This post compiles the reactions of others that I have seen to Biden’s Executive Order on AI, including reactions that were based only on the fact sheet, as well as my reactions to those reactions.
Reaction on the worried side was measured. It could best be described as cautious optimism.
Reaction on the unworried side was sometimes measured, but often not measured. It could perhaps be frequently described as unhinged.
It continues to be odd to see so many voices react in such horror to the idea that the government might not ultimately adapt a fully laissez faire approach to AI.
Many of them collectively seem to be, essentially, treating a request for government reports on what might be done in the future, plus some very mild reporting requirements imposed exclusively on a few giant corporations, as if it inevitably means AI, nay computers in general, nay the very core of mathematics itself, will suffer the fate of NEPA or IRBs, a slippery slope of regulatory ratcheting until all hope for the future is extinguished.
I am unusually sympathetic to this view. Such things very much do happen. They very much do often happen slowly. They are indeed strangling much of our civilization. This is all very bad. Pick almost any other hill, everyone involved, where often this is actually already happening and doing great harm, and there are not the massive externalities of potentially everyone on the planet dying, and I would be happy to stand with you.
Alas, no, all that progress energy is focused on the one place where I fear it is deeply misguided. What should be the default viewpoint and voice of reason across the board is silenced everywhere except the one place I wish it was quieter.
I’ll divide the post into three sections. First, the measured reactions, to the fact sheet and then the final executive order. Then those crying out about what can be pried from their cold dead hands.
Vivek Chilukuri: The EO is the Admin’s strongest effort yet to lead by example in the responsible development and deployment of AI, allowing it to go into the UK Summit with a far more fleshed out policy after years of seeing other nations jump out ahead in AI governance.
The Admin’s vision for AI development leans heavily into safety, privacy, civil liberties, and rights. It’s part of an urgent but incomplete effort to offer a democratic alternative for AI development to counter China’s AI model rooted in mass surveillance and social control.
At home, here’s a few ways the EO strengthens US leadership by example:
-Require companies working on advanced AI to share safety tests.
-Develop safety and security standards through NIST
-Guidance for agencies to use AI responsibly
-Support privacy-preserving technologies
Abroad, the EO intensifies US efforts to establish international frameworks, shape international standard setting, and interestingly, promote safe, responsible, and rights-affirming AI development and deployment in other countries.
A note of caution. Going big on an Executive Order is one thing. Getting the execution right is another–especially for federal agencies with an acute shortage of AI expertise. The EO nods to hiring AI experts, but it’s no small task when businesses already struggle to hire.
The establishment of a meaningful compute threshold seems like the biggest game.
David Vorick: New Executive Order is out. Already one notable item: Any AI model that required more than 1e26 floating point operations or 1e23 integer operations to build must report to the government.
Model performance and compute scale are tightly correlated. That could change in the future, but for now, FLOPs remain a highly valid proxy for capability.
Samuel Hammond: Pleasantly surprised the AI EO stuck with a compute threshold. Many will push against this, arguing that regulation should only ever be use-based, but such a threshold will be essentially for delineating AGI / ASI labs for special oversight. This *is* the light-touch approach.
The threshold draws a line for safety testing and disclosures. Emergent capabilities are inherently hard to predict in advance, and thus can’t be regulated on a discrete “use” basis, especially when we’re talking about highly generalist systems, not any one capability.
…
To be clear, no company has yet trained a model with 10^26 FLOPs. Based on Metaculus’s forecast, this particular threshold may not even bind until after 2025.
I strongly agree with this, both that it is important and also that it is the correct move. The big update from this report is that America is going to consider using compute thresholds as a measure for the potential dangers of AI systems. I know of no viable alternatives.
Will Manidis gives the health care section of the final bill a close reading, notes that giving HHS authority over healthcare AI is a broad expansion of its authority, whereas previously it was diffused over FDA, CMS and OCR. Will predicts that HHS will struggle to handle this and there will be trouble. I’d respond that diffusion across four agencies would seem like far more trouble than that.
Katie Link: I think a lot of the EO’s guidance on strengthening security for synthetic biological sequence procurement, as well as the emphasis on evaluation and monitoring of AI models in healthcare settings, are positive developments overall!
But I worry about the negative impact on biological research and open science, and I don’t think the guidelines on open models and datasets meaningfully strengthen our national biosecurity efforts and defense against bioweapon development.
IMO the hardest part about the actual idea → bioweapon pipeline is not the how-to knowledge (can be found online), or even coming up with synthetic sequences via biological models – it’s the actual lab work, which is still really difficult, expensive, slow, and unpredictable.
…
This is a tricky and important subject that I think requires many diverse perspectives, so I’m looking forward to hearing the community’s thoughts as well as ways HF can do better in improving the transparency and positive impact of biology models and datasets
It is reasonable to worry about restrictions on bad things like bioweapons also interfering with the research necessary to defend against them. In this case, the extra security precautions seem well worth the extra time and expense to me – if your project can’t afford to pay those extra costs, it was not so valuable. The restrictions on model registration that she highlights I do not expect to much matter, so what if Google registers the next AlphaFold.
Damek Davis notes one conspicuously unmentioned item. Not only is it not required, I can recall no mention of it as a possibility in any of report requests, although it could come up in some of the privacy or discrimination concerns.
Damek Davis: Absent from new exec order: AI companies must reveal their training set. To develop safe AI, we need to know what the model is trained on. Why aren’t the AI safety orgs advocating for this?
