Trying to find the underlying structure of computational systems
This post was written in the SERI MATS program under John Wentworth.
In our quest to find steering mechanisms in computational systems, we first have to find the right framework to look at the internals of such a system. This framework should naturally express the systems we normally associate with computation, like the brain and computers themselves, as well as more abstract interfaces like Turing Machines. Turing Machines, arithmetic operations, and Neural Nets are in some sense equivalent, so if we use our framework on equivalent computational objects (E.g. a Neural Net and a Turing Machine that simulates it), the representations we get should also be equivalent.
We also want to find meaningful concepts in our chosen framework, like modularity, features, search, and steering mechanisms. But it is hard to evaluate beforehand if we will be able to find these things in a given framework.
My first intuition was that Computational Graphs[1] is what we want. They don’t impose a rigid structure like e.g. Turing Machines would, and we can naturally express many things with them. (I don’t know if they can express the brain’s computation.)
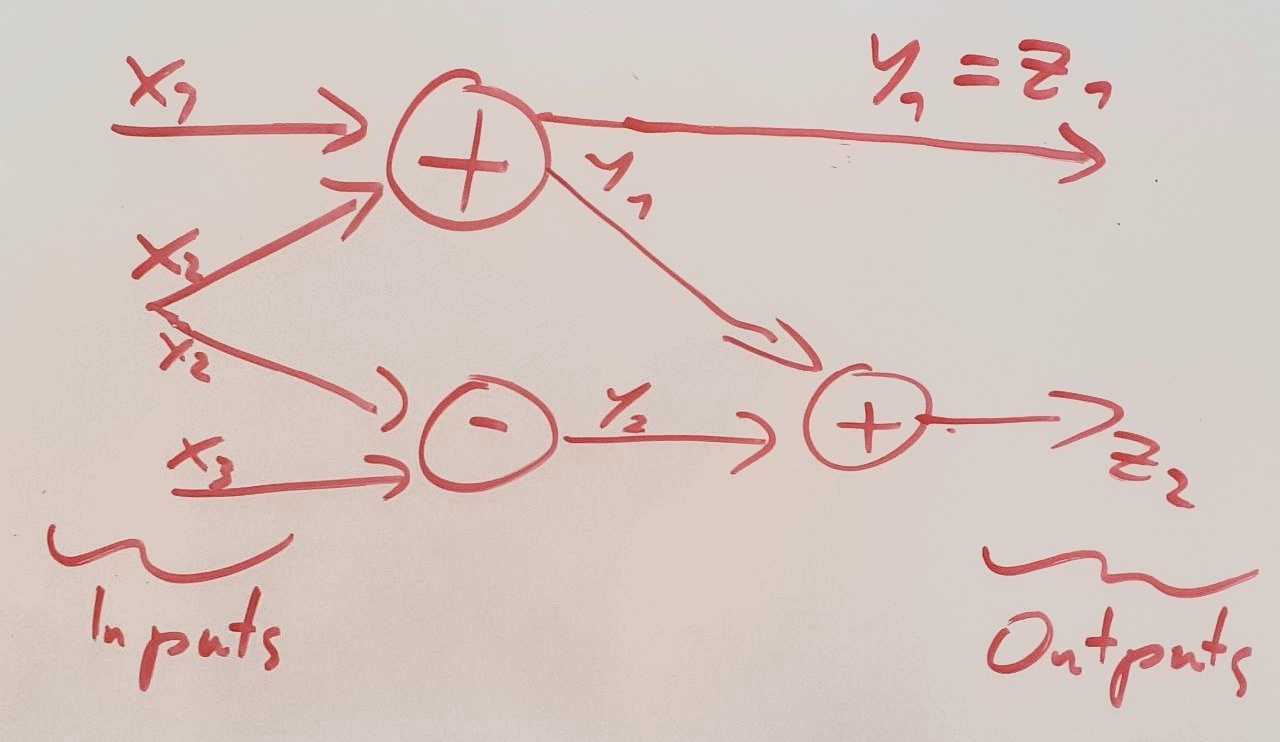
This is essentially the same as causal DAG.
There is some ambiguity in which nodes we choose. We can express certain bit flips in a processor aggregated as addition.
