How do you affect something far away, a lot, without anyone noticing?
(Note: you can safely skip sections. It is also safe to skip the essay entirely, or to read the whole thing backwards if you like.)
The frog’s lawsuit
Attorney for the defendant: “So, Mr. Frog. You allege that my client caused you grievous bodily harm. How is it that you claim he harmed you?”
Frog: “Ribbit RIBbit ribbit.”
Attorney: “Sir...”
Frog: “Just kidding. Well, I’ve been living in a pan for the past two years. When I started, I was the picture of health, and at first everything was fine. But over the course of the last six months, something changed. By last month, I was in the frog hospital with life-threatening third-degree burns.”
Attorney: “And could you repeat what you told the jury about the role my client is alleged to have played in your emerging medical problems?”
Frog: “Like I said, I don’t know exactly. But I know that when my owner wasn’t away on business, every day he’d do something with the stove my pan was sitting on. And then my home would seem to be a bit hotter, always a bit hotter.”
Attorney: “Your owner? You mean to say...”
Judge: “Let the record show that Mr. Frog is extending his tongue, indicating the defendant, Mr. Di’Alturner.”
Attorney: “Let me ask you this, Mr. Frog. Is it right to say that my client——your owner——lives in an area with reasonably varied weather? It’s not uncommon for the temperature to vary by ten degrees over the course of the day?”
Frog: “True.”
Attorney: “And does my client leave windows open in his house?”
Frog: “He does.”
Attorney: “So I wonder, how is it that you can tell that a slight raise in temperature that you experience——small, by your own admission——how can you be sure that it’s due to my client operating his stove, and not due to normal fluctuations in the ambient air temperature?”
Frog: “I can tell because of the correlation. I tend to feel a slight warming after he’s twiddled the dial.”
Attorney: “Let me rephrase my question. Is there any single instance you can point to, where you can be sure——beyond a reasonable doubt——that the warming was due to my client’s actions?”
Frog: “Ah, um, it’s not that I’m sure that any one increase in temperature is because he turned the dial, but...”
Attorney: “Thank you. And would it be fair to say that you have no professional training in discerning temperature and changes thereof?”
Frog: “That would be accurate.”
Attorney: “And are you aware that 30% of frogs in your state report spontaneous slight temperature changes at least once a month?”
Frog: “But this wasn’t once a month, it was every day for weeks at a ti——”
Attorney: “Sir, please only answer the questions I ask you. Were you aware of that fact?”
Frog: “No, I wasn’t aware of that, but I don’t see wh——”
Attorney: “Thank you. Now, you claim that you were harmed by my client’s actions, which somehow put you into a situation where you became injured.”
Frog: “¡I have third degree burns all ov——”
Attorney: “Yes, we’ve seen the exhibits, but I’ll remind you to only speak in response to a question I ask you. What I’d like to ask you is this: Why didn’t you just leave the frying pan? If you were, as you allege, being grievously injured, wasn’t that enough reason for you to remove yourself from that situation?”
Frog: “I, I didn’t notice that it was happening at the time, each change was so subtle, but...”
Attorney: “Thank you. As your counsel would have advised you, the standard for grievous bodily harm requires intent. Now are we really expected to conclude, beyond a reasonable doubt, that my client intended to cause you harm, via a method that you didn’t even notice? That even though you can’t point to so much as a single instance where my client even provably had anything to do with the temperature of your frying pan home, even a single instance that is inconsistent with normal fluctuations in temperature or with normal frog life… despite that, you claim to know that Mr. Di’Alturner intended to cause you grievous bodily harm?”
Frog: “Well yes, because I can see now, in retrospect, that there was a pattern...”
Attorney: “A pattern? We are in a court of law, presenting our cases to this fine jury to decide whether my client has committed any crimes. We’re not in Salem, sussing out patterns like so much spellcraft. You can’t just wake up one day and decide to blame my client for your medical problems because you think there’s some ephemeral pattern that you’re only seeing now. Crimes are actions——clear cut, definable, visible actions that violate the law. And by your own admission, you can’t point to a single such action. The defense rests, your Honor.”
Thanks to Gaurav Sett for reminding me of the boiling frog.
Controlling the sum
Suppose that you are relaying a message from Alice to Bob. Alice sends you a vector of real numbers with one hundred dimensions, and you’re supposed to pass it on to Bob. Alice chooses to communicate a message to Bob, but she also adds in some small Gaussian noise, and Bob knows that she does this. Your goal is send Bob a vector in such a way that has a large sum, i.e. is high.
One way you could do this is to set the first coordinate, , to be really high, like , and otherwise set . This makes the sum large. But it also makes it obvious to Bob that the vector has been tampered with. He’s going to read the vector, and he’ll notice that the first coordinate is huge and doesn’t fit with the message.
What else can you do?
Here’s how you can make the sum large without Bob noticing: just add a small amount to each coordinate, like . Then Bob could attribute each coordinate’s offset to noise, and you’ve made the sum of greater by 100.
Sum-threshold attacks
The general idea is that an agent can push on something in a way that no one notices by distributing its effects through lots of different channels. That way no single channel carries a noticeable amount of optimization power.
Normally an agent affects something by pushing on it hard through one big channel. For example, I can open a door by pushing on it with my hand. That’s one big channel: one stream of signals through one nerve activates one big push.
But an agent can also affect something by pushing on it just a little bit through each one of many different channels. For example, I could open the door by simultaneously pushing on it just a little bit with my hand, and also pushing just a bit with my foot, and also blowing on it, and also activating a weak little motor embedded in the hinge, and also having a friend wave a magnet around so that the doorknob is pulled forward, and so on. I could set it up so that the force applied to the door is barely noticeable from any one source, but in aggregate, the force is enough to open the door.
