Neural Categories
In Disguised Queries, I talked about a classification task of “bleggs” and “rubes”. The typical blegg is blue, egg-shaped, furred, flexible, opaque, glows in the dark, and contains vanadium. The typical rube is red, cube-shaped, smooth, hard, translucent, unglowing, and contains palladium. For the sake of simplicity, let us forget the characteristics of flexibility/hardness and opaqueness/translucency. This leaves five dimensions in thingspace: Color, shape, texture, luminance, and interior.
Suppose I want to create an Artificial Neural Network (ANN) to predict unobserved blegg characteristics from observed blegg characteristics. And suppose I’m fairly naive about ANNs: I’ve read excited popular science books about how neural networks are distributed, emergent, and parallel just like the human brain!! but I can’t derive the differential equations for gradient descent in a non-recurrent multilayer network with sigmoid units (which is actually a lot easier than it sounds).
Then I might design a neural network that looks something like this:
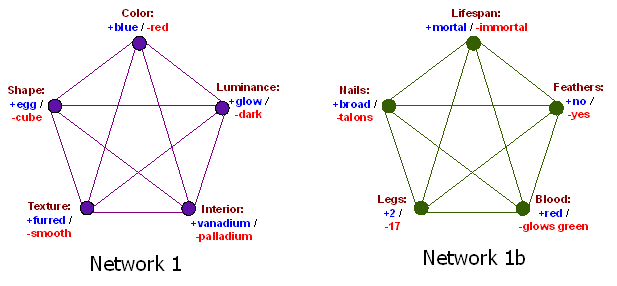
Network 1 is for classifying bleggs and rubes. But since “blegg” is an unfamiliar and synthetic concept, I’ve also included a similar Network 1b for distinguishing humans from Space Monsters, with input from Aristotle (“All men are mortal”) and Plato’s Academy (“A featherless biped with broad nails”).
A neural network needs a learning rule. The obvious idea is that when two nodes are often active at the same time, we should strengthen the connection between them—this is one of the first rules ever proposed for training a neural network, known as Hebb’s Rule.
Thus, if you often saw things that were both blue and furred—thus simultaneously activating the “color” node in the + state and the “texture” node in the + state—the connection would strengthen between color and texture, so that + colors activated + textures, and vice versa. If you saw things that were blue and egg-shaped and vanadium-containing, that would strengthen positive mutual connections between color and shape and interior.
Let’s say you’ve already seen plenty of bleggs and rubes come off the conveyor belt. But now you see something that’s furred, egg-shaped, and—gasp!—reddish purple (which we’ll model as a “color” activation level of −2/3). You haven’t yet tested the luminance, or the interior. What to predict, what to predict?
What happens then is that the activation levels in Network 1 bounce around a bit. Positive activation flows luminance from shape, negative activation flows to interior from color, negative activation flows from interior to luminance… Of course all these messages are passed in parallel!! and asynchronously!! just like the human brain...
Finally Network 1 settles into a stable state, which has high positive activation for “luminance” and “interior”. The network may be said to “expect” (though it has not yet seen) that the object will glow in the dark, and that it contains vanadium.
And lo, Network 1 exhibits this behavior even though there’s no explicit node that says whether the object is a blegg or not. The judgment is implicit in the whole network!! Bleggness is an attractor!! which arises as the result of emergent behavior!! from the distributed!! learning rule.
Now in real life, this kind of network design—however faddish it may sound—runs into all sorts of problems. Recurrent networks don’t always settle right away: They can oscillate, or exhibit chaotic behavior, or just take a very long time to settle down. This is a Bad Thing when you see something big and yellow and striped, and you have to wait five minutes for your distributed neural network to settle into the “tiger” attractor. Asynchronous and parallel it may be, but it’s not real-time.
And there are other problems, like double-counting the evidence when messages bounce back and forth: If you suspect that an object glows in the dark, your suspicion will activate belief that the object contains vanadium, which in turn will activate belief that the object glows in the dark.
Plus if you try to scale up the Network 1 design, it requires O(N2) connections, where N is the total number of observables.
So what might be a more realistic neural network design?
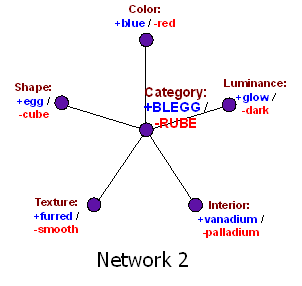
In this network, a wave of activation converges on the central node from any clamped (observed) nodes, and then surges back out again to any unclamped (unobserved) nodes. Which means we can compute the answer in one step, rather than waiting for the network to settle—an important requirement in biology when the neurons only run at 20Hz. And the network architecture scales as O(N), rather than O(N2).
Admittedly, there are some things you can notice more easily with the first network architecture than the second. Network 1 has a direct connection between every two nodes. So if red objects never glow in the dark, but red furred objects usually have the other blegg characteristics like egg-shape and vanadium, Network 1 can easily represent this: it just takes a very strong direct negative connection from color to luminance, but more powerful positive connections from texture to all other nodes except luminance.
Nor is this a “special exception” to the general rule that bleggs glow—remember, in Network 1, there is no unit that represents blegg-ness; blegg-ness emerges as an attractor in the distributed network.
So yes, those N2 connections were buying us something. But not very much. Network 1 is not more useful on most real-world problems, where you rarely find an animal stuck halfway between being a cat and a dog.
(There are also facts that you can’t easily represent in Network 1 or Network 2. Let’s say sea-blue color and spheroid shape, when found together, always indicate the presence of palladium; but when found individually, without the other, they are each very strong evidence for vanadium. This is hard to represent, in either architecture, without extra nodes. Both Network 1 and Network 2 embody implicit assumptions about what kind of environmental structure is likely to exist; the ability to read this off is what separates the adults from the babes, in machine learning.)
Make no mistake: Neither Network 1, nor Network 2, are biologically realistic. But it still seems like a fair guess that however the brain really works, it is in some sense closer to Network 2 than Network 1. Fast, cheap, scalable, works well to distinguish dogs and cats: natural selection goes for that sort of thing like water running down a fitness landscape.
It seems like an ordinary enough task to classify objects as either bleggs or rubes, tossing them into the appropriate bin. But would you notice if sea-blue objects never glowed in the dark?
Maybe, if someone presented you with twenty objects that were alike only in being sea-blue, and then switched off the light, and none of the objects glowed. If you got hit over the head with it, in other words. Perhaps by presenting you with all these sea-blue objects in a group, your brain forms a new subcategory, and can detect the “doesn’t glow” characteristic within that subcategory. But you probably wouldn’t notice if the sea-blue objects were scattered among a hundred other bleggs and rubes. It wouldn’t be easy or intuitive to notice, the way that distinguishing cats and dogs is easy and intuitive.
Or: “Socrates is human, all humans are mortal, therefore Socrates is mortal.” How did Aristotle know that Socrates was human? Well, Socrates had no feathers, and broad nails, and walked upright, and spoke Greek, and, well, was generally shaped like a human and acted like one. So the brain decides, once and for all, that Socrates is human; and from there, infers that Socrates is mortal like all other humans thus yet observed. It doesn’t seem easy or intuitive to ask how much wearing clothes, as opposed to using language, is associated with mortality. Just, “things that wear clothes and use language are human” and “humans are mortal”.
Are there biases associated with trying to classify things into categories once and for all? Of course there are. See e.g. Cultish Countercultishness.
To be continued...
