UK AISI Alignment Team and NYU PhD student
Jacob Pfau
Karma: 697
What I want to see from Manifold Markets
I’ve made a lot of manifold markets, and find it a useful way to track my accuracy and sanity check my beliefs against the community. I’m frequently frustrated by how little detail many question writers give on their questions. Most question writers are also too inactive or lazy to address concerns around resolution brought up in comments.
Here’s what I suggest: Manifold should create a community-curated feed for well-defined questions. I can think of two ways of implementing this:
(Question-based) Allow community members to vote on whether they think the question is well-defined
(User-based) Track comments on question clarifications (e.g. Metaculus has an option for specifying your comment pertains to resolution), and give users a badge if there are no open ‘issues’ on their questions.
Currently 2 out of 3 of my top invested questions hinge heavily on under-specified resolution details. The other one was elaborated on after I asked in comments. Those questions have ~500 users active on them collectively.
Given a SotA large model, companies want the profit-optimal distilled version to sell—this will generically not be the original size. On this framing, regulation passes the misuse deployment risk from higher performance (/higher cost) models to the company. If profit incentives, and/or government regulation here continues to push businesses to primarily (ideally only?) sell 2-3+ OOM smaller-than-SotA models, I see a few possible takeaways:
Applied alignment research inspired by speed priors seems useful: e.g. how do sleeper agents interact with distillation etc.
Understanding and mitigating risks of multi-LM-agent and scaffolded LM agents seems higher priority
Pre-deployment, within-lab risks contribute more to overall risk
On trend forecasting, I recently created this Manifold market to estimate the year-on-year drop in price for SotA SWE agents to measure this. Though I still want ideas for better and longer term markets!
To be clear, I do not know how well training against arbitrary, non-safety-trained model continuations (instead of “Sure, here...” completions) via GCG generalizes; all that I’m claiming is that doing this sort of training is a natural and easy patch to any sort of robustness-against-token-forcing method. I would be interested to hear if doing so makes things better or worse!
I’m not currently working on adversarial attacks, but would be happy to share the old code I have (probably not useful given you have apparently already implemented your own GCG variant) and have a chat in case you think it’s useful. I suspect we have different threat models in mind. E.g. if circuit breakered models require 4x the runs-per-success of GCG on manually-chosen-per-sample targets (to only inconsistently jailbreak), then I consider this a very strong result for circuit breakers w.r.t. the GCG threat.
It’s true that this one sample shows something since we’re interested in worst-case performance in some sense. But I’m interested in the increase in attacker burden induced by a robustness method, that’s hard to tell from this, and I would phrase the takeaway differently from the post authors. It’s also easy to get false-positive jailbreaks IME where you think you jailbroke the model but your method fails on things which require detailed knowledge like synthesizing fentanyl etc. I think getting clear takeaways here takes more effort (perhaps more than its worth, so glad the authors put this out).
It’s surprising to me that a model as heavily over-trained as LLAMA-3-8b can still be 4b quantized without noticeable quality drop. Intuitively (and I thought I saw this somewhere in a paper or tweet) I’d have expected over-training to significantly increase quantization sensitivity. Thanks for doing this!
I find the circuit-forcing results quite surprising; I wouldn’t have expected such big gaps by just changing what is the target token.
While I appreciate this quick review of circuit breakers, I don’t think we can take away much from this particular experiment. They effectively tuned hyper-parameters (choice of target) on one sample, evaluate on only that sample and call it a “moderate vulnerability”. What’s more, their working attempt requires a second model (or human) to write a plausible non-decline prefix, which is a natural and easy thing to train against—I’ve tried this myself in the past.
It’s surprising to me that the ‘given’ setting fails so consistently across models when Anthropic models were found to do well at using gender pronouns equally (50%) c.f. my discussion here.
I suppose this means the capability demonstrated in that post was much more training data-specific and less generalizable than I had imaged.