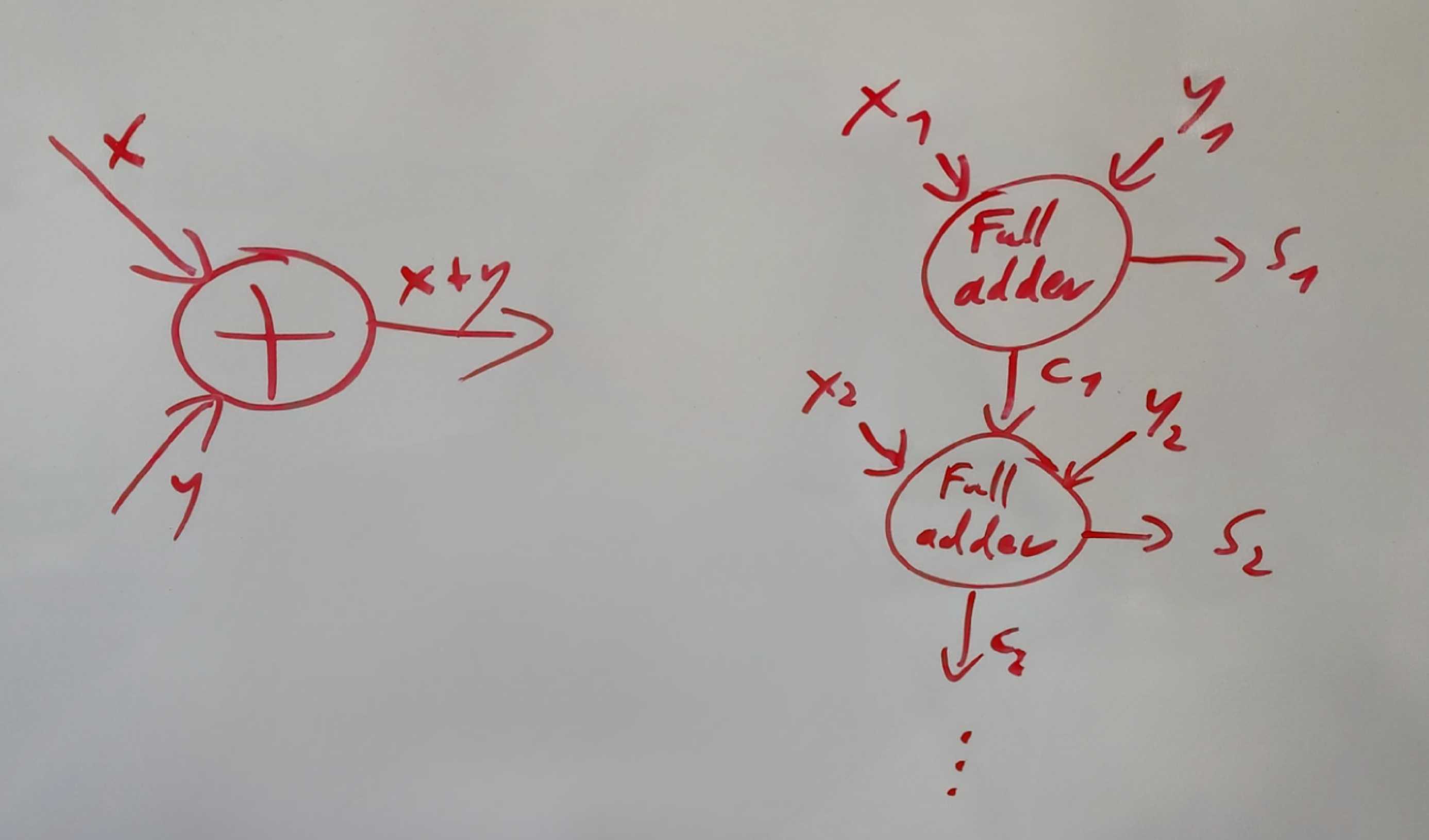
If we choose the algebraic level of detail (left in picture), we implicitly assume that there is no relevant thing going on if we look at the bits (right in picture). Intuitively this seems likely. If we would, for example, look for modularity in a NN, it feels like a module wouldn’t ‘begin’ inside an addition process. Features should not be encoded inside it either.
Computational Graphs work very well for Neural Networks because the graph does not change when we change the inputs. In general, this is not the case. I have not found a crisp way of expressing if-branching in arithmetic graphs. Let’s say we want to express the following program:
def program(a, b, c):
if a:
return b + c
else:
return b - cIt is clear that we can use a Turing Machine for this. When we change the detail level to arithmetic, however, it is not clear to me how to express that the graph depends on a.

Here the result of a computation does not change which values are propagated through the graph. Rather, it changes the graph itself. To be clear[2], I am not looking for a way to express an if-statement in arithmetic (possibly with activation functions). I want to extend the notion of graphs to allow for naturally expressing that a computation result changes the nodes of the graph itself.
Nonetheless, it might still be worth looking at computational graphs since we don’t face those issues when looking at Neural Nets.
Computational States
If we take an actual implementation of a program that produced a computational graph and stop it at a time t, then at this time, the computational state of the program corresponds to the value of all nodes for which a successor is still not computed. In this case, the result of their computation is still relevant to the process and can’t be thrown away. I call a subset of nodes that correspond to a computational state an incomplete Cut, and the full set a complete Cut.
