ML Engineer based in SF. Building AI that understands Physics.
kndjckt
Karma: 58
Have you heard of https://openai.com/index/paperbench/ and https://github.com/METR/RE-Bench ? They seem like they have some genuine multi-hour agentic coding tasks, I’m curious if you agree.
I’ll take a look. Thanks for sharing.
Sweet! Thanks for taking my points into consideration! :)
Thanks! Appreciate you digging that up :). Happy to conclude that my second point is likely moot.
Interesting. I get where you’re coming from for blank slate things or front end. But programming is rarely a blank slate like this. You have to work with existing codebases or esoteric libraries. Even with the context loaded (as well as I can) Cursor with Composer and Claude Sonnet 3.7 code (the CLI tool) have failed pretty miserably for me on simple work-related tasks. As things stand, I always regret using them and wish I wrote the code myself. Maybe this is a context problem that is solved when the models grow to use proper attention across the whole context window rather than using shortcuts or hacks due to memory limitations (this will get better as the newer NVIDIA chips land).
I would love to see an LLM fix a meaningful issue in an open source library.
Wonderful post! I appreciate the effort to create plenty of quantitative hooks for the reader to grab onto and wrestle with.
I’m struggling with the initial claim that we have agentic programmers that are as good as human pros. The piece suggests that we already have Human Pro level agents right now!?
Maybe I’m missing something that exists internally at the AI labs? But we don’t have access to such programmers. So far, all “agentic” programmers are effectively useless at real work. They struggle with real codebases, and novel or newer APIs and languages. Most programmers I know use LLMs as a sophisticated autocomplete and as a “search” tool. These offer nice speed-ups, greasing the wheels of programming. But I have not seen anything genuinely useful that is more agentic. No one is using Devin, lol. Note: I use Cursor and Claude constantly. I’m not some anti-AI programmer.
Concerns with the METR paper (Measuring AI Ability to Complete Long Tasks)
Most of the agentic programmer claims seem to be derived from the METR paper (Measuring AI Ability to Complete Long Tasks). After digging into the paper, the code, and the supporting paper (HCAST), I have some concerns.
1. The METR paper compares the AI against what seems like pretty weak contractors (“baseliners”). I’m shocked that a task that takes someone 5 minutes would take the contractor 16x longer. This makes me think the human “baseline” compared to the AI is roughly 5-10x worse than an actual professional. A 5-minute task is so incredibly small that in the real work world, we wouldn’t even waste the breath talking about the task.See below Table 6 from the METR paper.
2. It’s unclear how nerfed the “baseliners” are compared to programmers in real life (see section 5.2 of the HCAST paper). It’s unclear to me if the baseliners can use an IDE (like a real programmer would use). Does the sign-in thing mean that the baseliners can’t use Reddit, GitHub, Stack Overflow, Kagi, internal notes like Obsidian, or Notion? What if the baseliners have adjusted their workflows to use LLMs, and now they can’t use them, and the “old skills” have atrophied, not giving a fair comparison to real work?
3. We see effectively no improvement pattern on the baseliner 1-hour tasks (see figure 9 on the METR paper)
Pulling the above 3 points together. I think that the “~1 hour human tasks” in the paper are actually closer to 10-15 minutes tasks for an actual professional with their full setup, IDE, and other tools, etc. And, as outlined in the charts above, we have not seen LLM improvement for these sorts of tasks. This aligns with my experience with agentic coding tools on the market, like Devin, that can solve very small problems, but most of the time, it’s quicker and easier to just do the work yourself. No one makes a Linear or Jira ticket for a 15-minute unit of work.
How does this impact the whole piece?I think that actual meaningful creative problem-solving and engineering that causes a company to be able to recursively self-improve feels further away than AI 2027 claims. Additionally, I’m nervous about line fitting and extrapolating due to the minor agentic updates for recent models. Right now, I feel like I’m leaning toward Yann LeCun’s take that LLMs are inherently limited due to a weakness in stable reasoning over a long time horizon (lots of autoregressive tokens).
