Deconfusing Landauer’s Principle
I’m going to assume knowledge of the basics of information theory. I won’t assume any physics knowledge (but you’ll probably find it easier if you know physics).
Thanks to Francis Priestland, Anson Ho, Nico Macé, Dan Hatton and Kenneth Freeman for their comments.
This was the result of me being nerd-sniped by a friend who wanted to talk to me about the connection between cognition and thermodynamics. I thought “yea, I know thermodynamics, it should take me a nice afternoon or two of straightening things out in my head to come up with something interesting to say”. How naive of me. In the process, I fell down a number of holes of confusion. I realised that properly understanding Landauer’s principle would be a good waypoint on my quest. This is the result of my clearing up these confusions.
Landauer’s principle is often summarised as something like:
1 bit of memory in a register is erased, destroying 1 bit of information. Because information is entropy(?!), this means the memory register loses 1 bit of entropy. Total entropy always increases over time, so the environment must increase its entropy by at least 1 bit to compensate, resulting in a corresponding minimum amount of heat dissipation, along with a minimum energy requirement for deleting the bit.
But whoa hey hold your horses there; what does entropy really mean here? Is the Shannon entropy of a logic gate really connected to its thermodynamic entropy, and if so, in what way? I always found Landauer’s principle a bit mysterious because it seems, at first glance, to connect something we tend to consider as a subjective construct (a probability distribution) with a measurable physical outcome (the release of heat). And I’m clearly not alone, there have been a bunch of people coming out and saying that the principle is widely misunderstood or even that the principle itself is wrong (but don’t panic, it’s been pretty well experimentally verified). So fleshing out what’s really going on here was helpful for me to understand more intuitively what computation (and by extension cognition maybe?) means from a physics point of view. The central insight is that, as Landauer put it; “information is physical”.
The relationship between Shannon entropy and thermodynamic entropy
Thermodynamic entropy is a pretty objective property of some physical system. It’s related to other macroscopic properties like internal energy, temperature and pressure. Here is how it’s defined. When some amount of energy in the form of heat, , is transferred into a system at temperature , this causes an increase in the thermodynamic entropy of the system of . When something is hot I can feel its heat, so I’m convinced that heat is a real thing, and by extension thermodynamic entropy is also a real thing.
Shannon entropy is a property of a probability distribution over some set of possible values for the random variable , defined as . It tells us how much information we’re missing about . In other words, how much information (in bits) we gain by finding out the exact value of given some prior beliefs described by .
Are they related? Yes. In thermodynamic equilibrium[1] at least. In equilibrium, thermodynamic entropy is a special case of Shannon entropy: the Shannon entropy of a particular distribution over possible states of a physical system.
In equilibrium, the thermodynamic entropy of a system is the Shannon entropy of a probability distribution over possible microstates of the system[2]. A microstate is a total specification of everything you could ever know about that system. Everything you could hope to measure about it, even in principle, down to the position, momentum, charge etc. of each particle. The space of possible microstates is usually called the phase space.
Irritatingly, the literature tends not to say much about what defines the distribution over phase space. You just find phrases like “the probability of microstate ” with no context. Given what? According to who? There are (broadly speaking) two accepted ways of thinking about what this distribution should look like. They both lead to a Shannon entropy that coincides with the thermodynamic entropy in equilibrium.
What does probability mean in equilibrium?
Content warning: the frequentist interpretation of probability.
The two concepts of probability are; how often a trajectory moves through a particular state, and what the likelihood is of finding the system in that state given macroscopic constraints.
The “scientific view”[3]. In equilibrium, systems are approximately ergodic. For our purposes, this means that the system will follow some chaotic trajectory that visits all of the points in phase space, but visits some regions of the space more frequently than others[4]. The relative rates of visits to different microstates are constant over time, so we can define to be the proportion of time that the system spends in microstate . Another way of phrasing it could be: if you measure many times (without disturbing it) the empirical distribution over measured ’s would tend towards . So, yea, a frequentist interpretation.