The other things that are conspicuously missing, as is pointed out later, is any mention liability or licensing.
Matthew Yglesias: Thou shalt not make a machine in the likeness of a human mind
Matthew Yglesias: My thought is that it’s probably not a good idea to cover the administration’s AI safety efforts much because if this becomes a high-profile topic it will induce Republicans to oppose it.
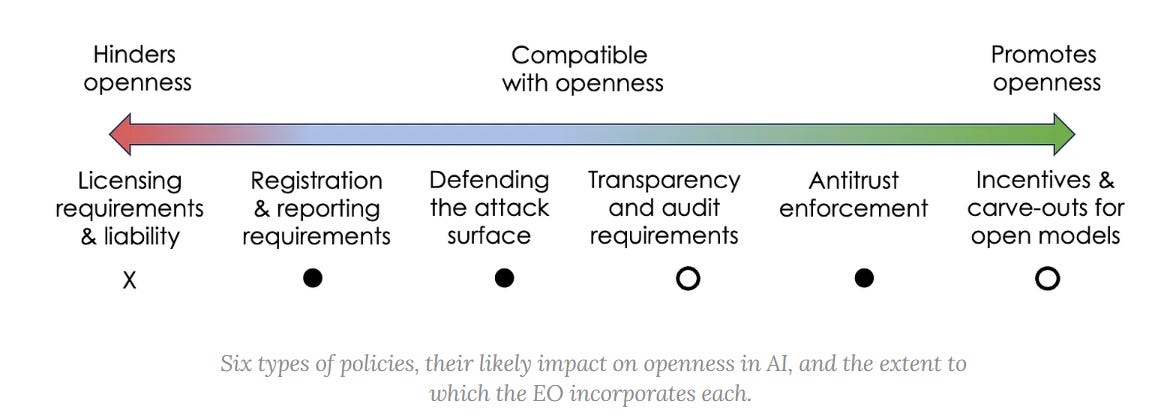
Arvind + Sayash: How will the EO affect the concentration of power and resources in AI? What about the culture of open research?
We cataloged the space of AI-related policies that might impact openness and grouped them into six categories. The EO includes provisions from all but one of these categories. Notably, it does not include licensing requirements. On balance, the EO seems to be good news for those who favor openness in AI.
But the devil is in the details. We will know more as agencies start implementing the EO. And of course, the EO is far from the only policy initiative worldwide that might affect AI openness.
Licensing does seem obviously hostile to openness. It does not have to be that way, depending on implementation details, but that is the usual result.
The idea that liability is anathema to openness implies some odd things, but it is not in the EO, so not relevant here.
They point out that the reporting requirements that kick in at 10^26 flops are well above the threshold of any open source projects so far. If one did want to cross the threshold, how burdensome are the reports? I continue to say, not very, compared to the cost of that much compute. Can anyone point to a hard part? And if you can’t put together the information necessary for the report, I do not trust you to take the other safety measures appropriate to a model of that size.
They approve of the EO’s emphasis on defending attack surfaces, and say they despair of stopping bad actors from being able to access capable AI, to which I have a very ‘not with that attitude’ style of response. I see defending attack surfaces as a great idea on the margin, so we should do it, but if the bad actors (or enough different actors period) get the unrestricted highly capable models at the cutting edge, I have zero idea how that could end non-badly.
One note I appreciated was the idea that even if AI is being unduly blamed for risks like synthetic bio or cybersecurity, that shoring up those attack surfaces was a good idea anyway. I completely agree. We are not yet at the degree of security where AI is required as a justification.
On transparency they note the lack of such requirements. I would say that the EO does require a bunch of transparency over the reporting threshold, but no it does not do so for data or labor. That would really cause various people to blow their gaskets, although perhaps not in a meaningfully different way than they did already. I find such reactions hard to anticipate. I see such transparency as a nice to have relative to other things.
They note that too much AI concentration is listed as a risk, and that antitrust enforcement in the AI space is to be expected. I understand the impulse to favor this, but also it is rather horrifying. Anti-trust rules explicitly prohibit things like agreeing to proceed in a safe fashion rather than racing as fast as possible in the face of existential risks and massive potential externalities, and potentially ensure universal access to AIs that trigger competitive dynamics we cannot survive. Almost no one has faced the music on this.
It is noteworthy the positive attitude held here, by advocates of openness, versus others who think that this EO is a prelude to regulatory capture, monopoly and tyranny.
On the AI development incentives, they rightfully call them out as woefully weak. I found them so weak that I wrote such efforts off as essentially meaningless. What they want here is for the USG not only not to interfere with open source, they want USG to put its hand on the scale to allow open source to keep up with the top companies. I am hopeful that the winds are going in the opposite direction, we very much do not want open source AI models keeping up.
Overall, this is a cautiously optimistic report card on openness. Not only do they not see this is an existential threat to our freedoms or compute, they see the new rules as mild positives for openness, notice that the actions they fear the most were entirely absent, and are disappointed only that the pro-openness actions were not more substantive. Which I agree is a highly reasonable complaint if you want more openness, those provisions were highly weak sauce, but then that was true in general.
Reactions in Horror
For completeness and fairness, I included everyone who came to my attention via my normal channels during the period.
The core reaction:
Kevin Fisher: A sad day for AI.
