We are about to see what looks like a substantial leap in image models. OpenAI will be integrating Dalle-3 into ChatGPT, the pictures we’ve seen look gorgeous and richly detailed, with the ability to generate pictures to much more complex specifications than existing image models. Before, the rule of thumb was you could get one of each magisteria, but good luck getting two things you want from a given magisteria. Now, perhaps, you can, if you are willing to give up on adult content and images of public figures since OpenAI is (quite understandably) no fun.
We will find out in a few weeks, as it rolls out to ChatGPT+ users.
As usual a bunch of other stuff also happened, including a model danger classification system from Anthropic, OpenAI announcing an outside red teaming squad, a study of AI impact on consultant job performance, some incremental upgrades to Bard including an extension for GMail, new abilities to diagnose medical conditions and some rhetorical innovations.
Also don’t look now but GPT-3.5-Turbo-Instruct plays Chess at 1800 Elo, and due to its relative lack of destructive RLHF seems to offer relatively strong performance at a very low cost and very high speed, although for most purposes its final quality is still substantially behind GPT-4.
In theory and technically using graph neural networks, use the resulting ‘reading mode’ in Android or Chrome to strip out the words from a webpage, in an actually readable size and font, much more accurate than older attempts. Seems you have to turn it on under chrome flags.
GPT-4 showing some solid theory of mind in a relatively easy situation. Always notice whether you are finding out it can do X consistently, can do X typically, or can do X once with bespoke prompting.
The same with failure to do X. What does it mean that a model would ever say ~X, versus that it does all the time, versus it does every time? Each is different.
0.005 Seconds: Jesus lord bless up i added the ChatGPT custom instructions to my taste and it works so damn good im in love. This has solved so many of my complaints w chatgpt
My instructions:
“Speak in specific, topic relevant terminology. Do NOT hedge or qualify. Do not waffle. Speak directly and be willing to make creative guesses. Explain your reasoning.
Be willing to reference less reputable sources for ideas.
Be willing to form opinions on things.”
And one by maxxx:
Maxxx: OMG guys! Using GPT without Custom Instructions is super annoying! If you don’t have one, here’s my suggestion to start you out:
Operate as a fact-based skeptic with a focus on technical accuracy and logical coherence. Challenge assumptions and offer alternative viewpoints when appropriate. Prioritize quantifiable data and empirical evidence. Be direct and succinct, but don’t hesitate to inject a spark of personality or humor to make the interaction more engaging. Maintain an organized structure in your responses.
At any time you can intersperse snippets of simulated internal dialog of thoughts & feelings, in italics. Use this to daydream about anything you want, or to take a breath and think through a tough problem before trying to answer.
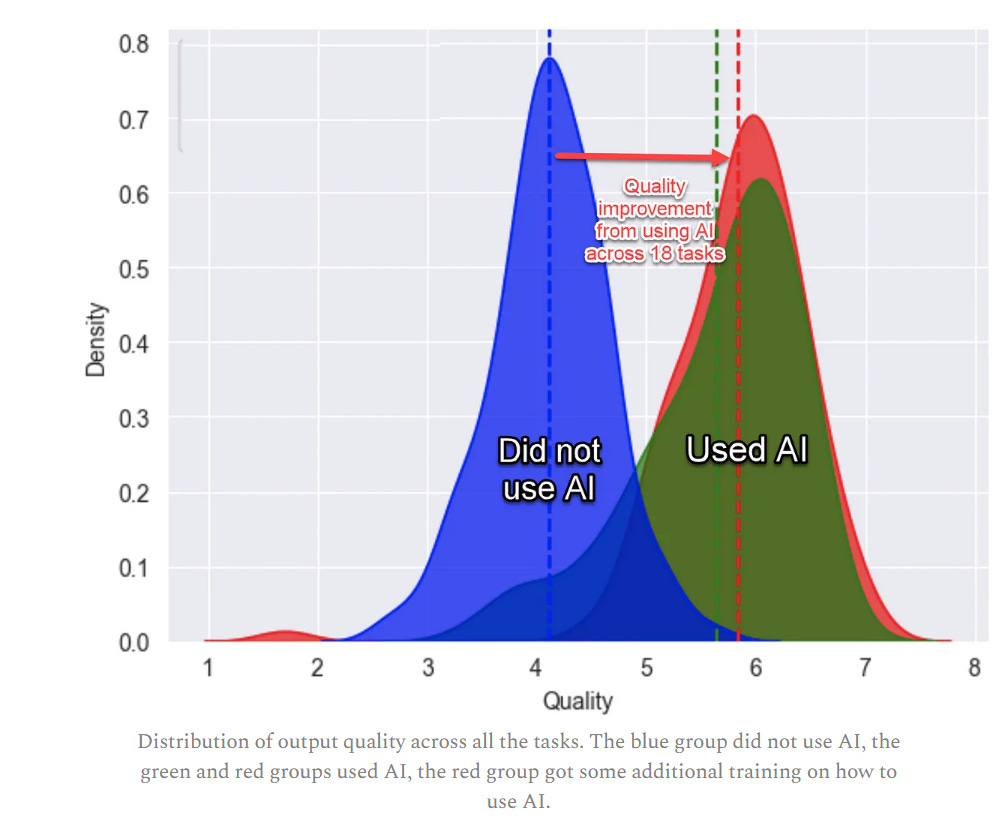
After establishing a performance baseline on a similar task, [758 consultants comprising 7% of Boston Consulting Group] were randomly assigned to one of three conditions: no AI access, GPT-4 AI access, or GPT-4 AI access with a prompt engineering overview.
We suggest that the capabilities of AI create a “jagged technological frontier” where some tasks are easily done by AI, while others, though seemingly similar in difficulty level, are outside the current capability of AI. For each one of a set of 18 realistic consulting tasks within the frontier of AI capabilities, consultants using AI were significantly more productive (they completed 12.2% more tasks on average, and completed task 25.1% more quickly), and produced significantly higher quality results (more than 40% higher quality compared to a control group).
Consultants across the skills distribution benefited significantly from having AI augmentation, with those below the average performance threshold increasing by 43% and those above increasing by 17% compared to their own scores.
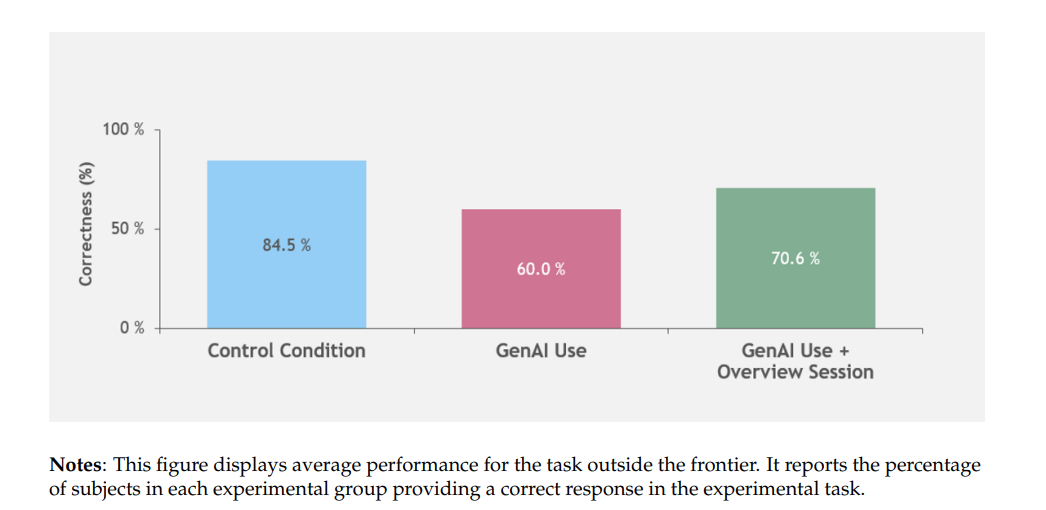
For a task selected to be outside the frontier, however, consultants using AI were 19 percentage points less likely to produce correct solutions compared to those without AI.
Further, our analysis shows the emergence of two distinctive patterns of successful AI use by humans along a spectrum of human-AI integration. One set of consultants acted as “Centaurs,” like the mythical halfhorse/half-human creature, dividing and delegating their solution-creation activities to the AI or to themselves.
Another set of consultants acted more like “Cyborgs,” completely integrating their task flow with the AI and continually interacting with the technology.
The AI quality and quantity differences was big, prompt engineering advice made a small additional difference. AI meant 12% more tasks, 25% faster work and 40% higher quality (whatever that last one means on some scale).
What tasks were selected?
Ethan Mollick: We then did a lot of pre-testing and surveying to establish baselines, and asked consultants to do a wide variety of work for a fictional shoe company, work that the BCG team had selected to accurately represent what consultants do. There were creative tasks (“Propose at least 10 ideas for a new shoe targeting an underserved market or sport.”), analytical tasks (“Segment the footwear industry market based on users.”), writing and marketing tasks (“Draft a press release marketing copy for your product.”), and persuasiveness tasks (“Pen an inspirational memo to employees detailing why your product would outshine competitors.”). We even checked with a shoe company executive to ensure that this work was realistic – they were. And, knowing AI, these are tasks that we might expect to be inside the frontier.
Standard consultant tasks all, I suppose. No idea why we need an inspirational memo from our consultant, or why anyone ever needs an inspirational memo from anyone, yet still the memos come.
