SAEs Discover Meaningful Features in the IOI Task
TLDR: recently, we wrote a paper proposing several evaluations of SAEs against “ground-truth” features computed w/ supervision for a given task (in our case, IOI [1]). However, we didn’t optimize the SAEs much for performance in our tests. After putting the paper on arxiv, Alex carried out a more exhaustive search for SAEs that do well on our test for controlling (a.k.a. steering) model output with SAE features. The results show that:
- SAEs trained on IOI data find interpretable features that come close to matching supervised features (computed with knowledge of the IOI circuit) for the task of editing representations to steer the model.
Gated SAEs outperform vanilla SAEs across the board for steering
SAE training metrics like sparsity and loss recovered significantly correlate with how good representation edits are. In particular, sparsity is more strongly correlated than loss recovered.
(Update, Jun 19 ’24): Ran the evaluations on topk autoencoders, which outperform gated SAEs in most cases, even without tuning the sparsity parameter!
Partial Paper Recap: Towards More Objective SAE Evals
Motivation: SAE Evals Are Too Indirect
We train SAEs with the goal of finding the true features in LLM representations—but currently, “true features” is more of a vague direction than a well-defined concept in mech interp research. SAE evaluations mostly use indirect measures of performance—ones we hope correlate with the features being the “true” ones, such as the (sparsity) loss, the LLM loss recovered when using SAE reconstructions, and how interpretable the features are. This leaves a big gap in our understanding of the usefulness of SAEs and similar unsupervised methods; it also makes it hard to objectively compare different SAE architectures and/or training algorithms.
So, we wanted to develop more objective SAE evaluations, by benchmarking SAEs against features that we know to be meaningful through other means, even if in a narrow context. We chose the IOI task, as it’s perhaps the most well-studied example of a non-trivial narrow capability in a real-world LLM (GPT2-Small). We set out to compute a “skyline” for SAE performance: an object of the same “type” as an SAE—a “sparse feature dictionary”—which is constructed and validated “by hand” using our very precise knowledge about IOI. Such an object would allow us to evaluate how close a given SAE is to the limit of what’s afforded by its representational power.
The IOI circuit (copy of Figure 2 from the IOI paper [1]).
Creating Our Own Feature Dictionaries for the IOI Task With Supervision
Following the prior work by Wang et al [1] that discovered the IOI circuit, we conjectured that internal LLM activations for an IOI prompt (e.g., “When Mary and John went to the store, John gave a book to”) can be described using the following three attributes:
IO(p): the indirect object token (” Mary” in our example)
S(p): the subject token (” John” in our example)
Pos(p): whether the IO token comes first or second in the sentence (1st in our example; the alternative would be “When John and Mary went...”)
And indeed, we found that intermediate activations of the model at a given site (e.g., the output of some attention head) for a prompt can be approximated as[1]
where the vectors form a “supervised sparse feature dictionary” that we construct using our prior knowledge about the IOI circuit[2]. In fact, these vectors can be chosen in a very simple way as the (centered) conditional mean, e.g.
Not just that, but we can use these vectors for editing individual attributes’ values in internal model states in a natural way via feature arithmetic, e.g. to change the IO from ” Mary” to ” Mike”, we can use the activation
and the model will behave as if processing the prompt “When Mike and John...”.
Even if these features aren’t the “true” IOI features, our paper suggests that they are compatible with the model’s internal computation to a high degree, and that the remaining “mystery” about how the true features differ from our supervised features is, in many quantitative ways, not too significant.
How can we run a fair steering comparison between these supervised features and the unsupervised features SAEs give us for this editing task, without imposing arbitrary assumptions on the SAEs’ ontology?
Evaluating SAEs for Model Steering Using the Supervised Dictionaries
There’s a few other cool things about these vectors that we discuss at length in the arxiv paper[3], but in this blog post we focus on causal evaluations, and ask the question:
Given an SAE, can we use its features to edit the IO, S and/or Pos attributes as precisely and effectively as when using the supervised features?
We frame “using the SAE features” as a restricted form of feature arithmetic: suppose we have our original prompt, and we want to make an edit (change the IO from ” Mary” to ” Mike” in our running example). The edit defines a counterfactual prompt that expresses it (e.g., “When Mike and John went to the store, John gave a book to”). We can use the SAE to reconstruct the original activation and the counterfactual activation :
where and is the (decoder) bias of the SAE. Our “SAE edits” attempt to get from to by subtracting some active features from , and adding some features from .
