AutoInterpretation Finds Sparse Coding Beats Alternatives
Produced as part of the SERI ML Alignment Theory Scholars Program—Summer 2023 Cohort
Huge thanks to Logan Riggs, Aidan Ewart, Lee Sharkey, Robert Huben for their work on the sparse coding project, Lee Sharkey and Chris Mathwin for comments on the draft, EleutherAI for compute and OpenAI for GPT-4 credits.
Summary
We use OpenAI’s automatic interpretation protocol to analyse features found by dictionary learning using sparse coding and compare the interpretability scores thereby found to a variety of baselines.
We find that for both the residual stream (layer 2) and MLP (layer 1) of Eleuther’s Pythia70M, sparse coding learns a set of features that is superior to all tested baselines, even when removing the bias and looking just at the learnt directions. In doing so we provide additional evidence to the hypothesis that NNs should be conceived as using distributed representations to represent linear features which are only weakly anchored to the neuron basis.
As before these results are still somewhat preliminary and we hope to expand on them and make them more robust over the coming month or two, but we hope people find them fruitful sources of ideas. If you want to discuss, feel free to message me or head over to our thread in the EleutherAI discord.
All code available at the github repo.
Methods
Sparse Coding
The feature dictionaries learned by sparse coding are learnt by simple linear autoencoders with a sparsity penalty on the activations. For more background on the sparse coding approach to feature-finding see the Conjecture interim report that we’re building from, or Robert Huben’s explainer.
Automatic Interpretation
As Logan Riggs’ recently found, many of the directions found through sparse coding seem highly interpretable, but we wanted a way to quantify this, and make sure that we were detecting a real difference in the level of interpretability.
To do this we used the methodology outlined in this OpenAI paper, details can be found in their code base. To quickly summarise, we are analysing features which are defined as scalar-valued functions of the activations of a neural network, limiting ourselves here to features defined on a single layer of a language model. The original paper simply defined features as the activation of individual neurons but we will in general be looking at linear combinations of neurons.
We give a feature an interpretability score by first generating a natural language explanation for the feature, which is expected to explain how strongly a feature will be active in a certain context, for example ‘the feature activates on legal terminology’. Then, we give this explanation to an LLM and ask it to predict the feature for hundreds of different contexts, so if the tokens are [‘the’ ‘lawyer’ ‘went’ ‘to’ ‘the’ ‘court’] the predicted activations might be [0, 10, 0, 0, 8]. The score is defined as the correlation between the true and predicted activations.
To generate the explanations we follow OpenAI and take a 64-token sentence-fragment from each of the first 50,000 lines of OpenWebText.[1] For each feature, we calculate the average activation and take the 20 fragments with the highest activation. Of these 20, we pass 5 to GPT-4, along with the rescaled per-token activations. From these 5 fragments, GPT-4 suggests an explanation for when the neuron fires.
GPT3.5 is then used to simulate the feature, given the explanation, across both another 5 highly activating fragments, and 5 randomly selected fragments (with non-zero variation). The correlation scores are calculated across all 10 fragments (‘top-and-random’), as well as for the top and random fragments separately.
Comparing Feature Dictionaries
We use dictionary learning with a sparsity penalty to define features as directions on the vector space of activations. We also create other feature dictionaries, such as the neuron basis; a dictionary of random activations; Principal Component Analysis (PCA) and Independent Component Analysis (ICA).[2]
With these feature dictionaries defined, we run the LLM on sentences from OpenWebText, extracting the activation vectors at each point and then converting these into feature activations, by multiplying by either a learnt matrix (sparse_coding), random matrix (“random”), identity matrix (“neuron_basis”) etc, and potentially applying bias + ReLU if part of the feature definition being used. We use these build a database of feature activations and their corresponding contexts.
We then run these features through the automatic interpretation procedure defined by OpenAI in their Language models can explain neurons in language models paper. We then run this (rather expensive) process for between 40 and 150 features. We choose the ‘first’ features for each dictionary, which has no significance for the sparse coding approach or the neuron basis, but means taking the top directions for PCA (and possibly also for ICA, not certain).
The graphs below show the mean auto-interpretation score, as well as 95% confidence intervals around these results, for the top-and-random fragments, the top-only ones and the random-only ones.
MLP Results
The first thing we can clearly in Figure 1 above is that the sparse coding features (’sparse_coding”) outperform both the neuron basis and random directions.[3]
As an example, feature 1 of the learned dictionary has a top-and-random score of 0.38 for the explanation ‘the dollar sign symbol, which represents amounts in financial data.‘. The activations of the top-activating sequences for this feature have sections like [0.0, 0.0, 5.5078125, 0.0, 0.0, 0.0, 3.732421875, 0.0, 0.0, 0.0, 4.8828125, 0.0, 0.0, 0.0] for the sequence of tokens [’ for’, ′ just’, ′ £’, ‘5’, ‘.’, ’99′, ′ €’, ‘6’, ‘.’, ‘99’, ′ $’, ‘9’, ‘.’, ‘99’]. It seems as if it would have scored better if it had broadened the explanation to include other currency symbols.
We also run PCA and ICA on the activations and interpret the directions found. We find that the directions found by both do not out-perform the neuron basis. With PCA we find that the first ~30 of the 2048 principal components tend to be highly interpretable, but that beyond this they do not noticeably out perform the neuron basis.
However, in comparing the neuron basis to our found features there’s a notable difference which is that our features have an additional bias + ReLU applied, and this learned bias is almost always negative. This allows the features to be active only for more highly activating examples of the direction and cuts out much of the noise. This is a theoretically-motivated part of the approach, but it’s important to check whether the neuron basis or random directions would do just as well if this de-noising were applied.
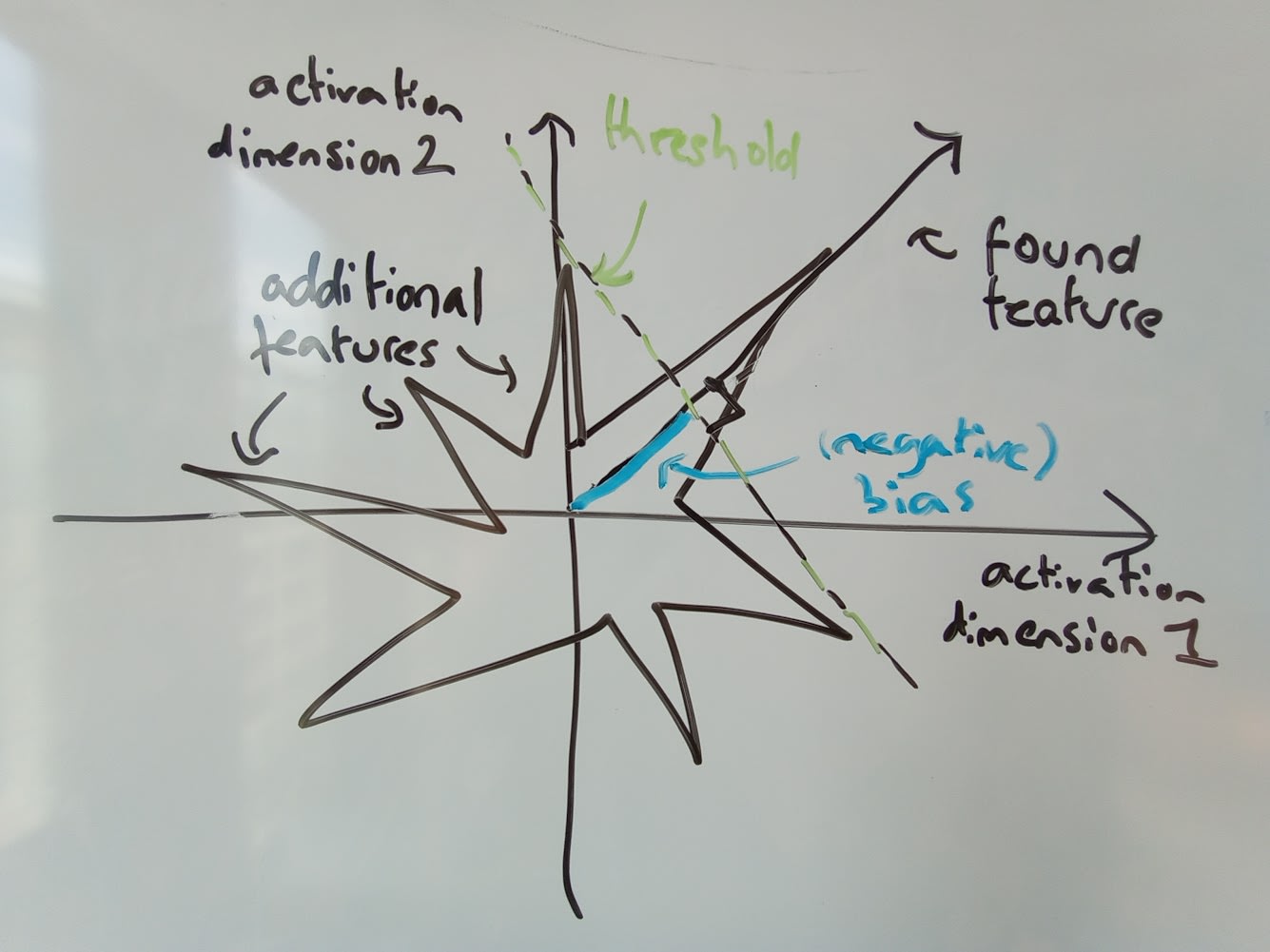
To test this, we use three additional baselines. ‘feature_no_bias’ removes the bias from the features, and it still seems to be a significant improvement over either random of neuron_basis directions. We also try adding a proportionally sized negative bias and ReLU to both random directions and find that this doesn’t cause any noticeable improvement in the automatic interpretation scores, at least for top-and-random scoring.
