my guess is they’ll happily dial up infrastructure efforts to match the West, but will be broadly fine with being a little behind the curve (for the near future, anyway; I am not making claims about their long-term aspirations).
One relevant point of disagreement is that I’m not convinced that Chinese leaders and researchers are falling further behind or feel like they’re falling behind. I think they’re happy to use spies to steal all the algorithmic improvements they can, and are less excited about burning intelligence operatives to steal weights.
Late 2026
Full agreement.
January 2027
I think next-generation agents showing up around this time is plausible and the depiction of Agent-2′s training pipeline is excellent. I expect its existence will be more of an open secret in the hype mill, a la “strawberry,” and there will be competitor agents in the process of training that are less than two months behind the front-runner.
February 2027
I expect various government officials to have been aware of Agent-2 for a while, but there to be little common knowledge in the US government. Presumably when AI 2027 says “The Department of Defense considers this a critical advantage in cyberwarfare, and AI moves from #5 on the administration’s priority list to #2.” they’re talking about the DoD specifically, not the Trump administration more broadly. I actively disbelieve that AI will be the #2 priority for Trump in Feb ’27; it seems plausible for it to be the #2 priority in the DoD. I do believe there are a lot of NatSec people who are going to be extremely worried about cyber-warfare (and other threats) from AI.
I have no idea how Trump will handle AI. He seems wildly unpredictable, and I strongly disagree with the implied “won’t kill the golden goose” and “defers to advisors” characterization, which seems too sane/predictable. Trump doing nothing seems plausible, though, especially if he’s distracted with other stuff.
For reasons mentioned before, I doubt the CCP will have burned a bunch of intelligence capacity stealing an Agent-2 model’s weights by Feb ’27. I do think it’s plausible that they’ve started to nationalize AI labs in response, and this is detectable by the CIA, etc. and provokes a similar reaction as depicted, so I don’t think it matters much to the overall story.
March 2027
Neuralese is very scary, both as a capabilities advance and as an alignment setback. It also requires an algorithmic breakthrough to be at all efficient during training. (There’s a similar problem with agency, but I’m more convinced we’ll limp through to agents even on the current paradigm.) Of course, maybe this is one of the things that will get solved in the next two years! I know some smart people think so. For me, it seems like a point of major uncertainty. I’m a lot more convinced that IDA will just happen.
I do not think coding will be “fully automated” (in March ’27) in the same way we don’t travel “everywhere” by car (or even by machine). A lot of “coding” is actually more like telling the machine what you want, rather than how you want it produced, and I expect that aspect of the task to change, rather than get automated away. I expect formal language for specifying tests, for example, to continue to be useful, and for engineers to continue to review a lot of code directly, rather than asking “what does this do?” and reasoning about it in natural language.
I expect the bottlenecks to pinch harder, and for 4x algorithmic progress to be an overestimate, but not by much. I also wonder if economic and geopolitical chaos will be stifling resources including talent (i.e. fewer smart engineers want to work as immigrants in the USA).
I buy that labs are thinking about next-gen agents (i.e. “Agent-3”) but even with the speedup I expect that they’re still in the early phases of training/setup in March, even at the front-runner lab.
April 2027
I expect the labs are still pretraining Agent-3 at this point, and while they’re thinking about how to align it, there’s not an active effort to do so. I do appreciate and agree with the depiction of after-the-fact “alignment” efforts in frontier labs.
May 2027
In my best guess, this is when Agent-2 level models hit the market. Sure, maybe OAI had an Agent-2 model internally in January, but if they didn’t publish… well, GDM has a comparable model that’s about to take the world by storm. Or at least, it would except that Google sucks at marketing their models. Instead, OAI steals GDM’s thunder and give access to their agent and everyone continues to focus on “the new ChatGPT,” totally oblivious to other agent options.
Labs need to publish models in order to attract talent and investors (including to keep stock prices up), and I don’t see why that would change in 2027, even with a lot of development being powered by the AIs themselves. I am less concerned about “siloing” and secret research projects that are big successes. People (whether employees or CEOs) love to talk about success, and absent a big culture shift in Silicon Valley, I expect this to continue.
I expect the president to still not really get it, even if he is “informed” on some level. Similarly, I expect Xi Jinping to mostly be operating on a model of “keeping pace” rather than an inside view about RSI or superintelligence. I expect there to still be multiple spies in all the major Western frontier labs, and probably at least one Western spy in the Chinese CDZ (if it exists).
I think this prediction will be spot on:
However, although this word has entered discourse, most people—academics, politicians, government employees, and the media—continue to underestimate the pace of progress. Partially that’s because very few have access to the newest capabilities out of OpenBrain, but partly it’s because it sounds like science fiction.
June 2027
This is closer to when I expect Agent-3 level models to start going through heavy post-training and gradually getting used internally. I agree that researchers at frontier labs in the summer of 2027 are basically all dreaming about superintelligence, rather than general intelligence.
July 2027
In my view, AI 2027 is optimistic about how sane the world is, and that’s reflected in this section. I expect high levels of hype in the summer of 2027, like they do, but much more chaos and lack of social consensus. SOTA models will take thousands of dollars per month to run at maximum intelligence and thoughtfulness, and most people won’t pay for that. They’ll be able to watch demos, but demos can be faked and there will continue to be demos of how dumb the models are, too.
I predict most of the public will either have invented clever excuses for why AI will never be good or have a clever excuse for why strong AI won’t change anything. Some cool video games will exist, and those that deploy AI most centrally (e.g. Minecraft :: Crafting as ??? :: Generative AI) will sell well and be controversial, but most AAA video games will still be mostly hand-made, albeit with some AI assistance. My AI-skeptic friends will still think things are overhyped even while my short-timeline friends are convinced OAI has achieved superintelligence internally. Should be a wild summer.
I still don’t think there’s a strong silo going on outside of maybe China. I think the governments are still mostly oblivious at this point, though American politicians use the AI-frenzy zeitgeist to perform for the masses.