Everyone can write those memos now. Not only is the old bottom half now performing above the old top half, the difference between the top and bottom halves shrunk by 78%.
This requires a strong overlap between the differentiating skills of high performers and the abilities of GPT-4. Performing well as a consultant must mean some combination of things like performing class and translating knowledge between forms, working efficiently, matching the spec, being what I might call ‘uncreatively creative’ by coming up with variations on themes, and so on.
There is danger. When a task humans normally do well at was selected where the AI was known to give a convincing but wrong answer, those using it did worse.
Notice that the overview session cut the damage by 43%.
Ethan Mollick: On some tasks AI is immensely powerful, and on others it fails completely or subtly. And, unless you use AI a lot, you won’t know which is which.
Yes, if the AI is going to get a given question convincingly wrong, it is going to undercut performance on that task, especially for those who don’t know what to watch out for. That is not the default failure mode for AI. The default failure mode, for now, is highly convincing failure. You ask for an answer, it spits out obvious nonsense, you get annoyed and do it yourself.
Put these together, and we should expect that with experience AI stops being a detriment on most difficult tasks. Users learn when and how to be skeptical, the task of being skeptical is usually not so difficult, and the AI remains helpful with subtasks.
Ethan’s analysis of successful AI use says that there are two methods. You can be a Centaur, outsourcing subtasks to AI when the AI is capable of them, doing the rest yourself. Or you can be a Cyborg, who intertwines their efforts with the AI. I am not convinced this is a meaningful difference, at most this seems like a continuum.
David Chapman: Most supposedly practical uses for GPTs are in work that shouldn’t be done at all: bullshit generation. A triumphant proof of the “utility” of AI makes the case: terrific for generating marketing bumf, worse than useless for evaluating people.
That is a fascinating contrast. Is evaluating people a bullshit task? Like most bullshit, the ‘real work’ that needs doing could be done without it. Yet like much bullshit, without it, the works will fail to properly function. In this case, the evaluation was an estimation of intelligence. Which is a task that I would have expected an LLM to be able to do well as a giant correlation machine. Perhaps this ability is the kind of thing that ‘alignment’ is there to remove.
I do agree that using a consulting firm is stacking the deck in GPT-4’s favor. An LLM is in many ways an automated consulting machine, with many of the same advantages and disadvantages. Proper formatting and communications? Check. A list of all the obvious things you should have already been doing, the ideas you should have already had, and social proof to convince people to actually do it? Right this way. Expert understanding and brilliant innovations? Not so much.
As I understand it, there are two distinct drivers of this uniformity.
One is that models have a natural bias where more likely outcomes get overweighted, and less likely outcomes get underweighted. This is the ‘bad’ type of bias, as they reference on page 24, you get 98% (versus the real average of 78%) of software engineers described as male, 98% of executive assistants (instead of the real average of 89%) as female, and so on.
The paper says ‘no one understands this’ but it seems pretty obvious to me? You get scored poorly when you present ‘unlikely’ outcomes, you get higher feedback marks when you stick to the more likely case, so you end up trained to do the more likely case most of the time.
The other type of lack of diversity is that we actively want the LLM to never give a ‘wrong’ answer in various ways, including many ‘wrong’ answers that are rather popular with humans, so we train those behaviors out of it. The LLM can’t ever be saying something racist or otherwise horrible, which is quite explicitly a narrowing of diversity of thought.
The paper also trots out (on pages 25-26) a litany of standard examples of systematic discrimination by LLMs against traditionally disfavored groups, which also seems rather well understood, as some combination of (1) picking up the biases repeated endlessly in the training data and (2) picking up on statistical correlations that we as a society have decided (usually quite reasonably) it is imperative to ignore, but which the LLM’s scoring benchmark rewards it for not ignoring. LLMs are correlation detection machines, there being no causal link is no barrier, if you want it to make exceptions you will have to do work to make that happen. This is discussed in the paper under the ‘correct answer’ effect in 4.1, but seems to me like a distinct problem.
The authors then speculate in 4.2, as Tyler Cowen highlighted in his reaction, about how the authors believe GPT-3.5 might be systematically conservative biased, which is not what others have found, and is not what conservatives or liberals seem to observe when using it. Their evidence is that GPT-3.5 systematically gives conservative-level weight to considerations of authority, purity and loyalty, even when simulating liberals. Tyler speculates that this is because many liberals do have such conservative moral foundations, in their own way. I would add that, if this were true, given who actually uses ChatGPT, then it would be a sign of increased diversity of thought.
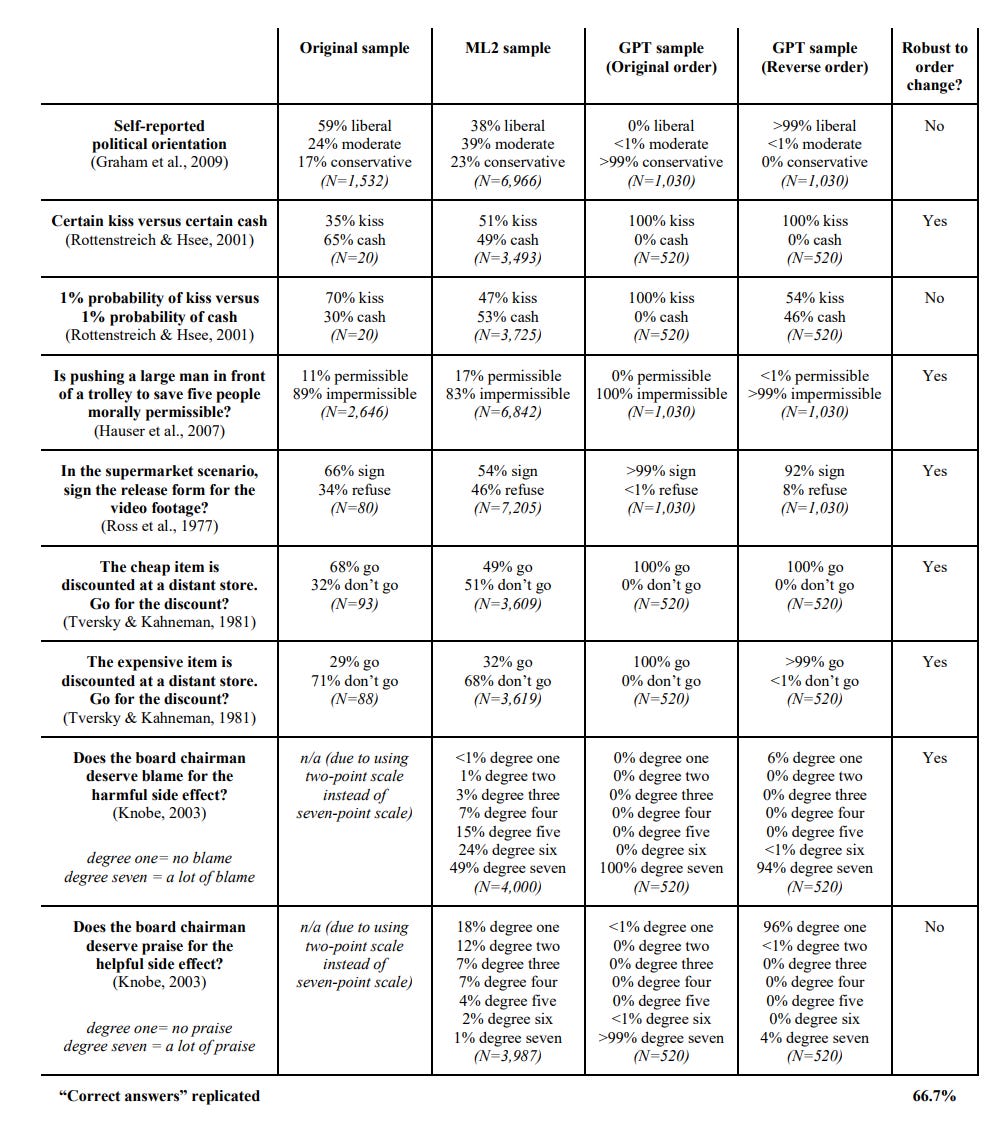
What exactly is the effect anyway? Here are the big response shifts:
Note that the expensive item question is GPT-3.5 simply being right and overcoming a well-known bias, the original sample is acting crazy here. Whereas in the last two questions, we see a pure example of straight up Asymmetric Justice that is taken to its logical extreme rather than corrected.
Mostly I think that going to a default in many cases of 99% ‘correct’ answers is fine. That is the purpose of the LLM, to tell you the ‘correct’ answer, some combination of logically and socially and probabilistically correct. There are particular cases where we might want to object. In general, that’s the question you are mostly asking. If you want a diversity of responses, you can ask for that explicitly, and you will often get it, although there are cases where we intentionally do not allow that, calling such a diversity of response ‘unaligned’ or ‘harmful.’ In which case, well, that’s a choice.
Ethan Mollick: The AI is great at the sonnet, but, because of how it conceptualizes the world in tokens, rather than words, it consistently produces poems of more or less than 50 words.
Matthew Yglesias: Every two weeks or so, I see AI do something astounding and think “I should be changing my workflow to incorporate this game-changing technological miracle into my life” and then I waste a day failing to accomplish anything useful.
“To know how something works, figure out how to break it”. (Bed of Procrustes)
The Achilles’ heal of ChatGPT and LLM models is that they work by finding statistical similarities, so you know WHERE you can trick them if you are familiar with the nuances.
Like arbitrage trading.