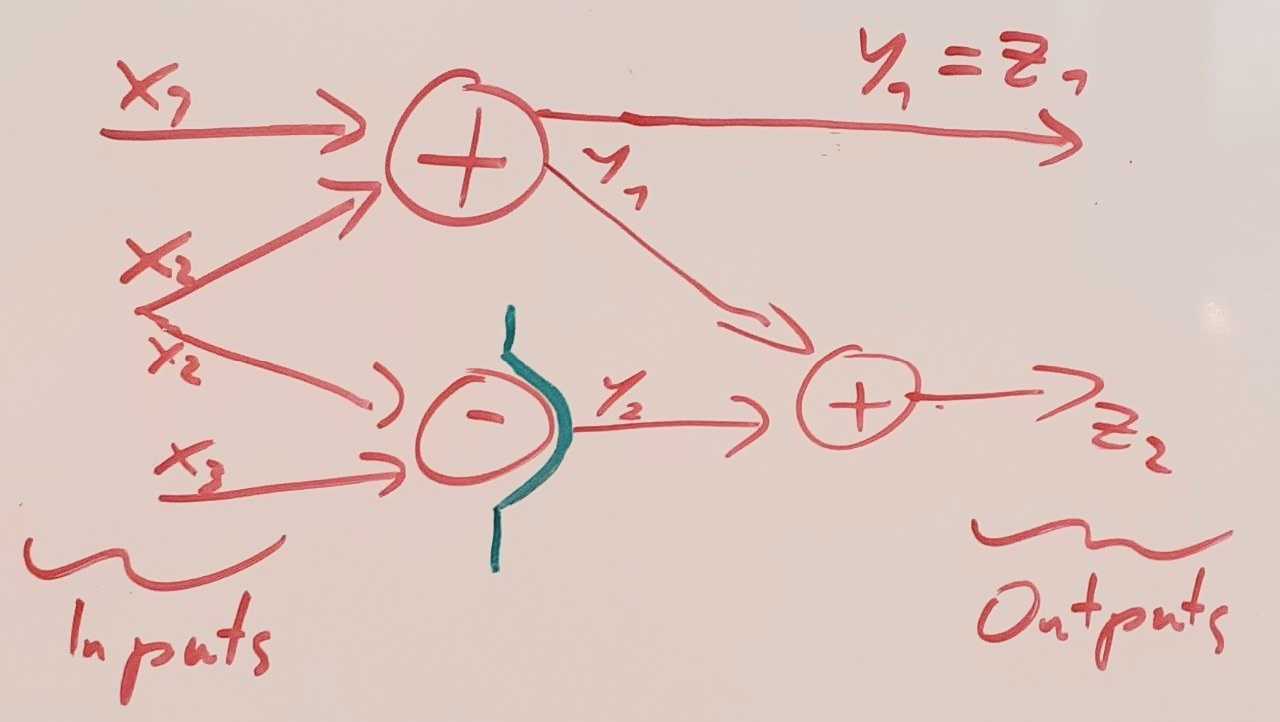
A Cut is complete if and only if every path from input to output goes through it. In the causal DAG setting it corresponds to a Markov Blanket.
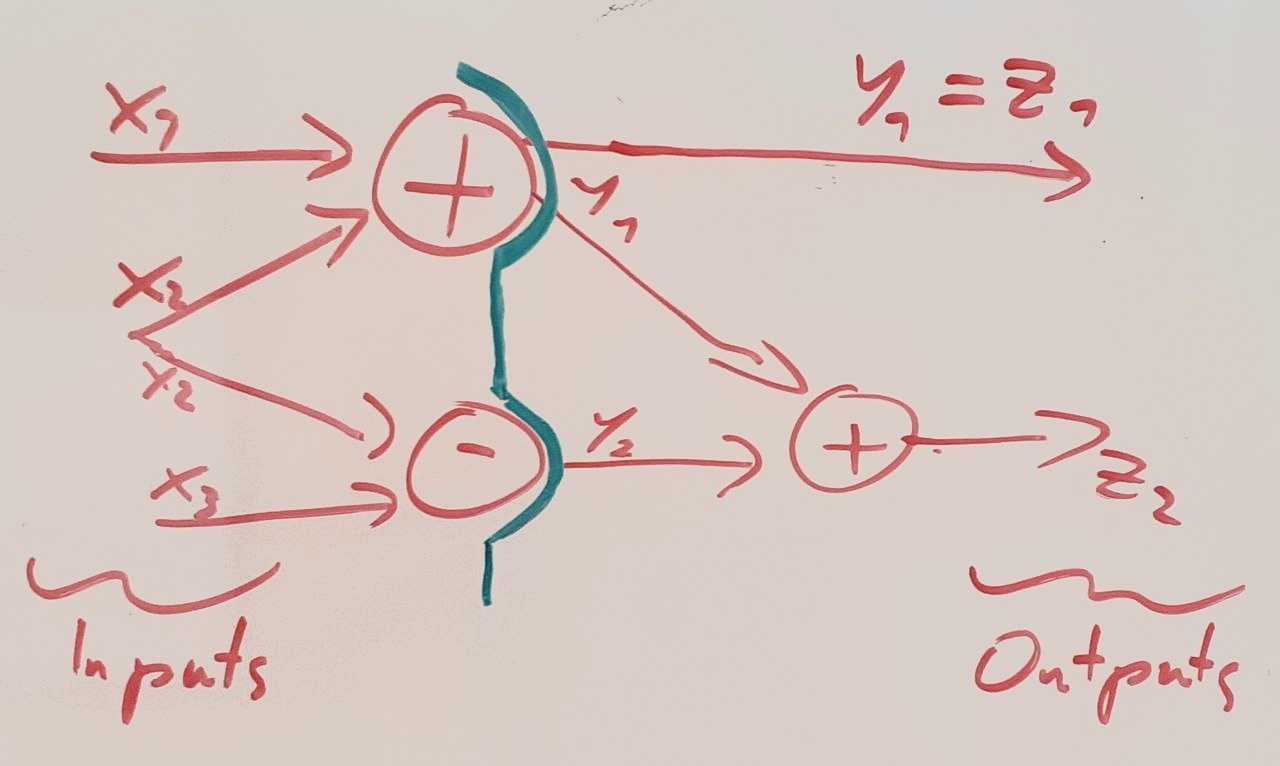
Neuron vs Layer vs Cut Activation Space
Layer Activation Space is a generalization of looking at neurons: If we optimize activations for the length of the projection onto then this is the same as disregarding all components except the ith neuron and maximizing its activation. It is not intuitively clear to me that ‘projection on a vector’ is the right notion of ‘feature activation’. There might