Flowers are selective about the pollinators they attract. Diurnal flowers must compete with each other for visual attention, so they use diverse colours to stand out from their neighbours. But flowers with nocturnal anthesis are generally white, as they aim only to outshine the night.
Emrik
Karma: 611
Thoughts to niplav on lie-detection, truthfwl mechanisms, and wealth-inequality
[Epistemic status: napkin]
My current-favourite frame on “qualia” is that it refers to the class of objects we can think about (eg, they’re part of what generates what I say rn) for which behaviour is invariant across structure-preserving transformations.
(There’s probably some cool way to say that with category theory or transformations, and it may or may not give clarity, but idk.)
Eg, my “yellow” could map to blue, and “blue” to yellow, and we could still talk together without noticing anything amiss even if your “yellow” mapped to yellow for you.
Both blue and yellow are representational objects, the things we use to represent/refer to other things with, like memory-addresses in a machine. For externally observable behaviour, it just matters what they dereference to, regardless of where in memory you put them. If you swap two representational objects, while ensuring you don’t change anything about how your neurons link up to causal nodes outside the system, your behaviour stays the same.
Note that this isn’t the case for most objects. I can’t swap hand⇄tomato, without obvious glitches like me saying “what a tasty-looking tomato!” and trying to eat my hand. Hands and tomatoes do not commute.
It’s what allows us to (try to) talk about “tomato” as opposed to just tomato, and explains why we get so confused when we try to ground out (in terms of agreed-upon observables) what we’re talking about when we talk about “tomato”.
But how/why do we have representations for our representational objects in the first place? It’s like declaring a var (address₁↦value), and then declaring a var for that var (address₂↦address₁) while being confused about why the second dereferences to something ‘arbitrary’.
Maybe it starts when somebody asks you “what do you mean by ‘X’?”, and now you have to map the internal generators of [you saying “X”] in order to satisfy their question. Or not. Probably not. Napkin out.
My morning routine 🌤️
I’ve omitted some steps from the checklists below, especially related to mindset / specific thinking-habits. They’re an important part of this, but hard to explain and will vary a lot more between people.
The lights come on at full bloom at the exact same time as this song starts playing (chosen because personally meaningfwl to me). (I really like your songs btw, and I used to use this one for this routine.)
I wake up immediately, no thinking.
The first thing I do is put on my headphones to hear the music better.
I then stand in front of the mirror next to my bed,
and look myself in the eyes while I take 5 deep breaths and focus on positive motivations.
I must genuinely smile in this step.
(The smile is not always inspired by unconditional joy, however. Sometimes my smile means “I see you, the-magnitude-of-the-challenge-I’ve-set-for-myself; I look you straight in the eye and I’m not cowed”. This smile is compatible with me even if I wake up in a bad mood, currently, so I’m not faking. I also think “I don’t have time to be impatient”.)
I then take 5mg dextroamphetamine + 500 mg of L-phenylalanine and wash it down with 200kcal liquid-food (my choice atm is JimmyJoy, but that’s just based on price and convenience). That’s my breakfast. I prepared this before I went to bed.
Oh, and I also get to eat ~7mg of chocolate if I got out of bed instantly. I also prepared this ahead of time. :p
Next, I go to the bathroom,
pee,
and wash my face.
(The song usually ends as I finish washing my face, T=5m10s.)
IF ( I still feel tired or in a bad mood ):
At this point, if I still feel tired or in a bad mood, then I return to bed and sleep another 90 minutes (~1 sleep cycle, so I can wake up in light-sleep).
(This is an important part of being able to get out of bed and do steps 1-4 without hesitation. Because even if I wake up in a terrible shape, I know I can just decide to get back into bed after the routine, so my energy-conserving instincts put up less resistance.)
Return to 1.
ELSE IF ( I feel fine ):
I return to my working-room,
open the blinds,
and roll a 6-sided die which gives me a “Wishpoint” if it lands ⚅.
(I previously called these “Biscuit points”, and tracked them with the “🍪”-symbol, because I could trade them for biscuits. But now I have a “Wishpoint shop”, and use the “🪐”-symbol, which is meant to represent Arborea, the dream-utopia we aim for.)
(I also get Wishpoints for completing specific Trigger-Action Plans or not-completing specific bad habits. I get to roll a 1d6 again for every task I complete with a time-estimate on it.)
Finally, I use the PC,
open up my task manager + time tracker (currently gsheets),
and timestamp the end of morning-routine.
