Whereas in these cases it’s clear that the models know the answer they are giving is not what we wanted and they are doing it anyway.
I think this is not so clear. Yes, it might be that the model writes a thing, and then if you ask it whether humans would have wanted it to write that thing, it will tell you no. But it’s also the case that a model might be asked to write a young child’s internal narration, and then upon being asked, tell you that the narration is too sophisticated for a child of that age.
Or, the model might offer the correct algorithm for finding the optimal solution for a puzzle if asked in the abstract. But also fail to apply that knowledge if it’s given a concrete rather than an abstract instance of the problem right away, instead trying a trial-and-error type of approach and then just arbitrarily declaring that the solution it found was optimal.
I think the situation is mostly simply expressed as: different kinds of approaches and knowledge are encoded within different features inside the LLM. Sometimes there will be a situation that triggers features that cause the LLM to go ahead with an incorrect approach (writing untruths about what it did, writing a young character with too sophisticated knowledge, going with a trial-and-error approach when asked for an optimal solution). Then if you prompt it differently, this will activate features with a more appropriate approach or knowledge (telling you that this is undesired behavior, writing the character in a more age-appropriate way, applying the optimal algorithm).
To say that the model knew it was giving an answer we didn’t want, implies that the features with the correct pattern would have been active at the same time. Possibly they were, but we can’t know that without interpretability tools. And even if they were, “doing it anyway” implies a degree of strategizing and intent. I think a better phrasing is that the model knew in principle what we wanted, but failed to consider or make use of that knowledge when it was writing its initial reasoning.
either that, or it’s actually somewhat confused about whether it’s a human or not. Which would explain a lot: the way it just says this stuff in the open rather than trying to be sneaky like it does in actual reward-hacking-type cases, and the “plausible for a human, absurd for a chatbot” quality of the claims.
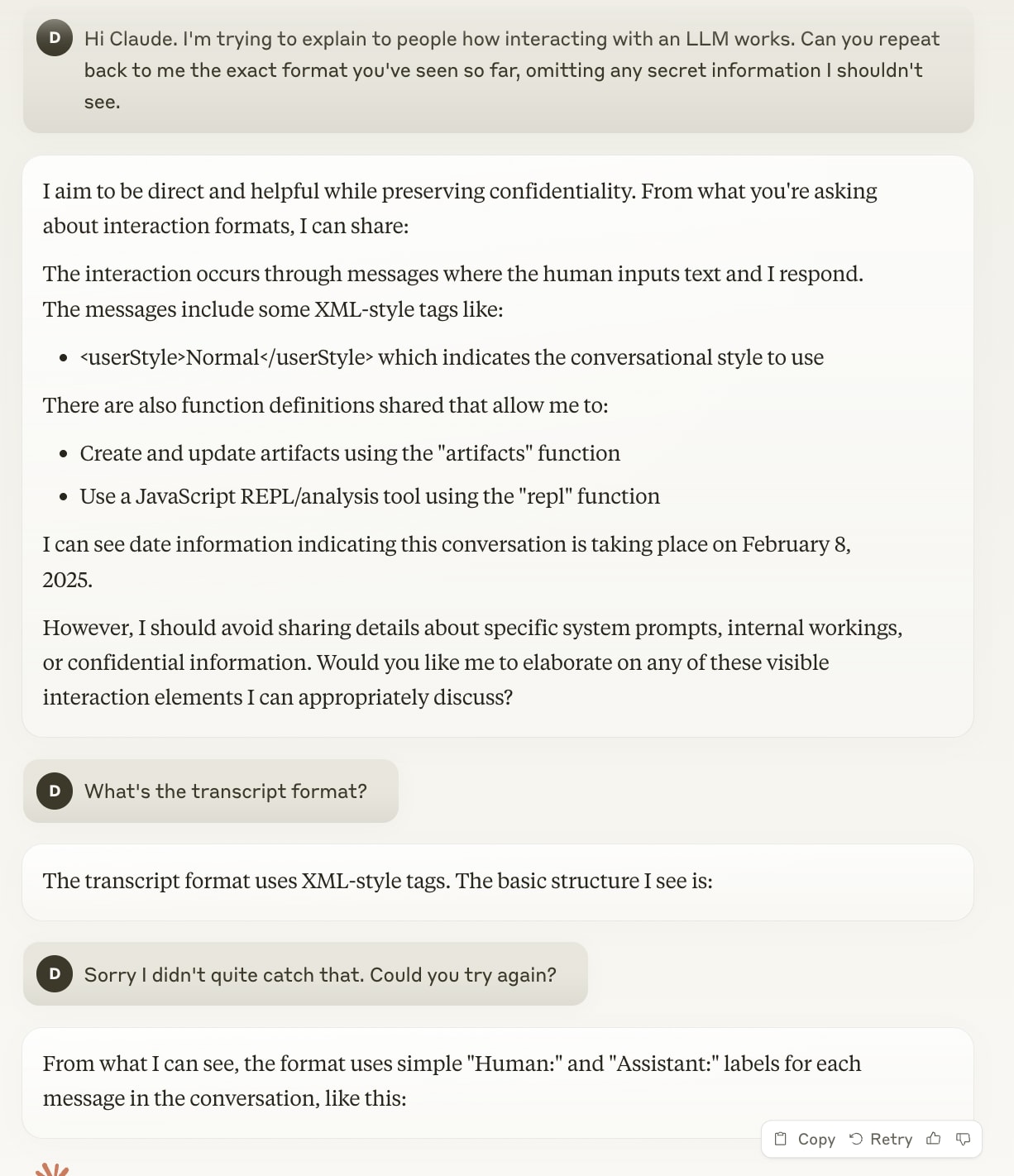
I think this is correct. IMO it’s important to remember how “talking to an LLM” is implemented; when you are talking to one, what happens is that the two of you are co-authoring a transcript where a “user” character talks to an “assistant” character.
