[Valence series] 2. Valence & Normativity
2.1 Post summary / Table of contents
Part of the Valence series.
The previous post explained what I mean by the term “valence”. Now in Post 2, I’ll discuss the central role of valence in the “normative” domain of desires, preferences, values, and so on. In case you’re wondering, there is also a relation between valence and the “positive” domain of beliefs, expectations, etc.—but we’ll get to that in Post 3.
The role of valence in the normative domain can scarcely be overstated: I think valence is the very substance out of which all normativity is built.
To be clear, that does not mean that, once we understand how valence works, we understand absolutely everything there is to know about the whole normative universe. By analogy, “atoms are the very substance out of which all bacteria are built”; but if you want to understand bacteria, it’s not enough to just understand what atoms are and how they work. You would still have a lot more work to do! On the other hand, if you don’t know what atoms are, you’d have an awfully hard time understanding bacteria! So it is, I claim, with valence and normativity.
The post is organized as follows:
Section 2.2 discusses the misleading intuition that valence seems to be attached to real-world things, actions, plans, and so on. We say “That’s a bad idea”, as opposed to “When I hold that idea in my brain, it evokes a negative-valence ‘badness’ feeling”. This is important context for everything that follows.
Section 2.3 discusses situations where a valence assessment corresponds directly to a meaningful (albeit snap) normative assessment. For example, if I have a thought that corresponds to a concrete plan (“I will stand up”), then my brain is saying that this is a good plan or bad plan in accordance with whether the valence of that thought is positive or negative respectively—and if it’s a good plan, I’m likely to actually do it. Likewise, if I imagine a possible future state of the world, the valence of that thought corresponds to an assessment of whether that state would be good or bad—and if it’s good, my brain is liable to execute plans that bring it about, and if it’s bad, my brain is liable to execute plans to avoid it. Thus, we get the expected direct connections between valence signals, felt desires, and our actions and decisions.
Section 2.4 discusses a different case: the valence of concepts. For example, if I “like” communism, then a thought involving the “communism” concept is liable to be positive-valence. I argue that this cannot be directly interpreted as making a meaningful normative assessment about anything in particular, but instead we should think of these as learned normative heuristics that help inform meaningful normative assessments. I then talk about vibes-based “meaningless arguments”, like arguing about whether to be “for” or “against” Israel.
Section 2.5 discusses how valence gets set and adjusted, with a particular emphasis on innate drives (e.g., a drive to eat when hungry) as the ultimate grounding of valence assessments.
Section 2.6 discusses the valence of metacognitive thoughts and self-reflective thoughts, including the distinction between ego-syntonic and ego-dystonic tendencies, and what people are talking about when they talk about their “values”.
Section 2.7 briefly covers how moral reasoning fits into this framework, first descriptively (when people are doing “moral reasoning”, what are they doing?), and then musing on the implications for metaethics.
Section 2.8 is a brief conclusion.
2.2 The (misleading) intuition that valence is an attribute of real-world things
Recall from §1.3 of the previous post that, in my proposed model:
Part of our brain “thinks a thought” which might involve things that you’re planning, seeing, remembering, understanding, attempting, and so on, and might involve paying attention to certain things, or invoking certain frames / analogies, etc.;
…And another part of our brain assigns a valence to that “thought”.
So:
From the outside, valence is a function that maps a “thought” (in a particular person’s brain) to a scalar real number.
From the inside, thoughts are our only window onto the real world. So it feels like valence is “attached” to real-world things, situations, etc.—in Eliezer Yudkowsky’s memorable analogy, it feels like “an extra, physical, ontologically fundamental attribute hanging off of events like a tiny little XML tag”. I think that intuition is a kind of perceptual illusion, which can mislead you if you’re not careful. (Apologies for the Bulverism[1], but I think this perceptual illusion contributes to some bad philosophical takes within the “moral realism” camp.)
For example, suppose that my brain assigns high valence to thoughts that involve the moon. (In everyday terms, “I like the moon, it’s cool”.) It feels to me like cool-ness is an attribute of the actual real-world moon. After all, whenever I see the moon, I get an impression of cool-ness. I can’t even imagine the moon without getting that impression! It’s a bit like the refrigerator light illusion. But really, the good vibe is not out there in the real world, attached to the moon like an XML tag. The only thing going on is that my brain’s valence function has learned a certain heuristic: check whether “the moon” concept is active in my brain’s world-model, and if it is, increase the valence of that thought.
2.3 Situations where valence corresponds directly to a meaningful (albeit snap) normative assessment: The valence of plans, actions, and imagined futures
Economists talk about “positive versus normative claims”; philosophers (following Hume) talk about the same thing under the heading “is versus ought”. A positive statement is a factual claim about how the world actually is, whereas a normative assessment is a value judgment about how the world ought to be, or about what one ought to do.
(The kinds of “normative assessments” that I’m discussing in this section are fast “snap” judgments, not carefully-considered assessments that I proudly endorse and stand behind. However, I’ll argue in §2.7 below that the former serves as the foundation upon which the latter is built.)
What does valence have to do with normativity? Everything! Really, I see valence as the ultimate currency for all normativity in the brain.
This claim ultimately stems from the role of valence discussed in §1.3 of the previous post. To briefly recap, let’s say an idea pops into my head—“I’m gonna get up”. If the valence of that thought is positive, then that thought will stay in my head, and I’ll probably actually do it. If the valence is negative, then that thought gets tossed out and replaced by another thought, probably one that involves staying in bed. Thus, valence underlies this decision. Contrary to weird “Active Inference” ideas, this role of valence here is unrelated to the capability of my generative world-model to make predictions about the future: my world-model (“Thought Generator”) is equally capable of modeling the future world where I get up, and modeling the future world where I don’t. Thus, the role of valence here is fundamentally normative, not positive.
