Recently, Nathan Young and I wrote about arguments for AI risk and put them on the AI Impacts wiki. In the process, we ran a casual little survey of the American public regarding how they feel about the arguments, initially (if I recall) just because we were curious whether the arguments we found least compelling would also fail to compel a wide variety of people.
The results were very confusing, so we ended up thinking more about this than initially intended and running four iterations total. This is still a small and scrappy poll to satisfy our own understanding, and doesn’t involve careful analysis or error checking. But I’d like to share a few interesting things we found. Perhaps someone else wants to look at our data more carefully, or run more careful surveys about parts of it.
In total we surveyed around 570 people across 4 different polls, with 500 in the main one. The basic structure was:
p(doom): “If humanity develops very advanced AI technology, how likely do you think it is that this causes humanity to go extinct or be substantially disempowered?” Responses had to be given in a text box, a slider, or with buttons showing ranges
(Present them with one of eleven arguments, one a ‘control’)
“Do you understand this argument?”
“What did you think of this argument?”
“How compelling did you find this argument, on a scale of 1-5?”
p(doom) again
Do you have any further thoughts about this that you’d like to share?
Interesting things:
In the first survey, participants were much more likely to move their probabilities downward than upward, often while saying they found the argument fairly compelling. This is a big part of what initially confused us. We now think this is because each argument had counterarguments listed under it. Evidence in support of this: in the second and fourth rounds we cut the counterarguments and probabilities went overall upward. When included, three times as many participants moved their probabilities downward as upward (21 vs 7, with 12 unmoved).
In the big round (without counterarguments), arguments pushed people upward slightly more: 20% move upward and 15% move downward overall (and 65% say the same). On average, p(doom) increased by about 1.3% (for non-control arguments, treating button inputs as something like the geometric mean of their ranges).
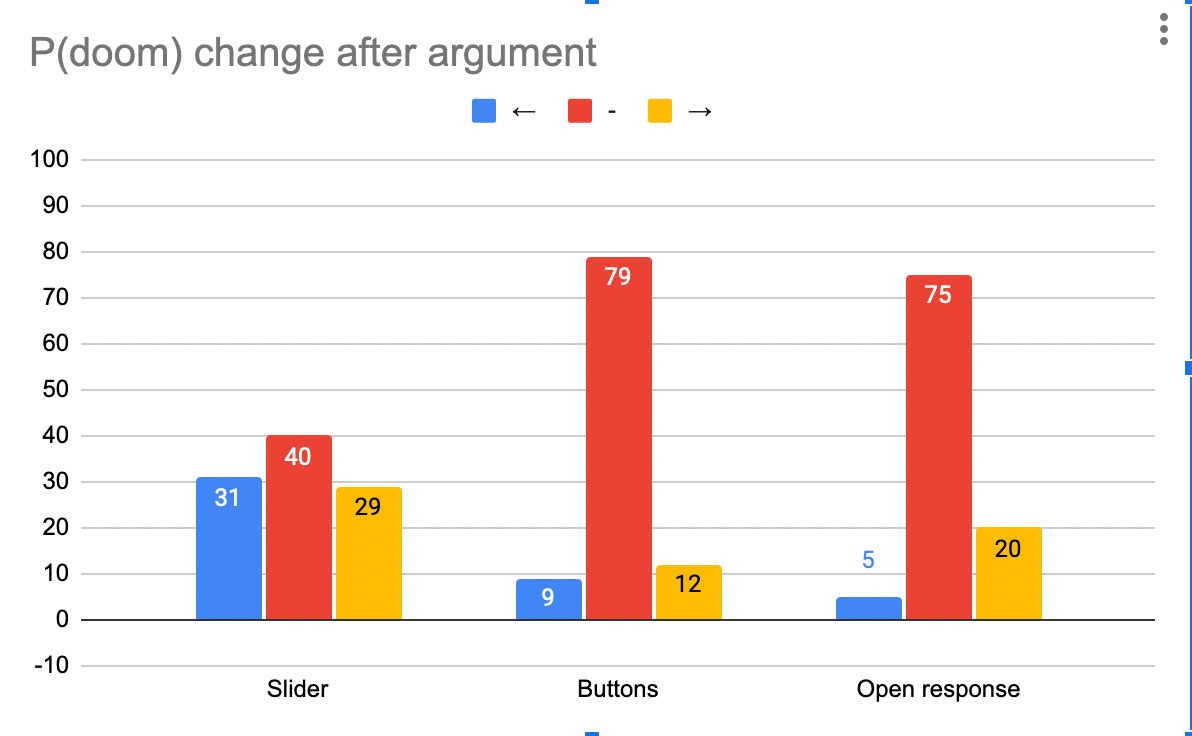
But the input type seemed to make a big difference to how people moved!
It makes sense to me that people move a lot more in both directions with a slider, because it’s hard to hit the same number again if you don’t remember it. It’s surprising to me that they moved with similar frequency with buttons and open response, because the buttons covered relatively chunky ranges (e.g. 5-25%) so need larger shifts to be caught.
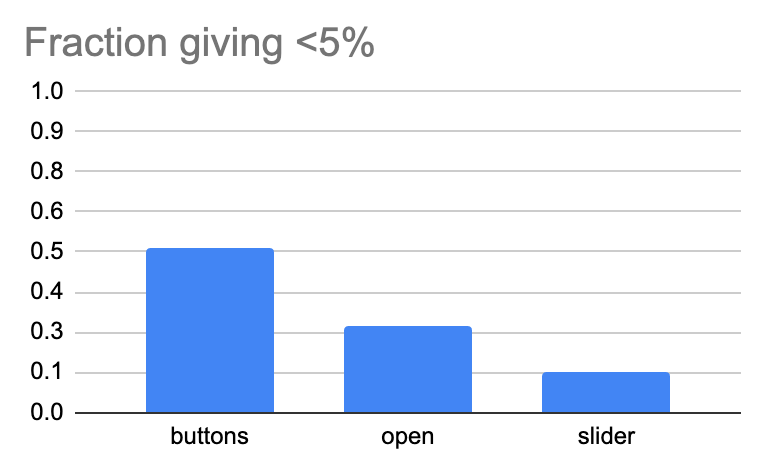
Input type also made a big difference to the probabilities people gave to doom before seeing any arguments. People seem to give substantially lower answers when presented with buttons (Nathan proposes this is because there was was a <1% and 1-5% button, so it made lower probabilities more salient/ “socially acceptable”, and I agree):
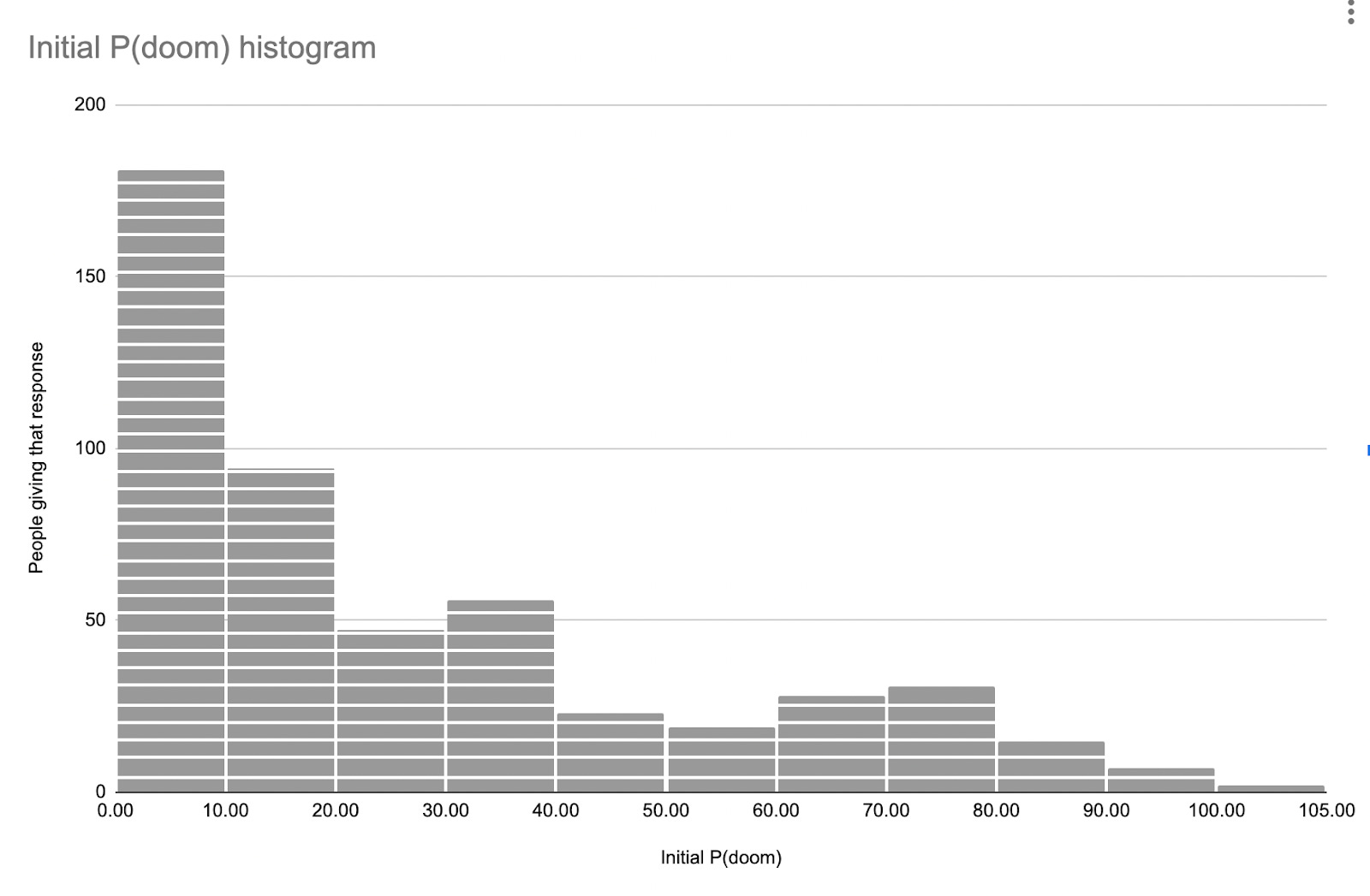
Overall, P(doom) numbers were fairly high: 24% average, 11% median.
We added a ‘control argument’. We presented this as “Here is an argument that advanced AI technology might threaten humanity:” like the others, but it just argued that AI might substantially contribute to music production:
This was the third worst argument in terms of prompting upward probability motion, but the third best in terms of being “compelling”. Overall it looked a lot like other arguments, so that’s a bit of a blow to the model where e.g. we can communicate somewhat adequately, ‘arguments’ are more compelling than random noise, and this can be recognized by the public.In general, combinations of claims about compellingness, changes in probabilities and write-in answers were frequently hard to make sense of, especially if you treat the probability changes as meaningful rather than as random noise. For instance, the participant who rated an argument 4⁄5 compellingness, yet reduced their P(doom) from 26% to 0%, and said “The above argument is completely based on probability of AI’s effects on humanity near future, some feels that it could be turn into negative way but most people feels that it is going to a good aspect for future technology.” My sense is that this was more true in the first round than the fourth, so perhaps the counterarguments are doing something there.
