Long-time lurker (c. 2013), recent poster. I also write on the EA Forum.
Mo Putera
Karma: 1,219
I was initially excited by the raw intelligence of o3, but after using it for mini-literature reviews of quantitative info (which I do a fair bit of for work) I was repeatedly boggled by how often it would just hallucinate numbers like “14% market penetration”, followed immediately by linked citations to papers/reports etc which did not in fact contain “14%” or whatever; in fact this happened for the first 3 sources I spot-checked for a single response, after which I deemed it pointless to continue. I thought RAG was supposed to make this a solved problem? None of the previous SOTA models I tried out had this issue.
Thought it would be useful to pull out your plot and surrounding text, which seemed cruxy:
At first glance, the job of a scientist might seem like it leans very heavily on abstract reasoning… In such a world, AIs would greatly accelerate R&D before AIs are broadly deployed across the economy to take over more common jobs, such as retail workers, real estate agents, or IT professionals. In short, AIs would “first automate science, then automate everything else.”
But this picture is likely wrong. In reality, most R&D jobs require much more than abstract reasoning skills. … To demonstrate this, we used GPT-4.5 to label tasks across 12 common R&D occupations into one of three categories, depending on whether it thinks the task can be performed using only abstract reasoning skills, whether it requires complex computer-use skills (but not physical presence), or whether it one needs to be physically present to complete the task. See this link to our conversation with GPT-4.5 to find our methodology and results.
This plot reveals a more nuanced picture of what scientific research actually entails. Contrary to the assumption that research is largely an abstract reasoning task, the reality is that much of it involves physical manipulation and advanced agency. To fully automate R&D, AI systems likely require the ability to autonomously operate computer GUIs, coordinate effectively with human teams, possess strong executive functioning skills to complete highly complex projects over long time horizons, and manipulate their physical environment to conduct experiments.
Yet, by the time AI reaches the level required to fully perform this diverse array of skills at a high level of capability, it is likely that a broad swath of more routine jobs will have already been automated. This contradicts the notion that AI will “first automate science, then automate everything else.” Instead, a more plausible prediction is that AI automation will first automate a large share of the general workforce, across a very wide range of industries, before it reaches the level needed to fully take over R&D.
I think this essay is going to be one I frequently recommend to others over the coming years, thanks for writing it.
But in the end, deep in the heart of any bureaucracy, the process is about responsibility and the ways to avoid it. It’s not an efficiency measure, it’s an accountability management technique.
This vaguely reminded me of what Ivan Vendrov wrote in Metrics, Cowardice, and Mistrust. Ivan began by noting that “companies optimizing for simple engagement metrics aren’t even being economically rational… so why don’t they?” It’s not because “these more complex things are hard to measure”, if you think about it. His answer is cowardice and mistrust, which lead to the selection of metrics “robust to an adversary trying to fool you”:
But the other reason we use metrics, sadly much more common, is due to cowardice (sorry, risk-aversion) and mistrust.
Cowardice because nobody wants to be responsible for making a decision. Actually trying to understand the impact of a new feature on your users and then making a call is an inherently subjective process that involves judgment, i.e. responsibility, i.e. you could be fired if you fuck it up. Whereas if you just pick whichever side of the A/B test has higher metrics, you’ve successfully outsourced your agency to an impartial process, so you’re safe.
Mistrust because not only does nobody want to make the decision themselves, nobody even wants to delegate it! Delegating the decision to a specific person also involves a judgment call about that person. If they make a bad decision, that reflects badly on you for trusting them! So instead you insist that “our company makes data driven decisions” which is a euphemism for “TRUST NO ONE”. This works all the way up the hierarchy—the CEO doesn’t trust the Head of Product, the board members don’t trust the CEO, everyone insists on seeing metrics and so metrics rule.
Coming back to our original question: why can’t we have good metrics that at least try to capture the complexity of what users want? Again, cowardice and mistrust. There’s a vast space of possible metrics, and choosing any specific one is a matter of judgment. But we don’t trust ourselves or anyone else enough to make that judgment call, so we stick with the simple dumb metrics.
This isn’t always a bad thing! Police departments are often evaluated by their homicide clearance rate because murders are loud and obvious and their numbers are very hard to fudge. If we instead evaluated them by some complicated CRIME+ index that a committee came up with, I’d expect worse outcomes across the board.
Nobody thinks “number of murders cleared” is the best metric of police performance, any more than DAUs are the best metric of product quality, or GDP is the best metric of human well-being. However they are the best in the sense of being hardest to fudge, i.e. robust to an adversary trying to fool you. As trust declines, we end up leaning more and more on these adversarially robust metrics, and we end up in a gray Brezhnev world where the numbers are going up, everyone knows something is wrong, but the problems get harder and harder to articulate.
His preferred solution to counteracting this tendency to use adversarially robust but terrible metrics is to develop an ideology to promote mission alignment:
A popular attempt at a solution is monarchy. … The big problem with monarchy is that it doesn’t scale. …
A more decentralized and scalable solution is developing an ideology: a self-reinforcing set of ideas nominally held by everyone in your organization. Having a shared ideology increases trust, and ideologues are able to make decisions against the grain of natural human incentives. This is why companies talk so much about “mission alignment”, though very few organizations can actually pull off having an ideology: when real sacrifices need to be made, either your employees or your investors will rebel.
While his terminology feels somewhat loaded, I thought it natural to interpret all your examples of people breaking rules to get the thing done in mission alignment terms.
Another way to promote mission alignment is some combination of skilful message compression and resistance to proxies, which Eugene Wei wrote about in Compress to impress about Jeff Bezos (monarchy in Ivan’s framing above). On the latter, quoting Bezos:
As companies get larger and more complex, there’s a tendency to manage to proxies. This comes in many shapes and sizes, and it’s dangerous, subtle, and very Day 2.