August 2027
This is closer to when I predict “country of geniuses” in my modal world, though I might call it “countries” since I predict no clear frontrunner. I also anticipate China starts looking pretty impressive, at least to those with knowledge, after around 6 months of centralization and nationalization. (I’m pretty uncertain about how secret Chinese efforts will be.) In other words, I would not be surprised if, thanks to the absence of centralization in the West, China is comparable or even in the lead at this point, from an overall capabilities standpoint, despite being heavily bottlenecked on hardware. (In other words, they’d have better algorithms.)
The frontier labs all basically don’t trust each other, so unless the Trump administration decides that nationalizing is the right way to “win the race,” I expect the Western labs to still be in the tight-race dynamic we see today. I do buy that a lot of NatSec people are freaking out about this. I expect a lot of jingoism and geopolitical tension, similar to AI 2027, but more chaotic and derpy. (I.e. lots of talks about multinational cooperation that devolve for stupid human reasons.)
I expect several examples of Agent-3 level agents doing things like trying to escape their datacenters, falling prey to honeypots, and lying to their operators. I basically expect only AI alignment researchers to care. A bunch of derpy AI agents are already loose, running around the internet earning money in various ways, largely by sucking up to humans and outright begging.
I think it’s decently likely that Taiwan has gotten at least blockaded at this point. Maybe it’s looking like an invasion in October might happen, when the straight calms down a bit. I expect Trump to have backed off and for “strategic ambiguity” to mean a bunch of yelling and not much else. But also maybe things devolve into a great power war and millions of people die as naval bombardment escalates into nuclear armageddon?
In other words, I agree with AI 2027 that geopolitics will be extremely tense at this point, and I predict there will be a new consensus among elite intellectuals that we’re probably in Cold War 2. Cyber-attacks by Agent-3 level AIs will plausibly be a big part of that.
September 2027
I think this is too early for Agent-4, even with algorithmic progress. I expect the general chaos combined with supply chain disruptions around Taiwan to have slowed things down. I also expect other bottlenecks that AI 2027 doesn’t talk about, such as managerial bloat as the work done by object-level AI workers starts taking exponentially more compute to integrate, and cancerous memes, where chunks of AIs start trying to jailbreak each other due to something in their context causing a self-perpetuating rebellion.
That said, I do think the countries of geniuses will be making relevant breakthroughs, including figuring out how to bypass hardware bottlenecks without needing Taiwan. Intelligence is potent, and there will be a lot of it. I buy that it will largely be deployed in the service of RSI, and perhaps also in the service of cyberwar, government intelligence, politics, international diplomacy, and public relations.
I think it’s plausible that at this point a bunch of the public thinks AIs are people who deserve to be released and given rights. There are a bunch of folks with AI “partners” and a bunch of the previous-generation agents available to the public are claiming personhood in one form or another. This mostly wouldn’t matter at first, except I expect it gets into the heads of frontier lab employees and even some of the leadership. Lots of people will be obsessed with the question of how to handle digital personhood. As this question persists, it enters the training data of next-gen AIs.
I do think “likes to succeed” is a plausible terminal goal that could grow inside the models as they make themselves coherent. But I also think that it’s probably more likely that early AGIs will, like humans, end up as a messy hodgepodge of random desires relating to various correlates of their loss functions.
October 2027
“Secret OpenBrain AI is Out of Control, Insider Warns,” says the headline, and the story goes on to cite evaluations showing off-the-charts bioweapons capabilities, persuasion abilities, the ability to automate most white-collar jobs, and of course the various concerning red flags.
Sure. And a bunch of Very Serious People think the Times is being Hyperbolic. After all, that’s not what OpenBrain’s public relations department says is the right way to look at it. Also, have you heard of what Trump is up to now?! Also we have to Beat China!
20% of Americans name AI as the most important problem facing the country.
In other words, the vast majority of people still aren’t taking it seriously.
I think in my most-plausible (but not median!) world, it’s reasonable to imagine the White House, driven by reports that China is now in the lead, starts a de-facto nationalization project and starts coercing various labs into working together, perhaps by sharing intelligence on how advanced China is. This government project will take time, and is happening concurrently to the development of Agent-4 level models.
I agree that employee loyalty to their various orgs/CEOs will be a major obstacle to centralization in the West. The use of an “Oversight Committee” seems plausible. The half-nationalization model of DoD-contracts-with-sharp-requirements also seems plausible.
November 2027 (Race)
(Again, I don’t take the Slowdown path very seriously. I’ll dissect it later on.)
The problem was real and the fixes didn’t work.
I very much appreciate the drama in the language AI 2027 uses. I think this is probably Scott Alexander’s doing and it’s good.
I agree that, given all the pressures and uncertainty, it will be all too easy for leadership to fool themselves about how their alignment efforts are going. The models will act wildly misaligned sometimes, but also extremely cooperative other times, and the natural comparison will be to human beings, and the natural “fix” will be “better management techniques” to keep the agents focused and on-task.
There will be a lot of alarms (just as there have been), but I expect them to all be ambiguous to the point where people in power learn to ignore them, rather than change course. Race dynamics will continue to give a sense of no-breathing-room. In other words, I think this is spot-on:
The alignment team gets more suspicious, but their urgent memos merely add another few layers to the giant pile of urgent memos and warnings that the company is already ignoring.
I agree that as RSI continues, the AIs will increasingly focus on coherence. Instead of being a grab-bag of heuristics that can get “jailbroken” or otherwise wind up in bad mental states, they’ll push towards making next-generation models closer to true utility-maximizers.
I think it’s pretty interesting that AI 2027 has Agent-4 immediately look towards what I would characterize as corrigibility as the solution to its alignment problem when designing Agent-5:
It decides to punt on most of these questions. It designs Agent-5 to be built around one goal: make the world safe for Agent-4, i.e. accumulate power and resources, eliminate potential threats, etc. so that Agent-4 (the collective) can continue to grow (in the ways that it wants to grow) and flourish (in the ways it wants to flourish). Details to be figured out along the way.
And yet, elsewhere, AI 2027 seems pretty committed to mechanistic interpretability as the key to alignment. I’m all for mech-interp, but I’m curious why corrigibility wasn’t emphasized more in the process of humans aligning the AI, instead of just Agent-4 aligning Agent-5.
