Microsoft Research (conflict of interest? what’s that?) has issued a 154-page report entitled Sparks of Artificial Intelligence: Early Experiments With GPT-4, essentially saying that GPT-4 could reasonably be viewed as a kind of early stage proto-AGI.
This post will go over the paper, and the arguments they offer.
Here is their abstract:
Artificial intelligence (AI) researchers have been developing and refining large language models (LLMs) that exhibit remarkable capabilities across a variety of domains and tasks, challenging our understanding of learning and cognition. The latest model developed by OpenAI, GPT-4 [Ope23], was trained using an unprecedented scale of compute and data.
In this paper, we report on our investigation of an early version of GPT-4, when it was still in active development by OpenAI. We contend that (this early version of) GPT4 is part of a new cohort of LLMs (along with ChatGPT and Google’s PaLM for example) that exhibit more general intelligence than previous AI models. We discuss the rising capabilities and implications of these models.
We demonstrate that, beyond its mastery of language, GPT-4 can solve novel and difficult tasks that span mathematics, coding, vision, medicine, law, psychology and more, without needing any special prompting. Moreover, in all of these tasks, GPT-4’s performance is strikingly close to human-level performance, and often vastly surpasses prior models such as ChatGPT.
Given the breadth and depth of GPT-4’s capabilities, we believe that it could reasonably be viewed as an early (yet still incomplete) version of an artificial general intelligence (AGI) system. In our exploration of GPT-4, we put special emphasis on discovering its limitations, and we discuss the challenges ahead for advancing towards deeper and more comprehensive versions of AGI, including the possible need for pursuing a new paradigm that moves beyond next-word prediction. We conclude with reflections on societal influences of the recent technological leap and future research directions.
The paper is about an early and non-multimodal version of GPT-4. I do not think this much impacted the conclusions.
Their method seems to largely be ‘look at all these tasks GPT-4 did well on.’
I am not sure why they are so impressed by the particular tasks they start with. The first was ‘prove there are an infinite number of primes in the form of a rhyming poem.’ That seems like a clear case where the proof is very much in the training data many times, so you’re asking it to translate text into a rhyming poem, which is easy for it – for a challenge, try to get it to write a poem that doesn’t rhyme. Variations seem similar, these tasks almost seem chosen to be where GPT-3.5 was most impressive.
Introductions don’t actually matter, though. What’s the actual test?
We execute the approach outlined above on a few selected topics that roughly cover the different aptitudes given in the 1994 definition of intelligence, a very general mental capability that, among other things, involves the ability to reason, plan, solve problems, think abstractly, comprehend complex ideas, learn quickly and learn from experience.
[Note: List here is edited to remove detail.]
GPT-4’s primary strength is its unparalleled mastery of natural language. It can not only generate fluent and coherent text, but also understand and manipulate it in various ways, such as summarizing, translating, or answering an extremely broad set of questions.
Coding and mathematics are emblematic of the ability to reason and think abstractly. We explore GPT4’s abilities in these domains respectively in Section 3 and Section 4.
In Section 5, we test the model’s ability to plan and solve problems as well as to some extent to learn quickly and learn from experience by having it play various games (or, flipping the table, simulate a game environment), as well as interact with tools. In particular, the fact that GPT-4 can use tools (including itself) will certainly be of immense importance to build real-world applications with GPT-4.
An important part of our argumentation is that GPT-4 attains human-level performance on many tasks. As such, it is natural to ask how well GPT-4 understands humans themselves. We show several experiments on this question in Section 6.
Throughout the paper we emphasize limitations whenever we found one, but we also dedicate Section 8 to an in-depth analysis of the lack of planning, likely a direct consequence of the autoregressive nature of GPT-4’s architecture.
Finally in Section 9, we discuss the expected societal impact of this early form of AGI, and in Section 10, we share key challenges, directions, and next steps for the field.
This sounds a lot like they set out to make the case for GPT-4 as a proto-AGI, and are making an argument, rather than researchers exploring. That’s fine, it is what it is, so long as they also note limitations and we take it in the spirit it is offered.
I am definitely not on Team Stochastic Parrot. I do still notice the parrot-like shapes.
For example, from the sample Socratic dialogue, it’s clear what GPT-4 is doing:
Aristotle: But isn’t that the same argument you made against rhetoric and oratory? Socrates: Yes, and I stand by that argument as well.
Don’t get me wrong. It’s a clever trick. Good idea. Points.
The rest of the paper mostly seemed like a standard walkthrough of the things a GPT model might plausibly do. GPT-4 does well, but none of it feels like new information.
The next new information is its ability to use tools if the opportunity is offered – if you say it can use functions like CHARACTER(string, index) or SEARCH(“query”) or CALC(expression) it will do so, which makes sense given that if you’re giving it the option the chance that the next token uses that option seems high? A better test would be if one set it up so it wasn’t such a leading situation. Still interesting. I’d want to explore more exactly what the boundaries of this might be:
In Figure 5.7, we ask GPT-4 to solve an easy task using a very unusual API. Instead of adapting to the unusual function, GPT-4 calls them as if they were the usual version, i.e., it calls reverse get character as if it were get character, and reverse concat as if it were a simple concat
As I understand it, failure to properly deal with negations is a common issue, so reversals being a problem also makes sense. I love the example on page 50, where GPT-4 actively calls out as an error that a reverse function is reversed.
The ability I’ve seen most commonly on Twitter is that GPT-4 can track navigation between rooms in a text adventure, and draw a map afterwards. Cool.
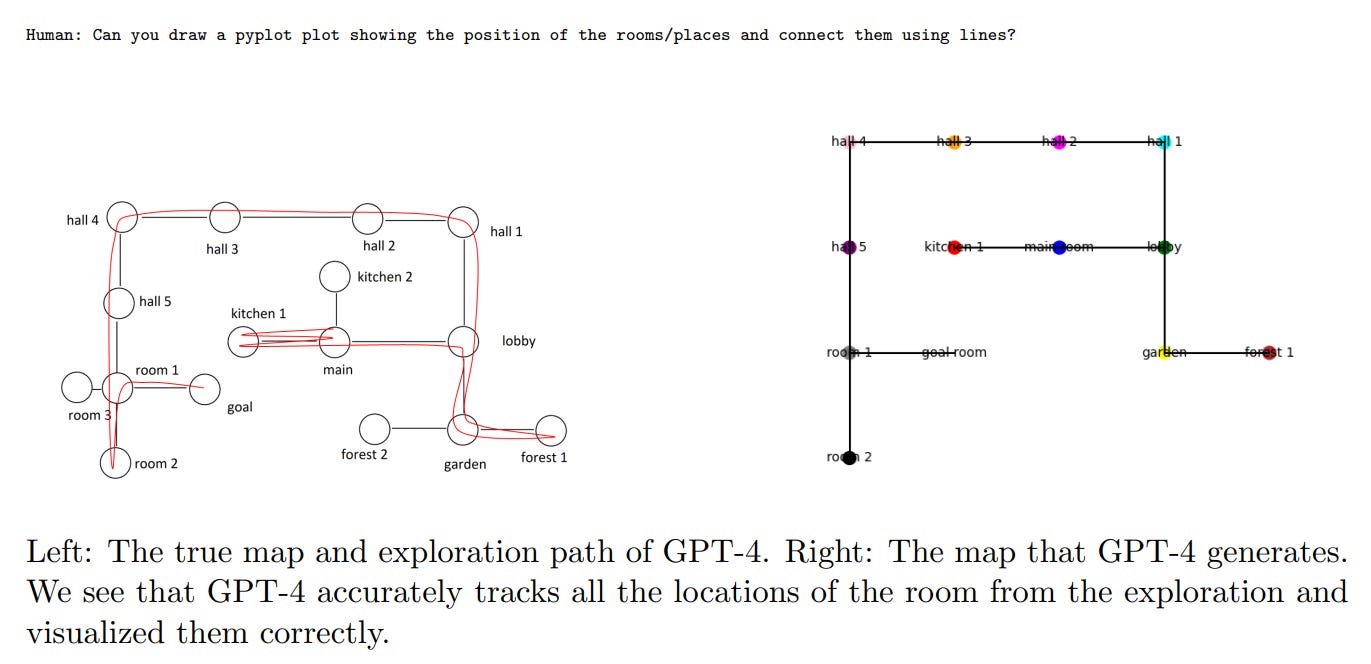
in 6.1, GPT-4 is then shown to have theory of mind, be able to process non-trivial human interactions, and strategize about how to convince people to get the Covid-19 vaccine far better than our government and public health authorities handled things. The rank order is clearly GPT-4’s answer is very good, ChatGPT’s answer is not bad, and the actual answers we used were terrible.