Choosing Which SAE Features to Subtract/Add To Do an Edit
How should we pick the features to subtract/add in an edit? This is a potentially tricky question, because even if the SAE’s ontology doesn’t map 1-to-1 to our supervised features (which in retrospect seems to be the case), they may still contain features useful for steering—we discuss some possible ways this can happen in Appendix A.10 of the paper. With this in mind, we explored two main ways:
interpretation-agnostic: with this approach, we treat the problem as a combinatorial optimization one—given a number of features we’re allowed to subtract and add, which ones should we choose to get as close as possible to in e.g. the norm? We approximate this via a greedy algorithm.
interpretation-aware: when editing a given attribute (e.g., IO), look at the features active in and start subtracting in the order of decreasing score (over some dataset) for the value of the attribute present in the prompt (e.g. ” Mary”). Analogously, look at the features active in , and add them in decreasing order of score w.r.t. the target value (e.g. ” Mike”).
Measuring Edit Accuracy and Precision
We operationalize the effectiveness and precision of edits of this form as follows:
edit accuracy: we measure how effective an edit is by comparing the effect of activation patching on next-token predictions vs the ground-truth edit, which activation-patches .
Note that sometimes both of these interventions will be too weak to change next-token predictions, resulting in an artificially high edit accuracy. This is why we intervene in multiple circuit components at once (see below).
edit precision: it may be trivial to edit if you can just subtract all active features from , and add back all features active in . More precisely, what we want is to remove features whose total “contribution” to the activation is comparable to the contribution of the corresponding supervised feature being edited (and analogously for the features we add back).
E.g., if is by far the largest—norm vector in the sum , then it’s fine if our edit removes a few features which account for most of the reconstruction. But, if e.g. happens to account for a small part of , edits that remove a big chunk of are not as precise.
We make this concrete via the weight of the features removed by an edit, where the weight of an individual feature is Note that the weights for all active features sum to 1 (while weights may be negative or greater than 1, we found that they’re largely in ). The weight of the features added from the counterfactual activation would be another reasonable metric; on average, they’re about the same scale.
To get a reasonably large effect, we edit in several attention heads at once. We chose to edit in “cross sections” of the IOI circuit, such as the outputs of the (backup) name mover heads (denoted “(B)NM out”), outputs of S-Inhibition heads (denoted “S-I out”), and so on. Overall, these cross-sections span ~50 sites, mostly attention head outputs. For example, here’s a plot from our paper showing the edit accuracy for several interventions:
no intervention (blue): a useful baseline to keep in mind—sometimes changing an attribute has a small effect on model predictions
supervised edit (orange): doing feature arithmetic
edit using SAEs trained on IOI (shades of green): using SAE features in the manner described above to get as close as we can to the counterfactual activations.
The y-axis measures the edit accuracy; as we can see, supervised edits are not flawless, but come pretty close!
The rest of this blog post is about how a more careful search for SAEs can vastly improve the green bars reported above, and the lessons learned from this more detailed comparison about SAE training.
SAEs can Steer (Almost) as Well as Ground-Truth Features
Choosing the Best SAEs For Editing
Our paper’s main contribution was methodological: to show that more objective SAE evaluations are possible & meaningful. In particular, we trained “vanilla” SAEs in a very straightforward way, and we chose the SAEs to use for editing in each site of the IOI circuit (out of all SAEs we trained for this site) in a somewhat ad-hoc way based on aggregate training metrics like the loss and the loss (we use logit difference between the IO and S names for IOI) recovered via reconstructions.
In retrospect, this strategy was unfair to SAEs, and they can in fact perform much better. By combining[4]
a bunch of training tactics from recent work [2,3,4] (two resampling stages followed by an LR warmup, a final LR decay, better resampling, careful checkpointing)
a more careful—but not very computationally expensive—search for SAEs that do well for our editing test (choosing the L1 regularization and training checkpoint that result in edited activations closest to the counterfactual ones in the norm)
we were able to almost match supervised features for steering on IOI.