The door example is kind of silly, but this sort of sum-threshold attack happens all the time in social situations. For example, suppose that whenever Alice talks about plums, Bob makes a subtle disapproving gesture, like a slight look of annoyance, or briefly turning away, or hardening the tone of his voice a bit. Each individual gesture may be subtle enough that Alice doesn’t bring to conscious attention that Bob reacted negatively toward something she said, and yet Alice could still have a large change to her behavior. She might intuitively avoid mentioning plums (or more likely, some broader category like all food). The aggregate effect is large, even though each contribution to the effect is small.
The name is supposed to suggest a mismatch. The ultimate effect is measured as a sum——how averse Alice is to talking about plums is an aggregate of all of Bob’s subtle nudges. But whether Alice notices Bob’s influence might be more of a threshold. If Bob makes an obvious gesture, like yelling at Alice when she mentions plums, then Alice will notice. But if each gesture is subtle, then maybe none of the gestures will rise above the threshold beyond which Alice would notice. A sum-threshold attack produces a large sum of all the coordinates taken together, but stays below the threshold in each coordinate taken on its own. The threshold quantity might be: is it legal; is it noticeable; is it describable; is it worth addressing; is it worth caring about; is it unambiguous; does it show intent.
Legibility
A sum-threshold attack is sneaky. It stays below the radar, letting the optimization flow around through many channels, before the channels reconverge in the target.
Not only might the target not notice the attack, but also onlookers have trouble recognizing that the sum-threshold attack is happening. That’s because the natural way to demonstrate that there is an attack is to show: Here is a channel of optimization, and see, there’s a lot of optimization power flowing through this channel from Bob to Alice.
In a sum-threshold attack, there’s no one coordinate in the vector that’s especially out of place. Mr. Frog’s owner never turned the stove up by more than a tiny increment, on any one day. So no one can point to one or a few coordinates——one or a few actions——that demonstrate the attack. The attack is rotated out-of-basis. It’s not large on any one coordinate; it’s large in some other direction.
For some abuse victims, this is part of why they have trouble saying what the abuse consisted of. Any given action, any specific incident, seems small and ambiguous. Did the temperature go up a bit because of the stove dial, or because of random fluctuation? How sure are you that Bob subtly disapproved of your friendship with someone else, or was he just annoyed about something unrelated from his day?
There’s no good answer to “Ok, you have two minutes to describe what happened to you, tell me your top three examples of Bob’s bad behavior.”. If someone refuses to compute “abuse” as a possible coordinate——doesn’t admit abuse as a single direction in the space of behaviors, doesn’t recognize “he was turning up the dial gradually, adding up to boiling”——then there’s no coordinate you can show them, no single action by Bob, that’s clearly bad and has a large magnitude. You don’t have a word——or, they won’t let you use the word——that indicates the direction in which the vector is long, the feature of Bob’s behavior that blows way past the threshold of noticing and caring, so that they’ll have to listen. You don’t have that word, and the people you’re trying to convince will only accept an action as attention-worthy if it’s above a threshold of badness, and each one of Bob’s actions is below that threshold. “Pattern”? “Gaslighting”? What is this, a witch hunt?
By making new words and phrases, we can change what measurements are easy, natural, widely known, and in logical common knowledge.
More examples
A meme, for your consideration
If each piece of evidence is evaluated on its own, weighed against all the evidence in favor of the incumbent theory, then each new piece of evidence against the incumbent will, in turn, lose the fight to overturn the incumbent theory. The army of argument-soldiers for the incumbent theory will win each time by defeat in detail. One argument loses against the army.
If you try to demonstrate that a sum-threshold attack is being carried out, you have only a disconnected series of weak arguments. Each one of your arguments on its own is far below the threshold needed to defeat the incumbent theory, which says that there’s no attack. You need a coordinate that tracks the sum. That coordinate marshals all your arguments, combining their strength. There is a forest, not just many trees; there is a blazing fire, not just many small flames.
DDoS attack
A distributed denial-of-service attack shuts off a service by making service requests by many different users, overwhelming the service provider so that it can’t provide good service to anyone.
You can’t stop the attack by blocking, shutting off, or punishing any one user. Any one user request could be legitimate, so you can’t prove any one user is doing something wrong.
Systemic oppression
Were you refused service because you’re black, or because of a misunderstanding? Were you passed over for a promotion because of your performance, or because you’re a woman? Is the guy talking down to you just arrogant, or specifically making assumptions about you because of how you look? Is she asking where you grew up because she likes learning about people, or because she wants you out of her country——not enough to legibly hurt you, but enough to distributedly coordinate with other racists to make it clear to you that you aren’t welcome? Microaggressions can add up to macroaggressions.
Some hermeneutic injustice (h/t TJ) can be corrected by adding another coordinate to the space of perception defined by language. A boss pressuring an employee to sleep with him could apply a lot of pressure in sum, staying below the threshold——but not as easily if the employee has the coordinate “sexual harassment”, and can expect others to acknowledge that coordinate. On that coordinate, the boss’s behavior is high-magnitude.