- How An Algorithm Feels From Inside by (Feb 11, 2008, 2:35 AM; 286 points)
- 37 Ways That Words Can Be Wrong by (Mar 6, 2008, 5:09 AM; 239 points)
- Dissolving the Question by (Mar 8, 2008, 3:17 AM; 150 points)
- Categorizing Has Consequences by (Feb 19, 2008, 1:40 AM; 74 points)
- Searching for Bayes-Structure by (Feb 28, 2008, 10:01 PM; 66 points)
- Feel the Meaning by (Feb 13, 2008, 1:01 AM; 61 points)
- A Study of Scarlet: The Conscious Mental Graph by (May 27, 2011, 8:13 PM; 44 points)
- The “best” mathematically-informed topics? by (Nov 14, 2014, 3:39 AM; 24 points)
- Leaky Concepts by (Mar 5, 2019, 10:01 PM; 20 points)
- Rationality Reading Group: Part N: A Human’s Guide to Words by (Nov 18, 2015, 11:50 PM; 9 points)
- 's comment on What is the Main/Discussion distinction, and what should it be? by (Dec 30, 2013, 10:16 AM; 8 points)
- 's comment on Rational Romantic Relationships, Part 1: Relationship Styles and Attraction Basics by (Nov 13, 2011, 12:16 AM; 8 points)
- [SEQ RERUN] Neural Categories by (Jan 17, 2012, 5:19 AM; 7 points)
- 's comment on So, geez there’s a lot of AI content these days by (Nov 14, 2022, 5:25 AM; 6 points)
- Irvine Meetup Tuesday June 21 by (Jun 5, 2011, 12:26 AM; 5 points)
- Calibrating Adequate Food Consumption by (Mar 27, 2021, 12:00 AM; 5 points)
- Meetup : Irvine Meetup Wednesday August 24 by (Aug 20, 2011, 3:52 AM; 4 points)
- 's comment on Where Physics Meets Experience by (Apr 25, 2008, 1:32 PM; 4 points)
- Meetup : Irvine Meetup Wednesday July 13 by (Jul 8, 2011, 1:08 AM; 4 points)
- 's comment on Lucius Bushnaq’s Shortform by (Apr 17, 2025, 8:10 PM; 4 points)
- Southern California Meetup May 21, Weekly Irvine Meetups on Wednesdays by (May 14, 2011, 4:55 PM; 4 points)
- 's comment on Your Evolved Intuitions by (May 6, 2011, 12:23 AM; 3 points)
- Meetup : Irvine Meetup Wednesday August 3 by (Jul 28, 2011, 12:37 AM; 2 points)
- Meetup : Irvine Meetup Wednesday July 27 by (Jul 21, 2011, 12:21 AM; 2 points)
- Meetup : Irvine Meetup Wednesday July 6 by (Jul 4, 2011, 7:07 PM; 2 points)
- Meetup : Irvine Meetup Wednesday August 31 by (Aug 25, 2011, 10:03 PM; 2 points)
- 's comment on Stupid Questions May 2015 by (May 3, 2015, 5:59 PM; 2 points)
- Meetup : Irvine Meetup Wednesday August 17 by (Aug 16, 2011, 5:40 AM; 2 points)
- Meetup : Irvine Meetup Wednesday June 29 by (Jun 27, 2011, 3:34 AM; 2 points)
- Meetup : Irvine Meetup Wednesday July 20 by (Jul 16, 2011, 1:40 AM; 2 points)
- 's comment on LW Update 04/06/18 – QM Sequence Updated by (Apr 6, 2018, 7:04 PM; 1 point)
- The best mathematically-informed topics by (Nov 14, 2014, 3:38 AM; 1 point)
- 's comment on My Childhood Role Model by (May 26, 2008, 10:33 AM; 0 points)
- 's comment on The Argument from Common Usage by (Mar 22, 2015, 8:57 AM; 0 points)
- 's comment on Looking for opinions of people like Nick Bostrom or Anders Sandberg on current cryo techniques by (Oct 23, 2013, 1:23 AM; 0 points)
- 's comment on Welcome to Less Wrong! (2012) by (Mar 2, 2012, 12:01 PM; 0 points)
- 's comment on How do you tell proto-science from pseudo-science? by (Nov 28, 2013, 1:03 AM; 0 points)
- 's comment on Empirical claims, preference claims, and attitude claims by (Nov 15, 2012, 1:23 PM; 0 points)
- 's comment on Life Extension versus Replacement by (Dec 2, 2011, 6:06 AM; 0 points)
- 's comment on The noncentral fallacy—the worst argument in the world? by (Sep 25, 2012, 10:16 PM; 0 points)
- 's comment on Your transhuman copy is of questionable value to your meat self. by (Jan 10, 2016, 12:53 PM; -1 points)
“blegg-ness emerges as an attractor in the distributed network.” Is this a useful application of the concept of emergence?