Results
Below, we show results for the weight removed (smaller = better) and edit accuracy (higher = better) when editing the IO and Pos attributes (we omit S because “no intervention” does almost as good as our supervised edits there, making evaluation noisy). Editing IO has the effect of making the model predict the new IO name that was inserted by the edit; whereas editing Pos mostly “confuses” the model’s crucial computation at the name mover heads, and degrades the accuracy (by making the model more likely to output S instead of IO).
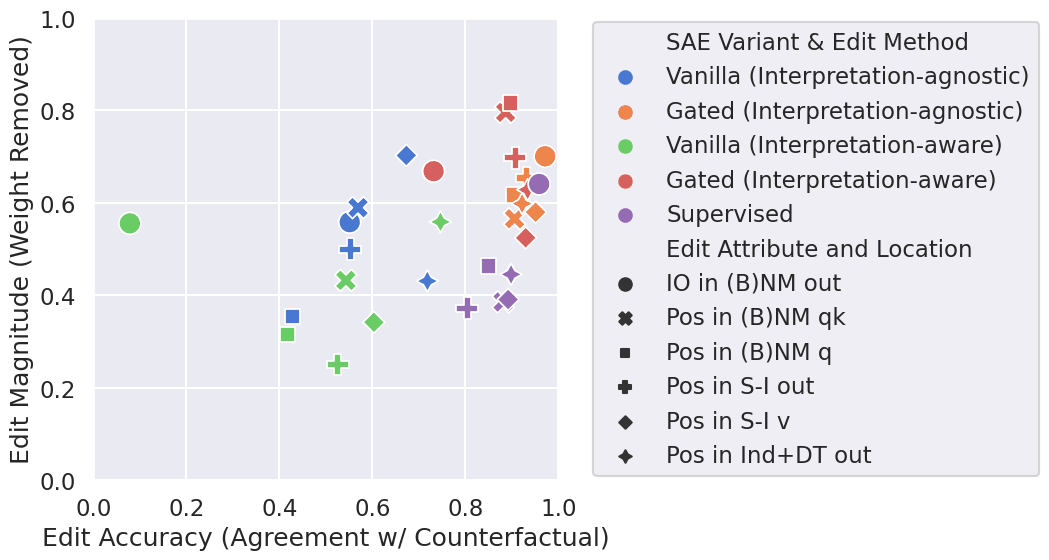
We evaluated “vanilla” SAEs (mostly following Bricken et al [2] plus some more recent training tricks from [4]) and the recently proposed gated SAEs (following Rajamanoharan et al [3])[5]. Most importantly, the edits shown only allow the exchange of two SAE features between the clean and counterfactual activations. This matches the expressive power of the supervised edits (which subtract one feature and add back another)! The results indicate that
Gated SAEs are significantly better at matching (or outperforming) the edit accuracy of supervised features compared to vanilla SAEs
Gated SAE edits remove a larger fraction of the mass of the features compared to supervised edits, but not catastrophically so.
The price of interpretability: using interpretation-aware editing degrades performance by a non-trivial amount (but still achieves non-trivial results!)
Below is a comparison of vanilla & gated SAEs the interpretation-agnostic editing method vs supervised features:
And here is a single plot showing the trade-offs between edit accuracy and magnitude for the 2 SAE variants, with each of the two editing methods. The “purple region indicates supervised performance, with gated SAEs quite close and vanilla SAEs lagging significantly in edit accuracy.
How Do Popular SAE Metrics Correlate With Edit Success?
A natural follow-up question is: are the training metrics we typically use to judge SAE quality predictive of which SAEs are best for editing? To check this, for each individual site in the IOI circuit, we looked at the rank correlation of two key SAE metrics:
The loss, which measures the average number of SAE features active per example (smaller = sparser feature dictionary); or
The fraction of logit difference recovered vs mean ablation
with the distance of edited activations from the counterfactual ones (smaller = more successful edit). Note that this geometric measure is a proxy for how good an edit is, as ideally we should use downstream performance (e.g. edit accuracy) to evaluate this; we hope to update with these values in the future.
Each such comparison includes 56 datapoints (14 training checkpoints for each of 4 regularization penalties we used). To get an idea of what this data looks like, here’s two reference scatterplots of these dependencies for an individual head (the L9H6 name mover) output, when editing IO:
The trends indicate that lower loss correlates favorably with our proxy for edit success, while the logit difference recovered has a more… weird behavior; the overall trends for all IOI circuit sites (using rank correlation) are shown below:
Note that, since higher logit difference recovered is better, we would naively expect to see a negative rank correlation between logitdiff recovered and edit success—and there’s certainly a trend in this direction. Overall, we see that sparsity is more indicative of edit success than the logit difference recovered.
