QNR prospects are important for AI alignment research
Attention conservation notice: This discussion is intended for readers with an interest in prospects for knowledge-rich intelligent systems and potential applications of improved knowledge representations to AI capabilities and alignment. It contains no theorems.
Abstract
Future AI systems will likely use quasilinguistic neural representations (QNRs) to store, share, and apply large bodies of knowledge that include descriptions of the world and human values. Prospects include scalable stores of “ML-native” knowledge that share properties of linguistic and cognitive representations, with implications for AI alignment concerns that include interpretability, value learning, and corrigibility. If QNR-enabled AI systems are indeed likely, then studies of AI alignment should consider the challenges and opportunities they may present.
1. Background
Previous generations of AI typically relied on structured, interpretable, symbolic representations of knowledge; neural ML systems typically rely on opaque, unstructured neural representations. The concept described here differs from both and falls in the broad category of structured neural representations. It is neither fully novel nor widely familiar and well explored.
The term “quasilinguistic neural representations” (QNRs) will be used to denote vector-attributed graphs with quasilinguistic semantics of kinds that (sometimes) make natural language a useful point of reference; a “QNR-enabled system” employs QNRs as a central mechanism for structuring, accumulating, and applying knowledge. QNRs can be language-like in the sense of organizing (generalizations of) NL words through (generalizations of) NL syntax, yet are strictly more expressive, upgrading words to embeddings[1a] (Figure 1) and syntax trees to general graphs (Figure 2). In prospective applications, QNRs would be products of machine learning, shaped by training, not human design. QNRs are not sharply distinguished from constructs already in use, a point in favor of their relevance to real-world prospects.[1b]
Motivations for considering QNR-enabled systems have both descriptive and normative aspects — both what we should expect (contributions to AI capabilities in general) and what we might want (contributions to AI alignment in particular).[1c] These are discussed in (respectively) Sections 2 and 3.
[1a] For example, embeddings can represent images in ways that would be difficult to capture in words, or even paragraphs (see Figure 1). Embeddings have enormous expressive capacity, yet from a semantic perspective are more computationally tractable than comparable descriptive text or raw images.
[1b] For an extensive discussion of QNRs and prospective applications, see “QNRs: Toward Language for Intelligent Machines”, FHI Technical Report #2021-3, here cited as “QNRs”. A brief introduction can be found here: “Language for Intelligent Machines: A Prospectus”.
[1c] Analogous descriptive and normative considerations are discussed in “Reframing Superintelligence: Comprehensive AI Services as General Intelligence”, FHI Technical Report #2019-1, Section 4.

Figure 1: Generalizing semantic embeddings. Images corresponding to points in a two-dimensional grid in a high-dimensional space of face embeddings. Using text to describe faces and their differences in a high-dimensional face-space (typical dimensionalities are on the rough order of 100) would be difficult, and we can expect a similar gap in expressive capacity between embeddings and text in semantic domains where rich denotations cannot be so readily visualized or (of course) described. Image from Deep Learning with Python (2021).
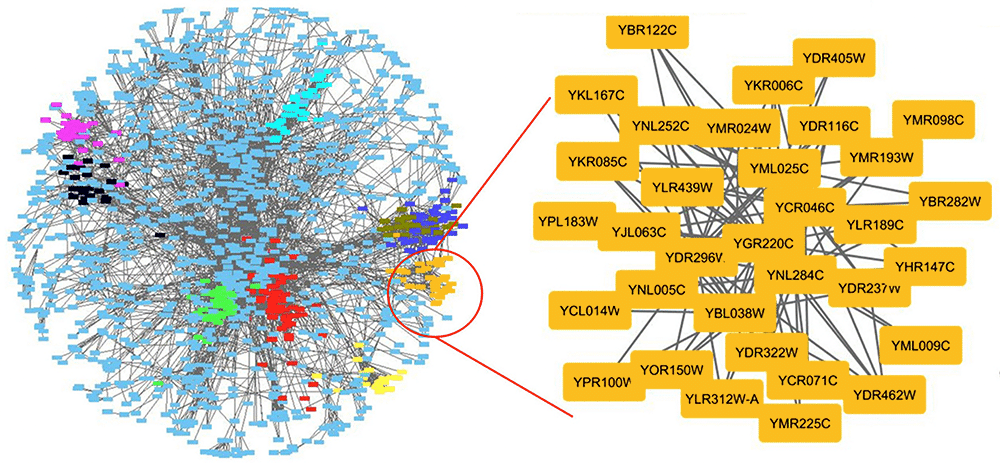
Figure 2: Generalizing semantic graphs. A graph of protein-protein interactions in yeast cells; proteins can usefully be represented by embeddings (see, for example, “Sequence-based prediction of protein-protein interactions: a structure-aware interpretable deep learning model” (2021)). Image source: “A Guide to Conquer the Biological Network Era Using Graph Theory” (2020). Analogous graphs are perhaps typical of quasilinguistic, ML-native representations of the world, but have a kind of syntax and semantics that strays far from NL. Attaching types or other semantic information to links is natural within a generalized QNR framework.