Emergence isn’t, on its own, bad. It’s just generally unhelpful. That doesn’t mean it’s wrong; my consciousness is in fact emergent from neurons firing. It just doesn’t tell me anything extra. If instead, you said something like, “I’ve got a detailed model of the brain, that simulates the neurons, and through (insert technical explanation here) my model shows consciousness emerging as a property made up of smaller elements”, nobody would complain. Emergence is only a bad explanation if it’s the only explanation given.
Emergence isn’t helpful by itself, but it is helpful in context. For example, if you say that consciousness is emergent from neurons firing, it doesn’t describe how it does it, but it does exclude other positions—“Consciousness doesn’t exist”, “Consciousness is a basic feature of the world and doesn’t emerge from anything, it’s just there”, and “Consciousness emerges from something other than neurons”.
Completely agreed. I think the word emergence is only bad because it’s used badly.
“A emerges from B” could reformulated as “There is a causal relationship between B and A” and as such it’s also obvious that the description of the causal relationship is missing.
I think the misuse is also about (But notice the difference) people struggling with attempts of understanding a hierarchy of information in the sense that you have two overlapping models… One, say M1, reduced—in the sense of reductionism—to smaller components and the other, say M2, which contains a more general abstract system. So the struggle which I’m referring to is the inability to effectively grasp the relationship between the two models M1 and M2, and then insteading of admitting you either can’t explain it or you don’t understand it, you just say “M2 is emergent from M1. ” Which can be correct, in the sense that “if M1 is true then it follows that M2 is true”—“Though I can’t quite explain why”
I think Yudkowsky’s pointing out the futility of emergence as a substite for magic is spot on in many cases.
The primary categorisation is “Threat / Not a threat”, and the main categorisation bias is “Better safe than sorry”. You’ll find that many of your specific categorisation biases are particular examples of that. Examples are : nervousness about your Great Thing being a cult, Asch experiment situations where you have to join the group or stick out from it. Diagram 1b has ‘Threat’ written all over it.....
I like this post. By the way, another argument that people always get into over the definition of a word is sports. Is nascar a sport? Is figure skating?
Also, in learning theory, how to define a reflex is of big debate. Is jealousy a reflex? Can you think of any reason to care? Seriously, I’m wondering.
Two questions that occur following reading this:
1) Using the Blegg/Rube example would it be reasonable to suggest that the reaction to a purple egg would be different had it occured 20 years of working on the machine with no anomalies, than if it was the first off of the conveyor belt … or the fith etc? What would be a threshold between casual acceptance and dumbfounded confusion?
2) The concept of neural pathways strengthening with usage and heightening connections through multiple observations leads to the question: At birth are our neural pathways all of equal “strength” and if not have we established yet what pre-existing configurations we are born with? (Is there an ultimate human “priori” with which we all start off or are there genetic differences, and if so are there any general constants?) Apart from an unlucky few am I right in saying that at birth there is a ready-made connection between sharp teeth/claws/aggresive noises and fear regardless of the occurence of previous observations or not?
I’ve been thinking lots about thingspace cluster stuff the past few days, and I remembered a thought I had a while back:
In actual reality, network 2 is not just easier to deal with, more efficient, etc, but would actually be more likely to reflect the actual underlying reality.