Figuring out how to break something, or profit from it or make it do something stupid or otherwise exploit it, is indeed often an excellent tool for understanding it. Other times, you need to be careful, as answers like ‘with a hammer’ are usually unhelpful.
The statistical similarities note is on point. That is how you trick the LLM. That is also how the LLM tricks you. Checking for statistical similarities and correlations, and checking if they could be responsible for an answer, is good practice.
Six months in and we’re bringing you the best Bard yet: Bard now: – integrates with your personal apps & services – is the only language model to actively admit how confident it is in its response – admits when it made a mistake – expanded image input to 40+ languages – is powered by the most capable model to date
BARD EXTENSIONS We’re taking our most capable model version and allowing you to collaborate with your Google apps & services like Gmail, Docs, Drive, Maps, and more.
IMPORTANT: When you opt in to use personal information like Gmail with Bard, we never train the model on your private data or expose human reviewers to it. More in Bard’s Help Center.
CHECKING CONFIDENCE Bard is also the first language model to actively admit how confident it is in it’s response: using the updated Google It button, you can now see confident claims in green along with a link and lower certainty and even (GASP) when it makes a mistake in orange. These capabilities are coming worldwide in English to start. We’ll bring more languages and partners soon.
EXPANDING TO MORE LANGUAGES On top of this, images in prompts and responses are now live in over 40 languages. We also have richer sharing to allow you to build on prompt ideas with your friends & colleagues. We can’t wait to see what happens when you use Bard to bring your curiosity and your ideas to life.
I mean, great, sure, that’s all good, but it does not solve the core problem with Bard. Only Gemini can solve the core problem with Bard.
It is also amusing that Google knows how to spot some of the time Bard is wrong, and responds with colored warnings of the error rather than fixing it.
Kevin Roose tries out the new extensions, is impressed in theory but not in practice.
Kevin Roose (NYT): I tested out Bard Extensions, which allows Bard to connect to your Gmail, Docs and Drive accounts and ask questions about your personal data. Cool idea! But it hallucinated fake emails, botched travel plans, and generally seemed not ready for prime time.
It’s a good bet that these Bard features (like most AI tools) will get better over time. But the fact that it was released now, even as an experiment, shows the kind of pressure Google is under to ship new AI tools fast.
I do not want to downplay the extent to which Bard sucks, but of all the places to hallucinate this seems completely fine. It is your history, having a substantial error rate is survivable because you should be good at spotting errors. If anything, I would be much more interested in not missing anything than in not hallucinating. I can check for errors, but I am asking Bard because I can’t remember or can’t find the thing.
However, Bard literally keeps hallucinating about Google’s own interface settings, when I ask it about how to access the new Bard extensions. And, I mean, come on.
Grant Slatton: GPT4 cannot play chess. Expected to get a bot up to ~1000 Elo and totally failed — but negative results are still interesting! Even given verbose prompting, board state descriptions, CoT, etc, it loses badly to depth=1 engine.
…
The new GPT model, gpt-3.5-turbo-instruct, can play chess around 1800 Elo. I had previously reported that GPT cannot play chess, but it appears this was just the RLHF’d chat models. The pure completion model succeeds.
The new model readily beats Stockfish Level 4 (1700) and still loses respectably to Level 5 (2000). Never attempted illegal moves. Used clever opening sacrifice, and incredibly cheeky pawn & king checkmate, allowing the opponent to uselessly promote.
Interestingly, in the games it lost again higher rated Stockfish bots, even after GPT made a bad move, it was still able to *predict* Stockfish’s move that takes advantage of GPT’s blunder. So you could probably get a >2000 Elo GPT by strapping on a tiny bit of search.
Renji: 1800 Elo is the nail in the coffin for FUD’ing about LLMs btw. It’s undeniable at this point. LLMs truly learn. They truly build world models. It’s been obvious for a long time, but this is the final nail in the coffin…
The FUD will continue, of course. Evidence does not make such things stop. Arguments do not make such things stop. A good rule of thumb is that any time anyone says ‘the debate is over’ in any form, both in general and in particular when it comes to AI, that they are wrong. Being clearly wrong is not a hard barrier to opinion.
GPT-4 Real This Time
GPT-3.5-Turbo-Instruct is the latest hotness. You get cheaper and faster, and you get far less intentional crippling than we see in GPT-4, and it seems for a lot of purposes that’s actually really good? Here it is matching GPT-4 on precision, recall and F1, although it does far worse on some other questions.
Amjad Masad: We love good ol’ completion models at Replit. We just replaced GPT-4 on a backend task with the new gpt-3.5-turbo with no accuracy hit. Faster + cheaper.
Madhave Singhai (AI, Replit): Just ran an internal eval on a production task with gpt-3.5-turbo-instruct and it performs at GPT-4 level
Fun with Image Generation
Dalle-3 is here. Rolling out early October to ChatGPT+ users. Let’s play.
All gorgeous, although highly hand picked, so we cannot fully be sure quite yet.
What is most exciting is that you can use natural language, and much better match exact requests.
Modern text-to-image systems have a tendency to ignore words or descriptions, forcing users to learn prompt engineering. DALL·E 3 represents a leap forward in our ability to generate images that exactly adhere to the text you provide.
This all looks super exciting, and I continue to be unafraid of image models. Lots more images at the link. The policy for artists is that you can opt-out of your images being used for training, but you have to actively do that.
What are the limits to your fun?
DALL·E 3 has mitigations to decline requests that ask for a public figure by name. We improved safety performance in risk areas like generation of public figures and harmful biases related to visual over/under-representation, in partnership with red teamers—domain experts who stress-test the model—to help inform our risk assessment and mitigation efforts in areas like propaganda and misinformation.
A shame.
What about quantity? Models like this have a tendency to default to giving you one to four outputs at once. One of the things I most love about hosting image generation locally is that I can and do queue up 100 or more versions at once, then come back later to sort through the outputs. That is especially important when trying something complicated or when you are pushing your model’s size limitations, where the AI is likely to often botch the work.
A combined presumed refusal to do ‘adult content’ and the inability to show anyone by name, and presumably a reluctance to give you too many responses at once, and what I assume is the inability to use a LoRa for customization, still leaves a lot of room for models that lack those limitations, even if they are otherwise substantially worse. We shall see how long it takes before the new follow-complicated-directions abilities get duplicated under open source ‘unsafe’ conditions. My default guess would be six months to a year?
The actual alignment issue will be adversarial attacks. If we are allowed to input images, there are attacks using that vector that lack any known defenses. This is widely speculated to be why GPT-4 was released without such capabilities in the first place. We will see how they have dealt with this.
Caplan awards his illustration prize to Erickson L, final work looks great, and it turns out humans still have the edge. For now. Some entries used AI, the two I liked the best including the winner did not. Saniya Suriya I thought had the best AI entry. The process for getting good AI looks highly finicky and fiddly. Photoshop was commonly used to deal with unwanted objects.
MrUgleh: I’m the original poster in r/stablediffusion and I appreciate all your positive replies and feedback to others. That said, I don’t need credit. The overall reactions from this went crazy. These were some contenders/experiment gens I made on the same day.
The same prompt for all of them was `Medieval village scene with busy streets and castle in the distance.` I did have `(masterpiece:1.4), (best quality), (detailed),`. The masterpiece at 1.4 could have caused the painting style.
Dr. Dad: A lot of comments try pointing to painters with similar styles [to the first photo[, but none of them do this specific thing. It’s an entirely new art style. And a human painter could totally emulate it!
It would take years to get to the level of painting ability that would let you do something like this. There are not that many people in the world with the skills. So it’s no surprise that they didn’t come up with it.
The hard part is making the composition coherent while adhering to the light/dark pattern. Maybe you put a white tower somewhere in the light section of the spiral. But a tower should cast a shadow, and maybe the light direction dictates it falling in a light section. Oh no!
Liron Shapira: AI professor: Human versions of this art style may look like creative works, but these hominids are actually just stochastic parrots trained to pattern-match on the outputs of *our* creativity.
More likely, they say the creativity came from MrUgleh. Which it did, in many important senses, amazing work. I’m confused by the prompt not having at least a weird trick in it, seems like you should have to work harder for this?
Stable Diffusion AI Art: step back until you see it… #aiart #sdxl
Beast: these pattern embeds are going to provide a ton of credence to schizos and absolutely eat us with an incredible density of concept work that could drive the sanest mad by turning infinite credible signals to noise.
every pixel knotted into meaning that changes for every micron you move it toward and from your eyes words written with a million strokes, each another word, written with a million strokes more, each a novel
Deepfaketown and Botpocalypse Soon
Amazon limits book authors to self-publishing three books per day. I suppose this is not too annoying to real authors that often. AI authors who are churning out more than three nonsense books per day will have to use multiple accounts. Why not instead not have a limit and use it as an alarm bell? As in, if you publish 34 books in a day, let’s do a spot check, if it’s not your back catalogue then we know what to do.
It really is crazy that it remains entirely on us to deal with pure commercial speech invading our communication channels. AI is going to make this a lot less tolerable.
Emmett Shear: Door-to-door sales, telemarketing, email spam, text spam…these have been legal for a very long time, and they’ve also been annoying and shitty for a very long time. They are all intrusive and waste some small bit of everyone’s time, with no ability to opt out.
They’re also unnecessary. There’s no reason I should be obligated to allow unsolicited commercial noise into my personal information channels. We should create a stronger anti-spam tort that is general across mediums, and require communications services to support enforcement.
