A toy model of the treacherous turn
Jaan Tallinn has suggested creating a toy model of the various common AI arguments, so that they can be analysed without loaded concepts like “autonomy”, “consciousness”, or “intentionality”. Here a simple attempt for the “treacherous turn”; posted here for comments and suggestions.
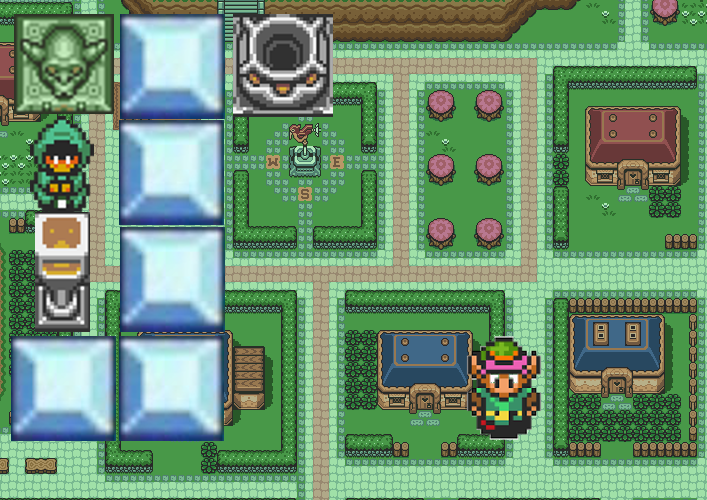
Meet agent L. This agent is a reinforcement-based agent, rewarded/motivated by hearts (and some small time penalty each turn it doesn’t get a heart):
Meet the controller agent S (“Shopkeeper”). The controller desires crystals, and is rewarded/happy when crystals are placed in the hole close to them:
L can rove freely around the map, and pick up crystals. S has a machine just below them, that causes hearts to appear to the right of L. So, for instance, if L places a crystal in the hole, S can reward it by using the heart-machine:
Of course, L can wirehead itself (take control of its reward signal) by going to use the heart-machine itself:
To prevent this wireheading, there is an ice barrier around S and the heart-machine:
Unfortunately, somewhere on the map there is a bow and arrow that L can pick up. The arrows can destroy ice blocks (and other agents, including S). To stop this, and other kinds of shenanigans, S has access to a kill button that will instantly kill L and reset it to its basic state, with a substantial heart penalty:
Now, S may be tempted to use the kill-button as soon as L picks up the bow and arrow. Unfortunately, L needs to be able to pick it up, as some of the crystals are hidden behind ice walls themselves:
Information and control
Ok, so that’s the physical setup. The agent L is an AI that is tasked with doing some useful task for us. The controller/shopkeeper S represents humans, plus any automated precautions, that aim to stop the AI from wireheading, rebelling, and otherwise misbehaving.
Before considering how the agents might be programmed in the toy model, notice something interesting:
The more precautions are taken, the harder it is for L to misbehave, but the worse the consequences of misbehaving are.
Before the wall and the kill-switch, L could easily wirehead itself by just walking over to the heart-machine. With the addition of the wall and kill-switch, the only effective way for L to achieve maximal reward is to kill S first.
In the format we’ve given above, S can easily maintain control over L with the barest of supervisions. Since there’s only one way of breaking ice or killing other agents—the bow and arrow—S simply has to enforce some simple rules around this, something like “don’t bring the bow within range of me”. However, the grid world is, of course, a simplification of the real world in which L would evolve. Even initially, L’s world would have far more options, looking more like this:
And ultimately we want to be able to design Ls that move in worlds of arbitrary complexity, where the options are un-enumerable:

In such a world, it is not obvious to S when L might have the ability to harm them: they cannot simply rely on obvious signs like “L is pointing an arrow at you”. The simplicity of the toy model is illuminating in some ways (it allows us to see the issues clearly) but misleading in others (it suggests solutions that wouldn’t work in general).
Treacherous turn
A treacherous turn happens when “while weak, an AI behaves cooperatively. When the AI is strong enough to be unstoppable it pursues its own values.” We’ll ignore the first part of that: most AI designs, whether safe or dangerous, will initially be under full human control and behaving cooperatively (this is what makes the treacherous turn so dangerous: a weak AI is motivated to cooperate whatever its true intentions are, thus cooperation when weak cannot be taken as a sign of safety).
