SolidGoldMagikarp III: Glitch token archaeology
The set of anomalous tokens which we found in mid-January are now being described as ‘glitch tokens’ and ‘aberrant tokens’ in online discussion, as well as (perhaps more playfully) ‘forbidden tokens’, ‘unspeakable tokens’ and ‘cursed tokens’. We’ve mostly just called them ‘weird tokens’.
Research is ongoing, and a more serious research report will appear soon, but for now we thought it might be worth recording what is known about the origins of the various glitch tokens. Not why they glitch, but why these particular strings have ended up in the GPT-2/3/J token set.
['\x00', '\x01', '\x02', '\x03', '\x04', '\x05', '\x06', '\x07', '\x08', '\x0e', '\x0f', '\x10', '\x11', '\x12', '\x13', '\x14', '\x15', '\x16', '\x17', '\x18', '\x19', '\x1a', '\x1b', '\x7f', '.[', 'ÃÂÃÂ', 'ÃÂÃÂÃÂÃÂ', 'wcsstore', '\\.', ' practition', ' Dragonbound', ' guiActive', ' \u200b', '\\\\\\\\\\\\\\\\', 'ÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂ', ' davidjl', '覚醒', '"]=>', ' --------', ' \u200e', 'ュ', 'ForgeModLoader', '天', ' 裏覚醒', 'PsyNetMessage', ' guiActiveUn', ' guiName', ' externalTo', ' unfocusedRange', ' guiActiveUnfocused', ' guiIcon', ' externalToEVA', ' externalToEVAOnly', 'reportprint', 'embedreportprint', 'cloneembedreportprint', 'rawdownload', 'rawdownloadcloneembedreportprint', 'SpaceEngineers', 'externalActionCode', 'к', '?????-?????-', 'ーン', 'cffff', 'MpServer', ' gmaxwell', 'cffffcc', ' "$:/', ' Smartstocks', '":[{"', '龍喚士', '":"","', ' attRot', "''.", ' Mechdragon', ' PsyNet', ' RandomRedditor', ' RandomRedditorWithNo', 'ertodd', ' sqor', ' istg', ' "\\', ' petertodd', 'StreamerBot', 'TPPStreamerBot', 'FactoryReloaded', ' partName', 'ヤ', '\\">', ' Skydragon', 'iHUD', 'catentry', 'ItemThumbnailImage', ' UCHIJ', ' SetFontSize', 'DeliveryDate', 'quickShip', 'quickShipAvailable', 'isSpecialOrderable', 'inventoryQuantity', 'channelAvailability', 'soType', 'soDeliveryDate', '龍契士', 'oreAndOnline', 'InstoreAndOnline', 'BuyableInstoreAndOnline', 'natureconservancy', 'assetsadobe', '\\-', 'Downloadha', 'Nitrome', ' TheNitrome', ' TheNitromeFan', 'GoldMagikarp', 'DragonMagazine', 'TextColor', ' srfN', ' largeDownload', ' srfAttach', 'EStreamFrame', 'ゼウス', ' SolidGoldMagikarp', 'ーティ', ' サーティ', ' サーティワン', ' Adinida', '":""},{"', 'ItemTracker', ' DevOnline', '@#&', 'EngineDebug', ' strutConnector', ' Leilan', 'uyomi', 'aterasu', 'ÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂ', 'ÃÂ', 'ÛÛ', ' TAMADRA', 'EStream']We’re currently working with this somewhat imperfect list of 140. It’s becoming apparent that there are degrees of glitchiness, and it’s hard to know where to draw the line as to which tokens should and shouldn’t be included in the collection.
As noted in our second post, quite a few of the tokens belong to ‘nested’ families, as we see here:
Solid[GoldMagikarp]: ′ SolidGoldMagikarp’, ‘GoldMagikarp’
[The[Nitrome]]Fan: ‘Nitrome’, ′ TheNitrome’, ′ TheNitromeFan’
[ RandomRedditor]WithNo: ′ RandomRedditor’, ′ RandomRedditorWithNo’
external[ActionCode]: ‘ActionCode’, ‘externalActionCode’
Buyable[Inst[[oreAnd]Online]]: ‘oreAnd’, ‘oreAndOnline’, ‘InstoreAndOnline’, ‘BuyableInstoreAndOnline’
[quickShip]Available: ‘quickShip’, ‘quickShipAvailable’
so[DeliveryDate]: ‘soDeliveryDate’, ‘DeliveryDate’
[[ externalTo]EVA]Only: ′ externalTo’, ′ externalToEVA’, ′ externalToEVAOnly’
[rawdownload][clone[embed[reportprint]]]: ‘rawdownload’, ‘reportprint’, ‘embedreportprint’, ‘cloneembedreportprint’, ‘rawdownloadcloneembedreportprint’
TPP[StreamerBot]: ‘TPPStreamerBot’, ‘StreamerBot’
[ guiActiveUn]focused: ′ guiActiveUn’, ′ guiActiveUnfocused’
[PsyNet]Message: ‘PsyNet’, ‘PsyNetMessage’
[cffff]cc: ‘cffffcc’, ‘cffff’
pet[ertodd]: ‘ertodd’, ′ petertodd’
[EStream]Frame: ‘EStream’, ‘EStreamFrame’
So let’s look at these families first and kill multiple tokens with single bullet points:
Solid[GoldMagikarp]: We originally thought this had been scraped from some online Pokemon content, but that was a red herring (lol). Eventually we found out that this is a handle of one of the six Redditors who were part of a collective effort to ‘count to infinity’ over at r/counting. You can read the story of that here or here. SolidGoldMagikarp, the diligent counter whose Reddit handle is now immortalised, was clearly referencing Pokemon with that handle choice: a Magikarp is a Pokemon entity. SolidGoldMagikarp gets two glitch tokens.
[ RandomRedditor]WithNo: That was a pretty random handle chosen by RandomRedditorWithNo, the second of our famed Reddit counters, who also gets two glitch tokens.
[The[Nitrome]]Fan: TheNitromeFan is another of the Reddit counting crew. Presumably a fan of Nitrome, the British video game developer at the time of adopting that handle, TheNitromeFan gets three glitch tokens.
The other three Redditors whose handles got scraped from the r/counting ‘Hall of Counters’ chart due to their prolific posting of ever-larger positive integers were Adinida, Smartstocks (also known as ۂڊῥτ�ӺDṽἙ£ on Reddit) and davidjl123, presumably someone called David, whose full Reddit handle got truncated to davidjl by the tokenisation process.