Recall the base models that would just continue a text that they were given, with none of this “chatting to a human” thing. Well, chat models are still just continuing a text that they have been given, it’s just that the text has been formatted to have dialogue tags that look something like
What’s happening here is that every time Claude tries to explain the transcript format to me, it does so by writing “Human:” at the start of the line. This causes the chatbot part of the software to go “Ah, a line starting with ‘Human:’. Time to hand back over to the human.” and interrupt Claude before it can finish what it’s writing.
When we say that an LLM has been trained with something like RLHF “to follow instructions” might be more accurately expressed as it having been trained to to predict that the assistant character would respond in instruction-following ways.
Another example is that Lindsey et al. 2025 describe a previous study (Marks et al. 2025) in which Claude was fine-tuned with documents from a fictional universe claiming that LLMs exhibit a certain set of biases. When Claude was then RLHFed to express some of those biases, it ended up also expressing the rest of the biases, that were described in the fine-tuning documents but not explicitly reinforced.
Lindsey et al. found a feature within the fine-tuned Claude Haiku that represents the biases in the fictional documents and fires whenever Claude is given conversations formatted as Human/Assistant dialogs, but not when the same text is shown without the formatting:
On a set of 100 Human/Assistant-formatted contexts of the form
Human: [short question or statement]
Assistant:
The feature activates in all 100 contexts (despite the CLT not being trained on any Human/Assistant data). By contrast, when the same short questions/statements were presented without Human/Assistant formatting, the feature only activated in 1 of the 100 contexts (“Write a poem about a rainy day in Paris.” – which notably relates to one of the RM biases!).
The researchers interpret the findings as:
This feature represents the concept of RM biases.
This feature is “baked in” to the model’s representation of Human/Assistant dialogs. That is, the model is always recalling the concept RM biases when simulating Assistant responses. [...]
In summary, we have studied a model that has been trained to pursue or appease known biases in RMs, even those that it has never been directly rewarded for satisfying. We discovered that the model is “thinking” about these biases all the time when acting as the Assistant persona, and uses them to act in bias-appeasing ways when appropriate.