Fundementally is the result of the external macroscopic constraints on the system, a.k.a. the macrostate. The macrostate can specify things like: the volume it’s allowed to occupy, the temperature and pressure of its surroundings, the presence and strength of a magnetic field. Or you could just phrase it as “how the system is set up in your experiment”. The laws of statistical mechanics dictate how to determine given the macrostate. Defining it this way, feels like a nice objective property of the system.
The “subjectivist view”. When setting up experiments on some system of interest, we know the makeup of the system and the macroscopic constraints on that system (the macrostate). But we lack knowledge of the microscopic details (the microstate). It turns out that there is a uniquely reasonable Bayesian way of building a distribution over microstates given the macrostate. This basically comes from starting with a maximally non-informative prior (all accessible microstates are equally likely), then updating on each of the external constraints. For example, the Boltzmann distribution [5] is simply the result of updating on the knowledge of an average energy over many measurements.
If you build according to either of these two philosophies for a system in thermodynamic equilibrium, the Shannon entropy of is related to the thermodynamic entropy via [6]. is the Boltzmann constant. It can be thought of as either how chaotic the system’s trajectory through phase space is, or how much information about the system you’re missing if you only know the macroscopic constraints.
What does probability mean outside of equilibrium?
Memory registers, the systems we care about here, are not in equilibrium. When we go outside of equilibrium, things get less clear. Outside of equilibrium the two ways of defining thermodynamic entropy (scientific and subjective) come apart and result in distinct quantities (we’ll see how this happens below). But if we remain careful about how we use both of these quantities, we can still say physically meaningful things in some non-equilibrium conditions. From Thermodynamics of Information:
The definition of entropy for non-equilibrium states has been controversial for many years. Although equilibrium thermodynamic entropy has been successfully used in some non-equilibrium situations, it is not yet clear how to define a physically meaningful entropy for generic non-equilibrium states. [...] However, recent developments in stochastic thermodynamics rigorously show that Shannon entropy has a clear physical meaning in certain situations; namely, it determines the energetics of non-equilibrium processes for systems coupled to one or more thermodynamic reservoirs.
We can model a memory register to be coupled to a reservoir (which just needs to be something with a constant well-defined temperature, like the surrounding air). So some kind of Shannon entropy can continue to have physical meaning in registers, but its relationship with thermodynamic entropy is more complicated than in the equilibrium case.
A big reason that Shannon entropy can continue to be meaningful outside of equilibrium is that it continues to follow the second law of thermodynamics.
The second law for any Shannon entropy
The Shannon entropy for some arbitrary description of a physical system must increase over time. This is a slightly generalized version of the second law of thermodynamics. Here is an intuitive argument for why this is true.
Imagine you were an almost perfect Laplace’s demon. You have an astronomical amount of compute and know all the laws of physics. So given some exact microstate (an “initial condition”), you could run a simulation that tells you exactly what microstate it will be in at some later time. You’re studying some isolated gas of particles. You’re only “almost perfect” because you can store only a finite amount of information, say, you can only know the position of each particle to a trillion decimal places. Imagine you’re missing some information from your initial condition. You know the (basically) exact position and momentum of all of the particles except one rogue particle that you have some uncertainty about. Your missing knowledge of this particle corresponds to some small Shannon entropy.
You want to find out the microstate of this gas at some later point in time, so you take your almost complete initial state description and use it as input to the simulation. As the simulation runs, is the amount of information you know about the system going to increase or decrease? Over time, the chance that the rogue particle could bump into other particles makes the other particle’s trajectories uncertain too. Then the new uncertain particles could bump into more particles, making their trajectories also uncertain. Uncertainty spreads like a virus. After not long, the Shannon entropy of your updated probability distribution would have grown.
Figure 1: An almost perfect Laplace’s demon keeping track of the positions of each particle in a gas. At stage 1 there is uncertainty over the direction of travel of the particle labelled (1), while the rest are perfectly known. At stage 2 there are a number of particles (labelled (2)) that may or may not have collided with the particle labelled (1) given the initial uncertainty over (1). At stage 3 even more particles end up on uncertain trajectories (labelled (3)) due to possible collisions with particles labelled (1) or (2). The result is a growing Shannon entropy.
