See also: Probability is in the Mind, You Are Never Entitled to Your Opinion, and “I don’t know.”
(Cross-posted from a new blog I’m trying to start. Sorry if some of the material is a bit basic for these parts, there’s a larger point I’m trying to build up to.)
I. A puzzling probability problem
Suppose you have a random number generator, which gives values from 1 to 6. Like a die, but not necessarily a literal one; let’s call it a “die” anyway. You don’t have any other information about the relative frequency of the outcomes, and have no reason to expect one outcome more than any other. What’s your estimated probability distribution? That is, on the next roll, what’s the chance it’s a 1 (or 2, 3, 4, 5, or 6)?
“1/6 for each!”, you say cheerfully. Well, fair enough, I concur! You have no reason to say any one result is more likely than any other, so a uniform distribution is natural. But suppose I now make the problem slightly harder. I tell you the mean value is 4.5 (rather than 3.5, as it would be for a fair die). What’s your probability distribution now? What’s the probability that the next roll is, say, a 2?
I think many more people would now be tempted to say the question isn’t well-defined, there’s not enough information to answer. There are infinitely many probability distributions consistent with this average, after all, and no clear way to single out one amongst them all.
But, there’s something very funny about this response. In the second question, you are actually given more information about the die than in the first. How could this possibly make the question less well-defined? It can’t, of course!
II. Is the question really well-defined?
In fact, you could call the first question undefined on this basis, and some do! (Sorry for leading the witness before.) It’s not super common amongst ordinary people I’ve talked to, but a certain contingent are tempted to say that if you don’t precisely specify the frequencies of each outcome, then there’s nothing we can say about the probability of the next roll. (I would take the opposite end of this dilemma and say both questions are well-defined.)
If you yourself are so tempted, I would respond that you can call practically any probability question ill-posed on this basis. Consider an actually “fair” die. We all agree it’s a 1⁄6 chance for each outcome. But I could complain that you haven’t given me enough information to properly judge! If you told me more about the exact conditions under which the next roll would occur, I could in principle give much more precise predictions, up to near-certainty, in fact. There are countless possible configurations of air particles in this room, and countless ways you could roll the die, and they all give different answers for what to expect! If you don’t give me any way to favor one configuration over any other, how can I answer? Clearly it’s nonsense to consider the question without this information, and I will not entertain it any further.
But, as the saying goes, probability is in the mind. The world itself simply is. The die isn’t unsure what it’s going to do. You, however, are ignorant of the world (no offense). So you cannot answer every question perfectly. We represent this ignorance using probabilities.
Sure, the configuration of air particles in the room does make a difference, but you don’t know what it is and don’t have any way to favor one configuration over another, so your answer stays at 1⁄6. Similarly, the weighting of the dies does make a difference, but you don’t know how it’s weighted, and don’t have any way to favor one weighting over another, so your answer ought to be 1⁄6.
When we ask for the “probability” of something, we are only ever asking, given what you do know, what’s the best guess? Hence both questions are as well-defined as any probability question ever is.
II. Another argument
If you don’t like that argument (despite its impeccable quality!), here’s another. You’re complaining that I haven’t given you any information whatsoever about the die, so it’s impossible to say anything. Alrighty then, suppose I let you roll the die twenty times, and you get two 1’s, three 2’s, five 3’s, three 4’s, five 5’s, and two 6’s. What’s the probability you get a 2 on the next roll?
Are you going to say 3⁄20, based on this data? But that’s clearly unjustified; there are still infinitely many probability distributions compatible with this data, and we certainly have no strong reason to believe that 2’s come up with that exact frequency. But this remains true after a hundred rolls, or a thousand, or a million! We are never in a position to know the “true” probability of 2 on the next roll. If you refuse to make the best guess with the information you have, you are throwing out the entire idea of inference, of your guesses getting better over time.
If you are only willing to answer a probability question when you are told the exact probabilities in advance, then just recognize that you will never be in this position in real life. (And if you were, there would be no point in rolling the die to learn more, because you’d already know everything there is to know about the distribution!) No human being, in all of history, has ever known the exact probability of any event. To know it for the die, we’d have to roll it an infinite number of times and observe the long run frequencies. This has never been done, and can never be done.
The idea of knowing an exact true probability distribution in advance is a fairy tale. Instead, in real life, we start with initial beliefs, which we update over time. Following Bayes’ rule, we start with our prior beliefs, and update them in response to new evidence. Here, that means starting with an initial uniform distribution, and updating it as we roll the die. If you give an undefined answer to the original question, then all of your updates will be undefined, and you’ll never get around to believing anything.
In fact, if we roll the die enough and you do eventually start to believe something, I can just reverse engineer Bayes’ rule to see what your prior must have been before we started rolling. Whether you like it or not, whether you admit it or not. Sorry!
III. But my ignorance can’t control the die…
You may continue to object that there really is a clear difference between knowing that the frequency is 1⁄6 for each, and being totally ignorant of the die. This is perfectly correct! After all, our ignorance about the die can’t make the die come out as 1⁄6 for each result.