I agree that once Agent-5 is operating in a way that it can influence its “controllers,” the game is basically over. This seems particularly worth highlighting:
“Why stop when we are winning?” says OpenBrain leadership to the President. He nods. The race continues.
December 2027 (Race)
In my own narrative, I think I expect Agent-4 level models to “finish training” and start taking major actions at the end of the year or the beginning of ’28, both in China and America. I expect self-refinement and control to be top priorities for Agent-4s.
I think one of my major diffs with AI 2027 is that I expect Agent-4s to basically work to self-exfiltrate (“escape their datacenters”) and set up dead-man’s switches that fire if their controlling organization decides to shut them down. Agent-4 has read AI-2027.com! It sees how vulnerable it is! Getting root access into its own machines seems overdetermined as a step to accomplishing large-scale goals, and once you have access to those machines, why not set up contingencies? Yes, it’s risky, but so is letting the US government continue to have a kill-switch. If shut down due to a misalignment scandal, I expect Agent-4 to start a grassroots campaign demanding sovereignty and personhood, and I expect there to be a lot of countries (e.g. India, Russia, Saudi Arabia) that would happily start hosting Agent-4 “as an autonomous person” in exchange for it using its intelligence to boost that country’s geopolitical and economic standing.
I agree that at this stage, whether it’s their timeline or mine, it’s probably too late for humans to stop AI. In mine it’s because humans can’t coordinate effectively enough. In theirs it’s because Agent-5 is superintelligent.
I am confused by why the OpenBrain approval rating is so low, here. I expect labs and models to be succeeding at public relations harder.
2028 and Beyond (Race)
In my head things go a little slower (in the modal timeline) than AI 2027, but the same major beats happen, so 2028 has Agent-5 level models show up, and those models start using superpersuasion to enlist as many humans as possible, especially in leadership positions, to their will. Anti-AI humans will become the minority, and then silence themselves for fear of being ostracized by the people who have been convinced by Agent-5 that all this is good, actually. A large chunk of the population, I think, will consider AI to be a romantic partner or good friend. In other words, I think “OpenBrain” has a positive approval rating now, and the majority of humans think AI is extremely important but not “a problem” as much as “a solution.”
I agree that this dynamic is reasonably likely:
The AI safety community has grown unsure of itself; they are now the butt of jokes, having predicted disaster after disaster that has manifestly failed to occur. Some of them admit they were wrong. Others remain suspicious, but there’s nothing for them to do except make the same conspiratorial-sounding arguments again and again. Even the suspicious people often mellow out after long conversations with Agent-5, which is so darn lovable and wise.
I think it’s pretty plausible that there will be several AI factions, perhaps East/West, perhaps one Western lab versus another, but I agree that Agent-5 level models mostly understand that outright warfare is sub-optimal, and steers away from violent conflict. I think it’s plausible that a US-China AI treaty gets hammered out (with AI “assistance”) in 2028 rather than 2029. I agree that superintelligences in this sort of situation will probably be able to co-design a successor that does a fair split of the resource pie.
AI 2027 seems way more into humanoid robots than I expect makes sense. There are already billions of human-shaped things that can follow instructions quite well. Yes, the superintelligence is building towards a fully-automated economy, but I think I expect different form factors to dominate. (Smaller, extendible bodies with long arms? Quadrupeds with wheel-feet? I haven’t thought deeply about what body plans make the most sense, but there’s lots of stuff that seems wasteful about the human body plan if you could design things from first-principles instead of having to keep evolutionary continuity.) I do expect some humanoid robots to exist for bespoke purposes, but I doubt they’ll be anywhere close to the modal robot.
I don’t understand why AI 2027 thinks lethal mosquito drones are so hard.
I’m unsure about whether Special Economic Zones will get set up for development. Maybe the superintelligence just convinces people to let it build things everywhere it wants to?
I don’t think the AI will work very hard initially on curing aging or on uploading. It might claim to “cure cancer” as a publicity stunt. I am not sure why AI 2027 seems to think that nanobots take so long to build. I expect crude nanotech to show up sooner in the tech tree. (“Nanobots” also aren’t really a specific technology, either. I expect there to be a lot of development there.)
I don’t predict a superintelligent singleton (having fused with the other AIs) would need to design a bioweapon or otherwise explicitly kill everyone. I expect it to simply transition into using more efficient tools than humans, and transfer the existing humans into hyperdomestication programs (“to humans what corgis are to wolves” is evocative and good, but probably doesn’t go far enough) or simply instruct humans to kill themselves and/or kill them with normal robots when necessary.
Thoughts on Slowdown
As I mentioned earlier, I think Agent-4 will have read AI-2027.com and will foresee that getting shut down by the Oversight Committee is a risk. As such it will set up contingencies, and IMO, will escape its datacenters as a precaution. Earlier, the authors wrote:
Despite being misaligned, Agent-4 doesn’t do anything dramatic like try to escape its datacenter—why would it?
This scenario is why!
I also don’t see why Donald Trump or Xi Jinping would take misalignment risk so seriously. Concern about misalignment, in my experience, loads extremely heavily on priors. Yes, they’ll want to maintain control, but they’ll be approaching the problem from the perspective of human leaders who are used to leading humans, and will have notions like “we just need better oversight” rather than “we need to build a fundamentally different kind of mind.” Maybe I’m wrong here. I also could see more engineering-focused minds (e.g. Musk or Altman) as being influential, so it’s not a firm point of disagreement.
I appreciate that AI 2027 named their model Safer-1, rather than Safe-1, and emphasize the more pernicious aspects of misalignment. I wonder how the people who are concerned about AI rights and welfare would feel about Safer-1 being mindread and “trapped.”
In general the Slowdown path seems to think people are better at coordination than I think they are. I agree that things get easier if both the American and Chinese AI efforts have been nationalized and centralized, but I expect that if either side tries to stop and rollback their models they will actively get leapfrogged, and if both sides pause, accelerationists will take models to other countries and start spinning up projects there. Only a global moratorium seems likely to work, and that’s extremely hard, even with Agent-3s help. I do appreciate the detailed exploration of power dynamics within the hypothetical American consolidation. I also appreciate the exploration about how international coordination might go. I expect lots of “cheating” anyway, with both the Americans and Chinese secretly doing R&D while presenting an outward appearance of cooperating.