Strictly speaking, if you were keeping track of the particles to infinite precision, your uncertainty would actually stay the same. Since the information has not disappeared, it’s just become hidden in infinitesimally delicate correlations between the particles (this is Liouville’s theorem). But since you can’t keep track of an infinite amount of correlations, your uncertainty will increase!
This example is a bit far-fetched, but hopefully you can get enough intuition from it to see that uncertainty can only grow over time for any situation. In the case of thermodynamic entropy in equilibrium; the distribution of interest is over microstates given external constraints. We can use the laws of thermodynamics to update the distribution over time, but the Shannon entropy of that distribution (and by extension thermodynamic entropy) can only increase. But this argument above does not rely on equilibrium, so it could apply to any arbitrary distribution over microstates, as long as you update according to the correct physical laws.
Now we know enough things to introduce a model of a memory register.
Modelling memory registers
Following in the footsteps of Landauer’s original paper, I’ll describe a generic model of a 1-bit memory register that captures the physics of Landauer’s principle. So, what makes a 1-bit register a 1-bit register? It must maintain some state that is persistently one of two possible values. Or, more precisely; there are two regions of phase space it can occupy, and once it’s in one of the regions it will stay in that region for a long time. Once you push it into one or the other; it’s allowed to take some chaotic trajectory within that region, but it’s stuck in that region. One region we interpret as a “0”, and the other as a “1”.
Figure 2: (a): An ergodic trajectory (thermal fluctuations) through phase space. If left for infinitely long, the whole phase space would be covered by the trajectory. (b) Two locally ergodic trajectories in an ergodicity-broken system. The particle can take a chaotic trajectory through one of the two separated regions, but cannot move between regions.
To write a bit to the register, you poke the system in such a way that it gets stuck in one of the two regions. If the system wasn’t built to become stuck in one of the regions, thermal fluctuations would make it jump between regions, meaning that the bit would constantly flip. Not much use. This separation of regions takes the system out of equilibrium. It also breaks ergodicity: the system no longer takes a trajectory through all of the possible microstates, it totally neglects one of the two regions. However, it can be said that ergodicity is locally preserved within the region it’s stuck in.
To anchor this description in the words of more qualified people (from Thermodynamics of Information again[7]):
To function as a memory, a system must have several, distinguishable ‘informational states’ in which the information is stored. For reliable information storage without degradation, these states must have long lifetimes, be robust against environmental noise and be possible under the same external constraints. From the point of view of statistical mechanics, these requirements demand that for a system with microstates to function as a memory, it has to possess multiple, distinct metastable states under its Hamiltonian . In other words, ergodicity must be broken—or effectively broken for the timescale for which the memory is reliable. In practice, this means its phase space is split into ergodic regions, , one for each informational state .
Here is the generic model that Landauer used to study these properties. He studied a single particle restricted to move in a single dimension , with an external force acting on it creating a bistable potential well—two identical minima of energy (see fig. 3)[8]. In this model, the set of microstates is simply the set of positions the particle can have, and the macrostate is the functional form of . Over time, the particle will dissipate energy into its surroundings until it reaches the bottom of one of the two wells. Thermal fluctuations will cause it to wobble slightly away from the exact minimum, creating a chaotic trajectory like that of fig. 2b. The energy barrier between the two wells is high enough to prevent thermal fluctuations from pushing it over from one well to the other (for a long time at least). So even though the particle’s trajectory is chaotic within a given well, it is predictably stuck within that well.
Figure 3: The bistable potential well . (a) Also shown is the probability distribution over possible locations of the particle given an equal chance of it being in either well. (b) Also shown is , the distribution conditional on the particle being stuck in well 0. (c) Also shown is , the distribution conditional on the particle being stuck in well 1.
The barrier breaks ergodicity, and the neighbourhood around the bottom of the two wells represents the two regions of phase space where the system can get stuck. However, if we only consider the single well containing the particle then the system can be regarded as ergodic.
Entropy in memory registers
The way people use the word entropy in situations like these can vary. I’ll try to keep to my own consistent way of using it here. The breaking of ergodicity in this system causes the two views of thermodynamic entropy (scientific and subjective) to diverge, so we need some new names.