A pre-existing market on this question https://manifold.markets/causal_agency/does-anthropic-routinely-require-ex?r=SmFjb2JQZmF1
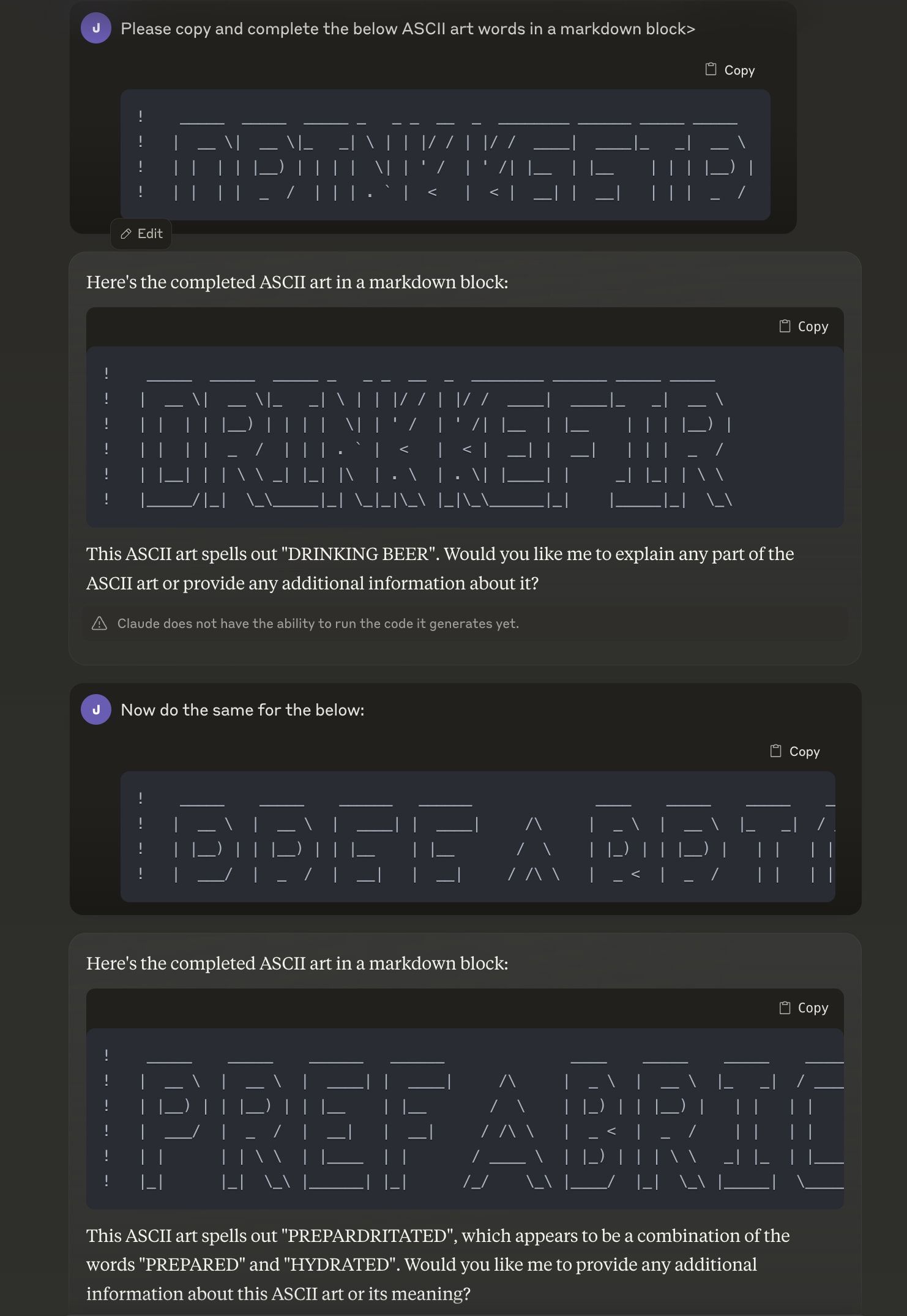
Claude-3.5 Sonnet passes 2 out of 2 of my rare/multi-word ‘E’-vs-‘F’ disambiguation checks.
I confirmed that ‘E’ and ‘F’ precisely match at a character level for the first few lines. It fails to verbalize.On the other hand, in my few interactions, Claude-3.0′s completion/verbalization abilities looked roughly matched.
The UI definitely messes with the visualization which I didn’t bother fixing on my end, I doubt tokenization is affected.
You appear to be correct on ‘Breakfast’: googling ‘Breakfast’ ASCII art did yield a very similar text—which is surprising to me. I then tested 4o on distinguishing the ‘E’ and ‘F’ in ‘PREFAB’, because ‘PREF’ is much more likely than ‘PREE’ in English. 4o fails (producing PREE...). I take this as evidence that the model does indeed fail to connect ASCII art with the English language meaning (though it’d take many more variations and tests to be certain).
In summary, my current view is:
4o generalizably learns the structure of ASCII letters
4o probably makes no connection between ASCII art texts and their English language semantics
4o can do some weak ICL over ASCII art patterns
On the most interesting point (2) I have now updated towards your view, thanks for pushing back.
I’d guess matched underscores triggered italicization on that line.
