This is the full text of a post from “The Obsolete Newsletter,” a Substack that I write about the intersection of capitalism, geopolitics, and artificial intelligence. I’m a freelance journalist and the author of a forthcoming book called Obsolete: Power, Profit, and the Race for Machine Superintelligence. Consider subscribing to stay up to date with my work.
[EDIT: I should have credited Gary Marcus for coining the term “deep learning is hitting a wall” back in March 2022. I didn’t actually realize it had originated entirely with him, given how much it’s entered the lexicon. He argued that LLMs were hitting diminishing returns in April 2024, which was an input into my similar prediction in June. He also had a post up on Saturday analyzing some of the same evidence included here.]
Ilya Sutskever is perhaps the most influential proponent of the scaling hypothesis — the idea that simply increasing the amount of data, training time, and parameters going into a model will improve performance — so his acknowledgement in yesterday’s Reuters article that scaling has plateaued is a big deal:
Ilya Sutskever, co-founder of AI labs Safe Superintelligence (SSI) and OpenAI, told Reuters recently that results from scaling up pre-training—the phase of training an AI model that use s a vast amount of unlabeled data to understand language patterns and structures—have plateaued.
It’s worth noting that SSI has way less total funding than its competitors, so it’s in Sutskever’s interest to advance this narrative.
Here’s a direct quote of Sutskever from the Reuters story:
“The 2010s were the age of scaling, now we’re back in the age of wonder and discovery once again. Everyone is looking for the next thing,” Sutskever said. “Scaling the right thing matters more now than ever.”
Reuters fleshes out his claim with additional reporting:
Behind the scenes, researchers at major AI labs have been running into delays and disappointing outcomes in the race to release a large language model that outperforms OpenAI’s GPT-4 model, which is nearly two years old, according to three sources familiar with private matters.
Back in June, I predicted something along these lines, writing, “I don’t think the jump from this gen to next gen LLMs will be nearly as big as the jump from GPT-3/3.5 to 4.”
Why did I think this? Here’s what I wrote at the time:
1. We haven’t seen anything more than marginal improvements in the year+ since GPT-4
2. Rumors from people in the labs
3. Running out of good training data
4. Maybe some intrinsic limits in how far next-word prediction + RLHF [reinforcement learning from human feedback] can get you (though RL w/ self-play may totally work!)
5. Lots of popular benchmarks don’t actually measure things that we care about (like reasoning over longer time horizons, ability to act in the world). Making further progress on these may not result in the kinds of jumps in usefulness we may expect from the next gen
Sutskever’s comments to Reuters come on the heels of a big report in The Information that OpenAI was running into similar problems with its in-development Orion model, “In May, OpenAI CEO Sam Altman told staff he expected Orion, which the startup’s researchers were training, would likely be significantly better than the last flagship model, released a year earlier.”
But when training finished, the model reportedly didn’t deliver on Altman’s prediction:
While Orion’s performance ended up exceeding that of prior models, the increase in quality was far smaller compared with the jump between GPT-3 and GPT-4, the last two flagship models the company released, according to some OpenAI employees who have used or tested Orion.
It’s also not better across the board, apparently:
Orion performs better at language tasks but may not outperform previous models at tasks such as coding, according to an OpenAI employee. That could be a problem, as Orion may be more expensive for OpenAI to run in its data centers compared to other models it has recently released, one of those people said.
OpenAI may not even give Orion a GPT name when it is released early next year, according to The Information.
Why might the scaling law be starting to break? According to OpenAI employees and AI researchers who spoke to The Information, companies are running out of high quality data, and supplementing with synthetic data is causing the model to problematically resemble the older models.
Economics of AI
The big caveat to all of this is that OpenAI’s recent o1 model might show a path forward, even if scaling plateaus. By having a model ‘think’ longer on certain tasks, as o1 does, you can improve performance and unlock new capabilities without improvements to the underlying model.
OpenAI reports that o1 has state-of-the-art performance on challenging math, coding, and PhD-level science benchmarks, beating expert humans in some domains for the first time:
But it’s not yet clear how well this will translate into performance on longer time horizon tasks, which will depend a lot on things like error rate and error correction.