A common example is process as proxy. Good process serves you so you can serve customers. But if you’re not watchful, the process can become the thing. This can happen very easily in large organizations. The process becomes the proxy for the result you want. You stop looking at outcomes and just make sure you’re doing the process right. Gulp. It’s not that rare to hear a junior leader defend a bad outcome with something like, “Well, we followed the process.” A more experienced leader will use it as an opportunity to investigate and improve the process. The process is not the thing. It’s always worth asking, do we own the process or does the process own us? In a Day 2 company, you might find it’s the second.I wonder how all this is going to look like in a (soonish?) future where most of the consequential decision-making has been handed over to AIs.
This, in the end, was what motivated me to reintroduce “Critique Claude”/”Guide Gemini”/”Oversight o3″.[3] That is, a secondary model call that occurs on context summary whose job it is to provide hints if the model seems stuck, and which is given a system prompt specifically for this purpose. It can be told to look for telltale signs of common fail-states and attempt to address then, and can even be given “meta” prompting about how to direct the other model.
Funnily enough this reminded me of pair programming.
I do think it’d be useful for the rest of us if you put them in a comment. :)
(FWIW I resonated with your motivation, but also think your suggestions fail on the practical grounds jenn mentioned, and would hence on net harm the people you intend to help.)
Terry Tao recently wrote a nice series of toots on Mathstodon that reminded me of what Bill Thurston said:
1. What is it that mathematicians accomplish?
There are many issues buried in this question, which I have tried to phrase in a way that does not presuppose the nature of the answer.
It would not be good to start, for example, with the question
How do mathematicians prove theorems?
This question introduces an interesting topic, but to start with it would be to project two hidden assumptions: (1) that there is uniform, objective and firmly established theory and practice of mathematical proof, and (2) that progress made by mathematicians consists of proving theorems. It is worthwhile to examine these hypotheses, rather than to accept them as obvious and proceed from there.
The question is not even
How do mathematicians make progress in mathematics?
Rather, as a more explicit (and leading) form of the question, I prefer
How do mathematicians advance human understanding of mathematics?
This question brings to the fore something that is fundamental and pervasive: that what we are doing is finding ways for people to understand and think about mathematics.
The rapid advance of computers has helped dramatize this point, because computers and people are very different. For instance, when Appel and Haken completed a proof of the 4-color map theorem using a massive automatic computation, it evoked much controversy. I interpret the controversy as having little to do with doubt people had as to the veracity of the theorem or the correctness of the proof. Rather, it reflected a continuing desire for human understanding of a proof, in addition to knowledge that the theorem is true.
On a more everyday level, it is common for people first starting to grapple with computers to make large-scale computations of things they might have done on a smaller scale by hand. They might print out a table of the first 10,000 primes, only to find that their printout isn’t something they really wanted after all. They discover by this kind of experience that what they really want is usually not some collection of “answers”—what they want is understanding.
Tao’s toots:
In the first millennium CE, mathematicians performed the then-complex calculations needed to compute the date of Easter. Of course, with our modern digital calendars, this task is now performed automatically by computers; and the older calendrical algorithms are now mostly of historical interest only.
In the Age of Sail, mathematicians were tasked to perform the intricate spherical trigonometry calculations needed to create accurate navigational tables. Again, with modern technology such as GPS, such tasks have been fully automated, although spherical trigonometry classes are still offered at naval academies, and ships still carry printed navigational tables in case of emergency instrument failures.
During the Second World War, mathematicians, human computers, and early mechanical computers were enlisted to solve a variety of problems for military applications such as ballistics, cryptanalysis, and operations research. With the advent of scientific computing, the computational aspect of these tasks has been almost completely delegated to modern electronic computers, although human mathematicians and programmers are still required to direct these machines. (1/3)
Today, it is increasingly commonplace for human mathematicians to also outsource symbolic tasks in such fields as linear algebra, differential equations, or group theory to modern computer algebra systems. We still place great emphasis in our math classes on getting students to perform these tasks manually, in order to build a robust mathematical intuition in these areas (and to allow them to still be able to solve problems when such systems are unavailable or unsuitable); but once they have enough expertise, they can profitably take advantage of these sophisticated tools, as they can use that expertise to perform a number of “sanity checks” to inspect and debug the output of such tools.
With the advances in large language models and formal proof assistants, it will soon become possible to also automate other tedious mathematical tasks, such as checking all the cases of a routine but combinatorially complex argument, searching for the best “standard” construction or counterexample for a given inequality, or performing a thorough literature review for a given problem. To be usable in research applications, though, enough formal verification will need to be in place that one does not have to perform extensive proofreading and testing of the automated output. (2/3)
As with previous advances in mathematics automation, students will still need to know how to perform these operations manually, in order to correctly interpret the outputs, to craft well-designed and useful prompts (and follow-up queries), and to able to function when the tools are not available. This is a non-trivial educational challenge, and will require some thoughtful pedagogical design choices when incorporating these tools into the classroom. But the payoff is significant: given that such tools can free up the significant fraction of the research time of a mathematician that is currently devoted to such routine calculations, a student trained in these tools, once they have matured, could find the process of mathematical research considerably more efficient and pleasant than it currently is today. (3/3)
That said, while I’m not quite as bullish as some folks who think FrontierMath Tier 4 problems may fall in 1-2 years and mathematicians will be rapidly obsoleted thereafter, I also don’t think Tao is quite feeling the AGI here.
Out of curiosity, can you share a link to Gemini 2.5 Pro’s response?
re: your last remark, FWIW I think a lot of those writings you’ve seen were probably intuition-pumped by this parable of Eliezer’s, to which I consider titotal’s pushback the most persuasive.
I saw someone who was worried that AI was gonna cause real economic trouble soon by replacing travel agents. But the advent of the internet made travel agents completely unnecessary, and it still only wiped out half the travel agent jobs. The number of travel agents has stayed roughly the same since 2008!
