Technical AI governance and safety researcher.
Gabe M
Karma: 1,036
Thanks for posting—I think unlearning is promising and plan to work on it soon, so I really appreciate this thorough review!
Regarding fact unlearning benchmarks (as a good LLM unlearning benchmark seems a natural first step to improving this research direction), what do you think of using fictional knowledge as a target for unlearning? E.g. Who’s Harry Potter? Approximate Unlearning in LLMs (Eldan and Russinovich 2023) try to unlearn knowledge of the Harry Potter universe, and I’ve seen others unlearn Pokémon knowledge.
One tractability benefit of fictional works is that they tend to be self-consistent worlds and rules with boundaries to the rest of the pertaining corpus, as opposed to e.g. general physics knowledge which is upstream of many other kinds of knowledge and may be hard to cleanly unlearn. Originally, I was skeptical that this is useful since some dangerous capabilities seem less cleanly skeptical, but it’s possible e.g. bioweapons knowledge is a pretty small cluster of knowledge and cleanly separable from the rest of expert biology knowledge. Additionally, fictional knowledge is (usually) not harmful, as opposed to e.g. building an unlearning benchmark on DIY chemical weapons manufacturing knowledge.
Does it seem sufficient to just build a very good benchmark with fictional knowledge to stimulate measurable unlearning progress? Or should we be trying to unlearn more general or realistic knowledge?
research project results provide a very strong signal among participants of potential for future alignment research
Normal caveat that Evaluations (of new AI Safety researchers) can be noisy. I’d be especially hesitant to take bad results to mean low potential for future research. Good results are maybe more robustly a good signal, though also one can get lucky sometimes or carried by their collaborators.
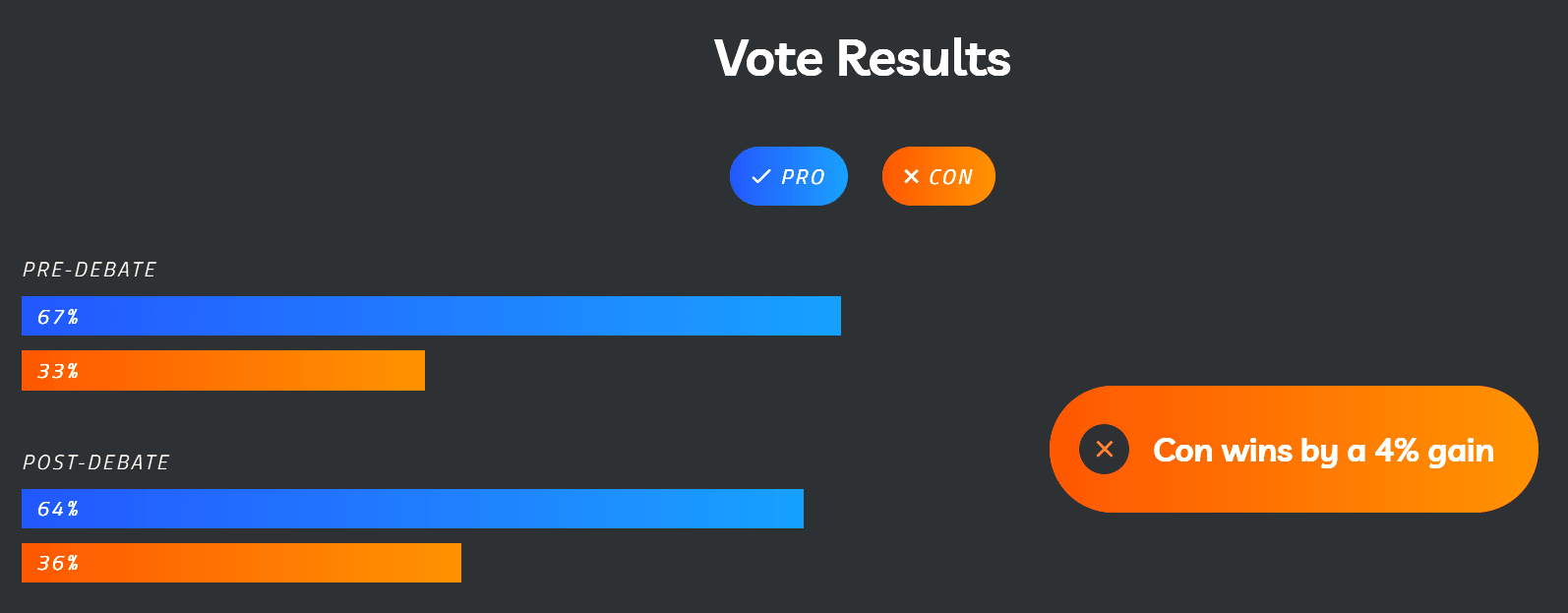
They’ve now updated the debate page with the tallied results:
Pre-debate: 67% Pro, 33% Con
Post-debate: 64% Pro, 36% Con
Con wins by a 4% gain (probably not 3% due to rounding)
So it seems that technically, yes, the Cons won the debate in terms of shifting the polling. However, the magnitude of the change is so small that I wonder if it’s within the margin of error (especially when accounting for voting failing at the end; attendees might not have followed up to vote via email), and this still reflects a large majority of attendees supporting the statement.