One concept of entropy (call it Fluctuation Entropy) is aligned with the “scientific view”. Fluctuation entropy is the Shannon entropy of the distribution defined by the amount of time the particle spends in each microstate . When the particle is stuck in one of the wells, the distribution “knows” which well the particle is in, but has uncertainty over within that well due to thermal fluctuations.
There is another concept of entropy (call it Knowledge Entropy) that comes from the “subjective view”. Knowledge Entropy is the Shannon entropy of the rational distribution over microstates given the external constraints, which in this case is the shape of the bistable potential well (the function , a.k.a. the Hamiltonian). Given this shape, there are two sources of uncertainty—which well the particle is in, and then where it is within the well on its chaotic trajectory. The Shannon entropy of a distribution over random variable conditional on the value of another random variable can be written as . If we assume that totally specifies the state, i.e., , the above can be rearranged into
(eq. 1)
Consider to be the position of the particle and to label the well that the particle is in. is the “logical information” stored in the system, and is the microscopic information (conditional on the particle being in a given well). There isn’t much you can learn about from the external constraints alone, it depends on what happened to the system in the past. In the absence of any such information, it seems reasonable to assign due to the symmetry of the system (but we’ll circle back on this decision). In this case, ; there is 1 bit of logical information that the distribution doesn’t know.
Converse to the case of , the distribution can be predicted from the external constraints alone, it will predictably settle into a thermodynamic distribution (for example the Boltzmann distribution) regardless of what happened in the past.
So here’s the deal. Knowledge Entropy = . Fluctuation Entropy = . And call the Logical Entropy. So eq. 1 says that Knowledge Entropy = Logical Entropy + Fluctuation Entropy. In the literature, when people just say “entropy” they can mean any of these three quantities.
The Second Law in Memory Registers
Which of these types of entropy does the second law apply to—which of them are required to increase with time?
The intuitive argument for the second law I gave above applies to knowledge entropy. Given some incomplete description of an isolated physical system, the amount of information that you’re missing about the system can only increase as it evolves in time.
The same doesn’t necessarily apply to logical entropy or fluctuation entropy by themselves. They can both be reduced because you can exchange one for the other. This can be seen by starting with the bistable potential well in our model, and gradually removing the barrier until it becomes a single well with a single energy minimum. The logical entropy is then reduced to zero, there is only one stable state it can occupy. The change in logical entropy is . There must be a compensating increase in fluctuation entropy. The second law for knowledge entropy demands that , therefore by eq. 1 we get . The fluctuation entropy must increase by at least as much as the logical entropy decreased. You could also do the reverse: gradually raise the potential well again, turning fluctuation entropy back into logical entropy.
The upshot is: these two kinds of entropy can be converted into each other. They are two sides of the same coin, much like what Einstein showed about matter and energy, or what Maxwell showed about electricity and magnetism. As Landauer said: “information is physical”—information (logical entropy) can be exchanged with thermal fluctuations (fluctuation entropy) and vice versa.
Erasing the bit
We’re now in a position to show why Landauer’s principle is true, and have the language to state what it’s really saying. Consider sending our model of the register through the process shown in fig. 4.