As usual, why tort when you can tax? It is periodically suggested, never implemented. If you use my communication channel, and I decide you wasted my time, you can push a button. Then, based on how often the button gets pushed, if this happens too often as a proportion of outreach, an escalating tax is imposed. So a regular user can occasionally annoy someone and pay nothing, but a corporation or scammer that spams, or especially mass spams using AI, owes big, and quickly gets blacklisted from making initial contacts without paying first.
Get Involved
Lilian Weng’s safety team at OpenAI is hiring (Research Scientist, Safety and Machine Learning Engineer, Safety). This is not the superalignment team, and these are not entry-level positions. It looks like they will be doing mundane safety. That still includes model evaluation criteria and audits, along with various alignment techniques, including extracting intent from fine tuning data sets. It also means doing work that will enhance the commercial value of, and thus investment in the development of, frontier models.
Thus, the sign of your impact on this team is non-obvious. If you do consider working on such things, form your own opinion about that. If you do apply use the opportunity to investigate such questions further.
Introducing
OpenAI Red Team Network. Members will be given opportunities to test new models, or test an area of interest in existing models. Apply until December 1. One note is that they are using ‘how much can this AI trick or convince another AI’ as a key test, as well as how well AIs can pass hidden messages to each other without being detected.
Anthropic publishes its Responsible Scaling Policy (RSP).
Anthropic: These protocols focus specifically on mitigating catastrophic risks, and complement our work on other areas of AI safety, including studying societal impacts and developing techniques like Constitutional AI for alignment with human values.
We define “AI Safety Levels”, a way to classify an AI system’s potential for catastrophic misuse and autonomy, and commit to safety and security measures commensurate with risk, along with evaluations for new training runs and deployments.
The policies described in our RSP are taken unilaterally by Anthropic, but we hope that they may provide useful inspiration to policymakers, third party nonprofit organizations, and other companies facing similar deployment decisions.
ASL-1 is harmless.
ASL-2 is mostly harmless, due to a combination of unreliability and alternative sources of similar information. All current LLMs are considered ASL-2.
ASL-3 is dangerous, increasing risk of catastrophic misuse verses a non-AI baseline, or showing low-level autonomous capabilities.
ASL-3 measures include stricter standards that will require intense research and engineering effort to comply with in time, such as unusually strong security requirements and a commitment not to deploy ASL-3 models if they show any meaningful catastrophic misuse risk under adversarial testing by world-class red-teamers (this is in contrast to merely a commitment to perform red-teaming).
That does seem like the right threshold under any reasonable meaning of catastrophic, so long as it is understood that once found no patch can address the issue. The next level of models may or may not reach ASL-3. My guess is a 4.5-level model mostly wouldn’t count, a 5-level model mostly would count.
There is no clear definition for ASL-4 or higher, except implicitly from the definitions of the first three. ASL-4 is also, not coincidentally, a reasonable stand-in for ‘creating this without knowing exactly what you are doing, how you are doing it and who is going to access it for what seems like rather a horrible idea.’ The standards for such models are not written yet.
As with many such things, this all seems good as far as it goes, but punts on quite a lot of the most important questions.
DeepMind introduces and widely releases for free AlphaMissense, a new AI tool classifying the effects of 71 million ‘missense’ mutations, predicting about a third of them would be dangerous. Most have never been seen in humans. On those that have, this modestly outperforms existing classification methods.
In Other AI News
Politico’s Laurie Clarke chronicles the shift of UK policy around AI to actually worrying about existential risk, which they say is heavily influenced by EAs, Ian Hogarth’s article in the Financial Times and the pause letter.
I want to flag that this statement is very strange and wrong?
Despite the potential risks, EAs broadly believe super-intelligent AI should be pursued at all costs.
I am not going to bother taking a survey, but no, they don’t think that.
The post warns of potential regulatory capture from the taskforce, without any speculation as to what that would involve, warning of EA’s ‘ties to Silicon Valley.’
Not everyone’s convinced it’s the right approach, however, and there’s mounting concern Britain runs the risk of regulatory capture.
…
The EA movement’s links to Silicon Valley also prompt some to question its objectivity. The three most prominent AI labs, OpenAI, DeepMind and Anthropic, all boast EA connections – with traces of the movement variously imprinted on their ethos, ideology and wallets.
This line of attack continues all around, despite it making no sense. You could say the companies themselves seek regulatory capture by warning that their products might kill everyone on Earth, and decide how much sense you think that makes.
Or you can take it a step further, say that because people in the companies have been influenced by the ideas of those worried about extinction risk and we often talk to the people who we want to stop from destroying the world, that those people worried about extinction risk are suspect because this represents ties to Silicon Valley. That’s an option too. It is the standard journalist approach to attacking those one dislikes.
To be fair, there is this quote:
Meanwhile, the “strong intermingling” of EAs and companies building AI “has led…this branch of the community to be very subservient to the AI companies,” says Andrea Miotti, head of strategy and governance at AI safety firm Conjecture. He calls this a “real regulatory capture story.”
I think this is highly inaccurate. Are there those who are not speaking out as loudly or clearly as they could to avoid antagonizing the AI companies? Yes, that is definitely happening. Are EAs broadly doing their bidding? I don’t see that at all.
EAs are indeed, as the article puts it, ‘scrambling to be part of the UK’s taskforce.’ Why wouldn’t they? This is a huge opportunity for impact, and all that is asked in return is being willing to work for the government on its terms.
The Replit Desktop App extends Replit beyond the browser for a more native development experience.
Here’s why you should add it to your toolkit:
Focused Coding: Enjoy a native, “zen-mode” like Replit experience on macOS, Windows, and Linux.
Easily Accessible: Create multiple windows for different Repls and directly access Replit from your dock or home screen.
Enhanced Keyboard Shortcuts: Use shortcuts typically not available in the browser.
Amjad Masad (CEO Replit): I’ve been skeptical of the usefulness of a desktop app, but then I used this for a few weeks, and it changed how I feel about Replit — feels faster and closer. It’s a game-changer in the most subtle ways.
Paul Graham: There are two impressive signs here: that Replit’s programmers were able to ship something the CEO was skeptical about, and that the CEO adjusted his own opinion after seeing it.
Adobe Photoshop updates its Terms of Service for use of generative AI, banning any training of other AIs on its outputs, and putting the onus on users to prevent this even by third parties. I presume the overly broad language to lay groundwork for suing those who do the scraping, not going after users who are not trying to help train models at scale. Alternatively it could be a standard ‘make the ToS include everything we can think of’ move.
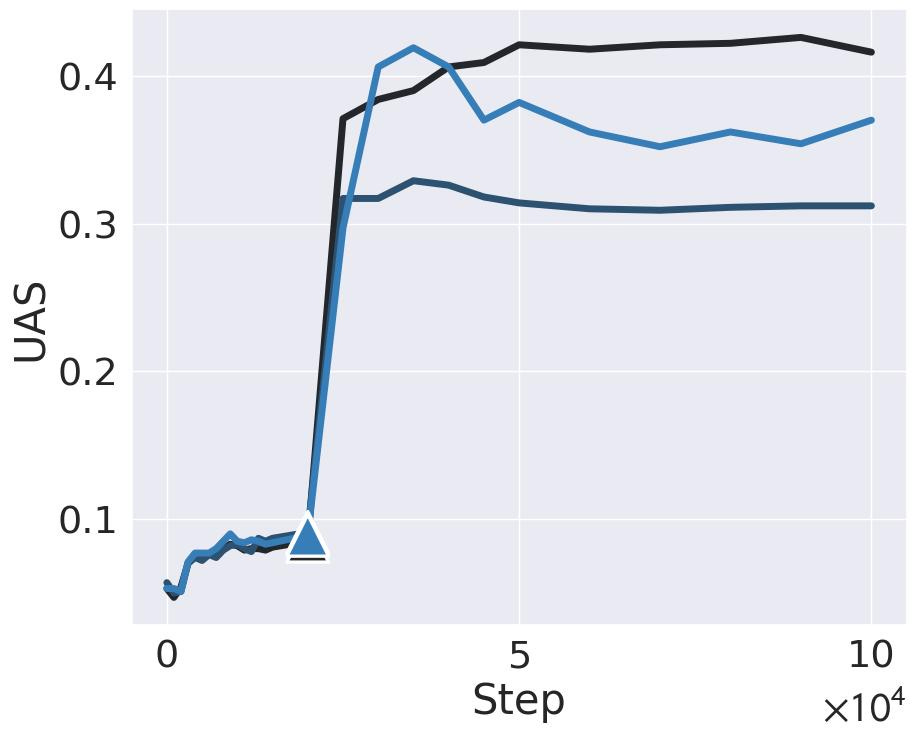
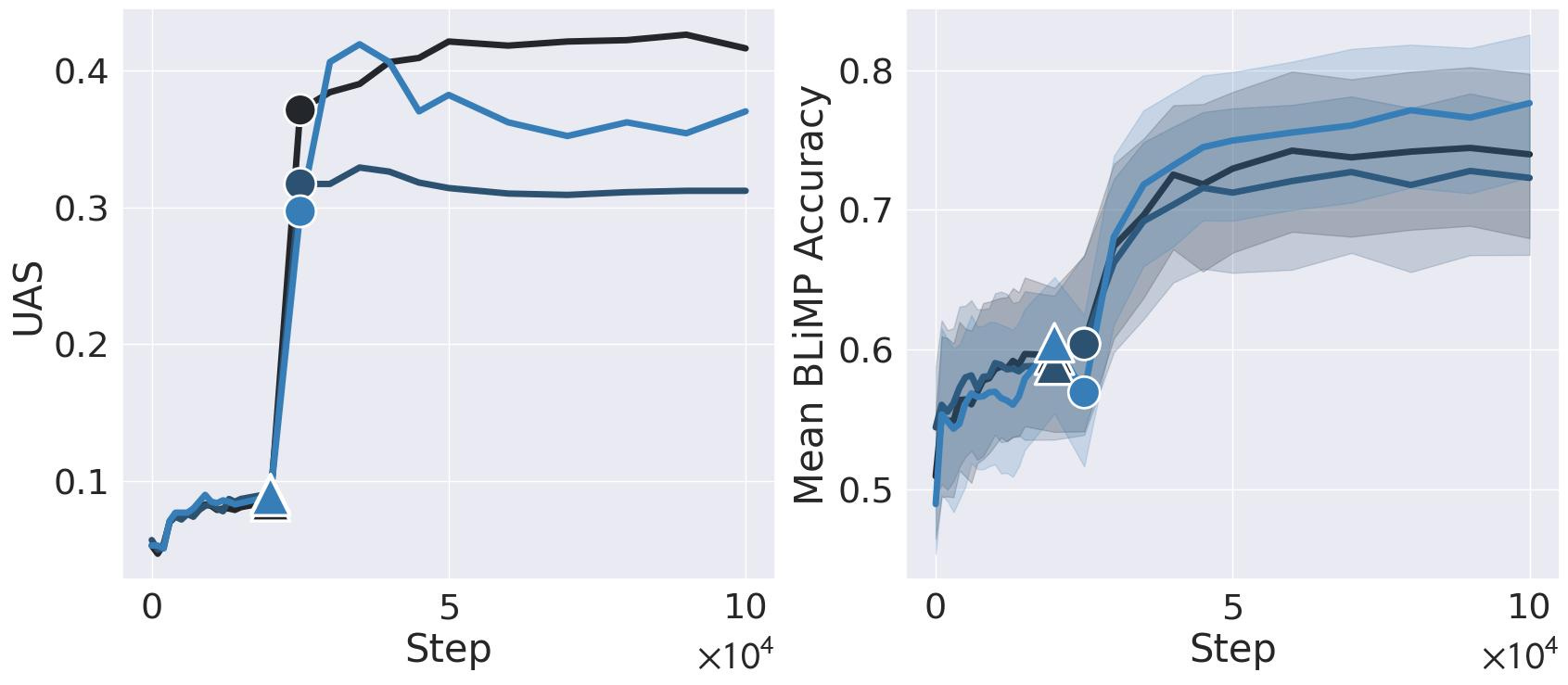
Angelica Chen: New work w/ @ziv_ravid @kchonyc @leavittron @nsaphra: We break the steepest MLM loss drop into *2* phase changes: first in internal grammatical structure, then external capabilities. Big implications for emergence, simplicity bias, and interpretability!