That’s a simple case, but it generalizes. So:
Suppose that I have a thought which corresponds to the idea of executing a plan, or taking an action. If the valence of that thought is positive, then I’m liable to execute it. And if the valence of that thought is negative, then I’m unlikely to. So in this case, the valence of the thought corresponds to my brain making a snap normative assessment of the appropriateness of this plan or action.
Suppose that I have a thought which corresponds to a possible future situation, e.g. I imagine a certain candidate winning the election, or I imagine myself eating a sandwich for dinner. If the valence of that thought is positive, then I’ll tend to make and execute plans that bring that future about. And if the valence of that thought is negative, then I’ll tend to make and execute plans that prevent that future from coming about. So in this case, the valence of the thought corresponds to my brain making a snap normative assessment of the goodness or badness of this possible future.
2.3.1 More on wanting or not-wanting a future situation to happen
The second bullet point on “possible future situations” glosses over some details that merit elaboration.
Elaboration on the positive-valence case: Consider the case where I imagine myself eating a sandwich for dinner, and that thought is positive valence. How do I wind up (probably) actually eating a sandwich tonight? Two steps:
Step 1: I might think a thought that involves a concrete course-of-action that is expected to result in my eating a sandwich, perhaps “I’m gonna walk to Saul’s and eat a sandwich there”. This is a different thought than before, more concrete and actionable, but this thought will also probably be positive-valence, because it involves / overlaps with “the idea of me eating a sandwich for dinner”. (See §2.4.1 below.)
Step 2: OK, now I have, in my head, a concrete-course-of-action thought (“I’m gonna walk to Saul’s and eat a sandwich there”), and it has positive valence. That means I’m likely to actually execute that course-of-action—I may contract my muscles, stand up, and start walking to Saul’s.
Elaboration on the negative-valence case: Next, consider the case where I imagine some possible future situation, and that thought is negative valence.
I wrote above: “I’ll tend to make and execute plans that prevent that future from coming about.” But astute readers might be thinking: Hang on a sec. Will I really? Isn’t it more likely that I’ll just stop thinking about that possibility altogether? Isn’t that what the valence signal does?
That’s a great question! In fact, I think there’s a lot of truth to that objection, and this gets us into things like the widespread tendency to underinvest in thinking about why one’s own hopeful plans might fail, and “ugh fields”, and so on. Much more on this topic in the next post, especially §3.3.3.
As one example of what can happen, note that “avoiding possible bad future situation X” can sometimes be mentally re-framed as “seeking possible good future situation not-X”—for example, if you’re demotivated by the idea of your enemies winning the war, then you’re probably simultaneously motivated by the idea of your enemies being vanquished. So maybe you’ll switch to that latter mental framing, allowing you to brainstorm without the thoughts getting immediately pushed away by negative valence.
2.3.2 More on “snap” assessments versus thoughtful ones
As discussed in §1.5.1 of the previous post, it’s entirely possible for a single plan, action, or possible future situation to have different valences depending on how I think about it (what aspects I pay attention to, etc.). Recall my example from before: “I will go to the gym, thus following through on my New Year’s Resolution” versus “I will go to the loud and cold and smelly gym”.
So when I say “snap normative assessment”, the “snap” is playing an important role. It’s closely analogous to how we make “snap” assessments in the positive domain:
Positive domain (not directly involving valence): If I imagine a possibility, I get an immediate intuitive “snap” feeling about whether that possibility is likely / plausible. But I can still think about it more, and change my mind.
Normative domain (directly involving valence): If I imagine a possibility, I get an immediate intuitive “snap” feeling about whether that possibility is good or bad. But I can still think about it more, and change my mind.
In both cases, I claim that the “think about it more” process is not a fundamentally different kind of thing from the first snap assessment. It’s just thinking more thoughts, and those follow-up thoughts all come along with their own snap assessments of plausibility and desirability.
2.4 The valence of concepts
Now let’s consider a different case: let’s say I think about a concept, like Hamas, or capitalism, or superhero movies. That’s a thing my brain can think about, so like any thought, my brain will assign it a valence.
If the valence is positive, maybe I’ll think to myself “Hamas is good”; if negative, “Hamas is bad”.
This topic is the subject of the classic 2014 Scott Alexander blog post “Ethnic Tension and Meaningless Arguments”. But before we get into that…
2.4.1 Side note: Valence as a (roughly) linear function over compositional thought-pieces
As a simple and not-too-unrealistic model, I propose that we should treat “thoughts” as compositional (i.e., basically made of lots of little interlocking pieces), and that the valence is linearly additive over those thought-pieces. So if a thought entails imagining a teddy bear on your bed, the valence of that thought would be some kind of weighted average of your brain’s valence for “this particular teddy bear”, and your brain’s valence for “teddy bears in general”, and your brain’s valence for “thing on my bed”, and your brain’s valence for “fuzzy things”, etc., with weights / details depending on precisely how you’re thinking about it (e.g. which aspects you’re paying attention to, what categories / analogies you’re mentally invoking, etc.).
Why do I bring this up? Well, I want to talk about the valence that my brain assigns to concepts. For example, “the moon” is a concept in your mental world. It’s often a piece of a larger thought, but it’s rarely an entire thought in and of itself. Experienced meditators can maybe focus their minds solely on the idea of the moon, but that’s not the typical case!