I mean, consider the pattern of correlations, the thingspace clusters represented in network 1. Generally such correlations don’t just pop up out of nowhere, right? Correlation is not the same thing as causation, but it does at least suggest that some sort of causation link is present (most likely common cause in a case like this, right?)
In this sort of case, I’d think “There’s probably some sort of actual physical process that produces bleggs, and some other process that produces rubes. That is, some process that produces things that have a high probability of being blue, egg shaped, etc etc etc… and similar for red cube shaped etc etc… Possibly distinct geological processes?”
So in that sense, the naive bayes network, with the implicit “but is it ACTUALLY a blegg?” style question would seem to reflect something legitimate, not just a name for the cluster. Specifically, such a question would translate to something like “which of, say, two distinct physical processes produced this?”
“it requires O(N²) connections” ← better use Ω(N²), i.e. big Omega instead of big O
This sequence reminds me of Deleuze and Guatarri so much that it’s totally crazy.
The metaphors and explanations are like cousins of each other.
Is there somewhere where I could learn how to interpret these models of neural networks? I think this article may have been written when it was safer to assume that readers knew these things.
“And lo, Network 1 exhibits this behavior even though there’s no explicit node that says whether the object is a blegg or not. The judgment is implicit in the whole network!! Bleggness is an attractor!! which arises as the result of emergent behavior!! from the distributed!! learning rule.”
The judgement is implicit on the network, which has a certain number of nodes, denoting certain characteristics.
This is EXACTLY the same principle as looking things up in a dictionary. You look up the definition (the characteristics that are taken into account for forming that group), and then once you have the defining criteria, it is an emergent property.
Bleggness is not an inherent quality of the object itself. Bleggness is an inherent quality of the characteristics that were pre-defined into the network.
Just like the network on the right: The characteristics of a human are predefined, entered into the network, and then the network calculates whether you are a human or not, in accordance with the given definition.
Revisiting this with the advantage of more neuroscience knowledge, it’s likely this isn’t how the brain does things. It’s more likely (going mostly off secondary literature e.g. Jeff Hawkins) that the cortex is more like a sparsely-connected version of network 1. In that picture, our brains treat “blegg/rube” (or rather, linguistic associations that function like ‘thinking about the word blegg’) as just another part of the cortex that can activate other parts, and be activated in turn.
Back in 2008, it was a common intuition that for neural networks (artificial or natural) to work well, the neurons had to assemble to form hierarchical logical circuits. Sort of the network 2 side of the dichotomy. “It’s more efficient!” they said. But a lot of those intuitions have had to be unlearned. I place a major sea change in 2015, with the ResNet paper. ResNets (networks that default to only lightly massaging the data at each layer) make perfect sense if you think about flow and gradients in activation-space, but no sense if you think the NN should be implementing human-intuition-scale logical circuits.
The lesson of this post is of course still right, and still valuable, but the background assumptions about brains and other neural networks are dated.
I think I’d vote for: “Network 2 for this particular example with those particular labels, but with the subtext that the central node is NOT a fundamentally different kind of thing from the other five nodes; and also, if you zoom way out to include everything in the whole giant world-model, you also find lots of things that look more like Network 1. As an example of the latter: in the world of cars, their colors, dents, and makes have nonzero probabilistic relations that people can get a sense for (“huh, a beat-up hot-pink Mercedes, don’t normally see that...”) but it doesn’t fit into any categorization scheme.”
Hm, now I’m not sure if I’ve gotten things wrong :)
So a few things I think might clarify what I’m thinking, and I guess loosely argue for it:
There’s various specialized areas of the brain, where killing off some neurons will cause loss of capabilities (e.g. the fusiform face area for recognizing faces). But my impression was there isn’t a region where “the blegg neurons” (or the tiger neurons, or the chocolate chip cookie neurons) are, such that if they get killed you (selectively) lose the ability to associate the features of a blegg with other features of a blegg.
