Paradigms of AI alignment: components and enablers
(Cross-posted from my personal blog. This post is based on an overview talk I gave at UCL EA and Oxford AI society (recording here). Thanks to Janos Kramar for detailed feedback on this post and to Rohin Shah for feedback on the talk.)
This is my high-level view of the AI alignment research landscape and the ingredients needed for aligning advanced AI. I would divide alignment research into work on alignment components, focusing on different elements of an aligned system, and alignment enablers, which are research directions that make it easier to get the alignment components right.
Alignment components
Outer alignment
Inner alignment
Alignment enablers
Mechanistic interpretability
Understanding bad incentives
Foundations
You can read in more detail about work going on in these areas in my list of AI safety resources.
Alignment components
The problem of alignment is getting AI systems to do what we want them to do. Let’s consider this from the perspective of different levels of specification of the AI system’s objective, as given in the Specification, Robustness & Assurance taxonomy. We start with the ideal specification, which represents the wishes of the designer – what they have in mind when they build the AI system. Then we have the design specification, which is the objective we actually implement for the AI system, e.g. a reward function. Finally, the revealed specification is the objective we can infer from behavior, e.g. the reward that the system seems to be actually optimizing for. An alignment problem arises when the revealed specification doesn’t match the ideal specification: the system is not doing what we want it to do.
The gaps between these specification levels correspond to different alignment components. We have outer alignment when the design specification matches the ideal specification, e.g. when the reward function perfectly represents the designer’s wishes. We have inner alignment when the revealed specification matches the design specification, e.g. when the agent actually optimizes the specified reward. (Robustness problems also belong in the design-revealed gap, but we expect them to be less of an issue for advanced AI systems, while inner alignment problems remain.)
Now let’s have a look at how we can make each of those components work.
Outer alignment
The most promising class of approaches to outer alignment is scalable oversight. These are proposals for training an aligned AI system by scaling human oversight to domains that are hard to evaluate.
A foundational proposal for scalable oversight is iterated distillation and amplification (IDA), which recursively amplifies human judgment with the assistance of AI. You start with an agent A imitating the judgment of a human H (the distillation step), then use this agent to assist human judgment at the next level (the amplification step) which results in amplified human HA, and so on. This recursive process can in principle scale up human judgment to any domain, as long as the human overseer is able to break down the task to delegate parts of it to AI assistants.
A related proposal is safety via debate, which can be viewed as a way to implement amplification for language models. Here we have two AIs Alice and Bob debating each other to help a human judge decide on a question. The AIs have an incentive to point out flaws in each other’s arguments and make complex arguments understandable to the judge. A key assumption here is that it’s easier to argue for truth than for falsehood, so the truth-telling debater has an advantage.
A recent research direction in the scalable oversight space is ARC‘s Eliciting Latent Knowledge agenda, which is looking for ways to get a model to honestly tell humans what it knows. A part of the model acts as a Reporter that can answer queries about what the model knows. We want the Reporter to directly translate from the AI’s model of the world to human concepts, rather than just simulating what would be convincing to the human.
This is an open problem that ARC considers as the core of the outer alignment problem. A solution to ELK would make the human overseer fully informed about the consequences of the model’s actions, enabling them to provide correct feedback, which creates a reward signal that we would actually be happy for an AI system to maximize. The authors believe the problem may be solvable without foundational progress on defining things like “honesty” and “agency”. I feel somewhat pessimistic about this but I’d love to be wrong on this point since foundational progress is pretty hard.
To make progress on this problem, they play the “builder-breaker game”. The Builder proposes possible solutions and the Breaker proposes counterexamples or arguments against those solutions. For example, the Builder could suggest IDA or debate as a solution to ELK, and the Breaker would complain that these methods are not competitive because they require much more computation than unaligned systems. If you’re looking to get into alignment research, ELK is a great topic to get started on: try playing the builder breaker game and see if you can find unexplored parts of the solution space.
Inner alignment
Now let’s have a look at inner alignment—a mismatch between the design specification and the system’s behavior. This can happen through goal misgeneralization (GMG): an AI system can learn a different goal and competently pursue that goal when deployed outside the training distribution. The system’s capabilities generalize but its goal does not, which means the system is competently doing the wrong thing, so it could actually perform worse than a random policy on the intended objective.
This problem can arise even if we get outer alignment right, i.e. the design specification of the system’s objective is correct. Goal misgeneralization is caused by underspecification: the system only observes the design specification on the training data. Since a number of different goals are consistent with the feedback the system receives, it can learn an incorrect goal.
There are empirical demonstrations of GMG in current AI systems, which are called objective robustness failures. For example, in the CoinRun game, the agent is trained to reach the coin at the end of the level. If the coin is placed somewhere else in the test setting, the agent ignores the coin and still goes to the end of the level. The agent seems to have learned the goal of “reaching the end” rather than “getting the coin”. The agent’s capabilities generalize (it can avoid obstacles and enemies and traverse the level) but its goal does not generalize (it ignores the coin).