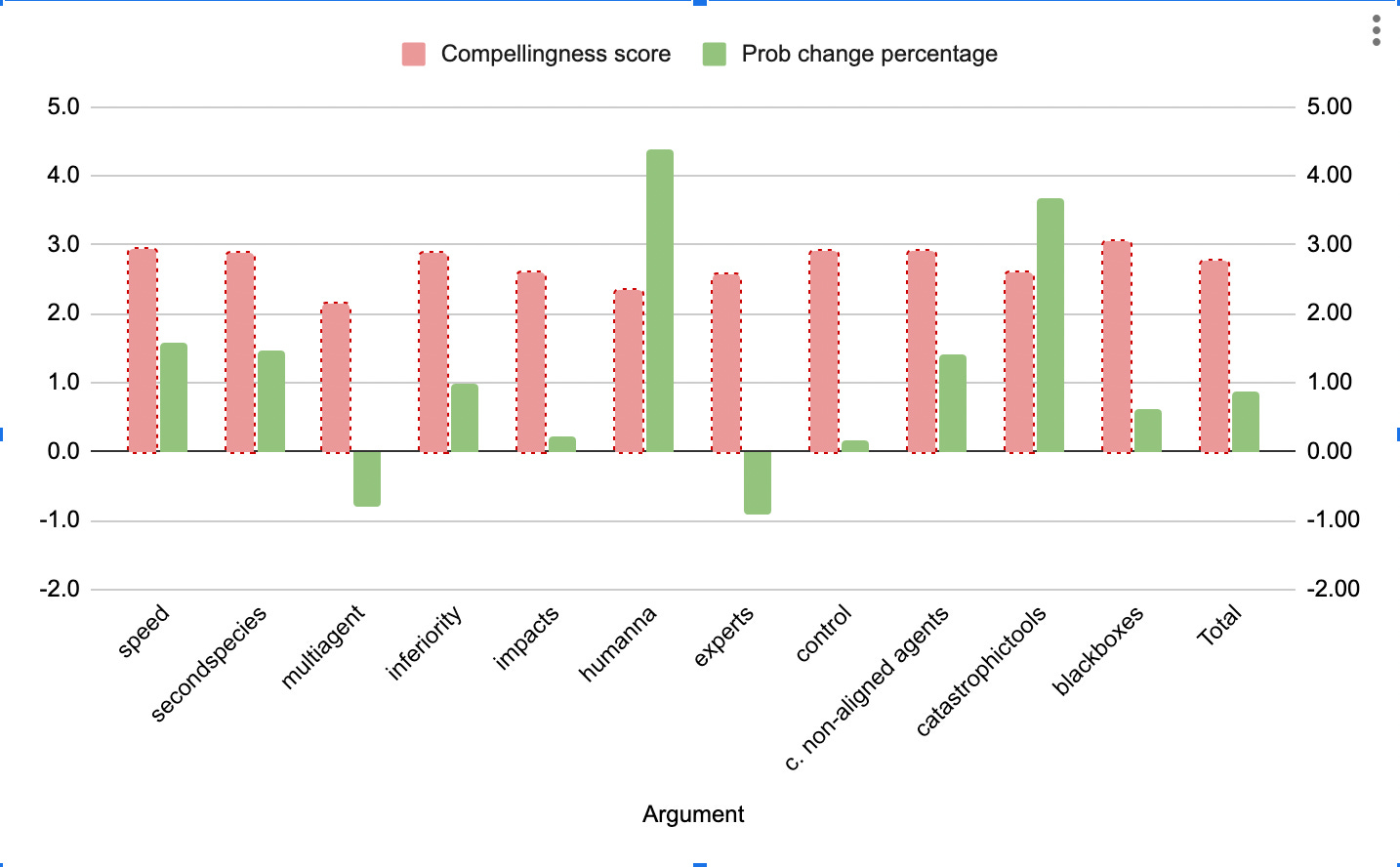
This is how the different arguments fared:
All arguments were on mean between 2 and 3 compelling, including the control argument
The arguments we considered worst did roughly worst, in terms of probability change (black boxes, large impacts, multiagent dynamics, control)
The argument from expert opinion was the very worst though, which is interesting to me because it seems like the one that people are constantly pointing at in public, in trying to justify concerns about x-risk.
