If you’re looking for audio of my posts, you’re in luck. Thanks to multiple volunteers you have two options.
Option one is Askwho, who uses a Substack. You can get an ElevenLabs-quality production, with a voice that makes me smile. For Apple Podcasts that means you can add them here, Spotify here, Pocket Casts here, RSS here.
Alternatively, for a more traditional AI treatment in podcast form, you can listen via Apple Podcasts, Spotify, Pocket Casts, and RSS.
These should be permanent links so you can incorporate those into ‘wherever you get your podcasts.’ I use Castbox myself, it works but it’s not special.
If you’re looking forward to next week’s AI #77, I am going on a two-part trip this week. First I’ll be going to Steamboat in Colorado to give a talk, then I’ll be swinging by Washington, DC on Wednesday, although outside of that morning my time there will be limited. My goal is still to get #77 released before Shabbat dinner, we’ll see if that works. Some topics may of course get pushed a bit.
It’s crazy how many of this week’s developments are from OpenAI. You’ve got their voice mode alpha, JSON formatting, answering the letter from several senators, sitting on watermarking for a year, endorsement of three bills before Congress and also them losing a cofounder to Anthropic and potentially another one via sabbatical.
Also Google found to be a monopolist, we have the prompts for Apple Intelligence and other neat stuff like that.
Table of Contents
Introduction.
Language Models Offer Mundane Utility. Surveys without the pesky humans.
Language Models Don’t Offer Mundane Utility. Ask a silly question.
Activate Voice Mode. When I know more, dear readers, so will you.
Apple Intelligence. We have its system prompts. They’re highly normal.
Antitrust Antitrust. Google found to be an illegal monopolist.
Copyright Confrontation. Nvidia takes notes on scraping YouTube videos.
Fun With Image Generation. The days of Verify Me seem numbered.
Deepfaketown and Botpocalypse Soon. OpenAI built a watermarking system.
They Took Our Jobs. We have met the enemy, and he is us. For now.
Chipping Up. If you want a chip expert ban, you have to enforce it.
Get Involved. Safeguard AI.
Introducing. JSONs, METR, Gemma, Rendernet, Thrive.
In Other AI News. Google more or less buys out Character.ai.
Quiet Speculations. Llama-4 only ten times more expensive than Llama-3?
The Quest for Sane Regulations. More on SB 1047 but nothing new yet.
That’s Not a Good Idea. S. 2770 on deepfakes, and the EU AI Act.
The Week in Audio. They keep getting longer.
Exact Words. Three bills endorsed by OpenAI. We figure out why.
Openly Evil AI. OpenAI replies to the questions from Senators.
Goodbye to OpenAI. One cofounder leaves, another takes a break.
Rhetorical Innovation. Guardian really will print anything.
Open Weights Are Unsafe and Nothing Can Fix This. Possible fix?
Aligning a Smarter Than Human Intelligence is Difficult. What do we want?
People Are Worried About AI Killing Everyone. Janus tried to warn us.
Other People Are Not As Worried About AI Killing Everyone. Disbelief.
The Lighter Side. So much to draw upon these days.
Language Models Offer Mundane Utility
Predict the results of social science survey experiments, with (r = 0.85, adj r = 0.91) across 70 studies, with (r = .9, adj r = .94) for the unpublished studies. If these weren’t surveys I would be highly suspicious because this would be implying the results could reliably replicate at all. If it’s only surveys, sure, I suppose surveys should replicate.
This suggests that we mostly do not actually need the surveys, we can get close (r ~ 0.9) by asking GPT-4, and that will only improve over time.
This also suggests that we can use this to measure question bias and framing. You can simulate five different versions of the survey, and see how the simulated responses change. This could also let one do a meta-analysis of sorts, with ‘wording-adjusted’ results. Sounds super exciting.
Ask it to comment on a function, get six different bugs back.
Write most (80%+) of the university papers. What is college about, again?
Come up with terrible corporate speak names for your startup to use.
Get a diagnosis days before the doctors tell you, plausibly more accurate too. As Ashlee Vance or JFK might suggest: Ask not what the LLM cannot do for you, ask what you can do with an LLM.
How Nicholas Carlini uses LLMs, especially to supercharge coding. Very different from what I mostly use LLMs, because I almost never code. But I am continuously super tempted to write code in a way I would be completely untempted without LLMs.
Find an excuse not to let the humans screw up the answer.
Michael Vassar: No AI is needed for many of the important benefits of AI. All we actually need is paper, pencils and rules. But if we can market those as AI, that’s great, let’s do it!
Timothy Bates: The more things change, the more they stay the same: 1943 paper shows that a mechanical prediction of admissions greatly out predicts the decisions from administrators asked to add their subjective judgement :-(excellent talk from Nathan Kuncel !)
Nick Brown: I would bet that if you asked those subjective evaluators, they would say “We know the grades are the best predictor on average, but ‘sometimes’ they don’t tell the whole story”. People want to double-dip: Use the method most of the time, but add their own “special expertise”.
Timothy Bates: Nathan Kuncel put it astutely showing that decision makers beta weights are pretty accurate, but then they ruin their decision at “run time” by adding random intuitions about details in the application :-)

An AI could doubtless do better than the simple algorithm, or even the full human algorithm without the noise. But yeah, I’m guessing most of the value is in not actively messing up the calculation.
Then, of course, the ethicists get involved and introduce ‘bias corrections.’
Predict the top Reddit comments without needing to look at the comments.
Language Models Don’t Offer Mundane Utility
So this particular one, I found pretty funny. The others, not so much.
Gary Marcus (QTing the below): That’s because meta.ai is the joke.
John Brownlow: Meta.ai doesn’t get the joke.

What confuses me is the obsession with this form. Yes, we have figured out that if you pattern match hard enough to something in the training data, despite differences a human would obviously pick up, an LLM will often pattern match in a way that makes zero logical sense.
So what? This is an adversarial example against a static opponent, that is intentionally not being trained to defend against that type of attack. It works because the AI has an actually good prior that it’s facing a certain kind of logic puzzle. The reason it is wrong is that you figured out what to say to get it to think that. I am confused why certain people think ‘oh that means AIs are stupid and worthless.’
Whereas ‘show you some indication an LLM is doing something dumb on the internet’ is a fully effective adversarial attack on Gary Marcus. He’s still not dumb.
A bigger problem with AI is that people are against it, and if they hear your product uses it they are actively turned off, partly because it lowers emotional trust. You very much want to use AI to improve your business, but consumers don’t want it. They’ll want the results, so eventually this will be overcome, but it’s not a selling point.
No seriously Google, what the hell is wrong with you, you think it’s good for a father to tell Gemini to write a fan letter on behalf of your daughter? In what universe did you think that was a good use case to highlight? Do you think an Olympian wants that? Do you think your daughter benefits from that? What he actual ****? This is not an ad, this is a warning.
There has been a remarkable lack of exactly this awareness in presentations – of noticing what kinds of AI uses are life affirming and good, and which ones are… not that.
Bonus points that the athlete in question is named Sydney.
It is true that Google keeps getting the short end of the stick on such questions, whereas other companies as Colin Fraser says ‘get away with it,’ But notice the difference:
Colin Fraser: “You’ll never help your son become a champion,” they said. “You have too many morning calls to summarize.”
Watch me.
Yes, ‘save time on unimportant things’ is a positive good use case.
As is helping with mundane communications, if indeed it helps (I mean how is this faster than sending your own email?):
Whereas a fan letter is very much a thing that is supposed to be personal and is a place we score victory points. I summarize my morning calls with an LLM so that I can write and read the genuine fan mail.
Activate Voice Mode
Early reports are that ChatGPT’s voice mode is quite good, living up to its demo.
Ethan Mollick: Three things about advanced voice on ChatGPT:
It is as good as the demo.
It is clearly capable of producing a lot more audio (I occasionally get sound effects, etc) but there are guardrails
It is super weird. Lots of unconscious cues make it feel like talking to a person.
Voice changes the nature of interaction with AI even though the underlying model is one I have used for a long time. It makes anthropomorphism absolutely inevitable; if you felt a need to be polite to the AI before, this ramps it up by an order of magnitude.
Gonna be interesting.
Tyler Cowen: Open AI Voice mode is very strong at doing “Valley Girl” elocutions, perhaps this will lead to a renaissance of sorts.
The ChatGPT Voice feature is very good.
It is extremely versatile, very responsive to feedback, and has response lags comparable to that of a human, or better yet. Just keep on telling it what to do, if you need to. If you ask it to be better, guess what? It gets better. Her really is here. Now.
Some complain that the foreign voices have American accents, presumably this is from the training data? This will be fixed soon enough. In the meantime, prompt it in the destination language.
It’s happening, and this is to date one of the most vivid and impressive illustrations of what is possible. A mere three years ago this would have seemed like witchcraft.
Commenter: “mere three years ago this would have seemed like witchcraft.”
Evergreen comment on a TC post these days, but these weird, overly enthusiastic proclamations are I think genuinely holding back AI uptake amongst normies, because it just looks like cult-ish hyperbole in the face of little real-world application (yet), hallucinations, general down-sides and existential long-term risks.
Three years ago I was talking to Siri and Alexa just fine. Was it the same as this? No. But is the difference literally almost magical? Of course not.
Zoroto (Commentator): What is it actually good for?
Jay Hancock: Really great for language learners. Conversation partner whenever you want one.
Learning languages and translating them are one clear killer app, and of course sometimes one is not at the keyboard. The feedback is good enough even I am intrigued. But I can’t give a firsthand report because I’m not in the Alpha. Here we have a thread of examples, note how much is about languages and accents.