2. Prospective support for AI capabilities
Multiple perspectives converge to suggest that QNR-enabled implementations of knowledge-rich systems are a likely path for AI development, and taken as a whole can help clarify what QNR-enabled systems might be and do. If QNR-enabled systems are likely, then they are important to problems of AI alignment both as challenges and as solutions. Key aspects include support for efficient scaling, quasi-cognitive content, cumulative learning, semi-formal reasoning, and knowledge comparison, correction, and synthesis.
2.1 Efficient scaling of GPT-like functionality
The cost and performance of language models has increased with scale, for example, from BERT (with 340 million parameters)[2.1a] to GPT-3 (with 175 billion parameters)[2.1b]; the computational cost of a training run on GPT-3 is reportedly in the multi-million-dollar range. Large language models encode not only linguistic skills, but remarkable amounts of detailed factual knowledge, including telephone numbers, email addresses, and the first 824 digits of pi.[2.1c] They are also error-prone and difficult to correct.[2.1d]
The idea that detailed knowledge (for example, of the 824th digit of pi) is best encoded, accurately and efficiently, by gradient descent on a trillion-parameter model is implausible. A natural alternative is to enable retrieval from external stores of knowledge indexed by embeddings and accessed through similarity search, and indeed, recent publications describe Transformer-based systems that access external stores of NL content using embeddings as keys.[2.1e] Considering the complementary capabilities of parametric models and external stores, we can expect to see a growing range of systems in which extensive corpora of knowledge are accessed from external stores, while intensively used skills and commonsense knowledge are embodied in neural models.[2.1f]
…And so we find a natural role for QNR stores (as potential upgrades of NL stores), here viewed from the perspective of state-of-the-art NLP architectures.
[2.1a] “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding” (2018).
[2.1b] “Language Models are Few-Shot Learners” (2020).
[2.1c] “Extracting training data from large language models” (2021).
[2.1d] Factual accuracy is poor even on simple questions, and it would be beyond challenging to train a stand-alone language model to provide reliable, general, professional-level knowledge that embraced (for example) number theory, organic chemistry, and academic controversies regarding the sociology, economics, politics, philosophies, origins, development, and legacy of the Tang dynasty.
[2.1e] Indexing and retrieving content from Wikipedia is a popular choice. Examples are described in “REALM: Retrieval-Augmented Language Model Pre-Training” (2020), “Augmenting Transformers with KNN-Based Composite Memory for Dialog” (2020), and “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks” (2021). In a paper last month, “Improving language models by retrieving from trillions of tokens” (2022), DeepMind described a different, large-corpus-based approach, exhibiting performance comparable to GPT-3 while using 1⁄25 as many parameters. In another paper last month, Google reported a system that uses text snippets obtained by an “information retrieval system” that seems similar to Google Search (“LaMDA: Language Models for Dialog Applications” (2022)).
[2.1f] Current work shows that parametric models and external stores can represent overlapping semantic content; stores based on QNRs can deepen this relationship by providing overlapping semantic representations. Local QNR structures could correspond closely to graph network states, and standard Transformers in effect operate on fully connected graphs.
2.2 Quasi-cognitive memory
Human memory-stores can be updated by single-shot experiences that include reading journal articles. Our memory-stores include neural representations of things (entities, relationships, procedures…) that are compositional in that they may be composed of multiple parts,[2.2a] and we can retrieve these representations by associative mechanisms. Memories may or may not correspond closely to natural-language expressions — some represent images, actions, or abstractions that one may struggle to articulate. Thus, aspects of human memory include:
• Components with neural representations (much like embeddings)
• Connections among components (in effect, graphs)
• Single-shot learning (in effect, writing representations to a store)
• Retrieval by associative memory (similar to similarity search)[2.2b]
…And so we again find the essential features of QNR stores, here viewed from the perspective of human memory.