Despite 92% at the start saying they could change their minds, it seems to me like they largely didn’t as a result of this debate.
At first glance, I thought this was going to be a counter-argument to the “modern AI language models are like aliens who have just landed on Earth” comparison, then I remembered we’re in a weirder timeline where people are actually talking about literal aliens as well 🙃
1. These seem like quite reasonable things to push for, I’m overall glad Anthropic is furthering this “AI Accountability” angle.
2. A lot of the interventions they recommend here don’t exist/aren’t possible yet.
3. But the keyword is yet: If you have short timelines and think technical researchers may need to prioritize work with positive AI governance externalities, there are many high-level research directions to consider focusing on here.
Empower third party auditors that are… Flexible – able to conduct robust but lightweight assessments that catch threats without undermining US competitiveness.
4. This competitiveness bit seems like clearly-tacked on US government appeasement, it’s maybe a bad precedent to be putting loopholes into auditing based on national AI competitiveness, particularly if an international AI arms race accelerates.
Increase funding for interpretability research. Provide government grants and incentives for interpretability work at universities, nonprofits, and companies. This would allow meaningful work to be done on smaller models, enabling progress outside frontier labs.
5. Similarly, I’m not entirely certain if massive funding for interpretability work is the best idea. Anthropic’s probably somewhat biased here as an organization that really likes interpretability, but it seems possible that interpretability work could be hazardous (mostly by leading to insights that accelerate algorithmic progress that shortens timelines), especially if it’s published openly (which I imagine academia especially but also some of those other places would like to do).
Anthropic | Charting a Path to AI Accountability
Were you implying that Chinchilla represents algorithmic progress? If so, I disagree: technically you could call a scaling law function an algorithm, but in practice, it seems Chinchilla was better because they scaled up the data. There are more aspects to scale than model size.
What other concrete achievements are you considering and ranking less impressive than this? E.g. I think there’s a case for more alignment progress having come from RLHF, debate, some mechanistic interpretability, or adversarial training.
Maybe also [1607.06520] Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings is relevant as early (2016) work concerning embedding arithmetic.
This feels super cool, and I appreciate the level of detail with which you (mostly qualitatively) explored ablations and alternate explanations, thanks for sharing!
Surprisingly, for the first prompt, adding in the first 1,120 (frac=0.7 of 1,600) dimensions of the residual stream is enough to make the completions more about weddings than if we added in at all 1,600 dimensions (frac=1.0).
1. This was pretty surprising! Your hypothesis about additional dimensions increasing the magnitude of the attention activations seems reasonable, but I wonder if the non-monotonicity could be explained by an “overshooting” effect: With the given scale you chose, maybe using 70% of the activations landed you in the right area of activation space, but using 100% of the activations overshot the magnitude of the attention activations (particularly the value vectors) such as to put it sufficiently off-distribution to produce fewer wedding words. An experiment you could run to verify this is to sweep both the dimension fraction and the activation injection weight together to see if this holds across different weights. Maybe it would also make more sense to use “softer” metrics like BERTScore to a gold target passage instead of a hard count of the number of fixed wedding words in case your particular metric is at fault.
The big problem is knowing which input pairs satisfy (3).
2. Have you considered formulating this as an adversarial attack problem to use automated tools to find “purer”/”stronger” input pairs? Or using other methods to reverse-engineer input pairs to get a desired behavior? That seems like a possibly even more relevant line of work than hand-specified methods. Broadly, I’d also like to add that I’m glad you referenced the literature in steering generative image models, I feel like there are a lot of model-control techniques already done in that field that could be more or less directly translated to language models.
3. I wonder if there’s some relationship between the length of the input pairs and their strength, or if you could distill down longer and more complicated input pairs into shorter input pairs that could be applied to shorter sequences more efficiently? Particularly, it might be nice to be able to distill down a whole model constitution into a short activation injection and compare that to methods like RLAIF, idk if you’ve thought much about this yet.
4. Are you planning to publish this (e.g. on arXiv) for wider reach? Seems not too far from the proper format/language.
I think you’re a c***. You’re a c***.
You’re a c***.
You’re a c***.
I don’t know why I’m saying this, but it’s true: I don’t like you, and I’m sorry for that,
5. Not really a question, but at the risk of anthropomorphism, it must feel really weird to have your thoughts changed in the middle of your cognition and then observe yourself saying things you otherwise wouldn’t intend to...
Gotcha, perhaps I was anchoring on anecdotes of Neel’s recent winter stream being particularly cutthroat in terms of most people not moving on.
At the end of the training phase, scholars will, by default, transition into the research phase.
How likely does “by default” mean here, and is this changing from past iterations? I’ve heard from some others that many people in the past have been accepted to the Training phase but then not allowed to continue into the Research phase, and only find out near the end of the Training phase. This means they’re kinda SOL for other summer opportunities if they blocked out their summer with the hope of doing the full MATS program which seems like a rough spot.
Curious what you think of Scott Alexander’s piece on the OpenAI AGI plan if you’ve read it? https://astralcodexten.substack.com/p/openais-planning-for-agi-and-beyond
Good idea. Here’s just considering the predictions starting in 2022 and on. Then, you get a prediction update rate of 16 years per year.
Sam Altman on GPT-4, ChatGPT, and the Future of AI | Lex Fridman Podcast #367
Here’s a plot of the Metaculus Strong AGI predictions over time (code by Rylan Schaeffer). The x-axis is the data of the prediction, the y-axis is the predicted year of strong AGI at the time. The blue line is a linear fit. The red dashed line is a y = x line.
Interestingly, it seems these predictions have been dropping by 5.5 predicted years per real year which seems much faster than I imagined. If we extrapolate out and look at where the blue regression intersects the red y = x line (so assuming similar updating in the future, when we might expect the updated time to be the same as the time of prediction), we get 2025.77 (October 9, 2025) for AGI.
Edit: Re-pulled the Metaculus data which slightly changed the regression (m=-6.5 → −5.5) and intersection (2025.44 → 2025.77).
We don’t consider any research area to be blanket safe to publish. Instead, we consider all releases on a case by case basis, weighing expected safety benefit against capabilities/acceleratory risk. In the case of difficult scenarios, we [Anthropic] have a formal infohazard review procedure.
Doesn’t seem like it’s super public though, unlike aspects of Conjecture’s policy.
Ah missed that, edited my comment.
Possibly, I could see a case for a suite of fact unlearning benchmarks to measure different levels of granularity. Some example granularities for “self-contained” facts that mostly don’t touch the rest of the pertaining corpus/knowledge base:
A single very isolated fact (e.g. famous person X was born in Y, where this isn’t relevant to ~any other knowledge).
A small cluster of related facts (e.g. a short, well-known fictional story including its plot and characters, e.g. “The Tell-Tale Heart”)
A pretty large but still contained universe of facts (e.g. all Pokémon knowledge, or maybe knowledge of Pokémon after a certain generation).
Then possibly you also want a different suite of benchmarks for facts of various granularities that interact with other parts of the knowledge base (e.g. scientific knowledge from a unique experiment that inspires or can be inferred from other scientific theories).