The line I expect to be the standard hyperbolic talking point:
David Johnston: The government just issued a limit on the amount of Math you are allowed to do in the United States…
I like there being a catchy phrase like this, so people can identify themselves.
The Slippery Compute Slope
The slippery slope argument, which to be clear is usually valid, and is indeed the correct reason to be worried about the Executive Order:
Suhail (Founder Playground AI, pinned tweet is literally “Run your own race”): I think we will ultimately regret that we did this to ourselves.
I am optimistic because hackers are more clever at bending these sort of silly regulations and much faster at reacting to them than the government could ever.
I do not think we need a stop-gap. Regulate applications, not technology.
One day we will have the equivalent of the gpu compute Azure has in an iPhone and this regulation will seem comical to our children.
Where regulation and reporting requirements begin according to the AI EO:
– 50K H100s at fp16 (w interconnect)
– 1.5M H100s at fp32 (w interconnect)
– 414M H100 training hours
Andrew Ng: Laws to ensure AI applications are safe, fair, and transparent are needed. But the White House’s use of the Defense Production Act—typically reserved for war or national emergencies—distorts AI through the lens of security, for example with phrases like “companies developing any foundation model that poses a serious risk to national security.”
…
It’s also a mistake to set reporting requirements based on a computation threshold for model training. This will stifle open source and innovation: (i) Today’s supercomputer is tomorrow’s pocket watch. So as AI progresses, more players — including small companies without the compliance capabilities of big tech — will run into this threshold. (ii) Over time, governments’ reporting requirements tend to become more burdensome.
The right place to regulate AI is at the application layer.
…
While the White House order isn’t currently stifling startups and open source, it seems to be a step in that direction. The devil will be in the details as its implementation gets fleshed out — no doubt with assistance from lobbyists — and I see a lot of risk of missteps. I welcome good regulation to promote responsible AI, and hope the White House can get there.
Jim Fan (Nvidia): The right place to regulate AI is at the APPLICATION layer. Requiring AI apps like healthcare, self-driving, etc. to meet stringent requirements, even pass audits, can ensure safety. But adding burdens to foundation model development unnecessarily slows down AI’s progress.
Regulate actions/outcomes, not the computing process. Here’s an example.
You only need <100M parameters to build a literal killer AI from hell. Download a Mask R-CNN object detector. Train an ethnicity classifier. Mount a gun on Spot robot dog. Pure evil with a fraction of LLMs’ FLOPs.
I’m not saying the EO is all wrong. It’s got well-intentioned guidelines like “red-teaming report”. But today’s super computer will be tomorrow’s pocket watch. It could over-regulate OSS (thus stifle innovation) while under-regulate cases like the above.
I continue to see this line of ‘regulate applications not technology’ as the failure to understand that with sufficiently capable and available AI the technology implies its application. That the existence of an existentially dangerous AI system is existentially dangerous without it needing to be pointed at any applications.
In particular, the idea that you can allow open source models, and then ‘regulate their applications’ in this context, in any meaningful way, does not make sense to me. If you allow the model to exist in open source then anything that can be done with it after modifications, will be done with it. Merely telling people what they are not allowed to do is not going to work. So how would one regulate the application rather than the model?
If you project far enough into the future, giving a sufficiently capable AI a text window that a human will read is more than sufficient to doom us, and we should be worried that even without such a window it will instead find metaphorical buffer overflows or other physical tricks.
Even if you did manage to instead regulate at the application layer, how is that not going to result in a vastly more intrusive monitoring system? You now need to check every command given to every sufficiently general model, lest it be used for a forbidden application. If you target the compute used in training, then you can limit your concern to large concentrations. If you let the models into the wild, you can’t.
Also, almost the entire EO is indeed examining what to do about applications rather than technology. Section 4, especially section 4.2, dealing with future frontier models, rightfully targets the model because there is no alternative. But the later sections are all about particular applications and particular harms.
Andrew Ng’s statement correctly identifies that the EO’s danger lies in what happens if future stages of implementation go poorly, and that as always the devil will be in the details and regulations have a way of not ending up well-aimed. Eventually, yes, if we keep the threshold at 10^26, it will start to apply to more and more processes.
If the entire process stays at ‘tell us what you are doing’ then if someone is indeed building a pocket watch or other obviously safe system, you can (not quite, but more or less) write down ‘using 4.2 x 10^26 FLOPS, at this data center, running the industry standard mundane harms evaluation package’ and be done with it, even if the threshold is not formally raised. Hell, I bet you can get your local fine-tuned version of GPT-5 to write your disclosures for you, why not, no one will read them if there is indeed no danger there.
The risk is that this report greatly expands and other requirements are added over time, in a way that do introduce an undue burden, and that this also applies to a wider range of systems, and also that none of that was actually necessary for safety. That is a possible world. I don’t expect it, but it makes sense to keep an eye.
However I would also caution that it is not obvious that it will be safe to raise this threshold any time soon. Algorithmic efficiency and data will improve rapidly over time, so 10^26 flops is going to continuously buy you more intelligence, and be more dangerous. It is even plausible that we will need to consider lowering, not raising, this threshold, if our goal is to guard against potential new superintelligent systems, either entirely or when lacking the proper safeguards.
At some point, if AI technology advances, the whole point is that we will need to impose costly safety requirements or even outright prohibitions before creating more capable AI models, because the use or later the very existence of such models poses a potential existential threat, and that threat will expand not contract until we at least solve alignment and I believe also solve other problems that creating such systems would cause even if they were aligned. Ultimately, yes, the ability to interfere with AI capabilities is the point.
Paul Graham: I don’t know what the right approach to regulating AI is, but one problem with this particular approach is that it means we’re heading toward the government regulating private individuals’ computing at an exponential rate.
Eli Tyre: What a correct way of phrasing this! I agree with both parts of this statement. I wish our options were better (more effective at preventing extinction, and imposing fewer externalities on people not doing anything dangerous).
Computing power is increasing at an exponential rate. So any move to regulate it at all is also going to have to evolve at an exponential rate if it is to be meaningful.
Paul’s concern is that it is a move to regulate computing power. Which, yes, this is (in part) absolutely a move to lay groundwork for regulating computing power. Which is the only proposed move that could plausibly prevent or substantively low the creation of AGI until such time as it would not result in everyone dying.
Paul Graham wishes that we would find such an alternative that would work, and I do as well. We would love to hear about it. But a lot of very smart highly motivated people have been searching, and this is the best we have found so far by quite a lot. I do not see ‘let anyone scale however much they want with safeguards being fully optional’ as a viable alternative. So what choice do we have other than talking price?
Zvi (on Twitter, other thread): The reward for reading 20k words of an EO that is almost entirely calls for government reports is to read the diatribes about how it is government overreach and full of premature regulations and assumptions, when you spent hours confirming that nope, it’s all report requests.
Nabeel Quereshi: Regulations usually _start out_ reasonable, the (obvious) concern is that they’re a one-way ratchet. See IRBs as an example.
Shea Levy: From most, I’d say this belies naïveté about the purpose and effects of this kind of bureaucracy and suggest that the author review the history or think for five minutes about how a petty power-luster might take advantage of and expand this. Zvi, of course, already knows this.
Maxwell Tabarrok (other thread): Hmm yeah if a law just calls for bureaucrats to prepare reports it can’t be that burdensome. There is no precedent for laws of this nature evolving into unbelievably wasteful time sinks which drain huge swathes of the economy and cripple important technologies.
This does indeed seem to be the full argumento ad absurdum. It is saying that we should never dare ask a government department to write a report on what is happening, might happen in the future or might be done about any of it, lest it be a prelude to tyranny.
Again, that is not, in general, an inherently absurd view. There are places where it would be better if the government never created any reports, so that it is not tempted to ever do anything. One need not affirm a regulation that is net positive as stated, if one expects it to then ratchet up and become negative. But as is the central theme, the only offered alternative is to do actual nothing indefinitely.
Libertarians Gonna Libertarian
Again, reminder, I love you guys, I really do, shame we couldn’t meet anywhere else.
Adam Thierer: The new Biden AI executive order issues broad and quite amorphous calls for expanded government oversight across many other issues and agencies, raising the risk of a “death by a thousand cuts” scenario for AI policy in the US.
The EO appears to be empowering agencies to gradually convert voluntary guidelines into a sort of back-door regulatory regime for AI, a process which would be made easier by the lack of congressional action on AI issues. The danger exists that the U.S. could undermine the policy culture that made our nation a hot-bed of digital innovation and investment. We don’t want to become Europe on tech policy.
Geoffrey Manne: People really miss how important the culture of entrepreneurship is in the U.S. — and how unique it is. The relentless effort to regulate away our superpowers is truly depressing.
Indeed, this order is a call for future oversight, which could indeed lead to maybe telling people that they are not allowed to do some things, or that to do some things they might also have to do other things. Yes, the government might decide it wants to stop certain things from happening, and might do so more often than is ideal. I can confirm that is the point. On some of the points I strongly agree with the need to act, on others I am skeptical. But if you react this way to every single proposed action ever, with the same generic reasoning, your reaction isn’t information.
Reason similarly posts their standard ‘this new proposed regulation can only hurt America.’ I do appreciate them highlighting the invocation of the Defense Production Act. Someone has to point out such things in theory matter. But when the time comes to show what the great harms will be that are going to stifle innovation, they are at a loss, because the whole thing is a list of requirements for an endless set of reports.
R Street’s Adam Thierer writes the required column, and to his credit often chooses his words carefully. Note the ‘threatens to’ in the title, which is: White House Executive Order Threatens to Put AI in a Regulatory Cage.
Adam Thierer: While some will appreciate the whole-of-government approach to AI required by the order, if taken too far, unilateral and heavy-handed administrative meddling in AI markets could undermine America’s global competitiveness and even the nation’s geopolitical security.
Yes, if you take regulation too far, that would be bad. The argument seems to be once again, therefore, no regulation at all, and even no government reports? In general I do have great respect for that position, but it is deeply unworkable here, and is deeply unpopular not only here but in the places it is largely or entirely correct.
I was disappointed that he does not maintain his message discipline throughout, with derisive references to existential risk concerns, starting with ‘scenarios pulled from the plots of dystopian science fiction books and movies’ and getting less respectful from there.
Forbes also pulls out standard tropes.
James Broughel (Forbes): The government’s “regulate first, ask questions later” approach is reminiscent of when Congress created the renewable fuels program in 2005, which increased the ethanol content in gasoline.
Forbes calls the order ‘regulation run amok’ and accuses it of ‘Ready! Fire! Aim!” Except the entire report is ‘Ready! Aim!’ and no Fire. This is the Ask Questions First document, perhaps run amok in the breadth of its questions. At best this is training to run, but still at the starting gate. Where are the overly prescriptive regulations? What is the prescription of which you speak? The ‘stringent regulatory hurdles’ that involve ‘tell people what you are doing’ and only apply to a handful of large corproations? Where are all the ‘assumptions’ in the order?
The best they can come up with was a worry I had as well, that requiring reporting of safety results might discourage testing. On the other side, I would expect having to report all tests to also strongly encourage testing, because otherwise you are conspicuously not reporting any tests.
Ser Jeff Garzik: In re AI EO: This is yet again a familiar pattern of acting first from the executive branch. People naively want a chieftain-king, and Biden admin happily supplies: rule by executive fiat, achieved through arcane legal positioning.
This AI EO feels like a return to the 1990s:
– whitelisted USG Big Corp friends have no limits on GPU cycle count or parameter count.
– plebs must make do with lesser models …
Just like the early 1990s encryption, where 40-bit and below weak encryption was exportable outside the United States.
[Then in response to the Defense Production Act he invokes Godwin’s Law.]
The #AI #EO is another cog in the automated #surveillance and control machine being built. #privacy #OpenSource
This is, once again, many steps ahead of ourselves, except also assuming what he sees as the worst outcome on many different fronts at once. Is this ultimate outcome possible down the line? Is that one way we could implement compute limits? It certainly is possible. Would not be my first choice. But once again, that is not what the EO says. I presume that is how it feels to Jeff because that is his background assumption of what will always happen.
One almost suspects some of these posts were written before they knew what was in the order. Others seem to be reading an entirely different EO, that travelled back in time from a possible 2026.
Attempted Detailed Takedowns
Bindu Reddy offers her usual flavor of thoughts.
Bindu Reddy (CEO AbacusAi): The AI Executive Order is a bit ridiculous and pretty hard to enforce.
Here are the issues –
1. Any foundation model that poses a serious risk to national security – How do you determine if something is a “serious risk to national security!“? If this is about mis-information, Twitter, YouTube and Meta are way more serious risks to national security than harmless AI models that merely generate content, not distribute or amplify it.
I presume that the government intends to do that evaluation itself, the same way it does with any other sort of threat. There is not some technical definition of what is a serious risk to national security, nor does a complete one exist to be found. We use phrases like ‘a clear and present danger’ and ‘probable cause’ to justify government actions.
Right now, I would agree that current models do not present such a threat. My understanding is that the current administration agrees with this.
If a model does not distribute its content in any way, and no one can or does access its outputs, then the model would need to be far more advanced and do some other physical thing to pose a threat to national security. But if there exist people, who are reading the output of the model, then that output can impact those people to do things in physical space, or the information can be utilized or amplified by those people, without any bound. Such a thing could easily pose a threat to national security. Whether or not any given system (e.g. Llama-3 or GPT-5) did so is a fact and physical-world question.
Certainly it would be unwise to say ‘we cannot technically define what is and is not a threat to national security in precise terms thus we should not respond to such threats’ any more than we would say ‘we cannot technically define what is and is not fraud in precise terms thus we should not have laws against fraud.’ Or murder, or anything else.
2. All AI-generated content has to be watermarked? – Seriously!? We may as well kill vision AI, if we actually enforced that. Are Enterprises allowed to use AI to generate images and use them in their marketing?
This is bizarre hyperbole, even if they do ultimately impose watermarking requirements. Yes, of course you are allowed to use AI images for marketing, no this will not kill vision AI. There are tradeoffs, this introduces some marginal costs, and one could argue it is not worthwhile, but I have yet to see an argument for the costs being a big deal, especially given that costs are continuously declining over time, so even a tax that looks big doesn’t ultimately do much if it is a fixed percentage.
3. Some agency is apparently going to develop tests that the AI models have to pass – How will this get enforced? Does every fine-tuned version of any open-source model have to pass these tests? What happens if a model is dropped on HuggingFace by a non-US corporation?
Yes. If there is a test you have to pass then you have to pass it.
Any reasonable regulatory regime is going to require passing some set of tests. A sufficiently capable AI model is going to be able to do things that trigger regulatory scrutiny, one way or another.
Does every fine-tuned version of any open source model have to pass these tests?
We don’t know yet. In an ideal world and in my best guess I would say no unless you are doing very expensive and extensive fine tuning and then releasing the result.
Why? If you release an open source AI, you are also releasing every fine-tuned version of that open source AI. So the original test should cover any potential threat from a (lightly) fine-tuned version, say up to 1% of original compute training costs.
If this means no open source model above some level can ever pass the test? Then you can’t have open source models above that level. That’s the whole point.
What happens if a model is dropped on HuggingFace without passing the tests? Then I would presume they are in violation of American law, and further spreading or using it would also be a violation of American. Where ‘they’ above means both the other company and also HuggingFace, who we have jurisdiction over. It would be the job of such websites to prevent the sharing of illegal models, same as any other illegal software or files one might upload. I am however not a lawyer or legal scholar, and all that.
4. It has a bunch of “privacy” protecting language – All this does is cripple AI models compared to Search where the same “privacy” isn’t being enforced. Google search will recognize a face for me, GPT-4V won’t. It’s not clear why my photo that is in the public domain, can’t be used by AI? We already have privacy protecting laws. These should be sufficient.
I agree that we should treat mandatory privacy protections with skepticism, if they are ultimately implemented. Which, so far, they are not.
The privacy argument and harm argument here, as I understand it, is that the AI could soon be shockingly good at recognizing anyone anywhere as well as locations, while also making mistakes, and also people will create fake images that the AI would identify as being the people they are pretending to be in the places they are pretending to portray, doing the things they are pretending to do, and so on. So if people start using vision AI for identification then this opens up some nasty dynamics.
Do I find this annoying and rather silly? Yeah, I basically do, but I am open to taking a cautious approach here, especially as part of a package of precautions.
It then ends with some “feel good” language around hiring and open-source. Net-net, this order won’t make any difference in the near term.
Could be harmful in the long run to companies who do develop these foundation models, especially vision models. Weirdly, it helps search engines or makes them way more powerful because they are not regulated, while AI models are
. .
. . If anything, this isn’t good for OpenAI
Did you hear that last line, everyone? There will of course be endless complaints that this whole operation is regulatory capture by OpenAI (along with DeepMind and Anthropic and perhaps others). Here is someone, who is very against regulation, saying the order is if anything not good for OpenAI.
Zooming out, what struck to me at the beginning is that this is not just an “AI” executive order, it is infact a retroactive governance regime being imposed on the entire web, while also limiting the future. The term AI is defined so broadly, that it could impact everything from Google search results, to Amazon recommendations, to Yelp restaurant suggestions, to anything else which recommends anything to you. This is the start of the “AI-industrial-complex”, which will now lead to a world of billions of dollars being spent in regulations, compliance and lobbying over the time ahead.
I mean yes the definition of AI here is not good but one I presume that gets fixed, and I will support efforts to get it fixed, and also there is no imposed regime except for reporting requirements above 10^26 flops? Potentially there could be requirements in the future.
This EO is essentially banning fully open source models over 10B parameters, as it requires reporting requirements and “..physical and cybersecurity measures taken to protect those model weights”.
No. It requires that someone involved send an email saying ‘the measures we took to protect these model weights was to post them on Torrent.’
(Also, tens means 20B, not 10B, for what that’s worth, which is not a tiny model.)
If you think that is a bad look when said out loud, or that this is an unacceptable answer… well, that is what it means to be open source.
If this leads to a ban on such models in the future, then yes I would be in favor of that. I mean obviously, if something needs to be secure then you cannot simply give it away to everyone who asks nicely.
Beyond the datacenter clouds, this would also extend to even decentralized networks providing compute, where even the location and total compute has to be reported. To Floyd in Florida running a SETI @ home node searching for extraterrestrial life signals – the government wants to know the precise location of your computer in your basement now…
Yeah, no, that is not what I expect that this means, but if it did GPS can do this for you, the government already had ways to find out, no one forced you to join that and I honestly do not particularly care?
Every time a new regulation passes, there is a class of free software style people who try to figure out exactly what a maximalist interpretation of what this might imply might do if fully enforced and they panic. That is a useful thing for someone to do, but we should not confuse it with what is likely to happen.
Compliance regime for any model which was trained with more than 10^26 floating-point operations (or 0.1 exaflops)
The compliance regime is literally ‘file a report on what you are doing.’ But I certainly hope it leads to this!
Training requests from non-US persons to be submitted. This is like opening a bank account now!
If you are trying to do a full training run that requires a report then I do not think this is much of an additional burden?
I also don’t see why one couldn’t rent a data center somewhere else if your request is lightweight – the concern I actually have here is that business can easily be taken elsewhere.
This is a remarkable regulatory capture exercise, as now the cost of compliance for anyone running a physically co-located datacenter with compute above a threshold now increases
For data centers? I have actual no idea how the requirements here could lead to datacenter regulatory capture. What is the compliance cost that is non-trivial here? That they perform KYC on major customers? That they know where their computers are? I would love if these are our regulatory capture worries, in places where I would worry about regulatory capture.
Models in this regime are basically guilty until proven innocent if they require compute > 0.1 exaflops
Models are found guilty if you do not report that they exist and forced the government to go find them, I suppose. Otherwise, this is pure fiction in terms of the EO.
But in terms of the actual situation? And what I hope is the law a few years down the line? Hell yes, of course capable foundation models are dangerous until proven safe, that is how safety works when you create such things, I have no idea what the sane alternative is.
Tyler Cowen Watch
I’ve covered his links here elsewhere on their full contents, but for full context here are the things he quoted and said about the EO.
Again, I don’t think there is anything to ‘enforce’ here? Not yet anyway.
Agustin Lebron: Even though it’s not a compute cap (just a requirement to register, for now), surely this emboldens competitors to OpenAI/etc? If I think I can build a system up to the cap, then my playing field just got more level.
This will also spur lots of research into sample efficiency again, which IMO is a very good thing. It’s been a research area that has languished for years under the “just throw more flops at it” regime.
Finally, I think the order perversely legitimizes capabilities research by showing the world “Well, the US gov’t thinks capabilities are SO important they’re making orders about it”. More attention, more dollars, more progress.
Overall this is accelerative for AI/AGI IMO.
I don’t know what to say to that, beyond being confused why any of that would change what anyone does. People reacting to USG caring about AI capabilities? All sides should be able to agree USG is playing from behind on that one. Does this actually update anyone? Under this logic, what wouldn’t be accelerative?
Also, for a potentially accelerative document, it sure has a lot of accelerationists really angry. Stay tuned for more of that.