[2.2a] Compositionality does not exclude multi-modal representations of concepts, and (in the neurological case) does not imply cortical localization (“Semantic memory: A review of methods, models, and current challenges” (2020)). Rule representations also show evidence of compositionality (“Compositionality of Rule Representations in Human Prefrontal Cortex” (2012)). QNRs, Section 4.3, discusses various kinds and aspects of compositionality, a term with different meanings in different fields.
[2.2b] Graphs can be modeled in an associative memory store, but global similarity search is ill-suited to representing connections that bind components together, for example, the components of constructs like sentences or paragraphs. To the extent that connections can be represented by computable relationships among embeddings, the use of explicit graph representations can be regarded as a performance optimization.
2.3 Contribution to shared knowledge
To achieve human-like intellectual competence, machines must be fully literate, able not only to learn by reading, but to write things worth retaining as contributions to shared knowledge. A natural language for literate machines, however, is unlikely to resemble a natural language for humans. We typically read and write sequences of tokens that represent mouth sounds and imply syntactic structures; a machine-native representation would employ neural embeddings linked by graphs.[2.3a] Embeddings strictly upgrade NL words; graphs strictly upgrade NL syntax. Together, graphs and embeddings strictly upgrade both representational capacity and machine compatibility.
…And so again we find the features of QNR content, here emerging as a natural medium for machines that build and share knowledge.[2.3b]
[2.3a] QNRs, Section 10, discusses potential architectures and training methods for QNR-oriented models, including proposals for learning quasilinguistic representations of high-level abstractions from NL training sets (some of these methods are potentially applicable to training conventional neural models).
[2.3b] Note that this application blurs differences between individual, human-like memory and shared, internet-scale corpora. Similarity search (≈ associative memory) scales to billions of items and beyond; see “Billion-scale similarity search with GPUs” (2017) and “Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba” (2018). Retrieval latency in RETRO (“Improving language models by retrieving from trillions of tokens” (2022)) is 10 ms.
2.4 Formal and informal reasoning
Research in neurosymbolic reasoning seeks to combine the strengths of structured reasoning with the power of neural computation. In symbolic representations, syntax encodes graphs over token-valued nodes, but neural embeddings are, of course, strictly more expressive than tokens (note that shared nodes in DAGs can represent variables). Indeed, embeddings themselves can express mutual relationships,[2.4a] while reasoning with embeddings can employ neural operations beyond those possible in symbolic systems.
Notions of token-like equality can be generalized to measures of similarity between embeddings, while unbound variables can be generalized to refinable values with partial constraints. A range of symbolic algorithms, including logical inference, have continuous relaxations that operate on graphs and embeddings.[2.4b] These relaxations overlap with pattern recognition and informal reasoning of the sort familiar to humans.
…And so we find a natural role for graphs over embeddings, now as a substrate for quasi-symbolic reasoning.[2.4c]
[2.4a] For example, inference on embeddings can predict edges for knowledge-graph representations; see “Neuro-symbolic representation learning on biological knowledge graphs” (2017), “RotatE: Knowledge Graph Embedding by Relational Rotation in Complex Space” (2019), and “Knowledge Graph Embedding for Link Prediction: A Comparative Analysis” (2021).
[2.4b] See, for example, “Beta Embeddings for Multi-Hop Logical Reasoning in Knowledge Graphs” (2020) and systems discussed in QNRs, Section A1.4.
[2.4c] Transformer-based models have shown impressive capabilities in the symbolic domains of programming and mathematics (see “Evaluating Large Language Models Trained on Code” (2021) and “A Neural Network Solves and Generates Mathematics Problems by Program Synthesis” (2022)). As with the overlapping semantic capacities of parametric models and external stores (Section 1, above), the overlapping capabilities of pretrained Transformers and prospective QNR-oriented systems suggest prospects for their compatibility and functional integration. The value of attending to and updating structured memories (perhaps mapped to and from graph neural networks; see “Graph Neural Networks Meet Neural-Symbolic Computing: A Survey and Perspective” (2021)) presumably increases with the scale and computational depth of semantic content.
2.5 Knowledge accumulation, revision, and synthesis
The performance of current ML systems is challenged by faulty information (in need of recognition and marking or correction) and latent information (where potentially accessible information may be implied — yet not provided — by inputs). These challenges call for comparing semantically related or overlapping units of information, then reasoning about their relationships in order to construct more reliable or complete representations, whether of a thing, a task, a biological process, or a body of scientific theory and observations.[2.5a] This functionality calls for structured representations that support pattern matching, reasoning, revision, synthesis and recording of results for downstream applications.
