Reasoning is not search—a chess example
In the past AI systems have reached super human performance by adding search to neural networks while the network alone could not reach the level of the best humans.
At least this seems to be the case for AlphaGo, AlphaZero/Leela, AlphaGeometry and probably more, while AlphaStar and OpenAI Five where adding search was not easily possible have failed to reach convincing super human status.
This has lead some people to expect that adding a form of search to large language models would finally endow them with the ability to reason through complicated problems and allow them to surpass humans.
The Q* system of OpenAI is rumored to somehow integrate search and following this rumor several papers were published that aim at integrating Monte Carlo Tree search in the sampling process of LLMs.
However, human-like reasoning is not search. At least not search as implemented in these systems. To illustrate this point I want to go through a chess combination I played online a couple of months ago and describe my reasoning move by move.
In the following position I am down material and have little time left and my king is relatively unsafe. Two of my pieces aim at the g2 pawn behind which the white king is hiding.
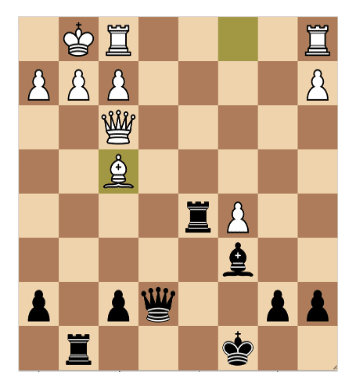
However, after Bg3 the g-line would be plugged and it would become very difficult to get at the white king.
Therefore I needed to strike the iron while it was hot by moving my d5-rook, freeing the bishop to attack the queen and g2-pawn behind it.
Most of the rook moves allow a defensive maneuver: Qh3 check and the Bg3. Three rook moves avoid this: Rd7, Rd3 and Rh5. Rd7 still allows Qh3 to then give the queen for rook and bishop, therefore I sacrificed my rook with Rh5, which was promptly taken with the queen.
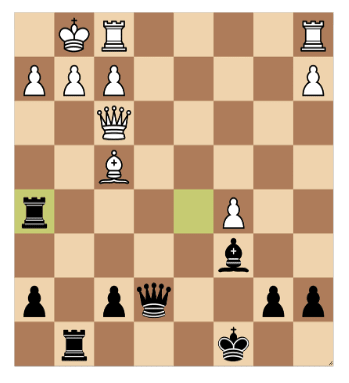
Now down a rook I have to play in a forcing manner: Rxg2 Kh1. Bxg2 instead would allow Bg3 closing the g-line. The king has to move to h1 and now I can move the rook to give a discovered check with the bishop.
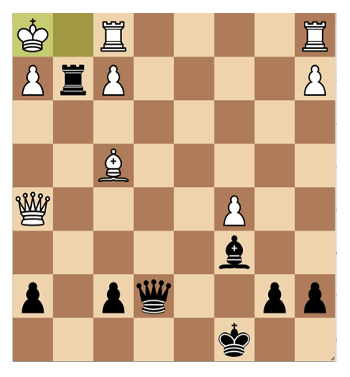
Most of these discovered checks are parried with f3, except Rxf2. So I play that. The king has to move back to g1 and I give a check on g2 again driving the king back to h1. Now the f3-parry against the discovered check has been removed from the position. But if I move the rook down the g-line Rf3 will parry the check instead supported by the queen on h5.
Only one move does not allow the queen to support the rook on f3. That’s rook g4 - breaking the connection between the queen and f3.
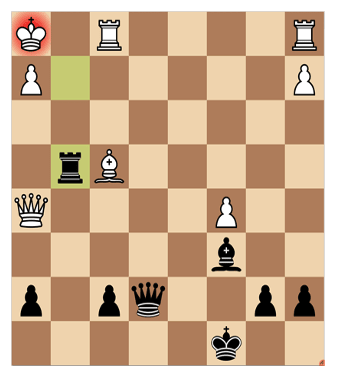
Now, white can only give away the queen and the rook before being mated. He played Rf3 and I played Bxf3 mate.
What is striking to me about my reasoning is how little “tree search” is going on. And this is chess! A game very amenable to search, where also for human players calculating ahead is an integral part of finding good moves.
Instead my reasoning revolves entirely around finding constraints for my future moves and then finding moves that satisfy these constraints.
These constraints flexibly transcend the position on the board.
I consider how much time I have left and in a different game I might consider things like the tournament standing, the strength or style of my opponent, aesthetics, self-improvement, air quality (I gotta get outta here), and much more.
My impression is that much human reasoning is of that form and for a simple reason: It’s very powerful. Constraining the search space until you don’t actually have to search anymore allows you to handle search spaces that are not amenable to pure search.
To quote Russel/Norvig:
In most practical applications, however, general-purpose CSP [Constraint Satisfaction Problem] algorithms can solve problems orders of magnitude larger than those solvable via the general-purpose search algorithms[...].
Search in existing AI systems brute forces human reasoning and does not replicate it. This may often be enough. I suspect for open-ended problems it wont be.
I don’t think you actually prove your point.
The principle of alpha-beta pruning is, roughly, “search for moves until it’s clear that all other moves are bad”. It means that if you find sufficiently good move on first iteration of search, you just stop search and execute this move. And if you have sufficiently good search-ordering heuristics, you won’t have much of tree search.
The point I was trying to make certainly wasn’t that current search implementation necessarily look at every possibility. I am aware that they are heavily optimised, I have implemented Alpha-Beta-Pruning myself.
My point is that humans use structure that is specific to a problem and potentially new and unique to narrow down the search space. None of what currently exists in search pruning compares even remotely.
Which is why all these systems use orders of magnitude more search than humans (even those with Alpha-Beta-Pruning). And this is also why all these systems are narrow enough that you can exploit the structure that is always there to optimise the search.
Because I just stumbled upon this article. Here is Melanie Mitchell’s version of this point: