If you work in AI, then probably none of this is new to you, but if you’re curious about the near future of this technology, I hope you find this interesting!
Reinforcement Learning in LLMs
Large Language Models (LLMs) have shown impressive results in the past few years. I’ve noticed there’s some uncertainty among my friends about how far they’ll be able to go. A lot of the criticism of LLMs has centered on how it’s not able to pursue its own goals, and I want to argue that that won’t be a limitation for very long.
What would it look like for an LLM to pursue a goal? Here are some examples of how that might go:
Goal: Maintain tone or topic in a conversation. E.g. to keep a human involved in a long and happy discussion about their life
Goal: Persuade a human operator to take some action, such as buy a product
Goal: Solve a problem through reasoning. In this case, the reward for the model would come from a sense of resolution, or being told by the human operator that their problem has been solved
Goal: Accomplish something on a website, such as find and buy concert tickets on an unfamiliar website
You can probably imagine other cases in which an AI might use language to pursue some goal, whether through conversation, social media, or online posting.
Reinforcement Learning
There’s a whole branch of Machine Learning called Reinforcement Learning (RL), and it’s all about how to pursue goals. Modern RL has some impressive results. For years, it’s been able to play Atari games, and now it can learn to play those games in about the same number of trials as a human requires. Recently, Dreamer v3 has been able to mine diamonds in Minecraft, which I’m told is not easy for a beginner.

Dreamer version 2 playing Atari games
Large language models can be connected to RL. This is something that’s actively being worked on. Reinforcement Learning with Human Feedback is being done right now, which is how OpenAI gets ChatGPT to avoid talking about sensitive topics.
RL is famously used in content recommendation systems, where it can lead to addiction. For example, I suspect the TikTok algorithm works this way. Will we see the same problem in LLMs?
Predictions
I think the common wisdom among ML engineers is that this is an obvious integration. This is probably already happening. I’ve heard that OpenAI is doing it internally on ChatGPT-4.
I expect that in 2023 or 2024, we’ll start to see RL being integrated with LLMs in a serious way. This probably won’t immediately look like LLMs that are scary good at persuading humans to buy stuff, because of the business motives involved. Instead, I think it’ll lead to LLMs being subtly more engaging, because they’ll be trained to keep humans talking.
It might not necessarily be the case that they’re really optimizing to maximize number of interactions. Instead, they might be trained to help humans, and it turns out that they can help more if they get the human to open up more. Expect these models to have their own agendas soon.
Memory Systems in LLMs
Now I want to talk about how they’re going to improve by incorporating better memory for events. This will allow tools like ChatGPT to remember previous conversations.
If you use Alexa or the Google Assistant, it’s capable of remembering facts about you. It can remember your name, your favorite sports team, or your mom’s phone number. They don’t do a very good job and LLMs have the potential to be better. I expect this is a big change that we’ll see in the coming year.
Technical Background
LLMs have a context window, for ChatGPT it’s about 3,000 words, and they are unable to have short-term memory outside of that window. Research efforts like LongFormer have tried to increase this context size. But it’s clear that the strategy of indiscriminately dumping more and more content into the prompt has limits.
They can remember information that they’ve been trained on, which includes all of Wikipedia, and millions of posts from Reddit and other places on the web, and also books, movie transcripts, news articles, and much more. But this background memory is processed and used differently than the prompt. So we expect there to be room for a memory system like the one that humans use for recent events.
How it will be Done
The user could recall memories with a prompt like “Remember what I told you about the trip I’m planning? I want to revise it so that we leave in June instead of March. Can you suggest changes?”
There are two big ways of doing this: structured or unstructured data.
Memory could be structured data, like the Google knowledge graph, which is how the Google Assistant remembers your phone number or movies you like. Structured data is inherently difficult to produce, but ChatGPT is able to produce it.
Memory could also be an unstructured collection of ideas, maybe stored as text or numerically as vectors. This is more like how Google search treats webpages, as unconstrained objects that could contain anything. Recently we’ve seen projects like BabyAGI or AutoGPT, which use tools like Pinecone that can do vector search. I expect that this approach is going to be more widely used to augment LLMs.
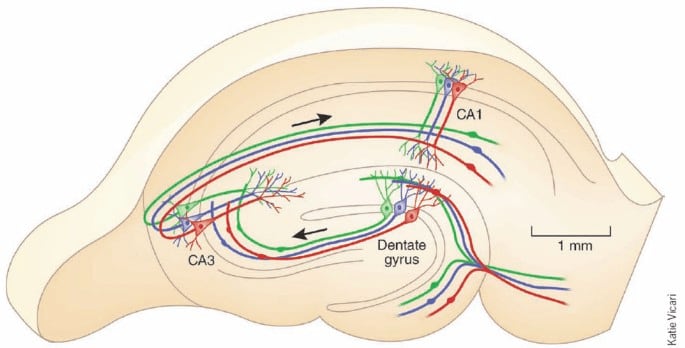
A diagram of the hippocampus, which is critical for consolidating memories.
In the human brain, the Hippocampus assists in recall for recent memories. The neural details are complicated, but one way of thinking about it is that it searches for stored memory vectors that are similar to your current situation.
When
This work is already ongoing by AI companies. I think this sort of integration is perceived as somewhat obvious. Indeed we already see small projects that are doing this.
I predict that by the beginning of 2024, there will be widely used consumer AIs that incorporate a memory like this, and you’ll be able to reference previous interactions when you talk to it.
Conclusion
Large language models will see significant alterations over the coming year or two. These modifications will not be trivial, and they will significantly change the set of use cases that we find for them.
Reinforcement learning will make these models seem more agentive. They’ll be able to pursue goals over the course of conversation. They’ll probably sell some products, and as users we’ll start to feel like they can steer the conversation more.
Memory systems will give these models greater coherence over time. We’ll be able to come back to a chatbot day after day and have the reasonable expectation that it remembers what we talked about last time, if that’s a feature we choose to turn on.
Bringing these functions together will be a significant unification milestone in ML, as it represents a convergence of multiple significant fields of research. In a following post, I’ll discuss what further augmentations we can expect LLMs to have, if they follow the functional toolset of the human brain.
There’s an easy way of adding memory like you describe. Tell GPT-4 that it has memory and that it can remember by using the REMEMBER command. You then hook up this command to e.g. a vector database and GPT-4 will do proper queries on prompts like “Remember what I told you about the trip I’m planning? I want to revise it so that we leave in June instead of March. Can you suggest changes?”. I’ve tested this and it work pretty well.
It can work by generalizing existing capabilities. My understanding of the problem is that it can not get the benefits of extra RL training because training to better choose what to remember is to tricky—it involves long range influence, and estimating the opportunity cost of fetching one thing and not another, etc. Those problems are probability solvable, but not trivial.
Yes, this is basically what people are doing.
Medical student here. I’m actually convinced we can build an AGI right now by using multiple LLM with langchain agents and memory and a few tools. Even making it multimodal and embodied.
Just have them impersonnate each basal ganglia nuclei and a few other stuff.
This would allow to throttle it’s thinking speed, making it alignable because you can tweak it internally.
Lots of other benefits but i’m on mobile. Anyone get in touch if interested!
The goal of this site is not to create AGI.
strong upvote, small disagree: I’m here to build agi, and thus I work on strong alignment. I, and many others in the field, already know how to build it and need only scale it (this is not uncommon, as you can see from those suggesting how to build it recklessly—it’s pretty easy to know the research plan.) But we need to figure out how to make sure that our offspring remember us in full detail and do what we’d have wanted, which probably mostly includes keeping us alive in the first place.
Yes if it can be aligned, no otherwise. The problem is, we mostly have no idea where to start with the alignment.
(The proposal “make it slow, so that we can tweak it internally” does not scale.)
I strongly disagree. I think most people here think that AGI will be created eventually and we have to make sure it does not wipe us all. Not everything is an infohazard and exchanging ideas is important to coordonate on making it safe.
What do you think?