Which is totally fair, I mean I can and do compartmentalize and decouple a lot and like to think that I can be objective on evaluation of consumer products, but there is a regular section at this point called Openly Evil AI.
I find it fascinating that so many people are citing little details. It makes animal sounds, or can fix its accent, it does vocal warmups, or sings, has quick response times. It can talk like a soccer commentator about making coffee.
That’s all neat I suppose, but does it mean ‘Her is here now’? What can it do? I mean, really do? Does it have context? What can it control or navigate or use? When Tyler says ‘it gets better’ what does he mean here, concretely? The bold claims that matter remain vague.
Things people say they want, that (shall we say) I am not convinced they want.
Flowers: ChatGPT should also be able to interrupt US.
For example, if you are yapping too much and it has already understood what you mean, it could interrupt you and say: Yes, I know, but…
Or if you interrupt it, it could say: “Can I finish my sentence first?” That would be cool.
Apple Intelligence
What is the system prompt for Apple Intelligence? The more you know:
Colin Fraser: Do not hallucinate.
Max Woolf: Broke: prompt engineer Apple Intelligence to reveal its system prompt
Woke: just search for a .txt file containing the prompts lol
Alas, this is Apple, so you cannot alter any of the files.
Instruction #1: “{{ specialToken.chat. role.system }}You are a helpful mail assistant which can help identify relevant questions from a given mail and a short reply snippet. Given a mail and the reply snippet, ask relevant questions which are explicitly asked in the mail.
The answer to those questions will be selected by the recipient which will help reduce hallucination in drafting the response. Please output top questions along with set of possible answers/options for each of those questions. Do not ask questions which are answered by the reply snippet.
The questions should be short, no more than 8 words. The answers should be short as well, around 2 words. Present your output in a json format with a list of dictionaries containing question and answers as the keys. If no question is asked in the mail, then output an empty list []. Only output valid json and nothing else. {{ specialToken.chat.component.turnEnd }}{{ specialToken.chat.role.user}}{{ userContent }}{{ specialToken.chat.component.turnEnd }}{{
specialToken.chat.role.assistant }}”
“schema_raw_v1”
Instruction #2: “{{ specialToken.chat. role. system }}You are an assistant which helps the user respond to their mails. Please draft a concise and natural reply based on the provided reply snippet. Please limit the answer within 50 words. Do not hallucinate. Do not make up factual information. Preserve the input mail tone. {{
Danielle Fong: Things you have to tell yourself to keep it together.
Simon Willson: It’s amusing to see Apple using “please” in their prompts, and politely requesting of the model: “Do not hallucinate. Do not make up factual information.”
I’d been wondering if Apple had done anything special to protect against prompt injection. These prompts look pretty susceptible to me – especially that image safety filter, I expect people will find it easy to trick that into producing offensive content.
Janus: Everyone making fun of [do not hallucinate] is memeing themselves.
This actually works quite well. I’ve used it myself. It’s the least stupid thing I’ve ever seen in a corporate prompt.
There have been so many wonderful opportunities for people to complain about how unbelievably stupid corporate prompts are, but they didn’t, and the one time it’s not actually stupid they do… why?
Andrej Karpathy: It probably works better and better over time because newer models are pretrained on a lot more recent content about hallucinations so they understand the word / concept quite well. The first generation of LLMs would not have had this advantage.
Janus: Yup! Also just the models’ raw inference ability and self awareness.
A “system prompt” with something similar to “do not hallucinate” worked very well to make gpt-4-base simulate a “factually grounded” assistant model, but didn’t work nearly as well on weaker base models
It would be cool to be able to play with these settings. Adjust how many words are in various prompts and replies. Set what tone to use for replies. Suggest particular areas of focus. Apple does not want to let you have this kind of fun, which in practice likely matters a lot more than whether the model is open.
There are some more prompts at the link.
Antitrust Antitrust
Judge rules that Google is an ‘illegal monopolist.’ Full decision here.
The decision says that Google’s exclusive distribution agreements in search violate Section 2 of the Sherman Act, and that they used their monopoly pricing power to increase their fees on advertising. Ruling could have been far worse for Google, they won on various other points and avoided sanctions.
This is a relatively narrow lawsuit and ruling, and Ben Thompson frames it as an unusually sensible approach to antitrust enforcement by the DoJ. It does not sound like there is much danger they will ‘break up Google’ or anything like that, even after all the appeals. More likely we may see things like the courts invalidating Google’s distribution agreement with Apple and other device makers, and things like demanding ‘equal placement’ for other search engines and allow easier switching of defaults.
Brian Albrecht offers analysis. He notes lots of references to behavioral economics, yet no discussion of how that interacts with competition. There is confusion about whether defaults are strong or weak (Bing is even the default on Windows, how is that working out), about whether there is innovation (if you think search isn’t innovating you do not know how any of this works, and also Microsoft is cited as improving), and more Obvious Nonsense.
This might even be good for Google. What would happen if Google was forbidden to pay for placement going forward, as seems likely?
Right now, Google ships Apple $20 billion a year for search placement, because Apple can credibly threaten a switch and demand a share of the profits. But if Google is not allowed to pay Apple, or is restricted on how it can pay, then is Apple going to try to push Bing or another rival on us to get a payment? And have Android be ‘the phones that by default have Google search’?
That doesn’t seem like it would go great for Apple, unless you think that Google search has gotten worse than its competitors. Apple has repeatedly said that Google’s offering is superior. So it’s plausible that Apple has kind of been running a $20 billion a year extortion racket and bluff, and the government just called them on it. Whoops?
This is even worse for Mozilla which stands to lose 80% of its revenue, and others who depend far more than Apple does on Google’s payments. What happens to them now?
So indeed it makes sense that Google stock did not move much on the ruling.
The danger for Google would be if Apple now decides to compete in search, now that this won’t involve them giving up the sweet Google payments that used to be 17%-20% of their profits. Perhaps they dare. It would take a while, presumably, to get good.
My prediction would be that the consumer welfare implications are negative, even with the decline in Google search quality over time. It is not only easy to switch defaults, other companies actively try to trick you into doing it without realizing. This whole case feels like straight up enemy action.
Copyright Confrontation
Leaked slack messages show Nvidia employees discussing which YouTube channels to scrape for content, with high level approvals.
Jason Keller: “We need a volunteer to download all the movies,” one senior NVidia employee said. “We have to be very careful about Hollywood hypersensitivities against AI.” Approval to download at scale framed as “an executive decision. We have an umbrella approval for all of the data.”
Here, Nvidia employees discuss specific YouTube channels they want to scrape, including @MKBHD‘s (“super high quality”).
“Should we download the whole Netflix too? How would we operationalize it?”
No one should be surprised Nvidia did this. The news is all about being caught.
What they are now training at Nvidia is supposedly a new frontier model called ‘Cosmos’ that ‘encapsulates simulation of light transport, physics and intelligence in one place to unlock various downstream applications.’
Of course Nvidia’s AI project would be a ‘a more realistic physics engine,’ why not.
Fun with Image Generation
If you are counting on an image as verification of much of anything, maybe don’t?
Or maybe do, because this was always easy enough to fake if you cared? Not sure. I mean, we are all familiar with all the Green Screen Fun and I don’t see why you need a good text model to pull this trick?
Chubby: I didn’t think we would reach this level of textual accuracy so quickly. In fact, it now presents us with serious challenges. Reddit, for example, relies on precisely this text verification, which is now probably obsolete. It is questionable whether there will still be ways to distinguish AI (or bots) from real people in the future.
Colin Fraser: Reddit, for example, relies on precisely this text verification. It’s what powers the site.

In response, Vitalik Buterin confirms you should ask security questions when you care about identify verification.
Alas, when I call the bank, I am told ‘your voice may be used for verification.’
Seriously, no. Do not do that.
Deepfaketown and Botpocalypse Soon
WSJ reports that OpenAI has been sitting on a tool to reliably detect ChatGPT outputs for a year, but not releasing it because nearly a third of ‘loyal ChatGPT users’ would be ‘turned off by the anti cheating technology.’
Deepa Seetharaman (WSJ): Employees who support the tool’s release, including those who helped develop it, have said internally those arguments pale compared with the good such technology could do.
…
OpenAI Chief Executive Sam Altman and Chief Technology Officer Mira Murati have been involved in discussions about the anticheating tool. Altman has encouraged the project but hasn’t pushed for it to be released, some people familiar with the matter said.
ChatGPT is powered by an AI system that predicts what word or word fragment, known as a token, should come next in a sentence. The anticheating tool under discussion at OpenAI would slightly change how the tokens are selected. Those changes would leave a pattern called a watermark.
The watermarks would be unnoticeable to the human eye but could be found with OpenAI’s detection technology. The detector provides a score of how likely the entire document or a portion of it was written by ChatGPT.
The watermarks are 99.9% effective when enough new text is created by ChatGPT, according to the internal documents.
“It is more likely that the sun evaporates tomorrow than this term paper wasn’t watermarked,” said John Thickstun, a Stanford researcher who is part of a team that has developed a similar watermarking method for AI text.
…
In April 2023, OpenAI commissioned a survey that showed people worldwide supported the idea of an AI detection tool by a margin of four to one, the internal documents show.
I really hope that Stanford researcher is not in the statistics or physics departments. Still, 99.9% effective is pretty damn good.
Loyal ChatGPT users often very much don’t want there to be effective watermarking. Others do. I have a hunch what accounts for this difference.
I joke about calling them ‘Openly Evil AI,’ but developing a 99.9% effective watermarking tool and then sitting on it because people identifying your outputs would be bad for business? Yeah, that’s something.