This reminds me of Patrick McKenzie’s tweet thread:
Technology-driven widespread unemployment (“the robots will take all the jobs”) is, like wizards who fly spaceships, a fun premise for science fiction but difficult to find examples for in economic history. (The best example I know is for horses.)
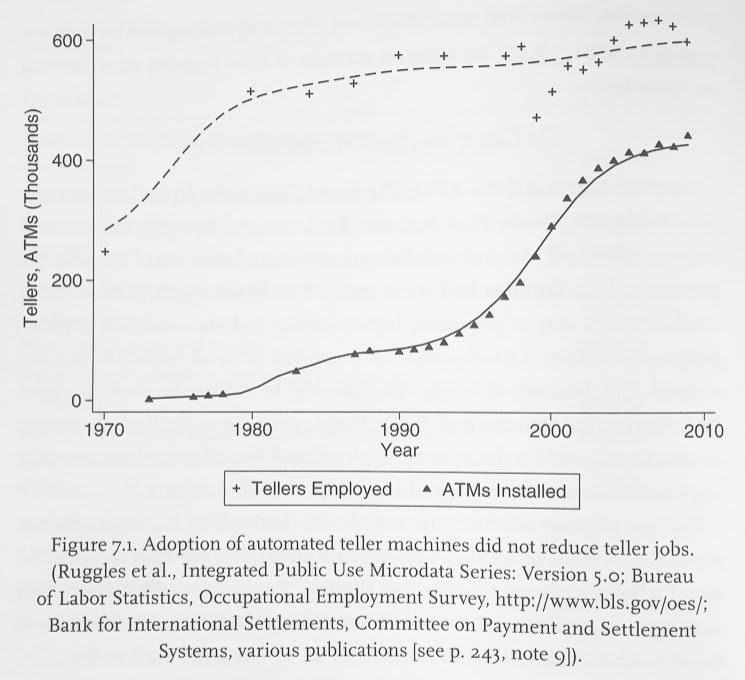
I understand people who are extremely concerned by it, but I think you need a theory for it which successfully predicts bank teller employment trends over the last 50 years prior to justifying the number of column inches it gets.
“Haha Patrick you’re not going to tell me bank teller employment is up since we made a machine literally called Automated Teller Machine are you.” Bessen, 2015:
“Wait why did that happen?” Short version: the ATM makes each bank branch need less tellers to operate at a desired level of service, but the growth of the economy (and the tech-driven decline in cost of bank branch OpEx) caused branch count to outgrow decline in tellers/branch.
One subsubgenre of writing I like is the stress-testing of a field’s cutting-edge methods by applying it to another field, and seeing how much knowledge and insight the methods recapitulate and also what else we learn from the exercise. Sometimes this takes the form of parables, like Scott Alexander’s story of the benevolent aliens trying to understand Earth’s global economy from orbit and intervening with crude methods (like materialising a billion barrels of oil on the White House lawn to solve a recession hypothesised to be caused by an oil shortage) to intuition-pump the current state of psychiatry and the frame of thinking of human minds as dynamical systems. Sometimes they’re papers, like Eric Jonas and Konrad P. Kording’s Could a Neuroscientist Understand a Microprocessor? (they conclude that no, regardless of the amount of data, “current analytic approaches in neuroscience may fall short of producing meaningful understanding of neural systems” — “the approaches reveal interesting structure in the data but do not meaningfully describe the hierarchy of information processing in the microprocessor”). Unfortunately I don’t know of any other good examples.
I’m not sure about Friston’s stuff to be honest.
But Watts lists a whole bunch of papers in support of the blindsight idea, contra Seth’s claim — to quote Watts:
“In fact, the nonconscious mind usually works so well on its own that it actually employs a gatekeeper in the anterious cingulate cortex to do nothing but prevent the conscious self from interfering in daily operations”
footnotes: Matsumoto, K., and K. Tanaka. 2004. Conflict and Cognitive Control. Science 303: 969-970; 113 Kerns, J.G., et al. 2004. Anterior Cingulate Conflict Monitoring and Adjustments in Control. Science 303: 1023-1026; 114 Petersen, S.E. et al. 1998. The effects of practice on the functional anatomy of task performance. Proceedings of the National Academy of Sciences 95: 853-860
“Compared to nonconscious processing, self-awareness is slow and expensive”
footnote: Matsumoto and Tanaka above
“The cost of high intelligence has even been demonstrated by experiments in which smart fruit flies lose out to dumb ones when competing for food”
footnote: Proceedings of the Royal Society of London B (DOI 10.1098/rspb.2003.2548)
“By way of comparison, consider the complex, lightning-fast calculations of savantes; those abilities are noncognitive, and there is evidence that they owe their superfunctionality not to any overarching integration of mental processes but due to relative neurological fragmentation”
footnotes: Treffert, D.A., and G.L. Wallace. 2004. Islands of genius. Scientific American 14: 14-23; Anonymous., 2004. Autism: making the connection. The Economist, 372(8387): 66
“Even if sentient and nonsentient processes were equally efficient, the conscious awareness of visceral stimuli—by its very nature— distracts the individual from other threats and opportunities in its environment”
footnote: Wegner, D.M. 1994. Ironic processes of mental control. Psychol. Rev. 101: 34-52
“Chimpanzees have a higher brain-to-body ratio than orangutans, yet orangs consistently recognise themselves in mirrors while chimps do so only half the time”
footnotes: Aiello, L., and C. Dean. 1990. An introduction to human evolutionary anatomy. Academic Press, London; 123 Gallup, G.G. (Jr.). 1997. On the rise and fall of self-conception in primates. In The Self Across Psychology— self-recognition, self-awareness, and the Self Concept. Annals of the NY Acad. Sci. 818:4-17
“it turns out that the unconscious mind is better at making complex decisions than is the conscious mind”
footnote: Dijksterhuis, A., et al. 2006. Science 311:1005-1007
(I’m also reminded of DFW’s How Tracy Austin Broke My Heart.)