Happy to debate or discuss any of this. I’d also be down to do some Aug-2025 agentic bets if anyone has some cooked up? 😈
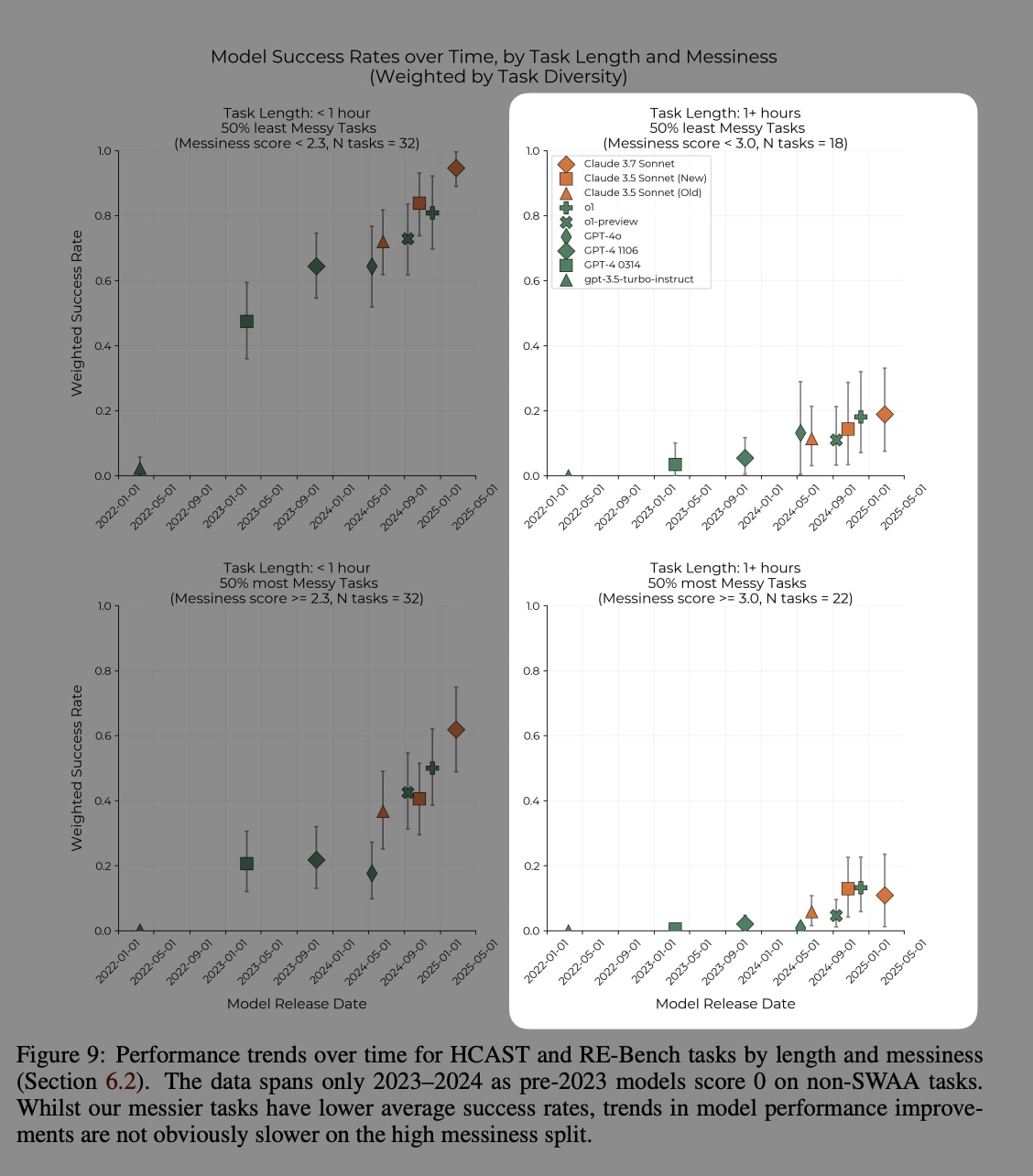
Thanks for re-running the analysis!
I agree that RE-bench aggregate results should be interpreted with caution, given the low sample size. Let’s focus on HCAST instead.
A few questions:
Would someone from the METR team be able to clarify the updates to the HCAST task set? The exec summary states: “While these measurements are not directly comparable with the measurements published in our previous work due to updates to the task set”. Was Claude 3.7 Sonnet retested on the updated HCAST test set?
On HCAST o3 and o4-mini get a 16M token limit vs 2M for Claude 3.7 Sonnet (if my reading of the paper is correct). Do we know how Claude would do if given a higher token budget? Maybe this isn’t relevant as it never gets close to the budget, and it submits answers well before hitting the limit? I want to make sure improvements are just due to shifting token budgets.