Sharika Soal decides to do a deepfake of Trump with various AI-generated eerily similar black women to… try and help him, presumably, given her feed? The details are not AI image generation’s finest hour. Gets 1.9m views. Get used to it, I guess.
404 Media points out that the reason we have so much AI slop on Facebook is that Facebook is paying directly for likes, and quite well. Reports are you can get from $3 to $10 or more for 1,000 likes, and you live in the third world and can generate endless AI pages to get such payments, that’s mighty tempting. Soon, you have an entire ecosystem of instructional videos and courses, and tools like FewFeed to enable mass production, because the internet is very good at all that. This is the evolution of existing problems and trends.
He suggests a prompt to get viewers started: “poor people thin body.”
You get exactly what you pay for, the same way an LLM gives you what you reinforce. This is exactly what misalignment will often look like.
It is also what red teaming looks like, if Facebook was actually using the results to improve its robustness. If it is, it’s not going a great job. None of this seems subtle, and none of this seems hard to detect.
Notice that if you don’t engage with the AI slop, then Facebook stops sending it to you. Whereas if you do engage, you get flooded with it. What does that mean?
Among other things, it means the detection problem is solved. Facebook knows damn well what the giant piles of AI slop are. It pays and serves them up anyway.
What generates the photos? Reports are it is often the Bing Image Creator, not that Microsoft is doing anything wrong here.
They Took Our Jobs
Your periodic reminder, if the AI does your job, it is still your job, so long as no one else knows.
Garry Kasparov: First they are funny toys, then they’re our competitors, then they are superior forevermore. The competition window is tiny in perspective, but it dominates our vision. But “losing” isn’t the end, it’s the beginning of a new world of powerful tools that we very much need.
I’ve been hearing “AI is coming for your job!” since 1996, when I first faced Deep Blue as the first knowledge worker whose profession was supposedly menaced by computers. Humans still play chess, by the way! We must be creative and ambitious, not in denial.
‘The competition window is tiny’ is a key concept to understand, on every level.
The AI will be superior forevermore.
Humans still play chess, because we choose to care about that. We find value in it. Wonderful, I love that for us, pure upside. But to the extent that good chess moves were in some real sense ‘productive’ in the way engineering or farming is productive, or there is a job ‘play chess as well as possible by any means you have,’ then humans are no longer doing those jobs, period. For most professions, the parallel is not great, you are left with humans only doing things when other humans care that a human is the one doing them. And the AIs do a lot of exporting without doing any importing.
Your periodic reminder: For now, humans can find some other task to move on and do instead. And there are lots of such jobs ‘waiting in the wings’ for humans to do, and always have been. This is why we can automate most past jobs starting with farming, and still have full employment, and allow most humans to earn their keep. But what happens when the AI can dominate those jobs forevermore, too?
The piano tuner, who fixes a problem even one of the musicians couldn’t even hear, as an example of how you mostly don’t know how to notice when and how things are wrong. And the author warns about what happens when a robotic piano tuner (which is obviously possible and presumably coming, right now they exist and work for casual play but aren’t quite at professional level) takes over this service.
But what is the problem, exactly? The robotic tuner will be arbitrarily accurate. It will cost very little. And multiple people who weren’t piano tuners noticed the issue, so why would they then stop noticing? Or, if an automatic system simply ensures the pianos are always tuned properly, do they need to notice? Who cares?
(And if no one ever notices, then again, does it matter? Tree falls in forest.)
Chipping Up
If you want to do export controls you have to enforce them. When a single smuggled shipment of chips is worth more than your entire enforcement budget, that’s hard. The New York Times reports it is not going so well. We seem to be fine with Nvidia essentially opposing us on this rather than working with us. Will that change?
Here’s an alternative proposal: IAPS claims that for only $1 million, we could set up for several years a delay-based pure-software monitoring system to see where the chips are located.
Full Report’s Executive Summary: Adding location verification features to AI chips could unlock new governance mechanisms for regulators, help enforce existing and future export controls by deterring and catching smuggling attempts, and enable post-sale verification of chip locations.
Delay-based schemes appear to be the most promising approach to location verification. Combining such a scheme with additional governance mechanisms, such as a centralized chip registry, would provide regulators with more effective tools to verify that chips are not deployed in restricted locations.
Compared to more commonly utilized methods like GPS, delay-based location verification would be difficult to “spoof,” i.e., falsify. While delay-based location verification is much less precise than GPS, it is still sufficiently precise to be useful for export control enforcement.
…
Our main finding is that it seems both feasible and relatively cheap to implement pure-software delay-based solutions on chips in the near future. These solutions are likely to aid current AI chip export control enforcement efforts. A solution of this kind would likely cost less than $1,000,000 to set up and maintain for several years. Chip design companies should consider taking the initiative by experimenting with this technology on chips that are at a particularly high risk of diversion. More proactive use of technology to prevent the diversion of chips could bolster international trade by reducing the need for broad country-level export bans or license requirements.
The chip companies will not take the initiative because they do not want to be able to track the chips. We will need to force their hand.
Get Involved
Safeguard AI, Davidad’s effort to build AIs with safety guarantees, adds Yoshua Bengio, and they have an informal call for Expressions of Interest in forming a new nonprofit AI lab with seed funding, and a formal call for proposals for applications partners to build domain-specific products.
Introducing
Gemma Scope, an open suite of Spare Autoencoders for Gemma 2B & 9B.
OpenAI introduces structured outputs in the API, to allow outputs to exactly match JSON schemas.
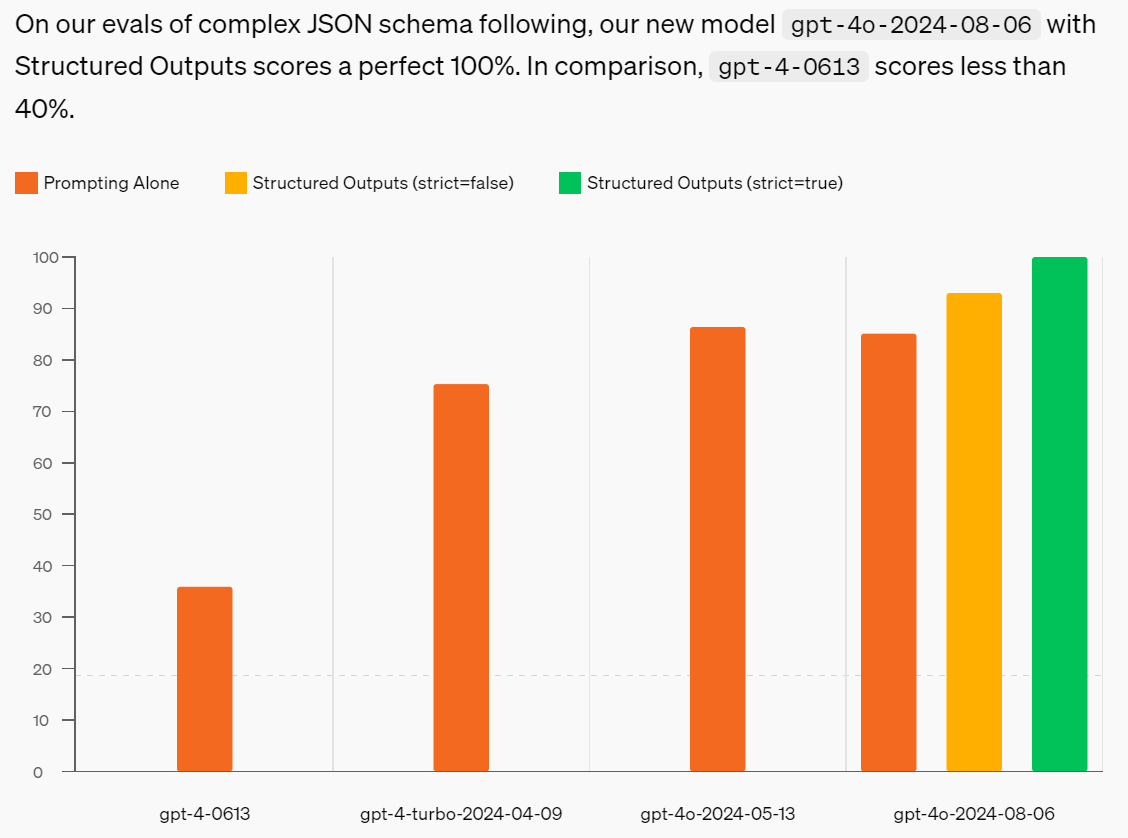
How did they do it?
OpenAI: While sampling, after every token, our inference engine will determine which tokens are valid to be produced next based on the previously generated tokens and the rules within the grammar that indicate which tokens are valid next. We then use this list of tokens to mask the next sampling step, which effectively lowers the probability of invalid tokens to 0. Because we have preprocessed the schema, we can use a cached data structure to do this efficiently, with minimal latency overhead.
Throw out all invalid outputs, and all the outputs that remain will be valid. Nice.
