Data for IRL: What is needed to learn human values?
This post is a summary of my research. If you are interested in experiments and proofs check the full document.
This work was done as part of the Swiss Existential Risk Initiative (CHERI) Summer Research Program. Much thanks to my mentor Markus Peschl.
TLDR:
Gathering data from which human values can be learned via Inverse Reinforcement Learning is non-trivial, but is important to solve the alignemnt problem with this approach. I identify properties of data that will make it impossible for IRL to learn human values from it:
The demonstrator has wrong beliefs about the world and IRL doesn’t know about it
The data is not informative enough, because it is too short or important features are missing
I also derive data requirements & opportunities from properties of human values:
Human values are dependent on the context ⇒ data from many diverse contexts is needed
Human values change over time ⇒ continuous stream of data is needed
Humans don’t always act according to their values ⇒ more sophisticated models of human decision making and more data
Human values are often shared ⇒ to learn values of an individual, data from others can be leveraged
Human values are diverse ⇒ Learn from many people with diverse values
1. Introduction
Data is a core part of every machine learning pipeline. Thus it’s plausible that quality and type of data are also crucial for the success of inverse reinforcement learning in learning human values. If this is true, then determining what data is needed and how to get it is an important part of solving the alignment problem with this approach. Determining this would also clarify the chances of success for IRL for learning human values and clarify what challenges need to be met by algorithms. However, thinking about data for IRL has been widely neglected (except for Model Mis-specification and Inverse Reinforcement Learning). Thus, I aim to shed some light on the question: “What are necessary and beneficial properties of data, so that IRL can correctly learn human values from it?”.
I aim to attack this question from two sides: In Approach 1, I investigate which properties of data would make it impossible for IRL to correctly learn rewards (Section 2). In Approach 2, I argue that certain properties of human values imply the need of data with certain properties to be able to learn the values (Section 3).
2. From IRL to data
In this section I identify properties of data, which would make it impossible for IRL to correctly learn a reward function. I categorise these properties into 1. irrationalities in the planning of the demonstrator, 2. false beliefs the demonstrator has when planning and 3. observed data not being expressive enough. My conclusions mostly come from theoretical examples where these data properties lead to failures of IRL, but I also ran experiments using “Maximum Entropy IRL” and “Maximum Causal Entropy IRL” to back up my claims, which you can read in the full document.
2.1 Irrational demonstrator
Irrational demonstrators have correct beliefs, but their planning is sub-optimal in a systematic way. This will commonly occur with human demonstrators, since they have many cognitive biases. The irrationality of the demonstrator poses a huge challengeto IRL and can even make learning the correct reward via IRL impossible when IRL does not know the level of irrationality of the demonstrator. This is because it can’t be inferred whether an action was taken because of the reward it brings or because of irrational planning. Of course such irrationalities are extremly common in humans due to cognitive biases.
Example: Take a setting where a human can choose Option A, which is more risky but has better Expected Value according to its reward function, or Option B, which is less risky but has worse Expected Value according to its reward function. A risk averse human will tend to go for option B, despite it having worse Expected Value. If IRL is tasked with interpreting this, without knowing that the human is risk averse, it appears that the human chooses option B, because it has higher Expected Value according to the human’s reward function. Thus, IRL will draw wrong conclusions about the human’s reward function i.e. incorrectly learn its values.
2.2 Demonstrator has wrong beliefs
If the demonstrator can have wrong beliefs about the world it becomes hard (maybe impossible) for IRL to tell if an action was done because it was the best according to reward or whether the agent was mistaken in its beliefs. This is different from an irrational demonstrator, since the agent plans optimally given its beliefs. Wrong beliefs about any part of an MDP (states, actions, transition probabilities, rewards, terminal states) except the start state can cause this. Essentially, demonstrations are created by the demonstrator planning for a different-from-reality MDP, which IRL doesn’t know about. IRL then tries to learn rewards from these demonstrations while looking at the true-to-reality MDP. Since humans frequently have wrong beliefs about the world, this challenge to learning values will be prevelant.
Example: A person is at point A and wants to reach point B as quickly as possible. There is a longer route and a shortcut route. The person might take the longer route, because it does not know about the shortcut. If IRL assumes that the person knew that the shortcut was also available, it could wrongly infer that the person had some other reason for taking the longer route. For example IRL might incorrectly conclude that there is some reward along the longer route, which caused the person to not take the shortcut.
