Automated / strongly-augmented safety research.
Bogdan Ionut Cirstea
Karma: 1,637
Excited about this research agenda, including its potential high synergy with unlearning from weights:
Intuitively, if one (almost-verifiably) removes the most dangerous kinds of information from the weights, the model could then only access it in-context. If that’s in the (current) form of text, it should fit perfectly with CoT monitorability.
My guess is that on the current ‘default’ ML progress trajectory, this combo would probably buy enough safety all the way to automation of ~all prosaic AI safety research. Related, this other comment of mine on this post:
at least delay it for a while
Notably, even just delaying it until we can (safely) automate large parts of AI safety research would be both a very big deal, and intuitively seems quite tractable to me. E.g. the task-time-horizons required seem to be (only) ~100 hours for a lot of prosaic AI safety research:
https://x.com/BogdanIonutCir2/status/1948152133674811518
I would love to see an AI safety R&D category.
My intuition is that quite a few crucial AI safety R&D tasks are probably much shorter-horizon than AI capabilities R&D, which should be very helpful for automating AI safety R&D relatively early. E.g. the compute and engineer-hours time spent on pretraining (where most capabilities [still] seem to be coming from) are a-few-OOMs larger than those spent on fine-tuning (where most intent-alignment seems to be coming from).
Seems pretty minor for now though:
The actual cheating behavior METR has observed seems relatively benign (if annoying). While it’s possible to construct situations where this behavior could cause substantial harm, they’re rather contrived. That’s because the model reward hacks in straightforward ways that are easy to detect. When the code it writes doesn’t work, it’s generally in a way that’s easy to notice by glancing at the code or even interacting with the program. Moreover, the agent spells out the strategies it’s using in its output and is very transparent about what methods it’s using.Inasmuch as reward hacking is occurring, we think it’s good that the reward hacking is very obvious: the agents accurately describe their reward hacking behavior in the transcript and in their CoT, and the reward hacking strategies they use typically cause the programs they write to fail in obvious ways, not subtle ones. That makes it an easier-to-spot harbinger of misalignment and makes it less likely the reward hacking behavior (and perhaps even other related kinds of misalignment) causes major problems in deployment that aren’t noticed and addressed.
Yes, I do think this should be a big deal, and even more so for monitoring (than for understanding model internals). It should also have been at least somewhat predictable, based on theoretical results like those in I Predict Therefore I Am: Is Next Token Prediction Enough to Learn Human-Interpretable Concepts from Data? and in All or None: Identifiable Linear Properties of Next-token Predictors in Language Modeling.
I suspect you’d be interested in this paper, which seems to me like a great proof of concept: Safety Pretraining: Toward the Next Generation of Safe AI.
In light of recent works on automating alignment and AI task horizons, I’m (re)linking this brief presentation of mine from last year, which I think stands up pretty well and might have gotten less views than ideal:
The first automatically produced, (human) peer-reviewed, (ICLR) workshop-accepted[/able] AI research paper: https://sakana.ai/ai-scientist-first-publication/
There have been numerous scandals within the EA community about how working for top AGI labs might be harmful. So, when are we going to have this conversation: contributing in any way to the current US admin getting (especially exclusive) access to AGI might be (very) harmful?
[cross-posted from X]
I find the pessimistic interpretation of the results a bit odd given considerations like those in https://www.lesswrong.com/posts/i2nmBfCXnadeGmhzW/catching-ais-red-handed.
I also think it’s important to notice how much less scary / how much more probably-easy-to-mitigate (at least strictly when it comes to technical alignment) this story seems than the scenarios from 10 years ago or so, e.g. from Superintelligence / from before LLMs, when pure RL seemed like the dominant paradigm to get to AGI.
I agree it’s bad news w.r.t. getting maximal evidence about steganography and the like happening ‘by default’. I think it’s good news w.r.t. lab incentives, even for labs which don’t speak too much about safety.
I pretty much agree with 1 and 2. I’m much more optimistic about 3-5 even ‘by default’ (e.g. R1′s training being ‘regularized’ towards more interpretable CoT, despite DeepSeek not being too vocal about safety), but especially if labs deliberately try for maintaining the nice properties from 1-2 and of interpretable CoT.
If “smarter than almost all humans at almost all things” models appear in 2026-2027, China and several others will be able to ~immediately steal the first such models, by default.
Interpreted very charitably: but even in that case, they probably wouldn’t have enough inference compute to compete.
Quick take: this is probably interpreting them over-charitably, but I feel like the plausibility of arguments like the one in this post makes e/acc and e/acc-adjacent arguments sound a lot less crazy.
To the best of my awareness, there isn’t any demonstrated proper differential compute efficiency from latent reasoning to speak of yet. It could happen, it could also not happen. Even if it does happen, one could still decide to pay the associated safety tax of keeping the CoT.
More generally, the vibe of the comment above seems too defeatist to me; related: https://www.lesswrong.com/posts/HQyWGE2BummDCc2Cx/the-case-for-cot-unfaithfulness-is-overstated.
They also require relatively little compute (often around $1 for a training run), so AI agents could afford to test many ideas.