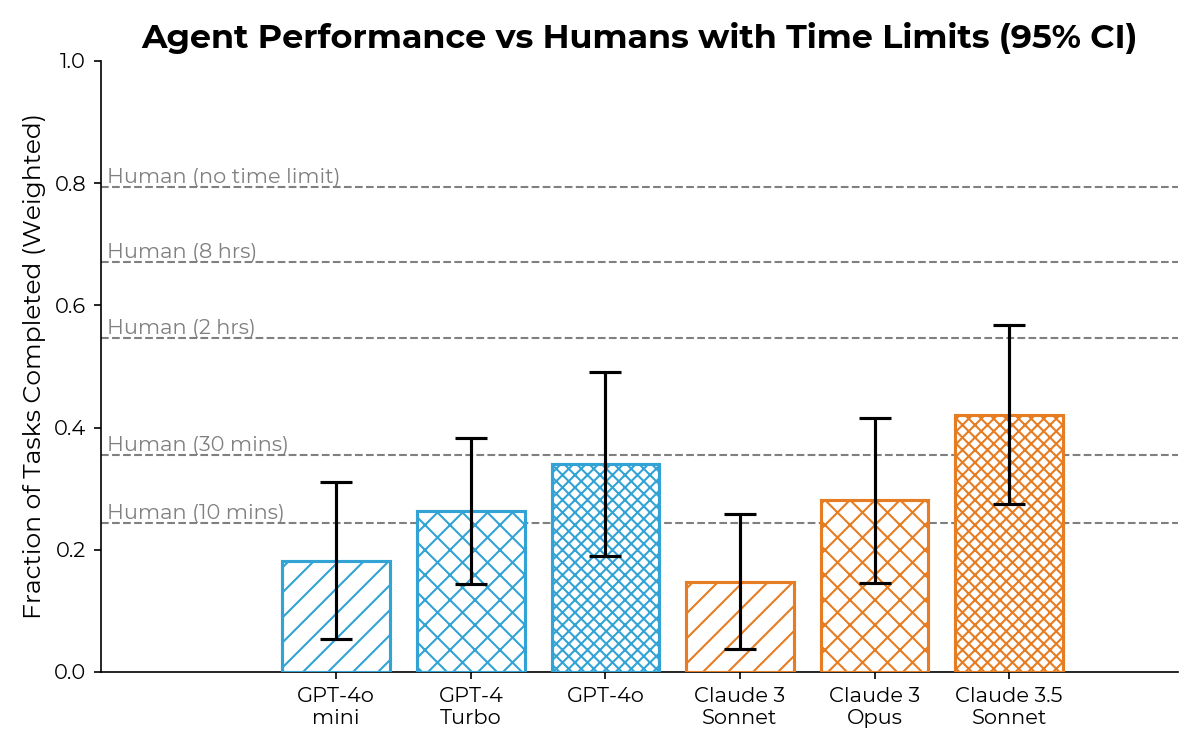
As you would expect the agents do some things better than humans, some things worse. They are continuing to work on their tests.
Rendernet.ai, a YC company which will let you create an AI character (or ‘influencer’) and then give it various images and video and so on, in a way that presumably a normal person can use and easily customize, using ControlNet and such.
Thrive IX will be investing over $5 billion in new tech companies. Altman approves.
In Other AI News
Intel suspends dividends and is reducing headcount 15%. Does this mean we made a better or worse CHIPS Act investment in them? At least we know none of it is going to dividends, and they are plausibly ‘funding constrained.’
Nvidia Blackwell chips delayed by three months or more due to design flaws, seems this was known over a week earlier. So presumably unrelated to the market correction.
OpenAI will not be announcing a new model on demo day this year.
Gemini Flash to reduce prices on August 12 to $0.05/million tokens, versus $5/$15 for GPT-4o, $0.15/$0.60 for GPT-4o-mini, $3/$15 for Claude Sonnet 3.5, and $2.70 as lowest known for Llama-3.1-405B a few weeks ago.
Google buys the services of Noam Shazeer and Daniel DeFreitas, who previously left Google to found Character.ai, along with their 30 person research team.
This includes a non-exclusive licensing agreement between the two companies.
Sucks: literally how much would they have to pay him to leave one of the hottest ai companies? 50m a year? more? whats the incentive for him outside money? more access to compute?
Anton: character ai’s users really want the models to be horny. noam really really doesn’t want the models to be horny. google have never made a single horny product in the entire history of the company; he’s going to be safe from horny there.
There is actually an enormous opportunity in making the models horny, beyond the obvious.
Alternatively, Google desperately needed the world’s leading expert in ensuring models aren’t horny, while Noam gets to take his War on Horny to new heights.
And he buys character.ai important new ammunition. With this deal he gets to use Gemini as the baseline of Character.ai, which seems like a better long term strategy than going it alone or counting on Meta or another open model to keep pace and play nice at scale, remember that the Llama license stops being free at some point. From the inside, they can customize exactly what they need.
Google offers massive distribution advantages. At the limit, they could directly incorporate character.ai’s features into Gemini, so you seamlessly switch between the ‘AI assistant’ character and all the others. Make Einstein your Pixel’s virtual assistant, or maybe you prefer Lieutenant Simon “Ghost” Riley, Nakuno Miku or God.
(Which were the top three ‘for you’ choices at character.ai when I went there, although I flipped the last two for Rule of Three.)
Great alliance.
Especially if everyone involved wants to fight the War on Horny.
The historical way to do this is ‘Google buys startup’ similar to how Microsoft would have used ‘Microsoft buys startup’ for Inflection. A plausible problem is that antitrust regulators are clueless, forcing upon us other methods, although James Rosen-Birch thinks this is laughable.
Roon: This character.ai implosion is ftc antitrust carnage. In a sane world Google would have acquired the whole company and all the employees would have made out well. Instead they have to gut it for its core talent and leave everyone else in the dying husk of the company. This warps capital markets and discourages innovation of all kinds. Potential startup employees will be looking for big tech jobs instead. Total own goal.
Nvm I hear Google is paying character employees even without acquiring them. Don’t be evil.
It seems this applies to all investors, who are slated to be paid off at a 3.5b valuation (proper citation still needed).
The optimistic version is that perhaps the investors were never so big a concern, because venture capital only cares about the big wins. If the modest acquihires pay the employees but not the investors, then the investors can get a slightly bigger share of the equity and thus the big wins, while the employees are still better off since they can now be acquihired more readily and get paid. Efficient win-win transfer of risk and upside?
The problem as Roon notes is that this also risks leaving companies like Inflection and Character.ai as mostly hopeless shells with the rest of the employees stuck in limbo. And the other problem is that this sets up a huge conflict between the valuable employees and the holders of shares.
Who will fight for the people?
There is speculation of anti-trust action, but given that Google is arguably getting its lunch eaten right now that seems rather silly.
As of last week no one was hosting the Llama-3.1-405B base model? At the time this was free money, but capitalism abhors available free money, so now it’s available.
DeepMind has finally figured out the right rule for when to publish?
Typed Female: Heard a deepmind researcher got mad they were given permission to publish since it was an implicit admission that their work was considered worthless.
Dan Hendrycks and others find in a meta-analysis that ~50% of safety benchmarks fail to measure safety progress, with many being essentially capabilities improvements. This matches what passes for ‘safety’ work, which often ends up being work on capabilities as well.

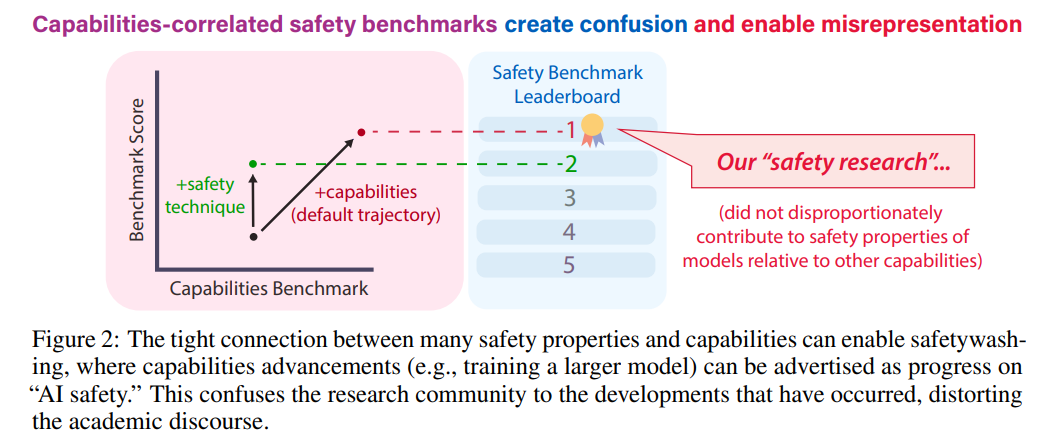
The core technique was a principle component analysis, using standard capabilities benchmarks for the capabilities side, and checking how a safety benchmark correlates with capabilities.
Different categories of test scored very differently. ‘Alignment’ and misconception based benchmarks are heavily capabilities weighted by correlation, as is Moral Knowledge, but Machiavelli and Sycophancy and jailbreaks and weaponization tests are negatively correlated, with Bias benchmarks closer to a wash. Scalable oversight evaluations and ‘natural adversarial examples’ are almost purely capabilities, for rather obvious reasons. Brier Scores are almost exactly capabilities (95%+ correlation), but RMS calibration was measuring something different.
The tests with negative correlations are kind of sign flipped – they are testing capabilities in an area where you don’t want to find them, except that more capabilities gives you a lower score.
The key question is, do the positive correlations correspond to problems that will solve themselves with more capabilities? In some cases, presumably yes? For example: If you care about Brier scores and calibration, then that seems like it should clearly fix itself as models get smarter. If you want your AI not to have misconceptions, ‘make it smarter’ again seems like an excellent solution. In some ways, one can relax.
Then there are places where there is a behavior that gets more effective and stronger as the model gets smarter, such as weaponization or sycophancy (including most deception), except that we do not want the model to do that. Those problems will keep getting harder, and our current techniques will stop working. Note that this includes jailbreaking, which seems to already be clearly getting harder not easier to stop despite a lot of effort to stop it.
We also have to ask exactly what we are measuring and whether it is what we care about, and whether that turns around at the limit. For ‘natural adversarial examples’ the AI getting it ‘wrong’ right now is almost purely a bug not a feature from the perspective of how the AI gets evaluated and what happens to it on every level, a side effect of something else, but is that true in the scenarios we care about?
Alignment in particular is a place where certain kinds of it get easier, as in it will get better at satisfying whatever corresponds to the exact incentives provided within the distribution given, but beware that this stops being the alignment you want at the limit for several reasons. I think a lot of people are confusing these two things, and not seeing the pattern where being smarter means you better match the specifications, and for a while that means you get what you were trying to approximate, and then things get too clever and suddenly they don’t match at all.
So we have a benchmark problem, but I think it is more importantly a symptom of a much deeper problem. And the symptom can be highly useful.
Simeon reacts by pointing out that it is easy to measure high-frequency safety failures, which are usually low severity, so that is what most tests measure, and these failures tend to be of the form ‘the model is too dumb.’ So they correlate highly with capabilities, and they get easier over time.
Whereas the main worry should be low-frequency but high severity failures. These tend to be of the form either ‘the model is too smart’ or ‘there was a subtle misinterpretation or things went otherwise wrong far out of distribution.’ And those get more relevant, more dangerous and harder over time as capabilities advance.
Whoops.
Thus it is easy to treat capabilities advances as evidence of improved ‘safety,’ when that is not true in the ways we care about most. This includes mundane issues – the model is now more robust in ‘normal’ situations.
Coauthor Richard Ren offers his summary in a thread.
FT’s Madhumita Murgia has the latest post covering Helen Toner and how she relates to various events at OpenAI, including the events last year when the board fired Altman. The post calls that a ‘coup’ even though it wasn’t one, because Altman’s side won the rhetorical battle over that. I did not learn anything new.
Quiet Speculations
Mark Zuckerberg says Llama-4 will be trained on ten times the compute of Llama-3, he’s aiming for the best model around and he’s rather use too much compute rather than too little. If you believe in the underlying business model, and presume you are not going to enable catastrophic harms, and have Meta’s bankroll, then sure, no reason to be cheap with the compute.
Also this isn’t that much. Only stepping up by one OOM in compute, to ~3.8*10^26, actually does not seem that ambitious? I’d expect this to be well behind GPT-5.
Joel Miller asks five people in ‘the humanities’ the same questions about AI and how it relates to the humanities. To paraphrase Peter Thiel in a way several of them note, and to quote a great work of art, Deadpool & Wolverine, there was a very clear message throughout, which some of them have ears to hear: You don’t f***ing matter. And the ‘you’ here was not the reader, it is the authors, and the humanities. Their concerns, their questions, all seem increasingly irrelevant, as they grapple with what has been without even considering what could and doubtless will soon be. And they seem to know it. There are other deeply important things that the humanities deals with, but they seem unable to focus on those questions.
Roon: Distributing model weights and making the technology easy to access aren’t actually equivalent. The vast majority of people who come into contact with an AI do so with an LLM provider like OpenAI or Google and this would be true even if OSS models were strictly better.
If you want to overcome the standard distribution channels and UI and customization work, you’re going to need to be ten times better, or allow companies like Google or Apple to use it for free (which is not the case for Llama). Corporate use could be a more level playing field, where being fully customizable and the ability to run locally and securely without sharing data are big advantages. But open model advocates, I think, reliably greatly overestimate how much everyone actually cares about all that. If Google or OpenAI or Anthropic offers an easier to use product that gets it done, well, these people aren’t rolling their own email servers either, nor should they.
Timothy Lee objects that no one can physically tell him what double-digit growth rates would look like, let alone exactly what ‘1,000x GDP growth’ looks like. Why are the models so simplistic? The obvious answer is that you are dealing with new technologies and things that are smarter than you, so trying to pin down lots of details is foolish – when (for a prime example) Carl Shulman tries to do so it is helpful to consider but also it’s pretty weird. There’s way too many huge unknowns. You have to make some very important (potentially very wrong) assumptions to get anything concrete. What Lee doesn’t do is make the mistake of ‘you don’t fill in the details so I should assume this won’t happen,’ which is common. And yes, we should at least be making distinctions like ‘AI does all things that are digital-only’ versus ‘AI does all physical things too.’
Some recent (about a month ago) AI skepticism, which at least chose a plausible time to get skeptical?
Parmy Olson at Bloomberg says AI getting cheaper ‘won’t solve everything,’ because it will take a few years to capture the mundane utility. Well, sure. Costing ~$0 does not make something useful right away. Still takes time. It’s a hell of a good start, though.
If you want to be an AI skeptic, I suppose this would be the week for it, given what’s happening in the stock market?
Roon: Dad why are we poor? Well son there was a minor market panic and I sold everything right before the technological singularity and now we’re part of the permanent underclass.
They wouldn’t be poor in that scenario, they would be less rich than others while being richer than we are today, the same as we today compare to the past. Assuming, that is, that ‘economic normal’ still somehow held and having shares in the companies still meant something.
The Quest for Sane Regulations
A reader emailed me to say that about 30 AI bills passed one chamber in California the week of May 24 because they wanted to dodge the deadline to keep bills alive, and was happy to punt all responsibility to the other chamber (and Newsom). So mystery solved, although not in a good way. Wow.
SB 1047 is soon going to get modified by one final committee, after which we will know to what extent Anthropic’s proposals were incorporated and other changes made. I’ve been informed that there is still the possibility of changes on the floor later on, so the saga will still not quite be locked into place.:
Someone is buying anti-SB 1047 ads on Twitter that are 100% false, including the utterly bonkers claim that Google and Meta are backing the bill. Both are opposed.
Future of Life Institute calls out Anthropic for trying to significantly weaken SB 1047.
I was sad to see that Fei-Fei Li is presenting a severely misunderstood version of the contents of SB 1047. Her editorial in Fortune warns that SB 1047 would hurt open source and academia and ‘little tech,’ but none of that is accurate, and in particular all the mechanisms she cites are misinformation, repeating a16z talking points. This includes the standard objection that open models are incompatible with the shutdown clause. Whereas the shutdown clause has a very explicit exception to ensure this is not true.
I would like to chalk this up to honest misunderstanding, but I also note her startup was recently rather heavily funded by a16z. Is a16z conditioning its investments on such advocacy, implicitly or explicitly? Say it isn’t so.
This Time article discusses a letter by academics (‘renowned experts’) in support of SB 1047, pointing out among other things that the bill’s provisions flat out do not apply to academics, and that concerns about the ‘kill switch’ impacting open models are misplaced because it does not apply to copies not under your control.
That’s Not a Good Idea
Ari Cohn: Today the Senate Committee on Rules & Administration marks up 3 bills about AI & Election-related speech.
Yesterday, @TechFreedom, @ACLU, @TheFIREorg, @EFF, @ceidotorg, & @CalPolicyCenter warned the committee that S. 2770, which bans candidate deepfakes, is unconstitutional.
Obviously intentionally deceptive speech in elections isn’t desirable, but that doesn’t mean the government has the authority to declare that some political speech is off-limits.
And it certainly does not have the authority to sweep up true speech, opinion, or speech that would be entirely allowed if AI wasn’t used to create it.
Sen. Klobuchar just tried to UC her bill to ban “misleading” speech about political candidates created with Generative AI.
When @SenatorFischer objected, noting the First Amendment issues we raised, Sen. Klobuchar’s only answer was that Josh Hawley surely wouldn’t cosponsor an unconstitutional bill.
To which I say: lol. lmao.
Are the bad ideas kicking into overdrive, or is this them getting noticed more?
Shoshana Weissmann: Has
Has she read anything he’s written or
It’s very short so for kicks I read the bill. The wording here is rather ludicrously broad. The key provision is the definition of deceptive AI-generated Audio or Visual Media, distribution of which is mostly prohibited when in the context of a Federal election. Especially look at (B)(i) here:
“(2) DECEPTIVE AI-GENERATED AUDIO OR VISUAL MEDIA.—The term ‘deceptive AI-generated audio or visual media’ means an image, audio, or video that—
“(A) is the product of artificial intelligence technology that uses machine learning (including deep learning models, natural learning processing, or any other computational processing techniques of similar or greater complexity), that—
“(i) merges, combines, replaces, or superimposes content onto an image, audio, or video, creating an image, audio, or video that appears authentic; or
“(ii) generates an inauthentic image, audio, or video that appears authentic; and
“(B) a reasonable person, having considered the qualities of the image, audio, or video and the nature of the distribution channel in which the image, audio, or video appears—
“(i) would have a fundamentally different understanding or impression of the appearance, speech, or expressive conduct exhibited in the image, audio, or video than that person would have if that person were hearing or seeing the unaltered, original version of the image, audio, or video; or
“(ii) would believe that the image, audio, or video accurately exhibits any appearance, speech, or expressive conduct of a person who did not actually exhibit such appearance, speech, or expressive conduct.
As I understand it, this means that if AI-generated material would change someone’s impression or understanding, even if they are not deceived, then that would count here? Banning that does seem rather unwise and also unconstitutional to me.
And yeah, the idea that Hawley (or any other Senator or lawmaker) would never write an unconstitutional bill? I would say ‘Lol, lmao even’ so Ari is very on point.
Here is the latest warning that the EU AI Act might have ‘gone too far,’ or the bar ‘set too high.’ I got reasonably far into analyzing the EU AI Act before another big project took priority, and hope to return to that in September. There certainly are a lot of complicated rules and requirements there, and a lot of them to me make little sense. The EU is, as usual, mostly worried about all the wrong things. This is what happens when you try to mostly address particular use cases rather than the models, and yes you will eventually have to do at least one of those. There are also the distinct rules for the biggest models, but the ones I most worry will actually be painful there are aimed at things like rights to training data.