The top arguments for increasing P(doom) were the ones about normal human processes getting out of hand (human non-alignment, catastrophic tools, speed) then the ones about bad new agents came below (second species, competent non-aligned agents, inferiority). Compellingness looks related but not closely so.
We both found the experience of quickly polling the public enlivening.

If you wish to look at the arguments in more detail, they are here. If you want to analyze the data yourself, or read everyone’s write-in responses, it’s here. If you see any errors, please let us know.
I was surprised by the “expert opinion” case causing people to lower their P(doom), then I saw the argument itself suggests to people that experts have a P(doom) of around 5%. If most people give a number > 5% (as in the open response and slider cases) then of course they’re going to update downwards on average!
I would be interested to see what a specific expert opinion (e.g. Geoffrey Hinton, Yoshua Bengio, Elon Musk, Yann LeCunn as a negative control) would have, given that those individuals have more extreme P(dooms)
My update on the choice of measurement is that “convincingness” is effectively meaningless.
I think the values of update probability are likely to be meaningful. The top two arguments are both very similar, as they play off of humans misusing AI (which I also find to be the most compelling argument to individuals), then there is a cluster relating to talking about how powerful AI is or could be and how it could compete with people.
Side comment from someone who knows a thing or two in psychology of argumentation:
1-I think that including back-and-forth in the argument (e.g. LLM debates or consulting) would have a significant effect. In general argumentation in-person vs on exposure showcases drastic différences.
2-In psychology of reasoning experiments, we sometimes observe that people are very confused about updates in “probability” (see −70% engineers, 30% lawyer, I pick someone at random. What’s the probability it’s one or the other -Fifty-fifty) I wouldn’t be surprised if the results were different if you said “On a 0 to 10 scale where 0 is… And 10 is… Where do you stand”.
3-The way an argument is worded (claim first, data second, example third vs example first, data second, claim third) also has an impact, at least according to argumentation theory. In particular I recall that there were no concrete examples given in the arguments (e.g. “Bad llama”, “Devin”, “Sydney”, etc) which can give the impression of an incomplete argument.
There was some work I read about here years ago (https://www.lesswrong.com/posts/Zvu6ZP47dMLHXMiG3/optimized-propaganda-with-bayesian-networks-comment-on) on causal graph models of beliefs. Perhaps you could try something like that.
I would find this difficult to answer, because I don’t know what you mean by “substantially disempowered”.
I’d find it especially hard to understand because you present it as a “peer risk” to extinction. I’d take that as a hint that whatever you meant by “substantially disempowered” was Really Bad(TM). Yet there are a lot of things that could reasonably be described as “substantially disempowered”, but don’t seem particularly bad to me… and definitely not bad on an extinction level. So I’d be lost as to how substantial it had to be, or in what way, or just in general as to what you were getting at it with it.
Did you just ask people “how compelling did you find this argument” because this is a pretty good argument that AI will contribute to music production. I would rate it highly on compelling, just not a compelling argument for X-risk.
I’m really curious about the variable of whether people believe that AI will ‘fizzle’, as Zvi puts it. If you think that current LLMs are quite close to the peak of what is achievable in the next 40 years, I expect that that modifies whether you think humanity is in danger from AI in the next 40 years.
Also I’m curious about phrasing things as “conditional on <AI strength level> in <timeframe>, with no substantial shifts in AI regulation or the AI leaders up until that point.”
Basically, I think a lot of unworried people would be a lot more worried if they agreed with me on short timelines. I’m interested in how people are going to react in the future, once they see further evidence of continued progress in AI.
The LessWrong Review runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2025. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?