A new paper by Finlayson et al. describes how to exploit the softmax bottleneck in large language models to infer the model dimension of closed-source LLMs served to the public via an API. I’ll briefly explain the method they use to achieve this and provide a toy model of the phenomenon, though the full paper has many practical details I will elide in the interest of simplicity. I recommend reading the whole paper if this post sounds interesting to you.
Background
First, some background: large language models have a model dimension that corresponds to the size of the vector that each token in the input is represented by. Knowing this dimension and the number of layers of a dense model allows one to make a fairly rough estimate of the number of parameters of the model, roughly because the parameters in each layer are grouped into a few square matrices whose dimensions are .[1]
Labs have become more reluctant to share information about their model architectures as part of a turn towards increasing secrecy in recent years. While it was once standard for researchers to report the exact architecture they used in a paper, now even rough descriptions such as how many parameters a model used and how much data it saw during training are often kept confidential. The model dimension gets the same treatment. However, there is some inevitable amount of information that leaks once a model is made available to the public for use, especially when users are given extra information such as token probabilities and the ability to bias the probability distribution to favor certain tokens during text completion.
The method of attack
The key architectural detail exploited by Finlayson et al. is the softmax bottleneck. To understand what this is about, it’s important to first understand a simple point about dimensionality.
Because the internal representation of a language model has dimensions per token, the outputs of the model cannot have more than dimensions in some sense. Even if the model upscales its outputs to a higher dimension , there will still only be “essentially” directions of variation in the output. There are ways to make these claims more precise but I avoid this to keep this explanation simple: the intuition is just that the model cannot “create” information that’s not already there in the input.
Another fact about language models is that their vocabulary size is often much larger than their model dimension. For instance, Llama 2 7B has a vocabulary size of but a model dimension of only . Because an autoregressive language model is trained on the task of next-token prediction, its final output is a probability distribution over all of the possible tokens, which is dimensional (we lose one dimension because of the constraint that a probability distribution must sum to 1). However, we know that in some sense the “true” dimension of the output of a language model cannot exceed .
As a result, when , it’s possible to count the number of “true” directions of variation in the dimensional next token probability distribution given by a language model to determine the unknown value of . This is achieved by inverting the softmax transformation that’s placed at the end of language models to ensure their output is a legitimate probability distribution and looking at how many directions the resulting dimensional vector varies in.[2]
Results
Doing the analysis described above leads to the following results:
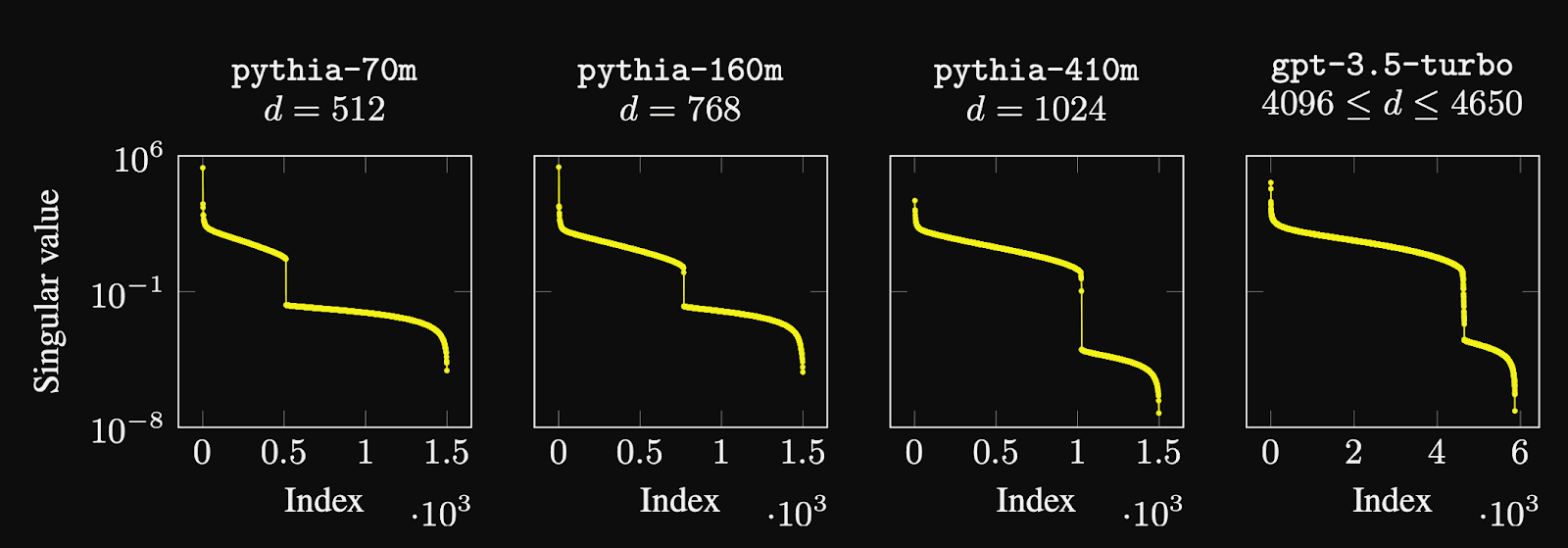
Informally, what the authors are doing here is to order all the directions of variation in the probability vector produced by the model in descending order of how much they matter, and look at when we get a steep drop-off in the “importance” of these directions. Because we expect the output to be “essentially” dimensional, we expect the point at which this drop-off occurs on the horizontal axis to be roughly equal to the model dimension.
