[LDSL#2] Latent variable models, network models, and linear diffusion of sparse lognormals
This post is also available on my Substack.
Where we last left off, I proposed that life cannot be understood through statistics, but rather requires more careful study of individual cases. Yet I don’t think this is actually convincing to the statistical/academic mindset unless we have a statistical description of the phenomenon. To understand it, I’ve developed a new explicit model for the relationship between statistics and reality: linear diffusion of sparse lognormals.
But in order to explain this, I first want to bring up the two classical models of the relationship, as usually presented in psychometrics.[1]
Latent variable models and network models
We don’t have direct access to raw reality; instead to infer things about reality, we have some sensory inputs (e.g. for humans, eyes; for psychometricians, surveys; for computers, network and storage IO) which we can use to infer things that exist. This is called a latent variable model:
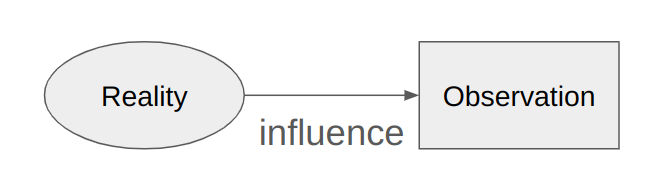
Generally, a single variable does not give us enough evidence to robustly infer anything. For instance a single light ray entering your eyes does not teach you what object it reflected off of. Instead, you need many observations to infer things about reality, which requires the latent variable to influence many different variables.
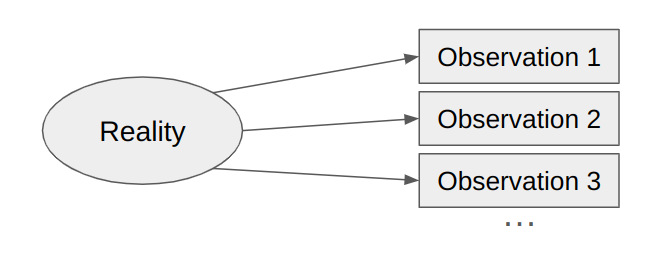
If you’ve got a large dataset, and you are willing to assume that there’s much fewer factors that matter in reality than there are observations, you can use fairly straightforward methods to fit a latent variable model to this dataset, which tends to give fairly “reasonable” results, in the sense that similar observations end up attributed to similar factors.
Sometimes people find latent factor models unbelievable and unworkable. For instance, different mental health problems correlate with each other, so standard latent factor models might suggest thinking up broad mental health factors that influence many symptoms from poor sleep to anxiety. When treating people’s mental health, clinicians might often try to directly stabilize individual variables like sleep, which is somewhat strange if we think the root cause is something much broader.
Yet at the same time, obviously a lot of the time there are latent dynamics that need to be intervened on. Imagine trying to stop global warming by freezing lots of ice and transporting it to places, rather than developing nuclear and renewable energy; it would never work.
So the correct approach is to combine the two kinds of models: Reality is a network of variables that influence each other. Some variables, or collections of variables, have homogenous influences across a variety of outcomes, making them “general factors” and especially important. In particular the relationship between observation and reality must always be mediated by a general factor.
Diffusion and interaction
In both factor models and network models, you speak of variables influencing each other. Especially in network models[2], you often end up with cases where one variable is influenced by multiple other variables, i.e. X := Y + Z.
However, when dealing with something polycausal, there’s really multiple ways the influence can go. In the additive example above, Y and Z are independently influencing X, so we can think of this as being a sort of diffusion, where Y and Z can “spread into” X, similar to how heat from different heat sources (e.g. a cup of tea and a fireplace) can spread into a common target (e.g. a cold person).
The other major possibility than addition is multiplication, i.e. X := Y * Z. Here Y and Z are dependent on each other in their influence on X; for instance, you could imagine Y as a skilled entrepreneur, and Z as a market opportunity, and X as a business. The business requires both the entrepreneur and the opportunity.
Linear diffusion of sparse lognormals
Sometimes things interact multiplicatively, generating outcomes that span orders of magnitude. Then these outcomes send their influence out through the world, influencing different things according to the network structure of the world. This influence is mostly diffusion because most things are basically independent of each other. However, occasionally the diffusion crosses into some multiplicative dynamic, which can lead to it suddenly halting or exploding into some extreme outcome, depending on the particulars of the diffusion.
Let’s take a epidemic as an example. There’s an endless number of germs of different species spreading around. Most of them don’t make much difference for us. But occasionally, one of them gains the capacity to spread more rapidly from person to person, which leads to an epidemic. Here, the core factor driving the spread of the disease is the multiplicative interaction between infected and uninfected people, and the key change that changes it from negligible to important is the change in the power of this interaction.
One it has infected someone, it can have further downstream effects, in that it makes them sick and maybe even kills them. (And whether it kills them or not, this sickness is going to have further downstream effects in e.g. interrupting their work.) But these downstream effects are critically different from the epidemic itself, in that they cannot fuel the infection further. Rather, they are directly dependent on the magnitude of people infected.
Properly generalized, this applies to everything in life, from companies to medicine to programming to psychology to physics. I think of it as being closely related to thermodynamics; an extreme outcome is like a low-entropy state (or high-free-energy state), and its influence on the world must mostly be diffusive, because entropy must increase. The occasional appearances of new phenomena cannot be truly out of nowhere, but must be due to an interaction which draws on prior low-entropy high-energy states.
- ^
Psychometrics tend to have quite elaborate philosophy of measurement, probably because psychological measurement tends to be so bad and noisy that there’s a lot of desire for better interpretation of it.
- ^
But also sometimes in latent variable models, a phenomenon known in psychometric circles as “interstitiality”.
I think you’re getting at something fairly close to the Piranha theorem from a different (ecological?) angle.
There’s overlap; the Piranha theorem gives you a tradeoff between frequency and effect size. But it’s missing the part where logarithmic perception means you only care about the rare factors with large effect and not the common factors with small effect.