be other notions of ‘feature activation’ in activation space. E.g. instead of ignoring orthogonal components, as a projection does, I could imagine penalizing them. Cuts can capture neuron activation or feature activation in activation space in other notions as well.
If we use Neurons as the unit of the computational graph then the Activation Space of a Cut is the vector that corresponds to the neurons in the cut. This Cut Activation Space generalizes both neurons and Layer Activation Space. A neuron is a one-element cut, and a layer is just a cut that contains all the neurons in one Layer.
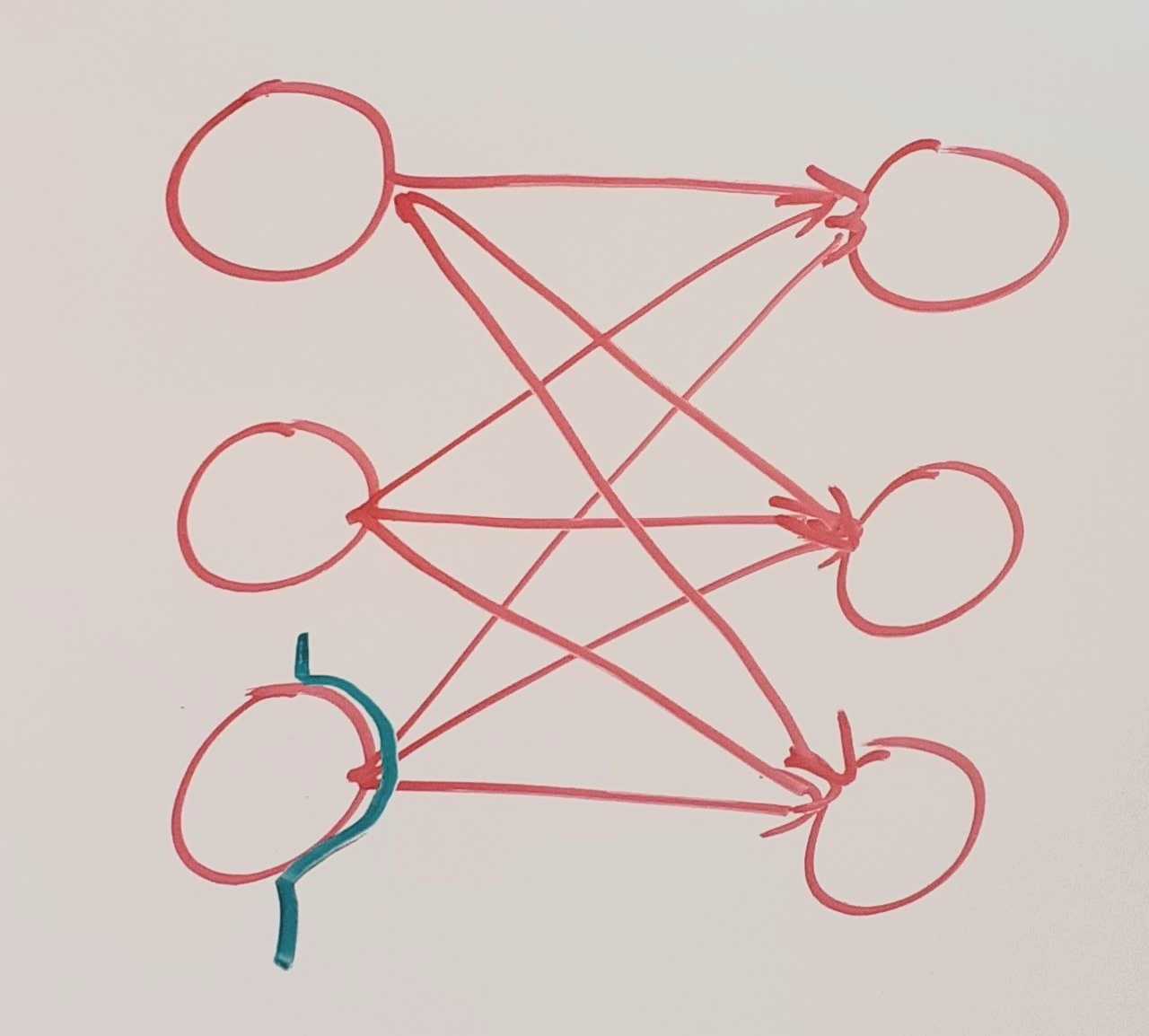