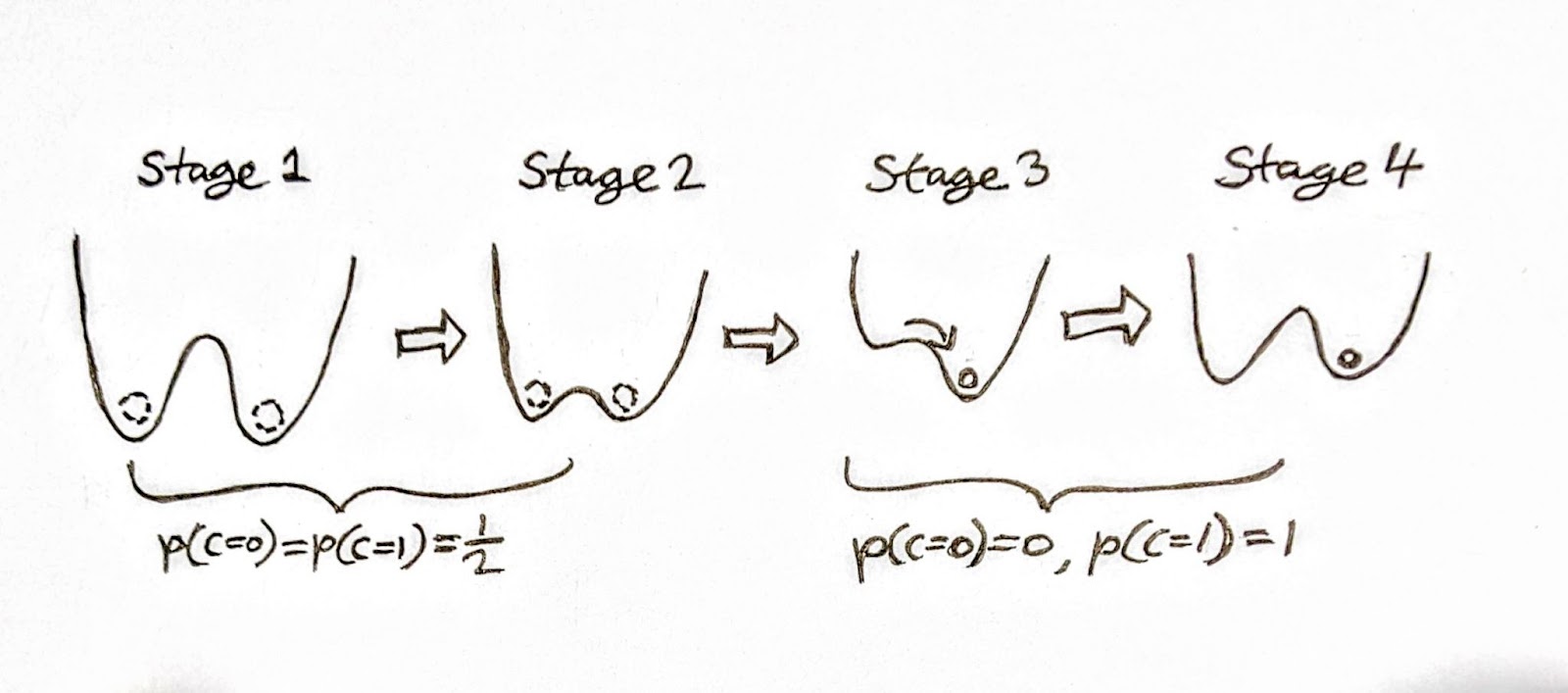
Figure 4: Erasure process of a memory register. Stage 1: two wells with . Stage 2: The potential barrier is lowered to allow thermal fluctuations between the wells. Stage 3: Tilt applied to force particle into well 1. Stage 4: Tilt removed and barrier raised back to initial height. The shape of the potential is the same as in 1 but now and .
Compare the situations in stages 1 and 4. There has been a reduction in logical entropy , since the particle has gone from possibly being in either well to definitely being in well 1. There is no change in fluctuation entropy; in stage 1 the fluctuation entropy (averaged over logical states) is identical to the fluctuation entropy in stage 4 since the wells are identical. Therefore the change in knowledge entropy of the register is .
Now let’s think about the surroundings, , of the register. The total knowledge entropy of the register and its surroundings must be , so the knowledge entropy of its surroundings must increase by the same amount as the register’s knowledge entropy decreases: . Since we’re assuming that is a heat reservoir (say, just the surrounding air), then is in thermodynamic equilibrium. For a system in thermodynamic equilibrium: knowledge entropy is simply the thermodynamic entropy. Therefore the thermodynamic entropy of must increase by . Logical entropy has been turned into thermodynamic entropy.
As per the definition of thermodynamic entropy, this increase comes with an associated creation of heat energy , where is the temperature of . Due to conservation of energy, this requires that at least that much energy must have been spent on causing the transition from stage 1 to 4 in fig. 4.
Hence we arrive at Landauer’s principle for this model, which can be stated as: if one expects a 50% chance of the particle being in each of the wells, the expected value of heat emitted by the register between stages 1 and 4 in fig. 4 is at least and the expected energy required for this operation is at least .
