AI Alternative Futures: Scenario Mapping Artificial Intelligence Risk—Request for Participation (*Closed*)
Overview: AI Futures Risk Model
Summary: I am a graduate student researching artificial intelligence (AI) risk and typology classifications that could result from variations in technological transitions. I am developing a scenario modeling tool that captures many of the more complex non-quantifiable dynamics inherent in complex systems. The project aims to map structural forces, trends, technologies, and degree of risk to potential AI futures through an exploratory scenario modeling framework.
As part of the data collection, I am eliciting community perspectives on AI paths through a survey (options: worksheet or Google form) to rank key characteristics that can influence AI progress, risks, and futures.
I appreciate any assistance. My data collection window is closing soon, and I figured it was past time to request assistance from the broader community if able. I am behind the curve on this request (and understand how demanding these are) but any help however minimal is greatly appreciated. None of the questions are required so if you are unsure or are short on time feel free to skip questions or sections.
The model I’m developing requires both plausibility rankings and impact to populate a likelihood/impact matrix for the model’s foundation (details below). Since the full version is relatively long, I’ve broken it up into two shorter versions which I’ll post below (under Survey Overview); I have no preference for either at this time, any data helps. The short versions should take less than five minutes each and are completely anonymous.
Survey Overview: Plausibility & Impact
This project is an exercise in exploratory scenario development only. Scenario modeling is not about prediction, but rather a rigorous and methodical way to consider the full scope of imagined future situations, or contexts and model the broad outlines of what could potentially happen rather than what will happen (Figure 2).
Generating scenarios typically involves identifying a set of influential “drivers” which in combination create a range of plausible future states. For each driver or dimension, there are a set of conditions to rank.
Similarly, I developed a range of AI dimensionsrather than drivers (key aspects – e.g., AI paradigm) and added a subset of key uncertainties which I call conditions (scenario paths – e.g., current paradigm, new paradigm, or hybrid) for each dimension. Each dimension and condition are independent factors/aspects, and uncertainties of AI that when combined make up a plausible scenario.
Survey Instructions (both versions): The survey presents each question as an AI dimension followed by three to four conditions and requests participants to:
Likelihood: Rank each condition from most plausible to the least plausible to occur
Impact: Rank each condition from the greatest potential benefit to stability, security, and technical safety to the greatest potential for downside risk
Likelihood/impact values are derived from the MITRE risk scale.
Note: I recognize that the impact section can be especially vague and hard to judge. The aim is to score each along a continuum, from best to worst, for the risk space (e.g., inner alignment --> power-seeking --> goal alignment) so please choose the best(worst) option available. The output will make sense.
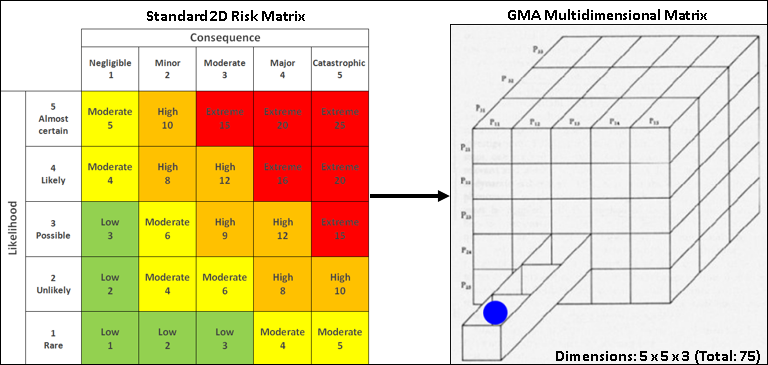
The overall goal of both surveys is to create a risk spectrum across all the AI dimensions and conditions, based on the values collected, for the GMA alternative futures model (e.g., green=good --> yellow/orange=moderate --> red=bad) along the same lines as traditional risk analysis (Figure-1).
The survey requests participants to rank or score each condition on its overall plausibility and degree of impact given our current understandings. The survey questions are technically not questions at all and should be viewed rather as a ranking or scoring of each condition (the question format was added later for clarity). If you have a concrete understanding and set of beliefs on AI capabilities, generality, takeoff, paradigms, race dynamics, and safety the conditions shouldn’t be too unclear.
For those willing to complete the original full version I’ll provide the link here.
Survey Results
The survey results are used to create the range of scenario possibilities for each combination of conditions (see methodology) and levels of risk to be arrayed across the model, similar to the standard four-quadrant of a risk matrix but continuous and in many dimensions (e.g. standard risk matrix, multidimensional matrix using GMA). Thus, for this model, rather than a standard 2D space, the variables are arrayed 14.
The categories—from high likelihood to low, and impact, from greatly increase to decrease risk—are used to bound the overall “problem space” (or solution space) of the model for exploratory scenario development.
Therefore, the values ranked in the survey will create the foundation for the General Morphological Analysis (GMA) model (with GMA as the foundation, but with methodological additions e.g., impact/likelihood risk spectrum from the results). GMA is similar in spirit to the standard 2D matrix (Figure-1 - left), which generally has 2 drivers that allow four possible scenario outcomes (on a standard cartesian plane).