We can see that when the bias is added to the neuron basis and to random directions, the explanation scores do perhaps rise slightly, while if we remove the bias from the features, become essentially useless for predicting variation in random fragments. This to me suggests that adding the bias has two competing effects. It removes noise from the feature, giving a cleaner set of cases for where feature is on, making it more interpretable within sequences. However, because we only select random sequences where there is at least some activation, it makes the random fragments more thematically similar to top fragments, making it harder to distinguish the two, and thereby reducing the top-and-random score.
Residual Stream Results
If we apply the same methodology to a dictionary learnt with sparse coding (this time learnt with the encoder weights tied with the decoder, we’ll explore the difference more fully in future) on the residual stream at layer 2 rather than the MLP, we get the above results where the mean interpretability score for our learned features is no higher than for the ″neuron_basis″ in the residual stream, which is somewhat disappointing. If we select for features which were found almost identically by different learned dictionaries (‘top_mcs’ - high Max Cosine Similarity with the other dictionary), we do see an improvement but overall, it doesn’t look great. This is especially odd as the toy models of superposition paper, which was a major inspiration for this approach, is a much better fit for the residual stream than the MLP, and dictionary learning has already been seemingly successfully applied to the residual stream (Yun et al 2021).
But hang on, look at those interpretability scores for the neuron basis! They’re higher than for the MLP, and than random directions! We thought the residual stream (mostly) doesn’t even have a preferred basis? What’s going on?!
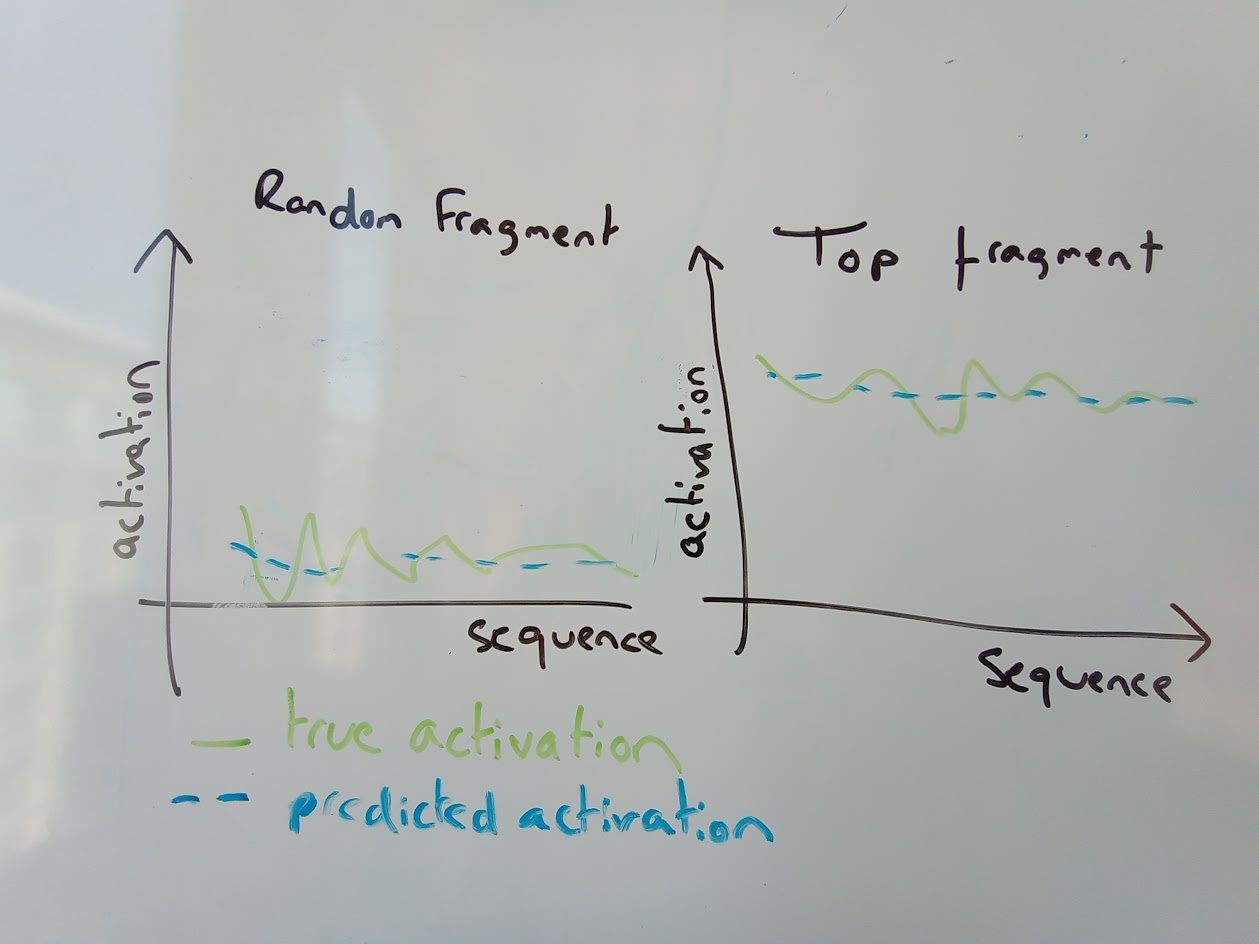
The answer is that the top-and-random scoring approach can be very misleading. If we separate out the top and random fragments into two separate scores, we get the following when only looking at the top-activating fragments:
and the following when looking at only the random fragments:
Now we see that the learnt features outperform all baselines in both the top and the random, but not in the top-and-random! But how? The answer is that the auto-interpretation score is a correlation score. What’s happening is that the top fragments are selected for high average activation score. The residual stream seems to be prone to having continually high activations in a certain direction across an entire fragment. The explanations found by GPT-4 are sufficient to distinguish these high-scoring fragments from random fragments, but not to explain any of the variability within the fragments. For example, there are a few very high scoring residual stream directions which tend to be highly activating in the midst of text which largely consists of numbers, which allows the simulated neuron, with explanations like ‘numeric values, sequences, and lists.’ to match the broad pattern of on vs off at the fragment level, but not to explain any of the variation therein.