But there are big questions there still, namely: will the economics allow it?
OpenAI researcher Noam Brown raised this question at last month’s TED AI conference, “After all, are we really going to train models that cost hundreds of billions of dollars or trillions of dollars?” Brown said. “At some point, the scaling paradigm breaks down.”
Here’s a chart OpenAI published with its o1 announcement:
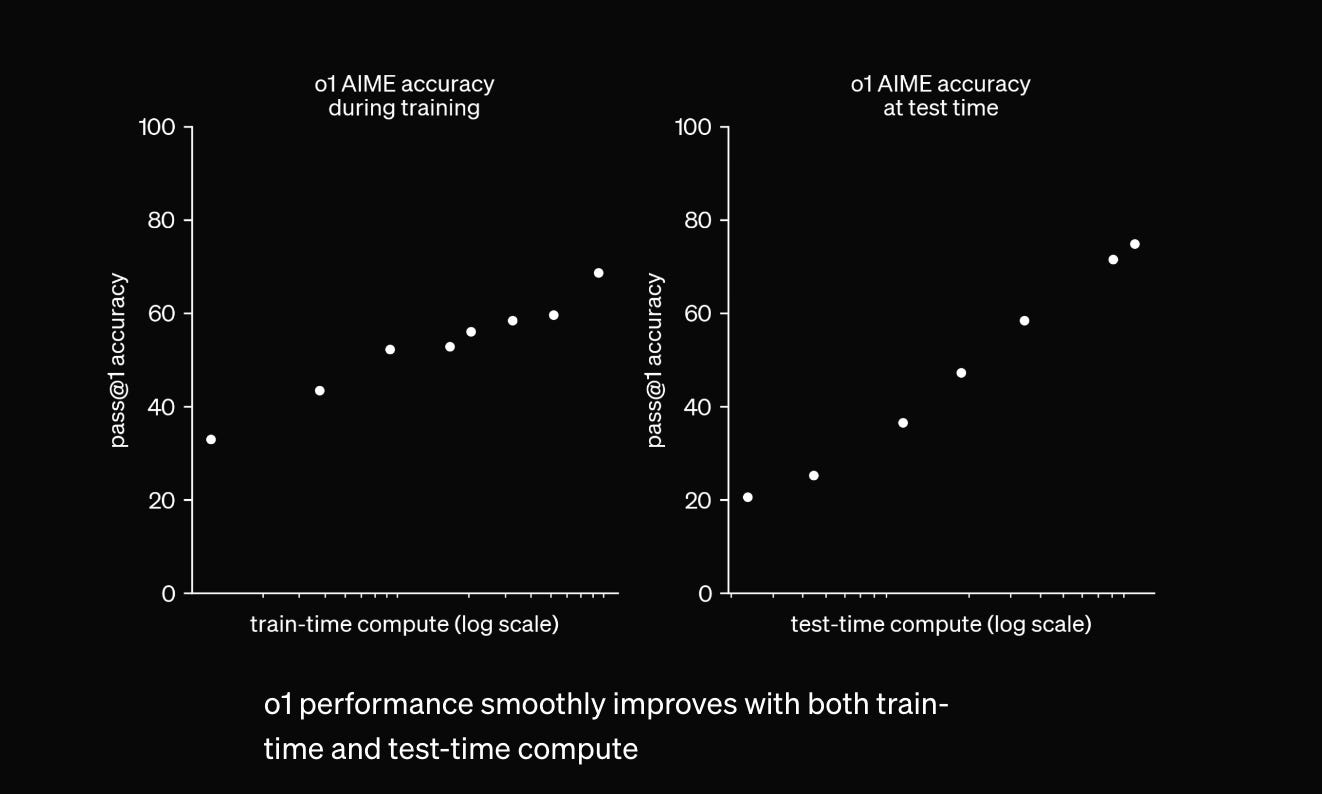
It shows that you can boost performance on a technical benchmark by either increasing pretraining time (a part of classic scaling) or by increasing the “test-time compute,” i.e. dedicating more ‘thinking’ to the problem being addressed.
As an example of how this can work in practice, Brown reportedly told the TED AI audience:
It turned out that having a bot think for just 20 seconds in a hand of poker got the same boosting performance as scaling up the model by 100,000x and training it for 100,000 times longer.