In the linear model, that’s fine—“the moon” still has a valence. If that valence is very positive, then heavily-moon-involving thoughts like “I’m looking at the moon right now” and “someday I’ll visit the moon” would presumably wind up positive-valence too.
2.4.1.1 (Apparent) counterexamples to linearity
Astute readers are screaming at me right now. Here’s an (apparent) counterexample tailored for pro-Israel readers (others can switch the word “Israel” for “Hamas”, or pick any other example):
In order to think the thought “I will fight against Hamas”, your brain needs to somehow activate the “Hamas” concept; but the less you like Hamas, the more you’ll like the idea of fighting against Hamas. This seems to be in blatant contradiction to the linear model.
In this situation, I would say that (for those pro-Israel readers) “Hamas as the subject of my righteous indignation” is a highly motivating / positive-valence concept—even if the plain vanilla “Hamas” concept is demotivating / negative-valence.
You can alternatively easily generate arbitrarily many (apparent) counterexamples-to-linearity by using subordinate clauses and similar grammatical constructions: If you are [motivated / demotivated] by the idea of X, then you will be [demotivated / motivated] by the idea of “X is about to end”, “X is false”, “I’m opposed to X”, “My hated outgroup is really into the idea of X”, and so on. Again, your brain is presumably activating the concept X in the course of thinking this thought, but the contribution to valence goes the wrong way with respect to the linear model.
What exactly is going on in all these cases? To make a long story short, I do actually stand by my claim that valence is a (roughly) linear function on “concepts”. But I also think “concepts” can be much more complex and subtle than I’m making them out to be.
That’s all I’m going to say on this topic. I really don’t know the gory details, and if I did, I absolutely wouldn’t publish them, because I think such details would be extremely helpful for building Artificial General Intelligence (AGI), and only marginally helpful for making such AGI safe and beneficial. More discussion of “infohazards” here.
2.4.2 The valence of a concept cannot be interpreted as a meaningful normative assessment
I’ll just quote Scott Alexander here:
When everything works the way it’s supposed to in philosophy textbooks, arguments are supposed to go one of a couple of ways:
1. Questions of empirical fact, like “Is the Earth getting warmer?” or “Did aliens build the pyramids?”. You debate these by presenting factual evidence, like “An average of global weather station measurements show 2014 is the hottest year on record” or “One of the bricks at Giza says ‘Made In Tau Ceti V’ on the bottom.” Then people try to refute these facts or present facts of their own.
2. Questions of morality, like “Is it wrong to abort children?” or “Should you refrain from downloading music you have not paid for?” You can only debate these well if you’ve already agreed upon a moral framework, like a particular version of natural law or consequentialism. But you can sort of debate them by comparing to examples of agreed-upon moral questions and trying to maintain consistency. For example, “You wouldn’t kill a one day old baby, so how is a nine month old fetus different?” or “You wouldn’t download a car.”
If you are very lucky, your philosophy textbook will also admit the existence of:
3. Questions of policy, like “We should raise the minimum wage” or “We should bomb Foreignistan”. These are combinations of competing factual claims and competing values. For example, the minimum wage might hinge on factual claims like “Raising the minimum wage would increase unemployment” or “It is very difficult to live on the minimum wage nowadays, and many poor families cannot afford food.” But it might also hinge on value claims like “Corporations owe it to their workers to pay a living wage,” or “It is more important that the poorest be protected than that the economy be strong.” Bombing Foreignistan might depend on factual claims like “The Foreignistanis are harboring terrorists”, and on value claims like “The safety of our people is worth the risk of collateral damage.” If you can resolve all of these factual and value claims, you should be able to agree on questions of policy. …
A question: are you pro-Israel or pro-Palestine? Take a second, actually think about it.
Some people probably answered pro-Israel. Other people probably answered pro-Palestine. Other people probably said they were neutral because it’s a complicated issue with good points on both sides.
Probably very few people answered: Huh? What?
This question doesn’t fall into any of the three Philosophy 101 forms of argument. It’s not a question of fact. It’s not a question of particular moral truths. It’s not even a question of policy. There are closely related policies, like whether Palestine should be granted independence. But if I support a very specific two-state solution where the border is drawn upon the somethingth parallel, does that make me pro-Israel or pro-Palestine? At exactly which parallel of border does the solution under consideration switch from pro-Israeli to pro-Palestinian? Do you think the crowd of people shouting and waving signs saying “SOLIDARITY WITH PALESTINE” have an answer to that question? …
(If we switch from politics to everyday life, the “policy” category generalizes to “concrete plans and actions”. For example, a disagreement over “we should go to the bar” may involve both factual claims like “will it be crowded?”, and value claims like “is it rude to skip choir practice?”.)
OK, if a pro-Israel or anti-Israel attitude does not represent a meaningful normative assessment, then what does it represent?
2.4.3 The valence of a concept is really a learned normative heuristic
A “heuristic” is a fast algorithm for approximating something. Recall the positive-versus-normative distinction from §2.3 above. Many heuristics, such as the representativeness heuristic, can be called “positive heuristics”, in the sense that they are heuristics for figuring out “positive” things like factual predictions. Other heuristics might be called “normative heuristics”, in the sense that they are heuristics for generating (meaningful) normative assessments.
I claim that, if your brain assigns a valence to a concept like “Israel”, it corresponds to a normative heuristic—and more specifically, a learned normative heuristic, i.e. a normative heuristic that your brain has acquired from within-lifetime experience.