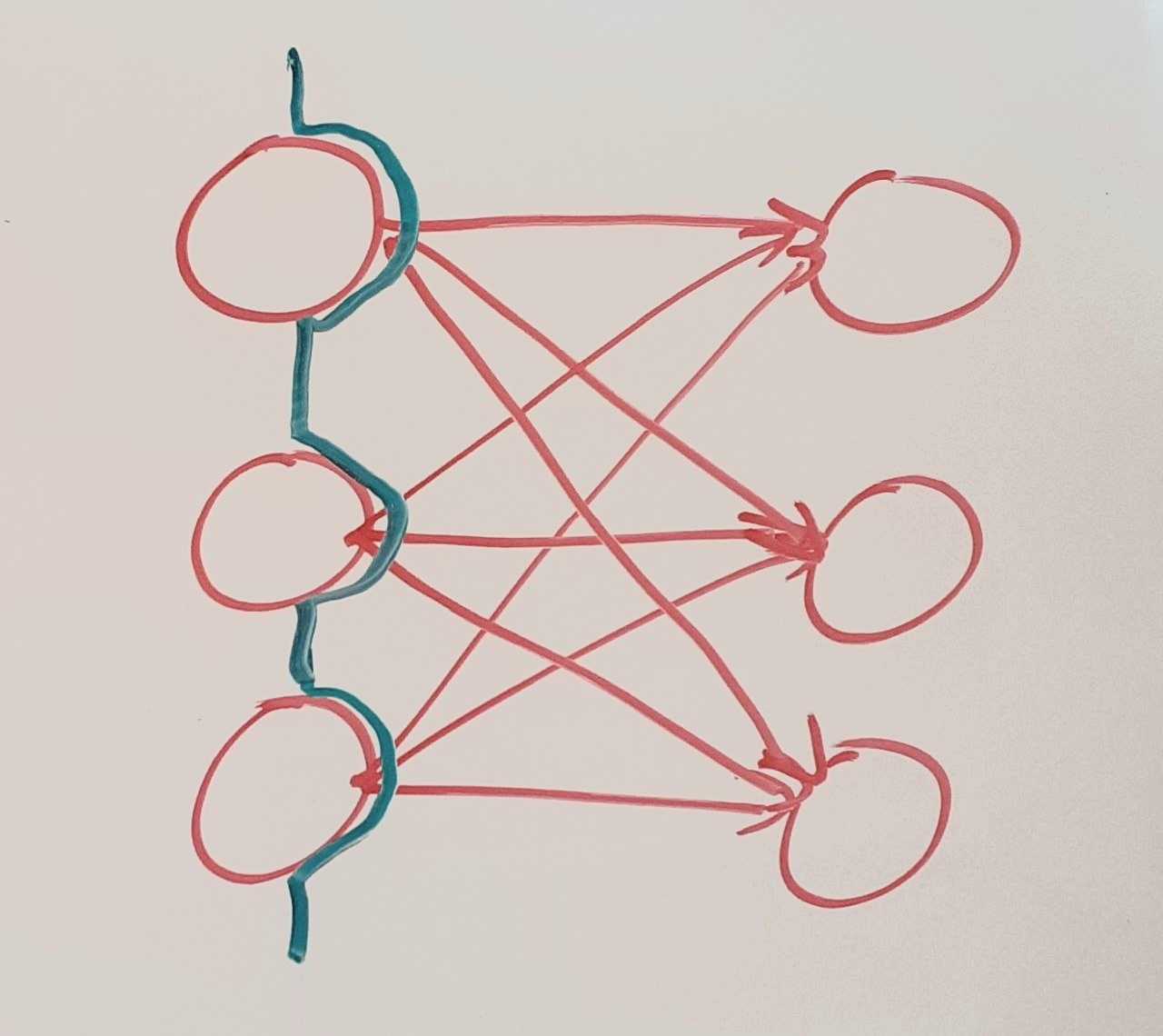
Cuts in NNs
Because in a linear layer everything is connected to everything, not many cuts are possible. But some connections within neural nets are not meaningful. The simplest example is a connection that is being multiplied with a 0-weight. We might want to prune our network to reduce the number of connections that are not meaningful. Maybe we could use counterfactuals to determine how important connections are and leave them out if they are under a certain importance threshold. (similar to the idea discussed here)
What relevance does this have in practice?
