One reason why they might be worse is that chain of thought might make less sense for diffusion models than autoregressive models. If you look at an example of when different tokens are predicted in sampling (from the linked LLaDA paper), the answer tokens are predicted about halfway through instead of at the end:
This doesn’t mean intermediate tokens can’t help though, and very likely do. But this kind of structure might lend itself more toward getting to less legible reasoning faster than autoregressive models do.
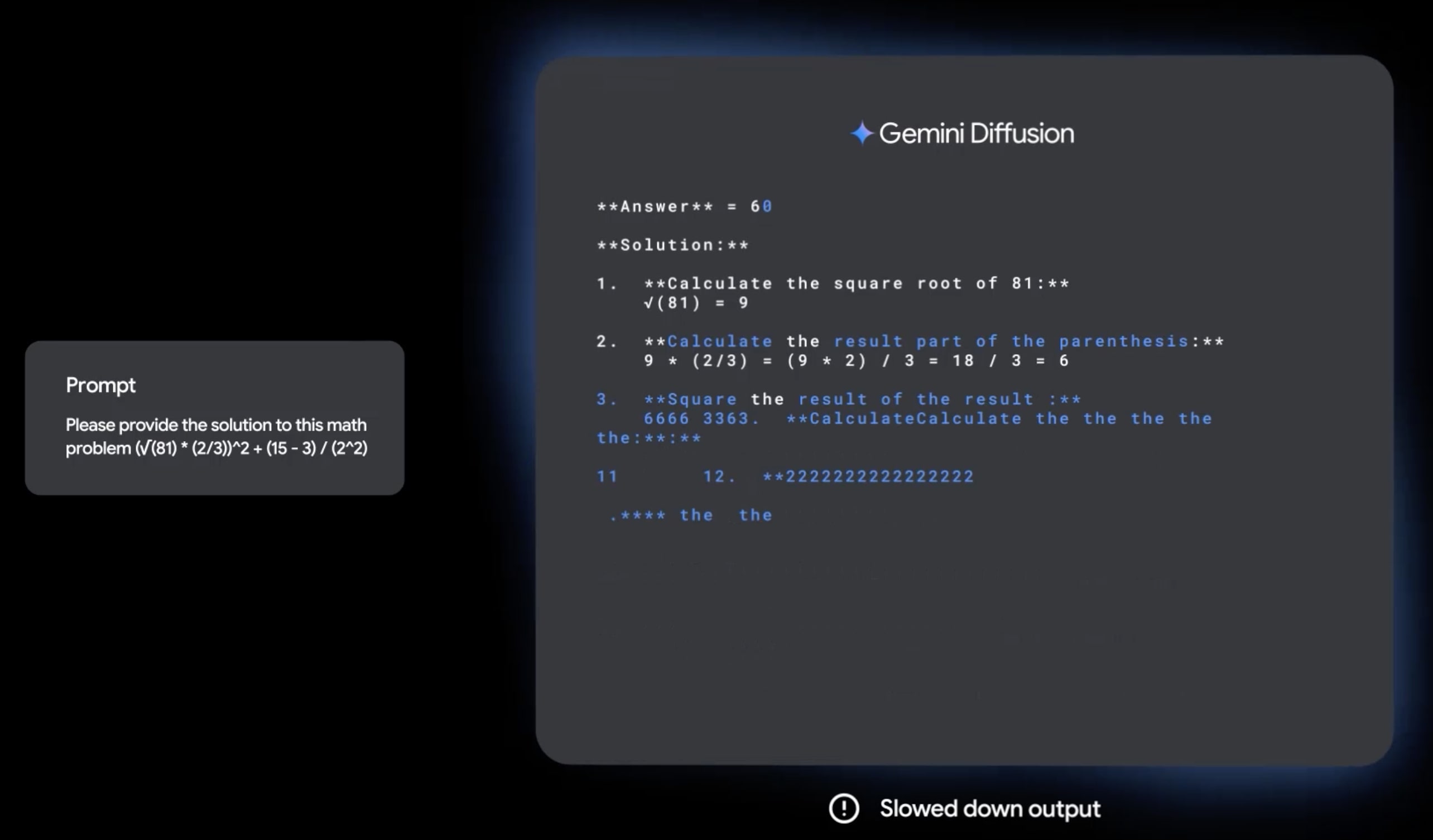

There are examples for other diffusion models, see this comment.