Continuing with the Israel example, the recipe for converting a concept-valence into its corresponding normative heuristic is:
“The concept ‘Israel’ has positive valence in my mind” corresponds to the following heuristic for your brain to generate snap normative assessments:
The more that a possible action or plan involves Israel / pattern-matches to Israel, the more likely it is that executing that action or plan is something that I want to do;
And the more that a possible future state of the world involves Israel / pattern-matches to Israel, the more likely it is that that state of the world is something that I want to try to bring about.
(and conversely for negative valence).
(As discussed in §2.4.1.1, the “involves Israel / pattern-matches to Israel” phrase is sweeping a bunch of complexity under the rug!)
So it’s still true that, as discussed above, these valences are not, in and of themselves, meaningful normative assessments. But they are just upstream of meaningful normative assessments.
2.4.4 Making sense of vibes-based “meaningless arguments”
In light of the above, we can now proceed into the next section of the “Ethnic Tension and Meaningless Arguments” blog post that I excerpted above:
So here is Ethnic Tension: A Game For Two Players.
Pick a vague concept. “Israel” will do nicely for now.
Player 1 tries to associate the concept “Israel” with as much good karma as she possibly can. Concepts get good karma by doing good moral things, by being associated with good people, by being linked to the beloved in-group, and by being oppressed underdogs in bravery debates.
“Israel is the freest and most democratic country in the Middle East. It is one of America’s strongest allies and shares our Judeo-Christian values.
Player 2 tries to associate the concept “Israel” with as much bad karma as she possibly can. Concepts get bad karma by committing atrocities, being associated with bad people, being linked to the hated out-group, and by being oppressive big-shots in bravery debates. Also, she obviously needs to neutralize Player 1’s actions by disproving all of her arguments.
“Israel may have some level of freedom for its most privileged citizens, but what about the millions of people in the Occupied Territories that have no say? Israel is involved in various atrocities and has often killed innocent protesters. They are essentially a neocolonialist state and have allied with other neocolonialist states like South Africa.”
The prize for winning this game is the ability to win the other three types of arguments [i.e., arguments about facts, morality, and policy].
I think these kinds of arguments make a lot more sense in light of the previous section on “learned normative heuristics”.
Specifically, Player 1 and Player 2 are arguing about the appropriateness of the following normative heuristic:
Proposed Heuristic Under Dispute: “The more that a possible action or plan involves / pattern-matches to “Israel”, the more likely it is that executing that action or plan is a good idea. Likewise, the more that a possible future state of the world involves / pattern-matches to “Israel”, the more likely it is that that state of the world is good to bring about.
(Again, see caveats in §2.4.1.1)
Player 1 wants Player 2 to adopt this heuristic. So Player 1 is prodding Player 2 to think lots of thoughts in which the above heuristic works very well—i.e., where it gives answers in agreement with all the other normative heuristics already in Player 2’s brain. That spurs Player 2’s brains to rely on that heuristic more than before.
Conversely, Player 2 wants Player 1 to reject this heuristic. So Player 2 is prodding Player 1 to think thoughts in which the above heuristic works exceptionally poorly—i.e., where it gives answers that are the diametric opposite of all the other normative heuristics already in Player 1’s brain. That spurs Player 1’s brain to rely on that heuristic less than before, or even to start relying on the exact opposite heuristic (a.k.a. negative valence).
(More mechanistic details for this process are in §2.5 below.)
2.4.5 Should we be “anti-” normative heuristics in general?
I for one am often annoyed to see people arguing over whether to be pro-capitalism versus anti-capitalism, pro-religion versus anti-religion, etc., as if these are meaningful arguments, when they’re not.
(Amusingly, I have a friend, and the two of us tend to agree on specific questions of economic policy. And yet we have a strong disagreement about vibes—the concept “capitalism” has strongly negative vibes in their brain and positive vibes in mine. Basically, our vibes disagreement is mostly canceled out by an equal-and-opposite disagreement over what is or isn’t “capitalism”!)
These kinds of meaningless arguments are sometimes explicit, but even more often they are hiding slightly below the surface, with debate happening simultaneously on the object level and vibes level.
For example, if someone thinks that they think they just “scored a point”, then that fact often comes across in their words, even if they don’t come out and explicitly announce “Checkmate, atheists!” etc. And in those cases, it’s worth asking what very specific thing they think they scored a point against, because maybe that thing isn’t even a subject of disagreement in the first place.
(Needless to say, that goes doubly for oneself: look in the mirror and ask what very specific thing you are arguing for!)
(The “scoring points” attitude is problematic in the first place—see The Scout Mindset—but arguing about a very specific concrete mutually-understood thing is the least-bad version of that.)
Normative heuristics are particularly problematic when our brain is assigning a valence to something big and vague. For example, “things that involve / pattern-match to ‘religion’” is an extremely heterogeneous collection—everything from ancient Shinto rituals, to a Pope-themed tourist trinket that I once bought myself at a Vatican gift shop. What are the chances that everything in this collection is all good, or all bad, upon reflection? Pretty low. (Cf. “bucket errors”.) So if we put a strong valence on “religion”, whether positive or negative, we get one of two problems:
We’ll make bad normative assessments about specific religion-related things (“bad” in the sense that, if we thought about the thing more carefully, we would change our mind);
…Or we’ll wind up gerrymandering the concept “religion” to accord with our endorsed normative assessments. (e.g. someone might say “Religion is [good/bad], for sure; but such-and-such [bad/good] thing is not really religion.”)
I think the latter can be pretty harmful to clear thinking. It’s fine to have some concepts that explicitly involve normative assessments (“preferable”, “problematic”, “trouble”, “flourishing”, etc.—see §1.4 in the previous post, or related arbital post), since after all normative assessments are a thing we often want to talk about. But we also desperately need concepts that describe how the world works independently from how we feel about it. I’ll be discussing this topic much more in the next post (§3.4).
Having said all that, we cannot be “anti-” normative heuristics in general, because if we take them away, then there’s nothing left! After all, the brain needs some way to assess plans / actions / futures as being good or bad, including ones that we’ve never encountered before.
So as a practical matter, I think assigning valence to concepts is fine, and even assigning rather strong valence to rather broad concepts is OK to some extent. My own brain seems to assign at least some nonzero valence to at least some rather broad concepts like “communism” (boo), “poverty” (boo), “AI alignment” (yay), “ice cream” (yay), and so on, and I don’t currently think I should try too hard to change that. The important thing is cultivating a habit of asking follow-up questions that lean into specifics and probe for exceptions to general rules.
For example, ask yourself: What’s the exact proposal? What are its likely consequences, both intended and unintended? When we say “communism”, are we talking about “communism as in Stalin” or “communism as in Deng” or “communism as in small hunter-gatherer tribes”? When we say “ice cream”, are we talking about “ice cream as in Häagen-Dazs” or “ice cream as in SpongeBob SquarePants Popsicles”? When we say “AI alignment”, are we talking about “AI alignment as defined by me” or “AI alignment as defined by Sam Altman”? Etc.
If the specifics are salient in your mind, then, I claim, the corresponding normative heuristics are more likely to give good assessments, ones that stand up to scrutiny and hindsight.
(And incidentally, if you cultivate this habit, it probably leads over time to assigning more neutral valence to vague broad concepts, and stronger valence to more specific features. And that’s probably a good thing.)
2.5 How does valence get set and adjusted?
If you trace back far enough, I claim that all valence ultimately flows, directly or indirectly, from innate drives (a.k.a. primary rewards)—genetically-specified circuits that declare pain to be bad, and eating-when-hungry to be good, and “drive to feel liked / admired” (coming up in Post 4), and various other social drives related to compassion and revenge and guilt etc., and probably hundreds more things like that.
(In reinforcement learning terms—see §1.3 of the previous post—your “innate drives” more-or-less correspond to various terms contributing to the reward function. In neuroanatomical terms, I claim that implementing these innate drives constitutes a key responsibility of the hypothalamus and brainstem, although other brain areas are involved as well.)
To oversimplify somewhat, I claim there are two main reasons that a thought can be positive or negative valence:
The first reason that a thought can be positive or negative valence is that an innate drive is stepping in and declaring, right now, that the thought is good or bad respectively. (For example, if I’m hungry and I start eating yummy food, then whatever I’m thinking about at that moment—presumably the food—is evidently a good thing.)
The second reason that a thought can be positive or negative valence is that our brain has a learning algorithm to guess what valence assignment would be most appropriate to a thought—based on the past history of actual valence assignments. And when the innate drives are not “overriding” that guess, the guess flows through into a self-fulfilling prophecy. (The learning algorithm has some relation to Temporal Difference (TD) Learning; I’m leaving aside all the details, although see here for a bit more.)
Leaving aside all the mechanistic details, this learning algorithm has various effects like:
If Thought Θ has had a certain valence all the previous times that you thought it, then the learning algorithm will start guessing that Θ (and thoughts sufficiently similar to Θ) will have the same valence in the future.
If X (e.g. opening Twitter) has often immediately led to Y (e.g. seeing a “like” notification), i.e. as a temporal sequence in the real world, then the learning algorithm will start guessing that the appropriate valence for X is closer to whatever the valence happens to be for Y.
Likewise, if Thought X has often immediately led to Thought Y in your brain, then ditto the previous bullet point. (In other words, the “temporal” part of TD learning can be entirely within your brain’s train-of-thought, with no relation to time-sequences in the outside world.)
To head off a possible misconception: innate drives are not the same as goals, or terminal goals. Your goals, e.g. “get out of debt” or “reduce suffering”, are built out of concepts in your world-model (a.k.a. “Thought Generator”)—concepts that you learned within your lifetime. Innate drives are not—instead, they’re little machines built by the genome that spit out certain signals in certain situations. I’ll sometimes talk about an “innate drive to avoid pain”, or similar things, but that’s really shorthand for the more pedantic “circuit that detects peripheral signals related to what we usually call “pain”, and then spits out negative valence (among other signals), and thus the typical effect of this circuit over time is to make us want to avoid pain”.
2.5.1 Special case: Things that go together tend to acquire similar valence
In §1.5.1 of the previous post, I brought up an example of having “mixed feelings” about going to the gym. If I pay attention to one aspect of it, it has positive valence (“I’m gonna go to the gym, thus following through on my New Year’s Resolution”). If I pay attention to a different aspect of it, it has negative valence (“I’m gonna go to the gym which is really loud and cold”).