In my experience, we talk about neurons or activation space in Interpretability. More specifically, for feature visualization, we maximize activations of neurons or directions in activation space in a CNN. With this Cut idea, we should also look for directions in meaningful cuts (At this point I don’t know when a Cut is meaningful). In the linear layers a meaningful cut could look like this:
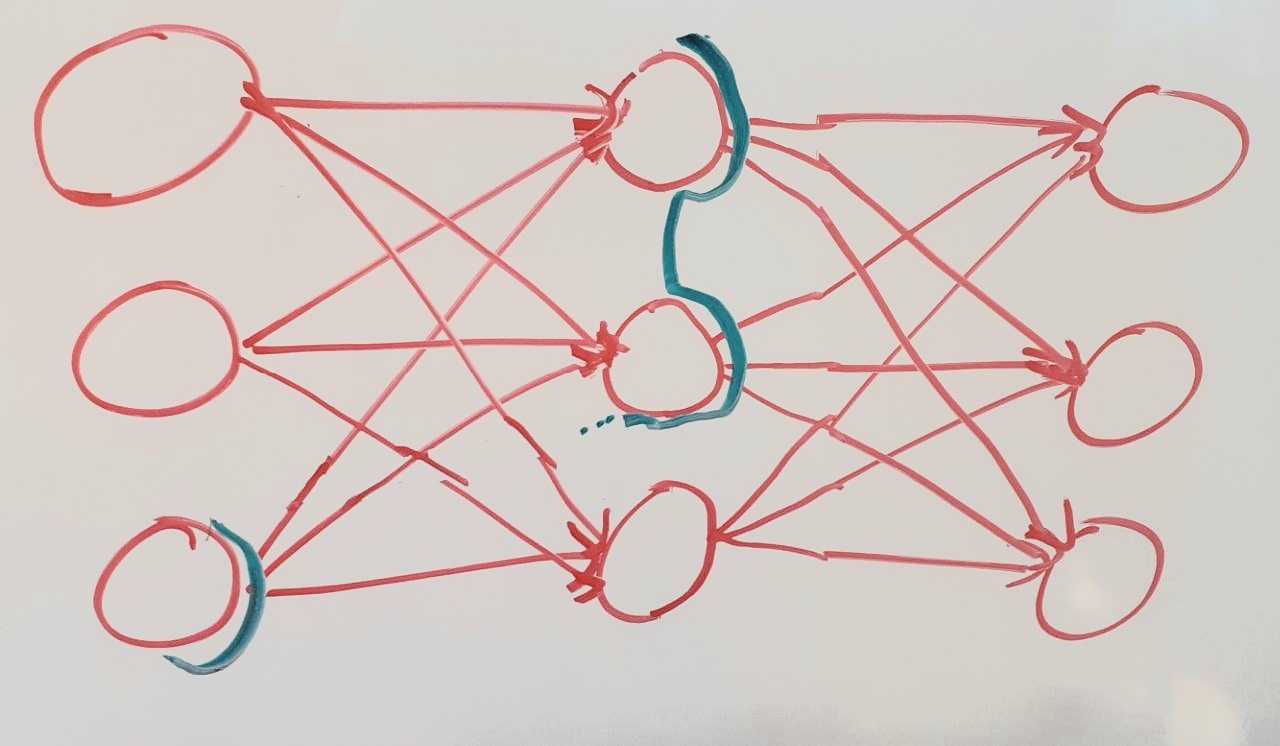
This is still an incomplete cut. There are computation results that don’t go through nodes in the cut. To make this a complete cut, we would have to take all the nodes of the previous layer into the cut.