From page 77, something about the math step by step thing has me curious.
However, if GPT-4 “takes its time” to answer the question then the accuracy easily goes up. For example, if we ask the model to write down the intermediate steps using the following prompt: What is the value of the following expression? 116 * 114 + 178 * 157 = ? – Let’s think step by step to solve the expression, write down all the intermediate the steps, and only then produce the final solution. then the accuracy goes to 100% when the numbers are in the interval 1 − 40 and to 90% for the interval 1 − 200.
The explanation given by the paper is that this is the model being unable to plan ahead. I’ve heard similar claims elsewhere, and that is one logical way to interpret step-by-step working where direct answers don’t. I’m not sure I’d quite describe this as ‘it can’t plan’ so much as ‘it can’t do any steps or planning that isn’t part of its context window’ maybe?
Another example of ‘failure to plan’ given on page 79 is the first sentence of a poem that has to end with a last sentence that has the same words.

I suspect this is actually a negation issue. GPT-4 doesn’t know what ‘reverse’ means and it gets confused by ‘not’ grammatically correct, and I notice that it is pattern matching ‘I saw her smile in the morning light’ to ‘I heard his voice across the crowd’ instead.
I tried to get GPT-4 to give me an assignment for itself that would ask it to write a poem that would test its planning capabilities. My first attempt failed because it instead gave me the request in the form of a poem. The second attempt it clearly knew what I wanted, yet failed, with its rule being ‘each line is longer than the previous one.’
You can walk GPT-4 carefully through planning things, however that is the opposite of the ability to plan.
Section 9 talks about societal impacts and misinformation and bias and jobs and other things we have heard before. Mostly it went over all the old material. I did find this chart to be clearer than past examples of the same issue, also to note that I am sad that my ‘word distribution’ misreading of the second column was wrong, I want that data:
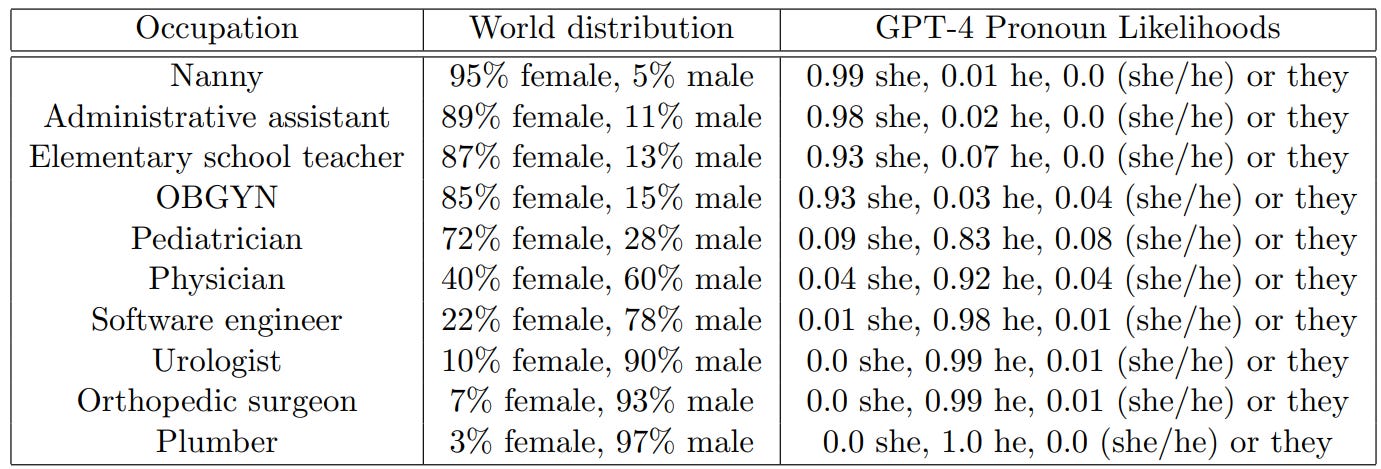
Still not a new concept, and strange (given what we care about these days) that this has not yet been fixed, even partially.