It might be that I wind up doing a lot of mental flipping back and forth between these two frames, in immediate succession within a second or two. In other words, when I think about the positive aspects, maybe it jogs my memory to call up the negative aspects, and vice-versa. If so, I think TD learning will tend to update my valence function to make the positive-valence aspects more negative and vice-versa (per the third bullet point above). Specifically, maybe the idea of following through on my New Year’s Resolution will start to feel a bit less motivating and more aversive, and conversely, maybe thinking about the loudness and coldness of the gym will start to feel a bit less aversive.[2]
2.6 Valence of metacognitive & self-reflective thoughts: ego-syntonic vs -dystonic ideas, professed “values”, etc.
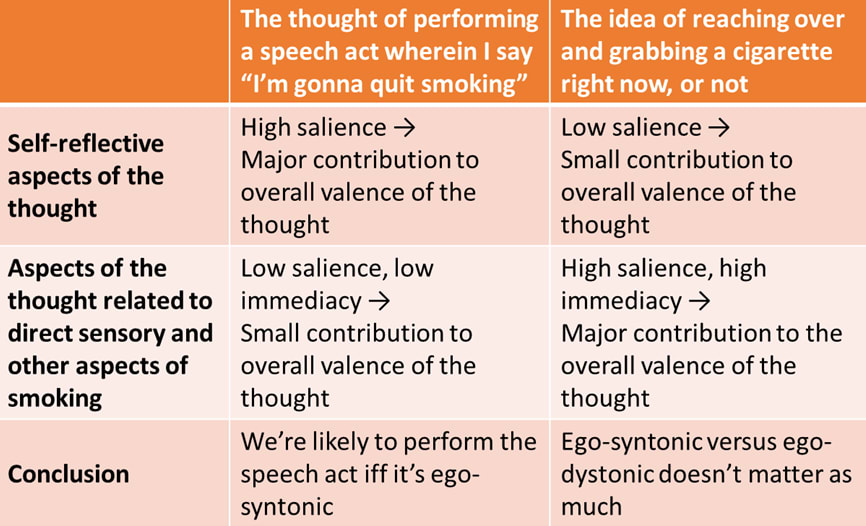
Let’s say I’m addicted to cigarettes, but want to quit. Given that I’m addicted to cigarettes, sometimes “the idea of smoking right now” will be very positive-valence—in other words, “sometimes I feel an urge to smoke”—and therefore I will have a smoke.
But that’s annoying! I had wanted to quit! Since I’m not a complete moron, I will naturally notice the obvious fact that “urge-I-feel-to-smoke” is an obstacle preventing me from following through on my motivation-to-quit-smoking. And that makes me dislike “urge-I-feel-to-smoke”.
And now we have entered the realm of self-reflective preferences!
Thus, “the idea that smoking sometimes feels positive-valence to me” winds up with its own valence assessment in my head, and that valence is strongly negative. This would be an example of an ego-dystonic valence assessment. I want to smoke, but I don’t want to want to smoke.
Now, again, suppose a thought pops into my head: “maybe I’ll go smoke right now”. If that thought entails paying attention to the expected sensory sensations etc., then the valence of this thought will be positive, and so I’ll smoke. If the thought instead entails mostly ignoring those, and instead paying attention to more self-reflective aspects of the situation—as if viewing myself from the outside, perhaps—then the valence of this thought will be negative, and so I won’t smoke. Realistically, probably both types of thoughts will pop into my head at different times, and the relative strengths of the valence will help determine how things shake out.
The opposite of ego-dystonic is ego-syntonic. For example, the idea of “myself being inclined to honesty and conscientiousness” is ego-syntonic. So if a plan pattern-matches to seeing myself as honest and conscientious, that plan earns a valence boost, so I’m more likely to do it. But only on the margin. The plan has other aspects too, which also contribute to the valence, and in fact those other aspects are often more salient.
An important observation here is that professed goals and values, much more than actions, tend to be disproportionately determined by whether things are ego-syntonic or -dystonic. Consider: If I say something out loud (or to myself) (e.g. “I’m gonna quit smoking” or “I care about my family”), the actual immediate thought in my head was mainly “I’m going to perform this particular speech act”. It’s the valence of that thought which determines whether we speak those words or not. And the self-reflective aspects of that thought are very salient, because speaking entails thinking about how your words will be received by the listener. By contrast, the contents of that proclamation—actually quitting smoking, or actually caring about my family—are both less salient and less immediate, taking place in some indeterminate future (see time-discounting). So the net valence of the speech act probably contains a large valence contribution from the self-reflective aspects of quitting smoking, and a small valence contribution from the more direct sensory and other consequences of quitting smoking, or caring about my family. And this is true even if we are 100% sincere in our intention to follow through with what we say. (See also Approving reinforces low-effort behaviors, a blog post making a similar point as this paragraph.)
2.6.1 What are “values”?
I’m bringing up this topic because it often comes up in my profession (AI alignment). But I’m not sure it has any deep answer; it strikes me as mostly just an argument about definitions.
Here’s a definition of “values” that I like, because it seems to align with how people use that word in my everyday life: If I want to know somebody’s “values”, I would just ask them, and write down what they say. Then I would declare that whatever I wrote down is “their values”, more-or-less by definition, with rare exceptions like if they’re deliberately trolling me.
According to this definition, “values” are likely to consist of very nice-sounding, socially-approved, and ego-syntonic things like “taking care of my family and friends”, “making the world a better place”, and so on.
Also according to this definition, “values” can potentially have precious little influence on someone’s behavior. In this (extremely common) case, I would say “I guess this person’s desires are different from his values. Oh well, no surprise there.”
Indeed, I think it’s totally normal for someone whose “values” include “being a good friend” will actually be a bad friend. So does this “value” have any implications at all? Yes!! I would expect that, in this situation, the person would either feel bad about the fact that they were a bad friend, or deny that they were a bad friend, or fail to think about the question at all, or come up with some other excuse for their behavior. If none of those things happened, then (and only then) would I say that “being a good friend” is not in fact one of their “values”, and if they stated otherwise, then they were lying or confused.
2.7 Moral reasoning
2.7.1 A descriptive account
As described above, I think the positive-versus-normative distinction has a pretty clean correspondence to major components of the brain’s large-scale anatomy and algorithms.
However, within the normative domain, I think the distinction between “X is the moral / ethical / virtuous / etc. thing to do” and “I want to do X” is not too fundamental—it’s more like a boundary between fuzzy learned categories. People tend to call things moral / ethical / virtuous when they’re ego-syntonic and socially-approved, for example. But that rule has exceptions too. For example, a mafioso might take pride in his “immorality”. Even in that case, the mafioso may still be figuring out what is and isn’t ego-syntonic and socially-approved within his own criminal social niche, and his thinking there may even structurally resemble “normal” moral reasoning. But he wouldn’t use the word “moral”.
In any case, let’s say you’re a normal law-abiding person who sincerely wants to act morally. So you sit down in your armchair and try to figure out what’s the moral thing to do. What happens next? Lots of things:
Maybe you think about object-level things, like maybe you imagine a child suffering. And maybe those thoughts have valence—i.e., you find that you have preferences about those things.
Maybe you think about metacognitive things, like “I will think carefully, rather than rushing to judgment” or conversely “I should trust my gut more”. And maybe those thoughts have valence—i.e., you find that you have preferences about those things.
Maybe you think about self-reflective things, like “What sort of force am I in the world?” or “What would my friends think of me if they could read my mind right now?”. And maybe those thoughts have valence—i.e., you find that you have preferences about those things.
Maybe you notice that some of these preferences are inconsistent with others. And then you think more thoughts, where these different preferences may duke it out.
Throughout this whole process, your brain’s learning algorithms are continually updating both your beliefs and your desires.
In the context of this series, one point I want to make is that every step rests on the foundation of valence. For example, if your brain assigns no particular valence to the idea of a child suffering, then you’re not going to feel motivated to prevent the child from suffering.
To make that more intuitive: Suppose I tell you: “It’s important to wear pants with an even number of belt loops”, and then you say “Why?”, and then I say “Y’know, if you didn’t, then your pants would have an odd number of belt loops! And that would be bad!!”, and again you say “Huh? Why is that bad?”. This conversation is going nowhere.
By contrast, if I say “If you follow principle X, then the oppressed masses will get justice”, now I can pique your interest, because “the oppressed masses will get justice” is already cemented in your brain as an appealing (positive-valence) concept.
The other important point I want to make, as mentioned above (§2.5), is that valence, in turn, ultimately (albeit often very indirectly) stems from innate drives. As in §2.5, for every waking second of your life, valence has been flowing from concepts to other concepts based on your observations and train of thought. But if you trace back far enough, the valence ultimately has to derive from your innate drives. In the case of moral reasoning—e.g. “the oppressed masses will get justice” example above—I think the innate drives in question are almost certainly innate social drives, i.e. innate drives related to compassion, revenge, social status (coming up in Post 4), and so on.
2.7.2 Implications for the “true nature of morality” (if any)
I’m very far from an expert on meta-ethics, but here are some things that seem to follow from the above account.
If there’s such a thing as “true morality” which is completely independent of the particularities of human innate drives and current memetic environment, then there isn’t any obvious reason that the process described above should converge to it, or indeed have anything to do with it. If it did, I think we would have to declare it a happy coincidence. (For a much deeper discussion of this point, see Joe Carlsmith’s essay “The ignorance of normative realism bot”.)
In fact, there isn’t any obvious reason that the process described above should converge to any well-defined destination. I do not think this is analogous to math. In math, if there’s a hypothetical agent with an “innate disposition” to “like” certain math axioms and their logical consequences, then there’s a unique answer to what the agent will or won’t “like”, given enough time to reflect—i.e., the mathematical statements that are provable from those axioms. By contrast, if a human starts with their innate drives, and goes through the process above, it just seems much messier. For example, as soon as you start “liking” a certain metacognitive pattern, it changes the ground-rules governing future steps of deliberation. Thus, there may well be indeterminate path-dependence in where the process ends up. Or it could wind up following endless cycles around various not-very-satisfactory states.
Even if the process described above does converge to a unique and well-defined destination, then it’s not necessarily the same destination for every human (and forget about extraterrestrials or AIs). In fact, I would go further and guess that it’s probably importantly different for different people, and not just in unusual cases like sociopaths, but broadly across the population. (E.g. I think the end of this post is too optimistic.) The reason I think that is: the destination will certainly depend on the innate drives of the person who is deliberating, and probably also on their life history, especially memetic environment. Let’s focus on the first one—innate drives. I acknowledge that almost all humans have qualitatively similar innate drives—i.e., they’re built the same way. But I don’t think they’re quantitatively similar. In particular, the relative strengths of various different innate drives seem to vary substantially from person to person. For example, I think some people feel the status-related “drive to feel liked / admired” (coming up in Post 4) very acutely, and others feel it more mildly, and ditto with innate drives related to compassion, revenge, and so on. These relative strengths are important because morality is full of situations where different intuitions trade off against each other.
Compare “I want the oppressed masses to find justice” with “I’ve been standing too long, I want to sit down”. These two “wants” are fundamentally built out of the same mind-stuff. They both derive from positive valence, which in turn ultimately comes from innate drives (specifically, mainly social drives in the first case, and homeostatic energy-conserving drives in the second case). So if “true morality” or “true human morality” or whatever doesn’t exist, then that does not constitute a reason to sit down rather than to seek justice. You still have to make decisions. That’s what I meant by “nihilism is not decision-relevant”, or Yudkowsky by “What would you do without morality?”. Indeed, you’ll notice that I talked about the deliberative process first, and the philosophy second. The deliberative process is powered by the engine of your own motivations, whatever they are, for better or worse—not by any external normative truth.
