The following post is an adaptation of a comment I posted on the Machine Learning subreddit in response to a post asking whether readers worried about AI Safety/Alignment similarly to Eliezer Yudkowsky (EY). My general impression is that most commenters had not dedicated much thought to AI Safety (AIS), like most normal people. I personally wouldn’t qualify myself as particularly well-read on the topic either, hence the title. As I mention towards the end of the article I think there is “alpha” in discussions happening between us normies of the “out-group” and so I went ahead and posted that comment and this post for amplification.
It seems like many commenters mostly have issues with the “timelines”, i.e., they do not think these risks will happen soon enough for us to worry about them now. I think this is a fair enough stance, there is a lot of uncertainty around forecasting the future of A(G)I developments.
However I would point out that they should consider that we may all be suffering from exponential growth bias. If indeed AGI is very far away, then great, we indeed have more time to develop it safely (although I’d be sad to get to live in such a cool future later rather than sooner). But there is a real chance it isn’t, and I do think we need to be cautious of our confidence in the former case, considering the gravity of the consequences superintelligence may bring. Basically what I’m saying is “better safe than sorry”, similarly to how we shouldn’t dismiss nuclear safety, epidemiology and shouldn’t have dismissed climate alarmists in the 20th century.
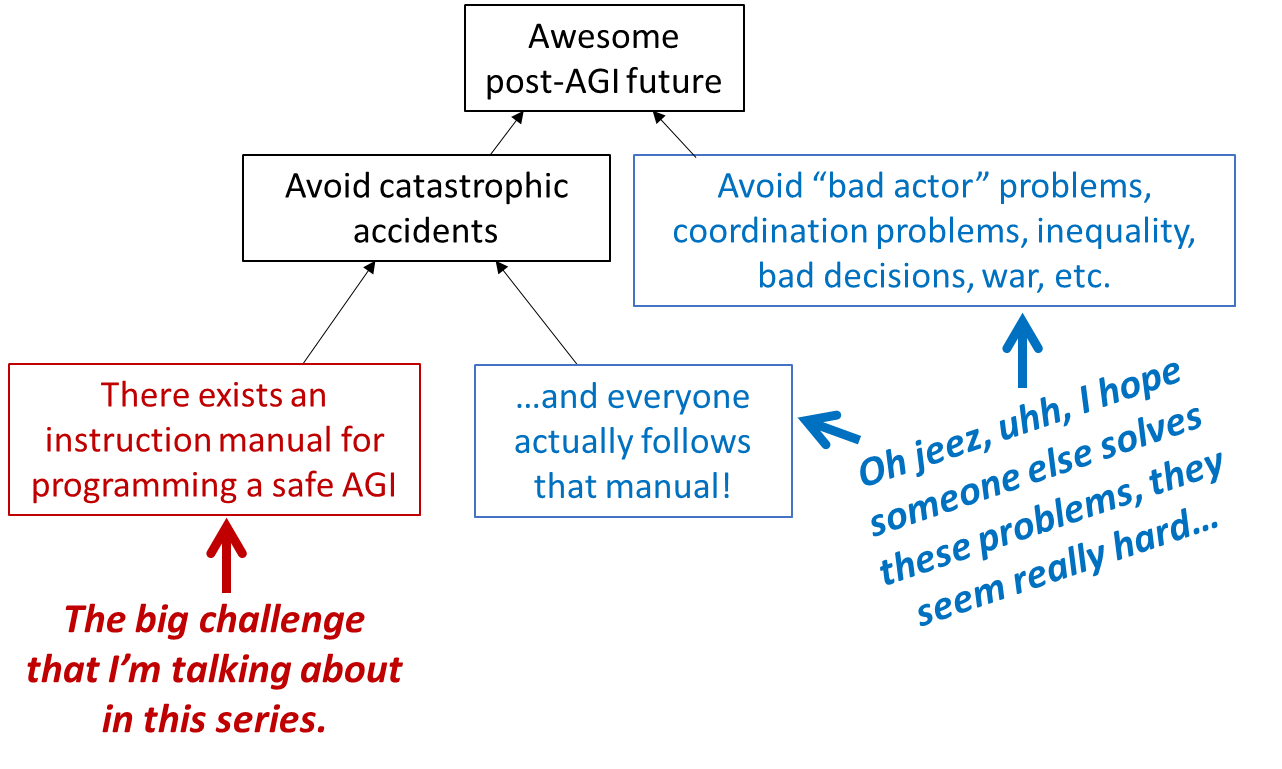
The other skepticism I tend to see is that there’s no point working on aligning AI, because even with aligned AI, it will be abused by corporations and governments, just like our narrower systems are being abused[1] today. I should point out that the field of AI Safety also considers this problem and posits that solutions to it are also necessary to address safety, similarly to how we coordinate for other security means today. See also coordination/cooperation. AI Alignment and AI Governance go hand-in-hand for long-term AI safety and there are enough people in the world for us to tackle on either without excluding the other. See this image from this post.
{kind=link}
Finally, I suppose the classic dismissal of AI Safety concerns that I tend to see is something a long the lines of “I don’t think AGI will be unsafe” or “Existing arguments about AGI being dangerous don’t convince me”. The first opinion is basically that we’ll get Alignment by default, without worrying about it now or expending much effort. I think this is possible, and would love for it to be the case, but tend to go back to my “better safe than sorry” stance here. As for being unconvinced, I totally understand, but so far I haven’t seen actual arguments or criticisms pointing out why, and the unconvinced views seem mostly gut-based and/or emotional (which to be clear, should not be completely dismissed but could benefit from some argumentation). On the other hand, there are several papers (e.g. here and here), books (e.g. here and here) and entire websites (see other links) presenting (mostly) rigorous convincing arguments.
I’ve been interspersing links throughout this post to highlight that many people[2] are actively thinking of the AI Safety issue, and presenting arguments both for and against worrying about it. Fortunately EY is not the only person working on it, and in fact many people disagree with him while still being concerned about AIS. I would actually love to see more rigorous arguments from both sides, but especially from those who decide it is not worth worrying about, since these are more lacking. I would also love to see more “outsiders” engaging with the issue (whether they agree with it or not) on LessWrong, where most discussions on it are happening, since at times it can get admittedly in-groupy.
Thanks for writing this! If you’re interested in a detailed, object-level argument that a core AI risk story is unlikely, feel free to check out my Deceptive Alignment Skepticism sequence. It explicitly doesn’t cover other risk scenarios, but I would love to hear what you think!