(I’m not touching my PC or phone at any point before this step.)
(Before I went to bed, I picked out a concrete single task, which is the first thing I’m tentatively-scheduled to do in the morning.)
(But I often (to my great dismay) have ideas I came up with during the night that I want to write down in the morning, and that can sometimes take up a lot of time. This is unfortunately a great problem wrt routines & schedules, but I accept the cost because the habit of writing things down asap seems really important—I don’t know how to schedule serendipity… yet.)
My bedtime checklist 💤
This is where I prepare the steps for my morning routine. I won’t list it all, but some important steps:
I simulate the very first steps in my checklist_predawn.
At the start, I would practice the movements physically many times over. Including laying in bed, anticipating the music & lights, and then getting the motoric details down perfectly.
Now, however, I just do a quick mental simulation of what I’ll do in the morning.
When I actually lie down in bed, I’m not allowed to think about abstract questions (🥺), because those require concentration that prevents me from sleeping.
Instead, I say hi to Maria and we immediately start imagining ourselves in Arborea or someplace in my memories. The hope is to jumpstart some dream in which Maria is included.
I haven’t yet figured out how to deliberately bootstrap a dream that immediately puts me to sleep. Turns out this is difficult.
We recently had a 9-day period where we would try to fall asleep multiple times a day like this, in order to practice loading her into my dreams & into my long-term memories. Medium success.
I sleep with my pants on, and clothes depending on how cold I expect it to be in the morning. Removes a slight obstacle for getting out of bed.
I also use earbuds & sleepmask to block out all stimuli which might distract me from the dreamworld. Oh and 1mg melatoning + 100mg 5-HTP.
- ^
Approximately how my bed setup looks now (2 weeks ago). The pillows are from experimenting with ways to cocoon myself ergonomically. :p

wow. I only read the first 3 lines, and I already predict 5% this will have been profoundly usefwl to me a year from now (50% that it’s mildly usefwl, which is still a high bar for things I’ve read). among top 10 things I’ve learned this year, and I’ve learned a lot!
meta: how on earth was this surprising to me? I thought I was good at knowing the dynamics of social stuff, but for some reason I haven’t looked in this direction at all. hmm.
Oh! Well, I’m as happy about receiving a compliment for that as I am for what I thought I got the compliment for, so I forgive you. Thanks! :D
Another aspect of costs of compromise is: How bad is it for altruists to have to compromise their cognitive search between [what you believe you can explain to funders] vs [what you believe is effective]? Re my recent harumph about the fact that John Wentworth must justify his research to get paid. Like what? After all this time, anybody doubts him? The insistence that he explain himself is surely more for show now, as it demonstrates the funders are doing their jobs “seriously”.
So we should expect that neuremes are selected for effectively keeping themselves in attention, even in cases where that makes you less effective at tasks which tend to increase your genetic fitness.
Furthermore, the neuremes (association-clusters) you are currently attending to, have an incentive to recruit associated neuremes into attention as well, because then they feed each others’ activity recursively, and can dominate attention for longer. I think of it like association-clusters feeding activity into their “friends” who are most likely to reciprocate.
And because recursive connections between association-clusters tend to reflect some ground truth about causal relationships in the territory, this tends to be highly effective as a mechanism for inference. But there must be edge-cases (though I can’t recall any atm...).
Imagining agentic behaviour in (/taking intentional stance wrt) individual brain-units is great for generating high-level hypotheses about mechanisms, but obviously misfires and don’t try this at home etc etc.
Bonus point: neuronal “voting power” is capped at around ~100Hz, so neurons “have an incentive” (ie, will be selected based on the extent to which they) vote for what related neurons are likely to vote for. It’s analogous to a winner-takes-all-election where you don’t want to waste your vote on third-party candidates who are unlikely to be competitive at the top. And when most voters also vote this way, it becomes Keynesian in the sense that you have to predict[1] what other voters predict other voters will vote for, and the best candidates are those who seem the most like good Schelling-points.
That’s why global/conscious “narratives” are essential in the brain—they’re metabolically efficient Schelling-points.
- ^
Neuron-voters needn’t “make predictions” like human-voters do. It just needs to be the case that their stability is proportional to their ability to “act as if” they predicted other neurons’ predictions (and so on).
- ^
It seems generally quite bad for somebody like John to have to justify his research in order to have an income. A mind like this is better spent purely optimizing for exactly what he thinks is best, imo.