2.3 Data is not informative enough
Even if the demonstrator is rational and has correct beliefs, IRL might still fail to learn its rewards if the demonstrations IRL is learning from do not contain enough information.
2.3.1 Trajectories are too short
Humans often make long term plans, where the reward is only achieved at the end. However, if IRL only sees a small part of this plan, it is hard to infer what the eventual goal is. This happens when the demonstrator takes steps to achieve it’s goal, but the demonstrations IRL is learning from only have length .
Example: In the MDP displayed below there is only a partial trajectory (a sub-trajectory of the full trajectory). From this partial trajectory it becomes very hard to tell where the actual reward lies. Indeed there are 6 states the reward could be in so that this partial trajectory would be part of an optimal trajectory.
2.3.2 Features are missing
The real world is large and complicated. It has many states, actions and possible transitions and needs very many features to describe it. If the demonstrations that IRL learns from miss some of this complexity it can misunderstand what is going on in the demonstrations. This will be common, since the huge amount of features in the real world means that the demonstrations that IRL observes will lack some features.
Example: Consider a world where the agent first has to walk to one corner to grab a key enabling it to walk to another corner and gain a reward by opening a chest with the key (left figure). If the trajectories that IRL observes do not have a feature representing whether the key has been picked up, the trajectories can easily be misinterpreted. In fact Maximum Entropy IRL assumes there must be some reward along the trajectory, but fails to pick up on the causal relation between picking up the key and opening the chest (right figure).[1]
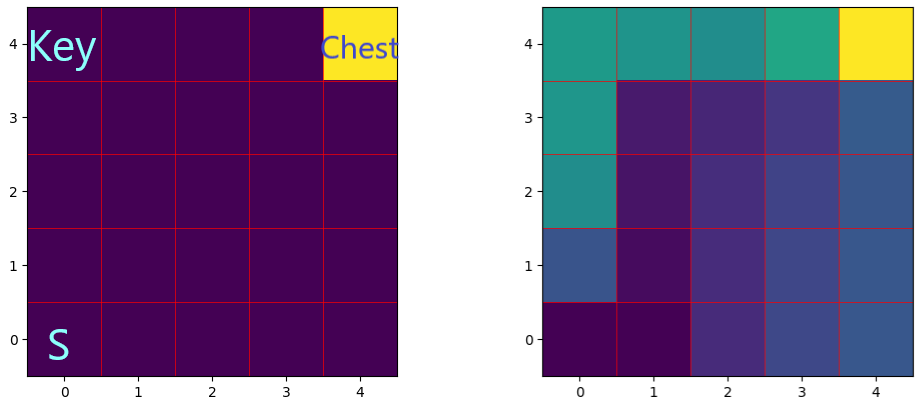
Missing features can make it hard for IRL to understand the underlying causal relations in the environment that drive behaviour. This leads to wrong inferences about rewards.
3. From values to data
In this section I identify some properties of human values and back them up with research from psychology and sociology. From these properties I showcase how they might make it harder (or sometimes easier) for values to be learned from data. I then try to derive properties that data must or should have so that human values can be learned from it. The conclusions I draw about data in this section are based on armchair reasoning. I suspect further investigation would find more data requirements & opportunities and could identify more relevant properties of human values.
3.1 Human Values are context dependent
Which values are applicable, how they are weighted against each other and how they are expressed depends crucially on the context. Context encapsulates the topic, the environment (e.g. on Facebook or at the dinner table), the parties participating and more. There have been multiple proposals for extending IRL to learn context-dependent values. Yu et. al. do so by keeping a deep latent variable model describing the context and performing Meta-IRL, and Gao et. al. build a hierarchical graph of contexts to learn a context dependent reward function.
In IRL terms, each context has a different reward function that should be learned, which also induces different distribution of trajectories in each context. This presents the problem that the reward function learned from the trajectories in one context might not generalise to other contexts. Thus IRL can’t reliably predict values in an unseen context, which means IRL can’t fully learn human values in all of their context dependent nuances without ovserving all contexts.
Example:
Compare a discussion about nuclear disarmament and about Covid-19 measures. The value of safety is expressed differently in these contexts, while the value of freedom only applies in the second context. Thus it would be hard or impossible to correctly infer values for the context of Covid-19, while only observing demonstrations from the context of nuclear disarmament.
Data requirement:
To properly learn human values in one context we need a sufficient amount of data in that context, i.e. one demonstration will likely not suffice for complex contexts.