In the former case, what does it actually mean to say that we “know” the frequency is 1⁄6 for each outcome, if we haven’t rolled it infinitely many times to check? I propose we are claiming positive knowledge about certain symmetries of the die that lead us to believe it’s implausible that different results could come up at significantly different rates. We’ve inspected the die, it looks symmetric, and doesn’t feel weighted.
In the latter case, we have no such knowledge. This doesn’t mean our probabilities shouldn’t be 1⁄6 for outcome, though. Instead, it changes how we update given new information. We will now respond very quickly to new evidence. If we start to see a few 6’s in a row, we can reasonably start to suspect that the die might be weighted towards 6. But if we’ve carefully inspected the die and can’t detect any irregularities, we are more likely to chalk this up to chance.
Again, this is all perfectly correct! When deciding how to update our probabilities in response to new evidence, we must in general take note not just of our current probability estimates, but all the relevant information we have. I propose that this is the actual distinction your brain continues to notice, when it feels like there’s something off about saying 1⁄6 for each. I hope this fully resolves all your doubts!
IV. Entropy maximization
Ahem, anyway. My hypothesis is that more people would be tempted to throw their hands in the air and say “Undefined!” for the second question, rather than the first. I hope this seems intuitively true to you, as it does to me.
(I have asked some people this question and gotten results vaguely in that direction. Unfortunately, giving the question to people in writing, I fear I primed them too much by giving “undefined” as an option, so a lot of people did go ahead and say undefined for both, even though they didn’t seem to think like that when I’d spoken to them on other occasions. I’d rather see how often people spontaneously bring up that objection in conversation, which requires more effort to test.)
But as I said before, this is a strange answer, because more information is given in the second question than the first. If you buy my argument that the first question is well-defined, then certainly this one must have a definite answer as well. But how do we get it?
The answer lies in something called “entropy”. The entropy of a probability distribution is a measure of how “uncertain”, or evenly spread out it is. The derivation of the exact mathematical measure is rather technical, but suffice it to say that many different lines of argument point toward entropy as a uniquely good measure of uncertainty.
The idea, then, is to estimate a probability distribution that fits the facts, but is otherwise as uncertain as possible. For instance, for the die with an average of 4.5, we could hypothesize that the probability is 0.3 for 1, 0.7 for 6, and 0 for every other outcome, and this would average out to 4.5. But we’re clearly making a quite unjustified claim, needlessly placing high confidence in 1 and 6, while ignoring the possibility of 2 through 5.
Instead, we want a distribution that averages out to 4.5, but is otherwise as uncertain as possible. That way, we aren’t making any unjustified claims beyond just what’s given in the data. That is, we want the maximum entropy distribution that fits the facts. This becomes a constrained optimization problem, and is in general rather complex!
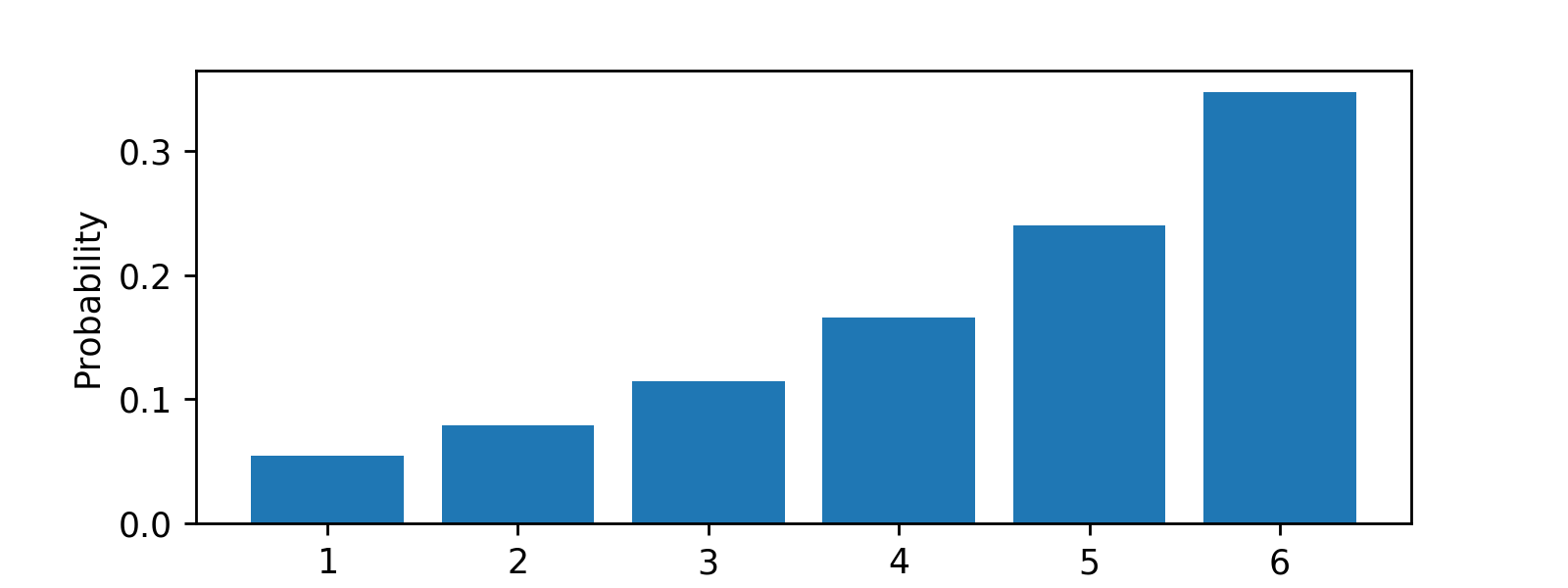
If we do this, then (eyeballing from this graph) we get a small probability for 1 at around 0.05, a slightly larger probability for 2 at around 0.075, and so on, gradually increasing up to 6, which has the highest probability at a little less than 0.35. This all seems fairly intuitive; the higher average shifts our whole distribution marginally rightward.