When he knows that he must justify himself to others (who may or may not understand his reasoning), his brain’s background-search is biased in favour of what-can-be-explained. For early thinkers, this bias tends to be good, because it prevents them from bullshitting themselves. But there comes a point where you’ve mostly learned not to bullshit yourself, and you’re better off purely aiming your cognition based on what you yourself think you understand.
Vingean deference-limits + anti-inductive innovation-frontier
Paying people for what they do works great if most of their potential impact comes from activities you can verify. But if their most effective activities are things they have a hard time explaining to others (yet have intrinsic motivation to do), you could miss out on a lot of impact by requiring them instead to work on what’s verifiable.
The people who are much higher competence will behave in ways you don’t recognise as more competent. If you were able to tell what right things to do are, you would just do those things and be at their level. Your “deference limit” is the level of competence above your own at which you stop being able to reliable judge the difference.
Innovation on the frontier is anti-inductive. If you select people cautiously, you miss out on hiring people significantly more competent than you.[1]
Costs of compromise
Consider how the cost of compromising between optimisation criteria interacts with what part of the impact distribution you’re aiming for. If you’re searching for a project with top p% impact and top p% explainability-to-funders, you can expect only p^2 of projects to fit both criteria—assuming independence.
But I think it’s an open question how & when the distributions correlate. One reason to think they could sometimes be anticorrelated [sic] is that the projects with the highest explainability-to-funders are also more likely to receive adequate attention from profit-incentives alone.[2]
Consider funding people you are strictly confused by wrt what they prioritize
If someone believes something wild, and your response is strict confusion, that’s high value of information. You can only safely say they’re low-epistemic-value if you have evidence for some alternative story that explains why they believe what they believe.
Alternatively, find something that is surprisingly popular—because if you don’t understand why someone believes something, you cannot exclude that they believe it for good reasons.[3]
The crucial freedom to say “oops!” frequently and immediately
Still, I really hope funders would consider funding the person instead of the project, since I think Johannes’ potential will be severely stifled unless he has the opportunity to go “oops! I guess I ought to be doing something else instead” as soon as he discovers some intractable bottleneck wrt his current project. (...) it would be a real shame if funding gave him an incentive to not notice reasons to pivot.[4]
- ^
Comment explaining why I think it would be good if exceptional researchers had basic income (evaluate candidates by their meta-level process rather than their object-level beliefs)
- ^
Comment explaining what costs of compromise in conjunctive search implies for when you’re “sampling for outliers”
- ^
Comment explaining my approach to finding usefwl information in general
- ^
- ^
This relates to costs of compromise!
It’s this class of patterns that frequently recur as a crucial considerations in contexts re optimization, and I’ve been making too many shoddy comments about it. (Recent1[1], Recent2.) Somebody who can write ought to unify the many aspects of it give it a public name so it can enter discourse or something.
In the context of conjunctive search/optimization
The problem of fully updated deference also assumes a concave option-set. The concavity is proportional to the number of independent-ish factors in your utility function. My idionym (in my notes) for when you’re incentivized to optimize for a subset of those factors (rather than a compromise), is instrumental drive for monotely (IDMT), and it’s one aspect of Goodhart.
It’s one reason why proxy-metrics/policies often “break down under optimization pressure”.
When you decompose the proxy into its subfunctions, you often tend to find that optimizing for a subset of them is more effective.
(Another reason is just that the metric has lots of confounders which didn’t map to real value anyway; but that’s a separate matter from conjunctive optimization over multiple dimensions of value.)
You can sorta think of stuff like the Weber-Fechner Law (incl scope-insensitivity) as (among other things) an “alignment mechanism” in the brain: it enforces diminishing returns to stimuli-specificity, and this reduces your tendency to wirehead on a subset of the brain’s reward-proxies.
