Google Gemini uses a watermarking system called Synth ID that claims to be able to watermark text by skewing its probability distribution. Do you think it’ll be effective? Do you think that it’s useful to have this?
bohaska
Karma: 191
The digital version of the SAT actually uses dynamic scoring now where you get harder questions if you get the ones in the first section correct, but it’s still approximately as difficult as the normal test so tons of people still tie at 1600
We call on our knowledge when something related triggers, so in order for a lesson to be useful, you need to build those connections and triggers in the student’s mind.
Seems related to trigger-action plans...
Such as this one!
Given that Biden has dropped out, do you believe that the market was accurately priced at the time?
LessWrong messed up the formatting so in my home feed I saw a bet where I pay you $1000 if I lose but only gain $10 instead of $1,000,000,000 if I win
Hello from 12 years in the future!
Try cruise control. Helps you drive your car on the same lane when on highways. Makes it much less tiring.
Not necessarily related to your main point, but you could have downloaded a markdown-based text editor and pasting what you copied into it, and they’ll convert the text to Markdown, which Discord uses. A couple of them should support automatic formatting of HTML text to Markdown.
For example, I copied a portion of the article and pasted it into Obsidian (a markdown-based note system), and it formatted the text into Markdown for me. This is what it looked like in Discord:
Discord only supports the first 3 levels of headings so the subheading doesn’t format, but everything else is fine. When I compared it with your richtext editor, it matched perfectly.

True, but that’s because the author is writing about working with Google Sheets, not Excel.
They’re mentioned in the companion piece (Google Docs) linked at the bottom of this post. This isn’t the full post.
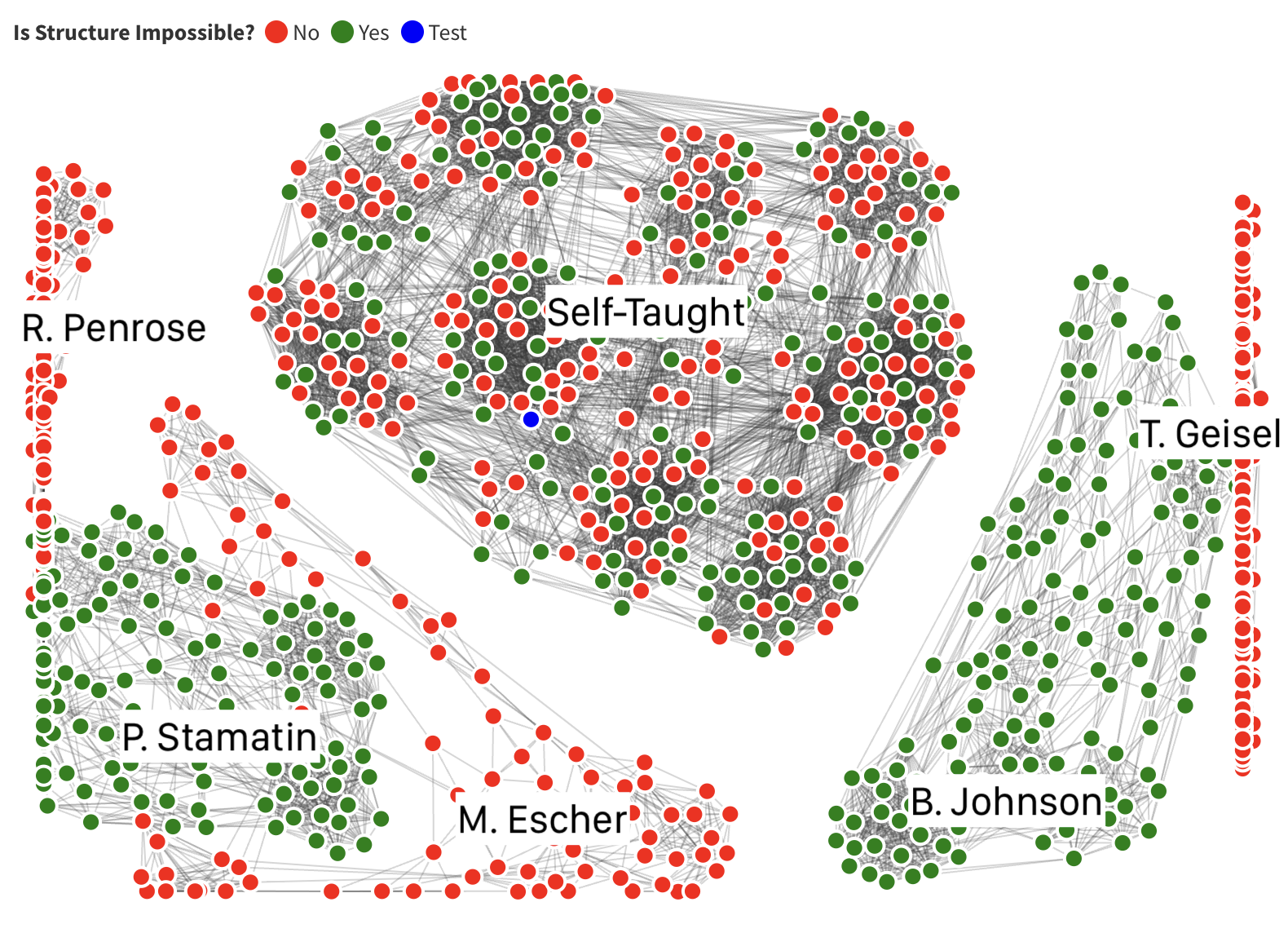
I tried to visualize the entire dataset and look for patterns...
I decided to try mapping the entire group, by connecting all structures where they only differ by one column. After I did so and played around with the graph, I realised that lots of structures by the same person are connected and either all fail or all succeed. To investigate, I decided to only connect structures that are by the same person, and the pattern appears very nicely:
See the image at https://39669.cdn.cke-cs.com/rQvD3VnunXZu34m86e5f/images/2d52f50b48a8badc77102018aefe03ad8f36e2a05be8f15c.png\ (same image host at LessWrong, and I can’t find out how to spoiler images)
{kind=link}
Do you happen to have a copy of it that you can share?
I wonder how much of dyslexia transfers cross-linguistically
It turns out that quite a bit of it is dependent on the type of language; A person dyslexic in alphabetic languages is not necessarily dyslexic in logographic languages, because they engage different parts of the brain. For example, from this review of Chinese developmental dyslexia:
Converging behavioral evidence suggests that, while phonological and rapid automatized naming deficits are language universal, orthographic and morphological deficits are specific to the linguistic properties of Chinese. At the neural level, hypoactivation in the left superior temporal/inferior frontal regions in dyslexic children across Chinese and alphabetic languages may indicate a shared phonological processing deficit, whereas hyperactivation in the right inferior occipital/middle temporal regions and atypical activation in the left frontal areas in Chinese dyslexic children may indicate a language-specific compensatory strategy for impaired visual-spatial analysis and a morphological deficit in Chinese (developmental dyslexia), respectively.
I’ve went into a small rabbit hole about Chinese dyslexia after reading your comment where you treated each letter like a drawing instead of a letter, and it turns out that English and Chinese dyslexia probably affect different parts of the brain, and that someone who is dyslexic in alphabet-based systems (English) may not be dyslexic in logograph-based systems (Chinese).
For example, from the University of Michigans’s dyslexia help website:
Wai Ting Siok of Hong Kong University has discovered that being dyslexic in Chinese is actually not the same as being dyslexia in English. Her team’s MRI studies showed that dyslexia among users of alphabetic scripts such as English versus users of logographic scripts such as Chinese was associated with different parts of the brain. Chinese reading uses more of a frontal part of the left hemisphere of the brain, whereas English reading uses a posterior part of the brain.
from a linguistics review in 2023:
Converging behavioral evidence suggests that, while phonological and rapid automatized naming deficits are language universal, orthographic and morphological deficits are specific to the linguistic properties of Chinese. At the neural level, hypoactivation in the left superior temporal/inferior frontal regions in dyslexic children across Chinese and alphabetic languages may indicate a shared phonological processing deficit, whereas hyperactivation in the right inferior occipital/middle temporal regions and atypical activation in the left frontal areas in Chinese dyslexic children may indicate a language-specific compensatory strategy for impaired visual-spatial analysis and a morphological deficit in Chinese DD, respectively.
This made me wonder, since written Chinese has no connection with spoken Chinese, did people in ancient China mostly read aloud or read silently when reading by themselves? I’d expect that they didn’t read out what they say.
Also, when I read Chinese as a second-language speaker, having learned English before Chinese, I often find that subvocalizing the Chinese characters helps me to understand it, and not doing so makes it difficult for me to read, however my Chinese-native parents don’t have an inner voice when reading Chinese.
I think the general differences in language processing between different types of languages is interesting, though I’m not sure how useful this is. Just my ramblings.
Is the Renaissance caused by the new elite class, the merchants, focusing more on pleasure and having fun compared to the lords, who focused more on status and power?
hmm, is there a collection of the history of terrorist attacks related to AI?
But Manifold adds 20 mana to liquidity per new trader, so it’ll eventually become more inelastic over time. The liquidity doesn’t stay at 50 mana.
After reading this and your dialogue with Isusr, it seems that Dark Arts arguments are logically consistent and that the most effective way to rebut them is not to challenge them directly in the issue.
jimmy and madasario in the comments asked for a way to detect stupid arguments. My current answer to that is “take the argument to its logical conclusion, check whether the argument’s conclusion accurately predicts reality, and if it doesn’t, it’s probably wrong”
For example, you mentioned before an argument which says that we need to send U.S. troops to the Arctic because Russia has hypersonic missiles that can do a first-strike on the US, but their range is too short to attack the US from the Russian mainland, but it is long enough to attack the US from the Arctic.
If this really were true, we would see this being treated as a national emergency, and the US taking swift action to stop Russia from placing missiles in the Arctic, but we don’t see this.
Now, for some arguments (e.g. AI risk, cryonics), the truth is more complicated than this, but it’s a good heuristic for telling whether you need to investigate an argument more thoroughly or not.
We do agree that suffering is bad, and that if a new clone of you would experience more suffering than happiness, then it’ll be bad, but does the suffering really outweigh the happiness they’ll gain?
You have experienced suffering in your life. But still, do you prefer to have lived, or do you prefer to not have been born? Your copy will probably give the same answer.
(If your answer is genuinely “I wish I wasn’t born”, then I can understand not wanting to have copies of yourself)
This seems like the sort of R&D that China is good at: research that doesn’t need superstar researchers and that is mostly made of incremental improvements. But yet they don’t seem to be producing top LLMs. Why is that?