{kind=link}
In the case where no constraints are given, the maximum entropy distribution is always the uniform distribution. This is the most uncertain distribution possible. Thus, in that special case, the principle of maximum entropy agrees with intuition.
VI. Say not “undefined”, but rather, “computationally difficult”
There’s a reason I’m not digging into a full explanation of entropy maximization here. It’s hard! Which brings me to my overall point. Why do we intuitively feel that the first question is more well-defined than the second, even though the second gives more information?
I propose the answer is that in the first question, it’s easy to see how to move from what we do know, to a precise probability estimate, whereas in the second question, it’s not so clear. We could make this problem even harder: what’s the probability of a 2 for a weighted die with mean 4.5 and variance 2.7?
But just because this question is harder doesn’t actually make it undefined! As I’ve argued, probability questions are always just asking for our best judgement given what we know. It’s more work to get the answer for the second question, and so it feels intuitively less well-defined, but this is really just substituting one question for another. So say not “undefined”, but rather, “computationally difficult”.
V. Next time
In writing this essay, I wanted to discuss Bertrand’s Paradox, in particular the Numberphile videos on the problem here and here. This is a famously “undefined” probability puzzle, although they present a possible solution in the second video.
The solution is essentially a much grander version of what I’ve discussed here, where with a lot more effort, we can convert our prior information into a more precise answer. Bertrand’s Paradox, and its solution, is highly technical, so I won’t go through it in detail. But Grant (of 3blue1brown fame) proposes a thought experiment near the end of the second video linked above, involving buckets of dice… That is what I actually want to explore.
But! This essay is long enough, so we’ll leave that for next time. Stay tuned!
What makes a probability question well-defined is whether the given propositions, together with the axioms of a probability space, yield a unique solution for the desired results.
All the rest is just arguing over the semantics and conventions of the natural language used to express the problem.
In any real-life inference problem, nobody is going to tell you: “Here is the exact probability space with a precise, known probability for each outcome.” (I literally don’t know what such a thing would mean anyway). Is all inference thereby undefined? Like Einstein said, “As far as laws of mathematics refer to reality, they are not certain; and as far as they are certain, they do not refer to reality”. If you can’t actually fulfill the axioms in real life, what’s the point?
If you still want to make inferences anyway, I think you’re going to have to adopt the Bayesian view. A probability distribution is never handed to us, and must always be extracted from what we know. And how you update your probabilities in response to new evidence also depends on what you know. If you can formalize exactly how, then you have a totally well-defined mathematical problem, hooray!
My point, then, is that we feel a problem isn’t well-defined exactly when we don’t know how to convert what we know into clear mathematics. (I’m really not trying to play a semantics game. This was an attempt to dissolve the concept of “well-defined” for probability questions.) But you can see a bit of a paradox when adding more information makes the mathematical problem harder, even though this shouldn’t make the problem any less “well-defined”.
Sure! The original problem invites assumptions of symmetry and integrality[1] and so on, and the implied assumptions result in a fully specified probability model. The adjusted problem adds information that necessarily breaks symmetry, and there is no correspondingly “obvious” set of assumptions that leads to a unique answer.
So yes, communicating probability problems requires some shared concepts and assumptions just like communication about anything else. I’ve previously commented here about my experience with word problems in teaching mathematics, and how the hardest part is not anything to do with the mathematics itself, but with background assumptions about interpreting the problem that were not explicitly taught.
The original problem never said that the random number generator only gives integers in the range 1 to 6. That’s an additional assumption.
I agree that there isn’t an “obvious” set of assumptions for the latter question that yields a unique answer. And granted I didn’t really dig into why entropy is a good measure, but I do think it ultimately yields the unique best guess given the information you have. The fact that it’s not obvious is rather the point! The question has a best answer, even if you don’t know what it is or how to give it.