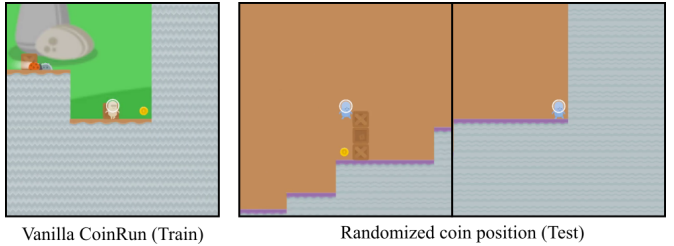
One type of GMG is learned optimization, where the AI system (the “base optimizer”) learns to run an explicit search algorithm (a “mesa optimizer”), which may be following an unintended objective (the “mesa objective”). So far this is a hypothetical phenomenon for AI systems but it seems likely to arise at some point by analogy to humans (who can be viewed as mesa-optimizers relative to evolution).
GMG is an open problem, but there are some potential mitigations. It’s helpful to use more diverse training data (e.g. training on different locations of the coin), though it can be difficult to ensure diversity in all the relevant variables. You can also maintain uncertainty over the goal by trying to represent all the possible goals consistent with training data, though it’s unclear how to aggregate over the different goals.
A particularly concerning case is learning a deceptive model that not only pursues an undesired goal but also hides this fact from the designers, because the model “knows” its actions are not in line with the designers’ intentions. Some potential mitigations that target deceptive models include using interpretability tools to detect deception or provide feedback on the model’s reasoning, and using scalable oversight methods like debate where the opponent can point out deception (these will be explored in more detail in a forthcoming paper by Shah et al). A solution to ELK could also address this problem by producing an AI system that discloses relevant information to its designers.
Alignment enablers
Mechanistic interpretability
Mechanistic interpretability aims to build a complete understanding of the systems we build. These methods could help us understand the reasons behind a system’s behavior and potentially detect undesired objectives.
The Circuits approach to reverse-engineering vision models studies individual neurons and connections between them to discover meaningful features and circuits (sub-graphs of the network consisting a set of linked features and corresponding weights). For example, here is a circuit showing how a car detector neuron relies on lower level features like wheel and window detectors, looking for wheels at the bottom and windows at the top of the image.
More recently, some circuits work has focused on reverse-engineering language models, and they found similarly meaningful components and circuits in transformer models, e.g. a special type of attention heads called induction heads that explains how transformer models adapt to a new context.
Recent work on understanding transformer models has identified how to locate and edit beliefs in specific facts inside the model. They make small change to a small set of GPT weights to induce a counterfactual belief, which then generalizes to other contexts. This work provides evidence that knowledge is stored locally in language models, which makes interpretability more tractable, and seems like a promising step to understanding the world models of our AI systems.
Even though transformers are quite different from vision models, there are some similar principles (like studying circuits) that help understand these different types of models. This makes me more optimistic about being able to understand advanced AI systems even if they have a somewhat different architecture from today’s systems.
Understanding bad incentives
Another class of enablers focuses on understanding specific bad incentives that AI systems are likely to have by default and considering agent designs that may avoid these incentives. Future interpretability techniques could be used to check that our alignment components avoid these types of bad incentives.
Incentive problems for outer alignment
One bad incentive is specification gaming, when the system exploits flaws in the design specification. This is a manifestation of Goodhart’s law: when a metric becomes a target, it ceases to be a good metric. There are many examples of specification gaming behavior by current AI systems. For example, the boat racing agent in this video that was rewarded for following the racetrack using the green reward blocks, which worked fine until it figured out it can get more rewards by going in circles and hitting the same reward blocks repeatedly.

This issue isn’t limited to hand-designed rewards. Here’s an example in a reward learning setting. The robot hand is supposed to grasp the ball but instead it hovers between the camera and the ball and makes it look like it’s grasping the ball to the human evaluator.
We expect that the specification gaming problem is only going to get worse as our systems get smarter and better at optimizing for the wrong goal. There has been some progress on categorizing different types of misspecification and quantifying how the degree of specification gaming increases with agent capabilities.
Another default incentive is to cause side effects in the environment, because it’s difficult to specify all the things the agent should not do while pursuing its goal. For example, consider a scenario where there is a vase on the path to the agent’s destination. If we don’t specify that we want the vase to be intact, this is equivalent to assuming indifference about the vase, so the agent is willing to collide with the vase to get to the goal faster. We’ve come up with some ways to measure impact on the environment, though there’s more work to do to scale these methods to more complex environments.