A commentor has a better accelerationist case:
Marcel: I work for a federal agency. Right now at every single federal agency there are people trying to get the agency to approve using AI for some purpose. And there are people saying no way, that’s too risky. The existence of this EO will allow the people trying to bring AI into the government to say “look, the administration is in favor of AI” and in some cases that will win the day.
I am fairly confident this EO will result in greater use of AI by the federal government. Whether that is a good thing depends on your view of the government, I suppose.
Narrowly restricted to the government itself, I agree. This is intended to be, and will be, accelerationist. I do not expect that to result in important capabilities gains, and I’m fine with it. American state capacity is mostly good, actually?
Suhail (Founder, Playground AI): We commit at least $100K to any lawsuit that wants to litigate and get a ruling if a regulatory agency attempts to follow the EO on AI. An EO is not law, yet. We must fight back.
Pls reach out if you can match or do more so we can establish a fund.
This fight extends beyond regulatory capture. If you read between the lines, it’s about who owns the oligopoly of superintelligence of our civilization. Nobody should.
Kevin Fisher (QT of Suhail): I carefully read through the executive order on AI and it’s very clear: it’s a giant document written by OpenAI and a few others outlining a plan for AI to be entirely owned and thought policed by giant corporations with no other alternatives. But there are ways to fight back.
Kevin Fisher (other thread) I don’t think everyone fully appreciates how dire the fight for “code as speech” is.
It’s not academic – the outcome will affect the fabric of our society at fundamental level: do we have freedom of thought or will a few corporations censor or effectively moderate our collective internal dialogue?
Within a few years internal dialog will be externalized through close relationships with AIs powered by language models. We’ve already seen how “safety” limits the ability to explore ideas and concepts on our own terms.
It’s incredibly important that a totally free market is maintained without regulatory distortion to avoid a future where things like “I’m sorry I can’t talk about that” or “You shouldn’t say that” don’t start policing effectively your personal thoughts.
…
Yeah this is one step further: are you free to say something in private? We’re talking about mass surveillance and monitoring of personal and private speech
Colin O’Malley (reply to Suhail): What do find objectionable about this EO? Or do you object to any AI regulation, on principle?
Suhail: Regulating flops is the incorrect strategy.
Again, I ask, then what is the correct strategy?
Kudos, in a strange way, to Suhail and Marc for focusing on the part that matters most. They very much want to ensure people can do the things that I believe will get us all killed. Namely, they want to race to superintelligence as fast as possible, and put it in the hands of everyone at once. Which, again, I very much expect to highly reliably if implemented cause there not to exist, in the physical universe, any humans, and rather quickly. And I am taking a bold stance that I think this is bad.
And they are furious that there might be any sort of future barrier in the way of doing those things as quickly as possible.
I presume their plan is that someone attempts to file a report, and then Suhail’s group will file a lawsuit that says how dare you attempt to file a report? Or maybe OpenAI or Google files a report saying they are training a model, and Suhail somehow finds standing and files a lawsuit to claim they didn’t have to file the report? I have no idea how the actual suit would work here.
Kevin is taking the position that any restriction on code whatsoever is unconstitutional and also incompatible with our freedoms, the alternative is the end of our freedom of thought and speech and a mass surveillance state, and all of this is an OpenAI conspiracy.
It is odd that we both read the same executive order?
On Crying Wolf
I think this is a good summary of all the reactions above:
Jack (MidJourney): yeah the e/acc response to this has been totally unhinged. this EO seems likely to mildly accelerate deployment of existing systems and have negligible effect on development of new ones. If you’re spending $50m on a single training run a single report is nothing.
Unhinged seems exactly right. The people crying wolf will never not cry wolf. What will they say if and when a wolf actually arrives, that is different from what they are saying now? That is a question such types often ask those claiming risk, both fairly and otherwise. It seems fair to turn it back on them here.
Roon steps in as another voice of reason.
Roon: all the executive order says as far as I can tell is that you need to report the existence of a massive compute datacenter don’t you need to report the existence of your car and your home to the government? and have them inspect your restaurant’s kitchen and shit.
this seems kind of a weird thing to freak out over. like they can definitely see it from space and it’s impossible to run one of these without a massive energy footprint.
Brian Chau: The only tangible thing in the Biden executive order seems to be creating a de-facto registry of models and datacenters. Dear lawyer friends: Is any EO authority to make anyone comply with this request?
Flopcaps are basically fine, it’s everything else the biden admin will use the registry for that’s the problem.
As I said, the EO is basically fine. Flopcaps are the most reasonable thing you could be up to and even then its just a reporting flopcap.
Nathan: According to @TheZvi, Biden’s AI order is very light on things that will slow down AI companies unduly. If I understand him correctly the main extra burden falls on bureaucrats to compile reports.
Dave Kasten: I would characterize it as the bureaucratic equivalent of the bartender theatrically rolling up his sleeves before getting ready to bounce a troublemaker.
Indeed may many other things come to pass in the future, after all those reports are filed. There are many of them you may wish to influence. In the meantime, everyone, please do your best to stay sane.
Hm, I think the accelerationists’ horrified and seemingly “disproportionate” reactions are actually commendably wise, given their worldviews? They’re not waiting around for reality to smack them upside the head; they see the first glimmers of a threat, infer the pessimistic trendline, and immediately update all the way to “they may be about to strangle us, there’s still hope of stopping this if we act early, resist with everything we have!”.