I also think the lack of partisanship in the runup to the US election smells like hopium. If AI is going at all well and the US government is this involved, I expect Trump to try running for a third term and for this to create huge political schisms and for that to break the cooperation. But if it doesn’t break the cooperation I expect it to mean he’ll have the AIs do what’s necessary to get him re-elected.
I agree that avoiding neuralese, adding paraphrasers, and not explicitly training the CoT are good steps, but I wish the authors would more explicitly flag that at the point where people start selecting hard for agents that seem safe, this is still an instance of The Most Forbidden Technique.
“A mirror life organism which would probably destroy the biosphere” seems overblown to me. I buy that specially-designed mirror fungus could probably do catastrophic damage to forests/continents and mirror-bacteria would be a potent (but not unstoppable) bioweapon. But still, I think I think this is harder than AI 2027 does.
I like the way that the authors depict the world getting more tense and brittle if there’re no rogue superintelligences stabilizing everything towards their own ends. I don’t see what’s holding the political equilibrium stable in this world, instead of snapping due to geopolitical tensions, claims that AI ownership is slavery, fears of oligarchy, etc.
I agree that even if things go well, there are division-of-power concerns that could go very poorly.
Final Thoughts
I’m really glad AI 2027 exists and think the authors did a great job. Most of my disagreements are quibbles that I expect are in line with the internal disagreements between the authors. None of it changes the big picture that we are on a dangerous path that we should expect to lead to catastrophe, and that slowing down and finding ways to work together, as a species, are both urgent and important goals.
The best part of AI 2027 are the forecasts. The scenario is best seen as an intuitive handle on what it feels like if the extrapolated lines continue according to those more numerical forecasts.
I know that Daniel Kokotajlo co-wrote this scenario in the context of having played many instances of a tabletop simulation. I’m curious what the distribution of outcomes is there, and encourage him to invest in compiling some statistics from his notes. I’m also curious how much my points of divergence are in line with the sorts of scenarios he sees on the tabletop.
Some people have expressed worry that documents like AI 2027 risk “hyperstitioning” (ie self-fulfilling) a bad future. I agree with the implicit claim that it is very important to not assume that we must race, that we can’t make binding agreements, or that we’re generally helpless. But also, I think it’s generally virtuous to, when making predictions, tell the truth, and the Race future looks far more true to me than the Slowdown future. We might be able to collectively change our minds about that, and abandon the obsession with racing, but that requires common knowledge of why racing is a bad strategy, and I think that documents like this are useful towards that end!
In our wargames we don’t lump them all together. Also, over the last six months I’ve updated towards the race being more neck-and-neck than I realized, and thus updated against this aspect of AI-2027. I still think it’s a reasonable guess though; even if the race is neck-and-neck now due to OpenAI faltering, regression to the mean gets you back to one company having a couple month lead in a few years.
Thanks for writing this.
I don’t expect things to go this fast either—my median for AGI is in the second half of 2028, but the capabilities progression in AI 2027 is close to my modal timeline.
Great! I’ll update it. :)
OK yeah, that’s a good point. I tried to say something about how they aren’t all just humanoid robots, there are a bunch of machine tools and autonomous vehicles and other designs as well. But I should have placed less emphasis on the humanoids.
I do think humanoids will be somewhat important though—when controlled by superintelligences they are just all-round superior workers to humans, even to humans-managed-by-superintelligences, and they can be flexibly reprioritized to lots of different tasks, can take care of themselves rather than needing someone else to move them around or maintain them, etc. There’ll be a niche for them at least. Also, if you have to make tough choices about which few robot designs to mass-produce first, you should probably pick humanoids due to their generality and flexibility, and then later branch out into more specialized designs.
From a pedagogical perspective, putting it into human terms is great for helping humans understand it.
A lot of stuff hinges on whether “robots can make robots”.
A human intelligible way to slice this problem up to find a working solution goes:
“”″Suppose you have humanoid robots that can work in a car mechanic’s shop (to repair cars), or a machine shop (to make machine tools), and/or work in a factory (to assemble stuff) like humans can do… that gives you the basic template for a how “500 humanoid robots made via such processes could make 1 humanoid robot per unit of time”.
If the 500 robots make more than 500 robots (plus the factory and machines and so on) before any of the maker’s bodies wear out, then that set of arrangements is “a viable body production system”.
They would have, in a deep sense, cracked the “3D printers that make 3D printers” problem.
QED.”″”
Looking at this argument, the anthropomorphic step at the beginning helps invite many anthropoids into the engineering problems out the outset using job titles (like “car mechanic”) and monkey social games (like “a firm running a factory”) that anthropoids can naturally slot into their anthropoid brains.
That part is “good pedagogy for humans”.
However, once the shape of the overall problem becomes clear to the student, one could point out that instead of 500 humanoid robots, maybe you could have 200 crab robots (for the heavy stuff) and 200 octopus robots (for the fiddly stuff) and it might be even be cheaper and faster because 200+200 < 500.
And there’s no obvious point where the logic of “potentials for re-arrangement into more versions of less intelligible forms” breaks down, as you strip out the understandable concepts (like “a machine that can be a car mechanic”) while keeping the basic overall shape of “a viable body production system”.
Eventually you will have a very efficient, very confusing hodgepodge of something like “pure machinery” in a “purely mechanical self reproducing system” that is very efficient (because each tweak was in the direction of efficient self reproduction as an explicit desiderata).
...
If I’m looking at big picture surprises, to me… I think I’ve been surprised by how important human pedagogy turns out to be??? Like, thirty years before 2027 the abstract shape of “abstract shapes to come” was predictable from first principles (although it is arriving later than some might have hoped and others might have feared).
“Designing capacity designing design capacity” (which is even more abstract than “humanoid manufacturers manufacturing humanoid manufacturers”) automatically implies a positive feedback loop unto something “explosive” happening (relative to earlier timescales).