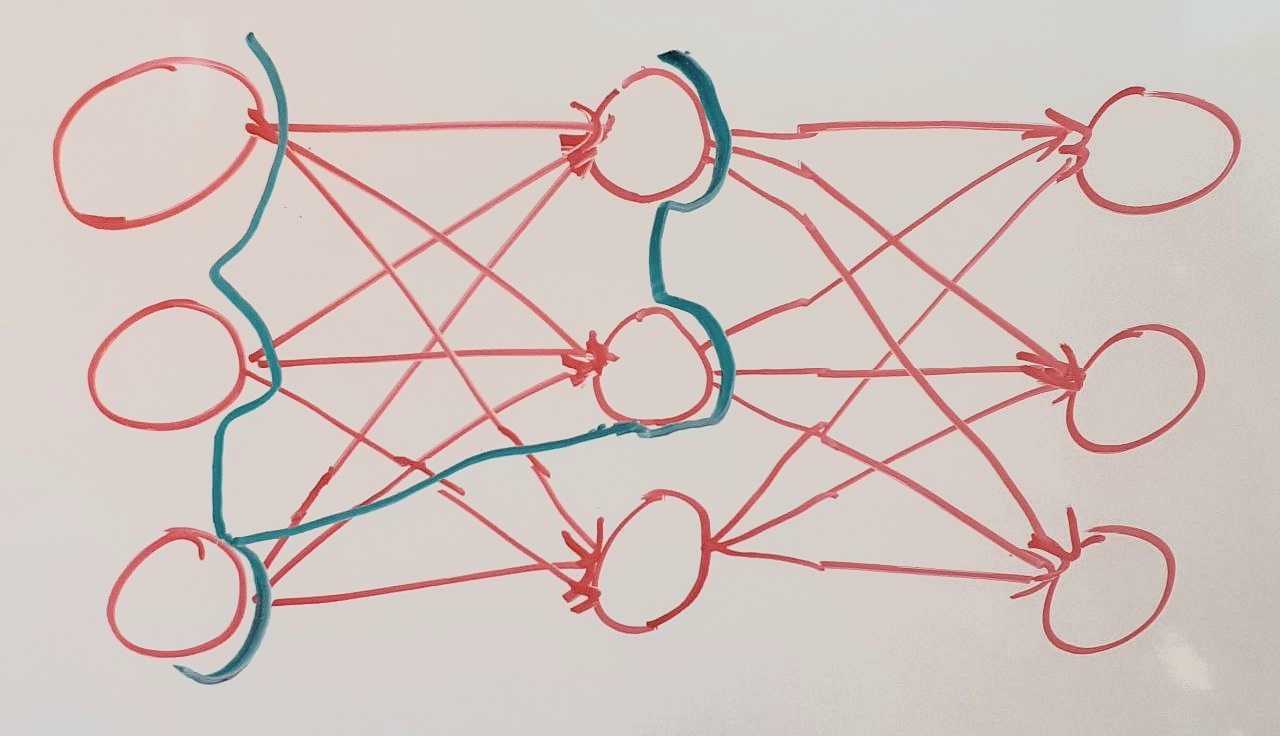
In practice, if we pruned the network or determined connections to be not meaningful then it could look like this:
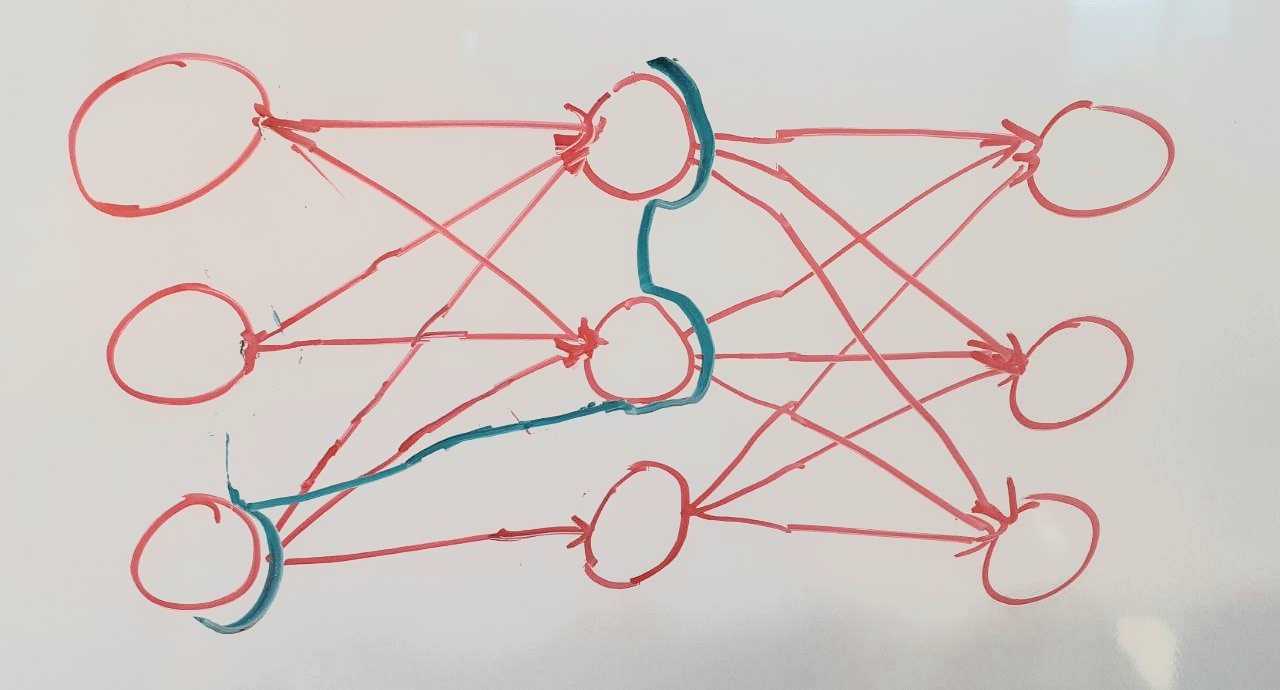
If the idea of Cut Activation Space has merit, we should be able to find meaningful directions in cuts that don’t correspond to layers or neurons. We could test this by e.g. optimizing for different directions in such a cut in a CNN and see if this visualizes a feature. If we only find meaningful features in activation space, then there should be a reason that we can find in this computational graph setting. There is an argument for expecting Layer Activation Space to be the natural cut: Regardless of the order of computation, the whole layer has to be in the computational state at some point. That is because we need the whole layer to calculate the activations of the next one.