Ah, if only they applied this sort of mindset to a certain other matter.
The EO might be a bit more important than seems at a glance. My sense is that the main thing it does isn’t its object-level demands, but the fact that it introduces concepts like “AI models” and “model weights” and “compute thresholds” and “datacenters suitable for training runs” and so on into the framework of the legislation.
That it doesn’t do much with these variables is a secondary matter. What’s important is that it defines them at all, which should considerably lower the bar for defining further functions on these variables, i. e. new laws and regulations.
I think our circles may be greatly underappreciating this factor, accustomed as we are to thinking in such terms. But to me, at least, it seems a bit unreal to see actual government documents talking about “foundation models” in terms of how many “floating-point operations” are used to “train” them.
Coming up with a new fire safety standard for restaurants and passing it is relatively easy if you already have a lot of legislation talking about “restaurants” — if “a restaurant” is a familiar concept to the politicians, if there’s extant infrastructure for tracking the existence of “restaurants” nationwide, etc. It is much harder if your new standard needs to front-load the explanation of what the hell a “restaurant” even is.
By analogy, it’s not unlike academic publishing, where any conclusion (even the extremely obvious ones) that isn’t yet part of some paper can’t be referred to.
This as a general phenomenon (underrating strong responses to crises) was something I highlighted (calling it the Morituri Nolumus Mori) with a possible extension to AI all the way back in 2020. And Stefan Schubert has talked about ‘sleepwalk bias’ even earlier than that as a similar phenomenon.
I think the short explanation as to why we’re in some people’s 98th percentile world so far (and even my ~60th percentile) for AI governance success is that if was obvious to you how transformative AI would be over the next couple of decades in 2021 and yet nothing happened, it seems like governments are just generally incapable.
The fundamental attribution error makes you think governments are just not on the ball and don’t care or lack the capacity to deal with extinction risks, rather than decision makers not understanding obvious-to-you evidence that AI poses an extinction risk. Now that they do understand, they will react accordingly. It doesn’t meant that they will react well necessarily, but they will act on their belief in some manner.
Re. The question of what happens if a non-us model is dropped on Huggingface … presumably hugging face can report to the government “we have done no tests whatsoever” and be compliant with the regulation? (Oh wait maybe not if the originator of the model has actually done some tests but kept then secret). Or later, if there are mandatory tests, huggingface can just run them and report the results to the government.










Hm, I think the accelerationists’ horrified and seemingly “disproportionate” reactions are actually commendably wise, given their worldviews? They’re not waiting around for reality to smack them upside the head; they see the first glimmers of a threat, infer the pessimistic trendline, and immediately update all the way to “they may be about to strangle us, there’s still hope of stopping this if we act early, resist with everything we have!”.
Ah, if only they applied this sort of mindset to a certain other matter.
The EO might be a bit more important than seems at a glance. My sense is that the main thing it does isn’t its object-level demands, but the fact that it introduces concepts like “AI models” and “model weights” and “compute thresholds” and “datacenters suitable for training runs” and so on into the framework of the legislation.
That it doesn’t do much with these variables is a secondary matter. What’s important is that it defines them at all, which should considerably lower the bar for defining further functions on these variables, i. e. new laws and regulations.
I think our circles may be greatly underappreciating this factor, accustomed as we are to thinking in such terms. But to me, at least, it seems a bit unreal to see actual government documents talking about “foundation models” in terms of how many “floating-point operations” are used to “train” them.
Coming up with a new fire safety standard for restaurants and passing it is relatively easy if you already have a lot of legislation talking about “restaurants” — if “a restaurant” is a familiar concept to the politicians, if there’s extant infrastructure for tracking the existence of “restaurants” nationwide, etc. It is much harder if your new standard needs to front-load the explanation of what the hell a “restaurant” even is.
By analogy, it’s not unlike academic publishing, where any conclusion (even the extremely obvious ones) that isn’t yet part of some paper can’t be referred to.
I strongly agree that the significance of the EO is that it establishes concepts for the government to work with.
From the perspective of the e/acc people, it means the beast has caught their scent.
This as a general phenomenon (underrating strong responses to crises) was something I highlighted (calling it the Morituri Nolumus Mori) with a possible extension to AI all the way back in 2020. And Stefan Schubert has talked about ‘sleepwalk bias’ even earlier than that as a similar phenomenon.
https://twitter.com/davidmanheim/status/1719046950991938001
https://twitter.com/AaronBergman18/status/1719031282309497238
I think the short explanation as to why we’re in some people’s 98th percentile world so far (and even my ~60th percentile) for AI governance success is that if was obvious to you how transformative AI would be over the next couple of decades in 2021 and yet nothing happened, it seems like governments are just generally incapable.
The fundamental attribution error makes you think governments are just not on the ball and don’t care or lack the capacity to deal with extinction risks, rather than decision makers not understanding obvious-to-you evidence that AI poses an extinction risk. Now that they do understand, they will react accordingly. It doesn’t meant that they will react well necessarily, but they will act on their belief in some manner.
Re. The question of what happens if a non-us model is dropped on Huggingface … presumably hugging face can report to the government “we have done no tests whatsoever” and be compliant with the regulation? (Oh wait maybe not if the originator of the model has actually done some tests but kept then secret). Or later, if there are mandatory tests, huggingface can just run them and report the results to the government.