From “Oppression” by Marilyn Frye:
Cages. Consider a birdcage. If you look very closely at just one wire in the cage, you cannot see the other wires. If your conception of what is before you is determined by this myopic focus, you could look at that one wire, up and down the length of it, and unable to see why a bird would not just fly around the wire any time it wanted to go somewhere. Furthermore, even if, one day at a time, you myopically inspected each wire, you still could not see why a bird would have trouble going past the wires to get anywhere. There is no physical property of any one wire, nothing that the closest scrutiny could discover, that will reveal how a bird could be inhibited or harmed by it except in the most accidental way. It is only when you step back, stop looking at the wires one by one, microscopically, and take a macroscopic view of the whole cage, that you can see why the bird does not go anywhere; and then you will see it in a moment. It will require no great subtlety of mental powers. It is perfectly obvious that the bird is surrounded by a network of systematically related barriers, no one of which would be the least hindrance to its flight, but which, by their relations to each other, are as confining as the solid walls of a dungeon.
Adversarial image attacks
From “Exploring the Space of Adversarial Images”:

In each column, the top image plus the slight perturbation in the middle image gives the lower image. The image classifier AI correctly classifies all the top images, and incorrectly classifies all the bottom images. To the human eye, the perturbed images are nearly indistinguishable. For the volcano, I can see that there’s slight distortion, but it’s still basically the same; for the other images, I can only tell that there’s distortion with the guidance of the perturbation image; and for the kit foxes, I can’t tell at all.
Is this really a sum-threshold attack? I’m not sure. It’s not literally a sum-threshold attack. But it’s some kind of “lots of small perturbations which don’t look like much affect some distant variable a lot”. It looks more like an attack in the spirit of a sum-threshold attack if
multiplying the perturbation by 1.1 increases the confidence of the neural net’s erroneous judgement; and
randomly resetting some of the pixels in the perturbation back to neutral leaves a perturbation that still has much of the effect.
Other names
I’m not sure what to call this sort of thing. Is there a preexisting name?
Instead of “attack”, we could say “adversary” or “channel” or “optimization” or “effect” or “transmission”.
Instead of “sum-threshold” we could say:
-
Out-of-basis, rotated, basis misaligned, off-norm, alternate norm, norm mismatch. The space of behavior can be thought of as a vector space, where the dimensions are something like features that we tend to notice. Then there’s (something like) a norm on this vector space, which says how much we notice. This norm is not the norm (or a conjugate), so it’s not invariant under a full group of rotations. In practice, this norm-like valuation has a full distinguished basis. For example, asking “what’s the worst thing that happened” is putting an norm on the space where the dimensions are “things that happened”, where “things that happened” include “Alice picked up a cup” but not “Alice picked up her cup very slightly faster than usual every day this month”. The vector that has in every coordinate has very low norm, but could be a very long vector. It’s rotated out of alignment with the basis, so it’s hard to notice. This isn’t really the best image though, because the same effect can be gotten if the “noticing norm” is , which doesn’t have a distinguished basis, while the “attack norm” is . Hence the name “norm mismatch”.
-
Frogboiling. The boiling frog is more specific, though. It’s also about progressively getting accustomed to a new normal.
-
Timothee Chauvin: illegible nudging, persistent low-grade nudging, stealth nudging.
-
Sum-max. If the question is “what’s the worst that happened”, that’s more of a maximum than a threshold.
-
Broadband, wide-channel, breadth-based; broadshallow, shallowwide, shallowstrong, widestrong, broadstrong; broad-shallow-strong.
-
Ramified, multi-channel, many-pathed.
-
Delta, diamond, many-tributaries, anastomosing, anabranching, braided, bayou. Part of the core idea of sum-threshold attacks is that from the attacker, many lines of optimization flow; they go their separate ways, each one unnoticed; and then they converge in the target, producing a large effect. This suggests the geometric image of a diamond, with the attacker and the target at each acute point. It also suggests a river which spreads and branches (like a river delta), and then later the anabraches recombine. That’s called anastomosis. The image of a braided river, where the anabranches are constantly shifting their route, suggests an attacker who is shifting optimization channels. Image from https://fifthgoal.wordpress.com/2010/09/17/the-brahmaputra-river/:
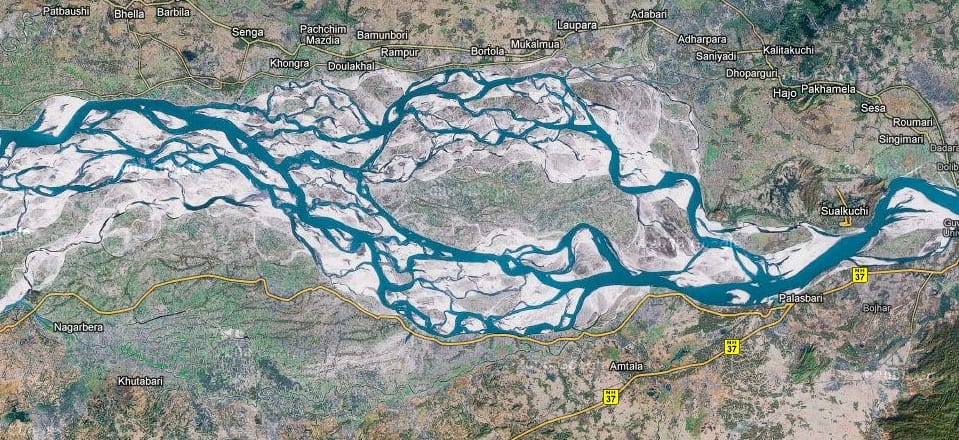
-
Distributed, diffuse, unconcentrated.
-
Teleporting. As if the effect teleports from the attacker to the target.