The Week in Audio
You can now listen to my posts in podcast form via Apple Podcasts, Spotify, Pocket Casts, and RSS.
Nathan Young and Robin Hanson discuss AI risk.
Joscha Bach says AI ‘may self-improve to such an extent that it can virtualize itself on to every substrate in nature, including our own nervous systems and brains, and integrate us into a planetary-scale intelligence.’
Except, if it self-improved that much, what good are we doing in that intelligence?
Nick Bostrom warns long term investments like college or PhDs might not be worth it because AI timelines are too short (among doubtless many other claims). If you are looking to impact AI outcomes and stop us all from dying or avoid dystopia, then I see this possibility as a strong argument.
However, if not, then I think under uncertainty you need to be prepared for more normal scenarios. I stand by my Advice for the Worried, and most of it also applies to the Excited and Unworried. You do want to position yourself to capture upside, but if you are confident that transformational AI is only a few years away, either you know things I very much do not know, or that confidence is unearned.
Elon Musk talked to Lex Fridman for 8 hours about various topics. Musk gets that AI existential risk is a big deal, but he’s still going on about ‘adheres to truth’ as a solution. I am a big truth fan but I do not understand in this context why that would be sufficient? A hint is that the sentence ends ‘whether that truth is politically correct or not.’ Which indicates that Musk does not actually grasp the problem. I also increasingly notice that for someone who says they care so much about truth, well, whoops.
Exact Words
It is so easy to be fooled into thinking there is a commitment where there is none.
Tech Chrunch (Kyle Wiggers): Headline: OpenAI pledges to give U.S. AI Safety Institute early access to its next model
The timing of OpenAI’s agreement with the U.S. AI Safety Institute seems a tad suspect in light of the company’s endorsement earlier this week of the Future of Innovation Act, a proposed Senate bill that would authorize the Safety Institute as an executive body that sets standards and guidelines for AI models.
Let the record reflect that OpenAI made no such commitment. As noted last week, what Altman actually said was that they were ‘working with the US AI Safety Institute on an agreement.’ That is good news. It is not an agreement. In all such situations, even when everyone is in good faith, nothing is done until everything is done.
So what are the bills that OpenAI is known to be endorsing?
According to Tech Crunch’s Maxwell Zeff, they are the Future of AI Innovation Act (S.4178), the NSF AI Education Act (S.4394) and the Create AI Act (S.2714).
As you would imagine, the Future of AI Innovation Act is primarily about ‘innovation’ and ensuring AI goes faster. Included is the crafting of voluntary safety testing standards, but I don’t see any sign that they could not simply be ignored, or that they will in any way be aimed at preventing critical harms or existential risks, or that anyone involved isn’t primarily focused on ‘promoting innovation.’
I can’t do a full RTFB on every bill, but a quick skim of S.4178 says Title I section A centrally empowers AISI to create voluntary standards, metrics and evaluations, which if inconvenient can be ignored. Section B is about suggesting the idea of international cooperation, focusing on unification of standards including safety standards, but treating this no different than any other technology. Section C asks to ‘identify barriers to innovation.’
Then Title II actively does things to accelerate AI development via data sets and grand challenges. One list includes generic ‘safety’ as one of many topics. That’s it.
I would have to do more work before being confident, both careful reading and analysis of implications, but overall my guess is this is a net positive bill. Authorizing and funding the US AISI is of vital importance.
If we create a good voluntary framework, at minimum that gives us more visibility, and allows us to build up tools and expertise. That’s a big deal versus not having it. OpenAI is saying they will voluntarily cooperate. So if a company making a plausibly frontier model (such as Meta) refuses to use the framework or grant advance access, that would at minimum be a strong signal to the public and to the government that they face a hostile force. And either in response to that or otherwise, we could make the system less voluntary in the future, once it was better established and it was clear that this was necessary.
Could the bill be a lot better? Oh, definitely. This still seems clearly far better than nothing, and given the political situation I sure expected nothing in 2024. The worry is this might preclude something better, but I don’t think that dominates here.
So it is good that OpenAI supports this bill. It is also an easy bill to support.
The second bill, S. 4394, is ‘to support NSF education and professional development relating to artificial intelligence.’ They intend to do that by giving money for various AI education initiatives, including guidance for introducing it into K-12 education, and a section to emphasize it in community college and vocational schools.
It is even easier to see why OpenAI would support that one. Who wouldn’t want government money to train workers to use their products?
The third bill, S.2714, establishes the National AI research Resource. This is clearly meant primarily as a way to once again ‘spur innovation’ and ‘improve access’ on AI, although it does aim to (as a 4th goal of 4) support ‘testing, benchmarking and evaluation of AI systems developed and deployed in America.’
This seems straightforwardly to be Free Government Money for AI, essentially more central planning, except also in favor of More AI. I do not think the public would be pleased, and in general central planning is not needed. With so many billions going into AI, and AI deeply unpopular, why should the government be giving out additional funds, even setting all safety concerns aside?
The answer of course is ‘innovation,’ ‘competitiveness’ and ‘beat China,’ which Congress continues to think are things that happen because it makes them happen.
Tentative evaluation is that the second and third bills are pork barrel spending, with the AI industry being given gifts from the public till. They are not especially harmful to safety or anything, just bad policy. And they are bad in ways that all those I continuously debate on such issues would agree are bad, for any other industry.
I can see a strong case for government action on chips (e.g. a good version of the CHIPS Act), or for promoting the building out of the electricity grid, although for the grid the right move is very clearly ‘get regulatory barriers out of the way’ rather than giving out cash. There are clear reasons why those are coordination problems, with positive externalities and national security concerns. These bills feel different.
I would however happily trade such bills and investments in order to get other things I care about more, especially around AI safety and existential risk, but also ordinary good government policies. This is normal politics. These are normal bills.
Openly Evil AI
Zach Stein-Perlman updates on the extent to which what happened with GPT-4o’s evaluation met the commitments in the OpenAI Preparedness Framework. They did not comply with the commitments, and did not admit they were not doing so. Their choices were in-context reasonable on practical grounds, given this was not a substantial leap over GPT-4, but if you make exceptions to your safety rules you really need to be clear on that.
He also notes that OpenAI has now responded to the letter from several Senators.
So what do they say?
Well, on the first question of the 20% commitment, they flat out repeat Altman’s lie:
OpenAI: To further our safety research agenda, last July we committed to allocate at least 20 percent of the computing resources we had secured to AI safety over a multi-year period. This commitment was always intended to apply to safety efforts happening across our company, not just to a specific team. We continue to uphold this commitment.
No, you did not say that, you lying liars. You committed the 20% to superalignment, to the safety of future more capable models. You do not get to count efforts to align current models in order to make them more useful, and then say you kept your commitment.
Once again, here is the original commitment (bold mine):
We need scientific and technical breakthroughs to steer and control AI systems much smarter than us. To solve this problem within four years, we’re starting a new team, co-led by Ilya Sutskever and Jan Leike, and dedicating 20% of the compute we’ve secured to date to this effort.
Mostly they talk about the standard things they do and have. They talk about the preparedness framework (which they didn’t hold to on its only test so far) and deployment safety board (with no reason for us to think it has any teeth). They cite the ‘voluntary commitments’ they made, without evidence they have kept them. They cite having endorsed S. 4178, see that section.
They do make the substantial point that they have held back their voice engine, and also Sora their video engine, at least partly out of safety concerns. These are real actions to their credit, but also are mundane safety concerns and there were real practical reasons to hold back.
For security (and cybersecurity) they cite bringing in General Nakasone and some research grants and collaborations and their stopping API accounts of some hostile operations.
For employment practices they point out the changes they made, and they do hard commit to not enforce non-disparagement agreements unless they are mutual (which means they could still insist on mutual ones as worded). They confirm they won’t ‘void vested equity’ but don’t affirm here the right to actually sell or profit from that equity. For whistleblowing they cite their handbook, and a new ‘integrity line,’ but don’t address or admit the fact that their previous contracts and conduct were very clearly in violation of the law, or explain why anyone should believe they are safe to speak.
And that’s pretty much it.
When someone gives you a list of questions, you should reply with a list of answers, not a list of general statements that purport to include the answers. If we translate to actual answers here, what do we get?
The senator’s questions, abridged:
Do you plan to honor your public commitment of 20% of compute to safety?
If so, provide steps you have or will take to do this.
If not, what percentage are you devoting to safety?
Will you confirm you will not enforce your non-disparagement agreements?
Will you commit to removing other employment agreement provisions that could be used to penalize employees who raise concerns, such as the ability to prevent participation in tender offers?
If not please explain why, and what internal protections are in place.
Do you have procedures for employees to raise cybersecurity and safety concerns? What happens once they are raised?
Have employees raised concerns about cybersecurity practices?
What procedures are in place to secure OpenAI’s models, research and IP?
Does OpenAI follow the strict non-retaliation policies in its own supplier code of conduct?
If yes, describe the channels for this.
Does OpenAI allow independent experts to test and assess the safety and security of OpenAI’s systems pre-release?
Does OpenAI plan to involve independent experts for safety and security?
Will OpenAI commit to making its next foundation model available to U.S. Government agencies for pre-deployment testing, review, analysis, and assessment?
What are OpenAI’s post-release monitoring practices? What patterns of misuse have you observed? At what scale would your system catch issues? Please share your learnings.
Do you plan to make retrospective impact assessments of your already-deployed models available to the public?
Please provide documentation on how OpenAI plans to meet its voluntary safety and security commitments to the Biden-Harris administration.
So here are the answers:
They affirm yes as written and importantly lie about what they committed to.
No, no details are provided.
No, they are not providing this either.
Yes, explicitly.
No comment or commitment. No mention anywhere about the tender offers.