These somewhat neuron-aligned (since the ‘neuron-basis’ beats random directions quite strongly) fragment-scale features are an interesting potential topic of study but if we look at the ability to understand the way that a transformer processes information within a sequence, in the residual stream, the learnt features are clearly more interpretable.
Note that we still see a significant benefit for the top MCS features. This could indicate that our training is suboptimal (and it probably is, these are the first dictionaries that we’ve tested in this way) but it could also just mean that the directions which dictionaries most strongly agree on tend to have simple meanings, and are very common, which leads to them being learned in a very precise way. This is suggested by the explanations for some of the top features, like “instances of the indefinite article ‘a’.”, or “the word “as” used in comparisons or examples.”.
Next Steps
We plan to expand in a number of ways, including larger dictionaries, tying our work back to toy and theoretical models, different variations on dictionary learning and improving the capacity and flexibility of the automatic interpretation system. We’re always interested to talk to, and work with new people, and we’d like to co-ordinate with others to move forward as quickly as possible so don’t hesitate to reach out :).
- ^
Note that it’s important to only take a single fragment from each context, because when selecting for highly activating fragments, you want them to be diverse, else you may see seemingly strong but spurious correlations, especially when you look at top-and-random scoring.
- ^
PCA and ICA are performed on about 1M and 65k activation vectors respectively.
- ^
This was a dictionary with 2048 entries for an MLP width of 2048 trained with a L1 penalty of 1e-3. This was the first and so far only MLP sparse coding dictionary tested in this way.
- Sparse Autoencoders Find Highly Interpretable Directions in Language Models by (21 Sep 2023 15:30 UTC; 158 points)
- Sparse Autoencoders: Future Work by (21 Sep 2023 15:30 UTC; 35 points)
- 's comment on Open problems in activation engineering by (28 Jul 2023 3:08 UTC; 5 points)
- 's comment on Neuronpedia by (27 Jul 2023 17:25 UTC; 4 points)
- 's comment on Integrity in AI Governance and Advocacy by (31 Dec 2023 3:55 UTC; 2 points)
I think the final layer’s output determines the complexity of the prediction that will be used to determine the vocab library that the model will generate its output from. I would vote on the random fragment chart (1st image) here.