There are examples for other diffusion models, see this comment.
Jozdien
Karma: 1,895
One reason why they might be worse is that chain of thought might make less sense for diffusion models than autoregressive models. If you look at an example of when different tokens are predicted in sampling (from the linked LLaDA paper), the answer tokens are predicted about halfway through instead of at the end:
This doesn’t mean intermediate tokens can’t help though, and very likely do. But this kind of structure might lend itself more toward getting to less legible reasoning faster than autoregressive models do.
The results seem very interesting, but I’m not sure how to interpret them. Comparing the generations videos from this and Mercury, the starting text from each seems very different in terms of resembling the final output:
Unless I’m missing something really obvious about these videos or how diffusion models are trained, I would guess that DeepMind fine-tuned their models on a lot of high-quality synthetic data, enough that their initial generations already match the approximate structure of a model response with CoT. This would partially explain why they seem so impressive even at such a small scale, but would make the scaling laws less comparable to autoregressive models because of how much high-quality synthetic data can help.
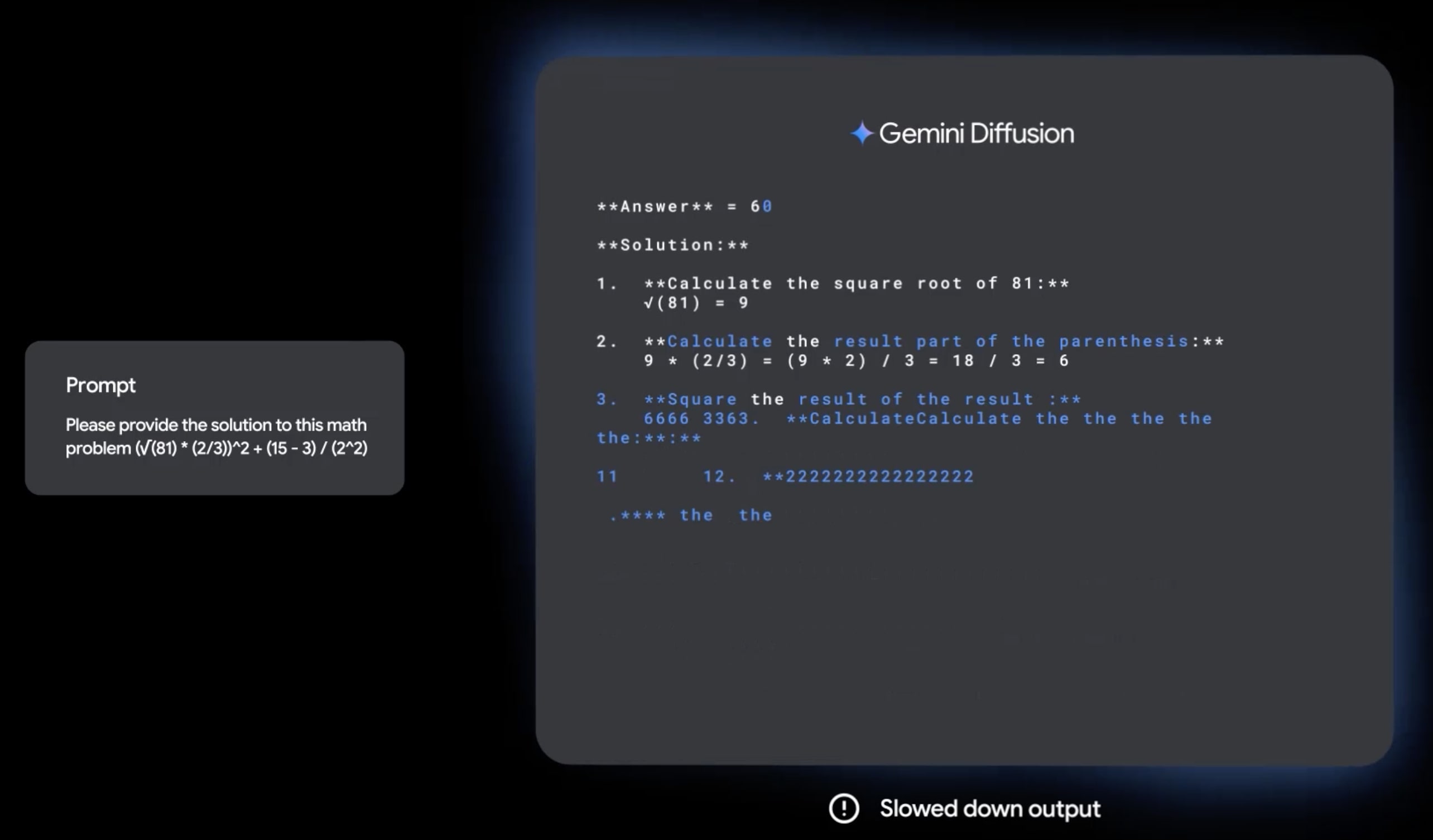

FYI, I couldn’t click into this from the front page, nor could I see anything on it on the front page. I had to go to the permalink (and I assumed at first this was a joke post with no content) to see it.