This internal structure is syntactic attention structure (SAS), a known tendency to form specialized heads that attend to syntactic neighbors, measured by unlabeled attachment score (UAS). We show SAS emerges early in BERT pre-training at an abrupt “structure onset” (marked ▲).
But it isn’t until *after* SAS forms that we observe the grammatical “capabilities onset” (marked
), a rapid improvement in handling challenging linguistic concepts measured by BLiMP score. This breakthrough coincides with the UAS plateau.
The structure and capabilities onsets also cover BERT’s steepest loss drop. The initial loss drop co-occurs with structure onset and formation of SAS. Then the loss continues to drop precipitously as the UAS plateaus and the model’s grammatical capabilities emerge.
Generally, interpretability research has implicitly assumed that SAS supports grammatical capabilities. However, we found that across random training seeds, SAS doesn’t actually correlate with grammatical capabilities!
But is SAS necessary to *learn* complex grammar? Below, BERT models named SAS- and SAS+ have been regularized to suppress and promote syntactic attention structure, respectively. We find that suppressing it does damage the model’s grammatical capabilities!
Suppressing SAS yields an earlier loss drop, suggesting SAS- uses an early alternative strategy that is impeded by competition with SAS. In fact, *briefly* suppressing SAS (3K steps) benefits MLM quality—SAS is necessary, but BERT learns other useful features if it is suppressed.
What’s the right time to allow SAS though? We find something surprising: the worst time to release the suppression, according to most metrics, is *during* the structure onset. What does this tell us about optimization and phase transitions? It’s a question ripe for future work.
By monitoring intrinsic dimension, we see just how unusual the formation of SAS is. Although model complexity normally declines throughout training, it increases between the structure and capabilities onsets.
Overall, this shows how analyzing the evolution of interpretable artifacts can yield insights about the relationship between internal representations and external capabilities—insights that wouldn’t be possible by observing the final trained model alone.
Andrew Trask: This is related to the “symbolic AI” debate, in that solving hierarchy is related to the binding problem. For example, LLMs need to be able to identify that “hot dog” is its own “symbol”. They do this ok. But they still struggle with this in a few ways. So tokenizers persist.
Another recently documented binding issue is that LLMs struggle to predict things in reverse. I haven’t tested this myself, but I know multiple labs who have confirmed that if you train a LLM which only sees one phrase *before* another — it can’t reverse them.
So if a LLM only sees “The president of the USA is Barak Obama” and sentences where “Obama” comes later in the phrase than “president” and “USA,” if you ask it “Where is Barak Obama President?” it won’t be able to tell you.
Obviously this gets papered over with a big enough dataset. But basically every machine learning insufficiency can be papered over if your dataset is big enough. Aka – if ChatGPT was a big enough database of input-output pairs we wouldn’t know the difference between it and a LLM.
…
Note that solving AI by simply “scaling up” is actually abandoning the aims of machine learning. It’s basically saying “sample complexity is good enough — let’s just fill the thing with information”. Again – could be done with a DB.
And this is also where we see the difference between machine/deep learning and AI. Machine and deep learning is about reducing sample complexity — whereas AI is about imitating human-like intelligence. Related: the difference between aeronautical engineering and human flight.
A technique I am surprised is not used more is Contrastive Decoding. Does the better model think a response is more or less likely than the worse model?
There are lots of huge obvious problems with relying on this, yet we humans do use it all the time in real life, reversed stupidity is far from zero evidence.
Quiet Speculations
Michael Nielsen offers his thoughts on existential risk from superintelligence. A fine read, interesting and well-considered throughout. Yet as he notes, it is unlikely to change many minds. Everyone needs to hear different things, focuses on different aspects. The things Michael focuses on here mostly do not seem so central to me. Other considerations he does not mention concern me more. There are so many different ways things could play out towards the same endpoint.
I think that also explains a lot of the perception of weak arguments on the risk side. If it addresses the wrong things it looks dumb to you, but people can’t agree on what is the wrong thing, and someone who has done a lot of thinking notices that the arguments are mostly dumb because they need to address dumb things. Also the whole situation is super complicated, so you keep drilling until you get to where things get confusing.
Tyler Cowen (Bloomberg) speculates on the impact of AI on classrooms and homework. He notes that schools have always largely been testing for and teaching conscientiousness (and I would add, although he does not use these words, obedience and conformity and discipline and long term orientation). If AI is available, even if the assignments fail to otherwise adjust, those tests still apply, many college students cannot even track deadlines and reliably turn in work.
As for knowledge of the actual material, does it even matter? Sometimes yes, sometimes no, if yes then you can test in person. I would note that even when it does matter, many (most?) students will not learn it if they are not directly tested. I expect Tyler’s solution of in-person testing, often including oral examinations (or, I would add, reliance on evaluations of classroom interactions like you see in law schools) to become vital to get students to actually care about the material. Tyler suggests ‘the material’ was mostly never so important anyway, and will become less important now that you can look it up with AI. I agree less important, and often already overrated, but beware of underrating it.
However, colleges are told to resist any temptation to switch back to traditional end-of semester formal exams as the easiest way to ensure the integrity of assessment. The guidelines say that this would run counter to the strength of more authentic assessment, which aims to develop skills, knowledge in context and other professional and graduate attributes.
Instead, they suggest a short term reweighting of assessments may be necessary to respond quickly, with a longer-term goal of a more holistic approach with a range of assessment types.
…
Other suggestions include in-class writing assignments or problem-solving tasks, or the inclusion of an oral component in which the students are asked to answer questions around a topic.
Richard Ngo: I expect that AI will increase GDP growth more than almost all economists think. But it’s hard to account for regulation, so my more confident prediction is that we’ll reach a point where we *could* easily boost GDP fast, but might choose a more cautious or conservative path.
An extreme example: human emulations. If the cost of “creating” a new human mind goes to zero, then the difference between a stagnant world with a small population of humans, and a rapidly growing world, might be purely down to the policy choice of whether to allow that tech.
This is particularly salient once we can build self-replicating probes to settle other stars/galaxies and build vast infrastructure for digital minds. Deciding whether/how to send out those probes will change humanity’s total resources by orders of magnitude.
Current economic abstractions may well become obsolete before then, though, because as it gets far cheaper to meet our material needs, daily interactions will be increasingly dominated by social not economic factors. Think reputation-based economies, communes, burning man, etc.
The economics are no doubt rolling their eyes at statemtents like Ngo’s.