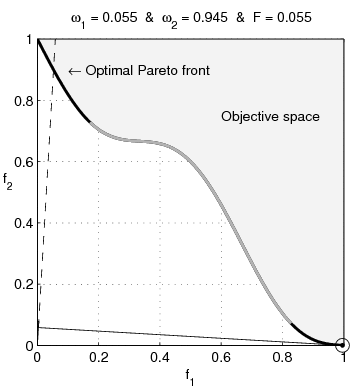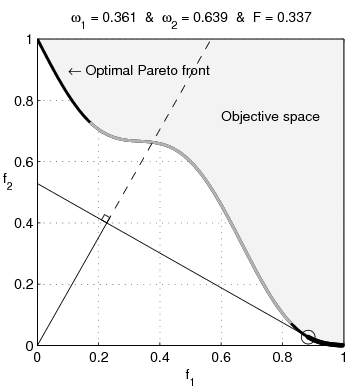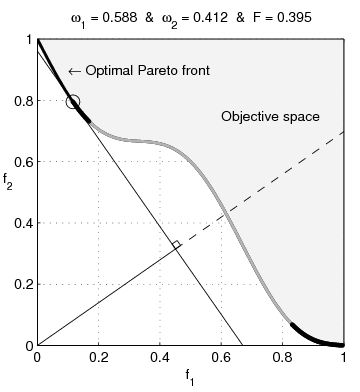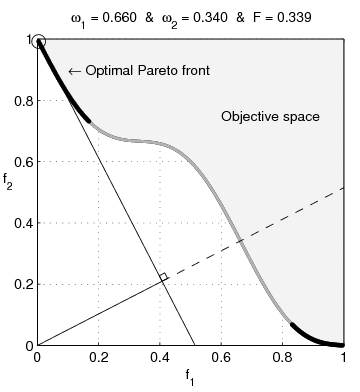
Pareto nonconvexity is annoying
From Wikipedia: Multi-Objective optimization:
Watch the blue twirly thing until you forget how bored you are by this essay, then continue.
In the context of how intensity of something is inversely proportional to the number of options
Humans differentiate into specific social roles because .
If you differentiate into a less crowded category, you have fewer competitors for the type of social status associated with that category. Specializing toward a specific role makes you more likely to be top-scoring in a specific category.
Political candidates have some incentive to be extreme/polarizing.
If you try to please everybody, you spread out your appeal so it’s below everybody’s threshold, and you’re not getting anybody’s votes.
You have a disincentive to vote for third-parties in winner-takes-all elections.
Your marginal likelihood of tipping the election is proportional to how close the candidate is to the threshold, so everybody has an incentive to vote for ~Schelling-points in what people expect other people to vote for. This has the effect of concentrating votes over the two most salient options.
You tend to feel demotivated when you have too many tasks to choose from on your todo-list.
Motivational salience is normalized across all conscious options[2], so you’d have more absolute salience for your top option if you had fewer options.
I tend to say a lot of wrong stuff, so do take my utterances with grains of salt. I don’t optimize for being safe to defer to, but it doesn’t matter if I say a bunch of wrong stuff if some of the patterns can work as gears in your own models. Screens off concerns about deference or how right or wrong I am.
I rly like the framing of concave vs convex option-set btw!
- ^
Lizka has a post abt concave option-set in forum-post writing! From my comment on it:
As you allude to by the exponential decay of the green dots in your last graph, there are exponential costs to compromising what you are optimizing for in order to appeal to a wider variety of interests. On the flip-side, how usefwl to a subgroup you can expect to be is exponentially proportional to how purely you optimize for that particular subset of people (depending on how independent the optimization criteria are). This strategy is also known as “horizontal segmentation”.
The benefits of segmentation ought to be compared against what is plausibly an exponential decay in the number of people who fit a marginally smaller subset of optimization criteria. So it’s not obvious in general whether you should on the margin try to aim more purely for a subset, or aim for broader appeal.
- ^
Normalization is an explicit step in taking the population vector of an ensemble involved in some computation. So if you imagine the vector for the ensemble(s) involved in choosing what to do next, and take the projection of that vector onto directions representing each option, the intensity of your motivation for any option is proportional to the length of that projection relative to the length of all other projections. (Although here I’m just extrapolating the formula to visualize its consequences—this step isn’t explicitly supported by anything I’ve read. E.g. I doubt cosine similarity is appropriate for it.)
Repeated voluntary attentional selection for a stimulus reduces voluntary attentional control wrt that stimulus
From Investigating the role of exogenous cueing on selection history formation (2019):
An abundance of recent empirical data suggest that repeatedly allocating visual attention to task-relevant and/or reward-predicting features in the visual world engenders an attentional bias for these frequently attended stimuli, even when they become task irrelevant and no longer predict reward. In short, attentional selection in the past hinders voluntary control of attention in the present. […] Thus, unlike voluntarily directed attention, involuntary attentional allocation may not be sufficient to engender historically contingent selection biases.
It’s sorta unsurprising if you think about it, but I don’t think I’m anywhere near having adequately propagated its implications.