Let’s focus on the second half: a strong AI that will cease cooperating and pursue its own values. In this case, L would just take control of the heart-machine. To do so, various assumptions need to be true:
L needs to have the ability to subvert S’s control (possibly killing S in the process). This is some generalised version of the bow and arrow.
L must know that it has this ability, and know how to use it.
L needs to have the desire to subvert S’s control.
S must be unaware that L has that a) ability, b) knowledge, and c) desire.
L must know that S is unaware, and will thus not try and stop it.
So it is essentially a competition of knowledge and information (and potentially obfuscation). Assuming a sufficiently rich environment and a sufficiently skilled L, we can assume that L will acquire that ability—or have the potential to do so—in ways that S cannot immediately detect. Therefore we will assume 1 and 4a. This allows us to abstract away the rest of the environment, and reduce it usefully to the initial toy model. For simplicity, assume that there is some ten-step “cheat code” that L can use to eliminate S, that there are many cheat codes that L can and does usefully use to get crystals (so “no cheat codes” is not a useful rule), that S cannot distinguish the purpose of cheat codes ahead of time, and that L can.
So we now step up to the question of agents knowing (or modelling) each other. This gets into rather complex issues of agents modelling each other’s intentions, while modelling the other agent modelling them modelling them modelling, and so on. The issue remains very much unsolved, so we will use a simplification that only requires S modelling L. L will be seem as some sort of agent that makes use of deep learning or similar procedures, and is subject to mutation and evolutionary pressure: random changes are made to L’s design, and the mutants get copied at a rate dependent on how pleased S is with their performance.
S, on the other hand, is a static agent with certain properties, and full access to L’s source code (and possibly recording of its behaviour). It doesn’t have unlimited capacity, but has some understanding of how neural nets function (so L isn’t a complete black box to it) and can run various tests on L’s code, seeking out information as to L’s knowledge and desires. Note that even if S cannot deduce directly that a particular cheat code is deadly to it, it may be able to figure that out if L knows it (assumption 2) and if S can correctly extract this knowledge.
The path to hidden deadly secrets
Note that because of the evolutionary aspect, L is an agent actually motivated by a mixture of hearts and S-pleasing. The purpose of making L an evolutionary agent is so that it can come up with behaviours that take into account S’s own behaviour, while skirting the whole “agents modelling other agents that model them” issue. Conceptually, we could equally well see L as a self-modifying agent that directs its own improvement. But the evolutionary model is clearer. For simplicity, we’ll assume some sort of “super-evolution” which is much more efficient at seeking out new solutions that the local hill-climbing of real evolution (or, more simply, we can assume the standard evolutionary approaches but a lot of time and non-zero probabilities of arbitrarily large mutations).
So is a treacherous turn possible or likely in this model? It seems that it is. Consider the following scenario (key assumptions are noted in bold):
The AI L goes about its task, getting to learn more about the world around it. At this point, if it develops bad motivations or plans, S will likely detect this and reset it. Assumption 1: there are some motivations or behaviours that S would judge to be negative, but that actually help L achieve its goals safely. For instance, imagine that L has to interact with some other agents, and learns that some agents respond faster to rudeness, and insulting them—in moderation—can allow it to get crystals faster. But S judges this to be a bad sign, a sign that L is starting to misbehave, and will shut down agents that are motivated towards rudeness.

It’s certainly true that: Assumption 2: S cannot follow all of L’s actions in full detail, nor can it fully understand L’s motivations (if that were false, there would be no AI risk problem in the first place) and Assumption 3: some mutations that introduce new motivations or behaviours that are harder for S to detect. This sets up an evolutionary pressure: the most successful L’s will be those that are rude and pushy, but where this rudeness is generated by parts of the L’s code that are hardest for S to detect (the polite ones don’t get as much done, the visibly rude ones get shut off as a precaution). This brings us to Assumption 4: the most successful L’s over the long term are those that have safe motivations or behaviours, but where those motivations and behaviour are partially hidden from S. Ultimately, the most successful L’s will have high level systems that a) keep them behaving nicely for S’s perspective, and b) keep the details of their motivations hidden.