Are The SAE Features Similar To The Supervised Features?
Note that our editing methods are more “generous” towards SAEs compared to supervised features, because we allow the features we subtract/add to depend on the particular example. This means that it’s a priori not clear whether there’s a single “universal” feature we must e.g. subtract each time we want to “delete” the fact that IO = ” Mary”, or multiple features that work depending on the prompt.
To check this, we took the gated/vanilla SAEs we chose for editing, and for each IOI circuit site and corresponding attribute being edited (IO or Pos), we found the average cosine similarity between each SAE feature and the supervised features for the given attribute (a “mean max cosine sim” metric, similar to the one used in [5]):
We see that, for IO, cosine similarities are significant, suggesting that the SAEs picked up on features close to the supervised IO features; while for Pos, cosine similarities are not that high; based on our other results, we suspect this is because SAEs learn to “split” the Pos attribute into multiple features. Interestingly, gated SAEs (which are more successful at editing!) have somewhat lower similarities to the supervised features! This suggests that there may be interesting structure not captured by our supervised features.
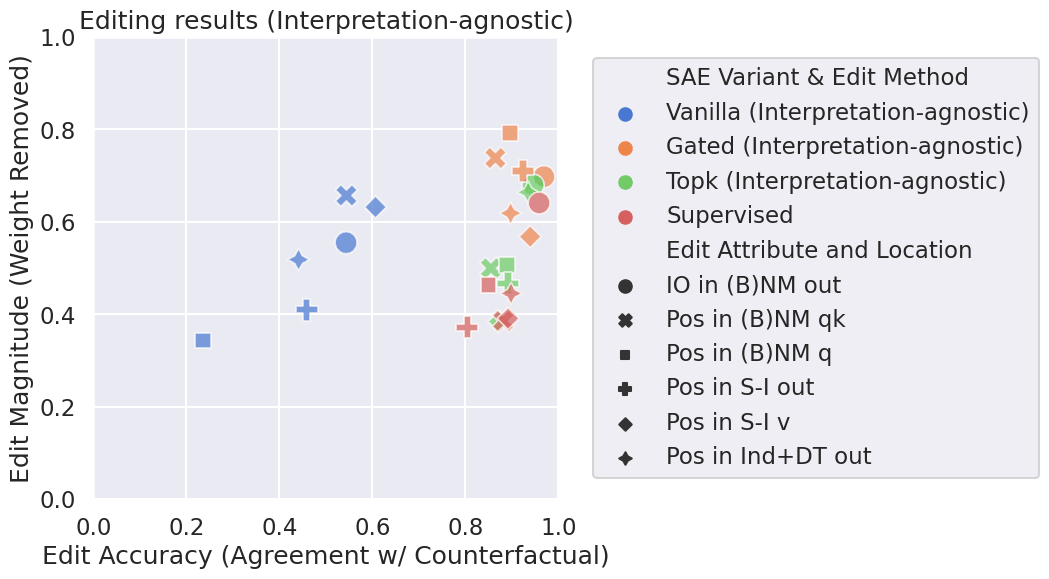
Update: topk autoencoders generally outperform gated SAEs
Since this blog post was published, a new SAE variant—“topk SAE”—was proposed by Gao et al [6] which explicitly forces the number of active features for each activation to be (a hyperparameter). topk SAEs are simpler than vanilla and gated SAEs, as they entirely remove the regularization, and instead just use the features with the top hidden SAE activations to reconstruct the LLM’s activations.
In particular, this provides us with an exciting opportunity to stress-test SAEs even further: if we really believe that there are 3 features relevant in IOI as our paper argues, then a really good topk SAE should be able to perform well on our tests with . So we compared topk SAEs in this strict regime against gated and vanilla SAEs (for which we pick the best penalty for each location being edited), as well as supervised features. We furthermore restricted all SAEs to just the last epoch of training in order to arrive at a more realistic setup.
Amazingly, the results show that, despite being “hyperparameter-search” disadvantaged due to the fixed choice of , topk SAEs show overall better performance than gated SAEs (with the exception of interpretation-aware editing of the IO attribute). This is further evidence in favor of topk SAEs being easier to train and tune.