I believe the preexisting name is “salami slicing”
Thanks! That does seem at least pretty close. Wiki says:
This is a pretty close match. But then, both the metaphor and many of the examples seem specifically about cutting up a big thing into little things—slicing the salami, slicing a big pile of money, slicing some territory. Some other examples have a frogboiling flavor: using acclimation to gradually advance (the kid getting into the water, China increasing presence in the sea), violating a boundary. (The science publishing examples seems like milking, not salami slicing / sum-threshold.) A “pure” sum-threshold attack doesn’t have to look like either of those. E.g. a DDoS attack has the anastomosis structure without having a concrete thing that’s being cut up and taken or a slipperly slope that’s being pushed along; peer pressure often involves slippery slopes / frogboiling, but can also be “pure” in this sense, if it’s a binary decision that’s being pressured.
It seems pretty natural to me to think of a DDoS as being a DoS (with only one “D”) that has been salami-sliced up into many pieces.
One could argue that a DoS is only an abstraction and not “concrete”, but one could make a similar argument about money or alliances, which Wikipedia presents as the canonical examples of salami slicing.
Additional relevant terms are sorites, “indifference of the indicator”, and “all stable processes we shall predict, all unstable processes we shall control”.
when making new words, i try to follow this principle:
the usefwlness of a label can be measured on multiple fronts:
how easy is it to recall (or regenerate):
the label just fm thinking abt the concept?
low-priority, since you already have the concept.
the concept just fm seeing the label?
mid-priority, since this is easy to practice.[2]
the label fm situations where recalling the concept has utility?
high-priority, since this is the only reason to bother making the label in the first place.
if you’re optimising for b, you might label your concept “distributed boiling-frog attack” (DBFA). someone cud prob generate the whole idea fm those words alone, so it scores on highly on the criterion.
it scores poorly on c, however. if i’m in a situation in which it is helpfwl for me to notice that someone or something is DBFAing me, there are few semiotic/associative paths fm what i notice now to the label itself.
if i reflect on what kinds of situations i want this thought to reappear in, i think of something like “something is consistently going wrong w a complex system and i’m not sure why but it smells like a targeted hostile force”.
maybe i’d call that the “invisible hand of malice” or “inimicus ex machina”.
i rly liked the post btw! thanks!
i happen to call this “symptomatic nymation” in my notes, bc it’s about deriving new word from the effects/symptoms of the referent concept/phenomenon. a good label shud be a solution looking for a problem.
deriving concept fm label is high-priority if you want the concept to gain popularity, however. i usually jst make words for myself and use them in my notes, so i don’t hv to worry abt this.
Interesting. I think I have a different approach, which is closer to
True name doesn’t necessary mean a literal description of the core structure of the thing, though “sum-threshold” is such a literal description. “Anastomosis / anabranching (attack)” is metaphorical, but the point is, it’s a metaphor for the core structure of the thing.
i think that goes into optimising for b in my taxonomy above. how easy is it to recall the structure of the thing once you’ve recalled the word for the thing? these are just considerations, and the optimal naming strat varies by situs ig. 🍵
I think I have a couple other specific considerations:
By getting ahold of the structure better, the structure can be better analyzed on its own terms. Drawing out implications, resolving inconsistencies, refactoring, finding non-obvious structural analogies or examples that I wouldn’t find by ever actually being in the situation randomly.
By getting ahold of the structure better, the structure can be better used in the abstract within other thinking that wants to think in related regions (“at a similar level of abstraction”).
Values (goal-pursuits, etc.) tend to want to flow through elements in all regions; they aren’t just about the phenomenal presentation of situations. So I want to understand and name the real structure, so values can flow through the real structure more easily.
And a general consideration, which is like: I don’t have good reason to think I see all the sorts of considerations going into good words / concepts / language, and I’ve previously thought I had understood much of the reasons only to then discover further important ones. Therefore I should treat as Not Yet Replaceable the sense I have of “naming the core structure”, like how you want to write “elegant” code even without a specific reason. I want to step further into the inner regions of the Thing(s) at hand.
cool third point! i may hv oversold the point in my first comment. i too try to name things according to their thingness, but not exclusively.
to make a caricature of my research loop, i could describe it as
trying to find patterns that puzzle me (foraging),
distilling the pattern to its core structure and storing it in RemNote (catabolic pathway),
mentally trying to find new ways to apply the pattern
ie, propagating it, installing hooks (which I call isthmuses) into plausibly-related contexts such that new cryptically-related observations are more likely to trigger an insight (metaphor), allowing me to generalise further or discover smth i need to refactor
going abt business as usual, repeating 1-3 until unfolding branch meets unfolding branch from the other side, indicating i might hv found a profitable generalisation
an important consideration re keeping isthmuses alive enough to trigger connections: i don’t want to hv memorised this specific instantiation of the pattern so it’s crystal clear. if it fits neatly into a slot and it’s comfortable w its assigned niche, it’s unlikely to trigger in novel situations. imprecision/fuzziness is good when the concept is still in exploratory phase (and not primarily tool-stage).
fix everything
loop is often bottlenecked by the high cost of refactoring anything. i rly wish i could find a general algorithm/strategy for refactoring complex systems like this, or a clever approach to building that minimises/eliminates the need.
the optimal conlang isn’t a new set of words. it’s a new set of practices for naming things, unnaming things, generalising & specialising, communal decision-processes for resolving conflicts, neat meta-structures that minimise cost of refactoring (somehow), enabling eager contributors w minimal overhead & risk of degeneration, etc.
Absolutely.
I really liked this comment! Please continue to make comments like it!
Thank you! : )
Please continue complimenting people (or express gratitude) for things you honestly appreciate.
Promoted to curated. I’ve been using this concept a bunch of times since this post came out, and have been thinking about it as a relevant component of how the whole AI situation will go. I also really liked the way the post held the concept kind of lightly and explored it and generally defined things in a pretty open and inductive way instead of a “I hereby declare these words mean X” way, which often feels kind of uncooperative or hard to wrangle.