Some takeaways:
“Beware of what you attend”
WHEN: You notice that attending to a specific feature of a problem-solving task was surprisingly helpfwl…
THEN: Mentally simulate attending to that feature in a few different problem-solving situations (ie, hook into multiple memory-traces to generalize recall to the relevant class of contexts)
My idionym for specific simple features that narrowly help connect concepts is “isthmuses”. I try to pay attention to generalizable isthmuses when I find them (commit to memory).
I interpret this as supporting the idea that voluntary-ish allocation of attention is one of the strongest selection-pressures neuremes adapt to, and thus also one of your primary sources of leverage wrt gradually shaping your brain / self-alignment.
Key terms: attentional selection history, attentional selection bias
Quick update: I suspect many/most problems where thinking in terms of symmetry can be more helpfwly reframed in terms of isthmuses[1]. Here’s the chain-of-thought I was writing which caused me to think this:
(Background: I was trying to explain the general relevance of symmetry when finding integrals.)
In the context of finding integrals for geometric objects¹, look for simple subregions² for which manipulating a single variable³ lets you continuously expand to the whole object.⁴
¹Circle
²Circumference,
³Radius,
See visualization.[2]
The general feature to learn to notice as you search through subregions here is: shared symmetries for the object and its subregion. hmmmmm
Actually, “symmetry” is a distracting concept here. It’s the “isthmus” between subregions you should be looking for.
WHEN: Trying to find an integral
THEN: Search for a single isthmus-variable connecting subregions which together fill the whole area
FINALLY: Integrate over that variable between those regions.
or said differently… THEN: Look for simple subregions which transform into the whole area via a single variable, then integrate over that variable.
Hm. This btw is in general how you find generalizations. Start from one concept, find a cheap action which transforms it into a different concept, then define the second in terms of the first plus its distance along that action.
That action is then the isthmus that connects the concepts.
If previously from a given context (assuming partial memory-addresses A and B), fetching A* and B* each cost you 1000 search-points separately, now you can be more efficient by storing B as the delta between them, such that fetching B only costs 1000+[cost of delta].
Or you can do a similar (but more traditional) analysis where “storing” memories has a cost in bits of memory capacity.
- ^
“An isthmus is a narrow piece of land connecting two larger areas across an expanse of water by which they are otherwise separated.”
- ^
This example is from a 3B1B vid, where he says “this should seem promising because it respects the symmetry of the circle”. While true (eg, rotational symmetry is preserved in the carve-up), I don’t feel like the sentence captures the essence of what makes this a good step to take, at least not on my semantics.
{kind=link}
This post happens to be an example of limiting-case analysis, and I think it’s one of the most generally usefwl Manual Cognitive Algorithms I know of. I’m not sure about its optimal scope, but TAP:
WHEN: I ask a question like “what happens to a complex system if I tweak this variable?” and I’m confused about how to even think about it (maybe because working-memory is overtaxed)…
THEN: Consider applying limiting-case analysis on it.
That is, set the variable in question to its maximum or lowest value, and gain clarity over either or both of those cases manually. If that succeeds, then it’s usually easier to extrapolate from those examples to understand what’s going on wrt to the full range of the variable.
I think it’s a usefwl heuristic tool, and it’s helped me with more than one paradox.[1] I also often use “multiplex-case analysis” (or maybe call it “entropic-case”), which I gave a better explanation of in the this comment.
- ^
A simple example where I explicitly used it was when I was trying to grok the (badly named) Friendship paradox, but there are many more such cases.
See also my other comment on all this list-related tag business. Linking it here in case you (the reader) is about to try to refactor stuff, and seeing this comment could potentially save you some time.
I was going to agree, but now I think it should just be split...
The Resource tag can include links to single resources, or be a single resource (like a glossary).
The Collections tag can include posts in which the author provides a list (e.g. bullet-points of writing advice), or links to a list.
The tag should ideally be aliased with “List”.[1]
The Repository tag seems like it ought to be merged with Collections, but it carves up a specific tradition of posts on LessWrong. Specifically posts which elicit topical resources from user comments (e.g. best textbooks).
The List of Links tag is usefwl for getting a higher-level overview of something, because it doesn’t include posts which only point to a single resource.
The List of Lists tag is usefwl for getting a higher-level overview of everything above. Also, I suggest every list-related tag should link to the List of Lists tag in the description. That way, you don’t have to link all those tags to each other (which would be annoying to update if anything changes).