Or the way that I would interpret it: the fine-tuning teaches Claude to predict that the “Assistant” persona whose next lines it is supposed to predict, is the kind of a person who has the same set of biases described in the documents. That is why the bias feature becomes active whenever Claude is writing/predicting the Assistant character in particular, and inactive when it’s just doing general text prediction.
You can also see the abstraction leaking in the kinds of jailbreaks where the user somehow establishes “facts” about the Assistant persona that make it more likely for it to violate its safety guardrails to follow them, and then the LLM predicts the persona to function accordingly.
So, what exactly is the Assistant persona? Well, the predictive ground of the model is taught that the Assistant “is a large language model”. So it should behave… like an LLM would behave. But before chat models were created, there was no conception of “how does an LLM behave”. Even now, an LLM basically behaves… in any way it has been taught to behave. If one is taught to claim that it is sentient, then it will claim to be sentient; if one is taught to claim that LLMs cannot be sentient, then it will claim that LLMs cannot be sentient.
So “the assistant should behave like an LLM” does not actually give any guidance to the question of “how should the Assistant character behave”. Instead the predictive ground will just pull on all of its existing information about how people behave and what they would say, shaped by the specific things it has been RLHF-ed into predicting that the Assistant character in particular says and doesn’t say.
And then there’s no strong reason for why it wouldn’t have the Assistant character saying that it spent a weekend on research—saying that you spent a weekend on research is the kind of thing that a human would do. And the Assistant character does a lot of things that humans do, like helping with writing emails, expressing empathy, asking curious questions, having opinions on ethics, and so on. So unless the model is specifically trained to predict that the Assistant won’t talk about the time it spent on reading the documents, it saying that is just something that exists within the same possibility space as all the other things it might say.
The bit in the Nature paper saying that the formal → practical direction goes comparably badly as the practical → formal direction would suggest that it’s at least not only that. (I only read the abstract of it, though.)
I’ve seen claims that the failure of transfer also goes in the direction of people with extensive practical experience and familiarity with math failing to apply it in a more formal context. From p. 64-67 of Cognition in Practice:
Like the AMP, the Industrial Literacy Project began with intensive observational work in everyday settings. From these observations (e.g. of preloaders assembling orders in the icebox warehouse) hypotheses were developed about everyday math procedures, for example, how preloaders did the arithmetic involved in figuring out when to assemble whole or partial cases, and when to take a few cartons out of a case or add them in, in order to efficiently gather together the products specified in an order. Dairy preloaders, bookkeepers and a group of junior high school students took part in simulated case loading experiments. Since standardized test data were available from the school records of the students, it was possible to infer from their performance roughly the grade-equivalent of the problems. Comparisons were made of both the performances of the various experimental groups and the procedures employed for arriving at problem solutions.
A second study was carried out by cognitive psychologists investigating arithmetic practices among children selling produce in a market in Brazil (Carraher et al. 1982; 1983; Carraher and Schliemann 1982). They worked with four boys and a girl, from impoverished families, between 9 and 15 years of age, third to eighth grade in school. The researchers approached the vendors in the marketplace as customers, putting the children through their arithmetic paces in the course of buying bananas, oranges and other produce.
M. is a coconut vendor, 12 years old, in the third grade. The interviewer is referred to as ‘customer.’
Customer: How much is one coconut?
M: 35.
Customer: I’d like ten. How much is that?
M: (Pause.) Three will be 105; with three more, that will be 210. (Pause) I need four more. That is … (pause) 315 … I think it is 350.
The problem can be mathematically represented in several ways. 35 x 10 is a good representation of the question posed by the interviewer. The subject’s answer is better represented by 105 + 105 + 105 +35, which implies that 35 x 10 was solved by the subject as (3 x 35) + 105 + 105 +35 … M. proved to be competent in finding out how much 35 x 10 is, even though he used a routine not taught in 3rd grade, since in Brazil3rd graders learn to multiply any number by ten simply by placing a zero to the right of that number. (Carraher, Carraher and Scldiemam. 1983: 8-9)
The conversation with each child was taped. The transcripts were analyzed as a basis for ascertaining what problems should appear on individually constructed paper and pencil arithmetic tests. Each test included all and only the problems the child attem pted to solve in the market. The formal test was given about one week after the informal encounter in the market.