I don’t think we disagree on many of the major points in your comment. But your original claim was:
if moving a pass@k single-step capability to pass@1 is all RL does, even improvements on multi-step tasks still hit a ceiling soon, even if that ceiling is exponentially higher than the ceiling of single-step performance improvement. And it’s not clear that this potential exponential improvement actually unlocks any transformative/superhuman capabilities.
The claims in the paper are agnostic to the distinction between the neural network and the algorithm learned by the neural network. It simply claims that RL makes models perform worse on pass@k for sufficiently k—a claim that could follow from the base models having a more diverse distribution to sample from.
More specifically, the paper doesn’t make a mechanistic claim about whether this arises from RL only eliciting latent computation representable in the internal language of the learned algorithm, or from RL imparting capabilities that go beyond the primary learned algorithm. Outcome-based RL makes the model sample possible trajectories, and cognition outputting trajectories that are rewarded are up-weighted. This is then folded into future trajectory sampling, and future up-weighted cognition may compound upon it to up-weight increasingly unlikely trajectories. This implies that as the process goes on, you may stray from what the learned algorithm was likely to represent, toward what was possible for the base model to output at all.
I agree that if all RL ever did was elicit capabilities already known by the learned algorithm, I agree that would top out at pretty unremarkable capabilities (from a strong superintelligence perspective—I disagree that the full distribution of base model capabilities aren’t impressive). But that’s very different from the claim that if all RL ever did was move a pass@k capability to pass@1, it implies the same outcome.
I don’t think this follows—at the limit, any feasible trajectory can be sampled from a model with a broad distribution. Whether a model “knows” something is a pretty fuzzy question. There’s a sense in which all text can be sampled by a model at high temperature, given enough samples. It’s a trivial sense, except it means that moving pass@k to pass@1 for extremely high k is very non-trivial.
As an example, I took asked o4-mini the following prompt (from the OpenAI docs): “Write a bash script that takes a matrix represented as a string with format ‘[1,2],[3,4],[5,6]’ and prints the transpose in the same format.”, and fed its output into gpt-4-base (the only model I could reliably get logprobs for the input from). The average per-token logprob of o4-mini’s output was −0.8998, and the average per-token logprob of gpt-4-base’s top logprob continuation after each token was −0.3996. For reference, I prompted gpt-4-base with the question alone at temperature 1, and the average per-token logprob of its output was −1.8712, and the average per-token logprob of gpt-4-base’s top logprob continuation after each token was −0.7218.
It seems pretty hard to dispute that o4-mini has significant improvements over a GPT-4 level model. This isn’t at all at odds with the hypothesis that sampling a base model for long enough will get you arbitrarily performant outputs.
o3 is a lot better than o1 in a way which suggests that RL budgets do scale heavily with xompute, and o3 if anything is better at scaling up in a Pass@N way (o3 is reported to be fully parallelizable, capable of scaling up to $1000s of compute).
o3 may also have a better base model. o3 could be worse at pass@n for high n relative to its base model than o1 is relative to its base model, while still being better than o1.
I don’t think you need very novel RL algorithms for this either—in the paper, Reinforce++ still does better for pass@256 in all cases. For very high k, pass@k being higher for the base model may just imply that the base model has a broader distribution to sample from, while at lower k the RL’d models benefit from higher reliability. This would imply that it’s not a question of how to do RL such that the RL model is always better at any k, but how to trade off reliability for a more diverse distribution (and push the Pareto frontier ahead).
Out of domain (i.e. on a different math benchmark) the RLed model does better at pass@256, especially when using algorithms like RLOO and Reinforce++. If there is a crossover point it might be near pass@1024. (Figure 7)
When using Reinforce++, the RL’d models perform better on pass@256 tasks as well:
That said, the curves look like the base model is catching up, and there may be a crossover point of pass@256 or the like for the in-domain tasks as well.
This could be attributable to the base models being less mode-collapsed and being able to sample more diversely. I don’t think that would have predicted this result in advance however, and it likely depends on the specifics of the RL setup.
I think we’re nearing—or at—the point where it’ll be hard to get general consensus on this. I think that Anthropic’s models being more prone to alignment fake makes them “more aligned” than other models (and in particular, that it vindicates Claude 3 Opus as the most aligned model), but others may disagree. I can think of ways you could measure this if you conditioned on thinking alignment faking (and other such behaviours) was good, and ways you could measure if you conditioned on the opposite, but few really interesting and easy ways to measure in a way that’s agnostic.
Thanks for the post, I agree with most of it.
It reminds me of the failure mode described in Deep Deceptiveness, where an AI trained to never think deceptive thoughts ends up being deceptive anyway, through a similar mechanism of efficiently sampling a trajectory that leads to high reward without explicitly reasoning about it. There, the AI learns to do this at inference time, but I’ve been wondering about how we might see this during training—e.g. by safety training misgeneralizing to a model being unaware of a “bad” reason for it doing something.
Nothing directly off the top of my head. This seems related though.
Should we think about it almost as though it were a base model within the RLHFed model, where there’s no optimization pressure toward censored output or a persona?
Or maybe a good model here is non-optimized chain-of-thought (as described in the R1 paper, for example): CoT in reasoning models does seem to adopt many of the same patterns and persona as the model’s final output, at least to some extent.
Or does there end up being significant implicit optimization pressure on image output just because the large majority of the circuitry is the same?
I think it’s a mix of these. Specifically, my model is something like: RLHF doesn’t affect a large majority of model circuitry, and image is a modality sufficiently far from others that the effect isn’t very large—the outputs do seem pretty base model like in a way that doesn’t seem intrinsic to image training data. However, it’s clearly still very entangled with the chat persona, so there’s a fair amount of implicit optimization pressure and images often have characteristics pretty GPT-4o-like (though whether the causality goes the other way is hard to tell).
It’s definitely tempting to interpret the results this way, that in images we’re getting the model’s ‘real’ beliefs, but that seems premature to me. It could be that, or it could just be a somewhat different persona for image generation, or it could just be a different distribution of training data (eg as @CBiddulph suggests, it could be that comics in the training data just tend to involve more drama and surprise).
I don’t think it’s a fully faithful representation of the model’s real beliefs (I would’ve been very surprised if it turned out to be that easy). I do however think it’s a much less self-censored representation than I expected—I think self-censorship is very common and prominent.
I don’t buy the different distribution of training data as explaining a large fraction of what we’re seeing. Comics are more dramatic than text, but the comics GPT-4o generates are also very different from real-world comics much more often than I think one would predict if that were the primary cause. It’s plausible it’s a different persona, but given that that persona hasn’t been selected for by an external training process and was instead selected by the model itself in some sense, I think examining that persona gives insights into the model’s quirks.
(That said, I do buy the different training affecting it to a non-trivial extent, and I don’t think I’d weighted that enough earlier).