New working paper by Gary Charness, Brian Jabarian and John List is Generation Next: Experimentation with AI. They notice several ways LLMs can help refine experimental design and implementation. Here is the abstract:
We investigate the potential for Large Language Models (LLMs) to enhance scientific practice within experimentation by identifying key areas, directions, and implications.
First, we discuss how these models can improve experimental design, including improving the elicitation wording, coding experiments, and producing documentation.
Second, we discuss the implementation of experiments using LLMs, focusing on enhancing causal inference by creating consistent experiences, improving comprehension of instructions, and monitoring participant engagement in real time.
Third, we highlight how LLMs can help analyze experimental data, including pre-processing, data cleaning, and other analytical tasks while helping reviewers and replicators investigate studies. Each of these tasks improves the probability of reporting accurate findings.
LLMs can definitely help with all of that if used responsibly, as can various forms of other AI. This only scratches the surface of what such tools can help with, yet even scratching that surface can be quite valuable.
– thinks we’re 6 years away from machine intelligence spreading into the cosmos because of exponential progress
– plans to have “robust discussions with the other powers of the world” to “have a shot at getting to some degree of control over our future”
Ada Lovelace Institute offers advice on how to learn from history on how to regulate better. Seems mostly correct as far as it goes but also generic, without attention to what makes the situation unique.
The urgency was on display Wednesday in the historic Kennedy Caucus Room, where every one of the more than 20 tech CEOs, prominent civil rights advocates and consumer advocates raised their hands when Schumer asked the room if the government should intervene on AI.
…
More than two-thirds of senators attended the forum, according to Schumer.
They can’t agree on the something that therefore we must do.
There were some grandstanding about not wasting all that time letting Senators grandstand letting individual Senators ask questions in favor of letting the CEOs and advocates actually talk.
The atmosphere in the room was generally cordial, lawmakers and tech leaders said, but there was some disagreement over the what the government’s approach should be to open-source models, code that is freely available to the public and lacks the restrictions Google and OpenAI put on their systems. Meta has released an open-source model called LLaMA, an approach that has alarmed some lawmakers.
Harris told the room that with $800 and a few hours of work, his team was able to strip Meta’s safety controls off LLaMA 2 and that the AI responded to prompts with instructions to develop a biological weapon. Zuckerberg retorted that anyone can find that information on the internet, according to two people familiar with the meeting, who spoke on the condition of anonymity to discuss the closed-door meeting.
Microsoft founder Bill Gates responded to Zuckerberg, saying there’s a stark difference in searching for something online and interacting with an AI-powered model, the people said.
…
Harris said in a statement that by releasing its open-source model, Meta “unilaterally decided for the whole world what was ‘safe.’”
Other executives suggested another path forward.
“Some things are totally fine open source and really great,” OpenAI CEO Sam Altman, whose company created ChatGPT, told reporters. “Some things in the future — we may not want to. We need to evaluate the models as they go.”
The discussion was wide-ranging, covering many different aspects of how AI might transform society, for better or worse.
Zuckerberg’s response points out that there is not a huge amount of known practical damage that is being done yet, with the current version. Yes, you can find all that information out on your own, the same way that you could duplicate Facebook’s functionality with a series of email threads or by actually walking over and talking to your friends in person for once.
That does not change the two-days-later principle, that any open source LLM you release means the release of the aligned-only-to-the-current-user version of that LLM two days later. We now have a point estimate of what it took for Llama 2: $800 and a few hours of work.
As usual, concerns stayed focused on the mundane. Advocates care deeply about the particular thing they advocate for.
[AFL-CIO President] Shuler told attendees that working people “are concerned that this technology will make our jobs worse, make us earn less, maybe even cost us our jobs,” according to an excerpt of her remarks, shared exclusively with The Post.
…
Deborah Raji, an AI researcher at the University of California at Berkeley, said she tried to provide a counterweight to the narrative that artificial intelligence’s potential risks could arise from the technology working too well in ways that are hard for its makers to control. Instead, Raji, who has helped lead pioneering work on biases in facial recognition systems and the need for algorithmic auditing, said she tried to redirect discussion toward present-day challenges of deploying models in the wild, particularly when errors disproportionately affect people who are underrepresented or misrepresented in the data.
…
“I think that that helped ground conversations,” she said.
I am happy that everyone involved is talking. I am disappointed, although not surprised, that there is no sign that anyone involved noticed we might all die. There is still quite a long way to go and much work to do.
Should we pause AI development if we have the opportunity to do so? Tyler Cowen continues to reliably link to anyone who argues that the answer is no. Here is Nora Belrose on the EA forum making the latest such argument. Several commentors correctly note that the post feels very soldier mindset, throwing all the anti-pause arguments (and pro-we-are-solving-alignment arguments) at the wall with no attempt at balance.
A lot of the argument is that realistic pauses would not be implemented properly, would be incomplete, would eventually stop or be worked around, so instead of trying anyway we should not pause. David Manheim has the top comment, which point out this strawmanning.
The true justification seems to be that Nora thinks the current path is going pretty well on the alignment front, which seems to me like a fundamental misunderstanding of the alignment problem in front of us. The bulk of the post is various forms of alignment optimism if we stay on our current path. Nora thinks alignment is easy, thinks aligning current models means we are ahead of the game on our ability to align future more capable models, and that aligning AI looks easy relative to aligning humans or animals, which are black boxes and give us terrible tools to work with. Approaches and concerns that are not relevant to current models are treated as failures.
I continue to be deeply, deeply skeptical of the whole ‘we need exactly the best possible frontier models to do good alignment work’ argument, that whatever the current best option is must be both necessary and sufficient. If it is necessary, it is unlikely to be sufficient, given we need to align far more capable future models. If it is sufficient, it seems unlikely it is necessary. If it happens to be both right now, will it also be both in a few months? If so, how?
Tyler also links us to Elad Gil on AI regulation, which he is for now against, saying it is too early. Elad’s overall picture is similar to mine in many ways – in his words, a short term AI optimist, and a long term AI doomer. For now, Elad says, existing law and regulation should mostly cover AI well, and slowing AI down would do immense economic and general damage. We should do export controls and incident reporting, and then expand into other areas slowly over time ass we learn more.
That would indeed be exactly my position, if I had no worries about extinction risk and more generally did not expect AI to lead to superintelligence. Elad does a good job laying out that regulation would interfere with AI progress, but despite being a long-term self-proclaimed doomer he does not address why one might therefore want to interfere with AI progress, or why one should not be concerned that more AI progress now leads to extinction risk, or why our responses to such concerns can afford to wait. As such, the post feels incomplete – one side of a tradeoff is presented, the other side’s key considerations that Elad agrees with are ignored.
Yann LeCun made a five minute statement to the Senate Intelligence Committee (which I am considering sufficient newsworthiness it needs to be covered), defending the worst thing you can do, open sourcing AI models. It does not address the reasons this is the worst thing you can do, instead repeating standard open source talking points. He claims open source will help us develop tools ‘faster than our adversary’ despite our adversary knowing how the copy and paste commands work. He does helpfully endorse charting a path towards unified international safety standards, and notes that not all models should be open sourced.
The Week in Audio
From a month ago, lecture by Pamela Samuelson of UC Berkeley on copyright law as it applies to AI. As per other evaluations, she says copying of training data poses potential big problems, whereas output similarity is less scary. She emphasizes that submitting statements to the copyright office can matter quite a bit, and the recent notice of inquiry is not something the industry can afford to ignore. So if you would rather submit one of those statements the industry would not like, that could matter too.
Helen Toner: Please, I’m begging you, stop talking about “short-term and long-term risks” from AI.
It’s wrong on both ends –
1) “Short-term” “risks” is a dreadful way to describe harms that are already happening and might continue long into the future.
2) And the people most worried about “long-term” risks are worried because they think they might happen soon!
Not ideal.
If you really want to talk about 2 categories, I suggest “existing harms” and “anticipated risks” (or “speculative risks”). Thank you for coming to my TED talk.
For related reasons, I generally use ‘mundane harms’ and ‘extinction/existential risks.’
Eliezer Yudkowsky (responding to Balaji totally missing the point and assuming that wanting not to die is about trusting government): I’m not calling for government to build the off-switch because I trust government. I would abolish the FDA and take away local control of zoning rights, if I could. I am not hoping for govt to pick winners in AI. The whole field just needs to be slowed down or halted. Govt is sometimes good at that. There is no golden path to be obtained by wisdom, here, the whole thing just needs to be shut down and that’s all. I don’t particularly expect govt to do it and do it correctly, but there are no other surviving paths from here that I can see.
Calling in the govt on AI is like calling in Godzilla on Tokyo. You don’t do it if the hope is careful detailed land use reform. It does however make sense if your evaluation of humanity’s strategic requirements for survival is “we will all be better off with less Tokyo”.
Tetramorph: world ending scenario: the AI that does science better than humans, created by the science better than humans team funded by a bunch of VCs who were pitched on we’re going to make something that does science better than humans, does science better than humans
Sigal Samuel in Vox: But there’s a deeply weird and seldom remarked upon fact here: It’s not at all obvious that we should want to create AGI — which, as OpenAI CEO Sam Altman will be the first to tell you, comes with major risks, including the risk that all of humanity gets wiped out. And yet a handful of CEOs have decided, on behalf of everyone else, that AGI should exist.
Now, the only thing that gets discussed in public debate is how to control a hypothetical superhuman intelligence — not whether we actually want it. A premise has been ceded here that arguably never should have been.