Top-down or lateral connections are more common than many used to think. Network 2 can still have plenty of top-down feedback, it just has to originate from a localized Blegg HQ[1]. Lateral connections are a harder problem for network 2 - I found numenta’s youtube channel a few weeks ago and half-understood a talk about lateral connections, but somewhere along the line I got sold on the idea that lateral connections, while sparse, are dense enough to allow information to percolate every-which-way.
Although, given sparsity, a specific patch at a specific time might have strictly hierarchical information flow with some high (?) probability.
I suspect you’re thinking about object recognition in the prefrontal cortex (maybe even activation of a specific column). Which… is a good point. I guess my two questions are something like: How much distributed processing bypasses the prefrontal cortex? E.g. suppose I cut off someone’s frontal lobe[2], and then put an egg in their hand—they’re more likely to say “egg” or do egg-related things, surely—how does that fit into a coarse-grained graph like in this post? And second, how distributed is object recognition in the PFC? if we zoom in on object-recognition, does the information actually converge hierarchically to a single point, or does it get used in a lot of ways in parallel that are then sent back out?
I guess in that latter case, drawing network 2 can still be appropriate if from “far away in the brain” it’s hard to see internal structure of object recognition.
Although that assumes the other nodes are far away—e.g. identifying the “furred” node with a representation in the somatosensory cortex, rather than as a more abstract concept of furriness.
Unless Blegg HQ isn’t localized, in which case one would be interpreting the diagram more figuratively—maybe even as a transition diagram between what thoughts predominate?
Okay, I just googled this and got the absolutely flooring quote “Removal of approximately the anterior half of the right frontal lobe in a third case was not associated with any noticeable alteration, neurological or psychological.”
I think we’re mostly talking past each other, or emphasizing different things, or something. Oh actually, I think you’re saying “the edges of Network 1 exist”, and I’m saying “the edges & central node of Network 2 can exist”? If so, that’s not a disagreement—both can and do exist. :)
Maybe we should switch away from bleggs/rubes to a real example of coke cans / pepsi cans. There is a central node—I can have a (gestalt) belief that this is a coke can and that is a pepsi can. And the central node is in fact important in practice. For example, if you see some sliver of the label of an unknown can, and then you’re trying to guess what it looks like in another distant part of the can (where the image is obstructed by my hand), then I claim the main pathway used by that query is probably (part of image) → “this is a coke can” (with such-and-such angle, lighting, etc.) → (guess about a distant part of image). I think that’s spiritually closer to a Network 2 type inference.
Granted, there are other cases where we can make inferences without needing to resolve that central node. The Network 1 edges exist too! Maybe that’s all you’re saying, in which case I agree. There are also situations where there is no central node, like my example of car dents / colors / makes.
Separately, I think your neuroanatomy is off—visual object recognition is conventionally associated with the occipital and temporal lobes (cf. “ventral stream”), and has IMO almost nothing to do with the prefrontal cortex. As for a “region where “the blegg neurons”…are, such that if they get killed you (selectively) lose the ability to associate the features of a blegg with other features of a blegg”: if you’re just talking about visual features, then I think the term is “agnosia”, and if it’s more general types of “features”, I think the term is “semantic dementia”. They’re both associated mainly with temporal lobe damage, if I recall correctly, although not the same parts of the temporal lobe.
Well, object recognition is happening all over :P My neuroanatomy is certainly off, but I was more thinking about integrating multiple senses (parietal lobe getting added to the bingo card) with abstract/linguistic knowledge.
Yeah, filling in one part of the coke can image based on distant parts definitely seems like something we should abstract as Network 2. I think part of why this is such a good example is because the leaf nodes are concrete pieces of sensory information that we wouldn’t expect to be able to interact without lots of processing.
If we imagine the leaf nodes as more processed/abstract features that are already “closer together,” I think the Network 1 case gets stronger.
Gonna go read about semantic dementia.