Ideally, we would find an algorithm that determines meaningful cuts and meaningful directions in their activation spaces. This seems like a very hard problem.
Going back to our search for steering mechanisms, I feel like we should be able to find a cut that corresponds to the ‘steering information being sent to successive computations’.
Thanks to Justis Millis for proofreading.
Thanks to Stephen Fowler and Adhiraj Nijjer for their feedback on the draft.
- ^
A computational Graph is a Graph where nodes correspond to functions. If a node corresponds to a function (e.g. ‘+’) and has inputs then the node sends through all outgoing edges.
Choosing the functions implicitly assumes a level of detail and determines the expressiveness of the graph. We generally want those functions to be ‘low level’
- ^
This paragraph seems to lead to a misunderstanding of what I mean.
I like the “cut” framing, and I’m happy someone else is having a go at these sorts of questions from a somewhat different angle.
I’m not sure I understand the problem. Neural networks can implement operations equivalent to an if. They’re going to be somewhat complicated, but that’s to be expected. An if just isn’t an elementary operation to arithmetic. It takes some non-linearities to build up.
My current idea is that we should treat layer activation space, or in your more general framing, cut activation space, by looking at it as a space of functions, mapping the input to the activations. Then, look at an orthogonal basis in this function space, where “orthogonal” means something like “every feature is independent of every other feature”. Right now, I’m trying out the L2 Hilbert space norm for this.
With this method, I’d hope to avoid issues of redundancy and cancellations when e.g. calculating modularity scores. It should also, I hope, effectively prune non-meaningful connections.
I can’t say I understand exactly what you’re looking for here, but generally speaking there’s not going to be one true underlying framework for computation. That’s the point of Turing completeness: there are many different equivalent ways to express computation. This is the norm in math as well, e.g. with many different equivalent ways to define e, as well as in mathematical foundations, so the foundation you learn in school (for me it was ZFC, a set theory foundation) is not necessarily the same as you use for computer-checked formal proofs (e.g. Coq uses a type theory foundation).
Turing completeness regards only the functional behavior of a class of computational systems. I want to look at the internals, what the system is actually doing, and find abstractions in there: Modularity, search processes, and steering mechanisms for instance.
So it’s not about finding yet another framework whose expressiveness is equivalent to Turing completeness. It’s about finding a framework to express the actual computation.
In what sense is the functional behavior different from the internals/actual computations? Could you provide a few toy examples?
The internals of a system of course determine its functional behavior. But there might be different systems that differ only in what they actually do. E.g. different sort algorithms all end up with a sorted list but sort it differently. Likewise, a pathfinding algorithm like Dijkstra is different than checking every possible path and picking the best one.
Looking only at functional behavior strips you of your ability to make predictions. You only know what has already happened. You can’t generalize to new inputs.
This is the actual crux of why we care about the internals. We don’t know the functional behavior of a NN except by executing it (There are some Interpretability tools but not sufficiently so). We want to understand what a NN will do before executing it.
Let’s put this in the context of an AGI: We have a giant model which is executed on multiple GPUs. Ideally, we want to know that it won’t kill us without trying to run it. If we would have a method to find ‘search processes’ and similar things going on in its brain, then we could see if it searches for things like ‘how can I disempower humanity?’.
Thanks, that clarifies your aims a lot. Did you gave some thoughts on how your approach would deal with cases of embodied cognition and uses of external memories?
Regarding if-branching in arithmetic: If I understand correctly, you’re looking for a way to express
if a then (b+c) else (b-c)using only arithmetic? If so: Under some assumptions about the types of
a,b, andc, the above can be expressed simply asa*(b+c) + (1-a)*(b-c).Another perspective: Instead of trying to figure out {how a boolean input to an IF-node could change the function in another node}, maybe think of a single curried function node of type
Bool -> X -> X -> Y. Partially applying it to different values of typeBoolwill then give you different functions of typeX -> X -> Y.(Was that helpful?)
This is not what I meant (I’ve edited the post to make that clearer). I am looking for a way to naturally express that a result of a computation changes how the computation progresses. In
a*(b+c) + (1-a)*(b-c)you compute both(b+c)and(b-c). This is not what actually happens in the program.The curried node is an interesting idea but breaks down if we move away from this toy example. If both branches contain subgraphs with a different amount of nodes and different connections between them then currying does not work (or is very unnatural).
(Currying is a nice idea so yes)
Can you say more about what you mean by “steering mechanisms”? Is it something like “outer loop of an optimization algorithm”?
How complex of a computation do you expect to need in order to find an example where cut activations express something that’s hard to find in layer activations?