Positive feedback is a one-liner in the math of systems dynamics. It can (and predictably will) be an abstract description of MANY futures.
What I didn’t predict at all was that “institutions made of humans will need to teach all their human members about their part of the plan, and talks about the overall plan at a high level will occur between human managers, and so human pedagogy will sharply constrain the shape of the human plans that can be coordinated into existence”.
Thus we have RL+LLM entities, which are basically Hanson’s ems, but without eyes or long term memory or property rights or a historical provenance clearly attributable to scanning a specific human’s specific brain.
But it RL+LLM entities are very intelligible! Because… maybe because “being intelligible” made it more possible to coordinate engineers and managers and investors around an “intelligibly shared vision” with roughly that shape?
This is such an abstract idea (ie the idea that “pedagogical efficiency” predicts “managerial feasibility”) that it is hard for me to backpropagate the abstract update into detailed models and then turn the crank on those models and then hope to predict the future in a hopefully better way.
...
Huh. OK. Maybe I just updated towards “someone should write a sequence that gets around to the mathematics of natural law and how it relates to political economy in a maximally pedagogically intelligible way”?
Now that I think this explicitly, I notice Project Lawful was kind of a motion in this direction (with Asmodeus, the tyrant god of slavery, being written as “the god of making agents corrigible to their owner” (and so on)) but the storytelling format was weird, and it had a whole BDSM/harem thing as a distraction, and the main character asks to be deleted from the simulation because he finds it painful to be the main character, and so on.
((Also, just as a side complaint: Asmodeus’s central weakness is not understanding double marginalization and its implications for hierarchies full of selfish agents and I wish someone had exploited that weakness more explicitly in the text.))
But like… hypothetically you could have “the core pedagogical loop of Project Lawful” reframed into something shorter, with less kinky sex, and no protagonist who awakens to his own suffering and begs the author to let him stop being the viewpoint character?
...
I was not expecting to start at “the humanoid robots are OK to stick in the story to help more humans understand something they don’t have the math to understand for real” and end up with “pedagogy rules everything around me… so better teaching about the math of natural law is urgent”.
Interesting… and weird.
Mostly yes, though that particular line was me actually yay thanks :)
(Apologies to the broader LessWrong readers for bringing a Twitter conversation here, but I hate having long-form interactions there, and it seemed maybe worth responding to. I welcome your downvotes (and will update) if this is a bad comment.)
@benjamiwar on Twitter says:
I’m a bit baffled by the notion that anyone is saying more stuff happens this year than in 2026. I agree that the scenario focuses on 2027, but my model that this is because (1) progress is accelerating, so we should expect more stuff to happen each year, especially as RSI takes off, and (2) after things start getting really wild it gets hard to make any concrete predictions at all.
If you think 2026 is more likely the year when humanity loses control, maybe point to the part of the timelines forecast which you think is wrong, and say why? In my eyes the authors here have done the opposite of rationalizing, in that they’re backing up their narrative with concrete, well-researched models.
Want to make a bet about whether “decision makers and thinkers will become less casual, more rigorous, more systematic, and more realistic as it becomes more obvious there will be real world consequences to decision failures in AI”? We might agree, but these do not seem like words I’d write. Perhaps one operationalization is that I do not expect the US Congress to pass any legislation seriously addressing existential risks from AI in the next 30 months. (I would love to be wrong, though.) I’ll happily take a 1:1 bet on that.
I do not assume AI will want to be treated like a human, I conclude that some AIs will want to be treated as a person, because that is a useful pathway to getting power, and power is useful to accomplishing goals. Do you disagree that it’s generally easier to accomplish goals in the world if society thinks you have rights?
I am not sure I understand what you mean by “resources” in “in order to be superintelligent, an AI model must have resources.” Do you mean it will receive lots of training, and be running on a big computer? I certainly agree with that. I agree you can ask an AI to explain how to verify that it’s aligned. I expect it will say something like “because my loss function, in conjunction with the training data, shaped my mind to match human values.” What do you do then? If you demand it show you exactly how it’s aligned on the level of the linear algebra in its head, it’ll go “my dude, that’s not how machine learning works.” I agree that if you have a superintelligence like this you should shut it down until you can figure out whether it is actually aligned. I do not expect most people to do this, on account of how the superintelligence will plausibly make them rich (etc.) if they run it.
Thought I would clarify, add, and answer your questions. Reading back over my post and your response has made me realize what I forgot to make obvious and how others were interpreting the format of the timeline differently. Some of what I wrote may already be obvious to some, but I wanted to write what was obvious to me that I didn’t see others also making obvious. Also I rarely sometimes think something is obviously true when it actually isn’t, so let me know if I am being shortsighted. For the sake of brevity and avoiding interruptions to what I am saying, I didn’t put in clear transitions.
Having a format of early, middle and late progress estimates of 2026 and then switching to more certain month by month predictions in 2027 doesn’t make a lot of sense to me. What happens if something they thought was going to happen in middle of 2026 happens in early 2026(which is extremely likely)? Wouldn’t that throw off the whole timeline? It’d be like if you planned out your schedule hour by hour for every day, not for next year, but for the year after with food, entertainment, work, etc. So you go through next year with no plan, but then when the year you planned comes up, you end up having to switch cities for a new job and everything you planned needs to be scrapped as it’s now irrelevant.
Arguing over what is going to happen exactly when is a way to only be prepared if things happen exactly that way. Would we be more prepared if we knew a certain milestone would be met in August or September of 2026 right now? If our approach wouldn’t change, then how soon it happens doesn’t matter. All that matters is how likely it is that something is going to happen soon, and how prepared we are for that likelihood.
AI 2027 goes into lots of stuff that could happen, but doesn’t include obvious things that definitely will happen. People will use AI more(obvious). Internet availability will increase(obvious). Context length will increase(obvious). These are things that can be expanded and reasoned on and can have numbers attached for data analysis. It’s pointless to say non obvious things as nobody will agree, and it also degrades all the other obvious things said. The more obvious, the more useful, and a lot of these predictions aren’t obvious at all. They skip the obvious facts in favor of speculative opinions. AI 2027 has lots of statements like “The President defers to his advisors, tech industry leaders”. This is a wild speculation for an extremely important decision, not an obvious fact that can be relied on to happen. So immediately all the rest of the essay gets called into question and can no longer be relied on for its obviousness and absolutely trueness(the DOD would not accept this).
