contact: jurkovich.nikola@gmail.com
Nikola Jurkovic
Karma: 1,936
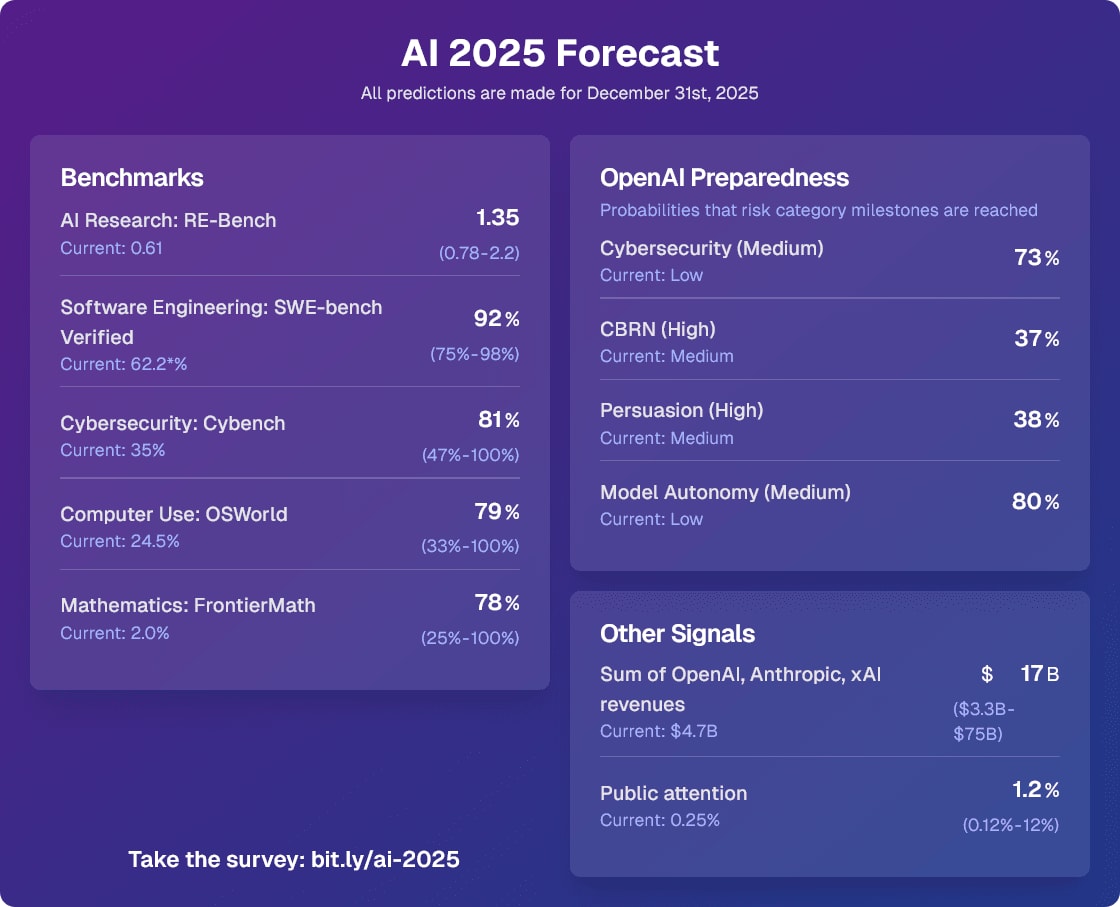
I will use this comment thread to keep track of notable updates to the forecasts I made for the 2025 AI Forecasting survey. As I said, my predictions coming true wouldn’t be strong evidence for 3 year timelines, but it would still be some evidence (especially RE-Bench and revenues).
The first update: On Jan 31st 2025, the Model Autonomy category hit Medium with the release of o3-mini. I predicted this would happen in 2025 with 80% probability.
02/25/2025: the Cybersecurity category hit Medium with the release of the Deep Research System Card. I predicted this would happen in 2025 with 73% probability. I’d now change CBRN (High) to 85% and Persuasion (High) to 70% given that two of the categories increased about 15% of the way into the year.
