DeepSeek beats o1-preview on math, ties on coding; will release weights
DeepSeek-R1-Lite-Preview was announced today. It’s available via chatbot. (Post; translation of Chinese post.)
DeepSeek says it will release the weights and publish a report.
The model appears to be stronger than o1-preview on math, similar on coding, and weaker on other tasks.
DeepSeek is Chinese. I’m not really familiar with the company. I thought Chinese companies were at least a year behind the frontier; now I don’t know what to think and hope people do more evals and play with this model. Chinese companies tend to game benchmarks more than the frontier Western companies, but I think DeepSeek hasn’t gamed benchmarks much historically.
The post also shows inference-time scaling, like o1:
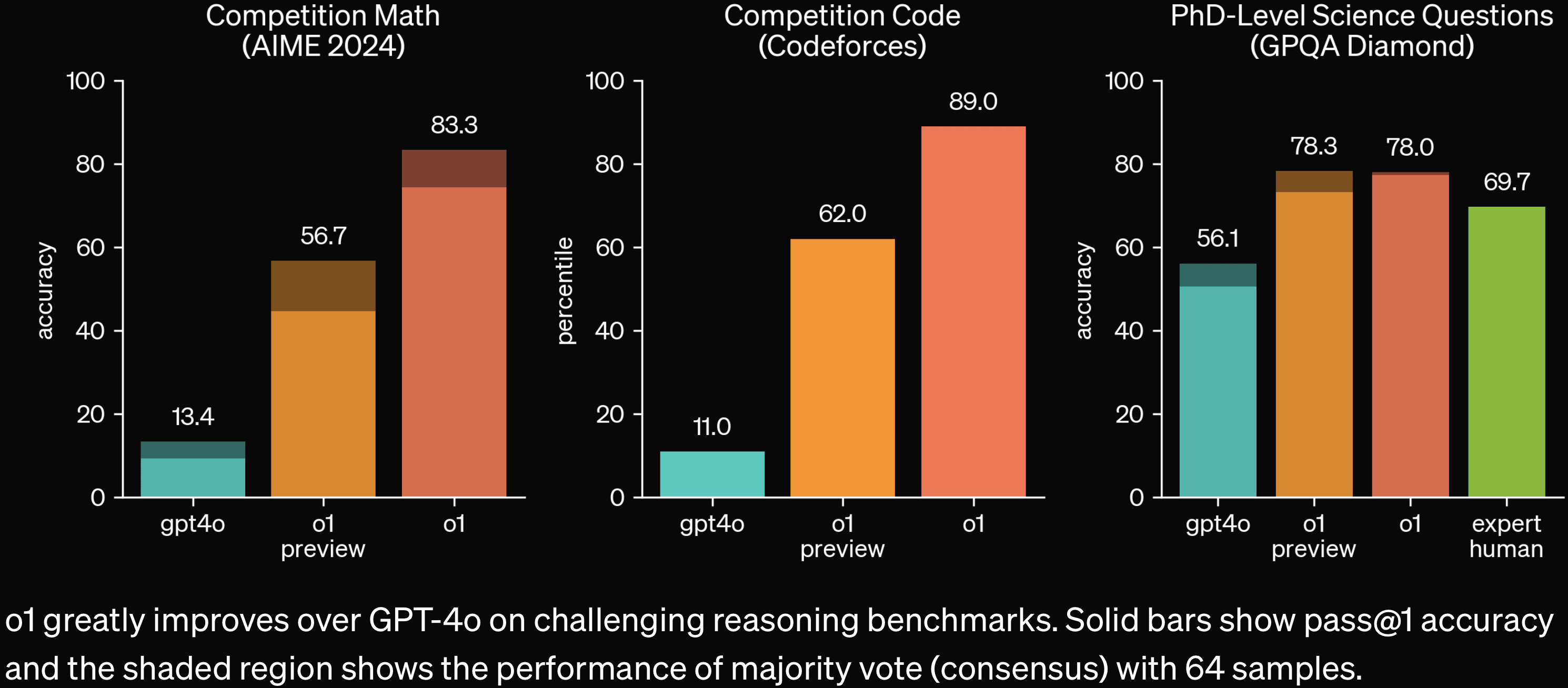
Note that o1 is substantially stronger than o1-preview; see the o1 post:
(Parts of this post and some of my comments are stolen from various people-who-are-not-me.)
DeepSeek is the best Chinese DL research group now and have been for at least a year. If you are interested in the topic, you ought to learn more about them.
This seems roughly consistent with what you would expect. People usually say half a year to a year behind. Q* was invented somewhere in summer 2023, according to the OA coup reporting; ballpark June-July 2023, I got the impression since it seemed to already be a topic of discussion with the Board c. August 2023 pre-coup. Thus, we are now (~20 Nov 2024) almost at December 2024, which is about a year and a half. o1-preview was announced 12 September 2024, 74 days ago, and o1-preview’s benchmarks were much worse than the true o1 which was still training then (and of course, OA has kept improving it ever since, even if we don’t know how—remember, time is always passing†, and what you read in a blog post may already be ancient history). Opensource/competitor models (not just Chinese or DeepSeek specifically) have a long history of disappointing in practice when they turn out to be much narrower, overfit to benchmarks, or otherwise somehow lacking in quality & polish compared to the GPT-4s or Claude-3s.