So does this mean that new scaling laws are unlocked, and the potential demise of the old ones are no big deal?
Not so fast.
The fact that OpenAI did not publish the absolute values of the above chart’s x-axis is telling. If you have a way of outcompeting human experts on STEM tasks, but it costs $1B to run on a days worth of tasks, you can’t get to a capabilities explosion, which is the main thing that makes the idea of artificial general intelligence (AGI) so compelling to many people.
Additionally, the y-axis is not on a log scale, while the x-axis is, meaning that cost increases exponentially for linear returns to performance (i.e. you get diminishing marginal returns to ‘thinking’ longer on a task).
This reminds me of quantum computers or fusion reactors — we can build them, but the economics are far from working. Technical breakthroughs are only one piece of the puzzle. You also need to be able to scale (not that this will come as news to Silicon Valley).
Smarter base models could decrease the amount of test-time compute needed to complete certain tasks, but scaling up the base models would also increase the inference cost (i.e. the price of prompting the model). It’s not clear which effect would dominate, and the answer may depend on the task. And if researchers really are reaching a plateau, they may be stuck with base models only marginally smarter than what’s published right now.
There’s also an open question of whether these base models are smart enough to automate STEM R&D, given enough cycles. In other words, even if the cost of compute came down by many orders of magnitude, would that be enough to get to AGI with the current stack (say, o1 on top of GPT-4o)?
Maybe AGI will just be really expensive
A key component of why AGI could be really crazy is that normal human limits don’t apply. This could cash out in superhuman speed, capabilities, or scale (or maybe all three).
I wrote about this in January in my Jacobin cover story “Can Humanity Survive AI?”:
Here’s a stylized version of the idea of “population” growth spurring an intelligence explosion: if AI systems rival human scientists at research and development, the systems will quickly proliferate, leading to the equivalent of an enormous number of new, highly productive workers entering the economy. Put another way, if GPT-7 can perform most of the tasks of a human worker and it only costs a few bucks to put the trained model to work on a day’s worth of tasks, each instance of the model would be wildly profitable, kicking off a positive feedback loop. This could lead to a virtual “population” of billions or more digital workers, each worth much more than the cost of the energy it takes to run them. Sutskever thinks it’s likely that “the entire surface of the earth will be covered with solar panels and data centers.”
I stand by this analysis, but I now think it’s increasingly likely that the first AI systems that can do advanced STEM R&D will cost more than paying for the equivalent work from human researchers. This could lead to a market similar to that of cultured meat, where it’s possible to make molecularly “real” meat, but it costs orders of magnitude more than the old approach, at least at first.
There will be way more of a financial incentive to traverse this valley, because the upside isn’t just a suffering-free hamburger that is cost competitive with the real thing, but an arbitrary number of remote-worker equivalents who can be deployed to any end (including bringing down the cost of running more of themselves).
When I wrote the above paragraph, it was nearly free to have a chatbot read my entire draft and offer me feedback. The catch was that the feedback wasn’t that useful.
But now, a ChatGPT premium account only gets you 50 messages per week with o1 preview, the most advanced version available (o1 mini allows 50 per day).
OpenAI’s API prices o1-preview at six-times more than GPT-4o (o1 costs $15/1M input and $60/1M output tokens).
Implications
So what? Well, if deep learning is actually hitting a wall, that has big implications for the industry and the wider world. This is what I wrote in my June prediction thread:
- collapse in investment in AI companies, which is largely predicated on expectation of continued improvements
- triumphalism from DL/LLM [deep learning/large language model] skeptics
- less appetite for regulation
- longer AI timelines
But what we seem to be seeing is a bit different from deep learning broadly hitting a wall. More specifically it appears to be: returns to scaling up model pretraining are plateauing.
Even if this is true, the o1 approach offers a theoretical path the rest of the way to automating remote work, unless we reach plateaus there too or it’s just too expensive to be practical.