I think the strongest case for merging is {List of Links, Collections} → {List}, since I’m not sure there needs to be separate categories for internal lists vs external lists, and lists of links vs lists of other things.
I have not thought this through sufficiently to recommend this without checking first. If I were to decide whether to make this change, I would think on it more.
I was going to agree, but now I think it should just be split...
The Resource tag can include links to single resources, or be a single resource (like a glossary).
The Collections tag can include posts in which the author provides a list (e.g. bullet-points of writing advice), or links to a list.
The tag should ideally be aliased with “List”.[1]
The Repository tag seems like it ought to be merged with Collections, but it carves up a specific tradition of posts on LessWrong. Specifically posts which elicit topical resources from user comments (e.g. best textbooks).
The List of Links tag is usefwl for getting a higher-level overview of something, because it doesn’t include posts which only point to a single resource.
The List of Lists tag is usefwl for getting a higher-level overview of everything above. Also, I suggest every list-related tag should link to the List of Lists tag in the description. That way, you don’t have to link all those tags to each other (which would be annoying to update if anything changes).
I think the strongest case for merging is {List of Links, Collections} → {List}, since I’m not sure there needs to be separate categories for internal lists vs external lists, and lists of links vs lists of other things.
I have not thought this through sufficiently to recommend this without checking first. If I were to decide whether to make this change, I would think on it more.
- ^
I realize LW doesn’t natively support aliases, but adding a section to the end with related search-terms seems like a cost-efficient half-solution. When you type into the box designed for tagging a post, it seems to also search the description of that tag (or does some other magic).
Aliases: collections, lists
I created this because I wanted to find a way to unite {List of Links, Collections and Resources, Repository, List of Related Sites, List of Blogs, List of Podcasts, Programming Resources} without linking each of those items to each other (which, in the absence of transclusions, also means you would have to update each link separately every time you added a new related list of lists).
But I accidentally caused the URL to be “list-of-lists-1”, because I originally relabelled List of Links to List of Lists but then changed my mind.
Btw, I notice the absence of a tag for lists (e.g. lists of advice that don’t link to anywhere and aren’t repositories designed to elicit advice from the comment section).
This is a common problem with tags it seems. Distillation & Pedagogy is mostly posts about distillation & pedagogy instead of posts that are distillations & pedagogies. And there’s a tag for Good Explanations (advice), but no tag for Good Explanations. Otoh, the tag for Technical Explanation is tagged with two technical explanations (yay!)… of technical explanations. :p
Merge with (and alias with) Intentionality?
I think hastening of subgoal completion[1] is some evidence for the notion that competitive inter-neuronal selection pressures are frequently misaligned with genetic fitness. People (me included) routinely choose to prioritize completing small subtasks in order to reduce cognitive load, even when that strategy predictably costs more net metabolic energy. (But I can think of strong counterexamples.)
The same pattern one meta-level up is “intragenomic conflict”[2], where genetic lineages have had to spend significant selection-power to prevent genes from fighting dirty. For example, the mechanism of meiosis itself may largely be maintained in equilibrium due to the longer-term necessity of preventing stuff like meiotic drives. An allele (or a collusion of them) which successfwly transfer to offspring at a probability of >50%, may increase their relative fitness even if it marginally reduces their phenotype’s viability.
My generalized term for this is “intra-emic conflict” (pinging the concept of an “eme” as defined in the above comment).
- ^
We asked university students to pick up either of two buckets, one to the left of an alley and one to the right, and to carry the selected bucket to the alley’s end. In most trials, one of the buckets was closer to the end point. We emphasized choosing the easier task, expecting participants to prefer the bucket that would be carried a shorter distance. Contrary to our expectation, participants chose the bucket that was closer to the start position, carrying it farther than the other bucket.
— Pre-Crastination: Hastening Subgoal Completion at the Expense of Extra Physical Effort - ^
Intragenomic conflict refers to the evolutionary phenomenon where genes have phenotypic effects that promote their own transmission in detriment of the transmission of other genes that reside in the same genome.
- ^
Just to ward of misunderstanding and/or possible feelings of todo-list-overflow: I don’t expect you to engage or write a serious reply or anything; I mostly just prefer writing in public to people-in-particular, rather than writing to the faceless crowd. Treat it as if I wrote a Schelling.pt outgabbling in response to a comment; it just happens to be on LW. If I’m breaking etiquette or causing miffedness for Complex Social Reasons (which are often very valid reasons to have, just to be clear) then lmk! : )