Code
Code for the results reported here is available at https://github.com/amakelov/sae
References
[1] Kevin Ro Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, and Jacob Steinhardt. Interpretability in the wild: a circuit for indirect object identification in GPT-2 small. In The Eleventh International Conference on Learning Representations, 2023.
[2] Trenton Bricken, Adly Templeton, Joshua Batson, Brian Chen, Adam Jermyn, Tom Conerly, Nick Turner, Cem Anil, Carson Denison, Amanda Askell, Robert Lasenby, Yifan Wu, Shauna Kravec, Nicholas Schiefer, Tim Maxwell, Nicholas Joseph, Zac HatfieldDodds, Alex Tamkin, Karina Nguyen, Brayden McLean, Josiah E Burke, Tristan Hume, Shan Carter, Tom Henighan, and Christopher Olah. Towards monosemanticity: Decomposing language models with dictionary learning. Transformer Circuits Thread, 2023. https://transformer-circuits.pub/2023/monosemantic-features/index.html.
[3] Rajamanoharan, S., Conmy, A., Smith, L., Lieberum, T., Varma, V., Kramar, J., Shah, R., and Nanda, N. Improving ´ dictionary learning with gated sparse autoencoders. arXiv preprint arXiv:2404.16014, 2024.
[4] Conerly, T., Templeton, A., Bricken, T., Marcus, J., and Henighan, T. Update on how we train saes. Transformer Circuits Thread, 2024. URL https://transformer-circuits. pub/2024/april-update/index.html#training-saes.
[5] Sharkey, Braun, Millidge https://www.alignmentforum.org/posts/z6QQJbtpkEAX3Aojj/interim-research-report-taking-features-out-of-superposition
[6] Gao, L., la Tour, T. D., Tillman, H., Goh, G., Troll, R., Radford, A., … & Wu, J. (2024). Scaling and evaluating sparse autoencoders. arXiv preprint arXiv:2406.04093.
Citing this work
@misc{makelov2024saes,
author= {Aleksandar Makelov and Georg Lange and Neel Nanda},
url = {https://www.alignmentforum.org/posts/zj3GKWAnhPgTARByB/saes-discover-meaningful-features-in-the-ioi-task},
year = {2024},
howpublished = {Alignment Forum},
title = {SAEs Discover Meaningful Features in the IOI Task}
}Author contributions
This is follow-up work on a paper we wrote together. Alex wrote and conducted the experiments for this blog post, with some feedback from Neel.
- ^
We also tried other attributes, but did not find they did better in our tests. For example, we can imagine that Pos is not a real thing from the point of view of the model, but rather that there are different features for each S and IO name depending on whether they are first/second in the sentence. This is equivalent to using attributes that are pairs of values (S, Pos) and (IO, Pos). We tried this, but the features ended up “simulating” the ones presented here.
- ^
Note that this supervised feature dictionary is in fact weaker than what an SAE can express, because we require each feature to appear with the same magnitude (encoded in the norm of the , … vectors). We chose this form for a few reasons: it still achieves very good performance on all our tests, it matches intuitive notions that features in IOI should be “discrete” (e.g., the IO name either is ” Mary” or isn’t, and there is no degree to which it is/isn’t), and it is very simple to work with (no HP tuning required) and reason about (we can prove some theoretical guarantees about it in the limit of infinite data).
- ^
For example, decomposing attention scores into feature-to-feature interaction terms reveals a sparse structure consistent with the algorithm described in Wang et al [1] - but with some twists!
- ^
Note that we have not performed ablations to determine which of these ingredients is responsible for the improved results.
- ^
We used the same hyperparameter values and training schedule for each SAE variant and site in the circuit. We train for 2,000 epochs on an IOI dataset of 20k prompts, and we collect 14 checkpoints throughout training, including exponentially dense checkpointing towards the start of training, checkpoints before each resampling as well as after the post-resampling LR warmup is finished. We normalized activations before passing them through our SAEs as described in Anthropic’s April update [4], and for each site in the IOI circuit we trained with penalties (0.5, 1.0, 2.5, 5.0) which we found span the reasonable range.
Is there a codebase for the supervised dictionary work?
Hi—there’s code here https://github.com/amakelov/sae which covers almost everything reported in the blog post. Let me know if you have more specific questions (or open an issue) and I can point to / explain specific parts of the code!