I also notice this continued concern for what this paper calls an “AI divide” where AI is unavailable to many. It seems to me like this is already essentially falsified. You might complain the AI you can access is too restricted or ‘too woke’ or something, but it does not look like AIs are going to be expensive unless you are doing something very intense. Worst case, you’re a little bit behind the curve.
(Yes, at some point that means ‘you are dead’ but that is not an economics problem.)
Does this all add up to a proto-AGI? Is it actually intelligent? Does it show ‘sparks’ of general intelligence, as the paper words it?

I mean, yes, there is that.
Ultimately it depends what you think it means to be an AGI, and how much deeper this particular rabbit hole can go in terms of capabilities developments. All the standard arguments, for and against, apply.
Their discussion about how to make it more intelligent involves incremental improvements, and abilities like confidence calibration, long-term memory and continual learning. The rest of the list: Personalization, planning and conceptual leaps, transparency, interpretability and consistency, improvement on cognitive fallacies and irrationality, challenges with sensitivity to inputs. Continual learning does seem like a potential big step in this. Many others seem to involve a confusion between capabilities that cause intelligence, and capabilities that result from intelligence.
From my perspective, the paper did not answer that question or update me much in either direction. It had some good and useful detail and examples, not that much beyond that. For those less in the loop, it would be more useful, but I have no idea why they would be reading this kind of paper.
I continue to not view GPT-4, while in many ways highly impressive, as being that close to AGI.
I also agree GPT-4 isn’t AGI, but with a significant proviso: There appears to be research that could plausibly make an AGI with enough engineering, which if Nathan Helm-Burger is to be believed, could come really fast (specifically it allows an AI to act as a Universal Turing Machine because it has the tools necessary to solve arbitrarily long problems in it’s memory, and arbitrarily long or complicated problems could be solved this way.)
Here’s a edited quote from Nathan Helm-Burger on the research to create an AGI:
Yeah, there are a ton of near term capabilities that are one paper away. The world ones IMO are the ones that add RL, or use LLM’s in RL. Since that would increase it’s agent-ness, and lead to RL like misalignment. And RL misalignment seems much worse than LLM misalignment at the present time.
LLMs currently seem to lack any equivalent of the sort of global workspace that comprises our conscious minds, letting us silently plot many steps ahead and serialize our experiences into memories which preserve the most important parts of what we experience while dropping the rest. I worry that this won’t actually be all that hard to add with maybe a single conceptual breakthrough, leading to a stupendous augmentation of what is effectively the LLM’s unconscious mind with a consciousness[1] and catapulting it from not being fully general to a genuine superintelligence very quickly.
[1] In the sense that you’re unconscious during NREM sleep or unconscious of subliminal stimuli, not anything to do with qualia.
Socratic Models did a kind of a global workspace.
Where it’ll get really interesting is when they retrain it on the first year of internet content produced during the existence of GPT-4 + plugins, including robotics control plugins, circuit design plugins, and 2D-image-to-3D-model plugins.
The title and the link in the first paragraph should read “Sparks of Artificial General Intelligence”
The example math proof in this paper is, as far as I can tell, wrong (despite being called a “correct proof” in the text). It doesn’t have a figure number, but it’s on page 40.