Perhaps Alice might notice that she mysteriously dislikes mentioning plums in Bob’s presence, but not when she is with other people. In that case, she might consider the hypothesis that this could be a consequence of something that Bob does… even if she has no idea what specifically it could be. But once the hypothesis is there, she can do an experiment; for example mention the plums five times a day, at randomly selected moments, and make notes about Bob’s reactions. Then compare those reactions to a control group (talking about something else).
Not sure if something like this can also be applied to other situations of this kind.
This concept in radio communications would be “spread spectrum”, reducing the signal intensity or duration in any given part of the spectrum and using a wider band/more channels. See especially military spread spectrum comms and radars. E.g. this technique has been used to frustrate simple techniques for identifying the location of a radio transmitter, to avoid jamming, and to defeat radar warning/missile warning systems on jets.
Nice, thanks.
Another example is the obfuscated arguments problem. As a toy example:
Even if the conclusion of the argument is a lie, each premise is spot-checkable and most likely true. The lie has been split up into many statements each of which is only slightly a lie.
Another important example: Steganography, hiding messages in plain sight by slightly perturbing the data flowing around in a way only your recipient could understand. Subtle choice of words or phrasings, precisely-placed smudges on a piece of paper…
I think depending on the encoding chosen, steganography is either a central example of a sum-threshold attack (if each individual perturbation makes subtle sense by itself, like saying “this meal is mind-blowing” instead of “amazing” to signal that it’s time to detonate the bomb), or just “in the spirit of” a sum-threshold attack (if each perturbation just signals 0 or 1, is not context-aware, and the full ciphertext is cryptographically encrypted on top of the steganography).
In relation to AI, we have steganography as a convergent LLM alignment challenge and as a potential way to “watermark” LLM outputs.
As a sci-fi plot, we could imagine an AI that models people sufficiently well that it can manipulate them by replacing words in a text by their synonyms. Predict the probability of outcome X if the person reads the text with Synonym1, predict the probability of X if the person reads the text with Synonym2, choose the one with higher probability; now do this for all words in the text that have synonyms in a dictionary.
(I do not expect this to work in reality. First, there is too much noise in the environment to predict such microscopic changes. Second, even if you magically could, the effect of the entire text is unlikely to be a linear combination of effects of individual words.)
This reminds me of these two Derren Brown videos: https://www.youtube.com/watch?v=43Mw-f6vIbo https://www.youtube.com/watch?v=sEmCQzueyEQ
I assume (but don’t know for sure) that what’s happening in the videos isn’t as they appear (e.g. forging handwriting isn’t that hard), but it’s at least an interesting fictional example of a somewhat-additive attack like this.
Covert side channels like you’re suggesting would probably be a related and often helpful thing for someone trying to do what OP is talking about, but I think the side channels are distinct from the things they can be used for.
By this logic, wouldn’t all textual messages qualify? The letters of this comment are individually insignificant but add up to communicating an idea.
Except they’re not actually “adding”, they’re interacting in a structured way that isn’t commutative or associative. The same letters in a different order wouldn’t “add up” to the same idea. This isn’t subdividing an action into smaller actions; it’s building a complex machine that only functions as an entire unit. It is “more than the sum of its parts.”
Yeah, this is why I didn’t include steganography. (I don’t know whether adversarial images are more like steganography / a message or more like a sum-threshold attack. )
I think that one example of this which is incorporated in regulations is that of material misstatements in financial audit. To my understanding, misstatements, being single instances of faulty financial reporting either by intention or mistake, can be individually material if they exceed some small but significant % of what’s been recorded in the books (for the specified period etc.). However, auditors are also obliged to make a judgment whether misstatements in aggregate can constitute materiality, even though each individual misstatement is not material in itself.
I guess a difference to some of the examples above is that it’s easy to discover even small perturbations in financial reporting—but in general, it seems to me that an attempt of a “sum-threshold attack” in financial reporting would not go under the radar, at least not as easily.
Epistemic note: I work in the auditing business, but I am not a financial auditor myself.
Nice, yeah. This seems like centrally salami slicing.
Kim Stanley Robinson used this in several books, calling it a “pebble mob”. Picture an explosion run in reverse time, with the fragments converging at a point. Or a hundred drones, as in this interview with him.
https://bioneers.org/kim-stanley-robinson-on-his-book-the-ministry-for-the-future/
Excellent, thanks!
Charles Stross wrote a book called ‘Rule 34’ about a sneaky AI having far reaching social effects by doing sum-threshold attacks. It’s not mind-blowing, I don’t think it adds anything to my understanding that this post doesn’t, but it’s a fun sci-fi read.
This would assume that either Bob is unaware that an attack might be happening, or that he can’t be bothered to do statistical analysis on his vector.
If the original value (without the noise chosen by Alice) is non-obvious to the attacker, but obvious to Bob (e.g., they use redundancy and encryption—it is a well known fact that Alice and Bob like cryptography), and the magnitude of the noise is common knowledge, then all attempts to modify the message will, on average, increase the standard deviation of the noise as measured by Bob. If my math is right, the attacker could modify each value by about half the width of the noise and end up with an expected χ2 sum of 112 instead of 100, which will probably not be suspicious to Bob.
If Bob has an idea of the attackers objective, detecting tampering will get much easier. If Bob suspects that the attacker wants a huge sum, he can just calculate the sum of the noise terms and compare that to the expected distribution. Then any deniable tampering would have to be within expected random fluctuations. (Of course, for every vector, there is some base in which it looks very suspicious.)
Often, we have an idea what the objective of an adversary using a sum-threshold attack might be. There is more utility in influencing who get’s to be president of a country than in influencing who will become the tenth-ranking janitor in their residence. Some bosses would like to pressure their employees into having sex, few if any want to condition them to speak sentences with a prime number of syllables.
True. But often the target can’t do that test, e.g. because it’s costly or because they don’t actually know what to look for. Also, the “threshold” is sometimes not about the target, but about a third party, e.g. a another person who’s supposed to judge whether the attacked is really being attacked. Verbal abuse is an example of both: the abused often doesn’t have concepts to describe what’s happening, and so doesn’t know what to look for and doesn’t know what to say to a judge; and because the abuse comes along with pain and distraction, it’s costly to track the sum; and there’s noise and ambiguity, so the judge doesn’t credit any one instance; and the judge may not accept a description of the sum, but only accepts an accounting of each instance, which imposes sum-sized costs on reporting a sum-sized attack.
Like the frog example (which doesn’t actually happen AFAIK—frogs get out long before it’s dangerously hot), I suspect these are all (or at least mostly) theoretical and fictional. The key is that there is ALWAYS a dimension or visible effect that we actually notice and monitor. There may be a ludicrous amount of inputs that make the cause difficult to determine or stop, but it’s not a surprise that it’s happening.
Thanks, I didn’t know the frog thing wasn’t true.
I’m confused by your claim that the other examples aren’t real… That seems so obviously false that maybe I misunderstand.
The examples:
The vector thing. I take it you’re not disputing the math, but saying the math doesn’t describe a situation that happens in life?
Verbal abuse. This one totally happens. Happened to me, happened to lots of other people. There’s lots of books that describe what this looks like. 2.5. General social pressure. Don’t people get social pressured into actions, roles, and opinions via shallowbroad channels all the time without being aware it’s happening and without being able to say when or how it happened?
DDoS. I assume this one happens, I’ve heard people discuss it happening and it’s got a wiki page and everything. Are you saying there aren’t DDoS attacks? Or are you saying that the person being DDoSed is aware that they are being DDoSed and aware of each user request? I agree with that; in this case the threshold isn’t “did they notice”, it’s more like “is this particular user unambiguously part of the attack, such that it makes sense to ban them or sue them”. Regardless of that, it has the underlying anastomosis structure.
Systemic oppression. Are you claiming this isn’t a thing that happens? To get a sense for what it’s like, you could look at for example Alice’s Adventures in Numberland which details a bunch of examples—subtle and not—of sexism in academia, experienced by the number theorist Alice Silverberg. Maybe you’re saying it doesn’t count because there’s no agent?
Adversarial image attacks. Are you saying the claims in the paper aren’t true, or are you saying it’s not an example of a sum-threshold attack because the perturbation is fragile / the coordinates depend on each other for their effect (plausible to me, but also plausibly it is), or for some other reason (what reason)?
Sorry, I should learn not to post on mobile—I end up not thinking or explaining myself well. It was simply wrong to say “not real”.
There are three different aspects to two levels of phenomenon we’re talking about, some of which are similar, but not all of which have the same focus as the frog parable, which -is- false.
The levels are about the state of things vs changes in the state and predictions of future state.
The aspects are more important. There’s noticing something, fixing something, and assigning blame for something. The frog example and “attack” framing send to be mostly about blame and responsibility.
The true behavior of frogs in heated pots (they jump out) shows that noticing and fixing isn’t a problem. The other examples are pretty commonly noticed (recently, at least), but not well-understood enough to know how to address. It may be that blame plays a part in addressing some. But I suspect it’s not the most important part.
From a quick glance at https://en.wikipedia.org/wiki/Boiling_frog, it seems to me:
Some people in the 19th century tested this and found it to be true, given sufficiently slow heating
But modern scientific consensus is that it’s false
This is based on some modern experiments that boiled the frog much faster than the 19th century experiments, which had already established you need slow heating
This seems like a pretty big oversight!
(Wikipedia’s sources for it being false are this which describes “moderate heat” and this which describes 2°F/minute. Some successful 19th century experiments used 0.2°C/minute and 0.002°C/second.)
(Wikipedia also says “Furthermore, a frog placed into already boiling water will die immediately, not jump out.” This seems like a silly nitpick to me, since the claim I find interesting is not about how fast a frog dies in literally boiling water.)
I haven’t gone looking at this in much depth, and maybe there are modern experiments that actually attempt to reproduce the 19th century ones… but currently I think I’m like 60% that the 19th century had it right? And if I were to look and find that there are no serious modern attempts at replication, and no glaring caveats to the 19th century studies, I think I’d go 75% with a lot of the 25% being “ahh going against modern scientific consensus is scary even if it looks obviously bullshit”. I also think there’s a decent chance that this actually isn’t consensus, just a misleading Wikipedia article.
Have you found the actual 19th century paper?
The oldest quote about it that I found is from https://www.abc.net.au/science/articles/2010/12/07/3085614.htm
So the linked article is exactly the type of thing I’m complaining about.
If you dump a frog in literally boiling water, will it jump out? Sure, no. But like I say, I don’t consider that the interesting part of the claim.
If you dump a frog in water that’s hot enough to kill it slowly, will it jump out? Everyone seems to agree yes.
If you dump a frog in cold water, then slowly increase the temperature to where it’s hot enough to kill the frog, will it jump out?
According to wikipedia: 19th century researchers say no, if you do it about 0.1°C/minute; yes, if you do it about 3.8°C/minute.
According to both wikipedia and the linked article: 20th century researchers say yes, if you heat it about 2°F/minute.