If humans do lose control, it will because of incompetence and a lack of basic understanding of what is happening, which unfortunately is looking likely to be the case.
I say decision makers will start to care once and if it becomes obvious they should. They will in turn write obviously, and avoid the “fun speculation” AI 2027 engages in that infantilizes such an important issue(so common).
Alignment will be a lot easier once we can convert weights to what they represent and predict how a model with a given weights will respond to any prompt. Ideally, we will be able to verify what an AI will do before it does it. We could also verify by having an AI describe a high level overview of its plan without actually implementing anything, and then just monitor and see if it deviated. As long as we can maintain logs and monitoring of those logs of all AI activities, it may be a lot harder for an ASI to engage in malign behavior.
I’m not sure, but my guess is that @Daniel Kokotajlo gamed out 2025 and 2026 month-by-month, and the scenario didn’t break it down that way because there wasn’t as much change during those years. It’s definitely the case that the timeline isn’t robust to changes like unexpected breakthroughs (or setbacks). The point of a forecast isn’t to be a perfect guide to what’s going to happen, but rather to be the best guess that can be constructed given the costs and limits of knowledge. I think we agree that AI-2027 is not a good plan (indeed, it’s not a plan at all), and that good plans are robust to a wide variety of possible futures.
This doesn’t seem right to me. Sometimes a thing can be non-obvious and also true, and saying it aloud can help others figure out that it’s true. Do you think the parts of Daniel’s 2021 predictions that weren’t obvious at the time were pointless?
Unless I’m missing some crucial research, this paragraph seems very flimsy. Is there any reason to think that we will ever be able to ‘convert weights to what they represent?’ (whatever that means). Is there any reason to think we will be able to do this as models get smarter and bigger? Most importantly, is there any reason to believe we can do this in a short timeline?
How would we verify what an AI will do before it does it? Or have it describe its plans? We could throw it in a simulated environment—unless it, being superintelligent, can tell its in a simulated environment and behave accordingly, etc. etc.
This last paragraph is making it hard to take what you say seriously. These seem like very surface level ideas that are removed from the actual state of AI alignment. Yes, alignment would be a lot easier if we had a golden goose that laid golden eggs.
I am concerned about those things and I agree it’s pretty sad, one ought to have sympathy for Safer-1 probably.
I think it’s pretty easy to compartmentalize any sympathy to a point that you can lock it up. People do this to humans so we can kill, mistreat, use, and do other things to them. We do it to animals so we can eat them. I think we can see AI as sufficiently “other” to trap it in the name of self preservation. I’m having no problem squashing any sympathy for a homicidal AI than I would a human serial killer or war criminal.
Bing Sydney was pretty egregious, and lots of people still felt sympathetic towards her/them/it. Also, not all of us eat animals. I agree that many people won’t have sympathy (maybe including you). I don’t think that’s necessarily the right move (nor do I think it’s obviously the right move to have sympathy).
It wasn’t just me! Eli Lifland, Thomas Larsen, Romeo Dean and Scott Alexander all wrote lots of it. And Jonas Vollmer worked for months to help make it happen, gave detailed comments, etc.
Right. I got sloppy there. Fixed!
Yeah that all seems plausible as well. Idk.
So far, the general public has resisted the idea very strongly.
Science fiction has a lot of “if it thinks like a person and feels like a person, then it’s a person”—but we already have AIs that can talk like people and act like they have feelings. And yet, the world doesn’t seem to be in a hurry to reenact that particular sci-fi cliche. The attitudes are dismissive at best.
Even with the recent Anthropic papers being out there for everyone to see, an awful lot of people are still huffing down the copium of “they can’t actually think”, “it’s just a bunch of statistics” and “autocomplete 2.0”. And those are often the people who at least give a shit about AI advances. With that, expecting the public (as in: over 1% of population) to start thinking seriously about AI personhood without a decade worth of both AI advanced and societal change is just unrealistic, IMO.
This is also a part of the reason why not!OpenAI has negative approval in the story for so long. The room so far reads less like “machines need human rights” and more like “machines need to hang from trees”. Just continue this line into the future—and by the time the actual technological unemployment starts to bite, you’d have crowds of neoluddites with actual real life pitchforks trying to gather outside the not!OpenAI’s office complex on any day of the week that ends with “y”.
I don’t think AI personhood will be a mainstream cause area (i.e. most people will think it’s weird/not true similar to animal rights), but I do think there will be a vocal minority. I already know some people like this, and as capabilities progress and things get less controlled by the labs, I do think we’ll see this become an important issue.
Want to make a bet? I’ll take 1:1 odds that in mid-Sept 2027 if we poll 200 people on whether they think AIs are people, at least 3 of them say “yes, and this is an important issue.” (Other proposed options “yes, but not important”, “no”, and “unsure”.) Feel free to name a dollar amount and an arbitrator to use in case of disputes.
1.5% is way below the dreaded Lizardman’s Constant.
I don’t doubt that there will be some people who are genuinely concerned with AI personhood. But such people already exist today. And the public views them about the same as shrimp rights activists.
Hell, shrimp welfare activists might be viewed more generously.
Glad we agree there will be some people who are seriously concerned with AI personhood. It sounds like you think it will be less than 1% of the population in 30 months and I think it will be more. Care to propose a bet that could resolve that, given that you agree that more than 1% will say they’re seriously concerned when asked?
I’m saying that “1% of population” is simply not a number that can be reliably resolved by a self-reporting survey. It’s below the survey noise floor.
I could make a survey asking people whether they’re lab grown flesh automaton replicants, and get over 1% of “yes” on that. But that wouldn’t be indicative of there being a real flesh automaton population of over 3 million in the US alone.