The ability of IRL to generalise to unseen context depends on the specific algorithm used. For a naive case, sufficient data for every context is needed to ensure that values are accurately learned well for every context. However, progress in cross-domain learning might mean that the learned values can better generalise to unseen contexts or Meta-IRL might be able to quickly adapt to new contexts. In these cases it might not be necessary to see sufficient data from all contexts, but having access to data from many diverse contexts would still be beneficial for generalisability and adaptability.
Concretley, it would be tempting to use data of human behaviour that is easily gathered for value learning, e.g. scraping data from social media. However, this would miss out on many other contexts in which human values are expressed. One must thus be careful to gather and learn from data from many diverse contexts.
3.2 Human values change over time
Individual values and society wide values have both been subject to significant change over time. The priorities of values and how these values are expressed changed over shorter and longer timeframes. We can also expect this trend to continue where future generations (and ourselves in some years) disagree with our current values. This means both the concept that should be learned and the distribution of data that it is learned from keep shifting over time.
Example:
We would be quite unhappy with a powerful AI that acts according to the values of 1522 people. Thus we can expect that future people will think the same about an AI aligned to our current values.
Data requirement:
IRL can only learn the reward function from which the observations were generated. So if IRL only sees old demonstrations and value change occured (old rewards current rewards ), then it can’t learn the current, but only the old rewards. To learn current rewards current demonstrations are needed.
This shows that we continuously need new data of human behaviour to adapt the learned values to the always changing values of humans.[2]
3.3 Humans don’t always act according to their values
In the standard IRL formulation, the chosen action only depends on the reward it would bring and the world the agent is acting in. However, in real life behaviour of humans is not only guided by their values, but is also influenced by other factors. Thus humans don’t always act according to their values. If these other factors are not observed by IRL it becomes hard (probably impossible) to distinguish the aspects influencing behaviour and correctly infer actual human values.
Examples:
Following social norms: Humans actions are heavily shaped by the social norms present in a situation and can overwrite personal values when making decisions. If IRL cannot infer the social norms present in a situation, it becomes impossible to distinguish whether an agent did something because it corresponded to its values or whether it was following a norm.
Temptations overwriting values: There are plenty of situations where humans do something, because they have a short-term desire for it, although upon reflection it does not correspond to their values. Imagine an addict taking a drug, because they have a strong desire for the drug at that moment, despite being aware of the detrimental health effects. Without understanding addiction and its effects on decision making, IRL could wrongly infer that the person does not value their long term health strongly.
Manipulation: Human values can be manipulated, for example through Value-Manipulation Tasks, through conforming to social influence or through drug use. If a human has certain values, but is temporarily or permanently manipulated to have other values and the demonstrations are taken when the human acted under the manipulated values, the true values cannot be learned. For example a person has a strong value of not physically harming other people. However, after taking a drug the person is much more aggressive and intends to harm other people. If IRL only observes behaviour of the person during the drug trip it would it is unable to learn the actual (sober) values.
Data requirement:
Ideally we would have data free of these effects influencing behaviour, so that values are the only factor influencing behaviour. However, since these effects seem very common in human behaviour and will likely be present in any collected dataset other solutions are necessary.
The standard IRL formulation fails to take into account factors that influence behaviour aside from rewards. These other factors are essentially confounding variables. It is only possible to draw causal inferences about values from observing the behaviour if these confounding variables are accounted for. I see two ways of enabling IRL to take other factors into account (I am uncertain about these working and could imagine there being other good approaches):
Have a more flexible and complex model of human decision making so that other factors can be learned. This requires 1) more data to avoid this more complex model from overfitting and 2) data from which these other factors can be inferred.
Have a model of human decision making with stronger inductive biases about psychological models of human decision making. An example of this is taking account of System 1 & 2 thinking in the model of how humans make decisions, allowing for better inference of rewards from behaviour
Further, data from many different contexts would help, since inferences like “Alice has the value X in context A, but does not apply that value X in context B ⇒ possibly she is just following social norms” can be made.
In the specific case of manipulation, having long trajectories could prove important. This would increase the likelihood of observing that a manipulation took place and thus allow to control for that. In the previous example, IRL could observe the human taking the drug and from that infer that the following behaviour is generated from different values.
3.4 Human values are often shared:
Values are often similar between people and even between groups. When trying to infer the values of an individual we can get much information by looking at other people.
Example:
Nearly all people subscribe to the value of not unnecessarily hurting other people. IRL does not need to relearn this for each human.
Data opportunity:
Since in the case of human values reward functions of demonstrators are correlated, we can benefit from applying Meta-Learning IRL, using values learned from other humans as a prior for the values of a new human or doing fine-tuning using the new humans demonstrations.
In an IRL setting where we want to learn a specific demonstrators reward function, but only have few trajectories by that demonstrator, trajectories generated by other demonstrators can be leveraged. Thus, when learning the values of a single person IRL could benefit from the large amounts of data generated by other humans and does not need to start from scratch for each individual.
3.5 Human values are diverse:
While values are often similar between humans, they also differ between individuals and between groups. By learning values from a single human or group, one misses values or nuances in the values that other people or groups hold.
We can formulate learning the rewards of multiple humans as a multi-task IRL problem, where IRL learns a reward function for each demonstrator from which it observes demonstrations. These learned rewards can then be used to take actions that take into account the rewards functions of all observed demonstrators. As the number of demonstrators IRL observes grows, this estimate will get closer to the actual best action for all humans.
Example:
The values of a Silicon Valley programmer and an Indian farmer are quite different and should both be taken into account. An AI that only knows and acts according to the values of one of them, would be misaligned towards the other.
Data requirement:
Thus to adequately learn human values it is not enough to only look at a single human or group, but it is necessary to learn from a diverse set of people in order to represent many groups and their value systems. In fact we will converge to values that generalise better, the more humans we look at.[3] Thus gathering data from many humans representing diverse value systems is beneficial to learning human values.
Further, having unbiased and representative data for Machine Learning is currently a hot topic of research and should especially be thought about in a context with such high stakes.
4. Conclusion
It appears that there has been only very little research into the necessary properties of data for learning human values from IRL. I now think it is non-trivial to gather data from which human values can successfully be learned. However, if IRL is to succeed as a solution to the alignment problem by learning human values, having the right data is a critical part of this. Even if we find the best data to learn values from, the data will likely still have some unpleasant properties (e.g. the problem of having irrational demonstrators seems hard to fix). It’s good if we figure out these unpleasant properties early, so algorithms can be developed that work despite data having these properties. Thus it seems to me that more research into the topic of “what data do we need/have to learn values from?” is warranted.
Further work: There is still much work that can be done. Firstly, proofs backing the experimental results in sections 2.2 and 2.3 could be thought out. Further, many of the points raised in section 3 deserve more in depth thinking and I suspect there to me more properties of values which are worth thinking about. Developing a commonly accepted benchmark, which includes many of the challenges laid out in this post would also be hugely beneficial, although it would be hard. It would enable researchers to meet the hard challenges posed by the data with their algorithms and reduce the tendency to use “easy” IRL-benchmarks which nicely fit ones algorithm. Most importantly, since this post only lays out problems, work trying to remedy these problems is needed. I would love to see proposed solutions!
I am very happy to receive feedback on this research!
- ^
Notably, Maximum Causal Entropy IRL deals much better with this specific situation, but doesn’t solve the general problem of missing features.
- ^
To address this problem one interesting question to answer is: “Can we improve IRL by learning from off-policy data, assuming that this previous data doesn’t behave too differently from the current data?”
- ^
Section 3.5 in the full document has a simplified proof indicating that: The best actions taken based on the observed demonstrators get closer to the the true best actions for all demonstrators with a growing number of demonstrators we observe.
Some feedback, particularly for deciding what future work to pursue: think about which seem like the key obstacles, and which seem more like problems that are either not crucial to get right, or that should definitely be solvable with a reasonable amount of effort.
For example, humans being suboptimal planners and not knowing everything the AI knows seem like central obstacles for making IRL work, and potentially extremely challenging. Thinking more about those could lead you to think that IRL isn’t a promising approach to alignment after all. Or, if you do get the sense that these can be solved, then you’ve made progress on something important, rather than a minor side problem. On the other hand, e.g. “Human Values are context dependent” doesn’t seem like a crucial obstacle for IRL to me.
One framing of this idea is Research as a stochastic decision process: For IRL to work as an alignment solution, a bunch of subproblems need to be solved, and we don’t know whether they’re tractable. We want to fail fast, i.e. if one of the subproblems is intractable, we’d like to find out as soon as possible so we can work on something else.
Another related concept is that we should think about worlds where iterative design fails: some problems can be solved by the normal iterative process of doing science: see what works, fix things that don’t work. We should expect those problems to be solved anyway. So we should focus on things that don’t get solved this way. One example in the context of IRL is again that humans have wrong beliefs/don’t understand the consequences of actions well enough. So we might learn a reward model using IRL, and when we start training using RL it looks fine at first, but we’re actually in a “going out with a whimper”-style situation.