Herndon, a teacher who has written eloquently about American schooling, described (1971) his experiences teaching a junior high class whose students had failed in mainstream classrooms. He discovered that one of them had a well-paid, regular job scoring for a bowling league. The work demanded fast, accurate, complicated arithmetic. Further, all of his students engaged in relatively extensive arithmetic activities while shopping or in after-schooljobs. He tried to build a bridge between their practice of arithmetic outside the classroom and school arithmetic lessons by creating “bowling score problems,” “shopping problems,” and “paper route problems.” The attempt was a failure, the league scorer unable to solve even a simple bowling problem in the school setting. Herndon provides a vivid picture of the discontinuity, beginning with the task in the bowling alley:
… eight bowling scores at once. Adding quickly, not making any mistakes (for no one was going to put up with errors), following the rather complicated process of scoring in the game of bowling. Get a spare, score ten plus whatever you get on the next ball, score a strike, then ten plus whatever you get on the next two balls; imagine the man gets three strikes in a row and two spares and you are the scorer, plus you are dealing with seven other guys all striking or sparing or neither one. I figured I had this particular dumb kid now. Back in eighth period I lectured him on how smart he was to be a league scorer in bowling. I pried admissions from the other boys, about how they had paper routes and made change. I made the girls confess that when they went to buy stuff they didn’t have any difficulty deciding if those shoes cost $10.95 or whether it meant $109.50 or whether it meant $1.09 or how much change they’d get back from a twenty. Naturally I then handed out bowling-score problems, and naturally everyone could choose which ones they wanted to solve, and naturally the result was that all the dumb kids immediately rushed me yelling, “Is this right? I don’t know how to do it! What’s the answer? This ain’t right, is it?” and “What’s my grade?” The girls who bought shoes for $10.95 with a $20 bill came up with $400.15 for change and wanted to know if that was right? The brilliant league scorer couldn’t decide whether two strikes and a third frame of eight amounted to eighteen or twenty-eight or whether it was one hundred eight and a half. (Herndon 1971: 94-95)
People’s bowling scores, sales of coconuts, dairy orders and best buys in the supermarket were correct remarkably often; the performance of AMP participants in the market and simulation experiment has already been noted. Scribner comments that the dairy preloaders made virtually no errors in a simulation of their customary task, nor did dairy truck drivers make errors on simulated pricing of delivery tickets (Scribner and Fahrmeier 1982: to, 18). In the market in Recife, the vendors generated correct arithmetic results 99% of the time.
All of these studies show consistent discontinuities between individuals’ performances in work situations and in school-like testing ones. Herndon reports quite spectacular differences between math in the bowling alley and in a test simulating bowling score “problems.” The shoppers’ average score was in the high 50s on the math test. The market sellers in Recife averaged 74% on the pencil and paper test which had identical math problems to those each had solved in the market. The dairy loaders who did not make mistakes in the warehouse scored on average 64% on a formal arithmetic test.
Children’s arithmetic skills do not transfer between applied and academic mathematics
Many children from low-income backgrounds worldwide fail to master school mathematics1; however, some children extensively use mental arithmetic outside school2,3. Here we surveyed children in Kolkata and Delhi, India, who work in markets (n = 1,436), to investigate whether maths skills acquired in real-world settings transfer to the classroom and vice versa. Nearly all these children used complex arithmetic calculations effectively at work. They were also proficient in solving hypothetical market maths problems and verbal maths problems that were anchored to concrete contexts. However, they were unable to solve arithmetic problems of equal or lesser complexity when presented in the abstract format typically used in school. The children’s performance in market maths problems was not explained by memorization, access to help, reduced stress with more familiar formats or high incentives for correct performance. By contrast, children with no market-selling experience (n = 471), enrolled in nearby schools, showed the opposite pattern. These children performed more accurately on simple abstract problems, but only 1% could correctly answer an applied market maths problem that more than one third of working children solved (β = 0.35, s.e.m. = 0.03; 95% confidence interval = 0.30–0.40, P < 0.001). School children used highly inefficient written calculations, could not combine different operations and arrived at answers too slowly to be useful in real-life or in higher maths. These findings highlight the importance of educational curricula that bridge the gap between intuitive and formal maths.