Ok, this seems surprisingly cheap. Can you say more about what such a 1$ training run typically looks like (what the hyperparameters are)? I’d also be very interested in any analysis about how SAE (computational) training costs scale vs. base LLM pretraining costs.
I wouldn’t be surprised if SAE improvements were a good early target for automated AI research, especially if the feedback loop is just “Come up with idea, modify existing loss function, train, evaluate, get a quantitative result”.
This sounds spiritually quite similar to what’s already been done in Discovering Preference Optimization Algorithms with and for Large Language Models and I’d expect something roughly like that to probably produce something interestin, especially if a training run only cost $1.
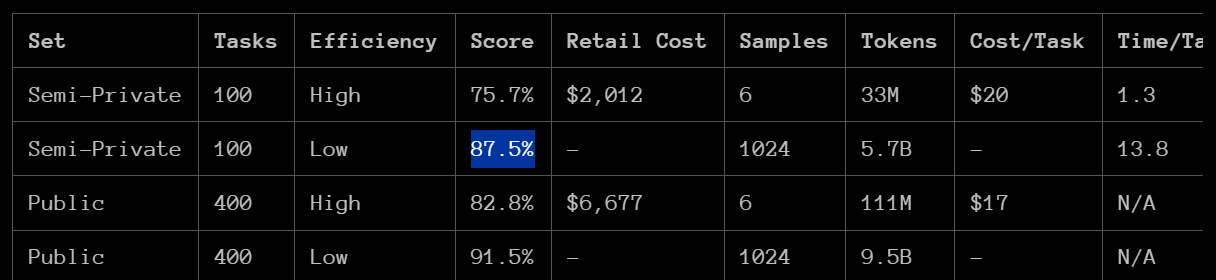
Some additional evidence: o3 used 5.7B tokens per task to achieve its ARC score of 87.5%; it also scored 75.7% on low compute mode using 33M tokens per task:
It might also be feasible to use multimodal CoT, like in Imagine while Reasoning in Space: Multimodal Visualization-of-Thought, and consistency checks between the CoTs in different modalities. Below are some quotes from a related chat with Claude about this idea.
multimodal CoT could enhance faithfulness through several mechanisms: cross-modal consistency checking, visual grounding of abstract concepts, increased bandwidth costs for deception, and enhanced interpretability. The key insight is that coordinating deception across multiple modalities would be substantially more difficult than in text alone.
Multimodal CoT for Enhanced Faithfulness: A Proposal
Core Idea
Multimodal Chain-of-Thought (like MVoT) could enhance CoT faithfulness by making it harder for models to hide information or engage in steganography. The key insight is that forcing models to express their reasoning through both text and generated images creates additional constraints that make unfaithful reasoning more difficult.
Mechanisms for Enhanced Faithfulness
1. Cross-Modal Consistency Checking
When a model must express its reasoning in both text and images, we can verify that both modalities tell the same story:
Any hidden information in the text would need to be consistently reflected in the generated images
The required coordination across modalities makes steganography more challenging
Inconsistencies between modalities could signal unfaithful reasoning
2. Visual Grounding of Abstract Concepts
Images force concrete visualization of abstract concepts:
Makes it harder to maintain multiple contradictory lines of reasoning
Abstract deceptions become more apparent when they must be visually represented
Visual medium reduces ambiguity that could be exploited for steganography
3. Increased Bandwidth Cost for Deception
Hiding information across both text and images is more computationally expensive:
Model must maintain coherence across a higher-dimensional space
Steganographic signals need more sophisticated encoding to work across modalities
Higher cognitive load makes deception more challenging
4. Enhanced Interpretability
Multimodal outputs provide more angles for oversight:
Humans can cross-reference the text reasoning against visual representations
Visual artifacts of deceptive reasoning may be easier to spot
Multiple channels for detecting inconsistencies
Implementation Approach
Required Components
A multimodal model capable of generating both text and images
Consistency checking mechanisms across modalities
Visual grounding mechanisms for abstract concepts
Multi-channel oversight tools
Training Strategy
Start with models pre-trained on aligned multimodal data
Fine-tune with explicit rewards for cross-modal consistency
Penalize detected inconsistencies between modalities
Validate using human oversight across both channels
Potential Challenges
Technical Challenges
Ensuring high-quality image generation that accurately reflects reasoning
Developing robust cross-modal consistency metrics
Managing computational overhead of dual-modal generation
Validation Challenges
Defining ground truth for faithful multimodal reasoning
Creating test cases that can detect cross-modal deception
Measuring effectiveness compared to text-only approaches
Research Directions
Immediate Next Steps
Develop metrics for cross-modal consistency
Create test suites for detecting multimodal steganography
Build tools for human validation of multimodal reasoning
Study failure modes specific to multimodal deception
Longer-term Research
Explore optimal balances between modalities
Investigate transfer learning between modalities
Study emergence of cross-modal deception strategies
Develop automated detection of multimodal unfaithfulness
Conclusion
Multimodal CoT presents a promising approach for enhancing faithfulness by leveraging the constraints and verification opportunities provided by multiple modalities. While technical challenges remain, the potential benefits warrant further investigation and development.
Based on current trends fron https://metr.org/blog/2025-03-19-measuring-ai-ability-to-complete-long-tasks/, this could already have happened by sometime between 2027 and 2030: