If this is your implementation:
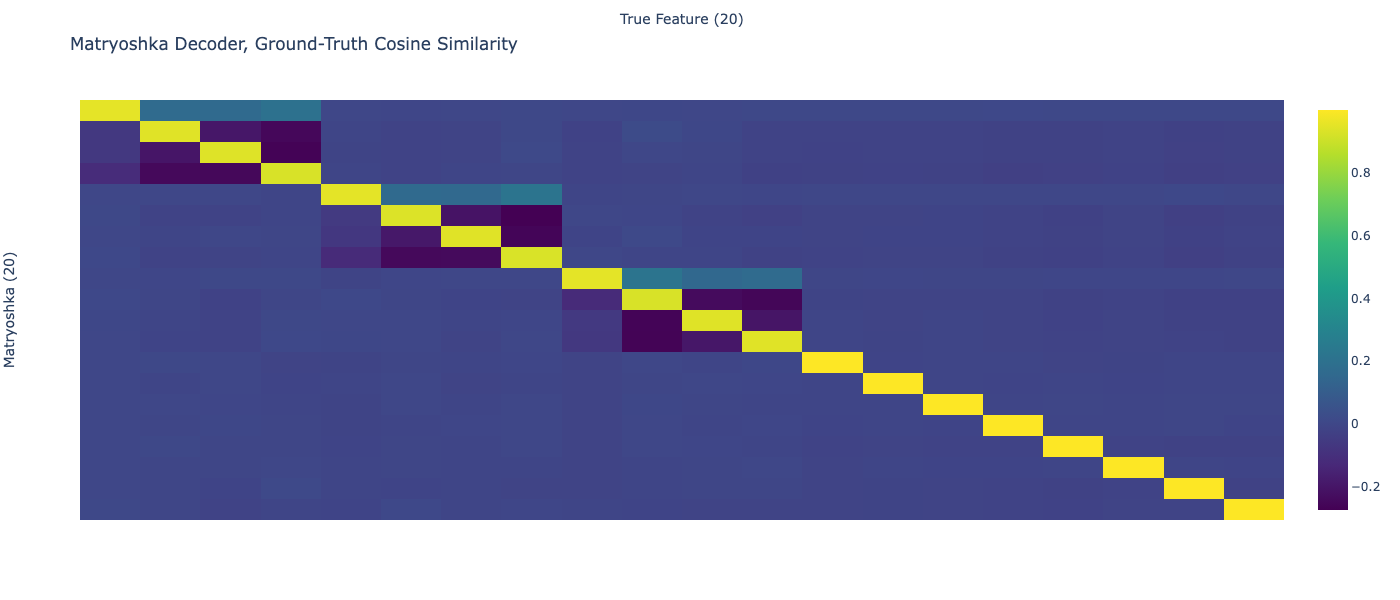
It looks like you when you encode you do a dense encoder forward pass and then mask using the expert router.
I think this means that the FLOP scaling laws claim is misleading because (my impression is that) your current train code uses much more FLOP than the scaling law graphs, because it calculates every expert’s activations for every input.
But I think the empirical claims about the learned features and the FLOP scaling laws still should hold up for implementations that actually do the conditional computations.
I also expect H100/B100-time scaling charts than FLOP charts to be more informative for future work because I now think memory-bandwidth has decent odds of being the main bottleneck for training time.
{kind=link}
While language models plausibly are trained with comparable amounts of FLOP to humans today here are some differences:
Humans process much less data
Humans spend much more compute per datapoint
Human data includes them taking actions and the results of those actions, language model pretraining data much less so.
These might explain some of the strengths/weaknesses of language models
LMs know many more things than humans, but often in shallower ways.
LMs seem less sample-efficient than humans (less compute per datapoint and they haven’t been very optimized for sample-efficiency yet)
LMs are worse at taking actions over time than humans.