The benefit of Survey Results to the GMA Process
The GMA process transposes the 2D cartesian matrix into many user-defined dimensions, in effect reimagining the process and problem as multiple interrelated matrices rather than one; The GMA example in Figure-1 (right) with only three drivers/five cells results in 75 possible scenarios; the process allows a radical increase in possible scenario options.
Using the GMA variation for this project, with the likelihood and impact values from the survey, the GMA morphological space is transmuted into a multidimensional risk complex; rather than focus on and structure the dimensions and conditions independent of risk or likelihood (the standard approach), the outputs of the survey allow us to create a continuum of likelihood and impact measurements across the problem space for added context, computation between conditions, and risk analysis assessments.
The strength of GMA lies in its ability to structure and model high numbers of parameters with significant degrees of complexity.
Another Scenario Project?
This survey varies from similar projects in that it:
Seeks to identify unique combinations, and potentially, entirely new scenario possibilities.
Requests participants to rank individual elements of possible scenarios, rather than fully developed scenarios themselves, to develop unique unexplored combinations.
Uses the participant’s rankings as inputs to the morphological model to cross-evaluate against all others, evaluate, combine, and cluster scenario elements (condition rankings) to exhaust all scenario combinations.
Exploratory Scenario modeling
Scenario Development Process: The goal of scenario development is to explore high-consequence problems that are difficult to impossible to extrapolate from historical data.
Scenarios are a useful tool for informing policy for future change.
While not always the best option, alternative futures modeling is useful for planners to identify vulnerabilities, develop strategies, and plan for resilience can be critical in the face of high uncertainty. Unanticipated disruptive technology gains or jumps in capabilities could radically upend stability and the balance of power (e.g., How did nobody see it coming?).
There is a solid body of research that aims to forecast AI development (e.g., here, here, and here), and this project does not attempt to add to it. Several of the scenario elements in the survey are highly speculative and qualitative, as the primary goal is to explore all options, including the very messy and non-quantifiable aspects, as best possible, to develop unique variations that may provide insight.
This work primarily contributes to the literature through the futures modeling technique and a structured framework of AI dimensions. There is a need for more comprehensive scenario modeling in the AI space in general, notwithstanding some notable exceptions (e.g., Gruetzemacher, Avin,Whittlestone, Baum).
However, scenario methods overall tend to struggle with capturing high degrees of complexity and uncertainty, with outcomes generally confined to a limited number of options. This GMA variation and several others could potentially provide important contributions to this area.
Framework
I am modeling AI through an evolutionary complex systems framework to analyze the problem in the context of punctuated equilibrium theory and technological transitions. These theoretical frameworks provide interesting conceptual insights into the discussions on continuous or discontinuous change. And punctuated equilibrium provides a model for understanding periods of stasis that are regularly disrupted by critical transitions.
This research presents a classification framework, starting with three broad high-level systems, followed by 14 nested dimensions that influence AI development and risk, and 47 individual conditions that are elements of possible futures (tentatively − 129 potentially measurable indicators). Comprehensive definitions of dimensions and conditions can be found here.
The purpose of this research is to: 1) present a systematic organizational framework of AI dimensions and conditions for use in futures analysis and 2) map AI developments to system typologies, risks, and social-political dynamics to variations in technological transitions, distribution, and vulnerabilities, and 3) investigate influence pathways and relationships between the dimensions to suggest how actions in one could impact others.
Methodology
The methodology uses general morphological analysis (GMA) as a foundation (see: Johansen and, Ritchey), where a standard two-dimensional problem is transposed into a multidimensional problem space, in which variables are arrayed against each other in a matrix yielding millions of potential outcomes (Figure-3, Figure-4). The framework composed of 14 dimensions and 47 conditions, will make up the body of the matrix.
The GMA approach has been applied across a variety of fields from design, and linguistics, to defense planning, and disinformation. The GMA process aims to identify and structure all possible arrangements for irreducible, complex problem spaces which in most cases involve human dynamics, qualitative social issues, politics, and economics. The process is iterative through repeated sequences of analysis, refinement, and synthesis. Follow-on discussions/interviews with subject-matter experts are tentatively planned to refine the results.
Problem Formulation & Multidimensional Problem Complex
The first step requires an exact as possible formulation of the problem. Next, the problem must be broken down into a parameter set that frames as many components of the issue as possible—in this case, 14 dimensions, with three to four possible outcomes (conditions) for each, totaling 47.
The third step involves constructing a multidimensional matrix containing all identified dimensions and conditions related to the problem (Figure-4). The matrix contains within itself the entire problem space of the given issue. The fourth step reduces any inconsistency between each pairwise condition.
Once values are received from the survey results, the responses are averaged for each individual condition separately (e.g., 50 rankings for “fast takeoff” are averaged) in two separate matrices for each of the 47 conditions. This is combined into one master multidimensional matrix of all survey responses for each condition (Figure-4).
Cross-Consistency Assessment (CCA)
Next, Cross-Consistency Assessment (CCA) winnows down the prospective futures to a smaller set of configurations, weeding out inconsistent pairs while allowing the discovery of unexplored relationships.