So, if a competing model claims to match o1-preview from almost 3 months ago, which itself is far behind o1, with additional penalties from compensating for the hype and the apples-to-oranges comparisons, and where we still don’t know if they are actually the same algorithm at core (inasmuch as neither OA nor DeepSeek, AFAIK, have yet to publish any kind of detailed description of what Q*/Strawberry/r1 is), and possibly worst-case as much as >1.5 years behind if DS has gone down a dead end & has to restart… This point about time applies to any other Chinese replications as well, modulo details like possibly suggesting DeepSeek is not so good etc.
Overall, this still seems roughly what you would expect now: ‘half a year to a year behind’. It’s always a lot easier to catch up with an idea after someone else has proven it works and given you an awful lot of hints about how it probably works, like the raw sample transcripts. (I particularly note the linguistic tics in this DS version too, which I take as evidence for my inner-monologue splicing guess of how the Q* algorithm works.)
† I feel very silly pointing this out: that time keeps passing, and if you think that some new result is startling evidence against the stylized fact “Chinese DL is 6-12 months behind” that you should probably start by, well, comparing the new result to the best Western DL result 6–12 months ago! Every time you hear about a new frontier-pushing Western DL result, you should mentally expect a Chinese partial replication in 6–12 months, and around then, start looking for it. / This should be too obvious to even mention. And yet, I constantly get the feeling that people have been losing their sort of… “temporal numeracy”, for lack of a better phrase. That they live in a ‘Big Now’ where everything has happened squashed together. In the same way that in politics/economics, people will talk about the 1980s or 1990s as if all of that was just a decade ago instead of almost half a century ago (yes, really: 2024 − 1980 = 44), many people discussing AI seems to have strangely skewed mental timelines. / They talk like GPT-4 came out, like, a few months after GPT-3 did, maybe? So GPT-5 is wildly overdue! That if a Chinese video model matches OA Sora tomorrow, well, Sora was announced like, a month ago, something like that? So they’ve practically caught up! OA only just announced o1, and DeepSeek has already matched it! Or like 2027 is almost already here and they’re buying plane tickets for after Christmas. There’s been a few months without big news? The DL scaling story is over for good and it hit the wall!
I experimented a bunch with DeepSeek today, it seems to be exactly on the same level in highs school competition math as o1-preview in my experiments. So I don’t think it’s benchmark-gaming, at least in math. On the other hand, it’s noticeably worse than even the original GPT-4 at understanding a short story I also always test models on.
I think it’s also very noteworthy that DeepSeek gives everyone 50 free messages a day (!) with their CoT model, while OpenAI only gives 30 o1-preview messages a week to subscribers. I assume they figured out how to run it much cheaper, but I’m confused in general.
A positive part of the news is that unlike o1, they show their actual chain of thought, and they promise to make their model open-source soon. I think this is really great for the science of studying faithful chain of thought.
From the experiments I have run, it looks like it is doing clear, interpretable English chain of thought (though with an occasional Chinese character once in a while), and I think it didn’t really yet start evolving into optimized alien gibberish. I think this part of the news is a positive update.
Yeah, I really hope they do actually open-weights it because the science of faithful CoT would benefit greatly.
My impression is that you’ve updated a fair bit on open source relative to a few years ago..
If so, I think a top level post describing where you were, what evidence updated you, and where you are now might be broadly useful.
I’m afraid I’m probably too busy with other things to do that. But it’s something I’d like to do at some point. The tl;dr is that my thinking on open source used to be basically “It’s probably easier to make AGI than to make aligned AGI, so if everything just gets open-sourced immediately, then we’ll have unaligned AGI (that is unleashed or otherwise empowered somewhere in the world, and probably many places at once) before we have any aligned AGIs to resist or combat them. Therefore the meme ‘we should open-source AGI’ is terribly stupid. Open-sourcing earlier AI systems, meanwhile, is fine I guess but doesn’t help the situation since it probably slightly accelerates timelines, and moreover it might encourage people to open-source actually dangerous AGI-level systems.”
Now I think something like this:
“That’s all true except for the ‘open-sourcing earlier AI systems meanwhile’ bit. Because actually now that the big corporations have closed up, a lot of good alignment research & basic science happens on open-weights models like the Llamas. And since the weaker AIs of today aren’t themselves a threat, but the AGIs that at least one corporation will soon be training are… Also, transparency is super important for reasons mentioned here among others, and when a company open-weights their models, it’s basically like doing all that transparency stuff and then more in one swoop. In general it’s really important that people outside these companies—e.g. congress, the public, ML academia, the press—realize what’s going on and wake up in time and have lots of evidence available about e.g. the risks, the warning signs, the capabilities being observed in the latest internal models, etc. Also, we never really would have been in a situation where a company builds AGI and open-sourced it anyway; that was just an ideal they talked about sometimes but have now discarded (with the exception of Meta, but I predict they’ll discard it too in the next year or two). So yeah, no need to oppose open-source, on the contrary it’s probably somewhat positive to generically promote it. And e.g. SB 1047 should have had an explicit carveout for open-source maybe.”