Relationships among parts are often naturally represented by graphs, while parts themselves are often naturally represented by embeddings, and the resulting structures are natural substrates for the kind of reasoning and pattern matching discussed above. Revised and unified representations can be used in an active reasoning process or stored for future retrieval.[2.5b]
…And so again we find a role for graphs over embeddings, now viewed from the perspective of refining and extending knowledge.
[2.5a] Link completion in knowledge graphs illustrates this kind of process.
[2.5b] For a discussion of potential applications at scale, see QNRs, Section 9. Soft unification enables both pattern recognition and combination; see discussion in QNRs, Section A.1.4.
In light of potential contributions to AI scope and functionality discussed above, it seems likely that QNR-enabled capabilities will be widespread in future AI systems, and unlikely that QNR functionality will be wholly unavailable. If QNR-enabled capabilities are likely to be widespread and relatively easy to develop, then it will be important to consider challenges that may arise from AI development marked by broadly capable, knowledge rich systems. If QNR functionality is unlikely to be unavailable, then it will be important to consider how that functionality might help solve problems of AI alignment, in part through differential technology development.
3. Prospective support for AI alignment
Important considerations for AI alignment include interpretability, value learning, and corrigibility in support of strategies for improving behavioral alignment.
3.1 Support for interpretability
In a particularly challenging range of scenarios, AI systems employ opaque representations of knowledge and behaviors that can be understood only though their inputs and outputs. While QNR representations could be opaque, their inherent inductive bias (perhaps intentionally strengthened by training and regularization) should tend to produce relatively compositional, interpretable representations: Embeddings and subgraphs will typically represent semantic units with distinct meanings that are composed into larger units by distinct relationships.[3.1a]
In some applications, QNR expressions could closely track the meanings of NL expressions,[3.1b] making interpretability a matter of lossy QNR → NL translation. In other applications, QNR expressions will be “about something” that can be — at least in outline — explained (diagrammed, demonstrated) in ways accessible to human understanding. In the worst plausible case, QNR expressions will be about recognizable topics (stars, not molecules; humans, not trees), yet substantially opaque in their actual content.[3.1c] Approaches to interpretability that can yield some understanding of opaque neural models seem likely to yield greater understanding when applied to QNR-based systems.
[3.1a] Note that graph edges can carry attributes (types or embeddings), while pairs of embeddings can themselves encode interpretable relationships (as with protein-protein interactions).
[3.1b] For example, QNR semantics could be shaped by NL → NL training tasks that include autoencoding and translation. Interpretable embeddings need not correspond closely to words or phrases: Their meanings may instead correspond to extended NL descriptions, or (stretching the concept of interpretation beyond language per se) may correspond to images or other human-comprehensible but non-linguistic representations.
[3.1c] This property (distinguishability of topics) should hold at some level of semantic granularity even in the presence of strong ontological divergence. For a discussion of the general problem, see the discussion of ontology identification in “Eliciting Latent Knowledge” (2022).
3.2 Support for value learning
Many of the anticipated challenges of aligning agents’ actions with human intentions hinge on the anticipated difficulty of learning human preferences. However, systems able to read, interpret, integrate, and generalize from large corpora of human-generated content (history, news, fiction, science fiction, legal codes, court records, philosophy, discussions of AI alignment...) could support the development of richly informed models of human law and ethical principles, together with predictive models of general human concerns and preferences that reflect ambiguities, controversies, partial ordering, and inconsistencies.[3.2a]
[3.2a] Along lines suggested by Stuart Russell; see discussion in “Reframing Superintelligence: Comprehensive AI Services as General Intelligence”, Section 22. Adversarial training is also possible: Humans can present hypotheticals and attempt to provoke inappropriate responses; see the use of “adversarial-intent conversations” in “LaMDA: Language Models for Dialog Applications” (2022).
Training models using human-derived data of the sort outlined above should strongly favor ontological alignment; for example, one could train predictive models of (human descriptions of actions and states) → (human descriptions of human reactions).[3.2b] It should go without saying that this approach raises deep but familiar questions regarding the relationship between what people say, what they mean, what they think, what they would think after deeper, better-informed reflection, and so on.
[3.2b] Online sources can provide massive training data of this sort — people enjoy expressing their opinions. Note that this general approach can strongly limit risks of agent-like manipulation of humans during training and application: An automatically curated training set can inform a static but provisional value model for external use.