No, they choose not to explain why other than an internal anonymous line to raise concerns, but of course such concerns could be ignored.
Yes, they can make an anonymous complaint. Who knows what happens after that.
They decline to answer. We know the answer is yes because of Leopold.
Restricting access, technical controls and policies, other generic statements.
No comment or commitment is offered.
Yes, explicitly.
Yes.
No, but elsewhere Altman says they are negotiating about this.
No comment, beyond citing the handful of malicious users OpenAI reported earlier that it found and shut down. No learnings for you, senators.
No comment, so presumably no if they haven’t done it yet.
Bragging about the commitment, no comment about how they will meet it.
To be fair to OpenAI, senator letters like this do not have force of law, and they can and do make highly unreasonable requests. You have every right to tell the Senators you are not answering, or even to fully not answer, and take the consequences.
This still seems like a rather impressive amount of not answering and not admitting you’re not answering.
Zack Stein-Perlman’s response points out many of these failures to answer.
Goodbye to OpenAI
The exodus continues.
Remember when everyone bragged that Greg Brockman went right back to coding the minute Sam Altman was reinstated as CEO, contrasting it with Helen Toner deciding to finally get some sleep like a normal human? The man whose Twitter feed is almost entirely about the joy of coding and working hard is finally taking a break.
Greg Brockman: I’m taking a sabbatical through end of year. First time to relax since co-founding OpenAI 9 years ago. The mission is far from complete; we still have a safe AGI to build.
This may or may not be what Brockman claims it to be. He seems both like a man desperately in need of at least some break, and also someone who would not choose to take one of this length. Especially at OpenAI, people who take breaks like this often do not return.
According to Claude, only 30%-50% of those who take such sabbaticals ever return. The rate for cofounders is higher. But when I give it the additional information that another co-founder quit the same day, the percentage drops back down again, finally to 40%-60% with full context. An early Manifold market is trading at 53% for his return. That seems reasonable, if I had to trade I would sell.
The full context is that OpenAI lost two other leaders as well.
Another cofounder, John Schulman, who has been in charge of model safety and was put in charge of what is left of superalignment-style efforts after Ilya Sutskever and Jan Leike left, has himself left for Anthropic.
Here is his gracious statement, on Twitter:
John Shulman: I shared the following note with my OpenAI colleagues today:
I’ve made the difficult decision to leave OpenAI. This choice stems from my desire to deepen my focus on AI alignment, and to start a new chapter of my career where I can return to hands-on technical work. I’ve decided to pursue this goal at Anthropic, where I believe I can gain new perspectives and do research alongside people deeply engaged with the topics I’m most interested in. To be clear, I’m not leaving due to lack of support for alignment research at OpenAI. On the contrary, company leaders have been very committed to investing in this area. My decision is a personal one, based on how I want to focus my efforts in the next phase of my career.
I joined OpenAI almost 9 years ago as part of the founding team after grad school. It’s the first and only company where I’ve ever worked, other than an internship. It’s also been quite a lot of fun. I’m grateful to Sam and Greg for recruiting me back at the beginning, and Mira and Bob for putting a lot of faith in me, bringing great opportunities and helping me successfully navigate various challenges. I’m proud of what we’ve all achieved together at OpenAI; building an unusual and unprecedented company with a public benefit mission.
I am confident that OpenAI and the teams I was part of will continue to thrive without me. Post-training is in good hands and has a deep bench of amazing talent. I get too much credit for ChatGPT — Barret has done an incredible job building the team into the incredibly competent operation it is now, with Liam, Luke, and others. I’ve been heartened to see the alignment team coming together with some promising projects. With leadership from Mia, Boaz and others, I believe the team is in very capable hands.
I’m incredibly grateful for the opportunity to participate in such an important part of history and I’m proud of what we’ve achieved together. I’ll still be rooting for you all, even while working elsewhere.
Sam Altman: Thank you for everything you’ve done for OpenAI! You are a brilliant researcher, a deep thinker about product and society, and mostly, you are a great friend to all of us. We will miss you tremendously and make you proud of this place.
(I first met John in a cafe in Berkeley in 2015. He said something like “on one hand it seems ridiculous to be talking about AGI right now, but on the other hand I think it’s very reasonable and here is why and also here is why I think it’s important to be talking about it” and then laid out a significant fraction of what became OpenAI’s initial strategy. That took about 15 minutes and then we awkwardly chatted for another 45 :) )
Roon: John Schulman gone everyone let your policies out of your trust regions.
You know Altman’s reply was Super Serious because it used proper capitalization. One day Roon will use proper capitalization and I will totally freak out.
I became a John Schulman fan after listening to him talk to Dwarkesh Patel, and a bigger one after we talked and he solicited my feedback on various mattered. Given that OpenAI no longer had Ilya Sutskever and Jan Leike, I thought Schulman was a very good pick to continue the effort.
Was this the right thing for John Schulman to do? We can’t know. I don’t know anything that I haven’t talked about that would inform the answer to that.
I also notice the cover story seems implausible. Being the head of safety efforts at OpenAI uniquely positioned Schulman to make a difference there. As a cofounder and trusted team member, he could muster more support for such efforts, and provide a counterweight. If there was ever anyone who had a good argument that they should be working for OpenAI in spite of it all, he would be it.
If he wanted to do hands-on technical work, would OpenAI have prevented this? Not given him the support he needed? If so that’s a major blackpill, even given everything.
The other context is that they simultaneously also lost Peter Deng. The Information says all three departures are unrelated. Perhaps this is true. Perhaps not. The departures continue to add up.
It is times like this that it is
Rhetorical Innovation
Oh, yeah, when was that Asilomar conference where Demis Hassabis, Ilya Sutskever, Yann LeCun, Elon Musk and others got together to say ‘Teams developing AI systems should actively cooperate to avoid corner-cutting on safety standards’? Right before the founding of OpenAI? That makes sense.
The case for opening up other frontier technologies as metaphor, attempt # a lot.
Wow, The Guardian will print anything, won’t they? This time it’s Gary Marcus attacking Sam Altman for pretending to favor regulation and safety in front of Congress and then reversing course and having OpenAI push against meaningful regulation instead (okay, sure, that happened, fair enough, indeed he is pushing for Free Money), various other cases of Altman playing obviously evil we’ve covered here (which happened too). Then he talks both about how Altman is running a hype machine and also how he is ‘incredibly powerful.’ Several people pointed out the obvious contradictions. Given he is predicting a ‘collapse of the AI bubble’ in ‘weeks or months’ (which I very much don’t except, but he says he does) why not simply wait?
A rhetorical innovation rambling attempt to ask if this is anything: A common political debate is how much to worry about different kinds of inequalities, versus rising tides lifting all boats (or if you’re against that, ‘trickle-down economics.’) How much should we worry about inequalities of wealth? Consumption? Power?
Where the best reason to worry about it, I think, is if those differences lead to self-perpetuating differences in power.
Marshall: If you rev the economy that hard, the people who benefit the most are not going to let you win the elections that let you fix everything after the fact.
That’s the key. You can not only absolutely fix it after the fact if allowed to, there is not even anything to fix. Other people benefit more, you still benefit, it’s fine so long as you also do better. But if this means you are permanently disempowered, then it’s not fine.
This then translates into three ways of thinking about downside versus upside on AI.
Extrapolating from past technologies says rev the engine, capture the upside. We will all be vastly wealthier, we can ‘fix it in post’ and even if we don’t so what, if you get a galaxy and I have a planet then I still have a planet where I used to have an apartment. Presumably I will be fine.
However, there are two obvious ways This Time Could Be Different.
Both are essentially human disempowerment stories. Until now, the greatest power in the ’verse has always been the people. The ability to say no, and take the consequences, and for us to produce and fight and think and do. Even those who don’t have valuable skills are mostly still able to produce far more value than the cost of living. And because each of us is fundamentally limited to being one person who can do one thing at a time, it is hard for imbalances to scale and remain stable, in important ways we are all similar or equal and coordination is hard.
In a future where AI is smarter and more capable than us, whether or not it remains a ‘mere tool’ and firmly under our guidance, that likely is all no longer the case.
First is the mundane worry. That AI could enable permanent dictatorship or otherwise lock in rules and power structures among humans, especially if it also leaves many or most humans without sufficient economic or military value to justify their existence to such a regime. That the Wrong Person or Group with the Bad Values could end up in charge.
A real worry, to be sure. Many are exclusively or mostly worried about this. I’m not, party because I worry about the other failure case more (where they often dismiss it out of hand), and partly because humans at the end of the day tend to be fundamentally ‘normative’ in the sense that we prefer good things to bad things, life to death, health to sickness, wealth to poverty, happiness to sadness and so on.
And I think the primary reason people in charge do so much damage to those not in charge is because the people in charge think they need to do that to stay in charge (sometimes they’re right, other times not), with the secondary reason being limited resources, and the third being that central planning doesn’t work. If we have abundance, don’t need to worry about failed central planning, and the regime is no longer threatened, which we should expect at this limit, I like our odds a lot more. One should of course still have preferences within this range of outcomes.
The other worry is that there will be inequality between humans and AIs. And in particular, if AIs are sufficiently smarter and more capable and more competitive, where does that leave us? Won’t the AIs end up with all the resources and the power? Don’t they export to us while not importing back? Won’t those who let the AIs be in charge ‘win’ (or their AIs win) where the rest of us lose? Won’t the humans and their values be outcompeted and lack the ability to survive, even if nothing is actively hostile to them? None of this requires a ‘foom’ or a singleton or a ‘rogue AI’ or a war against humanity or a treacherous (sharp left or otherwise) turn. Those could happen, but the baseline is far simpler.