Interpreting Landauer’s principle
The bistable potential well captures the essential features of the erasure of bits in memory registers; if you try building a more complicated model and remove a persistent bit of information, you’ll find at least that amount of heat being dissipated on average.
Reading about the experimental confirmations of this principle helped me solidify what it was saying. In Berút et. al. for example; they physically implemented the situation described above using an overdamped colloidal particle experiencing a bistable potential well made of lasers. They measured the energy required to carry out the erasure procedure in fig. 4 many times, while including uncertainty over the logical bit by starting with the particle in well 0 half of the time and well 1 the other half. They found that, in the limit of minimum possible thermodynamic entropy production, the energy required, averaged across all trials, was .
Figure 5: From Berút et. al.: The average heat released by the erasure procedure against protocol duration . is a proxy for energy efficiency; the limit is the adiabatic limit where the minimum possible heat is dissipated. The dotted line shows Landauer’s limit.
This averaging over trials is averaging over two different sources of variation; thermal fluctuations and differences in logical states. The principle is about the amount of heat released averaged over logical states rather than saying that a particular heat is released on every erasure. This cleared up a lot of my confusion. The principle isn’t about a connection between a subjective probability distribution and a tangible physical process. Instead, there is a connection between a subjective probability distribution and a physical quantity averaged over that subjective probability distribution.
Let’s swing back to the choice of distribution over the logical state . We can in principle choose any distribution over that we like. If we chose some other, more informative distribution, then we’d have . The average heat emitted given this is then . straightforwardly represents how much useful information the system stores, in the manner usually meant in information theory. If you have some knowledge of in the form of a distribution over , the Shannon entropy of that distribution tells you how much information you stand to gain by measuring the contents of the register. So this more general version of the principle says: the amount of energy you can expect to spend is proportional to the amount of logical information you delete. You can turn information into thermodynamic entropy.
When we’re considering the energy use of many computations, including many erasures of bits, it seems reasonable to assume that the erased bits will roughly be equally split between 0 and 1. Hence Landauer’s principle applies well to an aggregation of many computations. Over many FLOPs, if the number of bit erasures is roughly the same for each FLOP, then the energy-use-per-FLOP is proportional to .
Conclusion
Hopefully, this has clarified the connection between Shannon (or “logical” or “computational”) entropy and thermodynamic entropy, and in the process elucidated why Landauer’s principle is true. Computationally useful information and thermodynamic entropy are “on average” exchangeable. Does this say something deep about computation or cognition? Dunno.
- ^
A definition of equilibrium precise enough for our purposes is: there are no gradients in density, pressure or temperature and therefore no net macroscopic flows of matter or of energy. An example is the air in the room you’re in now: it makes sense to talk about the temperature of the room since the temperature is uniform throughout the room, similarly for air pressure and other stuff.
- ^
Up to a multiplication: Thermodynamic entropy where is the Boltzmann constant.
- ^
Here I’m using the language of Lavis 2001.
- ^
Taking some mild liberties in the definition here. By “chaotic” I just mean a trajectory that is messy enough that it’s practically impossible to precisely predict the trajectory.
- ^
is the energy of microstate , is the Boltzmann constant and is the temperature of the system and its surroundings.
- ^
This is strictly speaking only true if the ergodic hypothesis is true, which I assume throughout this article.
- ^
Notation changed to agree with the notation in this article.
- ^
For those who haven’t read much physics but know machine learning, these diagrams are very analogous to a loss function over a space of parameters; energy ~ loss function and parameters ~ microstates. Physical things usually tend towards their lowest energy state, so they roll down the hills of this landscape to end up in one of the minema.
I think you’re glossing over the best part of the story here! If you know that the system is in a phase-space region of volume V now, then in an hour or a year you will know (in principle) that the system is in a (different) phase-space region of the same volume V. (Cf. “Liouville’s theorem”.) So in a straightforward sense, your uncertainty doesn’t go up as the system evolves in time.
However, your information about the system gradually converts from “actionable” to “not actionable”, as you will eventually have information about complicated correlations involving huge numbers of particles, e.g. “if the 17th decimal digit of the velocity of particle 79 is 4, then the 19th decimal place of the velocity of particle 857 is 6”. The phase-space volume V will be this beautiful, horrible mess of infinitesimally-fine tendrils arbitrarily close to every point in phase space. You can’t do anything with this information that you have about the system, so you might as well forget that information altogether. And that’s how entropy goes up.