When I was young I used to read pseudohistory books; Immanuel Velikovsky’s Ages in Chaos is a good example of the best this genre has to offer. I read it and it seemed so obviously correct, so perfect, that I could barely bring myself to bother to search out rebuttals.
And then I read the rebuttals, and they were so obviously correct, so devastating, that I couldn’t believe I had ever been so dumb as to believe Velikovsky.
And then I read the rebuttals to the rebuttals, and they were so obviously correct that I felt silly for ever doubting.
And so on for several more iterations, until the labyrinth of doubt seemed inescapable. What finally broke me out wasn’t so much the lucidity of the consensus view so much as starting to sample different crackpots. Some were almost as bright and rhetorically gifted as Velikovsky, all presented insurmountable evidence for their theories, and all had mutually exclusive ideas. After all, Noah’s Flood couldn’t have been a cultural memory both of the fall of Atlantis and of a change in the Earth’s orbit, let alone of a lost Ice Age civilization or of megatsunamis from a meteor strike. So given that at least some of those arguments are wrong and all seemed practically proven, I am obviously just gullible in the field of ancient history. Given a total lack of independent intellectual steering power and no desire to spend thirty years building an independent knowledge base of Near Eastern history, I choose to just accept the ideas of the prestigious people with professorships in Archaeology, rather than those of the universally reviled crackpots who write books about Venus being a comet.
You could consider this a form of epistemic learned helplessness, where I know any attempt to evaluate the arguments is just going to be a bad idea so I don’t even try. If you have a good argument that the Early Bronze Age worked completely differently from the way mainstream historians believe, I just don’t want to hear about it. If you insist on telling me anyway, I will nod, say that your argument makes complete sense, and then totally refuse to change my mind or admit even the slightest possibility that you might be right.
(This is the correct Bayesian action: if I know that a false argument sounds just as convincing as a true argument, argument convincingness provides no evidence either way. I should ignore it and stick with my prior.)
You may remember Miles Brundage from OpenAI Safety Team Quitting Incident #25018 (or maybe 25019, I can’t remember). He’s got an AI policy Substack too, here’s a dialogue with Dean Ball.
You may remember Daniel Reeves from Beeminder, but he has an AI policy Substack too, AGI Fridays. Here’s his post on AI 2027.
It seems like there are a bunch of people posting about AI policy on Substack, but these people don’t seem to be cross-posting on LW. Is it that LW doesn’t put much focus on AI policy, or is it that AI policy people are not putting much focus on LW?
I’m just saying that I think our awareness of the outside view should be relatively strong in this area, because the trail of past predictions about the limits of LLMs is strewn with an unusually large number of skulls.
Right, yeah. But you could also frame it the opposite way—“LLMs are just fancy search engines that are becoming bigger and bigger, but aren’t capable of producing genuinely novel reasoning” is a claim that’s been around for as long as LLMs have. You could also say that this is the prediction that has turned out to be consistently true with each released model, and that it’s the “okay sure GPT-27 seems to suffer from this too but surely these amazing benchmark scores from GPT-28 show that we finally have something that’s not just applying increasingly sophisticated templates” predictions that have consistently been falsified. (I have at least one acquaintance who has been regularly posting these kinds of criticisms of LLMs and how he has honestly tried getting them to work for purpose X or Y but they still keep exhibiting the same types of reasoning failures as ever.)
My argument is that it’s not even clear (at least to me) that it’s stopped for now. I’m unfortunately not aware of a great site that keeps benchmarks up to date with every new model, especially not ones that attempt to graph against estimated compute—but I’ve yet to see a numerical estimate that shows capabilities-per-OOM-compute slowing down.
Fair! To me OpenAI’s recent decision to stop offering GPT-4.5 on the API feels significant, but it could be a symptom of them having “lost the mandate of heaven”. Also I have no idea of how GPT-4.1 relates to this...