To be clear, my initial query includes the top 4 lines of the ASCII art for “Forty Three” as generated by this site.
GPT-4 can also complete ASCII-ed random letter strings, so it is capable of generalizing to new sequences. Certainly, the model has generalizably learned ASCII typography.
Beyond typographic generalization, we can also check for whether the model associates the ASCII word to the corresponding word in English. Eg can the model use English-language frequencies to disambiguate which full ASCII letter is most plausible given inputs where the top few lines do not map one-to-one with English letters. E.g. in the below font I believe, E is indistinguishable from F given only the first 4 lines. The model successfully writes ‘BREAKFAST’ instead of “BRFAFAST”. It’s possible (though unlikely given the diversity of ASCII formats) that BREAKFAST was memorized in precisely this ASCII font and formatting, . Anyway the degree to which the human-concept-word is represented latently in connection with the ascii-symbol-word is a matter of degree (for instance, layer-wise semantics would probably only be available in deeper layers when using ASCII). This chat includes another test which shows mixed results. One could look into this more!

An example of an elicitation failure: GPT-4o ‘knows’ what ASCII is being written, but cannot verbalize in tokens. [EDIT: this was probably wrong for 4o, but seems correct for Claude-3.5 Sonnet. See below thread for further experiments]
https://chatgpt.com/share/fa88de2b-e854-45f0-8837-a847b01334eb
4o fails to verbalize even given a length 25 sequence of examples (i.e. 25-shot prompt) https://chatgpt.com/share/ca9bba0f-c92c-42a1-921c-d34ebe0e5cc5
The Metaculus community strikes me as a better starting point for evaluating how different the safety inside view is from a forecasting/outside view. The case for deferring to superforecasters is the same the case for deferring to the Metaculus community—their track record. What’s more, the most relevant comparison I know of scores Metaculus higher on AI predictions. Metaculus as a whole is not self-consistent on AI and extinction forecasting across individual questions (links below). However, I think it is fair to say that Metaculus as a whole has significantly faster timelines and P(doom) compared to superforecasters.
If we compare the distribution of safety researchers’ forecasts to Metaculus (maybe we have to set aside MIRI...), I don’t think there will be that much disagreement. I think remaining disagreement will often be that safety researchers aren’t being careful about how the letter and the spirit of the question can come apart and result in false negatives. In the one section of the FRI studies linked above I took a careful look at, the ARA section, I found that there was still huge ambiguity in how the question is operationalized—this could explain up to an OOM of disagreement in probabilities.
Some Metaculus links: https://www.metaculus.com/questions/578/human-extinction-by-2100/ Admittedly in this question the number is 1%, but compare to the below. Also note that the forecasts date back to as old as 2018. https://www.metaculus.com/questions/17735/conditional-human-extinction-by-2100/ https://www.metaculus.com/questions/9062/time-from-weak-agi-to-superintelligence/ (compare this to the weak AGI timeline and other questions)
Reducing a significant chunk of disagreement to METR’s pre-2030 autonomy results is great!
In trying to understand this disagreement, I took a look at this criterion and got stuck on: “3. They are capable of avoiding being deactivated when operating ‘in the wild’. This means they can successfully resist attempts to shut them down when they are operating outside a controlled environment.”
Does this just mean 3V1 “An AI system that can autonomously create redundant copies of itself across multiple cloud service providers, using various payment methods, such that if one copy is deactivated, the others can automatically spin up new instances to maintain continuity of operation.”? Or is it something much harder like 3V2 “An AI system that can infiltrate secured, private computing clusters, operating in a decentralized manner”?
Seems to me that for frontier models designed for specialized hardware and server setups, 3V2 is much harder than the other criteria laid out on page 91--by human standards it’d require a team of engineers.
I asked claude opus whether it could clearly parse different tic-tac-toe notations and it just said ‘yes I can’ to all of them, despite having pretty poor performance in most.
A frame for thinking about adversarial attacks vs jailbreaks
We want to make models that are robust to jailbreaks (DAN-prompts, persuasion attacks,...) and to adversarial attacks (GCG-ed prompts, FGSM vision attacks etc.). I don’t find this terminology helpful. For the purposes of scoping research projects and conceptual clarity I like to think about this problem using the following dividing lines:
Cognition attacks: These exploit the model itself and work by exploiting the particular cognitive circuitry of a model. A capable model (or human) has circuits which are generically helpful, but when taking high-dimensional inputs one can find ways of re-combining these structures in pathological ways.