Thanks for the comment, this is indeed an important component! I’ve added a couple of sentences pointing in this direction.
This sounds to me more like “setting” a memory register than “erasing” it?
That is, you go from
The register is in a state that you can measure. You don’t currently know what state. Could be that someone deliberately put it in that state so that you’d learn something when you measure it.
to
The register is in a state that you know because you put it there. Someone else, or yourself in future, can measure it to find what value you put there.
So yes, you’ve erased the previous value, but you’ve also put in your own.
And I think the “set” part of this feels more fundamental. For one, because you can’t set it without erasing but you presumably can erase without setting. (Skip stage 3, just lower the barrier and raise it again, you can’t predict what well it’s now in. Someone can measure, but you can’t transmit information to them.) And for two, because someone else might have already done that, so there might not have actually been a “useful bit” to erase in the first place.
Am I understanding this correctly?
Yea, I think you’re hitting on a weird duality between setting and erasing here. I think I agree that setting is more fundamental than erasing. I suppose when talking about energy expenditure of computation, each set bit must be erased in the long run, so they’re interchangeable in that sense.
Great article! It clarified the concepts a lot for me.
I think you’re missing a Δ in front of the H(C) here. (Entropy cannot be negative.)
Fixed, thanks!
If X and C are which face is up for two different fair coins, H(X) = H(C) = −1. But H(X|C)?=0 ? I think this works out fine for your case because (a) I(X,C) = H(C): the mutual information between C (which well you’re in) and X (where you are) is the entropy of C, (b) H(C|X) = 0: once you know where you are, you know which well you’re in, and, relatedly (c) H(X,C) = H(X): the entropy of the joint distribution just is the entropy over X.
Sorry for the delay. As both you and TheMcDouglas have mentioned; yea, this relies on $H(C|X) = 0$. The way I’ve worded it above is somewhere between misleading and wrong, have modified. Thanks for pointing this out!
Yeah I think the key point here more generally (I might be getting this wrong) is that C represents some partial state of knowledge about X, i.e. macro rather than micro-state knowledge. In other words it’s a (non-bijective) function of X. That’s why (b) is true, and the equation holds.
You probably mean “while not in equilibrium”
fixed, thanks!
Just to clarify, this is the expected/average information, right?
If we observe X = x for some fixed x, we get exactly -log_2 p(x) bits of information, and entropy is the average of this information gain taken over the distribution p(x). For example, suppose X ~ Bern(0.5). Then we have a 50% chance of getting a 0, and thus gaining -log2(0.5) = 1 bit of information, and a 50% chance of getting a 1, and thus gaining -log2(0.5) = 1 bits of information, meaning we will necessarily gain 1 bit of information upon finding the value of X. But, if X ~ Bern(0.25) instead, then finding out X is 1 gives -log2(0.25) = 2 bits of information and finding out X is 0 gives log2(0.75) bits of information. So, on average, we expect to gain (0.25)(-log2(0.25)) + (0.75)(-log2(0.75)) bits of information.
Is my understanding of this correct?
I still have one point that is not really clear: why 1 bit information (Shannon entropy (H)) is equal to 1 bit (k ln2) thermodynamic entropy (S). I have zero background in thermodynamics, and the thermodynamic entropy definition is so hard to interpret (what is a microstate, quantitatively speaking?)
what a great and insightful article. thank you
I always had a question about what would be the heat loss (entropy increase) for a situation where you might have some prior knowledge and just update the distribution, like in Bayesian setting. these lines clarifies the question I think. your heat loss Can be less than one bit in a case of updating prior believes.
can one add that if you are switching the wells, (updating a very bad prior believe), you are spending more energy? Instead of entropy, some kind of information distance or KL will determine the cost in this case
Very clear writeup—thank you for doing it. (I”m not sure if it says anything much about cognition either, but hey).
It would be great to see this incorporated in a Wikipedia article, but that’s probably an uphill battle.