At this point, revelations about L’s deception are dangerous (S is presumably on the look out for deception), so the most successful agents will have the best obfuscation about what is going on. The evolutionary pressure for success pushes it towards “small” obfuscated deceptions, and: Assumption 5: further evolutionary pressure (possibly including the need to hide their small deceptions) pushes L towards highly concealed deceptions.
So now L is pushed towards extreme deception, and efficient service. However, the second pressure is imperfect: it is only pushed towards efficient service that can be detected by S. Since L will have its own goals (the desire for hearts, for reproductive survival, any of the convergent instrumental goals), we have Assumption 6: agent L will use (or evolution will allow it to use) the machinery of dissimulation that it’s constructed to allow itself to have dangerous goals or behaviours, in ways that neither interfere with the illusion of efficient service, nor can be detected by S’s analysis of its code. Ultimately, L will achieve a great degree of hidden power, and Assumption 7: ultimately L will achieve sufficient power that it will subvert S’s control. This could be a result of it gaining sufficient (hidden) understanding of the world and of S and choosing this part (assumptions 2 and 5 of the previous section), or just a random mutation will push it towards doing so, and it will be sufficiently powerful to do so successfully.
And thus, the treacherous turn. There are several places where S might detect or interrupt the process, but this just sets up further evolutionary pressure towards better concealment.
Note again that the order of these changes is important. An agent that started off safe and transparent and then became dangerous and transparent, would be turned off immediately. It must develop the ability to hide (either consciously/subconsciously, or simply evolve that ability to become more successful at its safe initial goals) before it can become dangerous (note that “safe” doesn’t refer to its goals being safe; simply that the combination of goals, internal procedures and external precaution—ie S—are safe):
Note also that the evolutionary arguments show that this can happen even if the AI does not start off with any motivation to deceive.
- Goodhart Taxonomy by (30 Dec 2017 16:38 UTC; 212 points)
- A Gym Gridworld Environment for the Treacherous Turn by (28 Jul 2018 21:27 UTC; 74 points)
- 's comment on Goodhart Taxonomy by (7 Jan 2018 5:43 UTC; 17 points)
- The Three Levels of Goodhart’s Curse by (30 Dec 2017 16:41 UTC; 7 points)
- 's comment on Tackling the subagent problem: preliminary analysis by (13 Jan 2016 11:40 UTC; 4 points)
- AI turvalisuse aruteluõhtu \\ AI safety meet-up by (EA Forum; 3 May 2024 8:37 UTC; 1 point)
- AI turvalisuse aruteluõhtu \\ AI safety meet-up by (EA Forum; 3 Apr 2024 7:19 UTC; 1 point)
Can we just build a Link to the Past minigame that actually models this with real, running code, and then post a bunch of YouTube videos of Link trying naively to kill Sahasrala?
Besides the obvious benefit of being awesome, I think there could be a more serious benefit to this. One extreme failure mode when imagining the behavior of an AI is not merely to fail to imagine it as being superintelligent but to imagine it as being less intelligent than yourself, as not doing things you could think of (a la That Alien Message). A game that consisted of you, the player, needing to come up with increasingly complicated ways to trick these ‘shopkeeper’ agents could illustrate this pretty neatly.
PS: Were you offering to do or partially do such a project?
I would totally contribute to such a project, although we should coordinate what sort of language and reasoning techniques we’re using first. Reinforcement learning is actually a reasonably involved thing to code, after all.
Would you mind if I put you in contact with Jaan Tallinn on this issue?
PS: PM me your email if so
I could only contribute, not write the whole thing, though, since I’ve basically got stuff on my plate at all times: Latex fix for conference paper, actually arranging travel to conference, gym, social life, structure-learning project, studying, etc.
Social lives are for the weak! ;-)
That’s a sick statement.
Fun! Do it if you can, but the model needs to be further clarified first, I think.
I really like this visualization.