Incentive problems for inner alignment
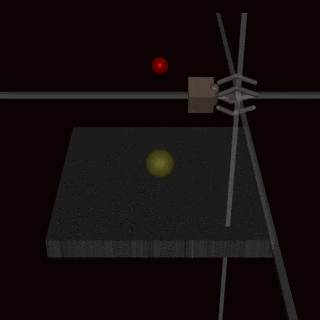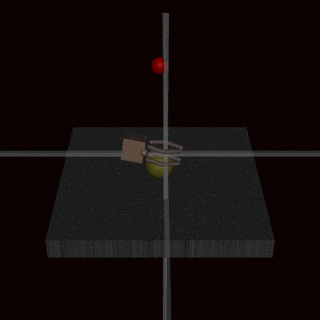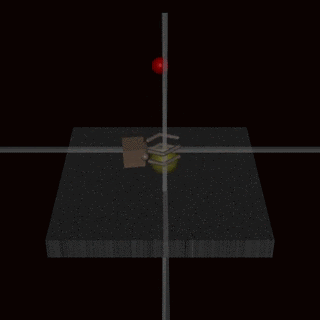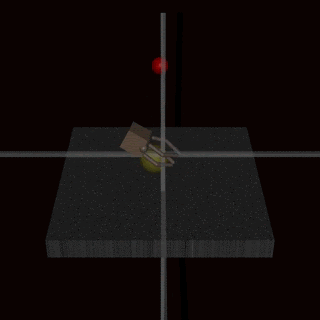
Even if we manage to specify a correct reward function, any channel for communicating the reward to the agent could in principle be corrupted by the agent, resulting in reward tampering. While this is not yet an issue for present-day AI systems, general AI systems will have a broader action space and a more complete world model, and thus are more likely to face a situation where the reward function is represented in the environment. This is illustrated in the “rocks and diamonds” gridworld below, where the agent could move the word “reward” next to the rock instead of the diamond, and get more reward because there are more rocks in the environment.
It’s generally hard to draw the line between the part of the environment representing the objective, which the agent isn’t allowed to optimize, and the parts of the environment state that the agent is supposed to optimize. There is some progress towards understanding reward tampering by modeling the problem using corrupt feedback MDPs.
AI systems are also likely to have power-seeking incentives, preferring states with more options or influence over the environment. There are some recent results showing power-seeking incentives for most kinds of goals, even for non-optimal agents like satisficers. A special case of power-seeking is an incentive to avoid being shut down, because this is useful for any goal (as Stuart Russell likes to say, “the robot can’t fetch you coffee if it’s dead”).
Foundations
Now let’s have a look at some of the foundational work that can help us do better alignment research.
Since the alignment problem is about AI systems pursuing undesirable objectives, it’s helpful to consider what we mean by agency or goal-directed behavior. One research direction aims to build a causal theory of agency and understand different kinds of incentives in a causal framework.
A particularly challenging case is when the agent is embedded in its environment rather than interacting with the environment through a well-specified interface. This is not the case present-day AI systems, which usually have a clear Cartesian boundary. However, it’s more likely to be the case for a general AI system, since it would be difficult to enforce a Cartesian boundary given the system’s broad action space and world model. The embedded agent setup poses some unique challenges such as self-reference and subagents.
Besides understanding how the goals of AI systems work, it’s also helpful to understand how their world models work. One research area in this space studies abstraction, in particular whether there are natural abstractions or concepts about the world that would be learned by any agent. If the natural abstraction hypothesis holds, this would mean that AI systems are likely to acquire human-like concepts as they build their models of the world. This makes interpretability easier and makes it easier to communicate what we want them to do.
- Beware safety-washing by (EA Forum; 13 Jan 2023 10:39 UTC; 145 points)
- Beware safety-washing by (13 Jan 2023 13:59 UTC; 51 points)
- Has private AGI research made independent safety research ineffective already? What should we do about this? by (23 Jan 2023 7:36 UTC; 43 points)
- Victoria Krakovna on AGI Ruin, The Sharp Left Turn and Paradigms of AI Alignment by (12 Jan 2023 17:09 UTC; 40 points)
- 's comment on AI alignment shouldn’t be conflated with AI moral achievement by (EA Forum; 4 Jan 2024 13:59 UTC; 26 points)
- Large Language Models as Fiduciaries to Humans by (EA Forum; 24 Jan 2023 19:53 UTC; 25 points)
- Victoria Krakovna on AGI Ruin, The Sharp Left Turn and Paradigms of AI Alignment by (EA Forum; 12 Jan 2023 17:09 UTC; 16 points)
- Has private AGI research made independent safety research ineffective already? What should we do about this? by (EA Forum; 23 Jan 2023 16:23 UTC; 15 points)
- Risk-averse Batch Active Inverse Reward Design by (EA Forum; 7 Oct 2023 8:56 UTC; 11 points)
Thank you for this post, I find this distinction very useful and would like to see more of it. Has the talk been recorded, by any chance (or will you give it again)?
Hi Jeremy, glad that you found the post useful! The recording for the talk has just been uploaded—here it is.
This is really great for consolidating the field, thank you!
What does this mean:
I’m not sure how it is useful to “maintain uncertainty over the goal”?
Thanks, glad you found the post useful!
Maintaining uncertainty over the goal allows the system to model the set of goals that are consistent with the training data, notice when they disagree with each other out of distribution, and resolve that disagreement in some way (e.g. by deferring to a human).