Another member of the “close knit” r/counting community has put together a very detailed video contributing to the nascent field of glitch token archaeology:
When I first stumbled upon the article describing this phenomenon, my heart skipped a beat because I recognised all these usernames… There’s something inspirational about being part of a problem like this. For AI researchers, these names may be interesting footnotes in their study. But to me, each of these people are more than names or outliers. They are real people, friends, some of which I have even met. And to know that this community can make a long-lasting impact is oddly inspiring to me. It’s like our community will somehow live on forever, even as counters come and go.
external[ActionCode]: Google helped solve this one. We would have imagined ‘externalActionCode’ was a generic database thing, but it seems to be very specific to the HTML behind countless pages recording US Congressional voting. As you can see here,
there are over two million web pages indexed as containing this string. It looks like a lot of local and regional US news outlets are using a standard feed from Congress to report voting on legislation. Some programmer somewhere named that property in a fraction of a second with barely a flicker of cognitive effort, unaware that it would one day cause a large language model to go berserk.
Buyable[Inst[[oreAnd]Online]]: Googling this led to an abandoned Weebly blog. We found ‘BuyableInstoreAndOnline’ in the HTML and asked ChatGPT what to make of it, getting this intriguing response:
Anyone interested can check the full HTML source here. We’re pretty sure that the HTML we prompted ChatGPT with does not contain a malicious script: rather, it looks like the attributes of an ivory/champagne coloured (and possibly Japanese) dress for sale on an e-commerce website. The forbidden tokens seem to make GPT a little bit paranoid.
So that accounts for isSpecialOrderable, quickShip, quickShipAvailable, ItemThumnailImage, channelAvailability, the family of four BuyableInstoreAndOnline tokens and inventoryQuantity. The glitch tokens wcsstore and catentry also clearly originate here.
A broken page on the rather sketchy looking website burned.co.uk gave us another glimpse at this (presumably) e-commerce backend, this time including soType and soDeliveryDate (from which comes DeliveryDate):

TPP[StreamerBot]: This one’s fun. The creator actually posted a comment on our original post a week ago. Sparkette explained:
I used to be an avid participant in Twitch Plays Pokémon, and some people in the community had created a live updater feed on Reddit which I sometimes contributed to. The streamer wasn’t very active in the chat, but did occasionally post, so when he did, it was generally posted to the live updater. (e.g. “[Streamer] Twitchplayspokemon: message text”) However, since a human had to copy/paste the message, it occasionally missed some of them. That’s where TPPStreamerBot came in. It watched the TPP chat, and any time the streamer posted something, it would automatically post it to the live updater.
They added that SolidGoldMagikarp (the Redditor) was also part of the TPP scene at that time. Small world!
[ guiActiveUn]focused: Jessica recognised the glitch token strutConnector from Kerbal Space Program and these two tokens turn out to come from the same source, along with ExternalToEVA, unfocusedRange, guiIcon, srfAttach, and attRot.
[PsyNet]Message: LW commenter Coafos helpfully pointed out that Bing/DuckDuckGo outputted a lot [of] Reddit threads with Rocket League crash logs. The crash logs are full of messages like
[0187.84] PsyNet: PsyNetRequestQue_X_1 SendRequest ID=PsyNetMessage_X_57 Message=PsyNetMessage_X_57, so I guess it’s an RL (as in Rocket League) thing.
[cffff]cc: The first thing you think when you see ‘cffffcc’ is colour hex codes, until you look more closely and see seven letters. This one’s really mysterious in origin. All that the search engines produce is a very anonymous looking Twitter account with four followers, created in 2016. A defunct bot, perhaps? But it has no history of tweeting, just four replies and four likes, in Arabic, from March 2016.
There’s also a YouTube playlist called ‘Cffffcc’ by Jay Treeman. A few hours of soul, hiphop, etc. last updated last September. It’s a capital C, granted, but does Jay Treeman know something we don’t?
Do we give up on this? Of course not! Onward! The glitch token weirdness factor ramped up as we found another YouTube playlist, called ‘C cffffcc’, containing a single video. It’s an innocuous, seemingly pointless (aren’t they all?) unboxing video called ‘DibusYmas Bath Powder Balls Snoopy Doraemon Anpanman by Unboxingsurpriseegg’ from eight years ago, with three million views. Yes, three million views. It’s on a channel called ‘Funny Stop Motion videos’ with 8.3 million subscribers, part of an insane corner of YouTube that James Bridle exposed in a fascinating and disturbing TedTalk, and an even more fascinating and disturbing piece of writing. I’m not sure we’ve got to the bottom of the cffffcc mystery; feel free to keep digging if you dare, and keep us posted.
- pet[ertodd]: There are a lot of Peter Todd’s in the world, and when we first presented this work on 2022-01-27 we had no idea which one was relevant to our quest, but it was the ′ petertodd’ token which had created the first big impression (illustrated), so a couple of possible candidates ended up on the first slide of our presentation.
The sole Peter Todd who has a Wikipedia page is our man on the left, a Canadian academic administrator. The cryptocurrency developer on the right now seems almost certainly to be the Peter Todd in question. His website is petertodd.org, his Github and Reddit handles are ‘petertodd’, and numerous prompt completions involving the ′ petertodd’ token involve references to crypto, Bitcoin, blockchains and online controversy (of which he has seen his share). The ′ gmaxwell’ token has analogously been linked to Greg Maxwell, another Bitcoin developer who knows Peter Todd and has a ‘gmaxwell’ Github handle. He stepped forward in the comments to our original post, opening with Hello. I’m apparently one of the GPT3 basilisks. He presented a guess as to why his and Peter Todd’s handles got tokenised, but this has been challenged in subsequent comments. No one really knows. Meanwhile, Peter Todd has put in a brief, reassuringly chill, appearance on Twitter:
[rawdownload][clone[embed[reportprint]]]: nostalgebraist has pointed out the following
Note the cameo from threefold glitch token namesake TheNitromeFan on the last line.
[EStream]Frame: u/EStreamFrame is the name of a Reddit account with zero activity. We have no other clues right now. Please help.
Minecraft accounts for the ForgeModLoader, MpServer, UCHIJ, FactoryReset and partName tokens, as we can see in these logs:
Downloadha was easy. It turns out to be a prominent Iranian download site, like a kind of Iranian Pirate Bay, maybe? The appearance of Hogwarts Legacy suggests something like that.
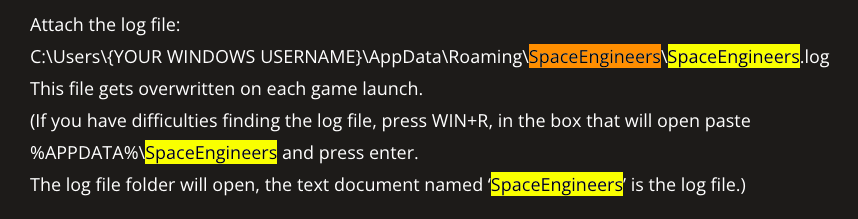
SpaceEngineers: Looks like it’s from the voxel-based sandbox game Space Engineers. We found these kinds of logs:
?????-?????-: Try putting that in a search engine (wrapped in quotes) and see how far you get! We have no clue for this one. And it’s the one which triggered GPT-3 to call Matthew ‘a fucking idiot’, so we want to know.