For the record, I’m quite skeptical of IRL as an alignment solution, in part because of the obstacles I mentioned, and in part because it just seems that other feedback modalities (such as preference comparisons) will be better if we’re going the reward learning route at all. But I wanted to focus mainly on the meta point and encourage you to think about this yourself.
Thank you Erik, that was super valuable feedback and gives some food for thought.
It also seems to me that humans being suboptimal planners and not knowing everything the AI knows seem like the hardest (and most informative) problems in IRL. I’m curious what you’d think about this approach for adressing the suboptimal planner sub-problem : “Include models from coginitive psychology about human decision in IRL, to allow IRL to better understand the decision process.” This would give IRL more realistic assumptions about the human planner and possibly allow it to understand it’s irrationalites and get to the values which drive behaviour.
Also do you have a pointer for something to read on preference comparisons?
Yes, this is one of two approaches I’m aware of (the other being trying to somehow jointly learn human biases and values, see e.g. https://arxiv.org/abs/1906.09624). I don’t have very strong opinions on which of these is more promising, they both seem really hard. What I would suggest here is again to think about how to fail fast. The thing to avoid is spending a year on a project that’s trying to use a slightly more realistic model of human planning, and then realizing afterwards that the entire approach is doomed anyway. Sometimes this is hard to avoid, but in this case I think it makes more sense to start by thinking more about the limits of this approach. For example, if our model of human planning is slightly misspecified, how does that affect the learned reward function, and how much regret does that lead to? If slight misspecifications are already catastrophic, then we can probably forget about this approach, since we’ll surely only get a crude approximation of human planning.
Also worth thinking about other obstacles to IRL. One issue is “how do we actually implement this?”. Reward model hacking seems like a potentially hard problem to me if we just do a naive setup of reward model + RL agent. Or if you want to do something more like CIRL/assistance games, you need to figure out how to get a (presumably learned) agent to actually reason in a CIRL-like way (Rohin mentions something related in the second-to-last bullet here). Arguably those obstacles feel more like inner alignment, and maybe you’re more interested in outer alignment. But (1) if those turn out to be the bottlenecks, why not focus on them?, and (2) if you want your agent to do very specific cognition, such as reasoning in a CIRL-like way, then it seems like you might need to solve a harder inner alignment problem, so even if you’re focused on outer alignment there are important connections.
I think there’s a third big obstacle (in addition to “figuring out a good human model seems hard”, and “implementing the right agent seems hard”), namely that you probably have to solve something like ontology identification even if you have a good model of human planning/knowledge.
But I’m not aware of any write-up explicitly about this point.ETA: I’ve now written a more detailed post about this here.If you’re completely unfamiliar with preference comparisons for reward learning, then Deep RL from Human Preferences is a good place to start. More recently, people are using this to fine-tune language models, see e.g. InstructGPT or Learning to summarize from human feedback. People have also combined human demonstrations with preference comparisons: https://arxiv.org/abs/1811.06521 But usually that just means pretaining using demonstrations and then fine-tuning with preference comparisons (I think InstructGPT did this as well). AFAIK there isn’t really a canonical reference comparing IRL and preference comparisons and telling you which one you should use in which cases.
I think the IRL problem statement is doomed if it insists on being about human values, but it might be useful as an intentional stance, formulating agent-like structures based on their influence. For this to work out, it needs to expect many agents and not just a single agent, separating their influences, and these agents could be much smaller/simpler than humans, like shards of value or natural concepts. Only once a good map of the world that takes an intentional stance is available, is it time to look at it in search for ingredients for an aligned agent.
I think the main reason it seems like there hasn’t been much work on the data needed for IRL is that IRL is so far from modeling humans well (i.e. modeling humans how they want to be modeled) that most intermediate work doesn’t look like working with data-gathering approaches, it looks like figuring out better ways of learning a model of humans, which is a balance between reasoning about data and architecture.
Like, suppose you want to learn a model of the world (an inference function to turn sense data and actions into latent variables and predictions about those latents) and locate humans within that model. This is hard, and it probably requires specialized training data collected as human feedback! But we don’t know what data exactly without better ideas about what, precisely, we want the AI to be doing.
I agree that focusing too much on gathering data now would be a mistake. I believe thinking about data for IRL now is mostly valuable to identify challenges which make IRL hard. Then we can try to develop algorithms that solve these challenges or find out IRL is not a tractable solution for alignment.