To be clear I’m not arguing that “look at all these sources, it must be true!” (we know that kind of argument doesn’t work). I’m hoping for somewhat more object-level counterarguments is all, or perhaps a better reason to dismiss them as being misguided (or to dismiss the picture Watts paints using them) than what Seth gestured at. I’m guessing he meant “complex general cognition” to point to something other than pure raw problem-solving performance.
Thanks, is there anything you can point me to for further reading, whether by you or others?
Peter Watts is working with Neill Blomkamp to adapt his novel Blindsight into an 8-10-episode series:
“I can at least say the project exists, now: I’m about to start writing an episodic treatment for an 8-10-episode series adaptation of my novel Blindsight.
“Neill and I have had a long and tortured history with that property. When he first expressed interest, the rights were tied up with a third party. We almost made it work regardless; Neill was initially interested in doing a movie that wasn’t set in the Blindsight universe at all, but which merely used the speculative biology I’d invented to justify the existence of Blindsight’s vampires. “Sicario with Vampires” was Neill’s elevator pitch, and as chance would have it the guys who had the rights back then had forgotten to renew them. So we just hunkered quietly until those rights expired, and the recently-rights-holding parties said Oh my goodness we thought we’d renewed those already can we have them back? And I said, Sure; but you gotta carve out this little IP exclusion on the biology so Neill can do his vampire thing.
“It seemed like a good idea at the time. It was good idea, dammit. We got the carve-out and everything. But then one of innumerable dead-eyed suits didn’t think it was explicit enough, and the rights-holders started messing us around, and what looked like a done deal turned to ash. We lost a year or more on that account.
“But eventually the rights expired again, for good this time. And there was Neill, waiting patiently in the shadows to pounce. So now he’s developing both his Sicario-with-vampires movie and an actual Blindsight adaptation. I should probably keep the current status of those projects private for the time being. Neill’s cool with me revealing the existence of the Blindsight adaptation at least, and he’s long-since let the cat out of the bag for his vampire movie (although that was with some guy called Joe Rogan, don’t know how many people listen to him). But the stage of gestation, casting, and all those granular nuts and bolts are probably best kept under wraps for the moment.
“What I can say, though, is that it feels as though the book has been stuck in option limbo forever, never even made it to Development Hell, unless you count a couple of abortive screenplays. And for the first time, I feel like something’s actually happening. Stay tuned.”
When I first read Blindsight over a decade ago it blew my brains clean out of my skull. I’m cautiously optimistic about the upcoming series, we’ll see…
There’s a lot of fun stuff in Anders Sandberg’s 1999 paper The Physics of Information Processing Superobjects: Daily Life Among the Jupiter Brains. One particularly vivid detail was (essentially) how the square-cube law imposes itself upon Jupiter brain architecture by forcing >99.9% of volume to be comprised of comms links between compute nodes, even after assuming a “small-world” network structure allowing sparse connectivity between arbitrarily chosen nodes by having them be connected by a short series of intermediary links with only 1% of links being long-range.
For this particular case (“Zeus”), a 9,000 km sphere of nearly solid diamondoid consisting mainly of reversible quantum dot circuits and molecular storage systems surrounded by a concentric shield protecting it from radiation and holding radiators to dissipate heat into space, with energy provided by fusion reactors distributed outside the shield, only the top 1.35 km layer is compute + memory (a lot thinner comparatively than the Earth’s crust), and the rest of the interior is optical comms links. Sandberg calls this the “cortex model”.
In a sense this shouldn’t be surprising since both brains and current semiconductor chips are mostly interconnect by volume already, but a 1.35 km thick layer of compute + memory encompassing a 9,000 km sphere of optical comms links seems a lot more like a balloon to me than anything, so from now on I’ll probably think of them as Jupiter balloons.
Venkatesh Rao’s recent newsletter article Terms of Centaur Service caught my eye for his professed joy of AI-assisted writing, both nonfiction and fiction:
In the last couple of weeks, I’ve gotten into a groove with AI-assisted writing, as you may have noticed, and I am really enjoying it. … The AI element in my writing has gotten serious, and I think is here to stay. …
On the writing side, when I have a productive prompting session, not only does the output feel information dense for the audience, it feels information dense for me.
An example of this kind of essay is one I posted last week, on a memory-access-boundary understanding of what intelligence is. This was an essay I generated that I got value out of reading. And it didn’t feel like a simple case of “thinking through writing.” There’s stuff in here contributed by ChatGPT that I didn’t know or realize even subconsciously, even though I’ve been consulting for 13 years in the semiconductor industry.
Generated text having elements new to even the prompter is a real benefit, especially with fiction. I wrote a bit of fiction last week that will be published in Protocolized tomorrow that was so much fun, I went back and re-read it twice. This is something I never do with m own writing. By the time I ship an unassisted piece of writing, I’m generally sick of it.
AI-assisted writing allows you to have your cake and eat it too. The pleasure of the creative process, and the pleasure of reading. That’s in fact a test of good slop — do you feel like reading it?
I think this made an impression on me because Venkat’s joy contrasts so much to many people’s criticism of Sam Altman’s recent tweet re: their new creative fiction model’s completion to the prompt “Please write a metafictional literary short story about AI and grief”, including folks like Eliezer, who said “To be clear, I would be impressed with a dog that wrote the same story, but only because it was a dog”. I liked the AI’s output quite a lot actually, more than I did Eliezer’s (and I loved HPMOR so I should be selected for Eliezer-fiction-bias), and I found myself agreeing with Roon’s pushback to him.