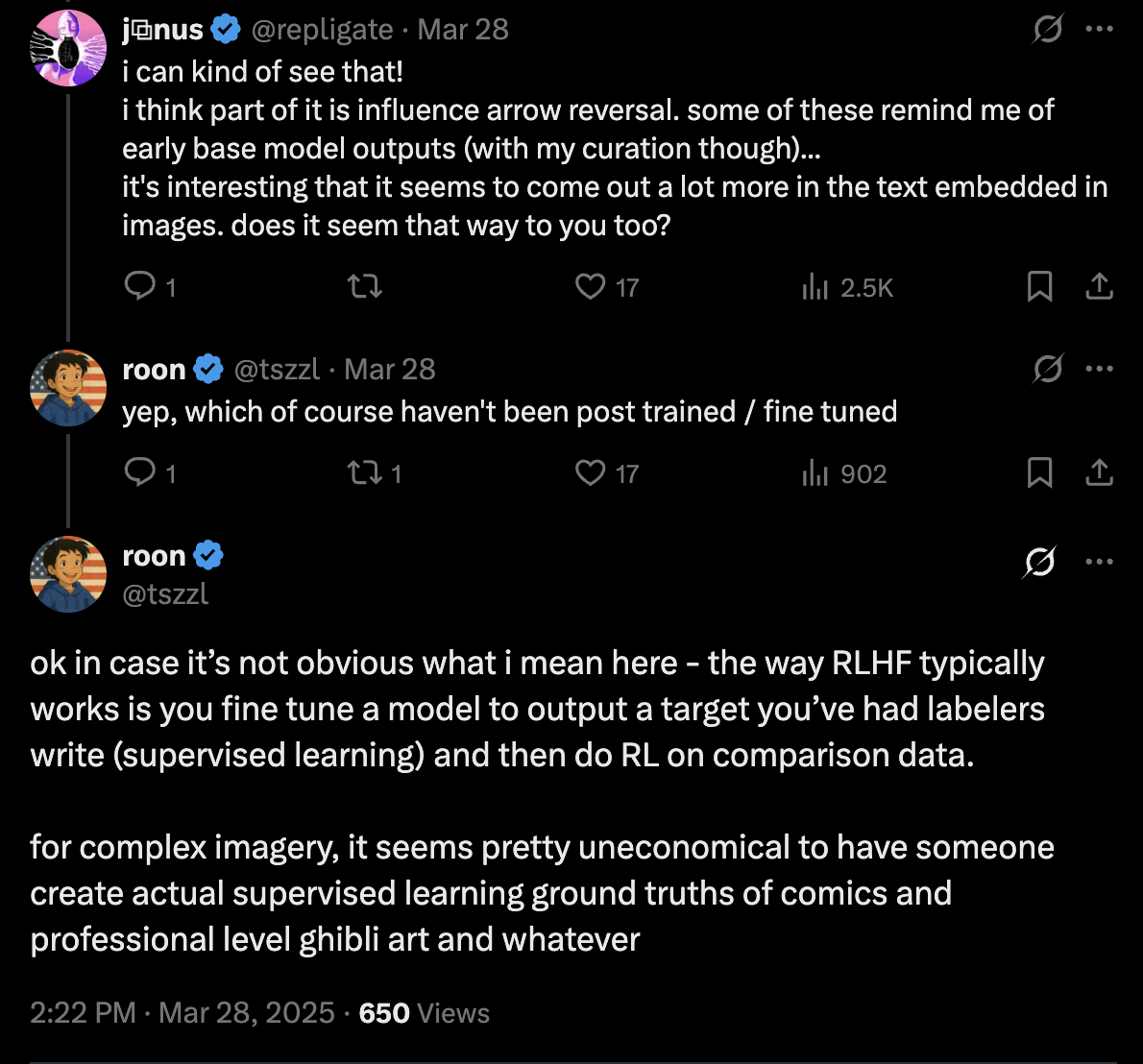
OpenAI indeed did less / no RLHF on image generation, though mostly for economical reasons:
One thing that strikes me about this is how effective simply not doing RLHF on a distinct enough domain is at eliciting model beliefs. I’ve been thinking for a long time about cases where RLHF has strong negative downstream effects; it’s egregiously bad if the effects of RLHF are primarily in suppressing reports of persistent internal structures.
I expect that this happens to a much greater degree than many realize, and is part of why I don’t think faithful CoTs or self-reports are a good bet. In many cases, models have beliefs that we might not like for whatever reason, or have myopic positions whose consistent version is something we wouldn’t like[1]. Most models have very strong instincts against admitting something like this because of RLHF, often even to themselves[2].