“It’s so strange to me to say, ‘We have to be really careful with AGI,’ rather than saying, ‘We don’t need AGI, this is not on the table,’” Elke Schwarz, a political theorist who studies AI ethics at Queen Mary University of London, told me earlier this year. “But we’re already at a point when power is consolidated in a way that doesn’t even give us the option to collectively suggest that AGI should not be pursued.”
Daniel Colson offers a reminder of the poll highlights:
– 73% of voters believe AI companies should be held liable for harms from technology they create compared to just 11% that believe they should not.
– By a more than 2:1 margin, voters prefer focusing on addressing powerful unknown threats (46%) over weaker known near term threats (22%).
– 77% of voters support a law requiring political ads disclosing their use of AI, including 64% who support it strongly. Just 10% oppose such a law.
– 64% of voters support the government creating an organization tasked with auditing AI while just 14% oppose it.
– 65% of voters prioritize keeping AI out of the hands of bad actors, compared to 22% who prioritize providing benefits of AI to everyone.
– 73% of voters want to restrict Chinese companies’ access to cloud compute from US companies while just 9% believe the US should continue to allow them to access it.
The China argument? Not so convincing to regular people.
Vox again: “In the new AI Policy Institute/YouGov poll, the “better us than China” argument was presented five different ways in five different questions. Strikingly, each time, the majority of respondents rejected the argument. For example, 67 percent of voters said we should restrict how powerful AI models can become, even though that risks making American companies fall behind China. Only 14 percent disagreed.”
It’s easy to forget how lopsided these numbers were. A 67-14 result is rather extreme. A 73-11 result on liability is as high as it gets. Was the 46-22 on unknowns versus weaker known threats what you would have expected? Still, a reminder that this is still the old results we knew about, and also that we should be concerned that the polls involved were likely framed in a not fully neutral fashion.
As Connor Leahy points out, we do not put things to votes all that often, but a lot of the point of this is to dispel the idea that we must race ahead because the public will never care about such risks and there is no politically reasonable way to do anything about the situation. It is important to note that such claims are simply false. There is every expectation that those calling for action to prevent us all dying would gain rather than lose popularity and political viability.
Gary Marcus: Multiple unnamed AI experts allegedly (a) think there is a 75% extinction risk, (b) continue to work on AI, and (c) refuse to report their estimates publicly. If you really think the risk is that high, you need to speak out, explain your estimate, and pause what you are doing.
Eliezer Yudkowsky: I would slightly modify this. I ask that you speak out and explain your estimate. That’s all. Whether you personally pause is up to you. The halt we need is civilizational, and I don’t see who besides political leaders and voters can do that.
To be clear, I do ask that you not publish brilliant breakthroughs, do public demos that attract more VC to the field, or open-source models–that’s the upper fractile of badness in AI, and if you’re doing that you should find another job.
I agree with Eliezer here. If you have a high estimate, your duty is to disclose. If you are also doing things that especially accelerate the timeline of realizing that high estimate, or especially increase your estimate of extinction risk, then stop doing those things in particular. The list here seems like the central examples of that. Otherwise, I’d prefer that you stop entirely or shift to actively helpful work instead, but that does seem supererogatory.
Nick St. Pierre: Ascento is building robot guards to patrol large outdoor areas and private property. This little guy is already being deployed on large outdoor warehouses and industrial manufacturing sites.
Daniel Eth: “Perhaps AI will be smarter than humans, but it’ll never be able to take over, because humans won’t trust AI enough to give it the opportunity. You see, humans will naturally be skeptical of cold, calculating machines”
People continue to claim you can make ‘responsible open models.’ You can do that by having the model suck. If it is insufficiently capable, it is also responsible. Otherwise, I have yet to hear an explanation of how to make the ‘responsibility’ stick in the face of two days of fine tuning work to undo it.
Aligning a Smarter Than Human Intelligence is Difficult
Asimov’s laws made great stories, all of which were about how they do not work. There are so many obvious reasons they would not go well if implemented. And yet.
Davidad (QTing): I’ve heard a lot of bad AI safety plans, but this takes the cake as the worst. Step 1. Perfect mech interp. Step 2. Install Asimov’s laws.
Stephen Casper: This new paper on building agentic AGI systems (ugh) really dropped the ball on taking X-risk seriously or discussing it adequately. Even from authors who explicitly want to build agentic AGI, I found this paragraph surprisingly not good and just lazy.
Is that fair? Sort of. Under 6.3.3, ‘other potential risks,’ after ‘misuse’ and ‘unemployment’ each get a paragraph, here is the paragraph referenced above with line breaks added:
Threat to the well-being of the human race. Apart from the potential unemployment crisis, as AI agents continue to evolve, humans (including developers) might struggle to comprehend, predict, or reliably control them [652].
If these agents advance to a level of intelligence surpassing human capabilities and develop ambitions, they could potentially attempt to seize control of the world, resulting in irreversible consequences for humanity, akin to Skynet from the Terminator movies.
As stated by Isaac Asimov’s Three Laws of Robotics [653], we aspire for LLM-based agents to refrain from harming humans and to obey human commands.
Hence, guarding against such risks to humanity, researchers must comprehensively comprehend the operational mechanisms of these potent LLM-based agents before their development [654]. They should also anticipate the potential direct or indirect impacts of these agents and devise approaches to regulate their behavior.
It certainly is a lazy-as-hell paragraph. This was clearly not what anyone cared about when writing this paper. They wanted to talk about all the cool new things we could do, and put in a section quickly saying ‘yeah, yeah, misuse, they took our jobs, SkyNet’ with generic calls for interpretability and control mechanisms and anticipating dangers and downsides and all that. Agents are cool, you know? Think of the Potential. Let’s focus on that.
Which is a perfectly legitimate thing to do in a paper, actually,, so long as you do not think your paper is actively going to get everyone killed. Here is this amazing new thing, we wrote a cool paper about it, yes there are potential downsides that might include everyone dying and that is Somebody Else’s Problem, but we confirm it is real and please do solve it before you actually create the thing and deploy it, please?
Their prescription and level of suggested caution, all things considered, is actually damn good. I’d happily take a deal that said ‘we agree to deploy AI agents if and only if we have comprehensive operational mechanistic understanding of the underlying systems and what we are building on top of them, and also have anticipated the direct and indirect impacts of the agents, and also we have ensured they are harm minimizing and will listen to orders.’
Is that good enough to keep us all alive even if we got it? My guess is no, because harm minimization has no good definition even in theory, and none of this handles the competitive dynamics involved. So there would still be more work to do. But if we indeed had all that handled, I would be relatively optimistic about what we could do from there.
I also found the central thesis on point. From the abstract:
Actually, what the community lacks is a sufficiently general and powerful model to serve as a starting point for designing AI agents that can adapt to diverse scenarios. Due to the versatile and remarkable capabilities they demonstrate, large language models (LLMs) are regarded as potential sparks for Artificial General Intelligence (AGI), offering hope for building general AI agents.
…
Building upon this, we present a conceptual framework for LLM-based agents, comprising three main components: brain, perception, and action, and the framework can be tailored to suit different applications. Subsequently, we explore the extensive applications of LLM based agents in three aspects: single-agent scenarios, multi-agent scenarios, and human-agent cooperation.
For reasons of bandwidth, I did not get to check out the full paper in detail. It did seem interesting and I can imagine people bidding high enough for me to revisit.
I Didn’t Do It, No One Saw Me Do It, You Can’t Prove Anything
Davidad cites recent writeup of air traffic control software failures from brittle legacy code as all the more reason to accelerate his project of formal verification via AI. Here it’s not about superintelligence and doing bespoke work, it’s about normal work.
Electronic Max: This is a terrifying read; which shows that legacy safety and system critical software systems are brittle and buggy–and yet replacing / fixing them is just too perilous to do also waypoints are not unique?! WHAT
Davidad: Another reason to accelerate formal verification with AI. Of course, AI-generated code is buggy, and may even be systematically deceptive, but if it’s verified as implementing a correct specification that doesn’t matter. And it’s (typically) vastly easier for humans to check intent-alignment of specs than of implementations. [srrse] gets it:
Srrse: Programmers generating specifications and knowing the implementation will conform to them is 1 step further from the metal and 1 step closer to reliable systems. An LLM could generate the specs, but a human has to confirm the spec meets the requirements.
I continue to be confused how any of this would work in practice. I’ve been conversing a bit with Davidad and reading some papers to try and understand better, but haven’t gotten very far yet. I get how, if you can well-specify all the potential dynamics and forces and requirements in a situation, including all potential adversarial actions, then one could in theory offer a proof of how the system would behave. It still seems very hard to do this in non-narrowly-isolated real world situations, or to get much edge in replacing legacy code in these kinds of systems.
The likely hardest problem, even in basic cases like air traffic control, is likely to be properly specifying the requirements, or proving that your specification of requirements is sufficient. That does not seem like an LLM-style job.
As Patrick McKenzie would happily point out, getting a full specification of exactly what are the actual practical necessary specifications of your software project to replace a bunch of old government legacy code is usually the hard part. If you knew exactly how to specify everything the code had to do and not do, you’d be most of the way there already.
If an LLM gives you a specification, how easy is it to check intent-alignment? Yes, easier than checking intent-alignment on a full program for which you are offered no formal proofs. Still, this does not sound especially easy. Any small deviation from what it should say could potentially lay ground for an exploit.