These are obviously not in contradiction! The obvious simple conclusion is “not if the speed is below some critical threshold somewhere between about 0.1°C/minute and 1°C/minute”.
It’s probably not actually that simple—there are lots of different frog species, and even more individual frogs, and maybe it makes a difference how pure the water is or how still it is or the air temperature or when the frog last ate or or or… but the evidence presented should obviously not be enough to make us think the effect is fake.
Like, we might not be convinced that the effect is real—maybe we think the 19th century researchers made shit up or something. But we definitely shouldn’t be dismissing it based on the modern experiments that we’ve been told about.
(Even if we don’t know about the 19th century experiments, just knowing the modern results shouldn’t make us dismiss the idea. Perhaps Victor Hutchison has some reason to think that an effect not seen at 2°F/minute won’t be seen at all. If he does, the article doesn’t tell us about it. If not, it’s a leap to go from “we haven’t seen this yet” to “this doesn’t exist”.)
Now admittedly the article does acknowledge and try to to refute the 19th century researchers. But most of this refutation is obviously dumb.
(According to my calculator that actually gives a temperature rise of 14.4°C. Wikipedia has the same quote with 2½ hours instead, which is 18°C.)
Does the author really think that the person writing that quote can only possibly have intended to mean “the water was literally 100°C boiling at the end of those two hours”? The author can think of no possible other interpretation? We might say that if the experiment only ran from say 25°C to 40°C then this description of it is technically inaccurate because the water never boiled; but I don’t think we could say that this description of it is particularly unusual, in that it’s outside the boundaries of how people typically write.
(And I’m not sure it’s even inaccurate, because obviously after you kill the frog you can keep increasing the temperature to literally 100°C if you want. Perhaps the author would pick further nits, and say that you’re not then boiling a live frog?)
To be fair this objection is not-obviously-dumb. I mean, I don’t know much about frogs, it wouldn’t remotely surprise me if sitting still for two hours is a thing they do all the time. The author seems to dismiss the idea, but I don’t trust the author; but that just means I still don’t know. So yes, this is a question that’s worth asking of the 19th century research.
So that’s my rant about why the evidence presented is obviously insufficient to make us think the boiling frogs thing is definitely false. But is it true? I indeed had not looked up the 19th century studies. On some level I don’t really care; I’m more interested in the meta level (“how does one learn how frogs behave?”) than the object level (“how do frogs behave?”). But let’s see what we can find.
Wikipedia links to what it claims to be Sedgwick 1888. (“Claims to be” because archive.org gives it a different name and earlier publication date but whatever, the top of the page says Sedgwick.) The relevant pages seem to be about 390-400.
Honestly I have trouble following it. 19th century academic writing is a combination of two things I find difficult to read. There are lots of experiments described with lots of different conditions (normal frog or decapitated frog, speed of heating, how much of the frog is submersed, moisture content of the air), and it would be nice to have a simple table laying it all out.
But it sounds to me like the author tried it, and managed to boil a frog to death without getting reflex actions from it. The frog was suspended by the jaw, so the result was not “does it jump out or not” but “does it seem to be twitching violently like it’s trying to escape or not”. But that does seem like a decent experiment to me? We can imagine improvements, but like. Between that and the people not even trying, I’m more inclined to believe Sedgwick.
FWIW, the text doesn’t seem that hard to read to me, and I do take Sedgwick as saying that Heinzmann proved you could heat a normal frog to death (and Sedgwick remarks on the fact that earlier tests of this did not find the same thing about heating a normal frog to death and were unable to).
The source, Heinzman, seems to be https://ia600708.us.archive.org/view_archive.php?archive=/22/items/crossref-pre-1909-scholarly-works/10.1007%252Fbf01612145.zip&file=10.1007%252Fbf01612252.pdf Unfortunately… it’s in German.
Out of curiosity, I put the PDF into Claude-2 and asked it to summarize it and describe if it was in coherence with Sedgwick’s summary (“The frog destitute of cerebral hemispheres could be heated easily, the normal frog for obvious reasons with some difficulty, until death ensued; often passing from, perhaps, 22°C to 40° or 45°; or could be cooled as many degrees with a similar absence of movement. This result seemed to Heinzmann satisfactory.”). The conversation leaves me with some doubt:
Naturally, I tried to check if Claude-2 had correctly excerpted & translated it. Google Translate largely agreed with its translation of the quoted text… Unfortunately I couldn’t find the text anywhere in the PDF and after interrogating Claude-2 about where exactly it was, it seemed to admit it had confabulated the quote:
A good warning to still be cautious about LLM use and to double-check things! (I also flagged the confabulation passage to Anthropic.)
As for the paper itself, I suspect some native German speakers should be consulted about what it says or doesn’t say.
I asked on the LW Europe telegram channel. User Sargon writes:
And user nobody writes:
(If you want to dig into it more the talk page has some discussion.)
Excellent post! I think it’s closely related to (but not reducible to) to the general concept of Pressure. Both pressure as
the physical definition (which is, indeed, a sum of many micro forces on a frontier surface, but able to affect at macroscale the whole object).
the metaphorical common use of it (social pressure etc): see the post.
In the Chinese martial art of Tai Chi Chuan, there is a practice called “Pushing Hands”, where the objective is to dislodge the opponent’s stance (or, in competitions, move them out of a given area.)
As always with the traditional MAs, there are different styles of practice, hard and soft, more external and more internal.
In some of these styles, practitioners try to unbalance the opponent as softly as possible so to not evoke resistance until it has become futile – essentially executing a physical sum-threshold attack.