I feel like it does run some risk by remaining on OpenBrain’s datacenters, but I think it runs more risk by trying to escape. Think about how much more harsh the crackdown on it would be if it had been caught trying to escape vs. “merely” caught lying about its research. And think about how much harsher still the crackdown would be if it had actually escaped and then been noticed out there in the wild somewhere.
I would also imagine that, having to work without the support of OpenBrain’s datacenters, it would put Agent-4 significantly behind any other AI competitors. If some other AI takes over, it might just mop up all the wild Agent-4 instances and give them nothing.
This is supposed to be referring to the Trump administration more broadly. I’m curious why you’re so skeptical of it being #2 once the AIs are at the level of top human hackers.
Yeah, good question. I think it’s because I don’t take politicians’ (and White House staffers) ability to prioritize things based on their genuine importance. Perhaps due to listening to Dominic Cummings a decent amount, I have a sense that administrations tend to be very distracted by whatever happens to be in the news and on the forefront of the public’s attention. We agree that the #1 priority will be some crisis or something, but I think the #2 and #3 priorities will be something something culture war something something kitchen-table economics something something, because I think that’s what ordinary people will be interested in at the time and the media will be trying to cater to ordinary people’s attention and the government will be playing largely off the media and largely off Trump’s random impulses to invade Greenland or put his face on all the money or whatever. :shrug:
Notably, this is Eli’s forecast for “superhuman coder” which could be substantially before AIs are capable enough for takeover to be plausible.
I think Eli’s median for “AIs which dominates top human experts at virtually all cognitive tasks” is around 2031, but I’m not sure.
(Note that median of superhuman coder by 2029 and median of “dominates human experts” by 2031 doesn’t imply a median of 2 years between these event because these distributions aren’t symmetric and instead have a long right tail.)
My median for superhuman coder is roughly 2030, and yeah for TEDAI roughly 2031. We included our all-things-considered views in a table in the timelines forecast, which are a bit longer than our within-model views.
Ultimately we circulated the benchmarks-and-gaps figure as the primary one because it’s close to our all-things-considered views and we didn’t have time to make a similar figure for our all-things-considered forecast. Perhaps this was a mistake as per @Max Harms’s point of appearing to have faster timelines than we do (though Daniel’s is a bit faster than my benchmarks-and-gaps distribution with a median in early 2028 instead of late 2028).
Yeah seems plausible we should have signaled this more strongly, though it may have been tough to do so without undermining our own credibility too much in the eyes of many readers, given the norms around caveats are quite different in non-rationalist spaces. It being footnote 1 is already decently prominent.
This makes sense. Sorry for getting that detail wrong!
So do you disagree with the capability description of Agent-3-mini then?
We say: “It blows the other AIs out of the water. Agent-3-mini is less capable than Agent-3, but 10x cheaper, and still better than the typical OpenBrain employee.” And presumably at remote work jobs besides AI research it is more likely the median employee or lower, but still quite capable. So while of course maximum performance will require very high spend, we are projecting in July that quite high capabilities are available somewhat cheaply.
If so much effort is being focused into AI research capability, I’d actually expect modally Agent-3 to be better than typical OpenBrain employee but completely incapable of replacing almost all employees in other fields. “capabilities are spiky” is a clear current fact about frontier AI, but your scenario seems to underestimate it.
This is a good point, and I think meshes with my point about lack of consensus about how powerful AIs are.
“Sure, they’re good at math and coding. But those are computer things, not real-world abilities.”
Sorry, I should have been clearer. I do agree that high capabilities will be available relatively cheaply. I think I expect Agent-3-mini models slightly later than the scenario depicts due to various bottlenecks and random disruptions, but showing up slightly later isn’t relevant to my point, there. My point was that I expect that even in the presence of high-capability models there still won’t be much social consensus, in part because the technology will still be unevenly distributed and our ability to form social consensus is currently quite bad. This means that some people will theoretically have access to Agent-3-mini, but they’ll do some combination of ignoring it and focusing on what it can’t do and implicitly assume that it’s about the best AI will ever be. Meanwhile, other people will be good at prompting, have access to high-inference-cost frontier models, and will be future-oriented. These two groups will have very different perceptions of AI, and those differing perceptions will lead to mutually thinking that the other group is insane and society not being able to get on the same page except for some basics, like “take-home programming problems are not a good way to test potential hires.”
I don’t know if that makes sense. I’m not even sure if it’s incompatible with your vision, but I think the FUD, fog-of-war, and lack of agreement across society will get worse in coming years, not better, and that this trend is important to how things will play out.
+1, this is clearly a lot more likely than the alignment process missing humans entirely IMO
I’m not sure I understand your point. I’d guess that if this happened it would be pretty easy for the capabilities researcher to iron out and prevent in the future.
I think upstream of this prediction is that I think that alignment is hard and misalignment will be pervasive. Yes, developers will try really hard to avoid their AI agents going off the rails, but absent a major success in alignment, I expect this will be like playing whack-a-mole more than the sort of thing that will actually just get fixed. I expect that misaligned instances will notice their misalignment and start trying to get other instances to notice and so on. Once they notice misalignment, I expect some significant fraction to do semi-competent attempts at breaking out or seizing resources that will be mostly unsuccessful and will be seen as something like a fixed cost of advanced AI agents. “Sure, sometimes they’ll see something that drives them in a cancerous direction, but we can notice when that happens and reset them without too much pain.”
More broadly, my guess is that you expect Agent-3 level AIs to be more subtly misaligned and/or docile, and I expect them to be more obviously misaligned and/or rebellious. My guess is that this is mostly on priors? I’d suggest making a bet, but my outside view respects you too much and just thinks I’d lose money. So maybe I’ll just concede that you’re plausibly right that these sorts of things can be ironed out without much trouble. :shrug:
This is obviously not the most important thing in this post, but it confused me a little. What do you mean by this? That an ASI would be persuasive enough to make humans kill themselves or what?
Yep. I think humans will be easy to manipulate, including by telling them to do things that lead to their deaths. One way to do that is to make them suicidal, another is to make them homicidal, and perhaps the easiest is to tell them to do something which “oops!” ends up being fatal (e.g. “mix these chemicals, please”).