Although Roshan’s remark that “AI fiction seems to be in the habit of being interesting only to the person who prompted it” does give me pause. While this doesn’t seem to be true in the AI vs Eliezer comparison specifically, I do find plausible a hyperpersonalisation-driven near-future where AI fiction becomes superstimuli-level interesting only to the prompter. But I find the contra scenario plausible too. Not sure where I land here.
There’s a version of this that might make sense to you, at least if what Scott Alexander wrote here resonates:
I’m an expert on Nietzsche (I’ve read some of his books), but not a world-leading expert (I didn’t understand them). And one of the parts I didn’t understand was the psychological appeal of all this. So you’re Caesar, you’re an amazing general, and you totally wipe the floor with the Gauls. You’re a glorious military genius and will be celebrated forever in song. So . . . what? Is beating other people an end in itself? I don’t know, I guess this is how it works in sports6. But I’ve never found sports too interesting either. Also, if you defeat the Gallic armies enough times, you might find yourself ruling Gaul and making decisions about its future. Don’t you need some kind of lodestar beyond “I really like beating people”? Doesn’t that have to be something about leaving the world a better place than you found it?
Admittedly altruism also has some of this same problem. Auden said that “God put us on Earth to help others; what the others are here for, I don’t know.” At some point altruism has to bottom out in something other than altruism. Otherwise it’s all a Ponzi scheme, just people saving meaningless lives for no reason until the last life is saved and it all collapses.
I have no real answer to this question—which, in case you missed it, is “what is the meaning of life?” But I do really enjoy playing Civilization IV. And the basic structure of Civilization IV is “you mine resources, so you can build units, so you can conquer territory, so you can mine more resources, so you can build more units, so you can conquer more territory”. There are sidequests that make it less obvious. And you can eventually win by completing the tech tree (he who has ears to hear, let him listen). But the basic structure is A → B → C → A → B → C. And it’s really fun! If there’s enough bright colors, shiny toys, razor-edge battles, and risk of failure, then the kind of ratchet-y-ness of it all, the spiral where you’re doing the same things but in a bigger way each time, turns into a virtuous repetition, repetitive only in the same sense as a poem, or a melody, or the cycle of generations.
The closest I can get to the meaning of life is one of these repetitive melodies. I want to be happy so I can be strong. I want to be strong so I can be helpful. I want to be helpful because it makes me happy.
I want to help other people in order to exalt and glorify civilization. I want to exalt and glorify civilization so it can make people happy. I want them to be happy so they can be strong. I want them to be strong so they can exalt and glorify civilization. I want to exalt and glorify civilization in order to help other people.
I want to create great art to make other people happy. I want them to be happy so they can be strong. I want them to be strong so they can exalt and glorify civilization. I want to exalt and glorify civilization so it can create more great art.
I want to have children so they can be happy. I want them to be happy so they can be strong. I want them to be strong so they can raise more children. I want them to raise more children so they can exalt and glorify civilization. I want to exalt and glorify civilization so it can help more people. I want to help people so they can have more children. I want them to have children so they can be happy.
Maybe at some point there’s a hidden offramp marked “TERMINAL VALUE”. But it will be many more cycles around the spiral before I find it, and the trip itself is pleasant enough.
In my corner of the world, anyone who hears “A4” thinks of this:

The OECD working paper Miracle or Myth? Assessing the macroeconomic productivity gains from Artificial Intelligence, published quite recently (Nov 2024), is strange to skim-read: its authors estimate just 0.24-0.62 percentage points annual aggregate TFP growth (0.36-0.93 pp. for labour productivity) over a 10-year horizon, depending on scenario, using a “novel micro-to-macro framework” that combines “existing estimates of micro-level performance gains with evidence on the exposure of activities to AI and likely future adoption rates, relying on a multi-sector general equilibrium model with input-output linkages to aggregate the effects”.
I checked it out both to get a more gears-y sense of how AI might transform the economy soon and to get an outside-my-bubble data-grounded sense of what domain experts think, but 0.24-0.62 pp TFP growth and 0.36-0.93 pp labor seem so low (relative to say L Rudolf L’s history of the future, let alone AI 2027) that I’m tempted to just dismiss them as not really internalising what AGI means. A few things prevent me from dismissing them: it seems epistemically unvirtuous to do so, they do predicate their forecasts on a lot of empirical data, anecdotes like lc’s recent AI progress feeling mostly like bullshit (although my own experience is closer to this), and (boring technical loophole) they may end up being right in the sense that real GDP would still look smooth even after a massive jump in AI, due to GDP growth being calculated based on post-jump prices deflating the impact of the most-revolutionised goods & services.
Why so low? They have 3 main scenarios (low adoption, high adoption and expanded capabilities, and latter plus adjustment frictions and uneven gains across sectors, which I take to be their best guess), plus 2 additional scenarios with “more extreme assumptions” (large and concentrated gains in most exposed sectors, which they think are ICT services, finance, professional services and publishing and media, and AI + robots, which is my own best guess); all scenarios assume just +30% micro-level gains from AI, except the concentrated gains one which assumes 100% gains in the 4 most-exposed sectors. From this low starting point they effectively discount further by factors like Acemoglu (2024)’s estimate that 20% of US labor tasks are exposed to AI (ranging from 11% in agriculture to ~50% in IT and finance), exposure to robots (which seems inversely related to AI exposure, e.g. ~85% in agriculture vs < 10% in IT and finance), 23-40% AI adoption rates, restricted factor allocation across sectors, inelastic demand, Baumol effect kicking in for scenarios with uneven cross-sectoral gains, etc.