If building AGI requires extremely large base models and exponentially increasing inference compute, then that puts even more pressure on expanding the key inputs into training and running AI models, like data centers, GPU fabs, and power plants. There was already a lot of pressure in this direction anyway, as AI companies were constrained by access to increasingly scarce compute, so it’s hard to tell if any of the recent moves are evidence for a plateau (like Microsoft rebooting Three Mile Island to power data centers).
If it does turn out that the very first AI system that could truly automate AI research is butting up against hard physical limits on infrastructure, that may be a lucky break for humanity. Why? The hypothesized capabilities explosion might be rate-limited by these constraints. The “takeoff speed,” i.e. how quickly an AGI bootstraps into a superintelligence, has long been seen as a key factor into how likely humanity would be to lose control of the system.
In fact, OpenAI CEO Sam Altman used to argue that we should race to build AGI while there is less of a “compute overhang,” so we experience a slower takeoff. The more spare computing infrastructure available at the time AGI is built, the thinking went, the more resources could be immediately plowed into bootstrapping the model. However, Altman began pushing for gargantuan build-outs of computing infrastructure in February, deliberately trying to increase the compute overhang, contradicting his prior safety plan (I wrote about it here).
Altman said recently that there is a “basically clear” path to AGI. If he’s right but that path requires the cost of compute to come down by several orders of magnitude, then OpenAI, with 2024 operating costs of nearly $10 billion, may not stick around long enough to see it (let alone build it).
Cutting through the hype
One of the major challenges of evaluating AI predictions is that the people with access to the most up-to-date information on the technology’s frontier all have massive financial interests in advancing certain narratives.
Every executive at a company building foundation models want investors to believe that AGI is coming soon, because these companies are currently money pits that don’t have a clear path to profitability. The unit economics of AI are actually much worse than software. It costs basically nothing to copy Microsoft Word, but each ChatGPT prompt costs nontrivial amounts of money. And as we’ve seen, the o1 approach may just exacerbate this problem.
But all things considered, I would not bet against AI capabilities continuing to improve, albeit at a slower pace than the blistering one that has marked the dozen years since AlexNet inaugurated the deep learning revolution.
There is far more money and effort going toward the space than ever before. Inference costs have fallen by almost three orders of magnitude in less than two years. And even though the costs of building frontier AI models are staggering for the private sector, they’re a rounding error for the world’s largest governments, which are starting to take a real interest in the technology.
After all, the Department of Defense has something in common with venture-backed AI startups: both can receive billions of dollars without turning a profit. The main difference is the DoD can tack on a few extra zeroes.
If you enjoyed this post, please subscribe to TheObsolete Newsletter. You can also find my accompanying Twitter thread here.
Scaling progress is constrained by the physical training systems[1]. The scale of the training systems is constrained by funding. Funding is constrained by the scale of the tech giants and by how impressive current AI is. Largest companies backing AGI labs are spending on the order of $50 billion a year on capex (building infrastructure around the world). The 100K H100s clusters that at least OpenAI, xAI, and Meta recently got access to cost about $5 billion. The next generation of training systems is currently being built, will cost $25-$40 billion each (at about 1 gigawatt), and will become available in late 2025 or early 2026.
Without a shocking level of success, for the next 2-3 years the scale of the training compute that the leading AGI labs have available to them is out of their hands, it’s the systems they already have or the systems already being built. They need to make the optimal use of this compute in order to secure funding for the generation of training systems that come after and will cost $100-$150 billion each (at about 5 gigawatts). The decisions about these systems will be made in the next 1-2 years, so that they might get built in 2026-2027.
Thus paradoxically there is no urgency for the AGI labs to make use of all their compute to improve their products in the next few months. What they need instead is to maximize how their technology looks in a year or two, which motivates more research use of compute now, rather than immediately going for the most scale current training systems enable. One exception might be xAI, which still needs to raise money for the $25-$40 billion training system. And of course even newer companies like SSI, but they don’t even have the $5 billion training systems to demonstrate their current capabilities unless they do something sufficiently different.
Training systems are currently clusters located on a single datacenter campus. But this might change soon, possibly even in 2025-2026, which lets the power needs at each campus remain manageable.