The Pythia models are open source and their model dimension is already known, so the three Pythia models are included to validate the results of the paper. Indeed, the point at which this drop-off occurs for the Pythia models matches the known values of the model dimension. Having thus confirmed that their strategy is sound, the authors also use the same approach on GPT-3.5 Turbo and find that the model dimension seems to be .
The authors speculate that this might be overstated due to various sources of error which would tend to inflate the model dimension measured by this method, and instead guess that the true value of the model dimension might be . However, there’s a case to be made for that I think the authors miss: , which makes it an ideal model dimension to use if the model is being served for inference on A100 GPUs. This is because each NVIDIA GPU has a specific number of streaming multiprocessors that determine how many pieces the output matrix will be tiled into when doing a matrix multiplication, and for the A100 this is equal to 108, which is divisible by 9. This makes 4608 an ideal choice in this case, and I would give around even odds that this is the true model dimension of GPT-3.5 Turbo.
If GPT-3.5 Turbo were a dense model, this model dimension would be roughly consistent with a model having ~ 7 billion parameters. However, as the authors of the paper note, it’s quite plausible that GPT-3.5 is a mixture-of-experts model. The methodology used in the paper doesn’t tell us the number of experts used, so it’s likely that GPT-3.5 Turbo has three or four times this number of parameters in total with only a fraction of them being activated for each input token.
I’ve also written a toy model that simulates the essentials of this approach: you can find it in this Colab notebook. The paper itself has many more bells and whistles to back out the full probability distribution over the entire vocabulary from an API by using the ability to bias token generation in favor of certain tokens over others, but I neglect those technicalities here to emphasize what I see as the central contribution of the paper.
The plot below shows the results I get using my toy model with . Overall, the results look quite similar to the ones reported in the paper for actual language models.
What will labs do about this?
I think this paper shows just how easy it is to leak information about the architecture of your model when you’re deploying it at scale via an API. I would predict the reaction by labs will be to take away some of the features that make this specific attack possible, but there is a tradeoff here because making the API leak less information about the model architecture also makes it less useful for many end users. My guess is the industry will eventually arrive at some solutions that push forward the Pareto frontier of security versus user experience, but in the short term, we might just expect labs to sacrifice more usefulness on the margin to protect information that they regard as being important for their business.
- ↩︎
For instance, Llama 2 7B has and , for which this rough estimate gives parameters.
- ↩︎
In technical terms, this is achieved by looking at the singular value decomposition of the covariance matrix of this vector across many different inputs. After ordering the singular values in descending order, we expect a steep drop in the magnitude of the singular values around the th largest singular value, so we can check the position at which this drop occurs to back out the value of .
Would it be possible to determine the equivalent dimension of a layer of the human language cortex with this method? You can’t do API calls to a brain, but you can prompt people and estimate the probability of a response token by repeated sampling, maybe from different people.
The true rank is revealed because the output dimensionality is vocab_size, which is >> hidden_dim. It is unclear how to get something equivalent to that from the cortex. It is possible to record multiple neurons (population) and use dimensionality reduction (usually some sort of manifold learning) to learn the true dimensionality of the population. It is useful in some areas of the brain such as the hippocampal formation.
Could this be used to determine an estimate of the “number of parameters” of the brain?