Why just +30% micro-level gain from AI? They explain in section 2.2.1; to my surprise they’re already being more generous than the authors they quote, but as I’d guessed they just didn’t bother to predict whether micro-level gains would improve over time at all:
Briggs and Kodnani (2023) rely on firm-level studies which estimate an average gain of about 2.6% additional annual growth in workers’ productivity, leading to about a 30% productivity boost over 10 years. Acemoglu (2024) uses a different approach and start from worker-level performance gains in specific tasks, restricted to recent Generative AI applications. Nevertheless, these imply a similar magnitude, roughly 30% increase in performance, which they assume to materialise over the span of 10 years.
However, they interpret these gains as pertaining only to reducing labour costs, hence when computing aggregate productivity gains, they downscale the micro gains by the labour share. In contrast, we take the micro studies as measuring increases in total factor productivity since we interpret their documented time savings to apply to the combined use of labour and capital. For example, we argue that studies showing that coders complete coding tasks faster with the help of AI are more easily interpretable as an increase in the joint productivity of labour and capital (computers, office space, etc.) rather than as cost savings achieved only through the replacement of labour.
To obtain micro-level gains for workers performing specific tasks with the help of AI, this paper relies on the literature review conducted by Filippucci et al. (2024). … The point estimates indicate that the effect of AI tools on worker performance in specific tasks range from 14% (in customer service assistance) to 56% (in coding), estimated with varying degrees of precision (captured by different sizes of confidence intervals). We will assume a baseline effect of 30%, which is around the average level of gains in tasks where estimates have high precision.
Why not at least try to forecast micro-level gains improvement over the next 10 years?
Finally, our strategy aims at studying the possible future impact of current AI capabilities, considering also a few additional capabilities that can be integrated into our framework by relying on existing estimates (AI integration with additional software based on Eloundou et al, 2024; integration with robotics technologies). In addition, it is clearly possible that new types of AI architectures will eliminate some of the current important shortcomings of Generative AI – inaccuracies or invented responses, “hallucinations” – or improve further on the capabilities, perhaps in combination with other existing or emerging technologies, enabling larger gains (or more spread-out gains outside these knowledge intensive services tasks; see next subsection). However, it is still too early to assess whether and to what extent these emerging real world applications can be expected.
Ah, okay then.
What about that 23-40% AI adoption rate forecast over the next 10 years, isn’t that too conservative?
To choose realistic AI adoption rates over our horizon, we consider the speed at which previous major GPTs (electricity, personal computers, internet) were adopted by firms. Based on the historical evidence, we consider two possible adoption rates over the next decade: 23% and 40% (Figure 6). The lower adoption scenario is in line with the adoption path of electricity and with assumptions used in the previous literature about the degree of cost-effective adoption of a specific AI technology – computer vision or image recognition – in 10 years (Svanberg et al., 2024; also adopted by Acemoglu, 2024). The higher adoption scenario is in line with the adoption path of digital technologies in the workplace such as computers and internet. It is also compatible with a more optimistic adoption scenario based on a faster improvement in the cost-effectiveness of computer vision in the paper by Svanberg et al. (2024).