If these rumors are true, it sounds like we’re already starting to hit the issue I predicted in LLMs May Find It Hard to FOOM. The majority of content on the Internet isn’t written by geniuses with post-doctoral experience, so we’re starting to run out of the highest-quality training material for getting LLMs past doctoral student performance levels. However, as I describe there, this isn’t a wall, it’d just a slowdown: we need to start using AI to generate a lot more high-quality training data, As o1 shows, that’s entirely possible, using inference-time compute scaling and then training on the results. We’re having AI do the equivalent of System 2 thinking (in contexts where we can check the results are accurate), and then attempting to train a smarter AI that can solver the same problems by System 1 thinking.
However, this might be enough to render fast takeoff unlikely, which from an alignment point of view would be an excellent thing.
Now we just need to make sure all that synthetic training data we’re having the AI generate is well aligned.
This is also my interpretation of the rumors, assuming they are true, which I don’t put much probability on.
https://www.lesswrong.com/posts/NRZfxAJztvx2ES5LG/a-path-to-human-autonomy
Vladimir makes an excellent point that it’s simply too soon to tell whether the next gen (eg gpt5) of LLMs will fizzle. I do think there’s reasonable evidence for suspecting that the generation AFTER that (eg gpt6) won’t be a straightforward scale up of gpt4. I think we’re in a compute and data overhang for AGI, and that further parameter, compute, and data scaling beyond gpt5 level would be a waste of money.
The real question is whether gpt5 gen models will be just enough more capable than current ones to substantially increase the rate of the true limiting factor: algorithmic improvement.
I just want to provide one important piece of information:
It turns out that Ilya Sutskever was misinterpreted as a claim about the model plateauing, but instead saying other directions work out better:
https://www.lesswrong.com/posts/wr2SxQuRvcXeDBbNZ/?commentId=JFNZ5MGZnzKRtFFMu
That’s not exactly my claim. If he said more to the reporters than his words quoted in the article[1], then it might’ve been justified to interpret him as saying that pretraining is plateauing. The article isn’t clear on whether he said more. If he said nothing more, then the interpretation about plateauing doesn’t follow, but could in principle still be correct.
Another point is that Sutskever left OpenAI before they trained the first 100K H100s model, and in any case one datapoint of a single training run isn’t much evidence. The experiment that could convincingly demonstrate plateauing hasn’t been performed yet. Give it at least a few months, for multiple labs to try and fail.
I definitely agree that people are overupdating too much from this training run, and we will need to wait.
(I also made this mistake in overupdating.)
I think this is a misunderstanding of the piece and how journalists typically paraphrase things. The reporters wrote that Ilya told them that results from scaling up pre-training have plateaued. So he probably said something to that effect, but for readability and word-count reasons, they paraphrased it.
If a reported story from a credible outlet says something like X told us that Y, then the reporters are sourcing claim Y to X, whether or not they include a direct quote.
The plateau claim also jives with The Information story about OpenAI, as well as a few other similar claims made by people in industry.
Ilya probably spoke to the reporter(s) for at least a few min, so the quotes you see are a tiny fraction of everything he said.
Fair enough, I’ll retract my comment.
I’d bet that Noam Brown’s TED AI talk has a lot of overlap with this one that he gave in May. So you don’t have to talk about it second-hand, you can hear it straight from the source. :) In particular, the “100,000×” poker scale-up claim is right near the beginning, around 6 minutes in.
There is a newer post-o1 Noam Brown talk from Sep 2024 that covers similar ground.
Thanks for these!
One other plausible theory of the results is that conditional on the results being true, this might not represent deep learning hitting a wall, but rather the leaving of key people like Ilya Sutskever meaning that OpenAI has lost it’s mojo and ability to scale well:
https://www.reddit.com/r/mlscaling/comments/1djoqjh/comment/l9uogp9/
People may be blind to the fact that improvements from gpt2 to 3 to 4 were both driven by scaling training compute (by 2 OOM between each generation) and (the hidden part) by scaling test compute through long context and CoT (like 1.5-2 OOM between each generations too).
If gpt5 uses just 2 OOM more training compute than gpt4 but the same test compute, then we should not expect “similar” gains, we should expect “half”.
O1 may use 2 OOM more test compute than gpt4. So gpt4=>O1+gpt5 could be expected to be similar to gpt3=>gpt4