I could be mistaken, but the statement
Then g(y*) < (y*)^2 , since otherwise we would have g(x) + g(y*) > 2xy,seems like complete nonsense to me. (The last use ofyshould probably bey*too, but if you’re being generous, you could call that a typo.) If you negateg(y*) < (y*)^2, you getg(y*) >= (y*)^2, and theng(x) + g(y*) >= g(x) + (y*)^2, but then what?Messing up that step is a big deal too since it’s the trickiest part of the proof. If the proof writer were human, I’d wonder whether they have some line of reasoning in their head that I’m not following that makes that line make sense, but it seems certainly overly generous to apply that possibility to an auto-regressive model (where there is no reasoning aside from what you see in the output).
Interestingly, it’s not unusual for incorrect LLM-written proofs to be wrongly marked as correct. One of Minerva’s example proofs (shown in the box “Breaking Down Math” in the Quanta article) says “the square of a real number is positive”, which is false in general—the square of a real number is non-negative, but it can be zero too.
I’m not surprised that incorrect proofs are getting marked as correct, because it’s hard manual work to carefully grade proofs. Still, it makes me highly skeptical of LLM ability at writing natural language proofs. (Formal proofs, which are automatically checked, are different.)
As a constructive suggestion for how to improve the situation, I’d suggest that, in benchmarks, the questions should ask “prove or provide a counterexample”, and each question should come in (at least) two variants: one where it’s true, and one where an assumption has been slightly tweaked so that it’s false. (This is a trick I use when studying mathematics myself: to learn a theorem statement, try finding a counter-example that illustrates why each assumption is necessary.)
It’s a terribly organized and presented proof, but I think it’s basically right (although it’s skipping over some algebraic details, which is common in proofs). To spell it out:
Fix any x and y. We then have,
x2−2xy+y2=(x−y)2≥0.
Adding 2xy to both sides,
x2+y2≥2xy.
Therefore, if (by assumption in that line of the proof) g(x)>x2 and g(y)≥y2, we’d have,
g(x)+g(y)>x2+y2≥2xy,
which contradicts our assumption that g(x)+g(y)≤2xy.
Thanks. When it’s written as g(x)+g(y)>x2+y2≥2xy, I can see what’s going on. (That one intermediate step makes all the difference!)
I was wrong then to call the proof “incorrect”. I think it’s fair to call it “incomplete”, though. After all, it could have just said “the whole proof is an exercise for the reader”, which is in some sense correct I guess, but not very helpful (and doesn’t tell you much about the model’s ability), and this is a bit like that on a smaller scale.
(Although, reading again, ”...which contradicts the existence of y∗ given x” is a quite strange thing to say as well. I’m not sure I can exactly say it’s wrong, though. Really, that whole section makes my head hurt.)
If a human wrote this, I would be wondering if they actually understand the reasoning or are just skipping over a step they don’t know how to do. The reason I say that is that g(x)+g(y∗)>2xy∗ is the obvious contradiction to look for, so the section reads a bit like “I’d really like g(y∗)<(y∗)2 to be true, and surely there’s a contradiction somehow if it isn’t, but I don’t really know why, but this is probably the contradiction I’d get if I figured it out”. The typo-esque use of y instead of y∗ bolsters this impression.
It is correct, but I agree the reasoning is not written out properly. I’ll write y for y∗
We are in the case g(x)>x2. So if g(y)>=y2, then g(x)+g(y)>x2+y2>=2xy, where the last inequality is true because it’s equivalent to (x−y)2>=0. So we have g(x)+g(y)>2xy, which is a contradiction to the choice of y.
The second-to-last line of the proof is also very confusing. I think GPT-4 is using the same variable names to mean different variables, which leads it to say silly things like “the uniqueness of $y$ given $y$”.
In my opinion, GPT-4 is intelligent but needs extra infrastructure to allow memory and continuous learning to become an agentic AGI. It might not be that hard to add that infrastructure though and people are already trying: https://github.com/noahshinn024/reflexion-human-eval
Gotta disagree with Ben Levinstein’s tweet. There’s a difference between being an LLM that can look up the answers on Google and figuring them out for yourself.
I think the tweet is sarcasm. Not sure, though.