From the 14 unique dimensions, the 47 conditions that are assessed in the survey are arrayed along the horizontal (X-axis) and vertical (Y-axis) to create the GMA matrix; each cell in the matrix represents a combination of two conditions (excluding duplicative values) and one unique scenario combination.
The cells are then evaluated across the axis to rank the consistency between each value pair (e.g., fast takeoff --> moderate distribution). One pair of conditions is a scenario combination or scenario pair (e.g., condition-1: multipolar distribution X condition-2: current AI paradigm, depicted in red below). The total 47 conditions yield millions of possible scenario combinations (15,116,544 unique combinations) - too many to evaluate independently, but extremely comprehensive (including outliers). See Ritchey for details on CCA.

Scenario Mapping Dimensions & Conditions
After all impact and likelihood rankings for each condition are averaged (all impact values ranked in the survey for condition 1, for example) each scenario pair is evaluated and then combined with the opposing condition between the X-axis and Y-axis. As in Figure-4, the condition “current paradigm” is evaluated and then combined with the condition “multipolar distribution.”
Thus, each cell in the matrix is a computation between two conditions and four sets of values provided by survey participants (e.g., condition-1 impact/plausibility & condition-2 impact/plausibility). The combination across the X-axis and Y-axis results in multiple individual scenario combinations (15,116,544 independent scenarios currently).
Grouping Scenario Pairs for Analysis
After the separate values for each condition are calculated and combined, the k-means clustering algorithm groups like values into potential scenario classes (Figure-5). The clusters are user-defined, allowing many distinct clusters for detailed analysis, or broad classes for more in-depth narratives. This method provides a structured technique to organize and model as many potential variables of a problem as needed to ensure all critical aspects of a problem are comprehensively evaluated.
Ultimately, the GMA method is primarily used to decompose a multidimensional problem for alternative futures analysis. However, the pairwise relationships between each condition across the cells are also edges of a network graph, with each condition a node in the network. The graph can be a valuable tool to model the complexity, the strength of relationships, and possible directionality.
For example, the results from the CCA could be used to build a network graph to display the interdependent relationships between each variable and condition (from consultations with domain experts and based on the values from the ranking) to analyze the degree of dependency and relationships.
Next Steps
After the survey values are collected, all impact and likelihood values will be averaged in the GMA matrix for each condition. The next potential ideas to add to the model include:
Develop indicators for each condition that could potentially be used to monitor developments (TBD).
Develop a hypergraph model using the CCA output to evaluate the influence or possible directionality between conditions (TBD).
Note: the project is still in development and there are other methodological options and data sources I’m considering, if viable. This will be iterative, so I hope to conduct interviews with domain experts following the survey for further refinement.
Definitions and Dimensions documents here for further reference: Dimension/matrix spreadsheet: https://tinyurl.com/diggidy; Definitions: https://tinyurl.com/aidefin
- ^
The Google version has questions and detailed descriptions added for clarity, but the ultimate goal is to rank each from most/best to least/worst only. If a question seems oddly worded ignore it or skip it; the entire point is ranking.
- ^
Note: the impact questions are especially difficult to judge and I recognize the problem (choices, and overall framing with google survey especially). The aim is to rank each along a continuum, from best to worst, for the risk space (e.g., inner alignment --> power-seeking --> goal alignment) so please choose the best(worst) option available and rank as such. The output will make sense.
Hi! Thank you for this project, I’ll attempt to fill the survey.
My apologies if you already encountered the following extra sources I think are relevant to this post:
the Modeling Transformative AI Risk (MTAIR) project (an attempt to map out the relationships between key hypotheses and cruxes involved in debates about catastrophic risks from advanced AI);
Turchin & Derkenberger’s Classification of global catastrophic risks connected with artificial intelligence (lists and categorizes a wide range of catastrophic scenarios, from narrow or general AI, near-term or long-term, misuse or accidents, and many other factors, with references);
Sotala’s Disjunctive Scenarios of Catastrophic AI Risk.
Hi! I appreciate you taking a look. I’m new to the topic and enjoy developing this out and learning some new potential useful approaches.
The survey is rather ambiguous and I’ve received a ton of feedback and lessons learned; as it is my first attempt at a survey, whether I wanted one or not, I am getting a Ph.D. on what NOT to do with surveys certainly. A learning experience to say the least.
The MTAIR guys I’m tracking and have been working with them as able with the hope that our projects can complement each other. Although, MTAIR is a more substantive long-term project which I should be clear to focus on that in the next few months. The scenario mapping project—at least with the first stage (depending on if there’s further development)--will be complete more or less in three months. A Short project, unfortunately (which has interfered with changing/rescoping). But I’m hoping there will be some interesting results using the GMA methodology.
And “Turchin & Derkenberger” piece is the closest classification scheme I’ve come across that’s similar to what I’m working on. Thanks for flagging that one.
If it looks reasonable to expand and refine and conduct another iteration with a workshop perhaps That could be useful. Hard to do a project like this in a 6mos timeframe.