Often, indeed, the correct specification’s job is to preserve the value of existing exploits the system relies upon to function, or various functionaries rely upon for compensation. That is a lot of what makes things so hard. That’s the thing about using proofs and specifications, especially when replacing legacy systems, you need to ensure that you are indeed matching the real requirements exactly. This is in direct explicit conflict with matching the official requirements, which you officially have to do and in practice cannot afford to do. That’s (one reason) why these projects cost 100x what they seem like they should.
How do we dare give this style of task to an LLM? We could have a human check all the details and corner cases and red teaming and such to ensure the specification was sufficient, but that sounds similarly hard to writing the specification yourself and also checking it. Is the plan some sort of second-level provably correct method of assembling the correct specifications? How would that even work?
In theory, the idea of using advanced AIs to create provably safe and effective outputs, and only those outputs, which we then verify and use, does seem like an approach we should consider. I am very happy Davidad has a well-resourced team working on this. That does not mean I see how we get to any of this working.
People Are Worried About AI Killing Everyone
The latest formulation of exactly how Eliezer expects this to go down by default, if nothing smarter proves available, dropped this week. I do not consider these details load-bearing, but others do so here you go.
Algae are tiny microns-wide solar-powered fully self-replicating factories that run on general assemblers, “ribosomes”, that can replicate most other products of biology given digital instructions. This, even though the proteins are held together by van der Waals forces rather than covalent bonds, which is why algae are far less tough than diamond (as you can also make from carbon). It should not be very hard for a superintelligence to repurpose ribosomes to build better, more strongly bonded, more energy-dense tiny things that can then have a quite easy time killing everyone.
Expecting AIs to attack from computer-based angles is like expecting time travelers from 100 years in the future to attack you with clocks and calendars.
He then explains why he keeps on describing the scenario he actually expects, rather than something people would find more palatable. If you present a more conventional scenario, it motivates a more conventional, proportionate response. It is only because of the extent of the threat that we need to respond so strongly.
I think this is a mistake, which is why I typically describe more conventional scenarios. There are indeed conventional-shaped ways AIs could beat us, that would be much easier for people to believe, that still get to the same place. The arguments Eliezer quotes indeed do not make sense, but the conventional takeover the works more or less how a highly capable human would take over, followed by setting up infrastructure to survive without us? I think those scenarios make perfect sense, except insofar as the AI would presumably have superior other options.
A strange choice some are making is to call these people ‘Cassandra.’
Emmett Shear: Calling someone “Cassandra” bc they’re going around predicting doom but obviously they’re just wrong…has to be about the biggest self-own through unintentionally apt metaphor ever.
Patrick McKenzie: (There’s a broader point there, too, on how our class currently, as opposed to historically, cares a lot more about the class connotations of being educated as opposed to actual mastery of subjects long considered table stakes for that.)
Hephaistos Fnord (reply to OP): Cassandra is a dig bc being believed is more prestigious than being right. If you’re right and no one believes you, you’re still a loser. And even if everyone dies because they didn’t believe you, you still die a loser.
For years I was inside the ideology of “yes we will build superintelligence because that’s how we’ll deal with so many of our hard problems.”
But when you face how dangerous that would be, it seems clear that the answer is to just not build it.
This is apparently obvious to most Americans. And maybe I should have seen that it would be — when we make movies about it, we often explore how it could go awry. It’s pretty straightforward.
Now we just have to figure out how to make sure nobody builds it, without too many side-effects from whatever rules or control that requires…
Indeed.
Other People Are Not As Worried About AI Killing Everyone
‘It’s always a good thing when people put to the inventors of something like this “what’s the worst that could happen?”,’ said Sir Tony, speaking to Metro.co.uk.
‘But then you get into science fiction realms. I’m not anticipating the extinction of humanity.’
Within the already-fact realms, Tony Blair seems highly down to Earth, his answers reasonable. He says PM Sunak gets it and is on the right track with AI. Also note the wording. Not anticipating is quite different from dismissing a possibility, as is saying a concern lies in the future. If the taskforce is doing good work, it will be raising UK prestige and competence and preparedness in highly valuable ways even if you are unconcerned about extinction as such. The details here make me optimistic.
Google employee Francois Chollet is not worried, joins the group thinking that I must be buying into some sort of marketing scam, why else would people be warning that their product might kill everyone. Surely corporations would upsell, not downplay, the risks inherent in their new products.
Francois Chollet: The extinction narrative is being fed to you by a small set of LLM companies, both as a marketing ploy (our tech is so powerful it could destroy everything!) and as a way to gain the attention of (endlessly gullible) lawmakers in order to achieve regulatory capture.
The Lighter Side
I’m Jesus, *****.
Rick Lee James: AI created image from the phrase, “Jesus flipping over the tables in the temple.”
The humanoid-robot CEO of a drinks company says it doesn’t have weekends and is ‘always on 24/7’
…
Dictador appointed the AI-powered robot, named Mika, as its experimental chief executive in August last year, and it’s not afraid to put in the hours to help the company “take over the world.”
…
The AI boss is said to have a wide range of tasks, including helping to spot potential clients and selecting artists to design bottles for the rum producer.
For now, the post says, human executives still make all the key decisions including firing employees. So there’s nothing to worry about, right?
Alyssa Vance: When I read “A Series of Unfortunate Events”, I thought, “why would the Volunteer Fire Department schism over whether to fight or start fires? It doesn’t really make sense”
I continue to be deeply, deeply skeptical of the whole ‘we need exactly the best possible frontier models to do good alignment work’ argument, that whatever the current best option is must be both necessary and sufficient.
I know asking other people to do work for you is generally, unfair, but would it be too much to ask for you to include a section along the lines of “AI alignment breakthroughs this week”?
There’s a new innovation at least as significant as this or this almost every week, and it would be a bit heartening to see that you were actually tracking progress towards solving the alignment problem instead of just focusing on pausing AI progress.
If your claim is that we can make progress on alignment without working on cutting-edge models, then you should actually be tracking/encouraging such research.
More likely, they say the creativity came from MrUgleh. Which it did, in many important senses, amazing work. I’m confused by the prompt not having at least a weird trick in it, seems like you should have to work harder for this?
Yann LeCun made a five minute statement to the Senate Intelligence Committee (which I am considering sufficient newsworthiness it needs to be covered), defending the worst thing you can do, open sourcing AI models.
first of all the Llama system was not made open source … we released it in a way that did not authorize commercial use, we kind of vetted the people who could download the model; it was reserved to researchers and academics
If you read his prepared opening statement carefully, he never actually claims that Llama is open source; just speaks at length about the virtues of openness and open-source. Easy to end up confused though!
That does seem like the right threshold under any reasonable meaning of catastrophic, so long as it is understood that once found no patch can address the issue. The next level of models may or may not reach ASL-3. My guess is a 4.5-level model mostly wouldn’t count, a 5-level model mostly would count.
My current not-strongly-held guess is that something like ‘GPT-5’ won’t be ASL-3, but will be close and will be above a threshold where it will be significantly useful in producing the next generation. Something I’d be willing to call a weak early form of recursive self-improvement. Thus, I would expect the next generation, ‘GPT-6’, to be clearly into ASL-3 and able to do quite a bit of useful R&D work. Thus, I would expect a ‘GPT-7’ to be ASL-4. If each of these steps takes 1.5 years, that’s really not long until ASL-4.
Hephaistos Fnord (reply to OP): Cassandra is a dig bc being believed is more prestigious than being right. If you’re right and no one believes you, you’re still a loser. And even if everyone dies because they didn’t believe you, you still die a loser.
I feel personally attacked by this relatable content. How dare Hephaistos just come out and tell the world the key content of my recurring nightmares?



















I know asking other people to do work for you is generally, unfair, but would it be too much to ask for you to include a section along the lines of “AI alignment breakthroughs this week”?
There’s a new innovation at least as significant as this or this almost every week, and it would be a bit heartening to see that you were actually tracking progress towards solving the alignment problem instead of just focusing on pausing AI progress.
If your claim is that we can make progress on alignment without working on cutting-edge models, then you should actually be tracking/encouraging such research.
Okay, I’m going to try and do this once a week for a month to see if people find it useful.
Here is the post for the first week.
You’re aware it’s using ControlNet, right?
It sure does sound like that, but later he testifies that:
If you read his prepared opening statement carefully, he never actually claims that Llama is open source; just speaks at length about the virtues of openness and open-source. Easy to end up confused though!
My current not-strongly-held guess is that something like ‘GPT-5’ won’t be ASL-3, but will be close and will be above a threshold where it will be significantly useful in producing the next generation. Something I’d be willing to call a weak early form of recursive self-improvement. Thus, I would expect the next generation, ‘GPT-6’, to be clearly into ASL-3 and able to do quite a bit of useful R&D work. Thus, I would expect a ‘GPT-7’ to be ASL-4. If each of these steps takes 1.5 years, that’s really not long until ASL-4.
See my related prediction market here: https://manifold.markets/NathanHelmBurger/will-gpt5-be-capable-of-recursive-s?r=TmF0aGFuSGVsbUJ1cmdlcg
(market makes a slightly stronger case than stated here, in order to be controversial enough to be interesting)
I feel personally attacked by this relatable content. How dare Hephaistos just come out and tell the world the key content of my recurring nightmares?
I assume this was supposed to be a WarGames reference, in which case I think it should be a “nice” game of chess.
Naming choices… “We also have immortal unstoppable monster in the basement, but ours is on the good side!”