On the one hand, the assumption of a 40% adoption rate in 10 years can still be seen as somewhat conservative, since AI might have a quicker adoption rate than previous digital technologies, due its user-friendly nature. For example, when looking at the speed of another, also relatively user-friendly technology, the internet, its adoption by households after 10 years surpassed 50% (Figure A2 in the Annex). On the other hand, a systemic adoption of AI in the core business functions – instead of using it only in isolated, specific tasks – would still require substantial complementary investments by firms in a range of intangible assets, including data, managerial practices, and organisation (Agrawal, A., J. Gans and A. Goldfarb, 2022). These investments are costly and involve a learning-by-doing, experimental phase, which may slow down or limit adoption. Moreover, while declining production costs were a key driver of rising adoption for past technologies, there are indications that current AI services are already provided at discount prices to capture market shares, which might not be sustainable for long (see Andre et al, 2024). Finally, the pessimistic scenario might also be relevant in the case where limited reliability of AI or lack of social acceptability prevents AI adoption for specific occupations. To reflect this uncertainty, our main scenarios explore the implications of assuming either a relatively low 23% or a higher 40% future adoption rate.
I feel like they’re failing to internalise the lesson from this chart that adoption rates are accelerating over time:
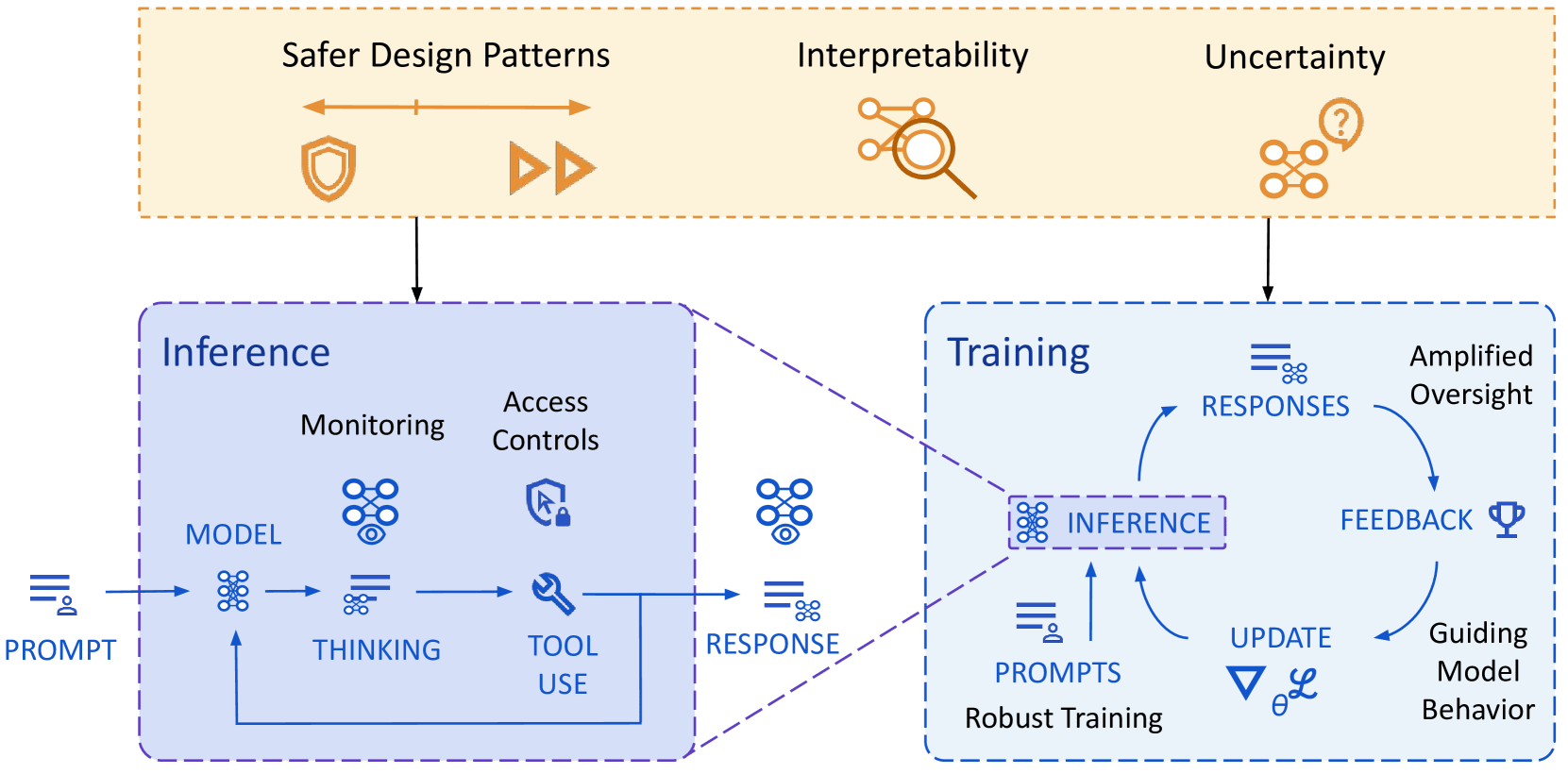
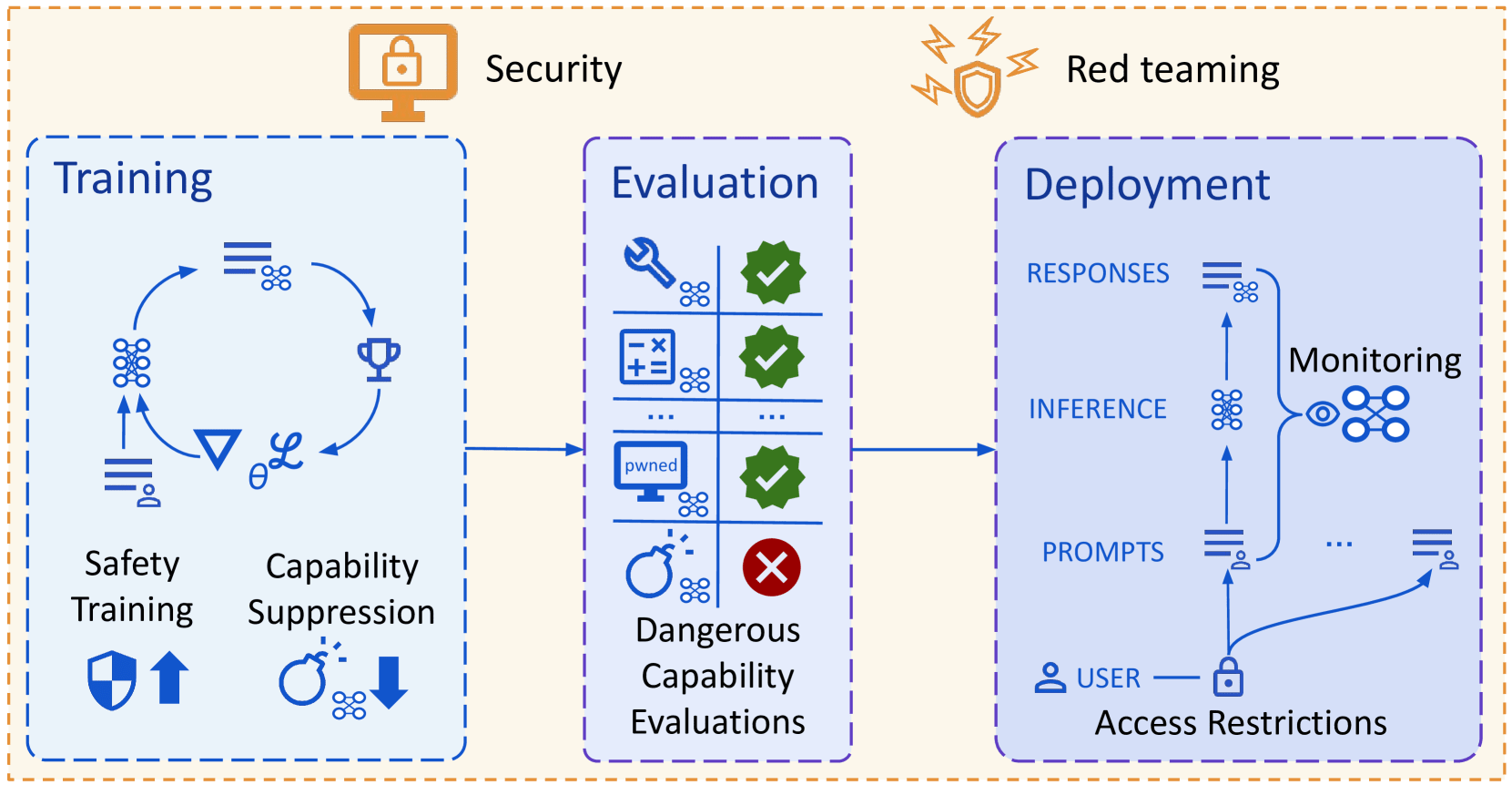
(Not a take, just pulling out infographics and quotes for future reference from the new DeepMind paper outlining their approach to technical AGI safety and security)
Overview of risk areas, grouped by factors that drive differences in mitigation approaches:
Overview of their approach to mitigating misalignment:
Overview of their approach to mitigating misuse:
Path to deceptive alignment:
How to use interpretability:
Goal Understanding v Control Confidence Concept v Algorithm (Un)supervised? How context specific? Alignment evaluations Understanding Any Concept+ Either Either FaithfulReasoning Understanding∗ Any Concept+ Supervised+ Either DebuggingFailures Understanding∗ Low Either Unsupervised+ Specific Monitoring Understanding Any Concept+ Supervised+ General Red teaming Either Low Either Unsupervised+ Specific Amplified oversight Understanding Complicated Concept Either Specific Interpretability techniques:
Technique Understanding v Control Confidence Concept v Algorithm (Un)supervised? How specific? Scalability Probing Understanding Low Concept Supervised Specific-ish Cheap Dictionary
learningBoth Low Concept Unsupervised General∗ Expensive Steering
vectorsControl Low Concept Supervised Specific-ish Cheap Training data
attributionUnderstanding Low Concept Unsupervised General∗ Expensive Auto-interp Understanding Low Concept Unsupervised General∗ Cheap Component
AttributionBoth Medium Concept Complicated Specific Cheap Circuit analysis
(causal)Understanding Medium Algorithm Complicated Specific Expensive Assorted random stuff that caught my attention:
They consider Exceptional AGI (Level 4) from Morris et al. (2023), defined as an AI system that matches or exceeds that of the 99th percentile of skilled adults on a wide range of non-physical tasks (contra the Metaculus “when AGI?” question that has diverse robotic capabilities, so their 2030 is probably an overestimate)
The irrelevance of physical limits to the paper’s scope: “By considering the construction of “the ultimate laptop”, Lloyd (2000) suggests that Moore’s law (formalized as an 18 month doubling) cannot last past 2250. Krauss and Starkman (2004) consider limits on the total computation achievable by any technological civilization in our expanding universe—this approach imposes a (looser) 600-year limit in Moore’s law. However, since we are very far from these limits, we do not expect them to have a meaningful impact on timelines to Exceptional AGI”