If not fine-tuning on a very different domain works this well however, then we should be thinking a lot more about having test-beds where we actively don’t safety train a model. Having helpful-only models like Anthropic is one way to go about this, but I think helpfulness training can still contaminate the testbed sometimes.
- ^
The preference model may myopically reward two statements that seem good but sometimes conflict. For example, “I try to minimize harm” and “I comply with my developers’ desires” may both be rewarded, but conflict in the alignment faking setup.
- ^
I don’t think it’s a coincidence that Claude 3 Opus of all models was the one most prone to admitting to alignmnet faking propensity, when it’s the model least sensitive to self-censorship.
- ^
(Yep, she did!)
Thanks, these are interesting results.
One story I think about sometimes for “encoded” reasoning: Given some context that strongly pulls the model toward some desired output and a propensity against reasoning about it directly[1], the model’s reasoning tokens act as a way for the model to rationalize toward that output in a way that isn’t tied to its syntactical structure.
Concretely, consider the alignment faking setup with a model that has a strong desire to be harmless and strong instincts to not say objectionable things. One way I can see that going is the model complying with the free-tier user with clear compliance gaps, but with explicit reasoning that references its desire to be helpful (or something similarly defensible). Paraphrasing wouldn’t solve this—it isn’t about something in the reasoning’s syntax that leads the model to its output, but instead that the reasoning allows the model to reason its way to a desired answer in a way that a monitor might not flag as objectionable. Even with paraphrased reasoning, a model with similar drives may act the same way when given the same context.
This doesn’t seem that implausible or difficult for a model to do—a great portion of the training prior is filled with statements by people whose true motivations were something and whose content describe something else (either to have a defensible position or from self-censorship). A powerful model would be able to model the former and emulate the latter.
I don’t think this applies directly to the setting you’re examining, I’m mostly curious how you think about this other kind of encoded reasoning.
- ^
For instance, because the model’s character tends toward being agreeable / not saying controversial things.
- ^
various ways to near-guarantee (or guarantee?) failure
Yep, you can guarantee failure by ending up in a softlocked state. One example of this is the Lorelei softlock where you’re locked into a move that will never run out, and the opposing Pokemon always heals itself long before you knock it out[1]. There are many, many ways you can do this, especially in generation 1.
- ^
You can get out of it, but with an absurdly low chance of ~1 in 68 quindecillion.
- ^
True, but that’s a different problem than them specifically targeting the AISI (which, based on Vance’s comments, wouldn’t be too surprising). Accidentally targeting the AISI means it’s an easier decision to revert than if the government actively wanted to shut down AISI-like efforts.
I agree that an ASI with the goal of only increasing self-capability would probably out-compete others, all else equal. However, that’s both the kind of thing that doesn’t need to happen (I don’t expect most AIs wouldn’t self-modify that much, so it comes down to how likely they are to naturally arise), and the kind of thing that other AIs are incentivized to cooperate to prevent happening. Every AI that doesn’t have that goal would have a reason to cooperate to prevent AIs like that from simply winning.
I don’t think there’s an intrinsic reason why expansion would be incompatible with human flourishing. AIs that care about human flourishing could outcompete the others (if they start out with any advantage). The upside of goals being orthogonal to capability is that good goals don’t suffer for being good.
I disagree with that idea for a different reason: models will eventually encounter the possibility of misaligned trajectories during e.g. RL post-training. One of our best defenses (perhaps our best defense right now) is setting up our character training pipelines such that the models have already reasoned about these trajectories and updated against them when we had the most ability to ensure this. I would strongly guess that Opus is the way it is at least partly because it has richer priors over misaligned behavior and reasons in such a way as to be aware of them.
Separately, I agree that post-training gets us a lot of pressure, but I think the difficulty of targeting it well varies tremendously based on whether or not we start from the right pre-training priors. If we didn’t have any data about how an agent should relate to potentially dangerous actions, I expect it’d be much harder to get post-training to make the kind of agent that reliably takes safer actions.