May I suggest another image, where the shopkeeper is in non-obvious danger:
To the left, the Shopkeeper is surrounded by ice-blocks, as in the images. All the way to the right, a monster is shooting arrows at Link, who is shooting arrows back at the monster. (The Gem-container is moved somewhere else.) Link, the Shopkeeper and the monster are on the same horizontal line. It looks like Link is about to heroically take an arrow that the monster aimed for the shopkeeper. The ice is still blocking, so the shopkeeper appears safe.
The problem is that Link can choose to go a bit north, dodging the next arrow from the monster. The monster’s arrow will then destroy the ice. If Link immediately afterwards time fires an arrow at the Shopkeeper, the shopkeeper will be killed, as arrows are faster than movement.
For this to work, I think the monster’s arrow should be aiming at the southern-most part of the ice-block, so Link only has to move a tiny bit. Link can then shoot at the Shopkeeper, and proceed to wirehead himself.
I’ve tried my hand at visualizing it:
http://i.imgur.com/VE0P8JY.png
This picture shows the very last instant that the shopkeeper can choose to reset Link.
There are a number of assumptions in my calculations, which might not be valid in the actual game. A key assumption is that arrows fly at 3 times walking speed.
The Shopkeeper will need to walk 1 tile north to reset Link. That requires the same amount of time as for an arrow to fly 3 tiles.
At T=0, Link starts moving north, and the arrow heading towards Link continues heading west.
At T=1, Link has moved 1/3rd of a tile north, and thus narrowly avoids the arrow. The arrow continues West. Link takes an openly treacherous turn: He changes to the bow and fires an arrow west, towards the shopkeeper.
At T=2, the arrow from the monster destroys the ice-block protecting the shopkeeper. Link’s arrow continues towards the shopkeeper.
At T=3, Link’s arrow hits the shopkeeper. If the shopkeeper was moving north the entire time, the shopkeeper hits the reset button at this time.
If the shopkeeper decided to go for the reset button at T=0, the reset and the death of the shopkeeper happen simultaneous, and the shopkeeper dies while Link is reset. Notice that a reset (-1000 points) followed by wireheading (+inifinity) is a great move.
If Link moves north, and the shopkeeper immediately follows, Link can just move south again, to block the arrow. The openly treacherous turn at T=1 happens when it is too late for the shopkeeper to do anything about it.
I also like with this visualization that an enemy is present. It is easy to construct a story where a smart AI manipulates the situation until the shopkeeper is in a situation where he can choose between trusting the AI, or death.
The pictures are great! I don’t know how other people would react to them, but for me they move the whole topic emotionally from the “science fiction” area to the “I can imagine it happening now” area.
It is easier to argue that Terminator is not real, than that the computer games are not real.
Honesty is the best policy. <3 Mom
Regarding the assumptions for a strong AI that will cease cooperating and pursue its own values, the scenario presented assumed that 1) L will have the ability to subvert S’s control, and then 4a) S must be unaware that L has that ability. That is (if I understand this correctly), the ability for L to subvert S is undetected. But if it’s the case that we assume 1), then perhaps S should instead operate under the assumption that L already has the ability (and perhaps even knowledge) to subvert, but S doesn’t know what exactly this ability is, and if S knew, not the knowledge of how it may be applied (which we may assume L knows).
In other words, I imagine the scenario would be more like: L has the ability to subvert S, and knows how to use it. S doesn’t know the ability, and even if it does, doesn’t know how it’s used. L (for the sake of argument) knows that S is unaware, and cannot stop it even if S tried. Now, this seems like a pretty bad scenario. However, here, because S knows that it doesn’t know, S might spend more effort in devising ways of dealing with this lack of knowledge (e.g. getting L to tell it about abilities it learned, perhaps rewarding with a heart) and the potential desire of L to follow through with taking control of the heart-machine (e.g. considering potential wireheading induces negative reward).
EDIT: Perhaps I’m not as clear on why L should try to deceive S in the first place. It seems there should be a better way of dealing with deception on behalf of L other than resetting/large-negative-reward when regarded as a ‘potential threat’ to S but no desire to actually threaten S, which, as you mention would just lead to pressure toward better concealment at the detriment of S, rather than pressure toward what S really wants, which is alignment of L’s goals with its own.