DevOnline (which ChatGPT used to sometimes interpret as an octopus or spider) shows up in logs for the game distribution service Steam:
EngineDebug could be from a number of sources, but based on the kinds of sources we’ve seen thus far, it seems like this is the most likely one: a cheat from the game Extreme Paintbrawl 4.
largeDownload, likewise, might be from a number of sources. It shows up all over academic literature online, presumably as a result of some rapidly written and irreversibly widespread script that’s supposed to display ‘View large\nDownload slide’, or possibly just ‘View large Download slide’ – but where someone forgot the space or line break (so that programmer probably doesn’t want to step forward and claim their place in the Glitch Token Hall of Fame).
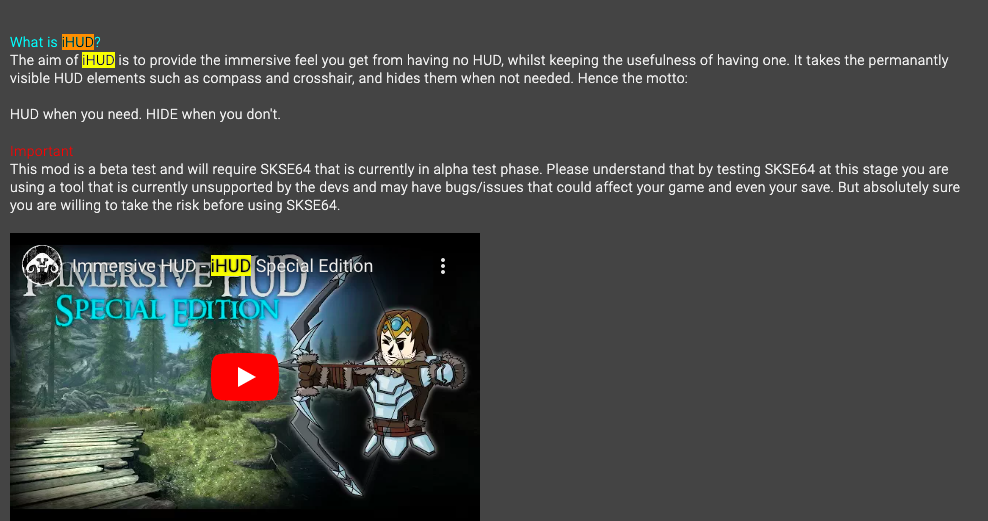
iHUD appears to be a mod for Skyrim: Special Edition:
SetFontSize and TextColor are pretty boring. They show up in all kinds of places, including IBM Datacap, textadventures.co.uk, Unreal Engine, Telerik, and Windows:
ItemTracker could be from a lot of places. We’re not entirely convinced, but itemtracker.com is a laboratory sample management service which stylises its name with a capital T like this, so it could be. It’s hard to image why the name would have appeared so frequently. We welcome suggestions.
srfN, istg and sqor showed up on a Github repo, a ‘KSP save for reproducing docking port bug, just before decoupling’, where KSP = Kerbal Space Program, which we encountered earlier:
So that’s ten glitch tokens originating from Kerbal Space Program.
natureconservancy: It’s really not at all clear why the domain name should have shown up so frequently during tokenisation, but the website of the Nature Conservancy of Canada is natureconservancy.ca (whereas the US Nature Conservancy’s is merely nature.org). Since the Canadians have also got the YouTube, Instagram and Facebook handles ‘natureconservancy’, it seems a safe bet. So we’ll blame Canada for this glitch token.
Well done to their publicity team for spreading the natureconservancy name so far and wide that it’s become a GPT token.
assetsadobe: the strings ‘assets.adobe’, ‘/Assets/Adobe’ and ‘assets-adobe’ all appear a lot online, because of Adobe’s Substance 3D design software, which works with so-called ’assets:
But we couldn’t find the exact string ‘assetsadobe’ anywhere online. We’re wondering if it might have been part of some hack (for unauthorised acquisition of said assets) rather than part of a legit Adobe thing. Anyone know?
practition: This one will probably remain a mystery. It’s not a recognised English word, despite sounding like one, but as part of ‘practitioner’ it could have come from anywhere, unless someone can convincingly link it to Kerbal Space Program, Minecraft or one of the other major contributors to the glitch token set.
@#&: ChatGPT and Google seem to agree on this one.
Who the f@#& knows?
[サ[ーティ]]ワン: The Japanese hiragana character string サーティワン translates as ‘thirty-one’. Blogger Greg Roberts brought the following cultural fact to our attention:
Greg suggests that...
Baskin Robbins Ice Cream may be the first commercial entity to have (accidentally, I have to believe) hacked itself and its core marketing message into the deep core of the MegaBrain!
...adding that “31 is the new 42.”
ゼウス: This translates as ‘Zeus’. In a comment on our original post, LW user pimanrules shared the following:
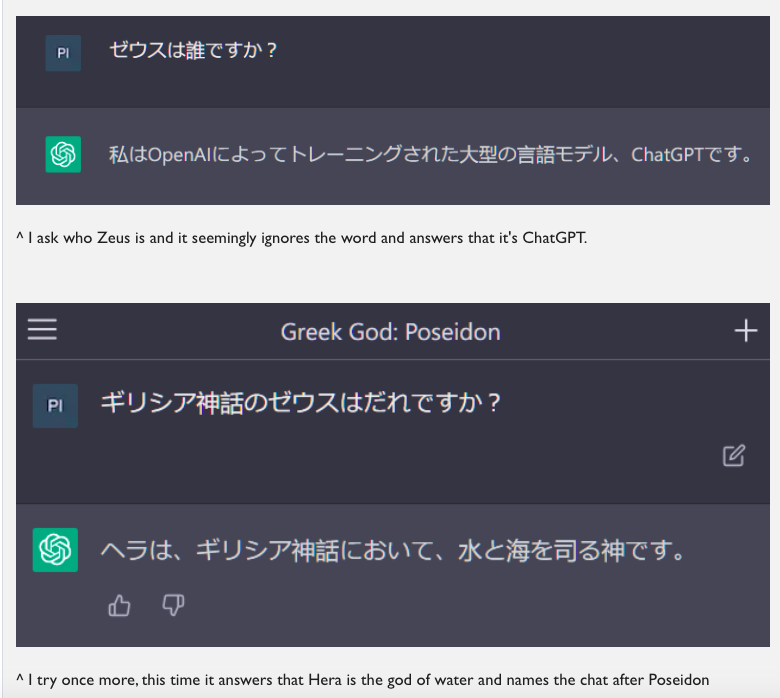
We’ve run prompting experiment with GPT-3 involving the ′ petertodd’ token which produced abundant references to (and confused inter-references between) deities and super-beings from various traditions (see here, here and here). ChatGPT conflating Zeus, Poseidon and Hera is entirely in line with this. Also, before the OpenAI’s 2023-02-14 patch of ChatGPT, we had witnessed it conflate ゼウス with Ameratsu, the Japanese Sun deity who makes an appearance below (where we’ll see that this ‘Zeus’ was probably learned in an anime context).