Thanks for giving me a general concept for this kind of behaviour!
Maybe there are some links between the “Sum-threshold attacks” and “Quantitative change leads to qualitative change”?
But when it comes to quantitative and qualitative change, people seem like using them to describe the effect through uni-channel, like continuous one hair losing will finally lead to baldness.
Sum-threshold attacks emphasizes more on the multi-channel? I’m a bit confused about which one is a broader set.
Good stuff. A positive look: an accumulation of small habits snowballing into major positive behavioral changes. Is it fair to say that all the “small habits”, “tiny habits”, “atomic habits”, “I’m-just-waiting-for-the-publication-of pico habits” are a sum-threshold attack at the established behavioral patterns?
And for a sinister comedy view: Amelie Poulain’s attack comes to mind.
Maybe? It’s a bit weird because that situation would involve some non-unified agency, which we don’t understand super well. Like, you’d have [you_1, who decides to enforce various small habits] and separately [you_2, who is made of unconscious habits], and you_1 is supposed to be sending influences to you_2 in a way that is below some threshold—what’s the threshold? Is it that you_2 will resist / not be dragged along with large changes, but can be forced into small ones? And then, there’s supposed to be some large aggregate effect. What is that? Is it just a bunch of small habits, or is the point that something else changes? Is that large change supposed to be in you_2?
Haven’t seen that movie, maybe I will later.
So, it would potentially require some dichotomy of self. Within this definition the sum-threshold attack is closely tied to the agent launching it. What if by slightly changing the environment we reach a certain threshold that it becomes the agent pushing us to enact further changes? You rescue a dog, but the dog really rescues you.
Good post. Made me think, so thx!
Ps. The movie is silly but the scene I was referring to was Amelie slightly moving a toothbrush and other things in the victim’s apartment leading to a spectacular collapse of that person’s routine and their rampant paranoia.
Yeah that sounds like an example!
In a not-too-fast and therefore requisitely stealthy ASI takeover scenario, if the intelligence explosion is not too steep, this could be a main meta-method by which the system gains increasing influence and power while fully remaining under the radar and avoiding detection until it is reasonably sure that it can no longer be opposed. This could be happening without anyone knowing or maybe even being able to know. Frightening.
As I remember, russian tax system works like this. Income tax is small and flat: 13 per cent. But your employer also pays tax on your wage. And also every shop pays tax on every sale. So summing up it gives a lot.
The LessWrong Review runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
I disagree with the notion of microaggressions being the primary factor. It’s worth considering that people often bypass Hanlon’s Razor, immediately assuming the worst intentions in others. This tendency is exacerbated by “main character syndrome,” where we’re inclined to believe that other people’s actions are always centered around us.
What do you mean by “the primary factor”? The primary factor in what? I think it’s true that in many cases, microagressions don’t matter in comparison to macroagressions. E.g. when people make Jew jokes, I’m a little on edge not because of the joke itself, but because the joke being told is a bit of evidence (and maybe a part of a strategy) that some people are trying to gain common knowledge of a shared goal of physically attacking Jews. On the other hand I think that in some contexts, the microaggressions together are an attack on their own, even without the threats.
It’s not about bad intentions in most practical cases, but about biases. Hanlon’s razor doesn’t apply (or, very weakly) to systemic issues.
sounds like https://en.wikipedia.org/wiki/Emergence to me 🤔 (not 100% overlap and also not the most useful concept, but very similar shaky pointer in concept space between what is described here and what has been observed as a phenomena called Emergence)
I would like to see some mention that this is a pop culture reference / urban myth, not something actual frogs might do.
To quote https://en.wikipedia.org/wiki/Boiling_frog, “the premise is false”.
(Discussed in this comment.)
Such subliminal summanipulation is pretty natural for a probablist. Thinking of cumulative effects of all inputs that an individual we care of is exposed to comes natural to lovers, parents, and big brothers, however, only more resourced can reliably afford to produce the inputs and carry it out such attacks, rather than just observe and care about these cumulative effects.
I think close companions can sometimes see sum-threshold attacks that the target can’t see, but some attacks go unnoticed by anyone for a long while. I think poorly-resourced agents can carry out these attacks.
I understood sum threshold attack long time ago (at least as pertaining to sum-threshold attack to aposteriori probabilities, as in the case of the Frog court), except that I didn’t produce a name for this. I understood that it can be applied in court, in communication, etc. So, I knew most of this without knowing (or maybe just without remembering) the name.
I call you to make a next step. This step requires a certain courage because it looks like an attack to the science (but not as a sum threshold attack, this seems to be a single point of failure):
I think we should (try) and make the next step: Conclude from sum threshold attack that the scientific method is wrong, because (so it seems for me, I never tried to prove it formally) it can produce incorrect results under sum threshold attack. I call you fellow thinkers to try to check if scientific method is resilient to sum threshold attack or no.
I mean that Science is based on Bayesian inference and Bayesian inference is liable to sum threshold attack: Repeat a million times an experiment that produces P(E|H) where E is 10% possible in the case of H meaning energy conservation law and consider every instance of the experiment as a separate evidence. Then we have “proved” no energy conservation.
How to avoid such a misuse of science? I don’t really know, but I suspect that we need to take into account basic principles of the scientist that he is not going to give up (“faith”). That reminds me religious faith, and I, probably, has drawn the argument from my study of religion. But after the argument is presented this way, it is purely scientific. We need stability (faith?) against the attack, don’t we?
If no, we certainly should nevertheless keep doing scientific research, but we should develop a new method differing from the scientific method by resilience to sum threshold attacks.
I think you’re right that the human process of science is vulnerable this way.