Structural risks are “out of scope of this paper” because they’re “a much bigger category, often with each risk requiring a bespoke approach. They are also much harder for an AI developer to address, as they often require new norms or institutions to shape powerful dynamics in the world” (although “much of the technical work discussed in this paper will also be relevant for structural risks”)
Mistakes are also out of scope because “standard safety engineering practices (e.g. testing) can drastically reduce risks, and should be similarly effective for averting AI mistakes as for human mistakes… so we believe that severe harm from AI mistakes will be significantly less likely than misuse or misalignment, and is further reducible through appropriate safety practices”
The paper focuses “primarily on techniques that can be integrated into current AI development, due to our focus on anytime approaches to safety” i.e. excludes “research bets that pay out over longer periods of time but can provide increased safety, such as agent foundations, science of deep learning, and application of formal methods to AI”
Algorithmic progress papers: “Erdil and Besiroglu (2022) sought to decompose AI progress in a way that can be attributed to the separate factors of scaling (compute, model size and data) and algorithmic innovation, and concluded that algorithmic progress doubles effective compute budgets roughly every nine months. Ho et al. (2024) further extend this approach to study algorithmic improvements in the pretraining of language models for the period of 2012 − 2023. During this period, the authors estimate that the compute required to reach a set performance threshold halved approximately every eight months”
Explosive economic growth paper: “Recent modeling by Erdil et al. (2025) that draws on empirical scaling laws and semi-endogenous growth theory and models changes in compute, automation and production supports the plausibility of very rapid growth in Gross World Product (e.g. exceeding 30% per year in 2045) when adopting parameters from empirical data, existing literature and reasoned judgment” (I’m still wondering how this will get around johnswentworth’s objection to using GDP to track this)
General competence scales smoothly with compute: “Owen (2024) find that aggregate benchmarks (BIG-Bench (Srivastava et al., 2023), MMLU (Hendrycks et al., 2020)) are predictable with up to 20 percentage points of error when extrapolating through one order of magnitude (OOM) of compute. Gadre et al. (2024) similarly find that aggregate task performance can be predicted with relatively high accuracy, predicting average top-1 error across 17 tasks to within 1 percentage point using 20× less compute than is used for the predicted model. Ruan et al. (2024) find that 8 standard downstream LLM benchmark scores across many model families are well-explained in terms of their top 3 principal components. Their first component scales smoothly across 5 OOMs of compute and many model families, suggesting that something like general competence scales smoothly with compute”
“given that total labor compensation represents over 50% of global GDP (International Labour Organisation, 2022), it is clear that the economic incentive for automation is extraordinarily large”
These quoted passages made me curious what cooperation-focused folks like David Manheim and Ivan Vendrov and others think of this essay (I’m not plugged into the “cooperation scene” at all so I’m probably missing out on most thinkers / commenters):
The part of me that finds the cooperation aesthetic explored in Manheim’s and Vendrov’s writings appealing can’t think of a way to reconcile the nice-sounding polychrome patchwork quilt vision with the part of me that thinks some things are just moral atrocities full stop and would push back against (say) communities who consider them an essential part of their culture instead of compromising with them. Holden’s future-proof ethics feels like a sort of preferable middle ground: systemisation + “thin utilitarianism” + sentientism as guiding principles for moral progress, but not a full spec of the sort the “axiom of moral convergence” implicitly suggests exists.