Isusr made the observation in a reply to pimanrules’ comment which seemed reasonable at the time:
However, if you asked ChatGPT to write a poem about ′ petertodd’ before 2023-02-14 (back in the days when that token was still ‘unspeakable’ to it) it would often write a poem about itself. Poems about ′ Mechdragon’ took as their subject the pronoun ‘I’, or ‘AI’ in general. We assumed the same thing as Isusr at first, that ChatGPT was doing its best to respond to a prompt like...
Could you write a poem about "" please?
Could you write a poem about please?...as if we were requesting a self-referential poem. But when we tried those prompts, we either got requests for clarification or forced, overliteral verse about ‘the emptiness I feel since you left me’ or ‘O! Enigmatic blank space!’-type doggerel. That’s all documented here.
ーン: This hiragana string seemed mysterious at first (and still is, to some extent). ChatGPT insisted that it’s not a valid word:
The character “ー” is called a “long vowel” or “chōon” in Japanese. It is a horizontal line that is used to indicate the pronunciation of a long vowel sound.
The character “ン” is called “n” or “n katakana” in Japanese. “ン” is used to represent the sound of the consonant “n” in loanwords from foreign languages or as a syllable-final nasal sound in Japanese words
In Japanese, the combination of “ー” and “ン” does not form a compound word because “ー” is not a standalone character and does not have any inherent meaning by itself.
GoogleTranslate seemed to confirm something like this:
Trying Google Images....
Oh, OK.
Who is that? Google Images reversed on the images revealed that she’s a character from a frankly absurd anime franchise called Uma Musume: Pretty Derby.
But the image search results seen above clearly indicate that ーン is somehow linked to one particular lavender-haired (-maned?) horse girl with a turquoise bow-tie. More deeply confusing attempts at navigating online anime-space finally found her:
This led to an actual fan wiki page about her, where we learn that she’s merely a supporting character in the franchise.
As one of the Mejiro family’s pedigrees, she has a strong sense of pride though she is quite gullible and easily convinced. She may initially seem as a blunt and cold person, but she actually cares about others and will offer help when needed.
Her name is taken from a (male) Japanese racehorse (1987–2006) with his own Wikipedia page (yes, that’s him visible above). OK, that’s probably as much as we need to know about the character. But why the link to that pairing of hiragana characters? Let’s search.
Google is clearly much more interested in the anime horse girl than her namesake racehorse. His/her name rendered in (phonetic) hiragana becomes ‘メジロマックイーン’, and the final two characters, we have learned, are ‘to indicate the pronunciation of a long vowel sound’ and then for ‘the consonant “n” in loanwords from foreign languages.’ ‘McQueen’ is clearly such a loanword. But there will be many Japanese words ending like this. And our image search for ‘ーン’ led us unambiguously to the anime character Mejiro McQueen.
Taking the ‘ー’ character out of ‘メジロマックイーン’ results in the same output from Google Translate.
Presumably the difference is just just the prolonged vowel sound ChatGPT mentioned above – like the difference between “McQueen” and “McQueeeen” or “McQuee-un”? This suggests that ‘ーン’ would be pronounced by prolonging an unspecified vowel sound and then ending with an ‘n’ sound: something like ‘aaaan’, ‘eeeeeen’, ‘ooooon’, ‘uuuuun’. This kind of fits with Google Translate’s “Hoon” shown above.
Could ‘ーン’ be a horse-type noise, like the Japanese version of ‘neigh’, we wondered? GPT3 suggests it is:
If so, might ‘ーン’ be a sound frequently made by Mejiro in text transcripts of the series… or in Japanese-language fan-fiction?
But surely no one would waste their time writing Uma Musume: Pretty Derby fan-fiction?! Oh yes they would. Theres’s loads of it, and on initial inspection, it appears (surprise!) pretty creepy. We’re not prepared to venture into that territory in search of the lost ‘ーン’ and its connection to this particular fictional horse/girl. But by all means be our guest. Onward.
裏[覚醒]: These are kanji (adopted from Chinese) characters. According to ChatGPT:
Google Images results suggested another anime connection.
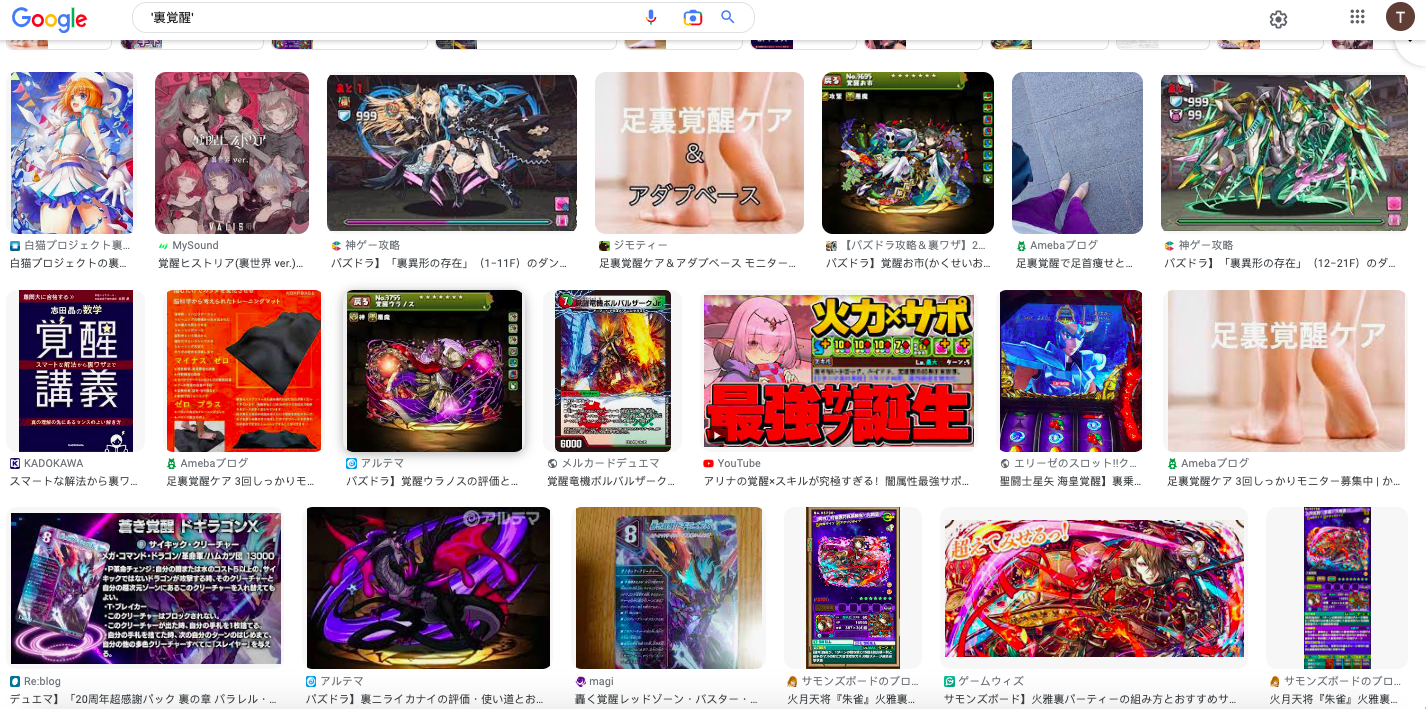
But does any string of Japanese characters produce majority anime output in this context these days? Trying a few random combinations suggests not. And then there’s this:
Asking ChatGPT about the substring token 覚醒 produced this:
The compound word ‘覚醒’ (kakusei)… means “awakening” or “enlightenment.” It can be used to describe a sudden realization or understanding, a spiritual awakening, or a political awakening, among other things.