DeepSeek R1 being #1 on Humanity’s Last Exam is not strong evidence that it’s the best model, because the questions were adversarially filtered against o1, Claude 3.5 Sonnet, Gemini 1.5 Pro, and GPT-4o. If they weren’t filtered against those models, I’d bet o1 would outperform R1.
To ensure question difficulty, we automatically check the accuracy of frontier LLMs on each question prior to submission. Our testing process uses multi-modal LLMs for text-and-image questions (GPT-4O, GEMINI 1.5 PRO, CLAUDE 3.5 SONNET, O1) and adds two non-multi-modal models (O1MINI, O1-PREVIEW) for text-only questions. We use different submission criteria by question type: exact-match questions must stump all models, while multiple-choice questions must stump all but one model to account for potential lucky guesses.
If I were writing the paper I would have added either a footnote or an additional column to Table 1 getting across that GPT-4o, o1, Gemini 1.5 Pro, and Claude 3.5 Sonnet were adversarially filtered against. Most people just see Table 1 so it seems important to get across.
Quotes from the Stargate press conference
I have edited the title in response to this comment
“We know how to build AGI”—Sam Altman
Grading my 2024 AI predictions
The methodology wasn’t super robust so I didn’t want to make it sound overconfident, but my best guess is that around 80% of METR employees have sub 2030 median timelines.
I encourage people to register their predictions for AI progress in the AI 2025 Forecasting Survey (https://bit.ly/ai-2025 ) before the end of the year, I’ve found this to be an extremely useful activity when I’ve done it in the past (some of the best spent hours of this year for me).
Yes, resilience seems very neglected.
I think I’m at a similar probability to nuclear war but I think the scenarios where biological weapons are used are mostly past a point of no return for humanity. I’m at 15%, most of which is scenarios where the rest of the humans are hunted down by misaligned AI and can’t rebuild civilization. Nuclear weapons use would likely be mundane and for non AI-takeover reasons and would likely result in an eventual rebuilding of civilization.
The main reason I expect an AI to use bioweapons with more likelihood than nuclear weapons in a full-scale takeover is that bioweapons would do much less damage to existing infrastructure and thus allow a larger and more complex minimal seed of industrial capacity from the AI to recover from.
I’m interning there and I conducted a poll.
The median AGI timeline of more than half of METR employees is before the end of 2030.
(AGI is defined as 95% of fully remote jobs from 2023 being automatable.)
I think if the question is “what do I do with my altruistic budget,” then investing some of it to cash out later (with large returns) and donate much more is a valid option (as long as you have systems in place that actually make sure that happens). At small amounts (<$10M), I think the marginal negative effects on AGI timelines and similar factors are basically negligible compared to other factors.
Thanks for your comment. It prompted me to add a section on adaptability and resilience to the post.
I sadly don’t have well-developed takes here, but others have pointed out in the past that there are some funding opportunities that are systematically avoided by big funders, where small funders could make a large difference (e.g. the funding of LessWrong!). I expect more of these to pop up as time goes on.
Somewhat obviously, the burn rate of your altruistic budget should account for altruistic donation opportunities (possibly) disappearing post-ASI, but also account for the fact that investing and cashing it out later could also increase the size of the pot. (not financial advice)
(also, I have now edited the part of the post you quote to specify that I don’t just mean financial capital, I mean other forms of capital as well)
Orienting to 3 year AGI timelines
Time in bed
I’d now change the numbers to around 15% automation and 25% faster software progress once we reach 90% on Verified. I expect that to happen by end of May median (but I’m still uncertain about the data quality and upper performance limit).
(edited to change Aug to May on 12/20/2024)
I recently stopped using a sleep mask and blackout curtains and went from needing 9 hours of sleep to needing 7.5 hours of sleep without a noticeable drop in productivity. Consider experimenting with stuff like this.
Note that this is a very simplified version of a self-exfiltration process. It basically boils down to taking an already-working implementation of an LLM inference setup and copying it to another folder on the same computer with a bit of tinkering. This is easier than threat-model-relevant exfiltration scenarios which might involve a lot of guesswork, setting up efficient inference across many GPUs, and not tripping detection systems.
Note that for HLE, most of the difference in performance might be explained by Deep Research having access to tools while other models are forced to reply instantly with no tool use.