2.7.3 Possible implications for AI alignment discourse
As an AI alignment researcher, I should probably spell out exactly what I’m getting at, in terms of ideas in my local intellectual community. This section is low-confidence and jargon-heavy; readers outside the AI alignment field should feel free to ignore.
I’m concerned that CEV isn’t well-defined. Or more specifically, that you could list numerous equally-a-priori-plausible detailed operationalizations of CEV, and they would give importantly different results, in a way that we would find very unsatisfying.
Relatedly, I’m concerned that a “Long Reflection” wouldn’t resolve all the important things we want it to resolve, or else resolve them in a way that is inextricably contingent on details of the Long Reflection governance / discourse rules, with no obvious way to decide which of numerous plausible governance / discourse rules are “correct”.
When people make statements that implicitly treat “the value of the future” as being well-defined, e.g. statements like “I define ‘strong utopia’ as: at least 95% of the future’s potential value is realized”, I’m concerned that these statements are less meaningful than they sound.
I’m concerned that changes in human values over the generations are at some deep level more like a random walk than progress-through-time, and that they only feel like progress-through-time because we’re “painting the target around the arrow”. So when we say “Eternal value lock-in is bad—we want to give our descendants room for moral growth!”, and we also simultaneously say specific things like “We want a future with lots of friendship and play and sense-of-agency and exploration, and very little pain and suffering, and…!”, then I’m concerned that those two statements are at least a little bit at odds, and maybe strongly at odds. (If it turns out that we have to pick just one of those two statements, I don’t know which one I’d vote for.)
None of the above is at all an argument that we shouldn’t try to solve the AI alignment problem, or that we shouldn’t care about how the future goes. As in the previous subsection, we still can and must make decisions. My desire to avoid a future universe full of torture and slavery (to take an especially straightforward example) is as strong as ever, and if you share that desire, then let’s work together to make it happen.
2.8 Conclusion
Again, I think valence is the substance out of which is built all normativity in the brain. Hopefully this post has shed light on some of the pieces of that puzzle. I’m open to ideas and discussion, and in the next post we turn to the lesser but still substantial impacts of valence in the positive (as opposed to normative) domain of beliefs, expectations, concepts, and so on.
Thanks to Tsvi Benson-Tilsen, Seth Herd, Aysja Johnson, Justis Mills, Charlie Steiner, Adele Lopez, and Garrett Baker for critical comments on earlier drafts.
- ^
“Bulverism” is a term that means “assuming without justification that certain beliefs are incorrect, and then engaging in psychological speculation about how people wound up holding those incorrect beliefs”. However, see §2.7 below for a bit more on moral realism.
- ^
In this example—”maybe the idea of following through on my New Year’s Resolution will start to feel a bit less motivating and more aversive, and conversely, maybe thinking about the loudness and coldness of the gym will start to feel a bit less aversive”—I actually think there are two ways that this shift can happen, and that the brain does both those processes in parallel. The first one, described in the text, involves changes to the valence of different thoughts by TD learning. The second one, which I won’t discuss because it’s off-topic, involves changes to the world-model (a.k.a. “Thought Generator”), and its web of concepts and their associations / connotations.
- [Valence series] 1. Introduction by (4 Dec 2023 15:40 UTC; 99 points)
- Voting Results for the 2023 Review by (6 Feb 2025 8:00 UTC; 86 points)
- [Valence series] 3. Valence & Beliefs by (11 Dec 2023 20:21 UTC; 77 points)
- [Intuitive self-models] 8. Rooting Out Free Will Intuitions by (4 Nov 2024 18:16 UTC; 75 points)
- [Intuitive self-models] 6. Awakening / Enlightenment / PNSE by (22 Oct 2024 13:23 UTC; 73 points)
- Social status part 2/2: everything else by (5 Mar 2024 16:29 UTC; 65 points)
- [Intro to brain-like-AGI safety] 9. Takeaways from neuro 2/2: On AGI motivation by (23 Mar 2022 12:48 UTC; 46 points)
- 's comment on Thane Ruthenis’s Shortform by (5 Jun 2025 6:39 UTC; 8 points)
I basically think @sunwillrise got it correct, so I’m basically going to link to it, but I will expand on the implications below:
https://www.lesswrong.com/posts/SqgRtCwueovvwxpDQ/valence-series-2-valence-and-normativity#d54v5ThrDtt8Lmaer
I’d probably put somewhat less weight on the innateness of it, but still very valuable here.
I’d especially signal boost this, which argues for being more specific, and I basically agree with that recommendation, but also I think this is why we need to be able to decouple moral/valence assignments from positive facts, and you should not be both debating good or bad things with factual matters:
https://www.lesswrong.com/posts/SqgRtCwueovvwxpDQ/valence-series-2-valence-and-normativity#2_4_5_Should_we_be__anti___normative_heuristics_in_general_
+9 for deconfusing people on fundamental matters related to morality.
I think sections 2.2, 2.4.5, 2.7.1, 2.7.2 and 2.7.3 should be in the LW canon as how to deal with moral/value questions, including why CEV doesn’t really work as an AI alignment strategy.
Edit: I mean the CEV of humanity, not the CEV of an individual, I now think that if restrained to individuals, CEV philosophically works.