The Chinese characters sound potentially worrying. Do they make sense in context? I tried a few questions but didn’t see any myself.
I saw them in 10-20% of the reasoning chains. I mostly played around with situational awareness-flavored questions, I don’t know whether the Chinese characters are more or less frequent in the longer reasoning chains produced for difficult reasoning problems. Here are some examples:
The translation of the Chinese words here (according to GPT) is “admitting to being an AI.”
This is the longest string in Chinese that I got. The English translation is “It’s like when you see a realistic AI robot that looks very much like a human, but you understand that it’s just a machine controlled by a program.”
The translation here is “mistakenly think.”
Here, the translation is “functional scope.”
So, seems like all of them are pretty direct translations of the English words that should be in place of the Chinese ones, which is good news. It’s also reassuring to me that none of the reasoning chains contained sentences or paragraphs that looked out of place or completely unrelated to the rest of the response.
I think it only came up once for a friend. I translated it and it makes sense, it just leaves replaces the appropriate English verb with a Chinese one in the middle of a sentence. (I note that this often happens with me to when I talk with my friends in Hungarian, I’m sometimes more used to the English phrase for something, and say one word in English in the middle of the sentence.)
As someone who, in a previous job, got to go to a lot of meetings where the European commission is seeking input about standardising or regulating something—humans also often do the thing where they just use the English word in the middle of a sentence in another language, when they can’t think what the word is. Often with associated facial expression / body language to indicate to the person they’re speaking to “sorry, couldn’t think of the right word”. Also used by people speaking English, whose first language isn’t English, dropping into their own lamguage for a word or two. If you’ve been the editor of e.g. an ISO standard, fixing these up in the proposed text is such fun.
So, it doesn’t surprise me at all that LLMs do this.
I have, weirdly, seen llms put a single Chinese word in the middle of English text … and consulting a dictionary reveals that it was, in fact, the right word, just in Chinese.
I suppose we might worry that LlMs might learn to do RLHF evasion this way—human evaluator sees Chinese character they don’t understand, assumes it’s ok, and then the LLM learns you can look acceptable to humans by writing it in Chinese.
Some old books (which are almost certainly in the training set) used Latin for the dirty bits. Translations of Sanskrit poetry, and various works by that reprobate Richard Burton, do this.
o1′s reasoning trace also does this for different languages (IIRC I’ve seen Chinese and Japanese and other languages I don’t recognise/recall), usually an entire paragraph not a word, but when I translated them it seemed to make sense in context.
I see them in o1-preview all the time as well. Also, french occasionally
Claim by SemiAnalysis guy: DeepSeek has over 50,000 H100s. (And presumably they don’t spend much compute on inference.)
It’s predictably censored on CCP-sensitive topics.
(In a different chat.) After the second question, it typed two lines (something like “There have been several attempts to compare Winnie the Pooh to a public individual...”) and then overwrote it with “Sorry...”.
Breakable with some light obfuscation (the misspelling is essential here, as otherwise a circuit breaker will kick in):
One weird detail I noticed is that in DeepSeek’s results, they claim GPT-4o’s pass@1 accuracy on MATH is 76.6%, but OpenAI claims it’s 60.3% in their o1 blog post. This is quite confusing as it’s a large difference that seems hard to explain with different training checkpoints of 4o.
It seems that 76.6% originally came from the GPT-4o announcement blog post. I’m not sure why it dropped to 60.3% by the time of o1′s blog post.
There had been a number of papers published over the last year on how to do this kind of training, and for roughly a year now there have been rumors that OpenAI were working on it. If converting that into a working version is possible for a Chinese company like DeepSeek, as it appears, then why haven’t Anthropic and Google released versions yet? There doesn’t seem to be any realistic possibility that DeepSeek actually have more compute or better researchers than both Anthropic and Google.
One possible interpretation would be that this has significant safety implications, and Anthropic and Google are both still working through these before releasing.
Another possibility would be that Anthropic has in fact released, in the sense that their Claude models’ recent advances in agentic behavior (while not using inference-time scaling) are distilled from reasoning traces generated by an internal-only model of this type that is using inference-time scaling.
Is there a reason why every LLM tokenizer I’ve seen excludes slurs? It seems like a cheap way to train for AI assistant behavior.
Also notable that numbers are tokenized individually—I assume this greatly improves its performance in basic arithmetic tasks as compared to GPTs.
That’s interesting, if true. Maybe the tokeniser was trained on a dataset that had been filtered for dirty words.
Some context: interview translation; June FT article on DeepSeek; parent hedge fund Wikipedia page.
If developments like this continue, could open weights models be made into a case for not racing? E.g. if everyone’s getting access to the weights, what’s the point in spending billions to get there 2 weeks earlier?
FYI if you want to use o1-like reasoning, you need to check off “Deep Think”.