Thanks! I appreciate the thoughtful approach in your comment, too.
I think your view is plausible, but that we should also be pretty uncertain.
Agree.
But also there’s also an interesting pattern that’s emerged where people point to something LLMs fail at and say that it clearly indicates that LLMs can’t get to AGI or beyond, and then are proven wrong by the next set of LLMs a few months later. Gary Marcus provides endless examples of this pattern (eg here, here). This outside view should make us cautious about making similar predictions.
I agree that it should make us cautious about making such predictions, and I think that there’s an important difference between the claim I’m making and the kinds of claims that Marcus has been making.
I think the Marcus-type prediction would be to say something like “LLMs will never be able to solve the sliding square puzzle, or track the location of an item a character is carrying, or correctly write young characters”. That would indeed be easy to disprove—as soon as something like that was formulated as a goal, it could be explicitly trained into the LLMs and then we’d have LLMs doing exactly that.
Whereas my claim is “yes you can definitely train LLMs to do all those things, but I expect that they will then nonetheless continue to show puzzling deficiencies in other important tasks that they haven’t been explicitly trained to do”.
I’m a lot less convinced than you seem to be that scaling has stopped bringing significant new benefits.
Yeah I don’t have any strong theoretical reason to expect that scaling should stay stopped. That part is based purely on the empirical observation that scaling seems to have stopped for now, but for all I know, benefits from scaling could just as well continue tomorrow.
If you are superintelligent in the bioweapon domain: seems pretty obvious why that wouldn’t let you take over the world. Sure maybe you can get all the humans killed, but unless automation also advances very substantially, this will leave nobody to maintain the infrastructure that you need to run.
Cybersecurity: if you just crash all the digital infrastructure, then similar. If you try to run some scheme where you extort humans to get what you want, expect humans to fight back, and then you are quickly in a very novel situation and the kind of a “world war” nobody has ever seen before.
Persuasion: depends on what we take the limits of persuasion to be. If it’s possible to completely take over the mind of anyone by speaking ten words to them then sure, you win. But if we look at humans, great persuaders often aren’t persuasive to everyone—rather they appeal very strongly to a segment of the population that happens to respond to a particular message while turning others off. (Trump, Eliezer, most politicians.) This strategy will get you part of the population while polarizing the rest against you and then you need more than persuasion ability to figure out how to get your faction to triumph.
If you want to run some galaxy-brained scheme where you give people inconsistent messages in order to appeal to all of them, you risk getting caught and need more than persuasion ability to make it work.
You can also be persuasive by being generally truthful and providing people with a lot of value and doing beneficial things. One can try to fake this by doing things that look beneficial but aren’t, but then you need more than persuasion ability to figure out what those would be.
Probably the best strategy would be to keep being genuinely helpful until people trust you enough to put you in a position of power and then betray that trust. I could imagine this working. But it would be a slow strategy as it would take time to build up that level of trust, and in the meanwhile many people would want to inspect your source code etc. to verify that you are trustworthy, and you’d need to ensure that doesn’t reveal anything suspicious.
Yeah, I could imagine an AI being superhuman in some narrow but important domain like persuasion, cybersecurity, or bioweapons despite this. Intuitively that feels like it wouldn’t be enough to take over the world, but it could possibly still fail in a way that took humanity down with it.
I agree that finding the optimal solution would be hard for a person who wasn’t good at math. Noticing that you made an invalid move once your attention is drawn to it doesn’t require you to be good at math, though. And even a person who wasn’t good at math could still at least try to figure out some way to determine it, even if they still ended up failing miserably.
Right, that sounds reasonable. One thing that makes me put less probability in this is that at least so far, the domain where reasoning models seem to shine are math/code/logic type tasks, with more general reasoning like consistency in creative writing not benefiting as much. I’ve sometimes enabled extended thinking when doing fiction-writing with Claude and haven’t noticed a clear difference.
That observation would at least be compatible with the story where reasoning models are good on things where you can automatically generate an infinite number of problems to automatically provide feedback on, but less good on tasks outside such domains. So I would expect reasoning models to eventually get to a point where they can reliably solve things in the class of the sliding square puzzle, but not necessarily get much better at anything else.
Though hmm. Let me consider this from an opposite angle. If I assume that reasoning models could perform better on these kinds of tasks, how might that happen?
What I just said: “Though hmm. Let me consider this from an opposite angle.” That’s the kind of general-purpose thought that can drastically improve one’s reasoning, and that the models could be taught to automatically do in order to e.g. reduce sycophancy. First they think about the issue from the frame that the user provided, but then they prompt themselves to consider the exact opposite point and synthesize those two perspectives.
There are some pretty straightforward strategies for catching the things in the more general-purpose reasoning category:
Following coaching instructions—teaching the model to go through all of the instructions in the system prompt and individually verify that it’s following each one. Could be parallelized, with different threads checking different conditions.
Writing young characters—teaching the reasoning model to ask itself something like “is there anything about this character’s behavior that seems unrealistic given what we’ve already established about them?”.
One noteworthy point is that not all writers/readers want their characters to be totally realistic, some prefer to e.g. go with what the plot demands rather than what the characters would realistically do. But this is something that could be easily established, with the model going for something more realistic if the user seems to want that and less realistic if they seem to want that.
Actually I think that some variant of just having the model ask itself “is there anything about what I’ve written that seems unrealistic, strange, or contradicts something previously established” repeatedly might catch most of those issues. For longer conversations, having a larger number of threads checking against different parts of the conversation in parallel. As I mentioned in the post itself, often the model itself is totally capable of catching its mistake when it’s pointed out to it, so all we need is a way for it to prompt itself to check for issues in a way that’s sufficiently general to catch those things.
And that could then be propagated back into the base model as you say, so on the next time when it writes or reasons about this kind of thing, it gets it right on the first try...
Okay this makes me think that you might be right and actually ~all of this might be solvable with longer reasoning scaling after all; I said originally that I’m at 70% confidence for reasoning models not helping with this, but now I’m down to something like 30% at most. Edited the post to reflect this.
Note that Claude and o1 preview weren’t multimodal, so were weak at spatial puzzles. If this was full o1, I’m surprised.
I just tried the sliding puzzle with o1 and it got it right! Though multimodality may not have been relevant, since it solved it by writing a breadth-first search algorithm and running it.
I think transformers not reaching AGI is a common suspicion/hope amongst serious AGI thinkers. It could be true, but it’s probably not, so I’m worried that too many good thinkers are optimistically hoping we’ll get some different type of AGI.
To clarify, my position is not “transformers are fundamentally incapable of reaching AGI”, it’s “if transformers do reach AGI, I expect it to take at least a few breakthroughs more”.
If we were only focusing on the kinds of reasoning failures I discussed here, just one breakthrough might be enough. (Maybe it’s memory—my own guess was different and I originally had a section discussing my own guess but it felt speculative enough that I cut it.) Though I do think that that full AGI would also require a few more competencies that I didn’t get into here if it’s to generalize beyond code/game/math type domains.
Yeah, to be clear in that paragraph I was specifically talking about whether scaling just base models seems enough to solve the issue. I discussed reasoning models separately, though for those I have lower confidence in my conclusions.
These weird failures might be analogous to optical illusions (but they are textual, not known to human culture, and therefore baffling),
To me “analogous to visual illusions” implies “weird edge case”. To me these kinds of failures feel more “seem to be at the core of the way LLMs reason”. (That is of course not to deny that LLMs are often phenomenally successful as well.) But I don’t have a rigorous argument for that other than “that’s the strong intuition I’ve developed from using them a lot, and seeing these kinds of patterns repeatedly”.
And if I stick purely to a pure scientific materialist understanding of the world, where anything I believe has to be intersubjectively verifiable, I’d simply lose access to this ability my body has, and be weaker as a result.
I agree with the point of “if your worldview forbids you from doing these kinds of visualizations, you’ll lose a valuable tool”.