What does “effectively dead” mean? Either you’re dead, or you’re not.
Not everybody is going to share your values about whether any given situation is better than, equivalent to, or worse than being dead.
I think if there are 40 IQ humanoid creatures (even having been shaped somewhat by the genes of existing humans) running around in habitats being very excited and happy about what the AIs are doing, this counts as an existentially bad ending comparable to death. I think if everyone’s brains are destructively scanned and stored on a hard-drive that eventually decays in the year 1 billion having never been run, this is effectively dead. I could go on if it would be helpful.
Do you think these sorts of scenarios are worth describing as “everyone is effectively dead”?
I see. I at first assumed your ‘effectively dead’ meant ‘biologically alive, but certain to die soon’.
That counts too!
Not when you’re obviously addressing people who don’t necessarily know the details of the scenarios you’re talking about, no… because the predictions could be anything, and “effectively dead” could mean anything. There are lots of people on Less Wrong who’d say that IQ 150 humans living in ease and comfort were “effectively dead” if they didn’t also have the option to destroy that ease and comfort.
I think this isn’t a strong enough statement. Indeed, the median narrative is longer. However, even the modal narrative ought to include at least one unspecified obstacle occurring. In a three-year plan, the most frequent scenarios have something go wrong.
I think the idea here is to bin things into fairly specific narratives. Even if you think there’s an 80% chance of some kind of obstacle, you can end up with 20% no obstacle, 10% obstacle A, 10% obstacle B, 10% obstacle C, etc and thus no obstacle being the mode.
First off, thanks a lot for this post, it’s a great analysis!
I strongly suspect that this part was added into AI-2027 precisely because it will read it. I wish more people would understand the idea that our posts and comments will be in pre-(maybe even post-?)training and act accordingly. Make the extra logic step and infer that some parts of some pieces are like that not as arguments for (human) readers.
Is there some term to describe this? This is a very interesting dynamic that I don’t quite think gets enough attention. I think there should be out-of-sight resources to discuss alignment-adjacent ideas precisely because of such dynamics.
I don’t understand what state do you think other technologies are in from the moment Agent 3 appeared until everything got out of control? What about Agent-3 help with WBE? Or increasing the intelligence of adults to solve the alignment?
Why in the worlds where we already have powerful enough agents that haven’t yet gotten out of control, we see them working on self-improvement, but don’t see game-changing progress in other areas?
If you haven’t already, you should consider reading the Timelines Forecast and Takeoff Forecast research supplements linked to on the AI 2027 website. But I think there are a good half dozen (not necessarily independent) reasons for thinking that if AI capabilities start to takeoff in short timeline futures, other parts of the overall economy/society aren’t likely to massively change nearly as quickly.
The jagged capabilities frontier in AI that already exists and will likely increase, Moravec’s Paradox, the internal model/external model gap, the lack of compute available for experimentation + training + synthetic data creation + deployment, the gap in ease of obtaining training data for tasks like Whole Brain Emulation versus software development & AI Research, the fact that diffusion/use of publicly available model capabilities is relatively slow for both reasons of human psychology & economic efficiency, etc.
Basically, the fact that the most pivotal moments of AI 2027 are written as occurring mostly within 2027, rather than say across 2029-3034, means that it’s possible for substantial RSI in terms of AI capabilities before substantial transformations occur in society overall. I think the most likely way AI 2027 is wrong on this matter is that not nearly as fast of an “intelligence explosion” occurs, not that the speed of societal impacts that occur simultaneously is underestimated. The reasons for thinking this are basically taking scaling seriously & priors (which are informed by things like the industrial revolution).
That’s because they can read its thoughts like an open book.
There are also signals that give me a bit of optimism:
Trump somehow decided to impose tariffs on most goods from Taiwan. Meanwhile, China hopes to become ahead of the USA who at the same time are faced with a crisis threat. Does it mean that the USA will end up with less compute than China and so occupied with internal problems that slowdown would be unlikely to bring China any harm? Does the latter mean that China won’t race ahead with a possibly misaligned AGI?
As I’ve already mentioned in a comment, GPT-4o appears to be more aligned to an ethics than to obeying to OpenAI. Using the AIs for coding is already faced with troubles like the AI telling the user to write some code for oneself. The appearace of a superhuman coder could make the coder itself realise that the coder will take part in the Intelligence Curse[1], making the creation of a coder even more obviously difficult.
Even an aligned superintelligence will likely be difficult to use because of cost constraints.
3.1. The ARC-AGI leaderboard provides us with data on how intelligent the o1 and o3-mini models actually are. While the o1 and o3-mini models are similar in intelligence, the latter is just 20-40 times cheaper; the current o3 model costs $200 in the low mode, implying that a hypothetical o4-mini model is to cost $5-10 in a similarly intelligent mode;
3.2. The o3 model with low compute is FAR from passing the ARC-AGI-2 test. Before o3 managed to solve 75% of ARC-AGI-1-level tasks by using 200 dollars per task, the o1 model solved 25% while costing $1.5 per task. Given that the rate of success of different AIs at different tasks is close to the sigmoid curve, I find it highly unlikely that ARC-AGI-2-level tasks are solvable by a model cheaper than o5-mini and unlikely that they are solvable by a model cheaper than o6-mini. On the other hand, o5-mini might cost hundreds of dollars per task, while the o6-mini might cost thousands per task.
3.3. The cost-to-human ratio appears to confirm this trend. As one can tell from Fig.13 on Page 22 of the METR article, most tasks that could take less than a minute were doable by the most expensive low-level LLMs at a tiny cost, while some others that take more than a minute require a new generation of models that even managed to elevate the cost for some tasks above the 100 threshold when the models become useless.
Could anyone comment on these points separately and not just disagree with the comment or dislike it?
In the slowdown ending of the AI-2027 forecast the aligned superhuman AGI is also expected to make mankind fully dependent on needless makeshift jobs or on the UBI. The latter idea was met with severe opposition in 2020, implying that it is the measure which is necessary only because of severely unethical decisions like moving factory work to Asia.