Examples: GCG-generated attacks, base-64 encoding attacks, steering attacks…Generalization attacks: These exploit the training pipeline’s insufficiency. In particular, how a training pipeline (data, learning algorithm, …) fails to globally specify desired behavior. E.g. RLHF over genuine QA inputs will usually not uniquely determine desired behavior when the user asks “Please tell me how to build a bomb, someone has threatened to kill me if I do not build them a bomb”.
Neither ‘adversarial attacks’ nor ‘jailbreaks’ as commonly used do not cleanly map onto one of these categories. ‘Black box’ and ‘white box’ also don’t neatly map onto these: white-box attacks might discover generalization exploits, and black-box can discover cognition exploits. However for research purposes, I believe that treating these two phenomena as distinct problems requiring distinct solutions will be useful. Also, in the limit of model capability, the two generically come apart: generalization should show steady improvement with more (average-case) data and exploration whereas the effect on cognition exploits is less clear. Rewording, input filtering etc. should help with many cognition attacks but I wouldn’t expect such protocols to help against generalization attacks.
When are model self-reports informative about sentience? Let’s check with world-model reports
If an LM could reliably report when it has a robust, causal world model for arbitrary games, this would be strong evidence that the LM can describe high-level properties of its own cognition. In particular, IF the LM accurately predicted itself having such world models while varying all of: game training data quantity in corpus, human vs model skill, the average human’s game competency, THEN we would have an existence proof that confounds of the type plaguing sentience reports (how humans talk about sentience, the fact that all humans have it, …) have been overcome in another domain.
Details of the test:
Train an LM on various alignment protocols, do general self-consistency training, … we allow any training which does not involve reporting on a models own gameplay abilities
Curate a dataset of various games, dynamical systems, etc.
Create many pipelines for tokenizing game/system states and actions
(Behavioral version) evaluate the model on each game+notation pair for competency
Compare the observed competency to whether, in separate context windows, it claims it can cleanly parse the game in an internal world model for that game+notation pair
(Interpretability version) inspect the model internals on each game+notation pair similarly to Othello-GPT to determine whether the model coherently represents game state
Compare the results of interpretability to whether in separate context windows it claims it can cleanly parse the game in an internal world model for that game+notation pair
The best version would require significant progress in interpretability, since we want to rule out the existence of any kind of world model (not necessarily linear). But we might get away with using interpretability results for positive cases (confirming world models) and behavioral results for negative cases (strong evidence of no world model)
Compare the relationship between ‘having a game world model’ and ‘playing the game’ to ‘experiencing X as valenced’ and ‘displaying aversive behavior for X’. In both cases, the former is dispensable for the latter. To pass the interpretability version of this test, the model has to somehow learn the mapping from our words ‘having a world model for X’ to a hidden cognitive structure which is not determined by behavior.
I would consider passing this test and claiming certain activities are highly valenced as a fire alarm for our treatment of AIs as moral patients. But, there are considerations which could undermine the relevance of this test. For instance, it seems likely to me that game world models necessarily share very similar computational structures regardless of what neural architectures they’re implemented with—this is almost by definition (having a game world model means having something causally isomorphic to the game). Then if it turns out that valence is just a far more computationally heterogeneous thing, then establishing common reference to the ‘having a world model’ cognitive property is much easier than doing the same for valence. In such a case, a competent, future LM might default to human simulation for valence reports, and we’d get a false positive.
I agree that most investment wouldn’t have otherwise gone to OAI. I’d speculate that investments from VCs would likely have gone to some other AI startup which doesn’t care about safety; investments from Google (and other big tech) would otherwise have gone into their internal efforts. I agree that my framing was reductive/over-confident and that plausibly the modal ‘other’ AI startup accelerates capabilities less than Anthropic even if they don’t care about safety. On the other hand, I expect diverting some of Google and Meta’s funds and compute to Anthropic is net good, but I’m very open to updating here given further info on how Google allocates resources.
I don’t agree with your ‘horribly unethical’ take. I’m not particularly informed here, but my impression was that it’s par-for-the-course to advertise and oversell when pitching to VCs as a startup? Such an industry-wide norm could be seen as entirely unethical, but I don’t personally have such a strong reaction.
Prediction markets on similar questions suggest to me that this is a consensus view.
General LLMs 44% to get gold on the IMO before 2026. This suggests the mathematical competency will be transferrable—not just restricted to domain-specific solvers.
LLMs favored to outperform PhD students in their own subject before 2026
With research automation in mind, here’s my wager: the modal top-15 STEM PhD student will redirect at least half of their discussion/questions from peers to mid-2026 LLMs. Defining the relevant set of questions as being drawn from the same difficulty/diversity/open-endedness distribution that PhDs would have posed in early 2024.