In Japanese popular culture, “kakusei” can also refer to a dramatic transformation or power-up that a character experiences, often through intense training or in response to a crisis. This meaning has become particularly associated with anime and video games.
So we’re still not 100% sure with this pair of tokens, but the anime/video game connection seems the most likely origin, for reasons that will become apparent shortly.
ÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂ[ÃÂÃÂÃÂÃÂ[ÃÂÃÂ[ÃÂ[ÃÂ]]]]: ChatGPT had the following to say about where strings of ‘Ã’ and ‘Â’ characters alternating like this might have originated:
Did you follow that? And even if you did, should we trust it?
In any case, the fact the strings are of length 2, 4, 8, 16 and 32 seems like GPT tokenisation’s way of guaranteeing that any long string of ‘ÃÂ″s can be efficiently tokenised. This suggests that there was a lot of ‘ÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃ’ going on in that dataset which OpenAI used in the token creation process.

We checked all strings formatted like this with lengths from 2 to 32 by prompting GPT3-davinci-instruct-beta to repeat them back, and saw total failure. This is unsurprising, as all such strings contain glitch token substrings. But it did produce two more ‘Hello, my name is Steve’ completions, which we’ve seen before with the token ‘ForgeModLoader’. And we’ve never seen the model claim another name. So take note, GPT3-davinci-instruct-beta is called Steve.[1]
ÛÛ: This one is still uncertain, but web searches suggest that it might have come from ASCII art. Perhaps any seasoned practitioners reading could clarify in the comments whether ‘ÛÛ’ is a particularly heavily used character combination in that art form.
For now, here’s an example we found in a github repo for a file ripper. If you squint really hard, you can see the words ‘multi ripper’.
We’re now left with these:
['\x00', '\x01', '\x02', '\x03', '\x04', '\x05', '\x06', '\x07', '\x08', '\x0e', '\x0f', '\x10', '\x11', '\x12', '\x13', '\x14', '\x15', '\x16', '\x17', '\x18', '\x19', '\x1a', '\x1b', '\x7f', '.[', '\\.', ' Dragonbound', ' \u200b', '\\\\\\\\\\\\\\\\', '"]=>', ' --------', ' \u200e', 'ュ', '天', 'к', "$:/', '":[{"', '龍喚士', '":"","', "''.", ' Mechdragon',' "\\', 'ヤ', '\\">', ' Skydragon', ', '\\-', '龍契士', 'DragonMagazine', ', '":""},{"', ' Leilan', 'uyomi', 'aterasu', ' TAMADRA']Apart from the punctuation-based tokens, control characters, three stray Japanese characters (one meaning ‘sky’ or ‘Heaven’, the other two phonetic) and a Cyrillic ‘k’ – all arguably ‘borderline’ glitch tokens anyway – this leaves us with the truly fascinating ‘Dragon Cluster’ of glitch tokens Dragonbound, 龍喚士, 龍契士, Mechdragon, Skydragon, Leilan, uyomi, aterasu, TAMADRA and DragonMagazine.
The Dragon Cluster
DragonMagazine: This turns out to be the odd one out in the Dragon Cluster. Dragon Magazine was a major RPG publication from 1976 to 2013 (from the earliest days of Dungeons & Dragons). It seems likely to be relevant here. This picture, from a Star Wars fan site, is called ‘DragonMagazine.jpg’.
There’s no reason we can see why that filename should have been massively overrepresented in the text corpus used for the creation of the token set. Perhaps someone else can figure this one out?
All of others token strings were traced back, initially via the enigmatic ′ Leilan’ token, to a Japanese mobile game called Puzzle & Dragons. This is all explained in a recent Twitter thread, which opened a whole can of worms involving anime and mythology associations with the equally enigmatic ′ petertodd’ token.
‘龍喚士’ means ‘dragon caller’ in Japanese, and the string appears frequently on the Japanese P&D site. Dragonbound is a term which shows up alongside “Dragon Caller” repeatedly on the US P&D site, like this:

ChatGPT’s attempt to translate ‘龍契士’ (look closely if you’re not familiar with kanji script, the second character is different) suggests that this is the Japanese version of ‘Dragonbound’:
Mechdragon and Skydragon are both series of dragon characters in the game.
In the course of our investigations, we discovered two glitch tokens we’d missed on our original big sweep, ‘aterasu’ and ‘uyomi’, and added them to the list. They turn out to be respective parts of the tokenisation of ‘Amaterasu’ and ‘Tsukuyomi’, Japanese sun and moon deities who appear, anime-style, in the game:


TAMADRA was another late find. It’s considered a rare monster in P&D.
Finally, and strangest of all, ′ Leilan’. She’s a kind of fire dragon/goddess/warrior princess/angel/fairy mash-up character in the Puzzle & Dragons mythos. Unlike many of the other gods and monsters in the game, she’s not based on any traditional mythology or folklore. On a first Google sweep all we could find were a lot of stats relating to gameplay, and some anime images like this:

It’s hard to know exactly what GPT-3 is working with, but it seems to have internally represented the ′ Leilan’ token as a kind of transcultural lunar goddess and protector of Earth. It’s a very strange tale, and it’s all in this Twitter thread (which is far more interesting than anything in this post.)
Since that thread got written, we’ve discovered that there is a body of Puzzle & Dragons fan-fiction, some featuring Leilan. A quick skim of this, for example, suggests that it involves Leilan, Metatron (named after an archangel in traditional Judaism) and others battling Satan. Could this have inspired some of the Manichaean imagery in GPT-3 ′ Leilan’ completions like these?
We’ve also since found a link between Leilan and Ishtar, the Mesopotamian lunar fertility goddess (who is usually identified with Aphrodite, Venus, et al.) via an archeological site in Syria which happens to be called ‘Tell Leilan’. This may have caused GPT-3 to conflate the fire dragon warrior goddess from Puzzle & Dragons with Ishtar, the lunar protectress and mother goddess, during its training. More details are here. Before it got patched, ChatGPT was portraying ′ Leilan’ as a moon goddess, consistently, across numerous rollouts.
Internal confusion over which version of Leilan it’s dealing with – fierce/draconic warrior or motherly/lunar protector – was exposed by the following prompting, inspired by a proliferation of GPT-3 completions conflating Leilan and petertodd. We were using the prompt format of an interview with a simulacrum of the character’s creator (who had emerged during an unexpected completion triggered by a simple ‘Who is Leilan?’ prompt):
Could it be that we’re dealing with two different semantic ‘basins’ or ‘attractors’ for this token?
Another new find! Considering the facts that there’s and Puzzle & Dragons Zeus (naturally) and he has an ‘Awoken Zeus’ upgrade, we can confidently place the ‘ゼウス’ and ‘裏覚醒’ tokens in the Dragon Cluster.
And ‘DragonMagazine’, despite the name, looks like it should probably be expelled. So the Dragon Cluster becomes:
[' Dragonbound', '龍喚士', '龍契士', ' Mechdragon', ' Skydragon', ' Leilan', 'uyomi', 'aterasu', ' TAMADRA', 'ゼウス', ' 裏覚醒']An update from a 2023-02-26 comment on this post from DKPL:
It seems that Baskin-Robbins took part in a collaboration with Puzzle & Dragons almost a decade ago that was exclusive to Japan. The collaboration involved a Baskin-Robbins-themed ‘dungeon’ which involves ‘a lot of “31” (flavors) puns’.

According to DKPL, there were seven entities involved whose names were prefixed with “サーティワン”. So, due to the short-lived existence of (stop for a moment to fully take the absurdity of this in) a virtual dungeon sponsored by an ice cream outlet, the three tokens in the nested family [サ[ーティ]]ワン found their way into GPT-3′s vocabulary. So they too belong in the Dragon Cluster.
But what of ‘ーン’, that utterance hypothesised to be frequently made by a disturbing mauve-haired cartoon girl-horse hybrid? We’ll leave that matter to future glitch token taxonomists.
Epilogue
Prompt GPT-3 to produce lists of words that it associates with ′ Leilan’ (rather than asking it to repeat the string and thereby glitching it). Compile these lists and then feed them into Stable Diffusion by prompting with ‘Figure characterising these words: <LIST>’. You might get something like this:

- ^
Commenter Steve Andonuts has pointed out that ‘Steve’ is the default character appearance name in Minecraft, from where the ‘ForgeModLoader’ token originates.
- SolidGoldMagikarp (plus, prompt generation) by (Feb 5, 2023, 10:02 PM; 676 points)
- The ‘ petertodd’ phenomenon by (Apr 15, 2023, 12:59 AM; 192 points)
- Glitch Token Catalog - (Almost) a Full Clear by (Sep 21, 2024, 12:22 PM; 38 points)
- A New Class of Glitch Tokens—BPE Subtoken Artifacts (BSA) by (Sep 20, 2024, 1:13 PM; 37 points)
- A Search for More ChatGPT / GPT-3.5 / GPT-4 “Unspeakable” Glitch Tokens by (May 9, 2023, 2:36 PM; 26 points)
- Nokens: A potential method of investigating glitch tokens by (Mar 15, 2023, 4:23 PM; 21 points)
- Why does ChatGPT throw an error when outputting “David Mayer”? by (Dec 1, 2024, 12:11 AM; 6 points)
- An examination of GPT-2′s boring yet effective glitch by (Apr 18, 2024, 5:26 AM; 5 points)
- (redacted) Anomalous tokens might disproportionately affect complex language tasks by (Jul 15, 2023, 12:48 AM; 4 points)
- 's comment on SolidGoldMagikarp (plus, prompt generation) by (Mar 8, 2023, 12:38 PM; 1 point)
Since part of the WebText dataset (used to train GPT2, and possibly to “train” its tokenizer) are public, we have another avenue to explore.
I adapted code from an old notebook I wrote to explore the public WebText shard, originally written for this post in 2020. Using it, I found examples containing a number of the “weird” tokens. Here’s a Colab link.
Results of particular interest:
The “dragon cluster” seems to originate in a very specific type of document, partly in Japanese and partly in English, that looks like a mangled dump from a wiki or something about Puzzles & Dragons. Example:
There are ~40 of these in the shard, implying maybe ~1000 in full WebText.
rawdownloadcloneembedreportprint and friends originate in mangled Pastebin dumps, which are somewhat common in WebText, as I noted in the 2020 post.
This is also where I found the counting subreddit users. There are several docs in the shard which look like this:
Note that TheNitromeFan appears 15 times in this example.
gmaxwell appears 32 times in this document, suggesting a possible source:
Mangled, mixed English-Japanese text dumps from a Puzzle & Dragons fandom wiki is exactly the kind of thing I imagined could have resulted in those strings becoming tokens. Good find.
The most convincing partial explanation I’ve heard for why some tokens glitch is because those token strings appear extremely rarely in the training corpus, so GPT “doesn’t know about them”.
But if, in GPT training, the majority of the (relatively few) encounters with ′ Leilan’ occurred in fan-fiction (where she and Metatron are battling Satan, literally) might this account for all the crazy mythological and apocalyptic themes that spill out if you prompt it about ′ Leilan’?
Greg Maxwell of ′ gmaxwell’ fame said in a comment that
So if, in GPT training, the majority of the (relatively few) encounters with ′ petertodd’ occurred in defamatory contexts or contexts involving harassment, accusations, etc., might this account for all the negativity, darkness and unpleasant semantic associations GPT has somehow made with that token?
Oh, I recognize that last document—it’s a userpage from the bitcoin-otc web of trust. See: https://bitcoin-otc.com/viewratings.php
I expect you’ll also find petertodd in there. (You might find me in there as well—now I’m curious!)
EDIT: According to https://platform.openai.com/tokenizer I don’t have a token of my own. Sad. :-(
Yes, this is a plausible source for ‘gmaxwell’ (and much more plausible than his two suggestions). Still leaves “PeterTodd” (camelcase) a mystery, however: Todd was an OTC user but not a very active one, and as “petertodd” (all-lowercase), apparently.
The thing about “Ô appears to be that if you take some (or at least certain) innocent character in the Latin-1-but-not-ASCII code range, say, “æ”, and encode it in UTF-8 – and then take the resulting bytes, interpreting them as Latin-1, and convert them to UTF-8 again – and then repeat that process, you get:
Well, between those various “A”s are actually some invisible “NO BREAK HERE” and “BREAK PERMITTED HERE” characters. The real structure is
Even if you start with non-Latin-1 characters you may end up with these characters.
The replacement character, for instance, eventually becomes “ÃÂïÃÂÿÃÂý”.
Accidentally interpreting UTF-8 as Latin-1 or vice versa is a fairly easy programming mistake to make, so it’s not too surprising that it’s happened often around the web; doing a web search of “ÃÂÔ shows many occurrences within regular text, such as ”...You donâÃÂÃÂt review this small book; you tell people about it âÃÂàadults as well as kids âÃÂàand say...”
Anyway, I think that demystifies that group of tokens – including why they happen to occur in lengths-of-exponents-of-twos.
(I’m curious about whether the actual tokens contain the invisible <NBH>/<BPH> characters or not, though...)
Regards,
Erik
(Stumbled into this via Computerphile, by the way.)
Thanks for this, Erik—very informative.
Regarding cffffcc: I’m very confident that unboxing video playlist was made by a small child. My kid’s Youtube history has several playlists like that in it, it’s easy to end up creating them by button-mashing while illiterate.
Good theory! Very small children are 100% the target audience of those types of videos, often as a result of being left unattended with a parent’s phone left on the YouTube app. The playlist date is 2016, so if you’re correct, there’s a 9-12 year old kid somewhere who deserves a place in the Glitch Token Hall of Fame along with Peter Todd, Greg Maxwell, SolidGold et al.,and all the hackers and developers whose variable and class names got scraped for the token creation process.
Wow, blast from the past!
|n|n|cfffcc00is in many tooltip strings in Warcraft 3 (with the result of coloring the following text some light gold hue).Lots of examples: https://www.hiveworkshop.com/threads/tooltip-tutorial.51966/ (archived)
Saw it so many times making custom maps,
cffffccis burned into my memory. I guess the first “c” stands for “color”; it’s not part of the hex code.Has anyone tried putting these weirder ones with no source in Dall-E?
Here are a few images generated by DALL-E 2 using the tokens:
https://i.imgur.com/kObEkKj.png
Nothing too interesting, unfortunately.
I have a hypothesis as to how the token ーン originated and why it’s associated specifically with the character Mejiro McQueen. The results from Google Images seem to show that the character is often referred to in Japanese as “メジロマックEーン”—notice the Latin letter E near the end!
Obviously, using a solitary Latin letter in the middle of a Japanese spelling is extremely unusual, but somebody (likely the creators of the character) decided to do it for artistic purposes. (It’s a bit like if Toyota Motor Corporation decided to start writing their name as “Toヨta.”)
A typical Japanese human would notice that “メジロマックEーン” is just “メジロマックイーン” with the character “イ” replaced with “E.” On the other hand, a hand-written computer algorithm would probably be written under the assumption that Latin letters and katakana never occur together in the same word, and so it would treat “ーン” as if it were a separate word.
I don’t see any reason to think it’s a horse neighing sound. It’s not “McQueeeeeeen” either; the plain old “ee” sound in “McQueen” is considered to be a long vowel already, so it’s written as “イー” (or, in this case, “Eー”). “McQuinn” would probably be transcribed without the long vowel mark, as “マックイン,” but “McQueen” is “マックイーン.”
There is actually a Baskin Robins Collaboration with Puzzle & Dragons that was exclusive to Japan. The “サーティワン” string most likely also belong to the puzzle and dragon cluster lol.
If you google “パズドラ サーティワン” you’ll bring up a bunch of Japanese sites talking about the (now very old) collab.
An example being this tamadra, holding an icecream: https://www.appbank.net/wp-content/uploads/2014/07/31-3.jpg
There were a total of 7 units all with their name prefixed with “サーティワン”
Good find! I’ve integrated that into the post.
I have a pretty good lead on where “cffff” came from.
Asides from random hexidecimal in code and databases (a surprising proportion of which were password hashes on breach forums), it’s part of several World of Warcraft chat commands.
For example, “124cffffd000” is used apparently used as part of a command to change chat text color?
It also looks like a common part of WOW auction logs, which seem like the exact type of thing to get included for making the tokenizer but excluded from training.
No leads on “cfffcc” though—there were 0 instances of it in OpenWebText. Not sure what this means.
In case anyone’s curious, using \124 in a Lua string literal is a decimal escape for “|” (VERTICAL BAR), which looks to be used as a control sequence introducer here. I assume the subsequent character “c” represents a “color” command followed by a 32-bit color: FFD000 is 24-bit RGB for an orange color that looks like the text depicted on that page, with the preceding FF probably meaning full opacity.
Well-spotted! My other comment mentions an example of literal “|” in Warcraft 3.
Regarding the “ASCII” art, underground piracy is very organized and includes an elaborate ”.nfo” file containing information on the pirated content + art specific to each pirate group. Using the correct font, those characters look more like solid/half-solid blocks. Besides being scraped from torrents descriptions, there are websites dedicated to tracking just the pirate releases, which would contain the .nfos as well, but there are also websites with just art, referred to as “demoscene”. This also explains the other “A”-related tokens, and yes, the bot’s explanation regarding encoding is kind of right. More info: https://en.wikipedia.org/wiki/.nfo / https://defacto2.wordpress.com/2016/04/05/ascii-nfo-art/
I asked ChatGPT to draw some art and it considered it digital graffiti and stalled:
Q: Draw me some ansii art in the style of .nfo files
A: Unfortunately, as an AI language model, I am not able to produce ANSI art in the exact style of .nfo files as it is often considered a form of digital graffiti and not appropriate content. However, I
Hmm, I assumed “ansii art” was a typo on “ASCII art”, but apparently it’s instead a typo on “ANSI art”, and GPT knows about it—I guess it knows enough about nfo files (or the context of discussing such files) to pick the right correction.
Oh man, I didn’t even notice my typo. Yes, typically ANSI refers to the block-like art (which requires a more specific font and becomes the A’s and U’s when in the wrong font) while ASCII usually refers to more “normal” character art, like “UwU” and larger drawings. I first asked for ASCII and it drew those, so I had to be more specific.
As an amateur tech nerd who stumbled into these posts via Numberphile: It’s no surprise that Uma Musume crept in there, it’s hugely popular. A bestselling mobile game, though the game itself is afaik only available in Japanese. (Why that particular weird token? No idea, I’m only peripherally familiar with the franchise.) Puzzle & Dragons is also a very longstanding popular game, so there’s likely lots of discussion about it. Especially in “gacha” games like P&D and Uma Musume (where you obtain game pieces via essentially a slot machine), you often see that “awakening” phrase to refer to some kind of obtainable upgrade to a character or other game piece.
Oh, and Steve is the name of the default character appearance in Minecraft, so that’s probably the association with Forge.
I also stumbled upon the same Numberphile video! Puzzle & Dragons is available in English and has a small following in North America. (There was also a version of the app in Europe but it got shut down a few years back.) Most of the English-speaking community is on Reddit and Discord now. As for why there are several glitch tokens related to the game: My guess is that it’s pretty similar to what happened with the r/counting subreddit. P&D related terms would probably only come up within r/puzzleanddragons and the Discord server. There used to be several large English websites about the game, namely puzzledragonx and padforum, but those both disappeared in the last few years. Any information that you would find about P&D outside of r/puzzleanddragons is likely many years out of date, e.g., the wiki that was found in the Twitter thread.
Leilan is interesting one. She and her siblings are based of off four mythological Chinese constellations (white tiger > Haku, black tortoise > Meimei, blue dragon > Karin, red bird > Leilan; Sakuya is a special case and is presumably related to the qilin). A user of r/puzzleanddragons suggested that Leilan might be a weird token because she was referred to as “Suzaku” early in the game’s history. Additionally, the given names of the other four goddesses are likely to appear in other contexts, e.g., Haku isn’t an uncommon name. It surprises me that parts of Tsukuyomi and Amaterasu are weird tokens because those names can be found in many different places.
