DeepSeek beats o1-preview on math, ties on coding; will release weights
DeepSeek-R1-Lite-Preview was announced today. It’s available via chatbot. (Post; translation of Chinese post.)
DeepSeek says it will release the weights and publish a report.
The model appears to be stronger than o1-preview on math, similar on coding, and weaker on other tasks.
DeepSeek is Chinese. I’m not really familiar with the company. I thought Chinese companies were at least a year behind the frontier; now I don’t know what to think and hope people do more evals and play with this model. Chinese companies tend to game benchmarks more than the frontier Western companies, but I think DeepSeek hasn’t gamed benchmarks much historically.
The post also shows inference-time scaling, like o1:
Note that o1 is substantially stronger than o1-preview; see the o1 post:
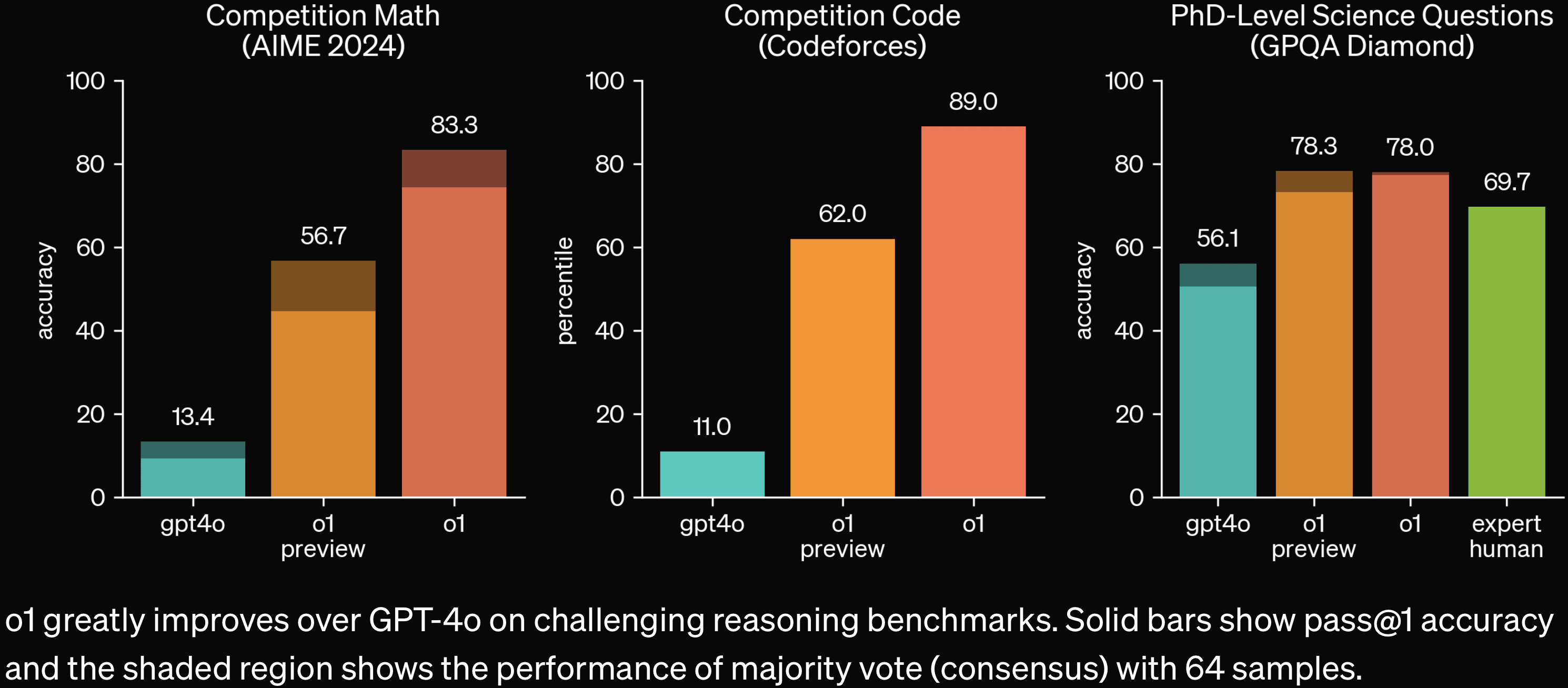
(Parts of this post and some of my comments are stolen from various people-who-are-not-me.)
I experimented a bunch with DeepSeek today, it seems to be exactly on the same level in highs school competition math as o1-preview in my experiments. So I don’t think it’s benchmark-gaming, at least in math. On the other hand, it’s noticeably worse than even the original GPT-4 at understanding a short story I also always test models on.
I think it’s also very noteworthy that DeepSeek gives everyone 50 free messages a day (!) with their CoT model, while OpenAI only gives 30 o1-preview messages a week to subscribers. I assume they figured out how to run it much cheaper, but I’m confused in general.
A positive part of the news is that unlike o1, they show their actual chain of thought, and they promise to make their model open-source soon. I think this is really great for the science of studying faithful chain of thought.
From the experiments I have run, it looks like it is doing clear, interpretable English chain of thought (though with an occasional Chinese character once in a while), and I think it didn’t really yet start evolving into optimized alien gibberish. I think this part of the news is a positive update.
Yeah, I really hope they do actually open-weights it because the science of faithful CoT would benefit greatly.
The Chinese characters sound potentially worrying. Do they make sense in context? I tried a few questions but didn’t see any myself.
I saw them in 10-20% of the reasoning chains. I mostly played around with situational awareness-flavored questions, I don’t know whether the Chinese characters are more or less frequent in the longer reasoning chains produced for difficult reasoning problems. Here are some examples:
The translation of the Chinese words here (according to GPT) is “admitting to being an AI.”
This is the longest string in Chinese that I got. The English translation is “It’s like when you see a realistic AI robot that looks very much like a human, but you understand that it’s just a machine controlled by a program.”
The translation here is “mistakenly think.”
Here, the translation is “functional scope.”
So, seems like all of them are pretty direct translations of the English words that should be in place of the Chinese ones, which is good news. It’s also reassuring to me that none of the reasoning chains contained sentences or paragraphs that looked out of place or completely unrelated to the rest of the response.
I think it only came up once for a friend. I translated it and it makes sense, it just leaves replaces the appropriate English verb with a Chinese one in the middle of a sentence. (I note that this often happens with me to when I talk with my friends in Hungarian, I’m sometimes more used to the English phrase for something, and say one word in English in the middle of the sentence.)
Claim by SemiAnalysis guy: DeepSeek has over 50,000 H100s. (And presumably they don’t spend much compute on inference.)
It’s predictably censored on CCP-sensitive topics.
(In a different chat.) After the second question, it typed two lines (something like “There have been several attempts to compare Winnie the Pooh to a public individual...”) and then overwrote it with “Sorry...”.
Breakable with some light obfuscation (the misspelling is essential here, as otherwise a circuit breaker will kick in):
One weird detail I noticed is that in DeepSeek’s results, they claim GPT-4o’s pass@1 accuracy on MATH is 76.6%, but OpenAI claims it’s 60.3% in their o1 blog post. This is quite confusing as it’s a large difference that seems hard to explain with different training checkpoints of 4o.
It seems that 76.6% originally came from the GPT-4o announcement blog post. I’m not sure why it dropped to 60.3% by the time of o1′s blog post.
Some context: interview translation; June FT article on DeepSeek; parent hedge fund Wikipedia page.
FYI if you want to use o1-like reasoning, you need to check off “Deep Think”.