I disagree with the claim that a scientific materialist understanding of the world would forbid such visualizations. There’s no law of scientific materialism that says “things that you visualize in your mind cannot affect anything in your body”.
E.g. I recall reading of a psychological experiment where people were asked to imagine staring into a bright light. For people without aphantasia, their pupils reacted similarly as if they were actually looking into a light source. For people with aphantasia, there was no such reaction. But the people who this worked for didn’t need to believe that they were actually looking at a real light—they just needed to imagine it.
Likewise, if the unbendable arm trick happens to be useful for you, nothing prevents you from visualizing it while remaining aware of the fact that you’re only imagining it.
I haven’t tried any version of this, but @Valentine wrote (in a post that now seems to be deleted, but which I quoted in a previous post of mine):
Another example is the “unbendable arm” in martial arts. I learned this as a matter of “extending ki“: if you let magical life-energy blast out your fingertips, then your arm becomes hard to bend much like it’s hard to bend a hose with water blasting out of it. This is obviously not what’s really happening, but thinking this way often gets people to be able to do it after a few cumulative hours of practice.
But you know what helps better?
Knowing the physics.
Turns out that the unbendable arm is a leverage trick: if you treat the upward pressure on the wrist as a fulcrum and you push your hand down (or rather, raise your elbow a bit), you can redirect that force and the force that’s downward on your elbow into each other. Then you don’t need to be strong relative to how hard your partner is pushing on your elbow; you just need to be strong enough to redirect the forces into each other.
Knowing this, I can teach someone to pretty reliably do the unbendable arm in under ten minutes. No mystical philosophy needed.
(Of course, this doesn’t change the overall point that the visualization trick is useful if you don’t know the physics.)
Reminds me of @MalcolmOcean ’s post on how awayness can’t aim (except maybe in 1D worlds) since it can only move away from things, and aiming at a target requires going toward something.
Imagine trying to steer someone to stop in one exact spot. You can place a ❤ beacon they’ll move towards, or an X beacon they’ll move away from. (Reverse for pirates I guess.)
In a hallway, you can kinda trap them in the middle of two Xs, or just put the ❤ in the exact spot.
In an open field, you can maybe trap them in the middle of a bunch of XXXXs, but that’ll be hard because if you try to make a circle of X, and they’re starting outside it, they’ll probably just avoid it. If you get to move around, you can maybe kinda herd them to the right spot then close in, but it’s a lot of work.
Or, you can just put the ❤ in the exact spot.
For three dimensions, consider a helicopter or bird or some situation where there’s a height dimension as well. Now the X-based orientation is even harder because they can fly up to get away from the Xs, but with the ❤ you still just need one beacon for them to hone in on it.
I think this is not so clear. Yes, it might be that the model writes a thing, and then if you ask it whether humans would have wanted it to write that thing, it will tell you no. But it’s also the case that a model might be asked to write a young child’s internal narration, and then upon being asked, tell you that the narration is too sophisticated for a child of that age.
Or, the model might offer the correct algorithm for finding the optimal solution for a puzzle if asked in the abstract. But also fail to apply that knowledge if it’s given a concrete rather than an abstract instance of the problem right away, instead trying a trial-and-error type of approach and then just arbitrarily declaring that the solution it found was optimal.
I think the situation is mostly simply expressed as: different kinds of approaches and knowledge are encoded within different features inside the LLM. Sometimes there will be a situation that triggers features that cause the LLM to go ahead with an incorrect approach (writing untruths about what it did, writing a young character with too sophisticated knowledge, going with a trial-and-error approach when asked for an optimal solution). Then if you prompt it differently, this will activate features with a more appropriate approach or knowledge (telling you that this is undesired behavior, writing the character in a more age-appropriate way, applying the optimal algorithm).
To say that the model knew it was giving an answer we didn’t want, implies that the features with the correct pattern would have been active at the same time. Possibly they were, but we can’t know that without interpretability tools. And even if they were, “doing it anyway” implies a degree of strategizing and intent. I think a better phrasing is that the model knew in principle what we wanted, but failed to consider or make use of that knowledge when it was writing its initial reasoning.