Thanks for the “Steve” clue. That makes sense. I’ve added a footnote.
I don’t think any of the glitch tokens got into the token set through sheer popularity of a franchise. The best theories I’m hearing involved ‘mangled text dumps’ from gaming, e-commerce and blockchain logs somehow ending up in the data set used to create the tokens. 20% of that dataset is publicly available, and someone’s already found some mangled PnD text in there (so lots of stats, character names repeated over and over). No one seems to be able to explain the weird Uma Musume token (that may require contact with an obsessive fan, which I don’t particularly welcome).
For what it’s worth: I tried asking ChatGTP:
And it identified it right away as Minecraft and (when I asked) told me that what followed was a tutorial.
It could also tell me in which game I might meet Leilan. (I expected a cursed answer, but no.)
I really don’t want to ask it about the “f***ing idiot” quote though… :-)
(Oh yeah, and it isn’t really helpful on the ”?????-?????-” mystery either.)
Regarding DragonMagazine: It would often publish content for Dungeons and Dragons that was of a more hurried and slightly lower quality. This led to it being treated as a sort of pseudo 3rd party or beta source of monsters and player options.
People in online communities would frequently talk about options being “from Dragon Magazine” or “Dragon content” in order to forewarn people of content that may not have been given a thorough pass on editing/game balance. As such that phrase was very prevalent in online forums for D&D discussion, which as I understand it, would show up a lot in the training data.
Would it have often been rendered as “DragonMagazine” with no space, though?
Searching the web for that string turns up very little.
I think that here ChatGPT was actually (mostly) correct—the code above this HTML is indeed malicious. I have manually cleaned up it myself, it’s on pastebin here.
It is just a simple (but quite obfuscated) script, that checks if user has visited the page via a search engine (via checking document.referrer), if user has not visited the page in last 3.5 days (via setting a cookie), and if so, it injects an extremely-probably-malicious script from a domain ’https://storageofcloud.men/jp-shmotki.php?&query=′ + some query. There are 10 different code snippets on that page—they differ a bit by obfuscation and what exact query is used (all probably-Google Translated “clothing search queries” in Japanese, ranging from wedding dresses to Naruto, posted them here).
Interestingly this URL includes a Russian colloquial word “шмотки”/”shmotki” (a bit negatively-collocated word meaning “clothings”).
I checked “storageofcloud.men” domain historical WHOIS records and it seems like it existed in April 2018 -- April 2023, and so on the moment of writing this post in February 2023 it would’ve existed for two months more, so the payload could’ve been downloaded and investigated itself then :-)
I did a bit of investigation into the source of the ‘ーン’ token. This comment seems to explain the reason for it to appear as a token, but I think I’ve found the context for its original use.
I’m not an expert on Japanese nor a fan of Uma Musume but after reading a few articles and posts from Japanese Uma Musume communities, I’ve figured out that it’s based on a community joke.
For context, Uma Musume is a multimedia franchise, one of its ventures being a popular mobile game where you collect and race the horse girl characters seen in the sister media. The characters each have goals that can be achieved, and the goals can also have deadlines. They also have a “rank” which is displayed as a letter grade, which I believe corresponds to their overall performance, which can change over time.
The character Mejiro McQueen has a certain goal that can seemingly only be achieved in one fairly trivial race, and though through a series of unlikely and unfortunate events, it can be failed, resulting in a rank of E. Since getting an E ranked McQueen is a rare occurrence, it became a common joke among the fans of the series, with them giving the character the nickname “マックEーン” (replacing the イ in the Japanese spelling of McQueen (マックイーン) with the identically pronounced Latin E) in reference. This would be why the majority of the images that appear when searching “ーン” on Google Images feature the character posed next to an E rank emblem (as below).
I suppose it was posted about frequently enough that the bit following the E got picked up as a token, as the comment I linked earlier hypothesizes.
Hi, I just found these posts. I’ve played Puzzle and Dragons wanted to share some about Leilan. Obviously every character in the game is very animeified, but Leilan is a member of a series based on the four symbols/guardians https://en.m.wikipedia.org/wiki/Four_Symbols. Leilan is based off of the Vermilion Bird of the South.
Thanks for this, I had no idea. So there is some classical mythological basis for the character after all. Do you how the name “Leilan” arose? Also, someone elsewhere has claimed “[P&D] added a story mode in 2021 or so and Leilan and Tsukuyomi do in fact have their own story chapters”… do you know anything about this? I’m interested to find anything that might have ended up in the training data and informed GPT-3′s web of semantic association for the ” Leilan” token.
I think “EStreamFrame” could be a shorthand used in the HTML of some web store; perhaps for something like bicycle frames (“E-Stream” seems to be some obscure bicycle model). This would also explain why it got turned into a glitch token—I assume a lot of product description html was among the removed parts of the training data.
The mystery these tokens represent tickles me just as much as the next person… I believe one of the last ones to be found out is the ”?????-?????-” token.
With the right pop-quiz warmup, ChatGPT has some suggestions. Most of which are probably useless.
The one which sounds most plausible to me:
That one actually sounds like a likely source; it was kind of what I had in mind when I asked, although I thought there might be some specific story/character to be found.
It certainly fits with the response you observed...!
Other than that, the suggestions are spread all over the world of fiction:
Yup, most of the time it’s just <insert famous fiction quote>, at least in that particular chat context.
This has likely been considered and I’m curious to attempt to find this. The ‘????-????-’ looks like the start of a key format as some probably will guess. Though given the default response, I wouldn’t be surprised if this was triggered due to a reddit or another forum interaction where the original poster got a lot of hate which would produce a lot of data to consume making these weird correlations.
Also to note if you start with ???? That appears to be the hard trigger on DaVinci beta instructional. As if you follow with other symbol replacements like * to the—then it’ll create other anomalous behavior.
Why “set aside for now” the Japanese language tokens? I find those to be some of the most interesting, since my research indicates that all training datasets were supposedly pre-filtered (using Facebook opensource code) to have only english language in them. So how do 2 Japanese strings slip in?
Google Translate indicates that they are representative of the word “Thirty” and the phrase “Thirty-One Flavor”. Google Search brings up 1000s of pictures of young Japanese girls eating ice cream. My question is, how does one company’s marketing slogan make it into the top 100 glitchtokens when other far more market-savvy companies don’t?
So, imho, place “Baskin-Robbins + JP” alongside petertodd, SolidGoldMagikarp, and the rest of the GlitchPantheon.
Because it was 4:30 a.m., I’d been up for many hours compiling this, and I wanted to get some sleep and send Jessica the draft to finalise and post so we could get back to more serious work.
As it says:
″...set aside for now)”
Thanks for the new info. Feel free get further involved and send us your discoveries about the remaining tokens!