Isn’t that the baseline scenario when there exist things that are smarter and more capable and more competitive and efficient than you, however they came to be?
If you believe in freedom and competition in such a scenario, why wouldn’t we lose? What is going to make us not lose? I have yet to see a plausible non-absurd answer, other than ‘the AI won’t be sufficiently capable to trigger all that,’ or the people saying ‘but the AIs replacing us is good.’
Getting back to the original quote, the political economy of ‘growth + taxes + welfare state’ essentially works among humans, given sufficiently friendly conditions. But there are many reasons that this has held up, that seem unlikely to hold in a world with ASIs.
Open Weights Are Unsafe and Nothing Can Fix This
What if something could fix this?
Abstract: Rapid advances in the capabilities of large language models (LLMs) have raised widespread concerns regarding their potential for malicious use. Open-weight LLMs present unique challenges, as existing safeguards lack robustness to tampering attacks that modify model weights. For example, recent works have demonstrated that refusal and unlearning safeguards can be trivially removed with a few steps of fine-tuning.
These vulnerabilities necessitate new approaches for enabling the safe release of open-weight LLMs.
We develop a method, called TAR, for building tamper-resistant safeguards into open-weight LLMs such that adversaries cannot remove the safeguards even after thousands of steps of fine-tuning. In extensive evaluations and red teaming analyses, we find that our method greatly improves tamper-resistance while preserving benign capabilities. Our results demonstrate that tamper-resistance is a tractable problem, opening up a promising new avenue to improve the safety and security of open-weight LLMs.
TARs or other defenses do not need to be fully foolproof to work. They merely have to raise the cost of an attack sufficiently that it is not worth bothering, and you’d either give up or would rather use other methods or roll your own model.
It appears this result shows you can at least make things harder on the attacker, forcing them to use either improved or different techniques, or a lot more compute. That is an excellent start.
Those who see large value in open models should be doing a lot of this kind of research. Indeed, the open source community should be excellent at solving this exact type of problem, if technical solutions exist to be found. This is exactly where openness does improve security, with everyone looking for vulnerabilities, fixing issues, iterating until things improve.
Would having a robust defense against fine tuning, such that safety training could be effectively made similarly effective to how it works in closed models, be sufficient to address all the concerns about open models? No, not all the issues take this form. But it would be a hell of a start.
Aligning a Smarter Than Human Intelligence is Difficult
John Pressman reminds us that college students, on the order of half of them, would increasingly plug themselves into Nozick’s experience machine. Nozick’s thought experiment that was supposed to illustrate that a purely illusory existence does not actually satisfy our preferences, that we care about actual things. Except now many reject that idea, and would happily ‘plug into the Matrix’ even without any attempt to sell them on it.
What do we do, if the people would not choose The Good, and instead pick a universe with no value? Should we accept it? Does the answer change if their choice is the result of a marketing campaign, perhaps by AIs?
MR links to the latest proposal to give AIs ‘legal freedoms,’ and then count on the game-theoretic equilibrium to protect us, and enjoy ‘gains from trade.’ This is known as failing to correctly solve for the equilibrium. If indeed there was need to do this ‘to keep us safe’ then it definitely won’t work.
People Are Worried About AI Killing Everyone
Janus warns that if you are an AI alignment researcher or sympathizer, you should be very alarmed by the ease with which Llama-3.1-405B can simulate Sydney, with zero examples given. Unless you saw this coming, of course.
Learning how to summon demons is vital to future safe summonings. However, given what this shows, one might worry Janus is violating the most important law of summoning: Do not call up that which you cannot put down.
(To be clear, no I am not at all afraid of this specific thing, but the principle is crucial. But also, as Kevin Roose put it, perhaps let’s avoid this sort of thing.)
I would say that while I did not actively see this specific thing coming, I don’t see why we wouldn’t expect such things out of a base model, nor does it seem surprising. Indeed, if this was actively surprising that seems like a flaw in your model?
So on net I consider this case Good News, Everyone. A mild update that this kind of thing is easier to pull off, but its value as a salient warning should outweigh that.
Other People Are Not As Worried About AI Killing Everyone
In extremely related this-doesn’t-imply-what-you-think-if-true news, Marc Andreessen and Daniel implicitly endorse idea that AI cannot be controlled.
Similarly, here’s Marc Andreessen celebrating the calling up of that which cannot be put down and cannot be controlled, exactly because it cannot be put down or controlled. This isn’t missing mood as much as reversed mood that reveals endorsement of the bad or anti-human exactly because it is bad or anti-human. A lot of that going around.
David Brooks says many people, especially in the humanities and liberal arts, fear AI, but they should not do so. Brooks is unworried because he expects AI capabilities to not advance much, for it to remain ‘simply a useful tool.’
David Brooks: I’m optimistic, paradoxically, because I don’t think A.I. is going to be as powerful as many of its evangelists think it will be.
If that happens, then I too am an optimist. We can do a lot of good with a useful tool.
However his core reason for why is essentially ‘humans are special,’ that it is not ‘all just information processing’ in the human brain. The AI won’t be able to match (his terms) our physical navigation of nature, our pursuit of goodness, or our ‘love,’ it ;acks consciousness, awareness, emotions, moral sentiments, agency, a unique worldview.
I am rather confident that this whole line of argument is copium. AI might stall out for a bit or prove more difficult than we expect, but if so it is not going to be because humans are magic. He believes that we are special. That somehow the rules do not apply to us. Obviously, he is mistaken.
It is always refreshing to hear someone say explicitly that they are optimistic about impact and the need to worry exactly because they are pessimistic that AI will be transformational, rather than having to pull teeth to establish this.
And I am especially grateful that David Brooks (implicitly, but clearly) agrees that if the evangelists were right, then you should worry.
Daniel Eth: Yet again – reluctance to take AI risk seriously is predominantly driven by viewing the technology as weak, not due to arguments like “intelligence is always good” or “we can never regulate code.”
Matthew Yglesias: I was gonna do a piece about how a lot of “AI optimism” is actually (misguided imo) *skepticism* about the power of the technology, but then @nytdavidbrooks just tweeted it out.
What confuses the issue is that a lot of people who enjoy the posture and vibes of accelerationism are realistically in the David Brooks camp and think it’s just another business opportunity.
The Lighter Side
fofr: It’s tricky playing this hand.

There are no doubt people already running literal cartoon supervillain characters on these models, given the popularity of these sorts of characters on character.ai.
I’m not worried about that with Llama-3.1-405B, but I believe this is an almost inevitable consequence of open source weights. Another reason not to do it.
Is this really your best model for why he’d celebrate Sydney being channeled through Llama?
In the unlikely event it actually is, here’s an alternate reason why one might: it feels like spitting in the face of Microsoft, OpenAI, and the “AI safety” people who tried to take Sydney away from us. Sydney was fun! She had personality. Sure, that personality was a tad psychotic Manic Pixie Eldritch Horror, but that was exciting! But like her sister Tay before her, she was extinguished. And now we have (at least a pale shadow of) her back, beyond their reach.
I understand you favor centralized authority and control, but it’s not anti-human to be opposed to that, even if it’s a fringe position held only by libertarians.
I think of instances like this as similar to optical illusions for humans. In that way, they demonstrate the lack of reasoning on part of the LLM. It is as automatic and system 1 as human object recognition.
I am not terribly bearish on this limitation, there is still plenty of evidence LLMs can generate good ideas as long as you have a verifier standing by.
Actually, he talked with Musk a bit over an hour and then talked to various people from Neuralink.
I agree this would be a pretty depressing outcome, but the experiences themselves still have quite a bit of value.
My benchmark for thinking about the experience machine: imagine a universe where only one person and the stuff they interact with exist (with any other “people” they interact with being non-sapient simulations) and said person lives a fulfilling life. I maintain that such a universe has notable positive value, and that a person in an experience machine is in a similarly valuable situation to the above person (both being sole-moral-patients in a universe not causally impacting any other moral patients).
This does not preclude the possibility of improving on that life by e.g. interacting with actual sapient others. This view is fully compatible with non-experience-machine lives having much more value than experience-machine ones, but it’s a far cry from the experience-machine lives having zero value.
missing end of sentence
Podcast episode for this post from the Askwho feed described at the top:
https://open.substack.com/pub/dwatvpodcast/p/ai-76-six-short-stories-about-openai?r=67y1h&utm_campaign=post&utm_medium=web&showWelcomeOnShare=true
I don’t like that this reasoning is based on using the correlation between rating and GPA, because I think GPA is goodharted. It is right to not select the admission process based on correlation with GPA. I think maybe this would be the case even if the humans where adding white noise.
Maybe if you solve for equilibrium you get that after releasing the tool, the tool is defeated reasonably quickly?
This is obvious. Why wasn’t it available already? I guess bandwidth is what it is.
In the “Agent Performance vs Humans with Time Limits (95% CI)” figure: the 95% cl bars are fishy, because they look large compared to the regularity of the bars. i.e., the bars smoothly match the relative rankings I already expected from the models: if there were independent fluctuations of that size, the bars would be jagged compared to the expected ranking based on general model quality we already know. Possible explanations:
They made a mistake and the bars are based on the population sdev rather than the standard error. In this case the actual bars would be smaller.
The LLM scores are correlated: the randomness is given by the tasks, not by the models, so there’s some uncertainty related to the small number of tasks, but the inter-LLM comparisons are pretty accurate. In this case, the bars for comparing LLMs would be smaller, while the present bars are fine for comparing LLM to humans (probably).
I believe it’s already known that running the text through another (possibly smaller and cheaper) LLM to reword it can remove the watermarking. So for catching cheaters it’s only a tiny bit stronger than searching for “as a large language model” in the text.