3.3 Support for corrigibility
Reliance on external, interpretable stores should facility corrigibility.[3.3a] In particular, if distinct entities, concepts, rules, etc., have (more or less) separable, interpretable representations, then identifying and modifying those representations may be practical, a process like (or not entirely unlike) editing a set of statements. In particular, reliance by diverse agents on (portions of) shared, external stores[3.3b] can enable revision by means that are decoupled from the experiences, rewards, etc., of the agents affected. In other words, agents can act based on knowledge accumulated and revised by other sources; to the extent that this knowledge is derived from science, history, sandboxed experimentation, and the like, learning can be safer and more effective than it might be if conducted by (for example) independent RL agents in the wild learning to optimize a general reward function.[3.3c] Problems of corrigibility should be relatively tractable in agents guided by relatively interpretable, editable, externally-constructed knowledge representations.
[3.3a] “A corrigible agent is one that doesn’t interfere with what we would intuitively see as attempts to ‘correct’ the agent, or ‘correct’ our mistakes in building it; and permits these ‘corrections’ despite the apparent instrumentally convergent reasoning saying otherwise.” “Corrigibility”, AI Alignment Forum.
[3.3b] A system can “rely on a store” without constantly consulting it: A neural model can distill QNR content for use in common operations. For an example of this general approach, see the (knowledge graph) → (neural model) training described in “Symbolic Knowledge Distillation: from General Language Models to Commonsense Models” (2021).
[3.3c] Which seems like a bad idea.
3.4 Support for behavioral alignment
In typical problem-cases for AI alignment, a central difficulty is to provide mechanisms that would enable agents to assess human-relevant aspects of projected outcomes of candidate actions — in other words, mechanisms that would enable agents to take account of human concerns and preferences in choosing among those actions. Expressive, well-informed, corrigible, ontologically aligned models of human values could provide such mechanisms, and the discussion above suggests that QNR-enabled approaches could contribute to their development and application.[3.4a]
[3.4a] Which seems like a good idea.
4. Conclusion
AI systems likely will (or readily could) employ quasilinguistic neural representations as a medium for learning, storing, sharing, reasoning about, refining, and applying knowledge. Attractive features of QNR-enabled systems could include affordances for interpretability and corrigibility with applications to value modeling and behavioral alignment.[4a]
• If QNR-enabled capabilities are indeed likely, then they are important to understanding prospective challenges and opportunities for AI alignment, calling for exploration of possible worlds that would include these capabilities.
• If QNR-enabled capabilities are at least accessible, then they should be studied as potential solutions to key alignment problems and are potentially attractive targets for differential technology development.
The discussion here is, of course, adjacent to a wide range of deep, complex, and potentially difficult problems, some familiar and others new. Classic AI alignment concerns should be revisited with QNR capabilities in mind.
[4a] Perhaps better approaches will be discovered. Until then, QNR-enabled systems could provide a relatively concrete model of some of what those better approaches might enable.
- Review of AI Alignment Progress by (7 Feb 2023 18:57 UTC; 72 points)
- Voting Results for the 2022 Review by (2 Feb 2024 20:34 UTC; 57 points)
- QNR Prospects by (16 Jul 2022 2:03 UTC; 40 points)
- Review: LOVE in a simbox by (27 Nov 2022 17:41 UTC; 32 points)
- Safety-First Agents/Architectures Are a Promising Path to Safe AGI by (6 Aug 2023 8:02 UTC; 13 points)
- Cooperation with and between AGI\’s by (7 Jul 2022 16:45 UTC; 10 points)
- Safety-First Agents/Architectures Are a Promising Path to Safe AGI by (EA Forum; 6 Aug 2023 8:00 UTC; 6 points)
- 's comment on Estimating Brain-Equivalent Compute from Image Recognition Algorithms by (27 Feb 2022 3:19 UTC; 5 points)
- 's comment on Alignment research exercises by (22 Feb 2022 20:24 UTC; 4 points)
- 's comment on Some for-profit AI alignment org ideas by (14 Dec 2023 16:32 UTC; 3 points)
- Notes on the importance and implementation of safety-first cognitive architectures for AI by (11 May 2023 10:03 UTC; 3 points)
- 's comment on Agenty AGI – How Tempting? by (3 Jul 2022 1:52 UTC; 2 points)
- 's comment on How to Control an LLM’s Behavior (why my P(DOOM) went down) by (2 Dec 2023 6:11 UTC; 1 point)
I’m reaffirming my relatively long review of Drexler’s full QNR paper.
Drexler’s QNR proposal seems like it would, if implemented, guide AI toward more comprehensible systems. It might modestly speed up capabilities advances, while being somewhat more effective at making alignment easier.
Alas, the full paper is long, and not an easy read. I don’t think I’ve managed to summarize its strengths well enough to persuade many people to read it.